☺️ AIFFEL 데이터사이언티스트 3기
1.[AIFFEL] Module1. 데이터사이언티스트로 가는 첫걸음
2.Node 01. 터미널로 배우는 리눅스 운영체제

학습 목표운영체제의 구성, 커널의 역할에 대한 이해터미널과 터미널 에뮬레이터, 셸의 차이점 이해기본적인 리눅스 명령어 실습참고 사항❤️: 필수 명령어👍️: 사용법 정도 숙지👌️: 추후 필요할 경우 검색해서 사용echo hello?echo는 뒤에 입력한 내용을 그대로
3.Node 02. 인공지능 개발자가 되기 위한 위대한 첫 걸음

학습목표우분투, 파이썬, 텐서 플로우 설명터미널의 다양한 명령어의 사용아나콘다를 설치하고, 가상환경을 실행시키는 방법 학습Ubuntu 22.04리눅스 기반으로 만들어진 운영 체제운영체제란?정의컴퓨터의 하드웨어를 관리하는 역할컴퓨터 하드웨어를 직접 접근하지 않아도 쉽게
4.Node 03. 개발자를 위한 첫 번째 필수 교양

학습목표Git과 GitHub의 차이 이해Git 명령어(add, commit, push, pull) 학습 및 활용GitHub로 소스코드 버전 관리하기Jupyter Notebook으로 코드/문서 작업하기마크다운 문법 사용하기개발자에게는 협업 능력이 매우 중요!생산성 도구S
5.Node 04. 파이썬과 환경 설정

학습 목표파이썬의 장점을 이해하기IDLE 사용하기코딩알고리즘 : 샌드위치 레시피를 적어낸 과정코딩 : 레시피를 토대로 샌드위치 구현파이썬귀도 반 로섬이름 유래 : ‘short, unique and slightly mysterious’한 이름을 찾아 “Monty Pyth
6.Node 05. 파이썬 용어들

5-1.학습목표파이썬 용어에 익숙해질 것목차 표현식과 문장식별자주석과 출력 : print()파이썬 실행 모드파이썬의 인기 이유
7.Node 06. 자료형(1)

6-1.학습 목표숫자를 나타내는 자료형(정수형, 실수형)의 개념 이해숫자형 자료형 연산문자열을 나타내는 자료형의 개념 이해문자열을 다양하게 다뤄보기
8.Node 07. 자료형(2)

7-1. 학습 목표리스트 자료형 개념 이해함수 활용해 리스트 다루기 튜플 자료형의 개념을 이해, 리스트와의 차이점튜플을 사용하는 이유 파악7-2. 리스트 자료형리스트(list)란?개별 변수
9.Node 08. 자료형(3)

8-1. 들어가며학습 목표딕셔너리 자료형 이해 및 활용집합 자료형 이해 및 특징 설명하기불 자료형 연산변수 활용8-2. 딕셔너리 자료형딕셔너리(Dictionary)란?키(Key), 값(Value)의 쌍을 저장하는 대용량 자료구조파이썬이 아닌 경우에는 연관 배열 또는해시
10.Node 09. 조건문

9-1. 들어가며학습목표다양한 연산자를 읽고 순서에 맞게 쓸 수 있어야 함.if문의 블럭 구조를 이해if - elif - else 순서를 이해하고 코드를 번역하기9-2. 연산자비교 연산자조건식 : 변수값을 비교하는 문장이 오며, 변수가 특정 값인지 평가
11.Node 10. 반복문

10-1. 들어가며학습 목표while문 코드를 읽고 이해하기무한 루프를 빠져 나올 수 있다!for문의 코드를 읽고 이해하기break와 continue의 차이점을 설명할 수 있다!10-2. while 반복문기본 구조유사한 명령을 계속 수행하는 제어문if문처럼 작성하면 된
12.Node 11. 함수

11-1. 들어가며학습 목표예약어 구별간단한 함수 코드를 읽고 이해하기11-2. 예약어(Reserved Words)예약어란?특정 기능을 수행하도록 미리 예약되어 있는 단어예약어는 절대로 변수명으로 쓰일 수 없다!파이썬 3.9 기준으로 36개의 예약어가 있음.참고) 3.
13.Node 12. 함수 활용하기

12-1. 들어가며학습 목표각 인수들의 특징을 이해하고 코드를 이해할 수 있음변수의 범위를 이해하고 구분할 수 있음목차인수의 종류와 리스트와 딕셔너리의 언패킹까지 살펴볼 예정인수의 형식변수의 범위(variable scope)함수에서 재귀호출 사용하기12-2. 인수의 형
14.Node 13. 리스트, 딕셔너리 다루기

학습 목표리스트와 딕셔너리를 다양한 방법으로 다루기리스트와 딕셔너리의 함수를 보고 -> 출력 결과를 예상할 수 있다!컴프리헨션에 대한 이해1차원 리스트리스트 선언 : 1차원 리스트는 1줄!2차원 리스트실제 형태2차원 리스트의 길이(length) = 행의 길이2차원 리스
15.Node 14. 람다, 일급 객체

학습 목표람다 표현식을 읽고 코드의 출력 결과 예상하기람다 함수를 직접 만들기함수가 일급 객체라는 것이 무슨 의미인지 설명하기매개변수와 인수매개변수 : 함수에 입력된 값 받는 변수인수 : 함수 호출 시 전달하는 입력값람다 표현식(Lambda Expression) 람다를
16.Node 15. 예외 처리

학습 목표구문 오류와 예외의 구분예외 처리 방법 배우기예외 강제 발생 방법 및 이유 설명어떤 함수의 내부 함수일 것내부 함수가 외부 함수의 변수를 참조할 것외부 함수가 내부 함수를 반환할 것구문 오류(Syntax error)예외(Exception) 또는 런타임 오류(R
17.Node 16. 모듈, 패키지, 라이브러리

학습 목표원하는 모듈과 패키지를 불러와 사용하기라이브러리와 프레임워크의 차이점 설명하기모듈(module): .py 확장자를 가진 파일(변수, 함수, 클래스, 실행 가능한 코드 등)패키지(package): 모듈 여러 개라이브러리(library): 여러 패키지와 모듈을 모
18.Node 17. 클래스

17-1. 들어가며 학습 목표 클래스 용어에 대한 이해 및 설명 클래스를 만들고 사용하기 17-2. 클래스와 객체 클래스와 객체의 관계 클래스(Class) : 설계도, 무엇을 계속 만들어 내는 틀 (∵ 클래스는 객체 정의 및 생성을 위한 변수와 메서드 집합
20.[AIFFEL] Module2. SQL을 사용하여 데이터베이스 다루기
21.Node 01. 데이터베이스와 테이블

학습 목표데이터베이스에 대한 개념 파악, 많이 쓰이는 관계형 데이터베이스 파악하기관계형 데이터베이스의 테이블에 대한 이해, 테이블의 구성요소와 특징 학습하기스키마에 대한 이해와 데이터 타입 파악하기데이터 == 기록데이터가 모인 공간구조를 짜서 관리하는 데이터의 집합!데
22.Node 02. 데이터 다루기

학습 목표SQL 사용하기 : 테이블 지정, 데이터 조회 쿼리 만드는 방법 학습하기DB 데이터 -> 조건을 통한 데이터 필터링하기특정 필드 데이터 정렬하기연산자로 데이터 세부 조건 만들어보기학습 준비Cloud Shell에 다음 명령어 입력Cloud Jupyter에서 데이
23.Node 03. 다양한 데이터 활용법

학습 내용특정 데이터 조건 : LIKE, Wildcard별칭 :Alias데이터 정렬 : ORDER BY중복 제거 : DISTINCT조건문 : IF다중 조건문 : CASE WHEN ~ THEN데이터 타입 변환 : CAST조회 조건 값 불명확할 경우 사용조건에 문자, 숫자
24.Node 04. 데이터 집계하기

학습목표데이터 그룹화, 집계함수를 통한 통계그룹화된 데이터의 중복없는 집계그룹핑된 데이터에 대한 조건을 통해 세부 추출하기COUNT(\*)\*은 모든 내용을 포함한다는 의미 -> 모든 행 개수 카운트NULL 포함 ✅컬럼의 NULL 값 유무 파악은 ❌COUNT(컬럼명)N
25.Node 05. 여러 개의 테이블 사용하기

학습 목표다수 테이블에 적재된 데이터를 조인해 조회하기여러 테이블에서 필요로 하는 데이터의 조인하기UNION을 이용한 테이블 이어붙이기테이블은 무조건 1개의 기본키DB는 다수의 테이블로 구성되어 -> key를 매개체로 테이블을 연결!PK는 1개의 컬럼 -> 이 데이터는
26.Node 07. SQL 심화 - 빅데이터 기술 톺아보기

빅데이터 톺아보기빅데이터 전반 내용빅쿼리 환경 설정 방법 학습빅쿼리?빅데이터 분석 및 관리 클라우드 기반 데이터 웨어하우스구글 클라우드 플랫폼(GCP)에서 사용데이터 센터에 복제본 3개가 분산 저장되어 유실 위험 적음.테라바이트급 쿼리 -> 초 단위 처리페타바이트급 쿼
27.Node 09. SQL 심화 - 실무에서 많이 쓰이는 고급 SQL 기술

학습목표윈도우 함수를 통한 데이터 분석 능력 키우기그룹 함수를 통해 빠른 자료 정리하기JSON 데이터 처리하기함수 구조 : OVER 구문 필수 사용!ARGUMENTS : 윈도우 함수에 따라 필요한 인수PARTITION BY : 전체 집합에 대해 소그룹을 나누는 기준OR
28.[이론내용만] Node 10. SQL 심화 - SQL로 데이터 분석하기

학습 목표실무 활용 분석 프레임워크 설명분석 프레임워크에 맞춘 SQL 쿼리문 작성분석 결과를 통한 인사이트 도출order 테이블과 payments 테이블을 이용해 모두몰 일별 매출액 총합 구하기기간 : 2018-01-01 이후부터 작성되어 있음.필요한 단계orders와
29.[Project_이론] Node 11. 고객을 세그먼테이션하자!
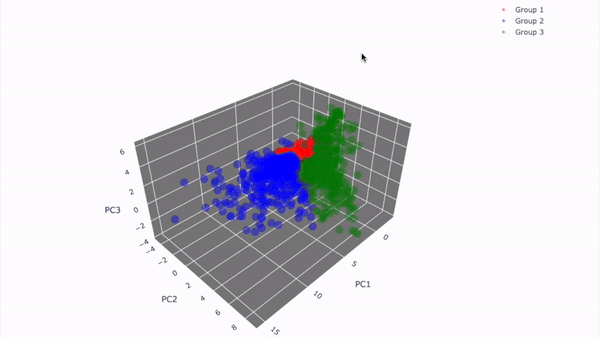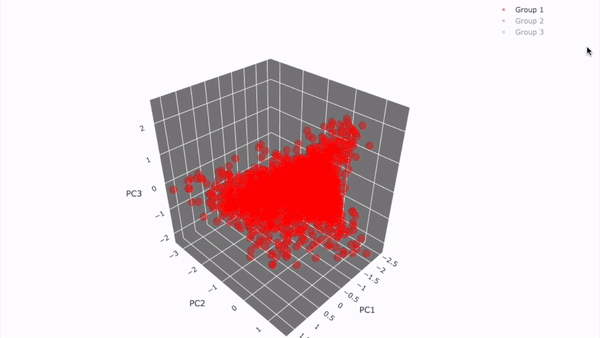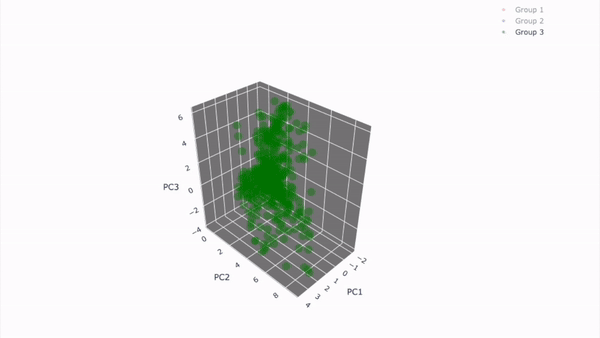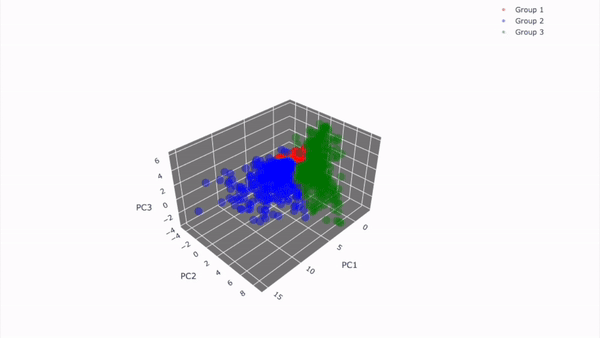
## 11-1. 들어가며 --- ### 해당 프로젝트의 목표 - 데이터에 근거해 고객 분류 및 시각화 - 각 타겟에 따른 **타겟팅 전략** 수립 가능! <br> ### 학습 목표 - 빅쿼리를 이용한 SQL 쿼리문 작성을 통해 원하는 결과 내기 - SQL 쿼리문 작
30.[이론 내용만] Node 12. 고객을 세그먼테이션하자!

데이터 분석으로 고객 세그먼테이션 진행 방식 및 인사이트 파악하기!dataset 내에서 다른 값들과는 달리 큰 차이가 나는 데이터 포인트클러스터링에서 결과 왜곡을 발생시키기 때문에 적절히 식별하고 처리해야 함!클러스터링 : 비슷한 데이터 포인트들을 그룹으로 묶는 것초등
32.[AIFFEL] Module3. 비정제 데이터 체험하기
업로드중..
33.[이론 내용만] Node 01. Data cleaning - 타이타닉 데이터 다루기

결측치 처리이상치 처리시간 데이터 및 텍스트 데이터 변환하기현재 데이터는 결측치 및 이상치 제거 작업을 위해 일부 가공되어 있음.현재 위치 포함도 가능csv 파일을 data로 지정해서 편리하게 불러올 것.data 폴더 안에는 새 파일을 만들 수 없음.그 이유는 뭘까?원
34.Node 02. Data cleaning 택시요금 데이터 다루기 [프로젝트]

🔗 프로젝트 링크github.com/hayannn/AIFFEL_MAIN_QUEST/taxi.ipynb리드미 내용 기록
35.[이론 내용만] Node 03. Data transformation - 연봉 데이터 다루기

데이터의 병합 및 변환데이터 스케일 변환카테고리형 데이터 -> 숫자로 변환데이터 차원 축소임의 데이터 만들기2개df_a, df_bdf_b, df_c인덱스는 새로 들어가지 않고, 기존값 그대로 가져옴 -> 새로 지정하려면 인덱스 리셋 필요3개수평 결합도 가능 : axis
36.Node 04. Data transformation - 영국시장의 중고 자동차 가격 데이터 다루기 [프로젝트]
github.com/hayannn/AIFFEL_MAIN_QUEST/secondhandCarByUK.ipynb데이터 불러오기 데이터를 합칠 기준 설정하기데이터 표준화하기데이터 병합하기카테고리형 변수를 숫자 형태로 변환하기One-Hot Encoding 적용결측치 처리하
37.Node 05. Feature Engineering - 스피드 데이팅 데이터 다루기

상황에 맞는 데이터 처리(다양한 방법을 통해)주어진 데이터 -> 추가 정보 찾아내기gender, age, age_o, race, race_o : 성별, 나이, 상대방 나이, 종교, 상대방 종교importance_same_race : 같은 인종이어야 하는 것에 대해서 얼
38.Node 06. Feature Engineering - 신용거래 이상탐지 데이터 다루기 [프로젝트]

github.com/hayannn/AIFFEL_MAIN_QUEST/FDSProject.ipynb🗂️ CodeFunction데이터 불러오기 데이터 기본 정보 파악하기불필요한 컬럼 제거하기결측치 처리하기이상치 처리하기새로운 Feature 만들기1 거래 시간 관련 Fe
40.[AIFFEL] Module4. 머신러닝 활용 다양한 데이터 다루기
41.Node 01. 데이터를 한눈에! Visualization

파이썬 라이브러리로 그래프 그리기Pandas, Matplotlib, Seaborn데이터셋으로 시각화 진행 -> EDA 및 인사이트 도출해보기사용 라이브러리Matplotlib, Seaborn일반적인 리스트 형식으로 데이터 정의 가능%matplotlib inline :
42.[textBook] Ch 10. 시각화

본 내용은 파이썬 머신러닝 완벽 가이드 교재 및 GitHub를 통해 작성되었으며, 추가된 내용이 있을 수 있음을 알립니다. Visualizaion_Matplotlib https://github.com/hayannn/AIFFELSTUDY/blob/main/textbo
43.Node 02. 사이킷런(scikit-learn) 살펴보기

범주형 데이터의 전처리수치형 데이터의 전처리머신러닝을 이용한 예측python을 이용한 머신러닝 툴(도구)데이터 분석 및 예측을 위한 툴오픈 소스사용이 쉽다는 장점이 있음.학습 : fit, 예측 : predict분류(ex. 스팸인지 아닌지)회귀(ex. 가격 예측)클러스터
44.[textBook] Ch 02. 사이킷런으로 시작하는 머신러닝

본 내용은 파이썬 머신러닝 완벽 가이드 교재 및 GitHub를 통해 작성되었으며, 추가된 내용이 있을 수 있음을 알립니다.hayannn/AIFFEL_STUDY📍github.com/hayannn/붓꽃품종예측.ipynb...📍github.com/hayannn/사이킷런기
45.Node 03. 지도학습(분류)

지도학습(분류) 모델의 활용하이퍼파라미터 튜닝모델의 평가지도학습 알고리즘(분류, 회귀 가능)직관적 알고리즘과대적합되기 쉬운 알고리즘(트리 깊이 제한이 필요함)정보 이득의 최대 기준 == 불순도를 측정하는 기준 == '지니', '엔트로피' 사용데이터 1종류 -> 엔트로피
46.[textBook] Ch 04. 분류

본 내용은 파이썬 머신러닝 완벽 가이드 교재 및 GitHub를 통해 작성되었으며, 추가된 내용이 있을 수 있음을 알립니다.hayannn/AIFFEL_STUDY📍github.com/hayannn/4-1.분류 개요 & 4-2. 결정 트리.ipynb...📍github.c
47.Node 04. 지도학습(회귀)

지도학습(회귀) 모델 활용최적 하이퍼파라미터모델 평가선형 회귀릿지 회귀라쏘 회귀엘라스틱넷 회귀랜덤포레스트 & xgboost하이퍼파라미터 튜닝평가(회귀)단순 선형 회귀 : 독립변수 1개⭐️다중 선형 회귀 : 독립변수 2개 이상자주 사용!비용함수, 목적함수와 동일한 의미데
48.[textBook] Ch 05. 회귀

본 내용은 파이썬 머신러닝 완벽 가이드 교재 및 GitHub를 통해 작성되었으며, 추가된 내용이 있을 수 있음을 알립니다.hayannn/AIFFEL_STUDY📍github.com/hayannn/5.1 회귀소개&5.2 단순선형회귀&5.3 경사하강법&5.4 보스턴주택가격
49.[MainQuest 03] Credit Card Fraud Detection

Mission Kaggle 신용카드 데이터셋을 활용해 "신용카드 사기 검출" 분류 고객이 구매하지 않은 상품에 대한 요금 청구를 방지 조건 분류 알고리즘 사용 예측 값: Class (0:정상, 1:사기) 평가: ROC-AUC 🔗 프로젝트 링크 [Main
50.Node 05. 비지도 학습

비지도학습 이해PCA 실습군집(클러스터링) 학습: 비계층적 클러스터링(K-means), 계층적 클러스터링(전통적)PCA(Principal Component Analysis)차원 축소의 대표적 기법고차원 to 저차원 축소(선형 투영 기법)차원 ⬆️ -> 거리 ⬆️, 오버
51.[textBook] 07. 군집화

본 내용은 파이썬 머신러닝 완벽 가이드 교재 및 GitHub를 통해 작성되었으며, 추가된 내용이 있을 수 있음을 알립니다.hayannn/AIFFEL_STUDY📍github.com/hayannn/7_1_KMeans.ipynb...📍github.com/hayannn/7
52.Node 06. 자연어 처리 / NLP(Natural Language Processing)

참고 자료 : 토큰화(Tokenization)한국어 문장의 형태소 단위 분리자연어 전처리긍정, 부정 감성 분석어휘 사전 구축어휘 사전과 새로 들어온 문장 매칭각 문장 속 단어 출현 횟수 카운팅BOW(Bag Of Word)특정 문서에 출현 빈도수가 높은 단어에 높은 가중
53.[textBook] 08. 텍스트 분석

본 내용은 파이썬 머신러닝 완벽 가이드 교재 및 GitHub를 통해 작성되었으며, 추가된 내용이 있을 수 있음을 알립니다.hayannn/AIFFEL_STUDY📍github.com/hayannn/8.1 텍스트 분석 이해 + 8.2 텍스트 정규화 + 8.3 BOW.ipy
55.[AIFFEL] Module5. 적절한 데이터 분석을 위한 기초통계
56.Day 01. 기초 통계와 탐색적 데이터 분석

1. 통계학의 중요성 통계학 모집단 정보를 알기 위해 표본(샘플)로 추론 모집단 전수 조사에는 시간과 비용 과다 발생 데이터 분석과 통계 분석의 유사성 모집단에 준하는 빅데이터 소유가 가능해져, 데이터 처리/분석 직군이 만들어짐! 데이터 직군 변화 현
57.Day 02. PA와 추론통계

1. Product Analyst 소개 하드 스킬에만 집중하지 말고, "서비스의 성장"에 초점을 맞추기 도구는 바뀌어도 조직 가치는 바뀌지 않기 때문 Product Analyst의 집중 포인트 Descriptive Analysis Ad-hoc 분석
58.Day 03. A/B Test

1. 실험의 종류 일반적 데이터 분석 수집이 끝난 데이터로 -> 기술 통계로 현황 파악 대부분 데이터 분석 입문 -> 기술 통계 및 머신러닝 기법을 통한 예측만 집중해서 추론 통계는 간과하는 경우가 많음! > 참고 기술 통계 : 데이터의 요약 추론 통계 : 관
60.[AIFFEL] Module6. 금융 시계열 체험하기
61.Node 01. 시계열 분석 시작하기

시계열 분석의 방법을 알아보기분석을 위해 필요한 기초 라이브러리 학습어떤 도메인에서 활용하는지 알아보기일정 시간 간격 배치 데이터의 수열(순서 O)시간적 종속이 있다면 시계열 데이터!시간 순서로 정렬된 데이터 -> 유의미한 요약 및 통계 정보 추출을 위한 노력예측에 활
62.Node 02. 시계열 데이터의 성질

\--시계열 기본 성질에서 시계열 요소 알아보기정상성, 정상과정 알아보기1949년 ~ 1960년까지 월간 항공기 이용 승객수 기록 데이터셋시계열 데이터주요 특성 및 분석 시 특징이 뚜렷하여 교육용으로 많이 사용추세(Trend), 계절성(Seasonality), 주기성(
63.Node 03. 시계열 데이터 EDA

시계열 데이터 표현: 그래프 그리기시계열 특화 EDA: ACF Plot, PACF PlotEuStockMarkets 데이터셋독일 주가 지수(DAX), 스위스 주가 지수(SMI), 프랑스 주가 지수(CAC), 영국 주가 지수(FTSE) 포함Line plot데이터 시간 및
64.Node 04. 시계열 분류

시계열 데이터 특징 파악하기tsfresh 라이브러리 파악 & feature 추출하기시계열 데이터 feature 추출 및 검증에 사용target 예측 & 분류에 강함병렬 연산, 사이킷런 호환 가능Maximum(최댓값)한 집합 내 가장 큰 값Minimum(최솟값)한 집합
65.[MiniProject] Node 05. 시계열 분류

🔗 github.com/hayannn/AIFFEL_MAIN_QUEST/MiniProject3비정상 데이터를 정상 데이터로 만들기분류 모델의 성능 높이기비정상 데이터를 정상 데이터로 만들기분산을 일정하게(로그 변환, log transformation)차분으로 추세 제거
66.Node 06. 통계 모델을 활용한 시계열 예측

ARIMA에 대해 알아보기ARIMA의 파생 모델 알아보기 & 실습Overfitting(과대적합)score, accracy는 높게 나오나, 너무 기존 데이터에 적합해서 새 데이터는 예측을 제대로 하지 못하는 경우Underfitting(과소적합)모델이 데이터셋 규칙을 잘
67.Node 07. 금융 시계열의 특징

금융 시계열에서만 나타나는 특징이 무엇이 있는지 파악하기금융 시계열 모델 알아보기 : ARCH, GARCHfactors(팩터)투자 자산의 전체 구성 성분 요소Return(수익률)자본에 대한 수익 비율투자 수익성 지표로 활용Multiperiod Simple Return(
68.[MiniProject] Node 08. ARIMA, ARCH

🔗 github.com/hayannn/AIFFEL_MAIN_QUEST/MiniProject4ARIMA를 통한 시계열 예측 수행ARCH를 통한 S&P500의 변동성 모델링 수행arch & pmdarima 설치ARIMA사용할 라이브러리 import데이터 불러오기 & 형태
69.Node 09. 어제 오른 내 주식, 과연 내일은?

시계열 데이터의 특성 + 안정적(Stationary) 시계열 이해하기ARIMA 모델: AR, MA, Diffencing 이해 및 적용하기주식 데이터에 대한 ARIMA 적용하기굳이 예측하려면, 2가지 전제가 있어야만 예측 가능과거의 데이터에 일정한 패턴이 발견됨과거의 패
70.Node 10. Finance Time Series 데이터 활용하기

Data Labeling 방식에 대한 학습예측값에 대한 설명력 높은 Feature 선정하는 방식에 대한 학습분류기 성능 개선 방안에 대한 학습주가 또는 코인 가격이 일정 방향으로 ➡️ 상승 or 하락 or 꾸준히 유지보합: 상승 or 하락 어떠한 방향으로도 움직이지 않
71.[MainQuest08] 프로젝트: Finance Time Series 데이터 활용하기

해당 내용은 Node 10의 프로젝트(메인 퀘스트) 내용을 담고 있음을 알립니다. 10-6. 프로젝트: Finance Time Series 데이터 활용하기 프로젝트 1. Data Labeling 2. Feature Engineering 3. Model Trainin
73.[AIFFEL] Module7. 딥러닝 알아보기
74.Node 01. 인공지능과 가위바위보 하기

Sequential Model 이용딥러닝 : 데이터 준비 ➡️ 딥러닝 네트워크 설계 ➡️ 학습 ➡️ 테스트(평가)입력 : 손으로 쓴 숫자 이미지출력 : 숫자MNIST Dataset, 텐서플로우 Sequential API를 이용한 숫자 손글씨 인식기 만들기Sequenti
75.Node 03. 딥러닝이란

인공신경망 개념 및 구조 파악인공신경망 역사인공신경망 문제점 및 딥러닝의 역사, 발전 파악인공신경망인공신경망 정의신경 세포인공 뉴런인공신경망 구조인공신경망 역사최초의 인공신경망퍼셉트론다층 퍼셉트론역전파 알고리즘딥러닝 역사인공신경망과 딥러닝기울기 소멸 문제과적합딥러닝의
76.Node 04. 텐서 표현과 연산

탠서 개념 학습텐서 데이터 타입 학습텐서 연산 수행데이터를 담기 위한 컨테이너다차원 배열 or 리스트와 유사수치형 데이터 저장동적 크기용어Rank : 축(차원) 개수Shape: 형상(=각 축 요소 개수)Type: 데이터 타입 TensorFlow import0차원 텐서1
77.Node 05. 딥러닝 구조와 모델

딥러닝 모델(네트워크) 구성 레이어 개념딥러닝 모델 구성 방법 실습딥러닝 구조Core Modules APIModel APILayer API레이어Input 객체Dense 레이어Activation 레이어Flatten 레이어딥러닝 모델Sequential APIFunction
78.Node 06. 딥러닝 모델 학습

딥러닝 모델 학습을 위한 개념 파악손실 함수, 옵티마이저, 지표에 대한 내용 파악손실 함수평균절대오차평균제곱오차원-핫 인코딩교차 엔트로피 오차이진 분류 문제의 교차 크로스 엔트로피옵티마이저와 지표경사하강법볼록함수와 비볼록함수안장점학습률지표딥러닝 모델 학습데이터 생성모델
79.Node 07. 모델 저장과 콜백

딥러닝 모델의 저장 및 복원 방법 학습모델 학습 시 사용 가능한 콜백 함수 학습MNIST 모델 예제모듈 import데이터 load & 전처리모델 구성모델 컴파일 & 학습모델 평가 & 예측모델 저장과 로드콜백(Callbacks)ModelCheckpointEarlyStop
80.Node 08. 모델 학습 기술

딥러닝 모델 학습의 개념 및 기술 파악과소적합 및 과대적합에 대한 설명IMDB 데이터셋 이용 : 긍정/부정 분류 딥러닝 모델 생성모델 학습 기술학습 단위데이터 스케줄링학습률과 에폭은닉층과 뉴런수활성화 함수가중치 초기화옵티마이저과소적합과 과대적합과소적합과대적합과대적합과
81.Node 09. 모델 크기 조절과 규제

딥러닝 모델 크기 조절딥러닝 모델 학습을 위한 규제 배우기모델 크기 조절모델 크기 증가모델 크기 감소규제(Regularization)L1 규제L2 규제L1-L2 규제드롭아웃(Dropout)레이어 유닛수 증가/감소 -> 모델 전체 파라미터 수 증가/감소레이어 수 증가 -
82.Node 10. 가중치 초기화와 배치 정규화

가중치 초기화Reuters 데이터셋 이용 -> 다중 분류를 위한 딥러닝 모델 학습배치 정규화 : 딥러닝 모델의 빠른 학습, 오버피팅 해결가중치 초기화선형 함수 가중치 초기화비선형 함수 가중치 초기화Reuters 딥러닝 모델 예제배치 정규화신경망 성능에 큰 영향을 줌가중
83.Node 11. 딥러닝 모델 실습

Fashion MNIST 데이터셋: 딥러닝 모델 실습모델 최적화: 딥러닝 모델 학습 기술 및 최적화 실습MNIST 손글씨 숫자 인식 유사패션 이미지 -> 10개 종류손글씨 숫자 인식보다는 어려운 형태fashion_mnist importtrain_test_split()
84.Node 13. 텍스트의 다양한 변신 (문자열, 파일 다루기)

파이썬에서의 텍스트 데이터 처리 방법 학습파이썬에서의 텍스트 파일 및 디렉터리 접근 방법 학습텍스트 파일 종류와 다루는 방식 학습텍스트 데이터의 문자열 저장인코딩, 디코딩문자열정규 표현식파일, 디렉터리파일디렉터리모듈 및 패키지포맷 파일CSVXMLJSON문자열(strin
85.Node 14. 텍스트 데이터 다루기

분산 표현의 직관적 이해, 설명문장 데이터의 정제 방법 학습토큰화 기법 학습단어 임베딩(Embedding) 구축 방법 학습
86.Node 16. 텍스트의 분포로 벡터화 하기

단어 빈도 이용: DTM, TF-IDF 구현LSA, LDA형태소 분석기단어 빈도 벡터화Bag of WordsDTM, 코사인 유사도DTM 구현 & 한계점TF-IDFLSA, LDALSA 학습 & 실습LDA 학습 & 실습텍스트 분포 이용 비지도 학습 토크나이저형태소 분석기
87.Node 17. 워드 임베딩

원-핫 인코딩Word2Vec의 CBoW, Skip-gramNegative SamplingFastText, GloVe벡터화텍스트 데이터의 벡터화 방법 학습벡터화 실습 : 원-핫 인코딩워드 임베딩희소 벡터 특징 및 문제점 학습Word2Vec분포 가설CBoW(Continuo
88.Node 18. 뉴스 카테고리 다중분류

18-1. 들어가며 Intro. 머신러닝을 이용한 텍스트 분류 텍스트 분류(Text Classification) 주어진 텍스트를 Pre-defined Class(사전 정의 클래스)로 분류 ex) 스팸 메일 자동 분류, 사용자 리뷰 감성 분류, 뉴스 카테고리 분
90.[AIFFEL] Module8. NLP 프로젝트 톺아보기
91.Day 01. 랭체인 기초, LLM 이론, 랭체인 기초 실습, 프롬프트 템플릿

본 내용은 RAG 시스템 구축을 위한 랭체인 실전 가이드 교재 및 강의 자료, 실습 자료를 사용했음을 알립니다.강의 : \[모두의AI] Langchain 강의실습 : Kane0002/Langchain-RAGLangChain 개념LangChain을 써야 하는 이유Lang
92.Day 02. LLM 챗봇 ,랭체인의 핵심 Retrieval - Document Loaders, Text Splitters

Retrieval Augmented GenerationLLM 답변에 외부 데이터 참조하는 프레임워크랭체인의 RetrievalRAG의 대부분 구성 요소 아우름구성 요소 하나하나 ➡️ RAG 품질에 중요한 영향을 미침순서 1\. Langchain의 Document Loa
93.Day 03. LLM 챗봇 ,랭체인의 핵심 Retrieval - Text Embeddings, Vectorstores, Retriever

본 내용은 RAG 시스템 구축을 위한 랭체인 실전 가이드 교재 및 강의 자료, 실습 자료를 사용했음을 알립니다.강의 : \[모두의AI] Langchain 강의실습 : Kane0002/Langchain-RAG텍스트를 숫자로 변환해 문장 간 유사성 비교가 가능하도록 하는
94.Day 03 Plus(1). 랭체인을 표현하는 언어, LCEL

본 내용은 RAG 시스템 구축을 위한 랭체인 실전 가이드 교재 및 강의 자료, 실습 자료를 사용했음을 알립니다.강의 : \[모두의AI] Langchain 강의실습 : Kane0002/Langchain-RAGLangChain Expression Language랭체인 모듈
95.Day 03 Plus(2). 기본 RAG 시스템 구축하기

본 내용은 RAG 시스템 구축을 위한 랭체인 실전 가이드 교재 및 강의 자료, 실습 자료를 사용했음을 알립니다.강의 : \[모두의AI] Langchain 강의실습 : Kane0002/Langchain-RAG모델 종류API를 통해 Closed source LLM을 활용하
96.Day 04. RAG 완전 정복하기
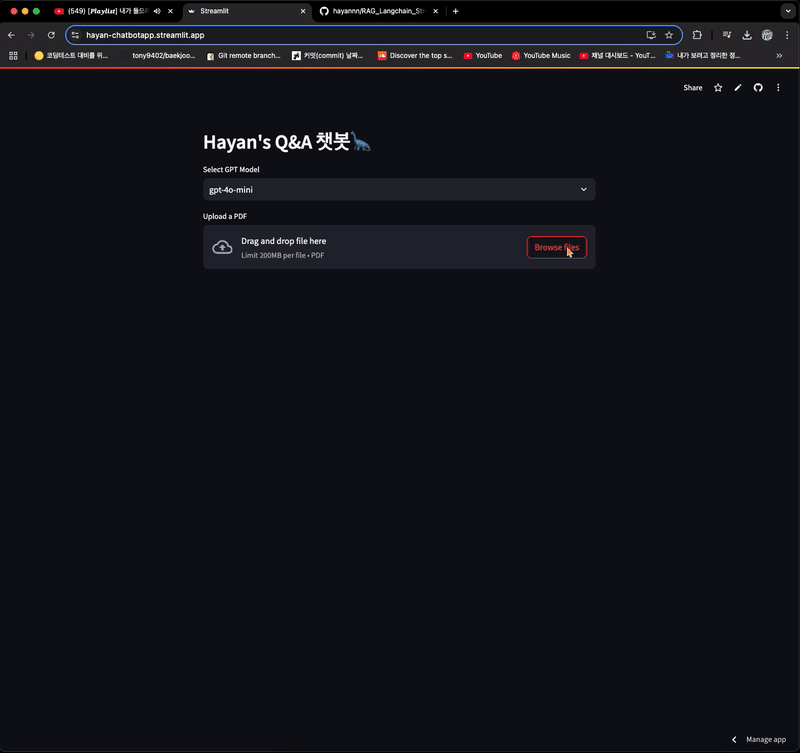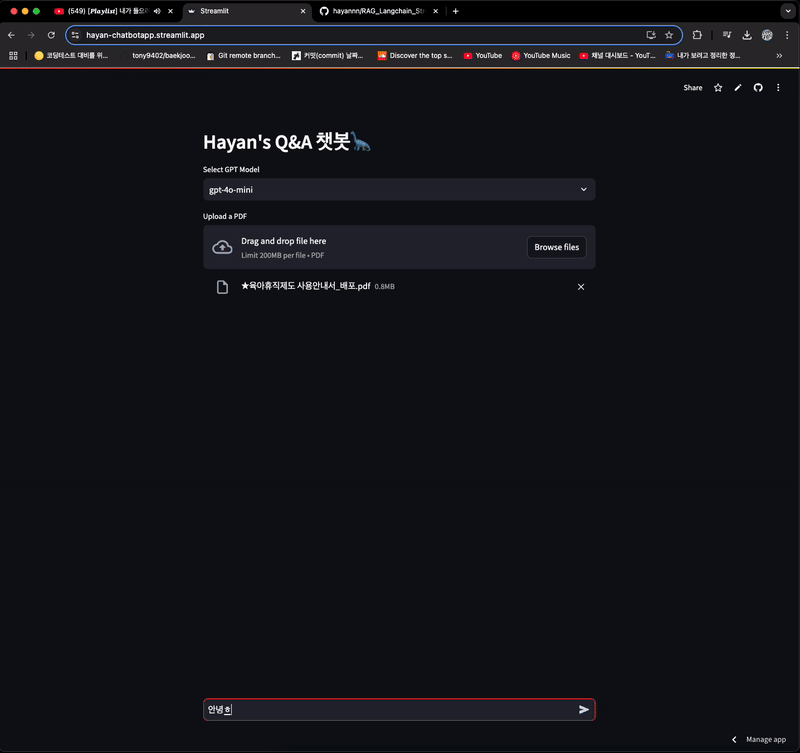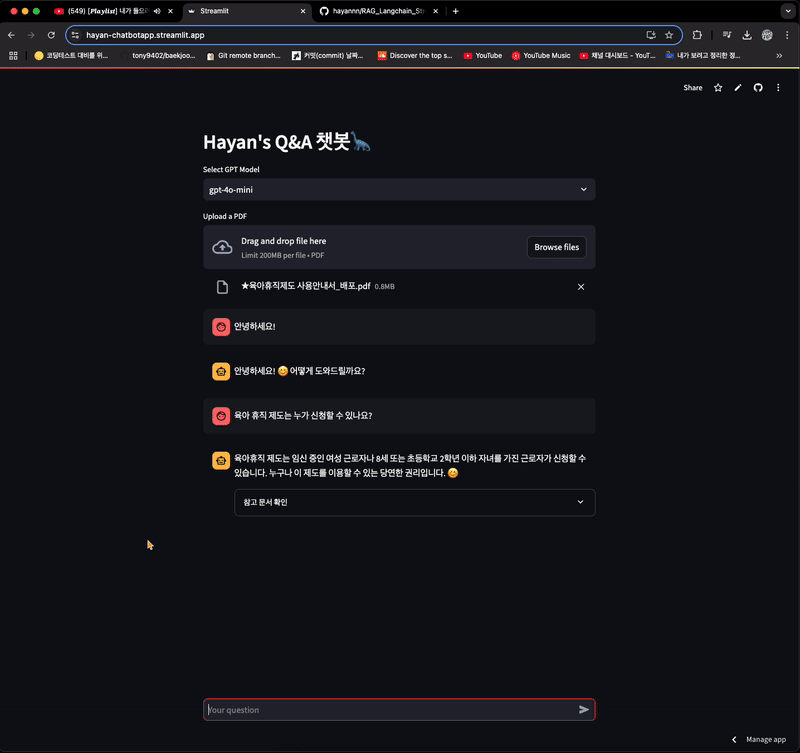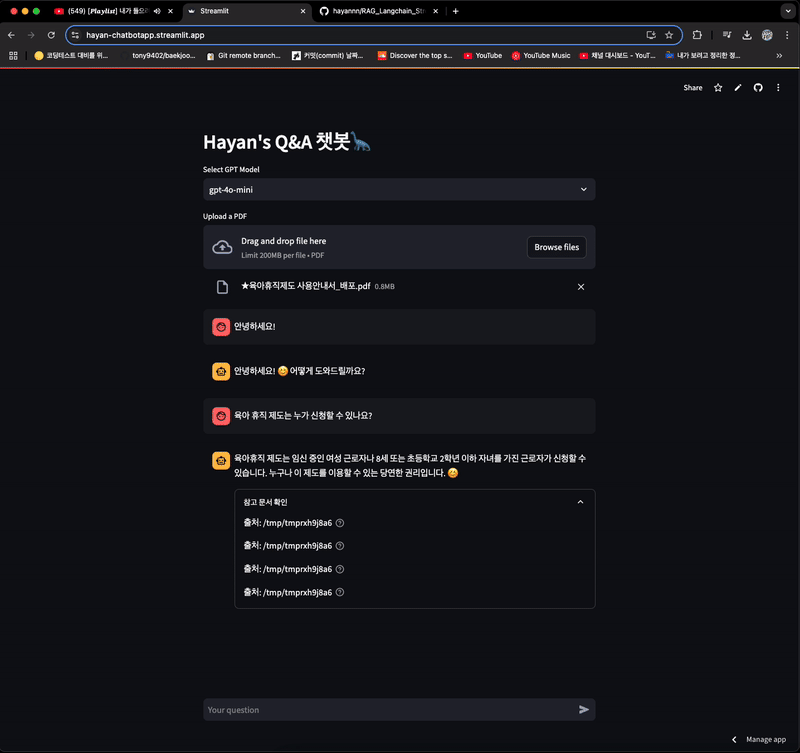
본 내용은 RAG 시스템 구축을 위한 랭체인 실전 가이드 교재 및 강의 자료, 실습 자료를 사용했음을 알립니다. 강의 : [모두의AI] Langchain 강의 실습 : [Kane0002/Langchain-RAG ](https://github.com/Kane0002/La
98.[AIFFEL] Module9. 추천 시스템 체험하기
99.Node 01. 사이킷런을 활용한 추천 시스템 입문

추천 시스템 기본 개념추천 시스템의 종류 학습 및 사이킷런을 이용한 연습실제 추천 시스템 이해추천 시스템이란?코사인 유사도추천 시스템 종류콘텐츠 기반 필터링협업 필터링사용자 기반아이템 기반잠재요인 협업 필터링실제 추천 시스템클라우드 주피터 이용 시 설정 필요사용자에게
100.Node 02. 다음에 볼 영화 예측하기

현재 시점에 고객이 좋아할만한 상품을 추천세션 데이터 기반 "유저가 다음 클릭" or "구매할 아이템 예측"으로 추천Session유저가 서비스를 이용하며 발생한 중요 정보를 담은 데이터서버에 저장유저 행동 데이터가 ➡️ 유저 측 브라우저를 통해 ➡️ 쿠키로 저장쿠키가
101.Node 03. 다음에 볼 영화 예측하기 [프로젝트]

github.com/hayannn/AIFFEL_MAIN_QUEST/MiniProject7/Movielens 영화 SBR_hayan.ipynb필요한 라이브러리 import데이터 로드Step 1. 데이터의 전처리ItemIdTimeSession 기본 설정Rating세션
102.Node 04. 아이유팬이 좋아할 만한 다른 아티스트 찾기

추천 시스템의 개념과 목적 파악Implicit 라이브러리를 이용한 MF 기반 추천 모델 생성음악 감상 기록을 이용한 유사 아티스트 찾기 및 추천CSR Matrix추천 시스템에서 자주 사용되는 데이터 구조유저 행위 데이터의 차이점Explicit dataImplicit d
103.Node 05. 딥러닝 기반 추천 시스템 - 딥러닝과 추천 시스템: 배경과 개요

Node 05. 딥러닝과 추천 시스템: 배경과 개요딥러닝의 시대와 추천 시스템딥러닝 추천 시스템 적용 사례추천 시스템은 딥러닝 알고리즘만 중요할까요?Node 06. 다양한 딥러닝 기반 추천 시스템: 특징과 목표협업 필터링의 발전Shallow 영역과 Deep 영역어텐션을
104.Node 06. 딥러닝 기반 추천 시스템 - 다양한 딥러닝 기반 추천 시스템: 특징과 목표

이미지 출처는 링크 or 아이펠 교육 자료입니다.협업 필터링의 발전CF와 NCFShallow 영역과 Deep 영역Shallow와 Deep의 융합어텐션을 활용한 추천 시스템어텐션과 추천 시스템다양한 딥러닝 기반 추천 시스템SequentialGraphImageLLM다양한
105.Node 07. 딥러닝 기반 추천 시스템 - 추천 시스템을 설계할 때 겪을 수 있는 문제들

추천 시스템 구축 전준비 단계(Feat. 데이터)추천 시스템을 괴롭히는 문제콜드 스타트(Cold start)다양성(Diversity)콜드 스타트와 다양성 문제추천 시스템 구축과 적용 후추천 모델과 시스템 관리추천 시스템 개발자커리어와 취업추천 시스템 구축 시 겪을 수
106.Node 08. 딥러닝 기반 추천 시스템 - 추천 시스템, 모델 톺아보기: 논문과 코드

이미지 출처는 링크 or 아이펠 교육 자료입니다.추천 시스템 논문을 학습하기 전에평가 방법활용 데이터 셋NCF논문 및 코드 리뷰DeepFM논문 및 코드 리뷰AutoInt논문 및 코드 리뷰HAFP논문 리뷰딥러닝 기반 추천 시스템에 대한 다양한 논문에 대한 이해 및 핵심
108.[AIFFEL] Module10. 데이터 분석 실무 알아보기
109.Node 01. MLOps 소개

이미지 출처는 링크 or 아이펠 교육 자료입니다.MLOps 소개도커 활용GCP 소개Airflow 소개파이프라인코드 : Google Colab, GitHub에 있음Google Colab 링크GitHub 링크GCP, Google Colab이 사용되니 미리 준비될 것강의 이
110.Node 02. 도커 활용

2-1. Docker 소개 및 설치 학습 목표 Docker 기술에 대한 이해, 기술 장단점 살펴보기 웹 서버를 통한 Docker 이용 및 실습 도커 스웜, 도커 컴포즈 이해 및 실습 쿠버네티스, Kubeflow 학습 개발 환경 vs 서비스 환경 개발 환경 mac
111.Node 03. GCP 소개

이미지 출처는 링크 or 아이펠 교육 자료입니다.Google Cloud 소개BigQuery 학습(데이터 웨어하우스 도구)예제 학습(BigQuery를 통한 대규모 데이터 처리, 실시간 처리를 다룸)Vertex AIGoogle Cloud 제공 클라우드 서비스AI, ML,
112.Node 04. Airflow 소개

이미지 출처는 링크 or 아이펠 교육 자료입니다.Airflow 소개데이터 워크플로우 관리 도구에 대한 학습예제 학습Airflow의 구성 및 예제를 통한 실습데이터 워크플로우MLOps에서의 데이터 워크 플로우의 관리 이유 설명데이터 아키텍쳐실제 환경에서의 데이터 처리를
113.Node 05. 파이프라인

CI/CD 소개모델 학습 파이프라인 개요모델 배포 파이프라인 개요예제 학습소프트웨어 개발 생애 주기에서의 CI(지속 통합), CD(지속 배포)로 코드 변경점을 자동화, 검증, 배포까지의 프로세스를 운영하는 것Linting: Lint 설정을 통해 코드 스타일이 지켜지지
114.Node 06. MLOps 프로젝트

이미지 출처는 링크 or 아이펠 교육 자료입니다.추천 시스템 동작 방식왼쪽 ➡️ 오른쪽: 가장 관심사일 것으로 예측되는 경우의 작품을 가장 왼쪽에 배치위 ➡️ 아래: 시리즈 중 가장 관심 있을만한 시리즈를 가장 상단에 배치이미지: 이미지도 추천을 해줌!추천 시스템의 동
115.[AIFFEL] 데이터사이언티스트 3기 회고

안녕하세요! 오랜만에 회고글로 찾아왔습니다. 그동안은 딱딱한 글들로 자주 찾아뵈었는데,, 오늘은 회고를 한 번 해보려고 해요. 전, 지난 2024년 10월부터 지금까지 데이터 관련 직무로의 전환을 위해 총 6개월 간 아이펠 데이터사이언티스트 3기 과정에 참여했습니다.