
3-1. 들어가며
학습목표
- 지도학습(분류) 모델의 활용
- 하이퍼파라미터 튜닝
- 모델의 평가
3-2. 의사결정나무
의사결정 나무모델
- 지도학습 알고리즘(분류, 회귀 가능)
- 직관적 알고리즘
- 과대적합되기 쉬운 알고리즘(트리 깊이 제한이 필요함)
- 정보 이득의 최대 기준 == 불순도를 측정하는 기준 == '지니', '엔트로피' 사용
- 데이터 1종류 -> 엔트로피/지니 불순도 ≒ 0
- 서로 다른 데이터 비율이 비슷 ≒ 1
- 정보 이득 최대 -> 1-불순도 즉, 불순도가 낮은 값 찾기
데이터셋 설정
의사결정나무 설정

의사결정나무 하이퍼파라미터
-
criterion
- 디폴트 : gini
- 불순도 지표(엔트로피 불순도)
-
max_depth
- 디폴트 : None
- 맥시멈 뎁스
-
min_samples_split
- 디폴트 2
- 자식 노드를 가지기 위한 최소 데이터 개수
-
min_samples_leaf
- 디폴트 1
- leaf 노드가 되기 위해 필요한 최소 샘플 개수
-
지니 vs 엔트로피


3-3. 랜덤포레스트
랜덤포레스트란?
- 지도학습 알고리즘(분류, 회귀 가능)
- 의사결정나무의 ➡️ 앙상블!
- 다수의 의사결정 트리로 구성됨
- 과대적합 가능성 낮음 ➡️ 성능이 좋음
- 부트스트랩 샘플링이기 때문에 데이터셋 중복을 허용함
- 최종 다수결 투표
- 배깅(bagging) 방식
앙상블 기법
- 배깅 : 같은 알고리즘 -> 여러 모델 생성해 분류(랜덤포레스트)
- 부스팅 : 학습 및 예측을 해서 가중치를 반영(xgboost)
랜덤포레스트 적용
random_state = 0으로 랜덤값 고정

랜덤포레스트 하이퍼파라미터
-
n_estimators
- 디폴트 100
- 트리 개수
-
criterion
- 디폴트 gini
- 불순도 지표
-
max_depth
- 디폴트 None
- 맥시멈 뎁스
-
min_samples_split
- 디폴트 2
- 자식 노드를 가지기 위한 최소 데이터 개수
-
min_samples_leaf
- 디폴트 1
- leaf 노드가 되기 위해 필요한 최소 샘플 개수
-
뎁스를 얇게 하면? -> 성능 떨어짐!

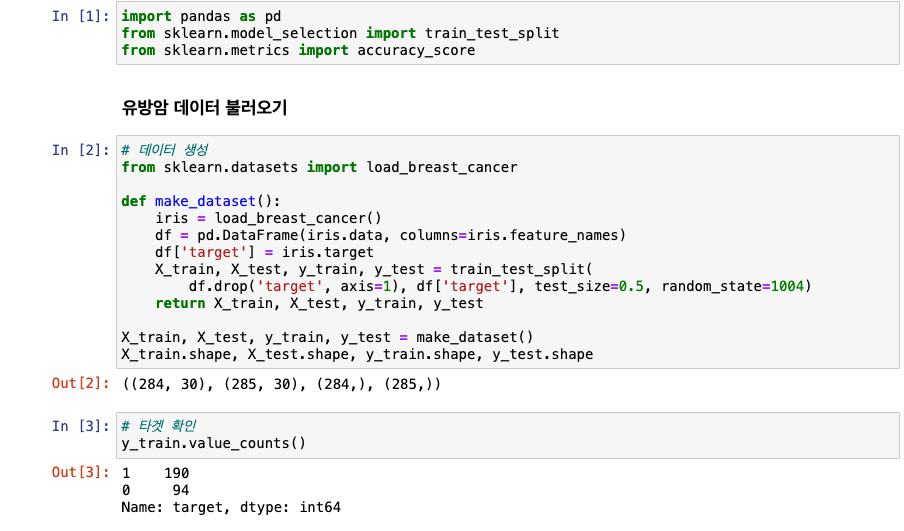
- n_estimators(트리 개수) -> 많아지면 -> 속도가 느려짐
- 이 데이터셋에서는 트리 개수가 많아지니 정확도가 올라감

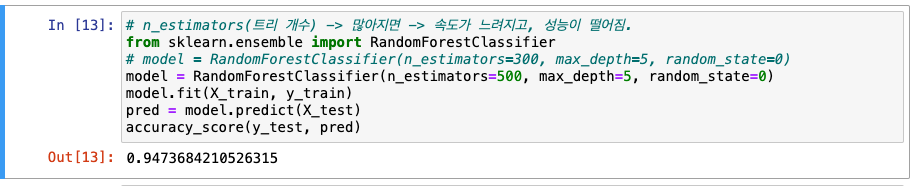
- 이 데이터셋에서는 트리 개수가 많아지니 정확도가 올라감
3-4. xgboost
XGBoost
- eXtreme Gradient Boosting
- 부스팅(앙상블) 기반 알고리즘
- 트리 앙상블 중 가장 성능 Good
- 약한 학습기 -> 지속 업데이트를 해서 좋은 모델을 만듦
- 캐글에서 뛰어난 성능을 보여 인기 UP
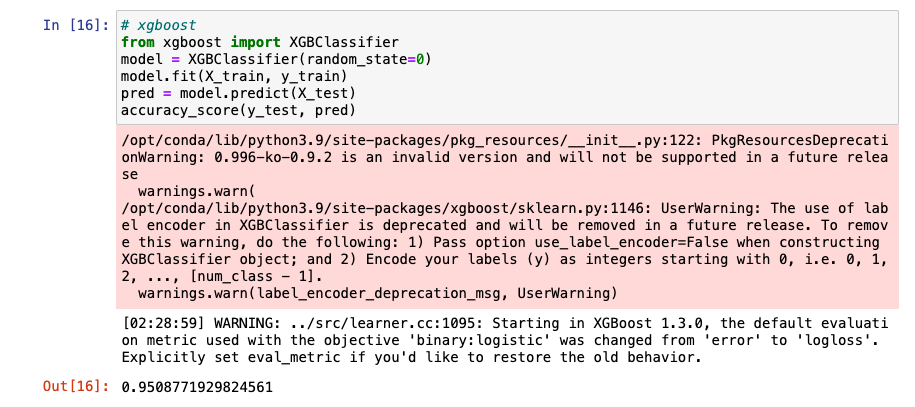
XGBoost 사용해보기
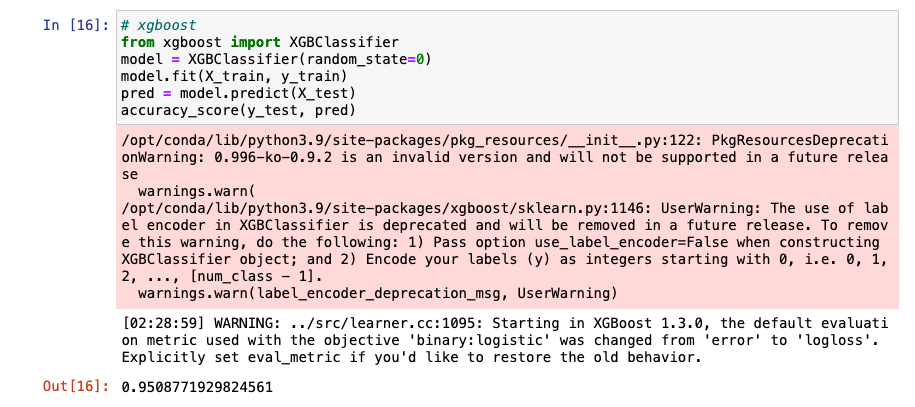
- warning 제거(파라미터 추가)
XGBoost 하이퍼파라미터
-
booster
- 디폴트 gbtree(dart, gblinear 등도 있음)
- 부스팅 알고리즘
-
objective
- 디폴트 binary:logistic(이진분류 할 때)
- 다중분류는 multi:softmax
-
max_depth
- 디폴트 6
- 맥시멈 뎁스
-
learning_rate
- 디폴트 0.1
- 학습률
기울기가 0인 지점을 찾아나가는데, 그 간격이 0.1인 것
- 보폭이 작으면 -> 지점을 찾는데 더 오랜 시간이 소요되는 원리!
-
n_estimators
- 디폴트 100
- 트리 개수
여기에서는 한 트리에서 학습한 걸 바탕으로 다음 트리 학습!(기존에는 각각 트리마다 학습하고 Voting했었음)
-
subsample
- 디폴트 1
- 훈련 샘플 개수 비율
-
colsample_bytree
- 디폴트 1
- 피쳐 개수 비율
-
n_jobs
- 디폴트 1(-1의 경우 모든 코어를 다 사용중일 경우임)
- 사용 코어 개수
-
max_depth 올리기 전
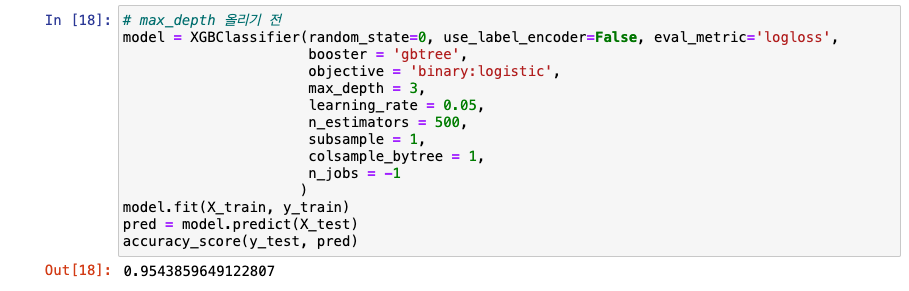
-
max_depth를 5로 올리면? -> 성능 향상!
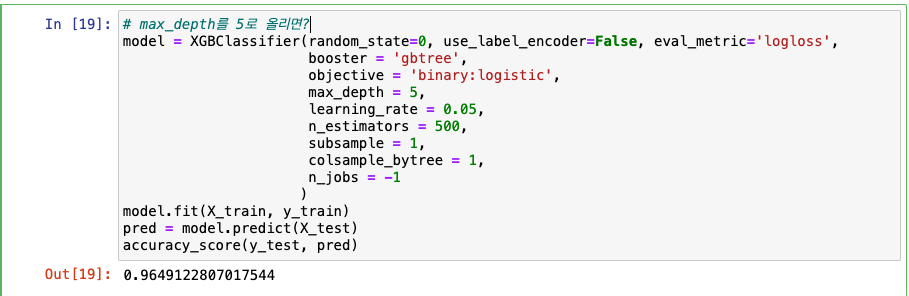
-
성능이 더 올라가는지 체크 -> learning_rate 0.1에서 0.05, n_estimators 100에서 500으로
- learning_rate를 낮추고, n_estimators를 높이면 -> 성능 향상에 도움!
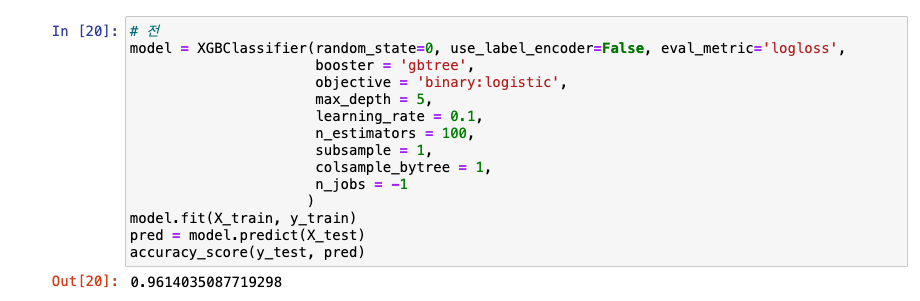

- learning_rate를 낮추고, n_estimators를 높이면 -> 성능 향상에 도움!
조기 종료
eval_set = [(X_test, y_test)]: 검증 데이터 설정early_stopping_rounds=10: 10번 이상의 성능 향상이 없다면 종료한다는 의미

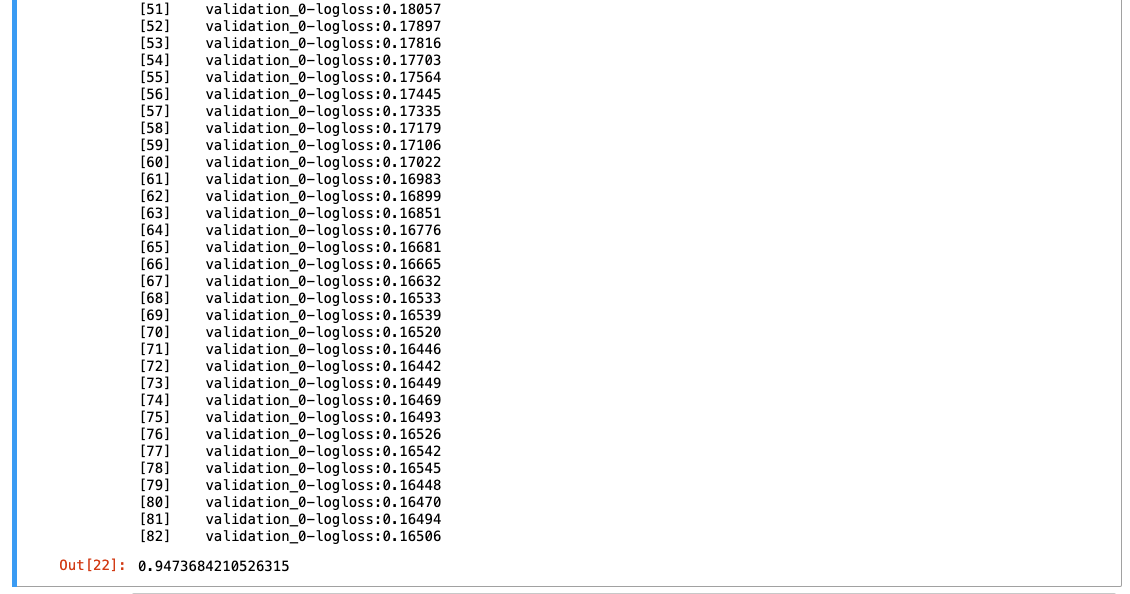
3-5. 교차검증
교차검증이란?
- 모델 학습 시 데이터는 train set, test set으로 나누고 train set으로 학습 수행
- 이 train set을 ➡️ 다시 train set, validation set으로 분리 ➡️ 학습중에 검증 및 수정 수행!
데이터셋 로드

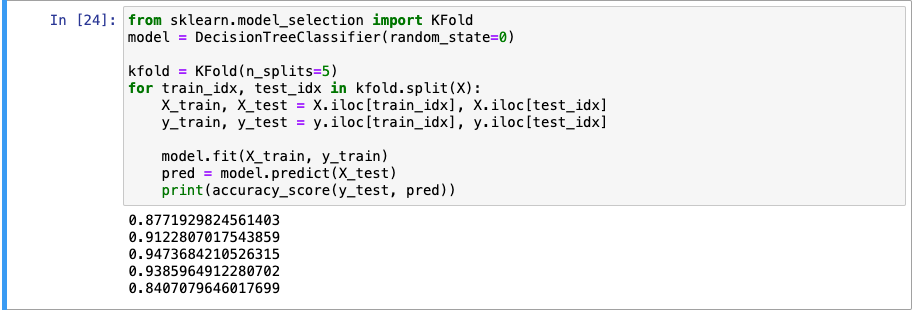
Kfold
- 일반적인 교차 검증 기법
- test set과 validation set을 번갈아가며 수행
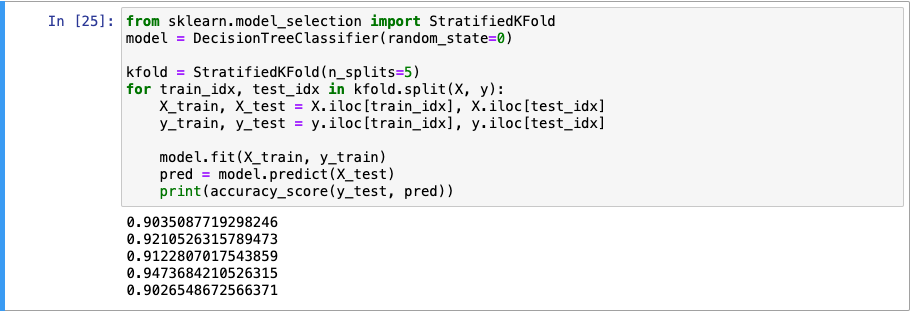
StratifiedKfold
- 불균형 타겟 비율을 가진 데이터가 -> 편중(한쪽으로 치우침)되는 것 방지
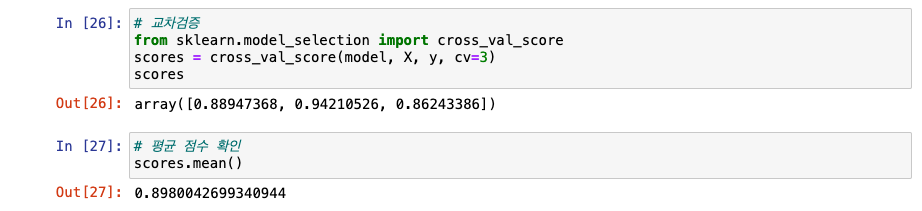
사이킷런 교차검증
-
사이킷런 내부 API로 실행
- fit ➡️ predict ➡️ evaluation순
- 학습 ➡️ 예측 ➡️ 평가
-
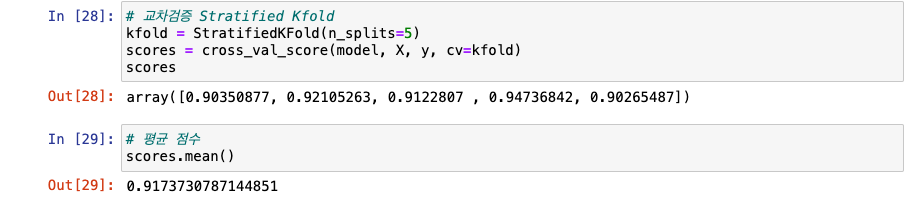
KFold
-
Stratified Kfold
3-6. 평가(분류)
평가(분류 모델) 종류
-
Accuracy
- 정확도
- 실제값 및 예측값의 일치 비율
-
Precision
- 정밀도
- 양성 예측값 중 실제 양성값 비율
-
Recall
- 재현율
- 실제 양성값 중 양성 예측값 비율
-
F1
- 정밀도, 재현율 조화 평균(가중치 평균)
-
ROC-AUC
- ROC: 참 양성 비율에 대한 거짓 양성 비율 곡선
- AUC: ROC곡선 면적의 아래부분(완벽 분류시 값은 1)
정확도

정밀도

재현율

f1

roc_auc
model.predict_proba: 확률값으로 계산


언젠가 내 코드로 세상에 기여할 수 있도록, Data Science&BE 개발 기록 노트☘️