본 내용은 RAG 시스템 구축을 위한 랭체인 실전 가이드 교재 및 강의 자료, 실습 자료를 사용했음을 알립니다.
- 강의 : [모두의AI] Langchain 강의
- 실습 : Kane0002/Langchain-RAG
1️⃣ Streamlit으로 RAG 챗봇 만들기
플로우 이해를 위한 강의 참고
-
📄 streamlit_refer.py
import streamlit as st
import tiktoken
from loguru import logger
from langchain.chains import ConversationalRetrievalChain
from langchain.chat_models import ChatOpenAI
from langchain.document_loaders import PyPDFLoader
from langchain.document_loaders import Docx2txtLoader
from langchain.document_loaders import UnstructuredPowerPointLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.memory import ConversationBufferMemory
from langchain.vectorstores import FAISS
# from streamlit_chat import message
from langchain.callbacks import get_openai_callback
from langchain.memory import StreamlitChatMessageHistory
def main():
st.set_page_config(
page_title="DirChat",
page_icon=":books:")
st.title("_Private Data :red[QA Chat]_ :books:")
if "conversation" not in st.session_state:
st.session_state.conversation = None
if "chat_history" not in st.session_state:
st.session_state.chat_history = None
if "processComplete" not in st.session_state:
st.session_state.processComplete = None
with st.sidebar:
uploaded_files = st.file_uploader("Upload your file",type=['pdf','docx'],accept_multiple_files=True)
openai_api_key = st.text_input("OpenAI API Key", key="chatbot_api_key", type="password")
process = st.button("Process")
if process:
if not openai_api_key:
st.info("Please add your OpenAI API key to continue.")
st.stop()
files_text = get_text(uploaded_files)
text_chunks = get_text_chunks(files_text)
vetorestore = get_vectorstore(text_chunks)
st.session_state.conversation = get_conversation_chain(vetorestore,openai_api_key)
st.session_state.processComplete = True
if 'messages' not in st.session_state:
st.session_state['messages'] = [{"role": "assistant",
"content": "안녕하세요! 주어진 문서에 대해 궁금하신 것이 있으면 언제든 물어봐주세요!"}]
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])
history = StreamlitChatMessageHistory(key="chat_messages")
# Chat logic
if query := st.chat_input("질문을 입력해주세요."):
st.session_state.messages.append({"role": "user", "content": query})
with st.chat_message("user"):
st.markdown(query)
with st.chat_message("assistant"):
chain = st.session_state.conversation
with st.spinner("Thinking..."):
result = chain({"question": query})
with get_openai_callback() as cb:
st.session_state.chat_history = result['chat_history']
response = result['answer']
source_documents = result['source_documents']
st.markdown(response)
with st.expander("참고 문서 확인"):
st.markdown(source_documents[0].metadata['source'], help = source_documents[0].page_content)
st.markdown(source_documents[1].metadata['source'], help = source_documents[1].page_content)
st.markdown(source_documents[2].metadata['source'], help = source_documents[2].page_content)
# Add assistant message to chat history
st.session_state.messages.append({"role": "assistant", "content": response})
def tiktoken_len(text):
tokenizer = tiktoken.get_encoding("cl100k_base")
tokens = tokenizer.encode(text)
return len(tokens)
def get_text(docs):
doc_list = []
for doc in docs:
file_name = doc.name # doc 객체의 이름을 파일 이름으로 사용
with open(file_name, "wb") as file: # 파일을 doc.name으로 저장
file.write(doc.getvalue())
logger.info(f"Uploaded {file_name}")
if '.pdf' in doc.name:
loader = PyPDFLoader(file_name)
documents = loader.load_and_split()
elif '.docx' in doc.name:
loader = Docx2txtLoader(file_name)
documents = loader.load_and_split()
elif '.pptx' in doc.name:
loader = UnstructuredPowerPointLoader(file_name)
documents = loader.load_and_split()
doc_list.extend(documents)
return doc_list
def get_text_chunks(text):
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=900,
chunk_overlap=100,
length_function=tiktoken_len
)
chunks = text_splitter.split_documents(text)
return chunks
def get_vectorstore(text_chunks):
embeddings = HuggingFaceEmbeddings(
model_name="jhgan/ko-sroberta-multitask",
model_kwargs={'device': 'cpu'},
encode_kwargs={'normalize_embeddings': True}
)
vectordb = FAISS.from_documents(text_chunks, embeddings)
return vectordb
def get_conversation_chain(vetorestore,openai_api_key):
llm = ChatOpenAI(openai_api_key=openai_api_key, model_name = 'gpt-3.5-turbo',temperature=0)
conversation_chain = ConversationalRetrievalChain.from_llm(
llm=llm,
chain_type="stuff",
retriever=vetorestore.as_retriever(search_type = 'mmr', vervose = True),
memory=ConversationBufferMemory(memory_key='chat_history', return_messages=True, output_key='answer'),
get_chat_history=lambda h: h,
return_source_documents=True,
verbose = True
)
return conversation_chain
if __name__ == '__main__':
main()Streamlit 실행하기
- 설치
pip install streamlit
- 코드 작성: 📄 streamlit_chat_ex.py
import streamlit as st
from openai import OpenAI
with st.sidebar:
openai_api_key = st.text_input ("OpenAI API Key", key="chatbot_api_key", type="password")
"[Get an OpenAI API key](https://platform.openai.com/account/api-keys)"
"[View the source code](https://github.com/streamlit/11m-examples/blob/main/Chatbot.py)"
"[](https://codespaces.new/streamlit/11m-examples?quickstart=1)"
st.title("💬 Hayan's Chatbot")
if "messages" not in st.session_state:
st.session_state["messages"] = [{"role": "assistant", "content": "How can I help you?"}]
for msg in st.session_state.messages:
st.chat_message(msg["role"]).write(msg["content"])
if prompt := st.chat_input():
if not openai_api_key:
st.info("Please add your OpenAI API key to continue.")
st. stop()
client = OpenAI(api_key=openai_api_key)
st.session_state.messages.append({"role": "user", "content": prompt})
st.chat_message ("user"). write(prompt)
response = client.chat.completions.create(model="gpt-3.5-turbo", messages=st.session_state.messages)
msg = response.choices[0].message.content
st.session_state.messages.append({"role": "assistant", "content": msg})
st.chat_message("assistant").write(msg)- 프롬프트 or 터미널에서 실행
# 파일 경로 이동
cd LLM06
# 실행
streamlit run streamlit_chat_ex.py
- API KEY 작성 후

Streamlit chat 기능 설정
📄 streamlit_chat.py
streamlit_chat()- 사용자로부터 OpenAI API를 입력받고 챗봇 엔진으로 OpenAI의 GPT-4o를 사용하는 앱 구축
- 필요한 라이브러리 호출 & OpenAI API Key 설정
import os
import streamlit as st
from langchain_openai import ChatOpenAI
os.environ["OPENAI_API_KEY"] = "API키 입력"- 메인 화면 제목 설정
st.title("💬 Chatbot")session_state- dictionary로 key, value wjwkd
- 새로운 session_state를 만들 경우의 if문도 작성
- 사용자가 어떤 입력을 하지 않았더라도 AI가 첫 마디를 인사로 시작하도록 설정
- 코드 순서
- session_state에 messages 변수 지정
- 챗봇 화면 진입 시 AI가 첫 인사말을 하도록 기록
- 사용자와 AI 모두 message 값 발생 시, chat_message() 함수를 실행
#session_state에 messages Key값 지정
# Streamlit 화면 진입 시, AI의 인사말을 기록하기
if "messages" not in st.session_state:
st.session_state["messages"] = [{"role": "assistant", "content": "How can I help you?"}]
#사용자나 AI가 질문/답변을 주고받을 시, 기록하는 session_state
for msg in st.session_state.messages:
st.chat_message(msg["role"]).write(msg["content"])if prompt := st.chat_input():- st.chat_input() 함수에 입력 값이 있는 경우, 프롬프트로 저장하고 조건절 이어감
- 순서
- 채팅 입력창에 프롬프트 입력됨
- 미리 선언한 messages의 session_state에 role, content를 키 값으로 하는 딕셔너리 추가
- chat_message()를 통해 사용자 메시지를 채팅창에 나타냄
- 사용자 프롬프트에 대한 AI 답변 : ChatOpenAI의 invoke() 함수로 가져와 msg 답변 부분만 저장
- 사용자 답변을 session_state에 저장해 채팅창에 나타내는 방법과 같게 AI 답변도 나타냄
#챗봇으로 활용할 AI 모델 선언
chat = ChatOpenAI(model="gpt-4o", temperature=0)
#chat_input()에 입력값이 있는 경우,
if prompt := st.chat_input():
#messages라는 session_state에 역할은 사용자, 컨텐츠는 프롬프트를 각각 저장
st.session_state.messages.append({"role": "user", "content": prompt})
#chat_message()함수로 사용자 채팅 버블에 prompt 메시지를 기록
st.chat_message("user").write(prompt)
response = chat.invoke(prompt)
msg = response.content
#messages라는 session_state에 역할은 AI, 컨텐츠는 API답변을 각각 저장
st.session_state.messages.append({"role": "assistant", "content": msg})
#chat_message()함수로 AI 채팅 버블에 API 답변을 기록
st.chat_message("assistant").write(msg)
2️⃣ 대화 기능 추가하기
📄 streamlit_rag_local.py
필요한 라이브러리 호출, OpenAI API Key 지정
import os
import streamlit as st
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain_chroma import Chroma
from langchain.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
#오픈AI API 키 설정(로컬)
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY"
# 배포
# openai_api_key = st.secrets["OPENAI_API_KEY"]PDF 문서 로드 및 벡터화 함수
- RAG 챗봇 핵심 기능 수행 함수 4개
load_and_split_pdf(file_path)- File_path로 지정된 파일 경로상 PDF 파일을 PyPDFLoader로 로드
- 페이지별로 분할해 return
create_vector_store(_docs)- Document 객체를 RecursiveCharacterTextSplitter로 분할
- Chroma 벡터 DB에 저장
- 임베딩 벡터로 변환할 모델은 text-embedding-3-small 사용
get_vector_store(_docs)- 벡터 DB가 이미 있다면 그 DB를 로드
- 없다면, create_vector_store(_docs) 함수 실행해 새 벡터 DB 생성
format_docs(docs)- Document 객체의 page_content 추출 및 결합
참고사항
- PyPDFLoader 대신 UnstructuredFileLoader 활용 or PDF가 아닌 파일 로드를 위해 다른 로더도 활용 가능
- create_vector_store(_docs)는 chunk_size, chunk_overlap 등 변수를 필요에 맞게 변경 or 다른 벡터 DB, 임베딩 모델로 변경도 가능
@st.cache_resource- Streamlit으로 구현된 웹앱이 한번 구동할 때 생성된 데이터를 캐싱
- 캐시 데이터를 이용한 로드 시간 단축에 용이
- 함수 위에 데코레이터로 지정해줄 수 있음
@st.cache_resource
def load_and_split_pdf(file_path):
loader = PyPDFLoader(file_path)
return loader.load_and_split()
#텍스트 청크들을 Chroma 안에 임베딩 벡터로 저장
@st.cache_resource
def create_vector_store(_docs):
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
split_docs = text_splitter.split_documents(_docs)
persist_directory = "./chroma_db"
vectorstore = Chroma.from_documents(
split_docs,
OpenAIEmbeddings(model='text-embedding-3-small'),
persist_directory=persist_directory
)
return vectorstore
#만약 기존에 저장해둔 ChromaDB가 있는 경우, 이를 로드
@st.cache_resource
def get_vectorstore(_docs):
persist_directory = "./chroma_db"
if os.path.exists(persist_directory):
return Chroma(
persist_directory=persist_directory,
embedding_function=OpenAIEmbeddings(model='text-embedding-3-small')
)
else:
return create_vector_store(_docs)
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)RAG 체인 구성
-
chaining- 위에서 함수로 만든 요소들을 가져와 RAG 체인에 하나로 통합
- 동일하게
@st.cache_resource데코레이터 지정
-
코드 구성
load_and_split()- 파일 로드 경로 설정, 경로를 load_and_split_pdf() 함수에 매개변수로 지정해 PDF 파일 로드
- 파일 로드 경로 설정, 경로를 load_and_split_pdf() 함수에 매개변수로 지정해 PDF 파일 로드
get_vector_store()- 벡터 임베딩으로 변환 & ChromaDB에 저장
- 이렇게 만들어진 벡터 DB를 기반으로 Retriever로 선언하기 위해 as_retriever() 함수 실행
- 벡터 DB가 기존에 있는 경우, 기존 벡터 DB 로드
- RAG 프롬프트 선언
- RAG 프롬프트를 선언하여 ChatPromptTemplete 시스템 프롬프트로 지정
- HumanMessage에는 {input}을 지정해 ChatPromptTemplete에 입력되는 값을 HumanMessage에 맵핑
- 답변 완결성 강조, 존댓말 및 이모지를 붙여 사용자 친화적 답변 제공
- LLM 지정 및 RAG 체인 결합
- rag_chain으로 앞에서 저장한 요소들을 하나로 결합
- context : retriever 검색 결과가 format_docs로 정리된 상태로 맵핑
- input : 사용자 질문이 들어와 그대로 통과됨 -> 유사 문서 검색 결과 및 사용자 질문이 RAG 프롬프트에 주입됨 -> 프롬프트를 LLM이 전달받아 답변 생성
- StrOutPutParser()를 연결해 LLM 답변을 문자열로만 출력하도록 형식 지정
# Initialize the LangChain components
@st.cache_resource
def chaining():
# 로컬
file_path = r"/Users/hayan/Downloads/대한민국헌법(헌법)(제00010호)(19880225).pdf"
# 서버
# file_path = r"./대한민국헌법(헌법)(제00010호)(19880225).pdf"
pages = load_and_split_pdf(file_path)
vectorstore = get_vectorstore(pages)
retriever = vectorstore.as_retriever()
# Define the answer question prompt
qa_system_prompt = """
You are an assistant for question-answering tasks. \
Use the following pieces of retrieved context to answer the question. \
If you don't know the answer, just say that you don't know. \
Keep the answer perfect. please use imogi with the answer.
Please answer in Korean and use respectful language.\
{context}
"""
qa_prompt = ChatPromptTemplate.from_messages(
[
("system", qa_system_prompt),
("human", "{input}"),
]
)
llm = ChatOpenAI(model="gpt-4o-mini")
rag_chain = (
{"context": retriever | format_docs, "input": RunnablePassthrough()}
| qa_prompt
| llm
| StrOutputParser()
)
return rag_chainStreamlit UI 구성
# Streamlit UI
st.header("헌법 Q&A 챗봇 💬 📚")
rag_chain = chaining()
if "messages" not in st.session_state:
st.session_state["messages"] = [{"role": "assistant", "content": "헌법에 대해 무엇이든 물어보세요!"}]
for msg in st.session_state.messages:
st.chat_message(msg['role']).write(msg['content'])
if prompt_message := st.chat_input("질문을 입력해주세요 :)"):
st.chat_message("human").write(prompt_message)
st.session_state.messages.append({"role": "user", "content": prompt_message})
with st.chat_message("ai"):
with st.spinner("Thinking..."):
response = rag_chain.invoke(prompt_message)
st.session_state.messages.append({"role": "assistant", "content": response})
st.write(response)
3️⃣ 파일 업로드 기능 추가하기
📄 streamlit_rag_upload.py
Streamlit 파일 업로드
- 사용자만의 문서를 업로드, 해당 문서로 RAG 수행할 경우를 가정
기본 설정
import os
import streamlit as st
import tempfile
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain_chroma import Chroma
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
#Chroma tenant 오류 방지 위한 코드
import chromadb
chromadb.api.client.SharedSystemClient.clear_system_cache()
#오픈AI API 키 설정
os.environ["OPENAI_API_KEY"] = "{API key}"업로드된 PDF 문서 처리 함수
#cache_resource로 한번 실행한 결과 캐싱해두기
@st.cache_resource
def load_pdf(_file):
with tempfile.NamedTemporaryFile(mode="wb", delete=False) as tmp_file:
tmp_file.write(_file.getvalue())
tmp_file_path = tmp_file.name
#PDF 파일 업로드
loader = PyPDFLoader(file_path=tmp_file_path)
pages = loader.load_and_split()
return pages
#텍스트 청크들을 Chroma 안에 임베딩 벡터로 저장
@st.cache_resource
def create_vector_store(_docs):
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
split_docs = text_splitter.split_documents(_docs)
vectorstore = Chroma.from_documents(split_docs, OpenAIEmbeddings(model='text-embedding-3-small'))
return vectorstore
#검색된 문서를 하나의 텍스트로 합치는 헬퍼 함수
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)RAG 체인 구성
#PDF 문서 기반 RAG 체인 구축
@st.cache_resource
def chaining(_pages):
vectorstore = create_vector_store(_pages)
retriever = vectorstore.as_retriever()
#이 부분의 시스템 프롬프트는 기호에 따라 변경하면 됩니다.
qa_system_prompt = """
You are an assistant for question-answering tasks. \
Use the following pieces of retrieved context to answer the question. \
If you don't know the answer, just say that you don't know. \
Keep the answer perfect. please use imogi with the answer.
Please answer in Korean and use respectful language.\
{context}
"""
qa_prompt = ChatPromptTemplate.from_messages(
[
("system", qa_system_prompt),
("human", "{input}"),
]
)
llm = ChatOpenAI(model="gpt-4o")
rag_chain = (
{"context": retriever | format_docs, "input": RunnablePassthrough()}
| qa_prompt
| llm
| StrOutputParser()
)
return rag_chainStreamlit UI 수정
st-file_uploader선언 부분 추가- 업로드된 파일의 존재 여부 조건절 추가
# Streamlit UI
st.header("ChatPDF 💬 📚")
uploaded_file = st.file_uploader("Upload a PDF", type=["pdf"])
if uploaded_file is not None:
pages = load_pdf(uploaded_file)
rag_chain = chaining(pages)
if "messages" not in st.session_state:
st.session_state["messages"] = [{"role": "assistant", "content": "무엇이든 물어보세요!"}]
for msg in st.session_state.messages:
st.chat_message(msg['role']).write(msg['content'])
if prompt_message := st.chat_input("질문을 입력해주세요 :)"):
st.chat_message("human").write(prompt_message)
st.session_state.messages.append({"role": "user", "content": prompt_message})
with st.chat_message("ai"):
with st.spinner("Thinking..."):
response = rag_chain.invoke(prompt_message)
st.session_state.messages.append({"role": "assistant", "content": response})
st.write(response)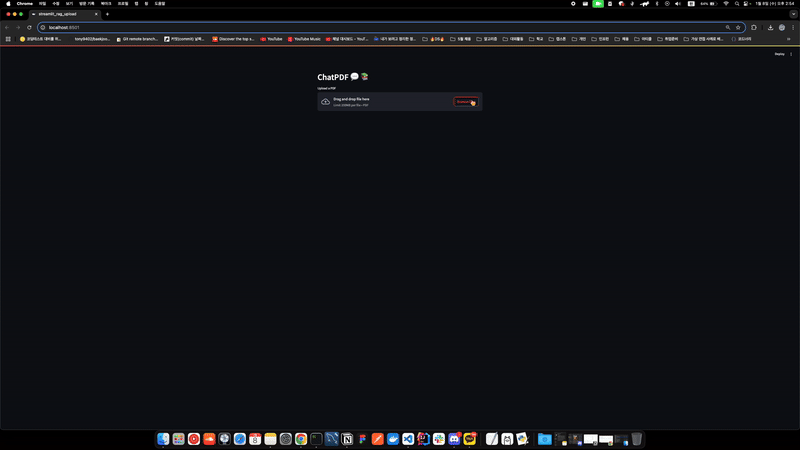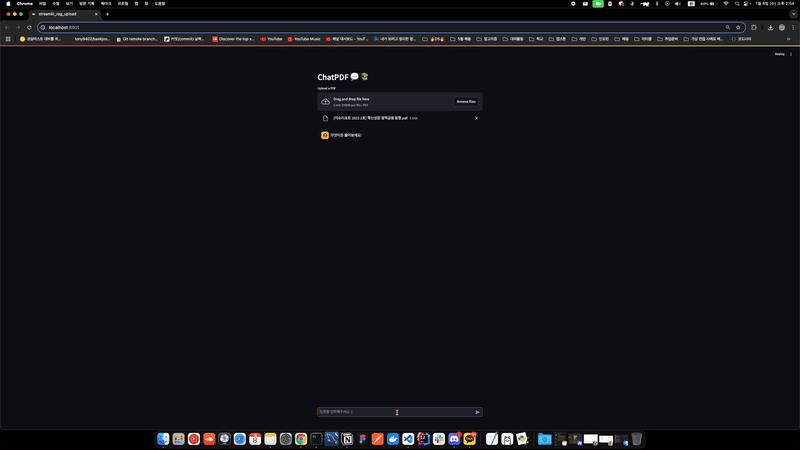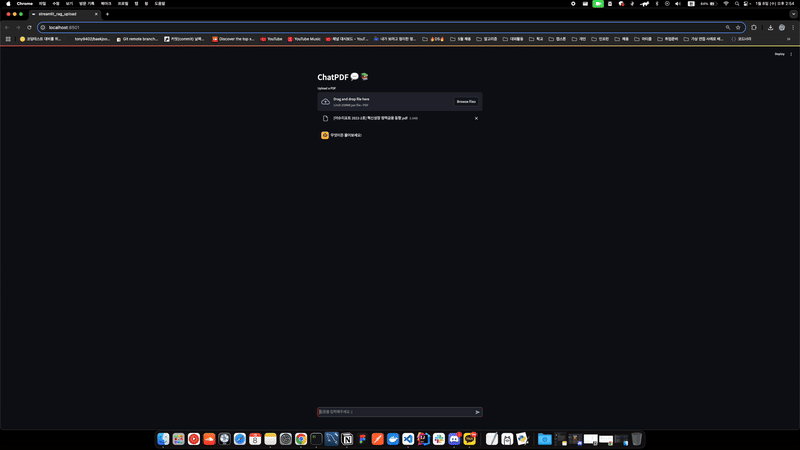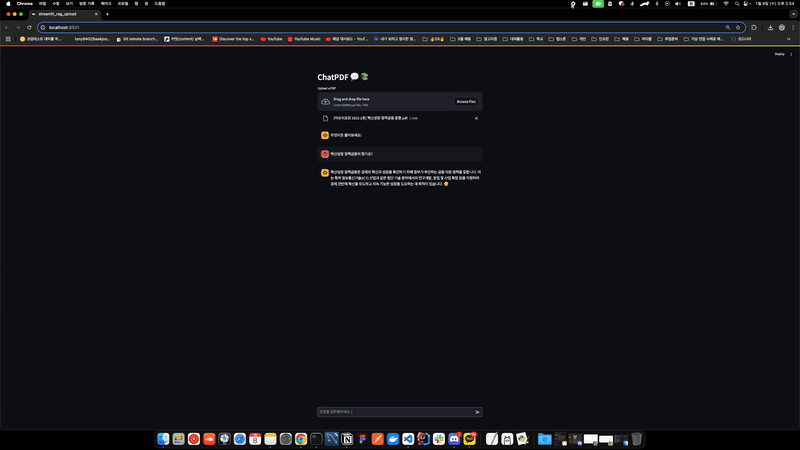
4️⃣ 고급 기능을 더해 RAG 챗봇 완성하기
📄 streamlit_rag_memory.py
필요 라이브러리 호출 및 OpenAI API Key 저장
import os
import streamlit as st
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain.vectorstores import Chroma
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain.chains import create_history_aware_retriever, create_retrieval_chain
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_community.chat_message_histories.streamlit import StreamlitChatMessageHistory
#오픈AI API 키 설정
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY"PDF 문서 로드 및 벡터화 함수
#cache_resource로 한번 실행한 결과 캐싱해두기
@st.cache_resource
def load_and_split_pdf(file_path):
loader = PyPDFLoader(file_path)
return loader.load_and_split()
#텍스트 청크들을 Chroma 안에 임베딩 벡터로 저장
@st.cache_resource
def create_vector_store(_docs):
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
split_docs = text_splitter.split_documents(_docs)
persist_directory = "./chroma_db"
vectorstore = Chroma.from_documents(
split_docs,
OpenAIEmbeddings(model='text-embedding-3-small'),
persist_directory=persist_directory
)
return vectorstore
#만약 기존에 저장해둔 ChromaDB가 있는 경우, 이를 로드
@st.cache_resource
def get_vectorstore(_docs):
persist_directory = "./chroma_db"
if os.path.exists(persist_directory):
return Chroma(
persist_directory=persist_directory,
embedding_function=OpenAIEmbeddings(model='text-embedding-3-small')
)
else:
return create_vector_store(_docs)메모리 기능이 추가된 RAG 체인 구성 함수
# PDF 문서 로드-벡터 DB 저장-검색기-히스토리 모두 합친 Chain 구축
@st.cache_resource
def initialize_components(selected_model):
file_path = r"../data/대한민국헌법(헌법)(제00010호)(19880225).pdf"
pages = load_and_split_pdf(file_path)
vectorstore = get_vectorstore(pages)
retriever = vectorstore.as_retriever()
# 채팅 히스토리 요약 시스템 프롬프트
contextualize_q_system_prompt = """Given a chat history and the latest user question \
which might reference context in the chat history, formulate a standalone question \
which can be understood without the chat history. Do NOT answer the question, \
just reformulate it if needed and otherwise return it as is."""
contextualize_q_prompt = ChatPromptTemplate.from_messages(
[
("system", contextualize_q_system_prompt),
MessagesPlaceholder("history"),
("human", "{input}"),
]
)
# 질문-답변 시스템 프롬프트
qa_system_prompt = """You are an assistant for question-answering tasks. \
Use the following pieces of retrieved context to answer the question. \
If you don't know the answer, just say that you don't know. \
Keep the answer perfect. please use imogi with the answer.
대답은 한국어로 하고, 존댓말을 써줘.\
{context}"""
qa_prompt = ChatPromptTemplate.from_messages(
[
("system", qa_system_prompt),
MessagesPlaceholder("history"),
("human", "{input}"),
]
)
llm = ChatOpenAI(model=selected_model)
history_aware_retriever = create_history_aware_retriever(llm, retriever, contextualize_q_prompt)
question_answer_chain = create_stuff_documents_chain(llm, qa_prompt)
rag_chain = create_retrieval_chain(history_aware_retriever, question_answer_chain)
return rag_chainStreamlit UI - 모델 선택 Select box 구현
# Streamlit UI
st.header("헌법 Q&A 챗봇 💬 📚")
option = st.selectbox("Select GPT Model", ("gpt-4o-mini", "gpt-3.5-turbo-0125"))
rag_chain = initialize_components(option)
chat_history = StreamlitChatMessageHistory(key="chat_messages")
conversational_rag_chain = RunnableWithMessageHistory(
rag_chain,
lambda session_id: chat_history,
input_messages_key="input",
history_messages_key="history",
output_messages_key="answer",
)Streamlit UI - 채팅 시스템 구현
if "messages" not in st.session_state:
st.session_state["messages"] = [{"role": "assistant",
"content": "헌법에 대해 무엇이든 물어보세요!"}]
for msg in chat_history.messages:
st.chat_message(msg.type).write(msg.content)
if prompt_message := st.chat_input("Your question"):
st.chat_message("human").write(prompt_message)
with st.chat_message("ai"):
with st.spinner("Thinking..."):
config = {"configurable": {"session_id": "any"}}
response = conversational_rag_chain.invoke(
{"input": prompt_message},
config)
answer = response['answer']
st.write(answer)
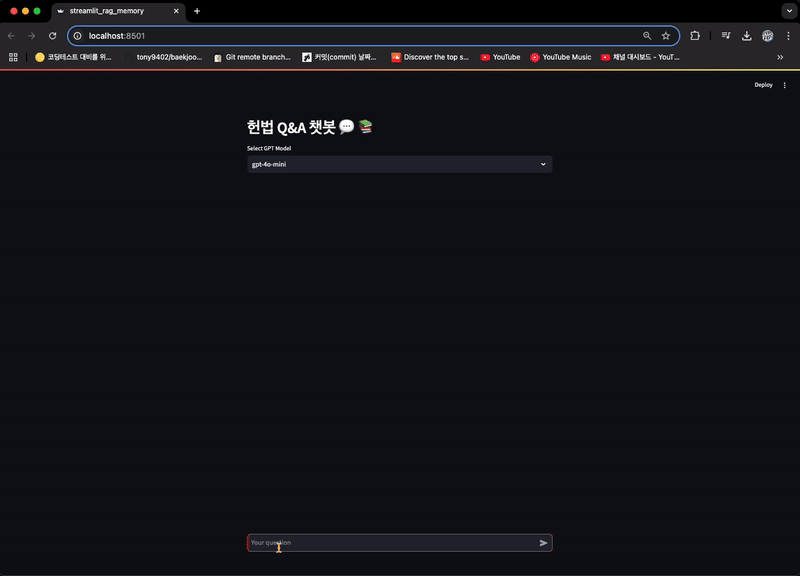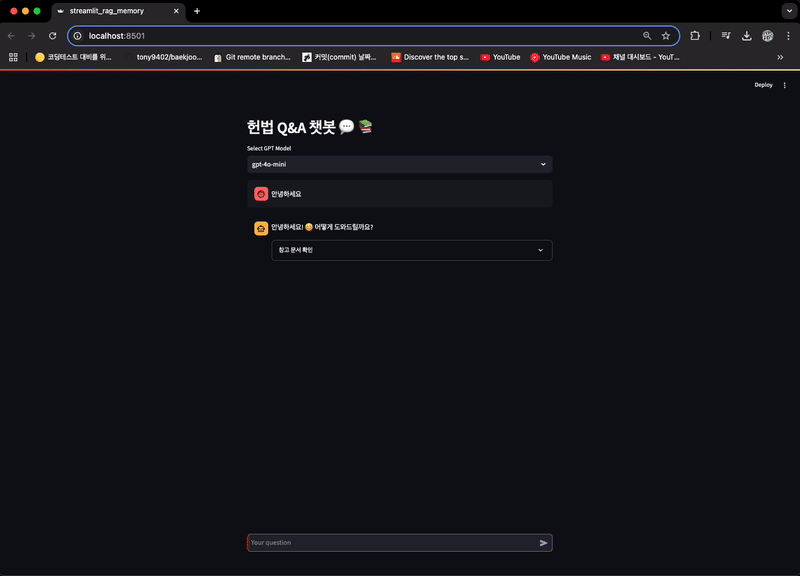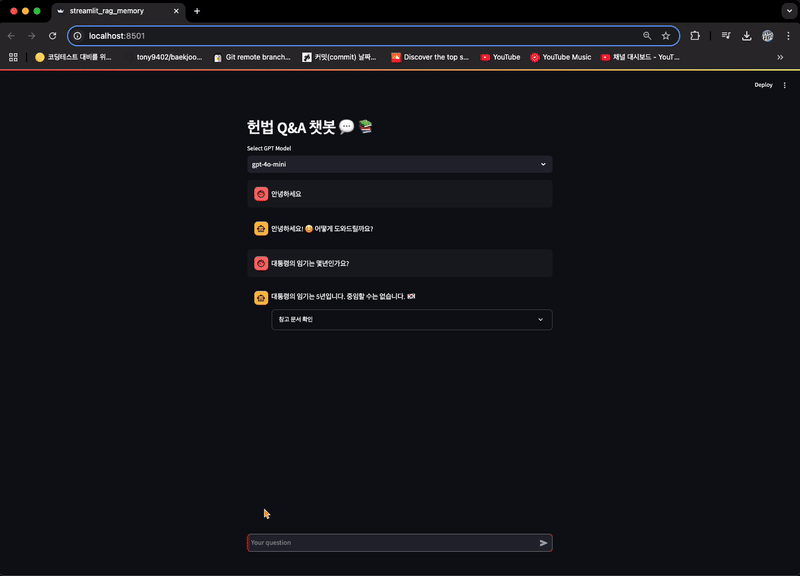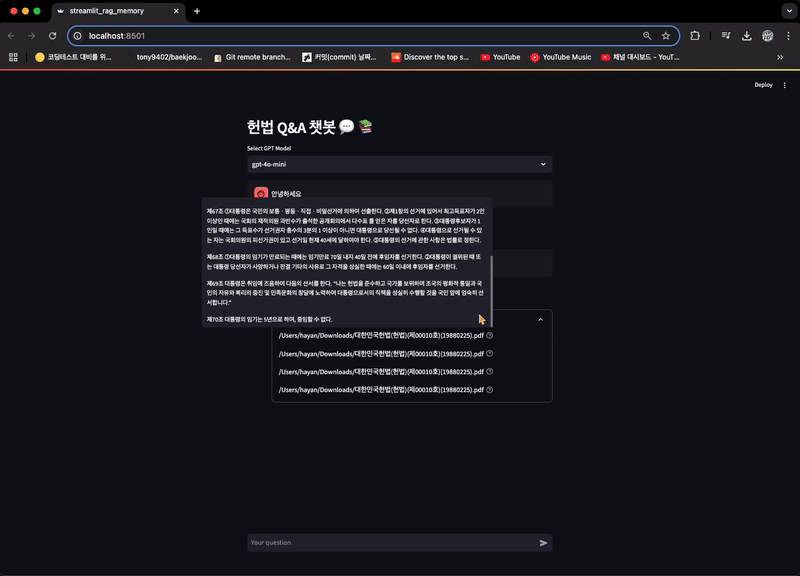
with st.expander("참고 문서 확인"):
for doc in response['context']:
st.markdown(doc.metadata['source'], help=doc.page_content)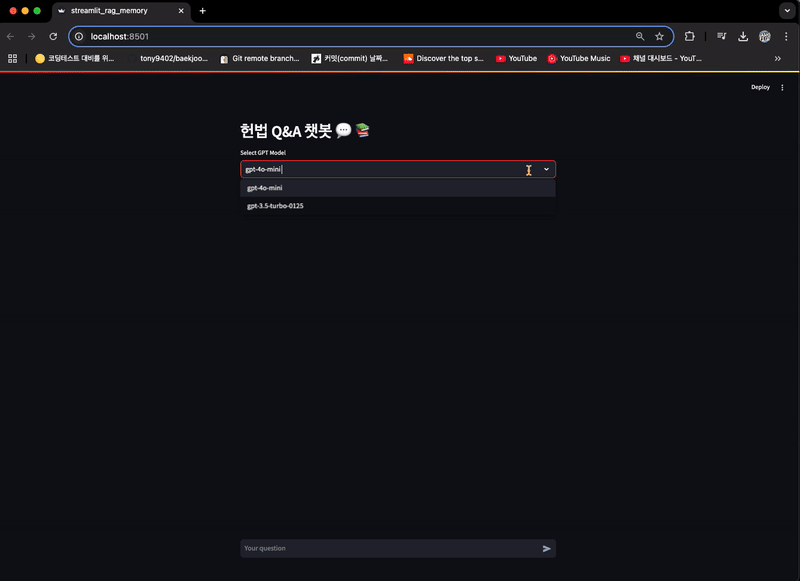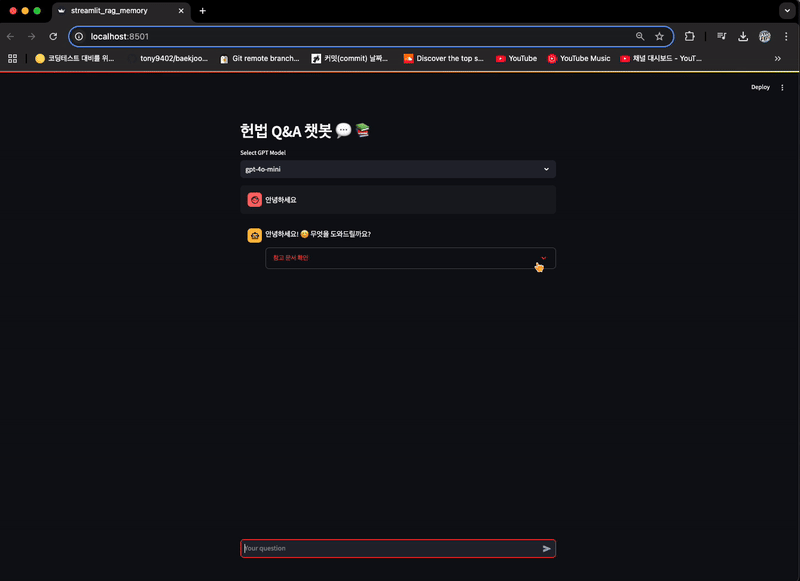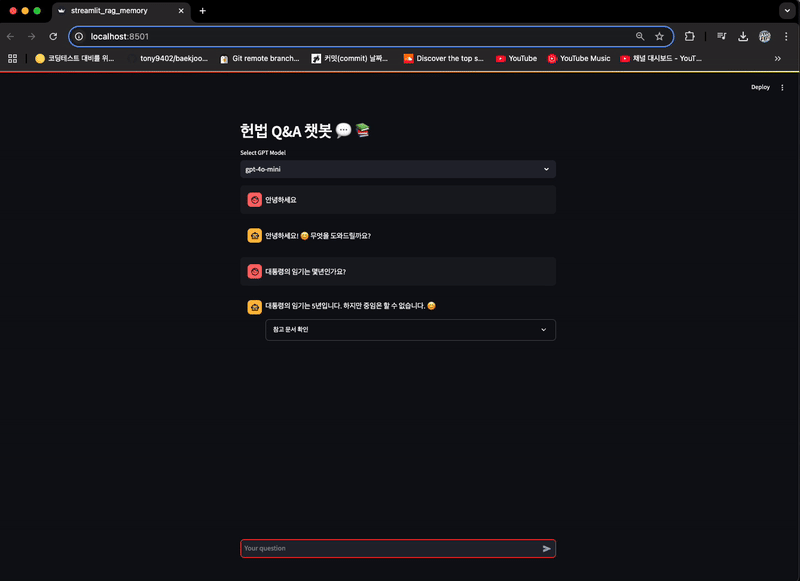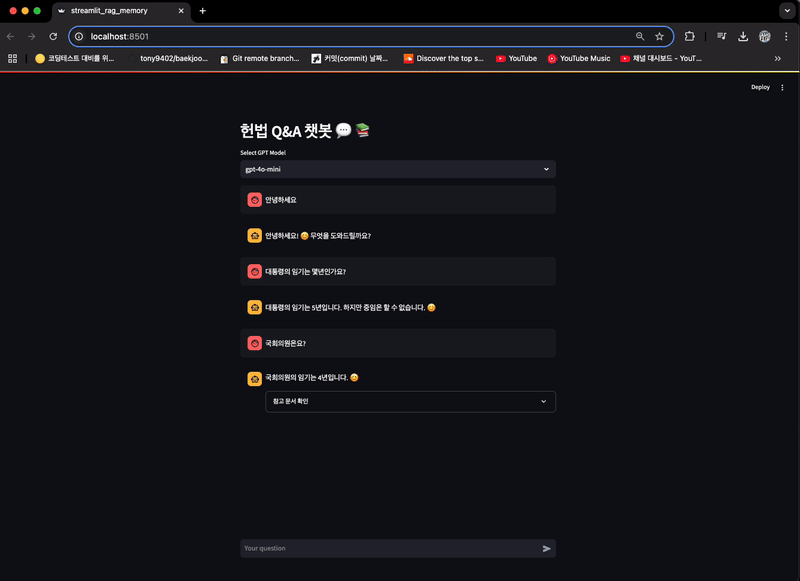
- 참고 문서 확인
5️⃣ Streamlit에서 배포하기
😽 깃허브 링크 : https://github.com/hayannn/RAG_Langchain_Streamlit_Chatbot
애플리케이션 파일
📄 streamlit_rag_memory.py 일부 수정하여 사용
📄 streamlit_rag_memory_deploy.py로 별도 저장
- 라이브러리 호출 및 API KEY 설정 부분만 변경
import os
import streamlit as st
import tempfile
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
__import__('pysqlite3')
import sys
sys.modules['sqlite3'] = sys.modules.pop('pysqlite3')
from langchain_chroma import Chroma
os.environ["OPENAI_API_KEY"] = st.secrets['OPENAI_API_KEY']설치 필요 라이브러리 목록 파일
📄 requirements.txt
streamlit
langchain
langchain-community
langchain-openai
langchain-core
langchain-chroma
pypdf
langchain-text-splitters
pysqlite3-binaryStreamlit Cloud로 배포하기
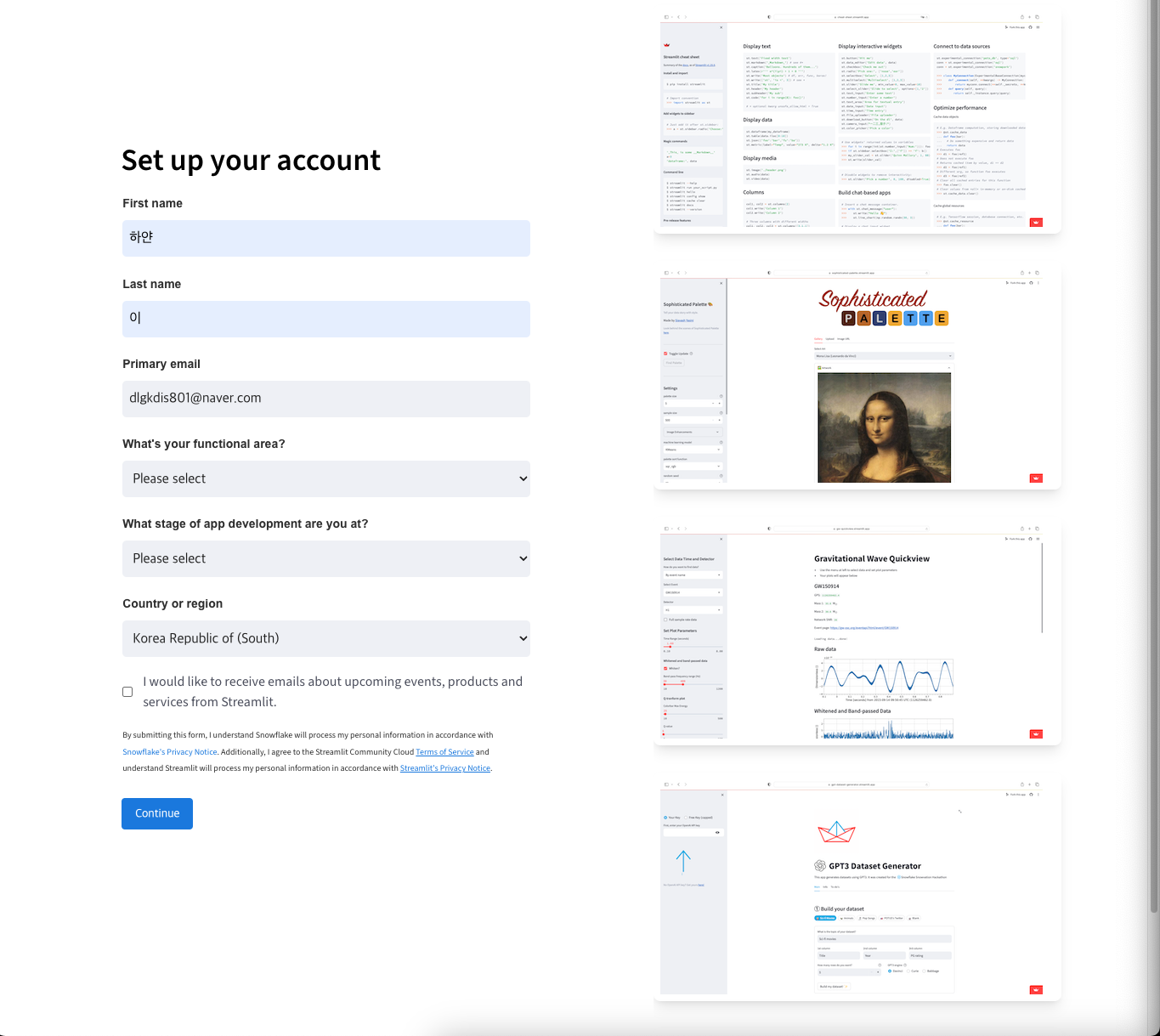
- Streamlit Cloud 사이트 로그인
- 사이트 : https://share.streamlit.io/
- 이메일 : Github 가입 시 사용한 이메일 사용해 로그인
- 이메일 인증 코드 인증 성공 시 프로필 작성 공간이 나옴
- 이름, 이메일 입력
- 사용자 전문 영역, 앱 준비 상태 입력
- 나라 : Korea Republic of (South)
Continue버튼 클릭
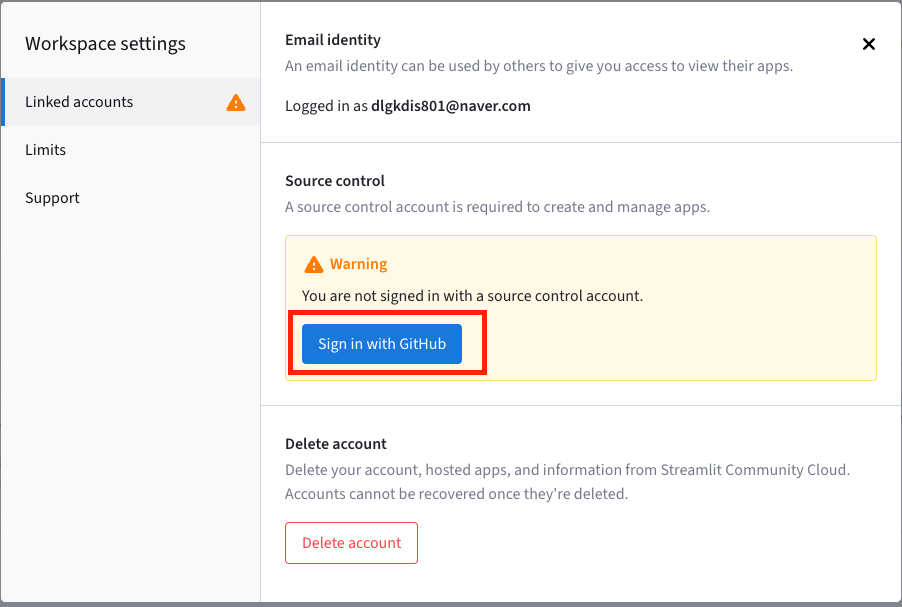
- 깃허브 연동
Workspaces>settings>Sign in with GitHub
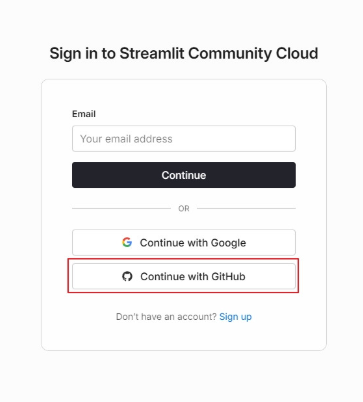
이 과정이 번거롭다면, 처음 회원가입 시에
Continue with GitHub로 진행하면 됨!
앱 생성
-
Create app클릭

-
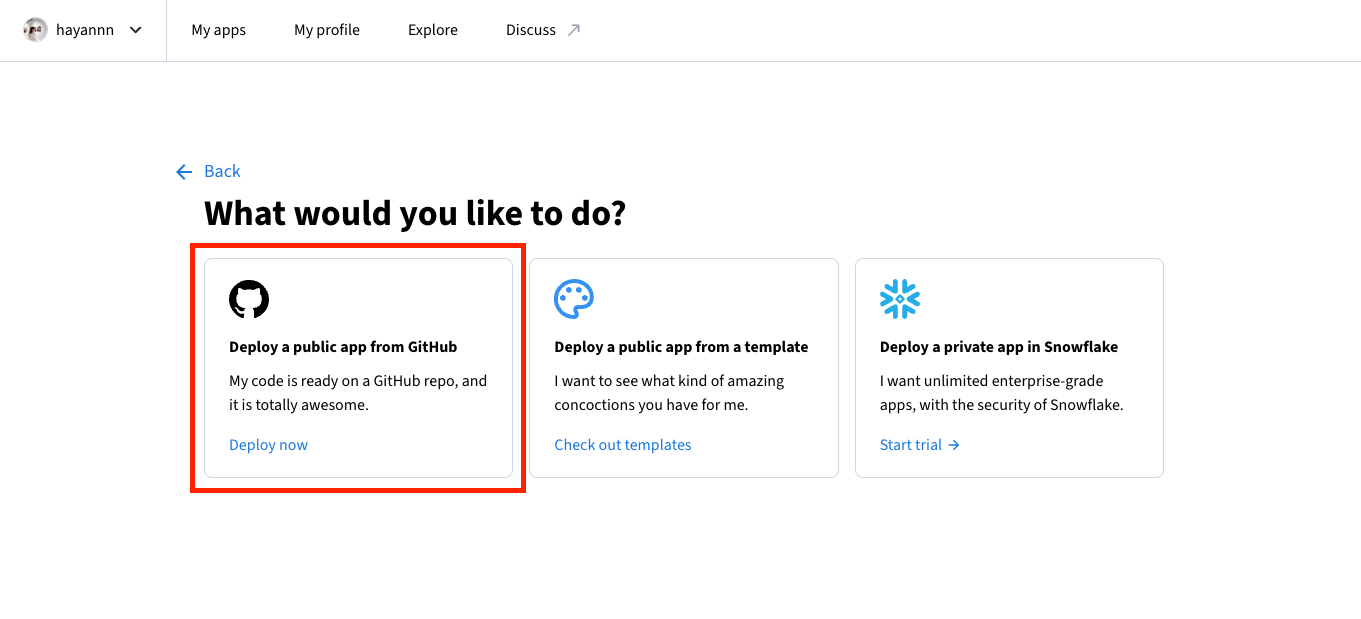
Deploy a public app from GitHub클릭
-
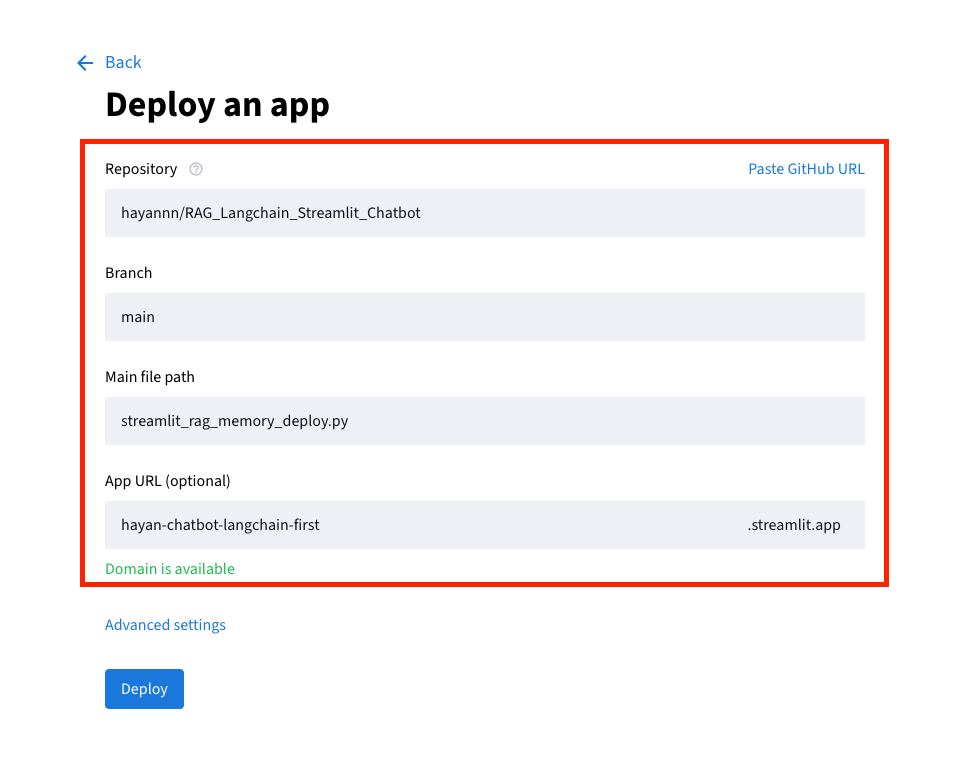
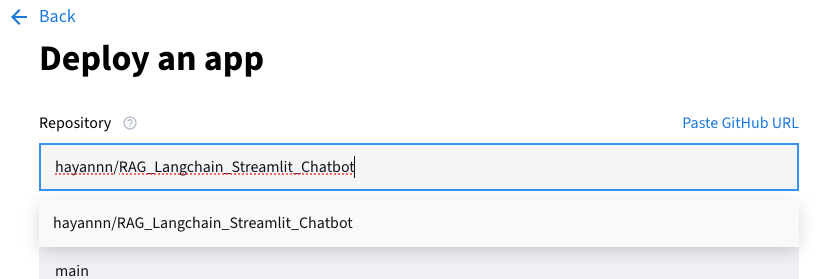
깃허브에 잘 연결되어 있다면 자동으로 아래에 뜨기 때문에 직접 입력보다는 선택하는 것을 추천
-
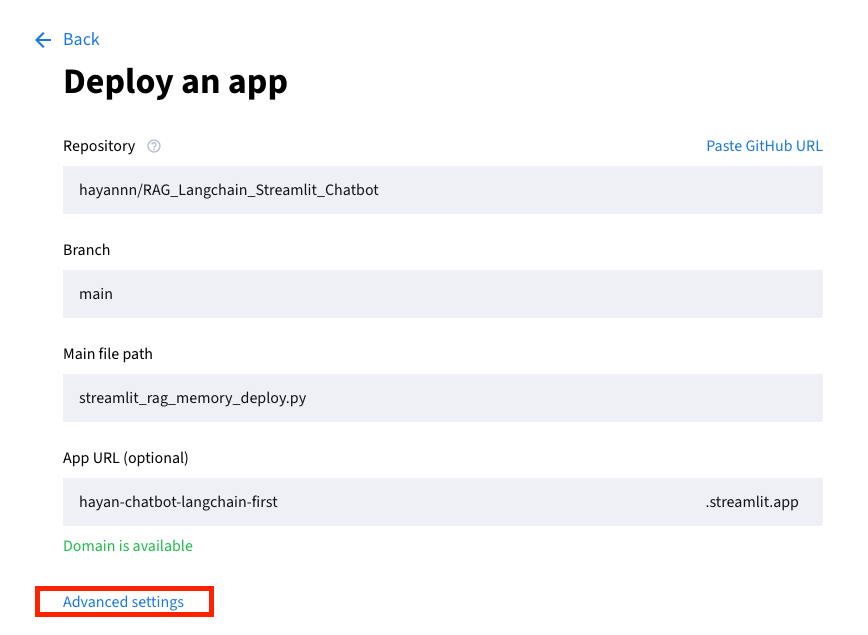
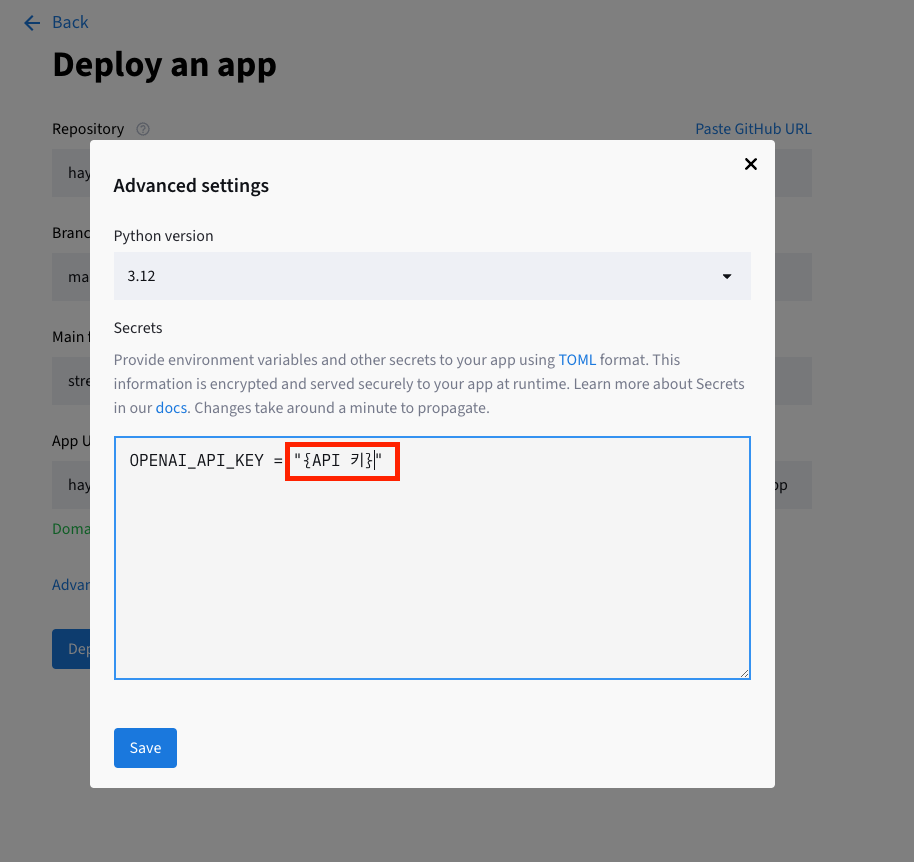
API KEY 설정:
Advanced settings클릭
-
실제 키 입력 후 저장할 것!
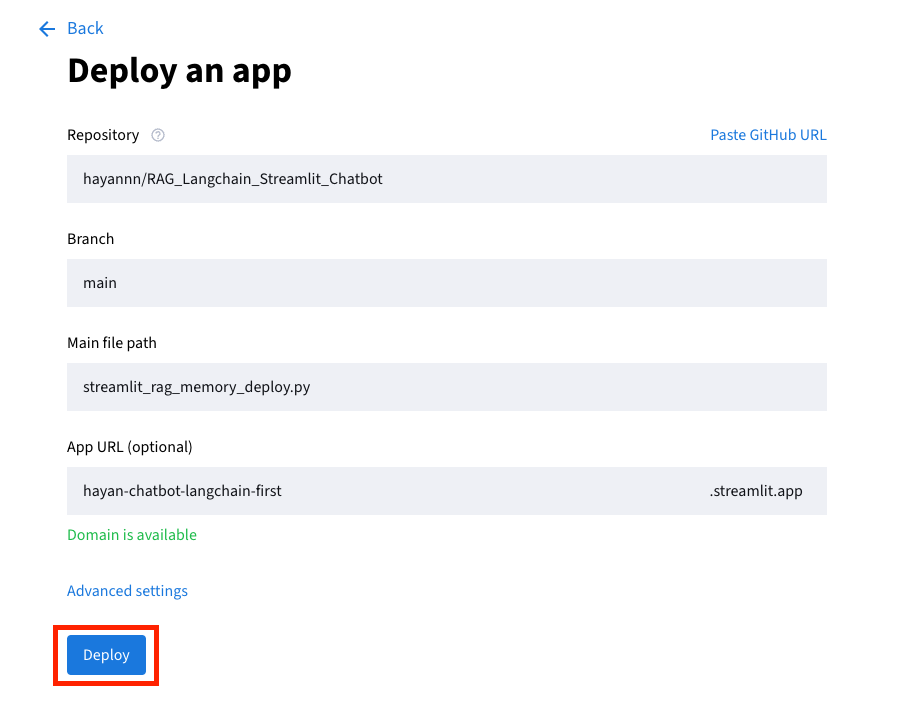
Deploy클릭해 완료하기
최종 배포
-
파일 업로드 + 채팅 메모리 기능까지 합쳐서 재배포
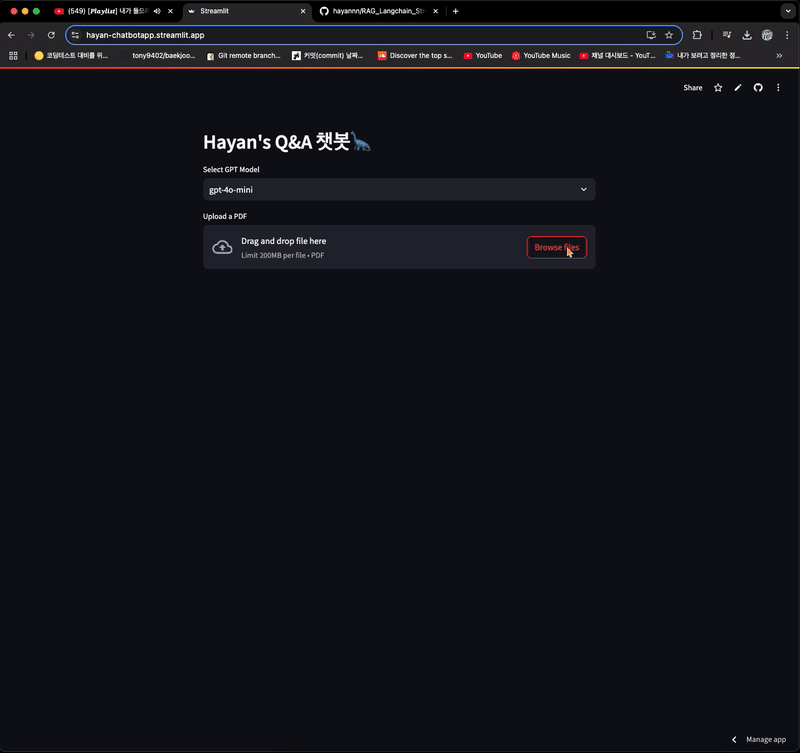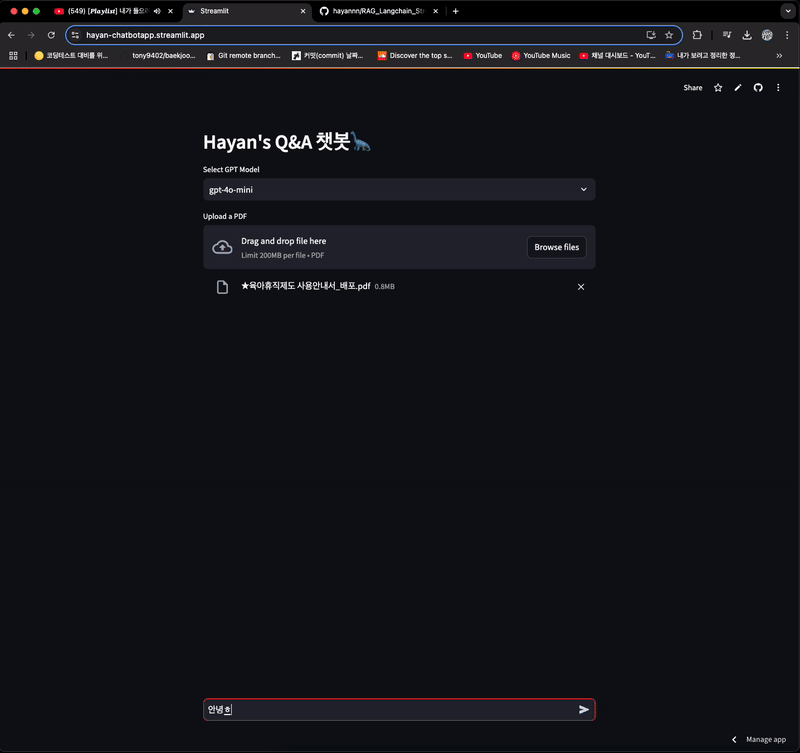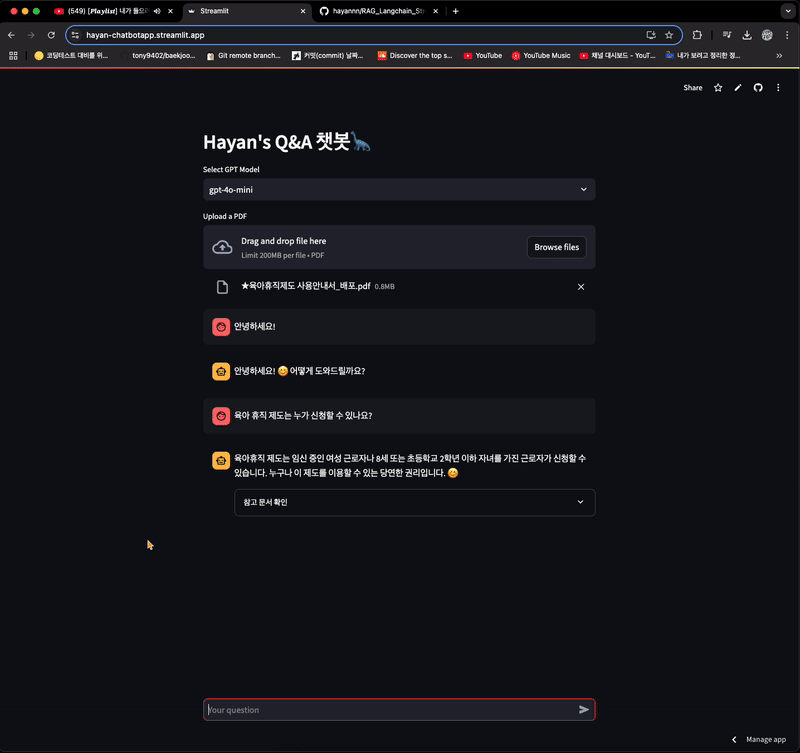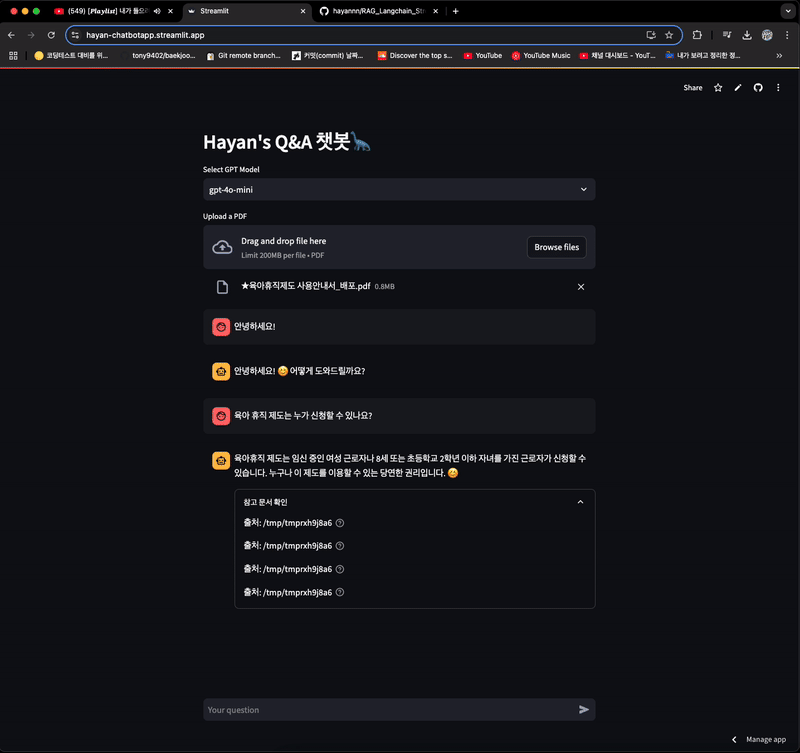
- 채팅 메모리 기능으로 인해, 참고 문서 확인 부분이 이전 채팅을 기반으로 가져오는 문제가 있는 상태
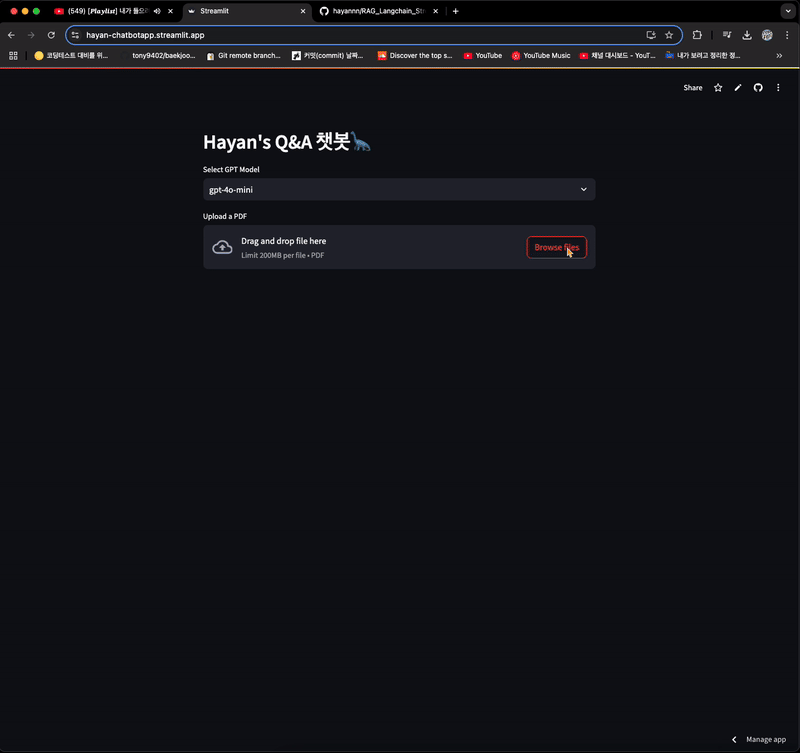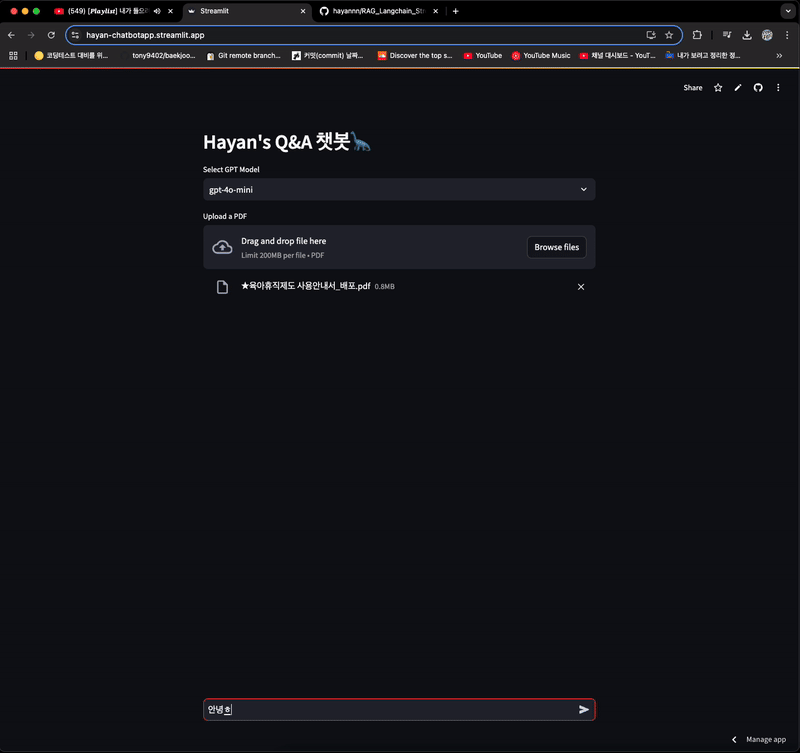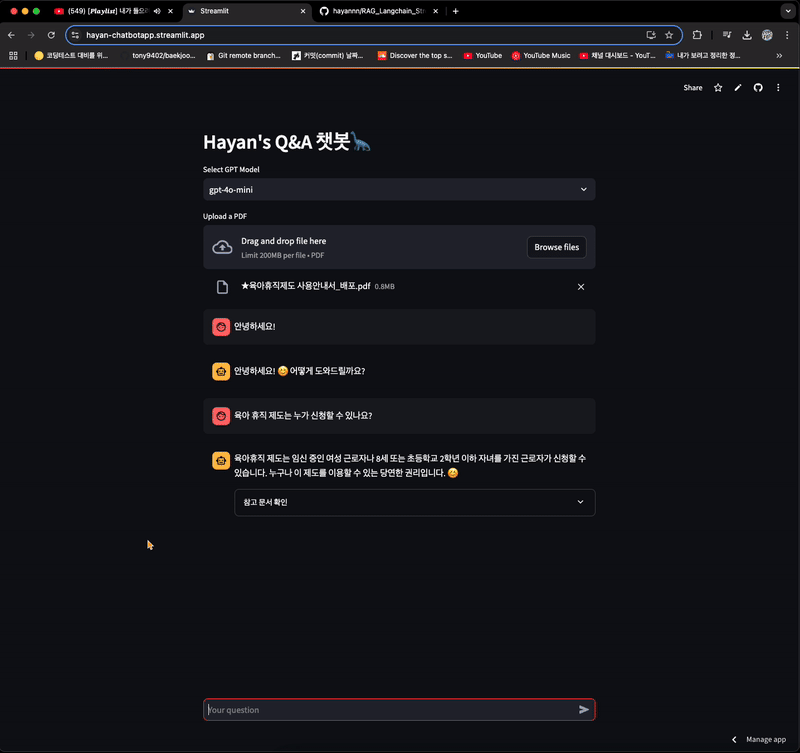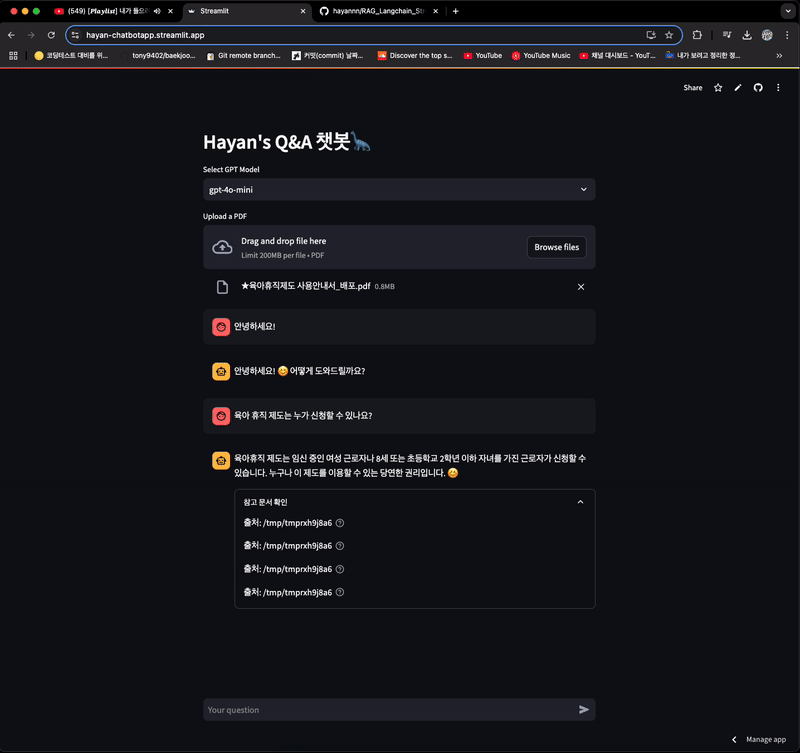
- 채팅 메모리 기능으로 인해, 참고 문서 확인 부분이 이전 채팅을 기반으로 가져오는 문제가 있는 상태
-
새로고침만 할 경우
- 내용을 넣었지만, 알 수 없다는 답변
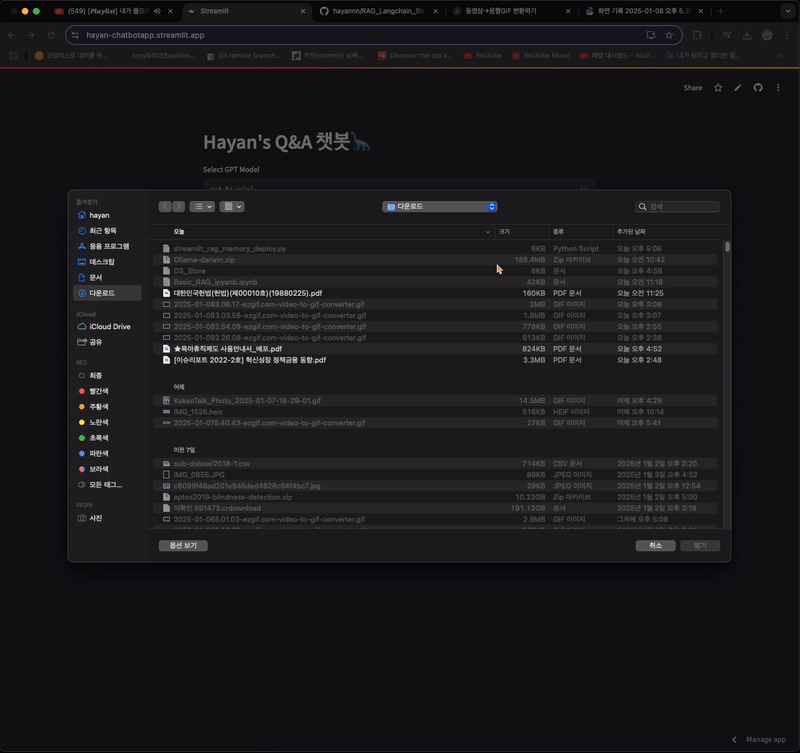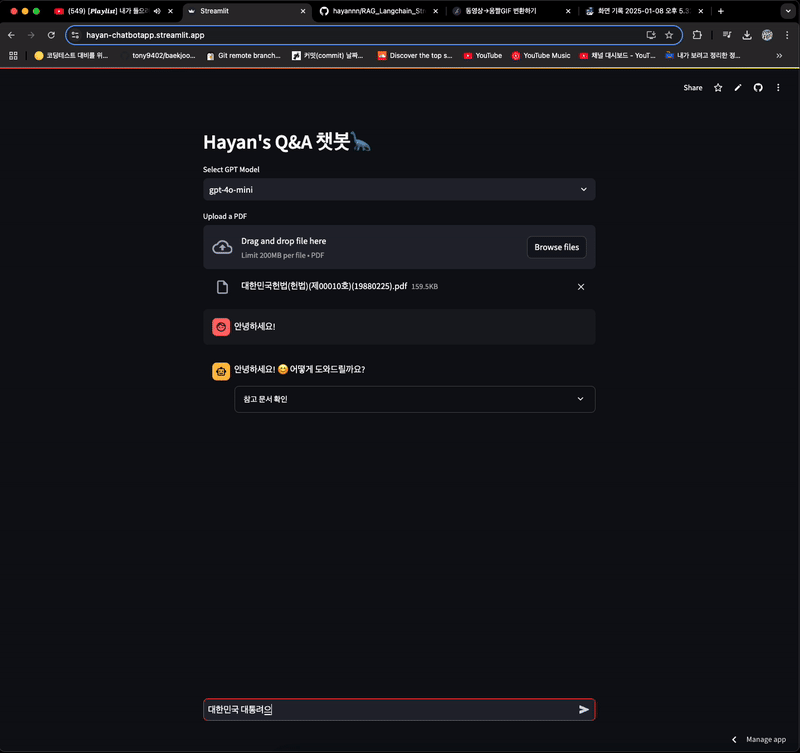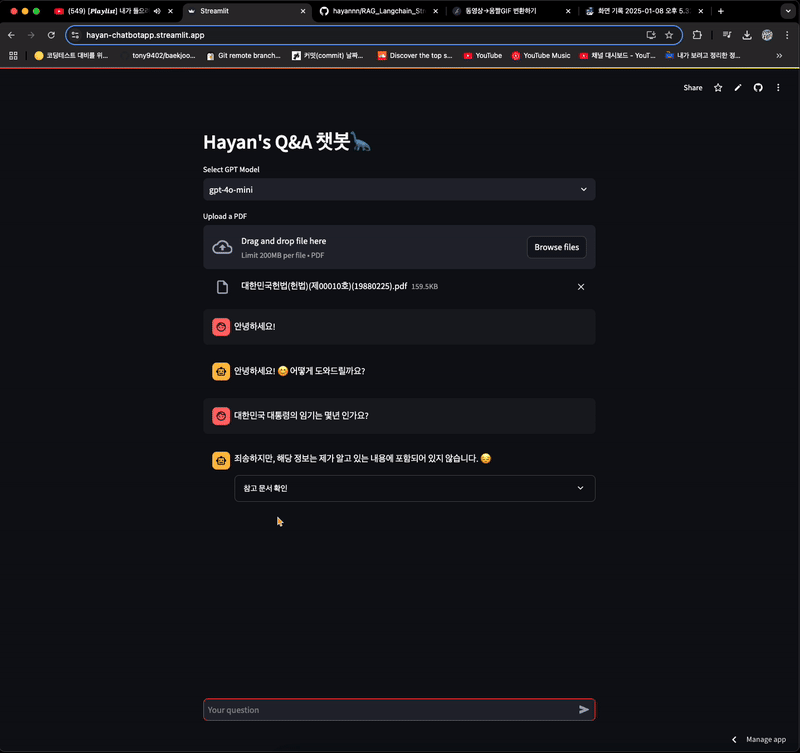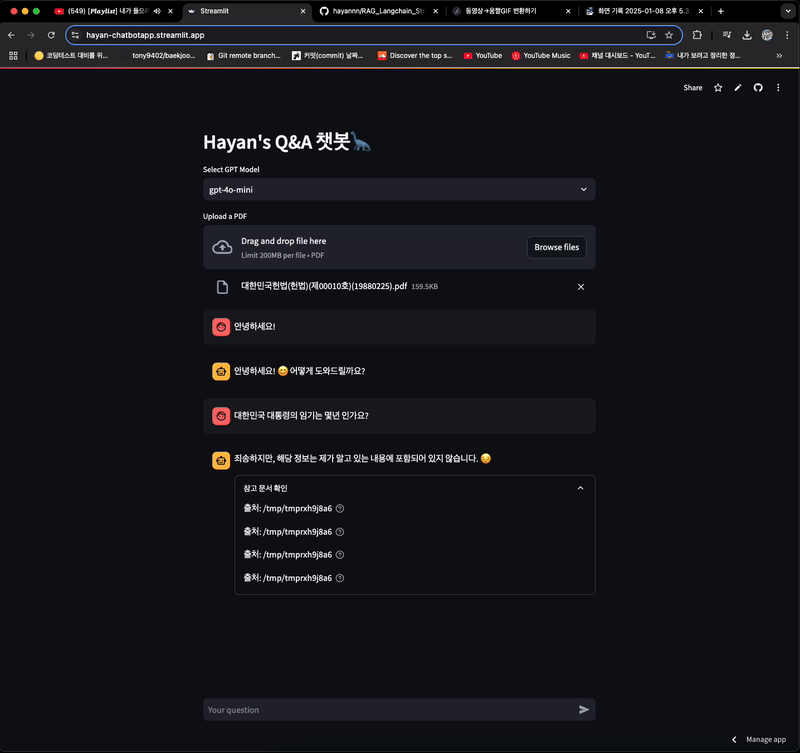
- 내용을 넣었지만, 알 수 없다는 답변
- 재시작 후, 동일 질문을 한 경우
- 답변을 하긴 하지만 참고 문서는 이전에 등록한 파일임
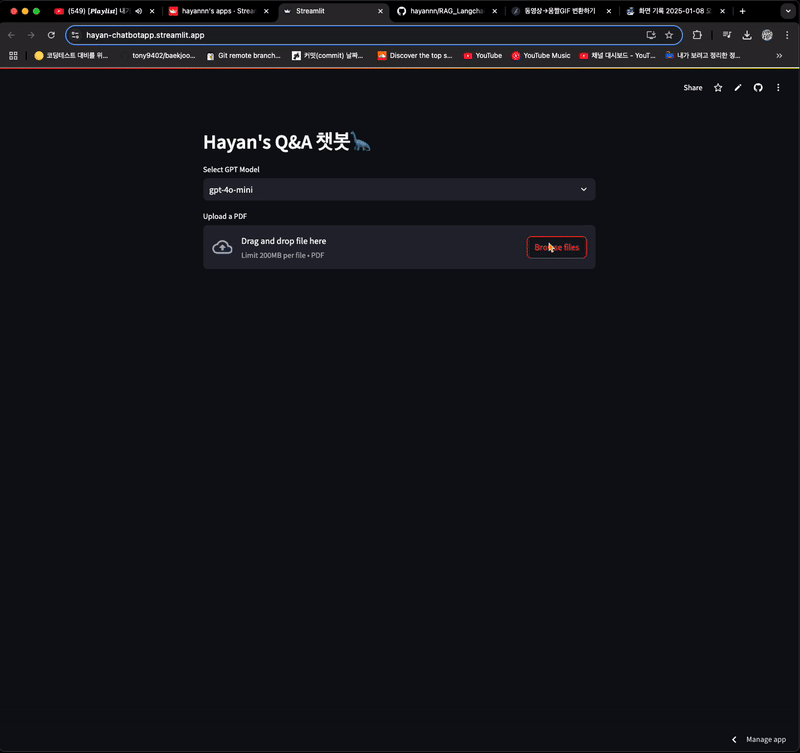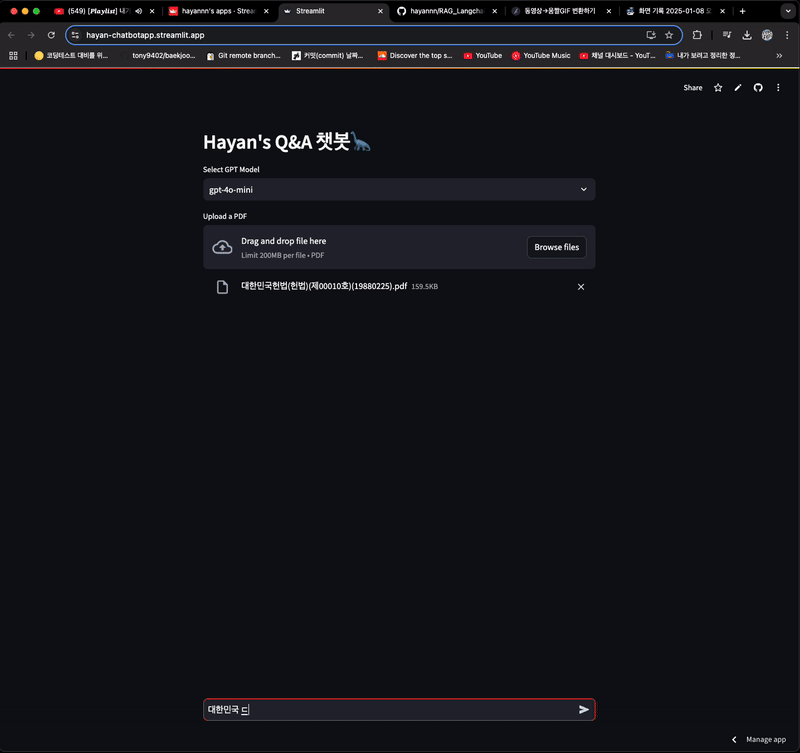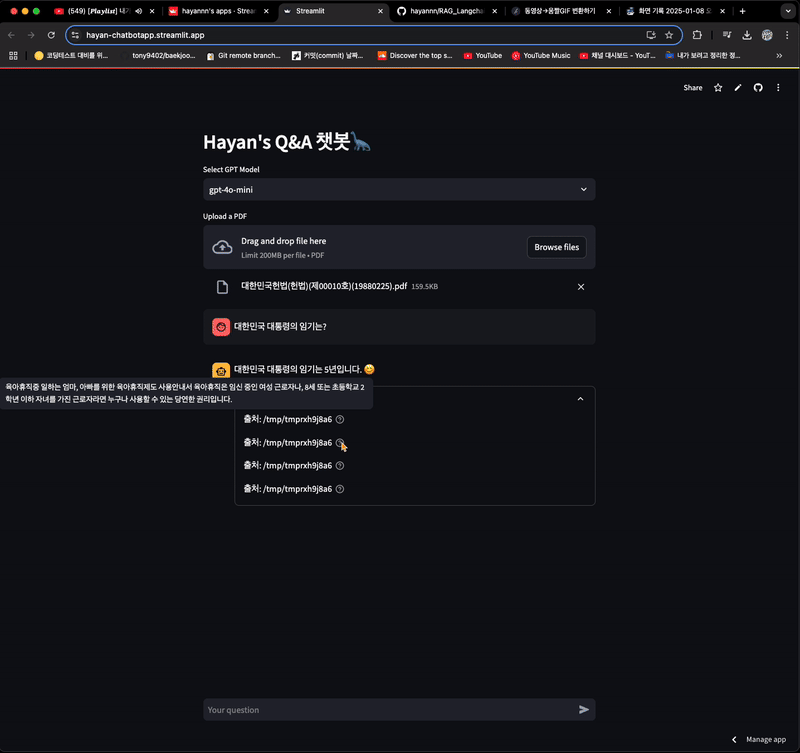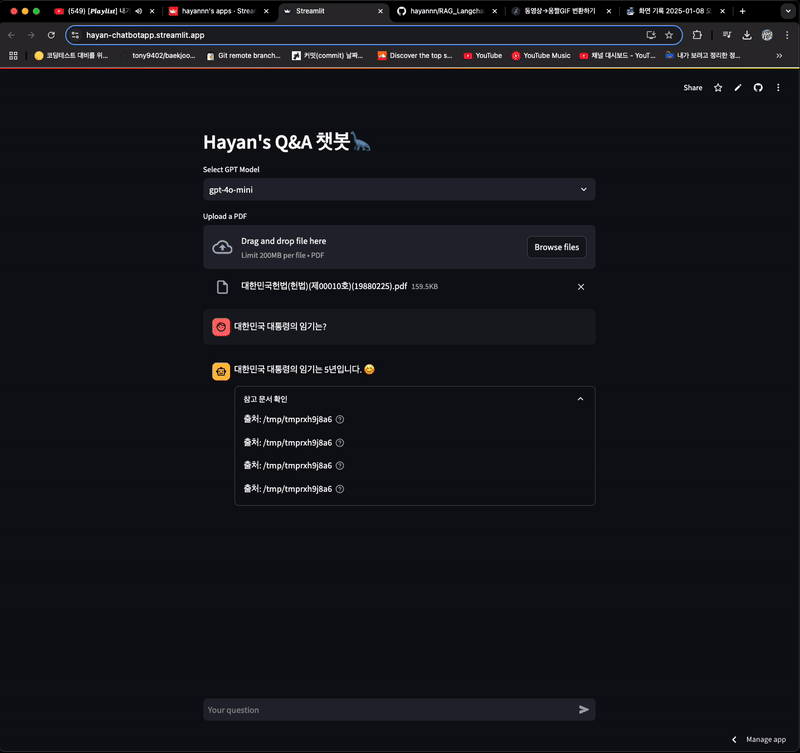
- 답변을 하긴 하지만 참고 문서는 이전에 등록한 파일임
🚀 TroubleShooting
ERROR: No matching distribution found for pysqlit3-binary
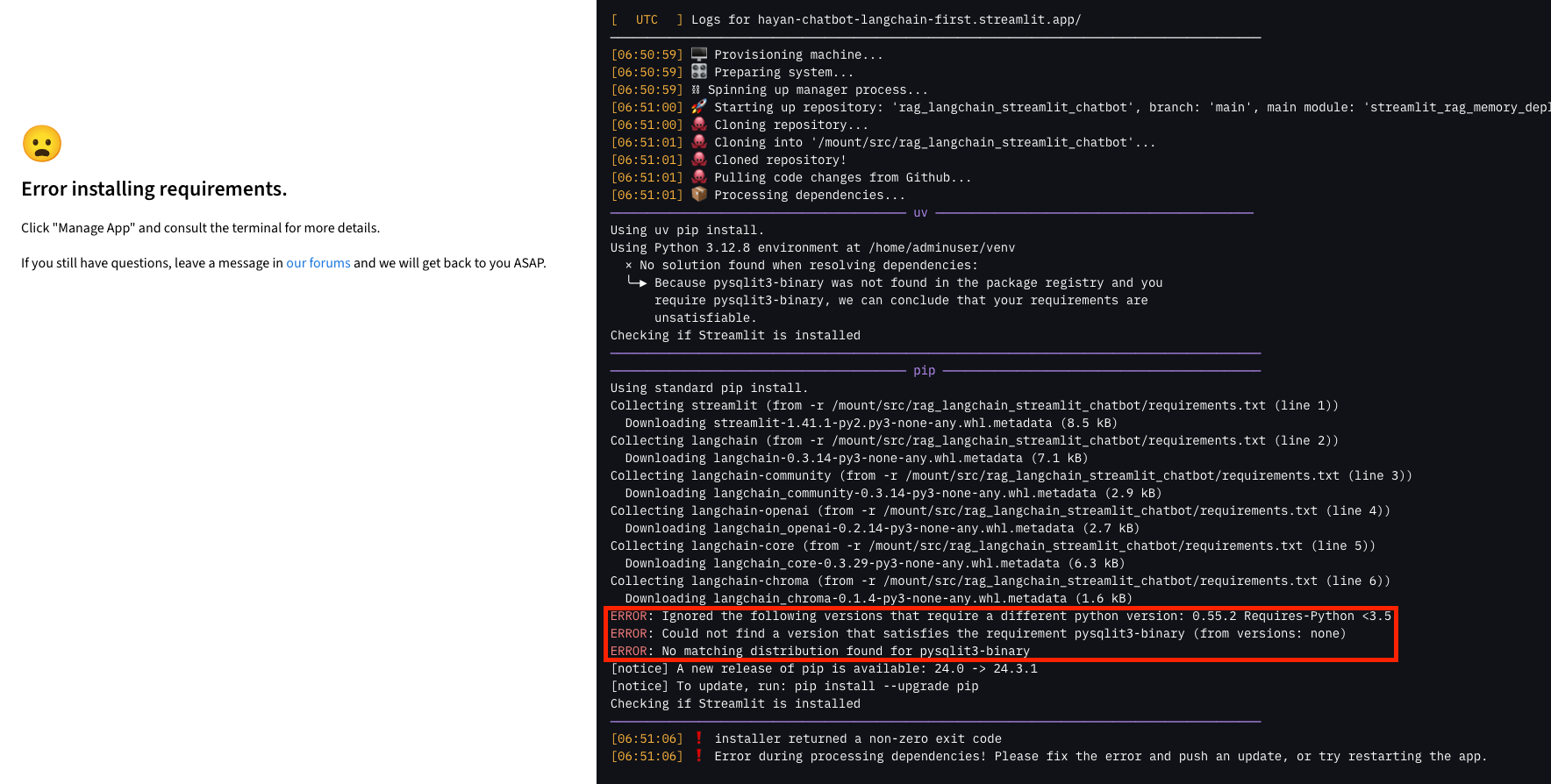
-
requirements.txt에 pysqlite3 추가
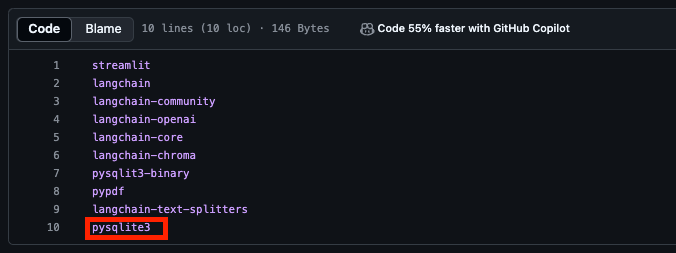
-
기존 pysqlit3-binary는 삭제
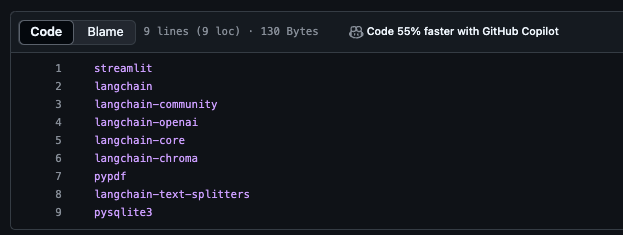
-
다시 pysqlite3-binary 입력하여 저장
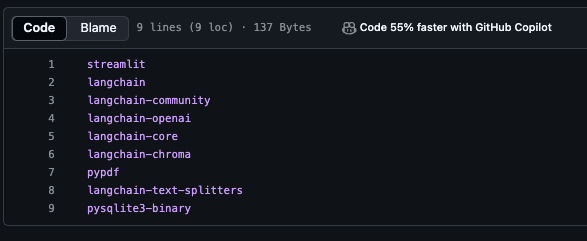
파일 내 pysqlite3-binary 오타로 발생한 문제
AttributeError: This app has encountered an error. The original error message is redacted to prevent data leaks. Full error details have been recorded in the logs (if you're on Streamlit Cloud, click on 'Manage app' in the lower right of your app).
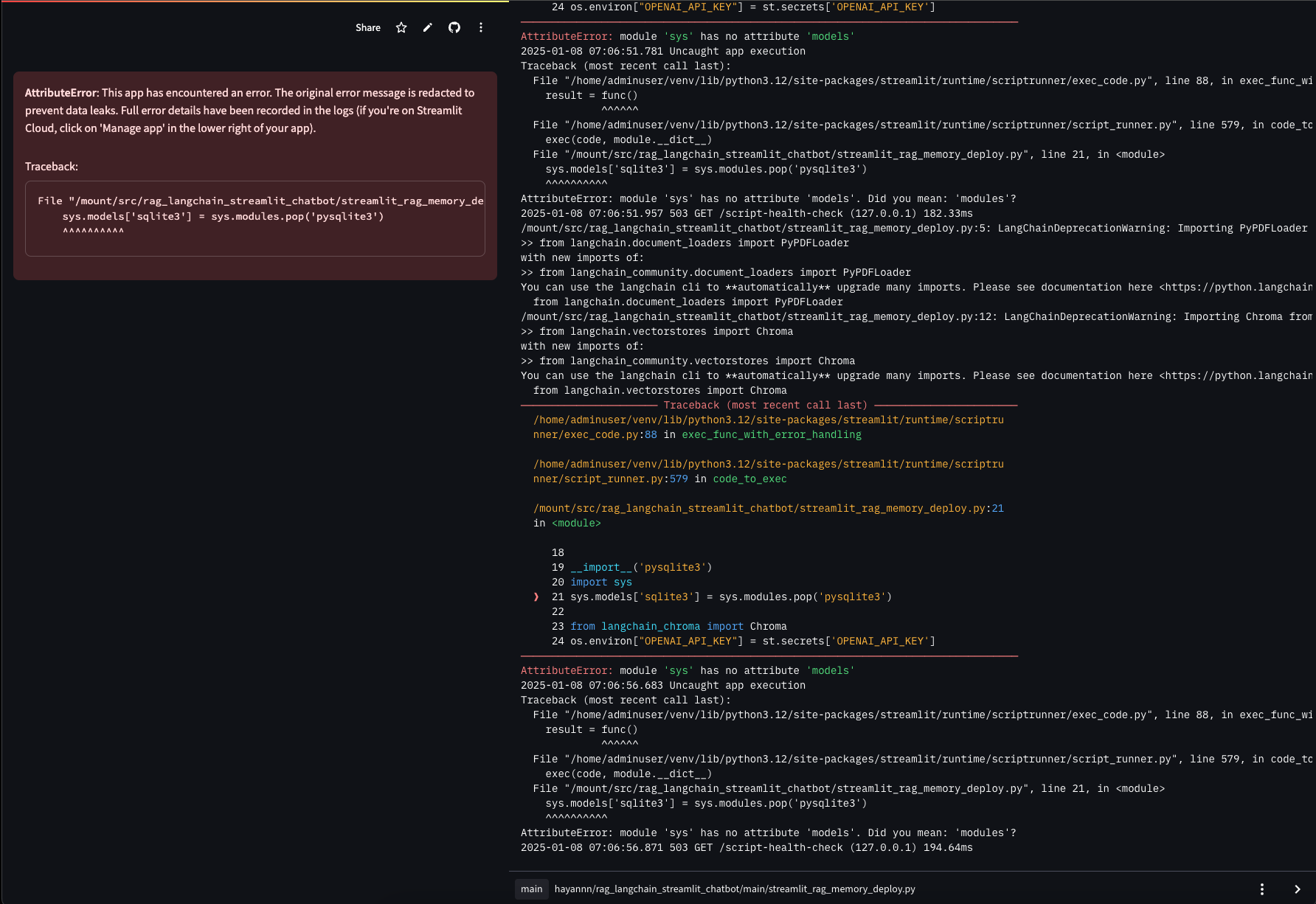
- streamlit_rag_memory_deploy.py 내의 modules 오타로 발생한 문제


수정하여 다시 push해 해결
ValueError: File path .pdf is not a valid file or url
- 로컬 부분으로 서버에 업로드하여 생긴 문제
- 수정하여 재배포 + 파일 업로드로 해결
- 수정하여 재배포 + 파일 업로드로 해결

언젠가 내 코드로 세상에 기여할 수 있도록, Data Science&BE 개발 기록 노트☘️
QnA 챗봇 프로젝트 만들고 있었는데 이 글이 많은 도움이 되었습니다!! 감사합니다💖