
본 내용은 RAG 시스템 구축을 위한 랭체인 실전 가이드 교재 및 강의 자료, 실습 자료를 사용했음을 알립니다.
- 강의 : [모두의AI] Langchain 강의
- 실습 : Kane0002/Langchain-RAG
RAG 시스템 구축하기1 - 기본적인 QA 체인 구성
대한민국 헌법 PDF 파일 기반 Q&A 챗봇 구축
RAG 작동 순서
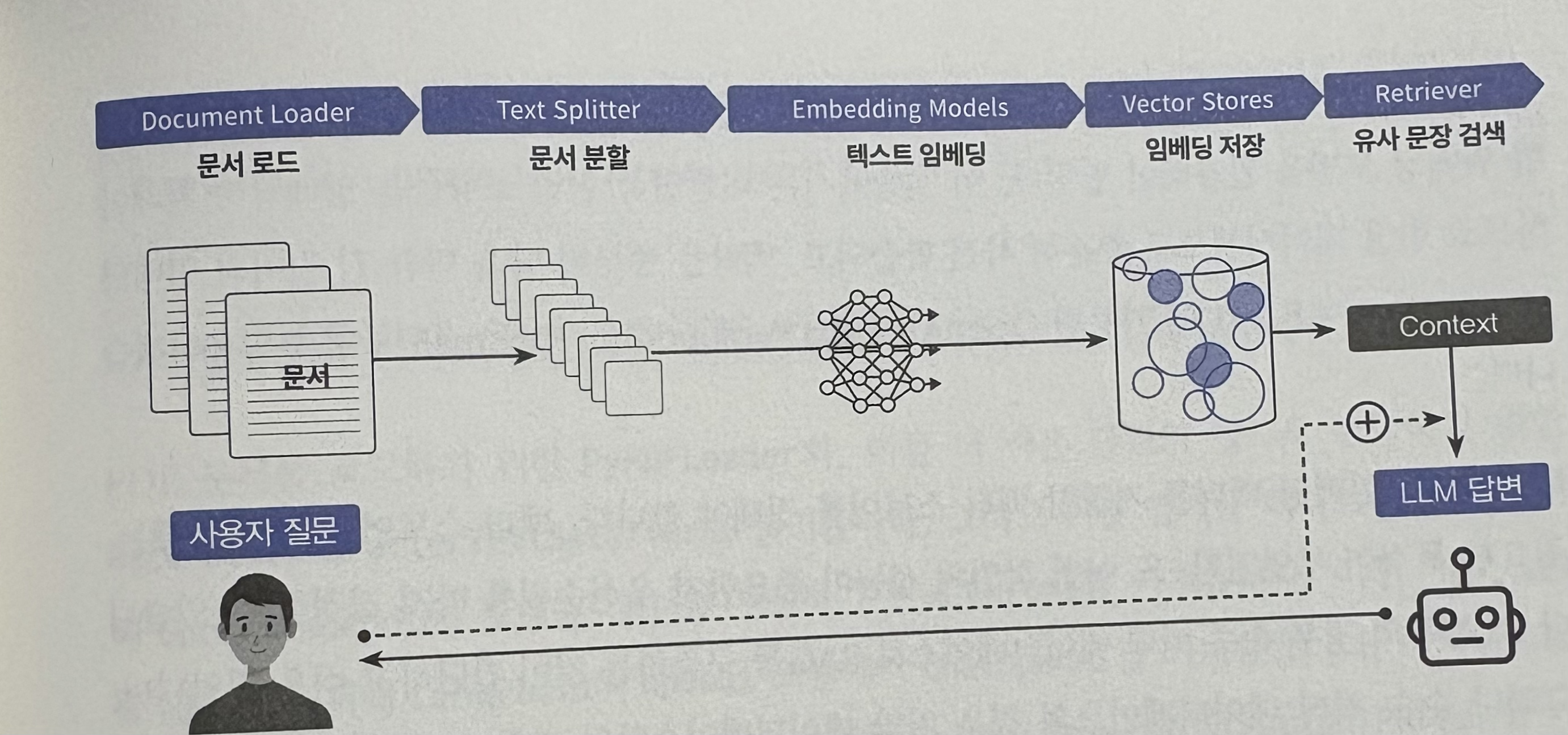
고려해야할 요소 7가지
- 모델 종류
- API를 통해 Closed source LLM을 활용하는 경우 품질 안정적, 구축이 빠름
- OpenAI의 GPT를 API 형태로 활용
- Document Loader 선정
- PDF 형식의 여러 파일을 RAG에 활용: PDF Loader or 다양한 파일 활용 시 각 형식을 불러오기 위한 Document Loader 모두 로드
- 대한민국 헌법 PDF 파일을 로드하기 위해 PDF Loader 활용
- Text Splitter 선언
- 문서를 적절한 크기의 텍스트 청크로 분할하기 위함
- 다른 요소들에 비해서는 고려 요소가 적은편
- 대부분
RecursiveCharacterTextSplitter,chunk_overlap파라미터 설정만 해도 충분한 성능이 나옴 - 실습에서도 동일하게 적용 예정
- 임베딩 모델 활용
- 분할된 청크를 임베딩 벡터로 변환하기 위함
- 문서의 언어와 청크의 길이를 고려해야 함
- 영어 : 영어 데이터로 사전 학습된 임베딩 모델 활용, 한글 : 한글 데이터가 충분히 사전 학습된 모델 활용
- 청크 길이가 길다면 ➡️ 컨텍스트 윈도우가 충분한 임베딩 모델 활용
- 대한민국 헌법 조항들을 임베딩 변환 ➡️ 한글 데이터셋으로 충분히 학습되고, 맥락을 잘 담을만큼 긴 길이의 임베딩이 가능한 모델 사용해야 함(max_token = 8,191)
- OpenAI의 text-embedding-small 모델 활용
- 임베딩 벡터를 저장할 벡터 스토어 선정
- 필요한 목적이 무엇인지, 어떤 작업의 성능이 중요한지에 대한 우선순위를 따져야함
- 대부분 순수 벡터 데이터베이스로 RAG를 구축하는 것이 가장 간단하고 쉬움
- 일반 데이터베이스와의 결합 까다로움
- 대규모 확장 시 속도, 안정성이 기존 데이터베이스 대비 보장되지 않을 수 있음
- 기존 데이터베이스에 벡터 형태로 저장할 수 있는 방법을 강구하는 것도 좋은 아이디어
- 파일럿 형태의 RAG 시스템을 구축 ➡️ Chroma 활용
- Retriever 결정
- 사용자의 질문과 유사한 문장을 검색하기 위함
- Chroma로 설정한 경우, 벡터 스토어 기반 검색기 활용 가능
- RAG 성능이 충분하지 않다면 ➡️
Parent Document RetrieverorLong Context Reorder기법 사용해 보완
- Chain
- LCEL 기반으로 앞 요소들을 하나로 묶어서 구성
실습 노트북 : Basic RAG.ipyanb
필요한 라이브러리 호출 및 API 키 설정
hub: 프롬프트 공유 및 관리, 랭체인 활용 시 참고할만한 프롬프트가 다수 존재- 랭체인 Hub의 RAG 전용 프롬프트를 활용하기 위한 라이브러리
PyPDFLoader: PDF 문서 로드RecursiveCharacterTextSplitter: 더 작은 단위 청크로 분할OpenAIEmbeddings: 임베딩 벡터로 변환하기 위함Chroma: 벡터 저장ChatOpenAI: GPT API 활용RunnablePassthrough: LCEL이 잘 작동하도록 랭체인에서 개발한 고유 객체 Runnable 일종- Chain이 받은 input을 수정 없이 다음 요소에 전달하기 위해 사용
- 사용자 질문을 받아 프롬프트 템플릿에 그대로 넘기는 역할 담당
Runnable 객체의 종류
- Runnable Parallel : 병렬 처리
- RunnableBranch : 조건에 따라 실행할 브랜치 선택
- RunnableLambda : 사용자 정의 함수를 Chain에 결합할 수 있도록 함
StrOutputParser: LLM 답변을 문자열로 출력하도록 만들기 위한 Output parser 사용
from langchain import hub
from langchain.document_loaders import PyPDFLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain.vectorstores import Chroma
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
import os
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY"문서 로드/분할 및 벡터 임베딩
as_retriever(): 벡터 데이터베이스를 기반으로 Retriever를 만들기 위해 사용
#헌법 PDF 파일 로드
loader = PyPDFLoader(r"/content/drive/MyDrive/NLP톺아보기/file/대한민국헌법(헌법)(제00010호)(19880225).pdf")
pages = loader.load_and_split()
#PDF 파일을 1000자 청크로 분할
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=100)
docs = text_splitter.split_documents(pages)
#ChromaDB에 청크들을 벡터 임베딩으로 저장(OpenAI 임베딩 모델 활용)
vectorstore = Chroma.from_documents(docs, OpenAIEmbeddings(model = 'text-embedding-3-small'))
retriever = vectorstore.as_retriever()프롬프트와 모델 선언
-rlm/rag-prompt : Langchain Hub에서 RAG 전용 프롬프트로 활용됨
#GPT 3.5 모델 선언
from langchain import hub
llm = ChatOpenAI(model="gpt-4o-mini")
#Langchain Hub에서 RAG 프롬프트 호출
prompt = hub.pull("rlm/rag-prompt")
#Retriever로 검색한 유사 문서의 내용을 하나의 string으로 결합
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)- Langchain Hub에서 가져온 RAG 프롬프트
- ChatPromptTemplate 형식으로 불러온 것을 확인
prompt
- 프롬프트 메시지 출력
- context 매개변수 : Retriever를 통해 검색한 사용자 질문과의 유사 문장들이 들어감
- Retriever 출력 결과물로 여러 개의 Document가 출력됨
- 바로 context에 넣으면 불필요한 토큰 소모 발생
- Document(page_content)와 같은 Document 객체 자체 텍스트, metadata 정보는 context에 넣어줄 필요가 없음!
- context 매개변수 : Retriever를 통해 검색한 사용자 질문과의 유사 문장들이 들어감
- format_docs() 함수를 Chain에 삽입 ➡️ Retriever 검색 결과물에서 page_content 부분만 추출 + 하나의 텍스트로 합침
prompt.messages
Chain 구축
-
Dictionary 객체
- Chain으로 사용자 질문 입력 받기
- 벡터 데이터베이스에서 유사 문장을 검색하기 위해 Retriver에 연결
- 결과물을 context의 Value로 지정 ➡️ 사용자 질문은 수정 없이 question의 Value로 전달됨
-
Dictionary 객체를 그대로 사전 정의한 프롬프트 템플릿에 전달
- 매개변수로 context, question을 갖고 있었고, 앞선 사용자 질문을 바탕으로 완성한 Dictionary에 매개변수 값이 저장되어 있기 때문에 그래도 프롬프트를 완성하는 것에 활용되는 형태
-
완성된 프롬프트 ➡️ LLM에 전달
-
사용자 질문과 검색 결과물 종합 작성한 LLM 답변 ➡️ StrOutputParser()를 거쳐 문자열 형태로 출력
rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)rag_chain의 작동 결과 보기- 헌법 조항에 기반해 답변함!
answer = rag_chain.invoke("국회의원의 의무는 뭐야?")
print(answer)국회의원의 의무는 청렴성을 유지하고 국가 이익을 우선하여 양심에 따라 직무를 수행하는 것입니다. 또한, 국회의원은 자신의 지위를 남용하여 재산상의 이익을 취득하거나 타인을 위해 알선할 수 없습니다. 이외에도 국회의원은 직무상 행한 발언과 표결에 대해 국회 외부에서 책임을 지지 않습니다.rag_chain시각화
rag_chain.get_graph().print_ascii()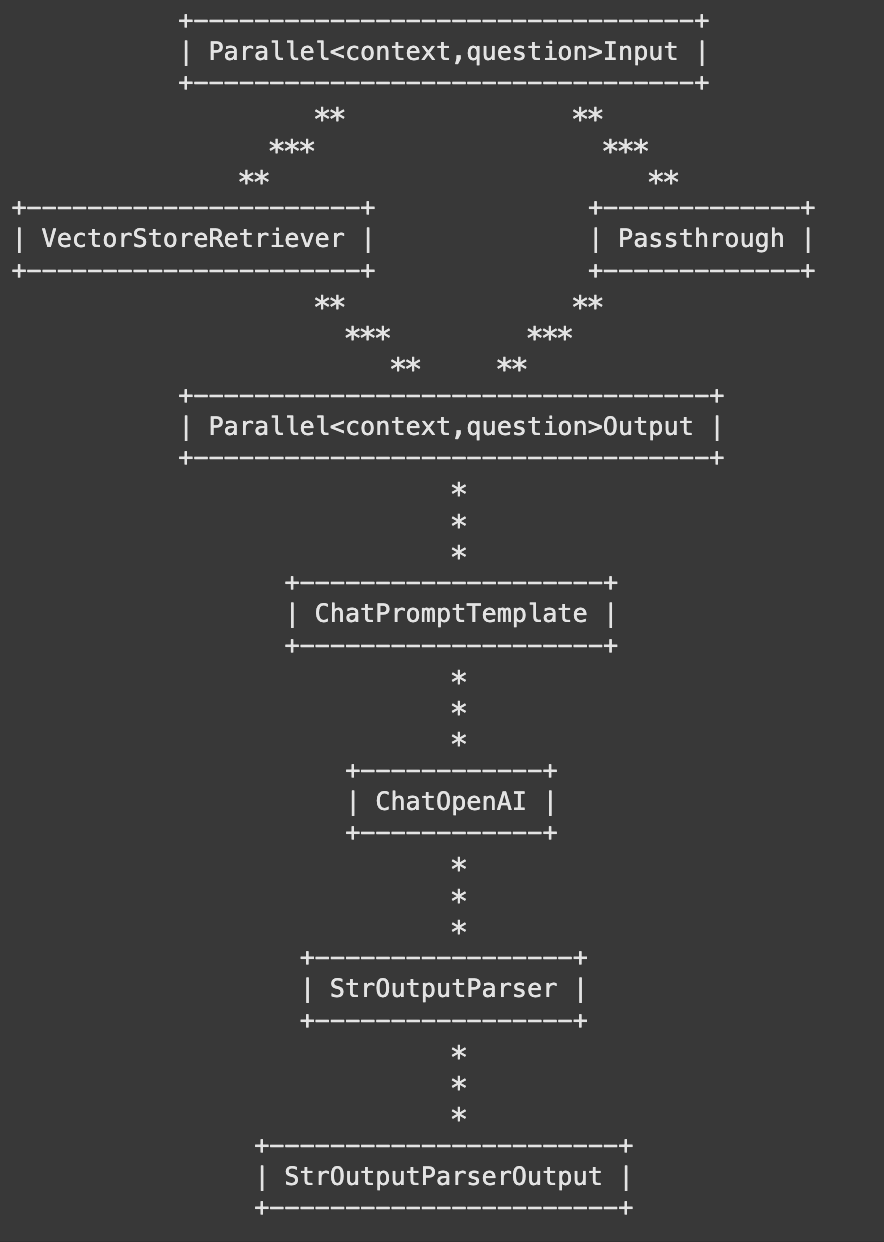
Chain 구동 순서
-
Parallel input으로
context,question구성 확인할 수 있음 -
Runnable Parallel : rag_chain의 가장 첫 요소로 선언한 Dictionary가 Parallel input으로 활용됨
- Dictionary의 Key-Value 형식으로 작업 병렬 수행 -> 결과를 저장해 다음 단계로 전달
-
rag_chain
- 벡터 DB 기반 Retriever 수행
- 병렬 수행
- format_docs() 함수로 결과물 후가공
- question이 RunnalbePassthrough로 통과됨
-
Dictionary로 context와 question 값을 ChatPromptTemplate에 전달
-
전달된 템플릿 ➡️ ChatOpenAI로 전달
-
받은 답변 ➡️ StrOutPutParser로 문자열 처리됨
RAG 시스템 구축하기2 - Memory 기능 구축
랭체인에서의 Memory 기능
- ChatPromptTemplete을 변형
- 채팅 히스토리 저장
- Retriever, Chain 복합 활용
- 사용자 질문이 들어오면 그동안 적재한 채팅 히스토리와 통합
- LLM에게 주어지는 프롬프트
- "채팅 기록과 최신 사용자 질문을 통합하여 채팅 기록 없이 이해 가능한 독립형 질문을 만들어라"
- 채팅 히스토리와 사용자 질문 통합 후, 기존 RAG와 동일한 과정을 거쳐 답변 생성
- Retriever를 통해 통합된 질문과 유사한 문장 검색
- Q&A 프롬프트 내에 맥락으로 주입해 LLM에게 답변할 수 있도록 힌트 제공
- LLM은 채팅 히스토리, 사용자 질문, 힌트 컨텍스트를 갖춘 상태로 답변하게 됨
문서 로드-분할-벡터 저장(Retriever 생성)
from langchain import hub
from langchain.document_loaders import PyPDFLoader
from langchain.vectorstores import Chroma
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain_core.runnables import RunnablePassthrough, RunnableParallel
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables.history import BaseChatMessageHistory, RunnableWithMessageHistory
# PDF 파일 로드 및 처리
loader = PyPDFLoader(r"/content/drive/MyDrive/NLP톺아보기/file/대한민국헌법(헌법)(제00010호)(19880225).pdf")
# 1,000자씩 분할하여 Document 객체 형태로 docs에 저장
pages = loader.load_and_split()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
docs = text_splitter.split_documents(pages)
# Chroma 벡터 저장소 설정 및 retriever 생성
vectorstore = Chroma.from_documents(docs, OpenAIEmbeddings(model='text-embedding-3-small'))
retriever = vectorstore.as_retriever()채팅 히스토리와 사용자 질문 통합
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain.chains import create_history_aware_retriever, create_retrieval_chain
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder
# Define the contextualize question prompt
contextualize_q_system_prompt = """Given a chat history and the latest user question \
which might reference context in the chat history, formulate a standalone question \
which can be understood without the chat history. Do NOT answer the question, \
just reformulate it if needed and otherwise return it as is."""
contextualize_q_prompt = ChatPromptTemplate.from_messages(
[
("system", contextualize_q_system_prompt),
MessagesPlaceholder("chat_history"),
("human", "{input}"),
]
)
history_aware_retriever = create_history_aware_retriever(llm, retriever, contextualize_q_prompt)from langchain_core.messages import AIMessage, HumanMessage
contextualize_q_prompt = ChatPromptTemplate.from_messages(
[
("system", contextualize_q_system_prompt),
MessagesPlaceholder("chat_history"),
("human", "{input}"),
]
)
chat_history = [
HumanMessage(content='대통령의 임기는 몇년이야?'),
AIMessage(content='대통령의 임기는 5년입니다.')
]
contextualize_q_prompt.invoke({"input":"국회의원은?", "chat_history" : chat_history})
- 채팅 히스토리와 사용자 질문을 활용해 만들어낸 독립형 질문과 유사한 청크를 벡터 DB에서 검색
history_aware_retriever = create_history_aware_retriever(llm, retriever, contextualize_q_prompt)
result = history_aware_retriever.invoke({"input":"국회의원은?", "chat_history" : chat_history})
for i in range(len(result)):
print(f"{i+1}번째 유사 청크")
print(result[i].page_content[:250])
print("-"*100)
RAG 체인 구축
from langchain.chains import create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
qa_system_prompt = """You are an assistant for question-answering tasks. \
Use the following pieces of retrieved context to answer the question. \
If you don't know the answer, just say that you don't know. \
Use three sentences maximum and keep the answer concise.\
{context}"""
qa_prompt = ChatPromptTemplate.from_messages(
[
("system", qa_system_prompt),
MessagesPlaceholder("chat_history"),
("human", "{input}"),
]
)
question_answer_chain = create_stuff_documents_chain(llm, qa_prompt)
rag_chain = create_retrieval_chain(history_aware_retriever, question_answer_chain)RAG 체인 사용 방법 및 채팅 히스토리 기록
from langchain_core.messages import HumanMessage
#채팅 히스토리를 적재하기 위한 리스트
chat_history = []
question = "대통령의 임기는 몇년이야?"
#첫 질문에 답변하기 위한 rag_chain 실행
ai_msg_1 = rag_chain.invoke({"input": question, "chat_history": chat_history})
#첫 질문과 답변을 채팅 히스토리로 저장
chat_history.extend([HumanMessage(content=question), ai_msg_1["answer"]])
second_question = "국회의원은?"
#두번째 질문 입력 시에는 첫번째 질문-답변이 저장된 chat_history가 삽입됨
ai_msg_2 = rag_chain.invoke({"input": second_question, "chat_history": chat_history})
print(ai_msg_2["answer"])
채팅 세션별 기록 자동 저장 RAG 체인 구축
- 채팅 세션별로 다른 채팅 히스토리를 저장해 개별 대화방 만들기 가능
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_core.chat_history import BaseChatMessageHistory
from langchain_core.runnables.history import RunnableWithMessageHistory
#채팅 세션별 기록 저장 위한 Dictionary 선언
store = {}
#주어진 session_id 값에 매칭되는 채팅 히스토리 가져오는 함수 선언
def get_session_history(session_id: str) -> BaseChatMessageHistory:
if session_id not in store:
store[session_id] = ChatMessageHistory()
return store[session_id]
#RunnableWithMessageHistory 모듈로 rag_chain에 채팅 기록 세션별로 자동 저장 기능 추가
conversational_rag_chain = RunnableWithMessageHistory(
rag_chain,
get_session_history,
input_messages_key="input",
history_messages_key="chat_history",
output_messages_key="answer",
)- 질문 1
conversational_rag_chain.invoke(
{"input": "대통령의 임기는 몇년이야?"},
config={
"configurable": {"session_id": "240510101"}
}, # constructs a key "abc123" in `store`.
)["answer"]
- 질문 2
conversational_rag_chain.invoke(
{"input": "국회의원은?"},
config={"configurable": {"session_id": "240510101"}},
)["answer"]

Open source LLM으로 RAG 구축하기
Ollama 설치
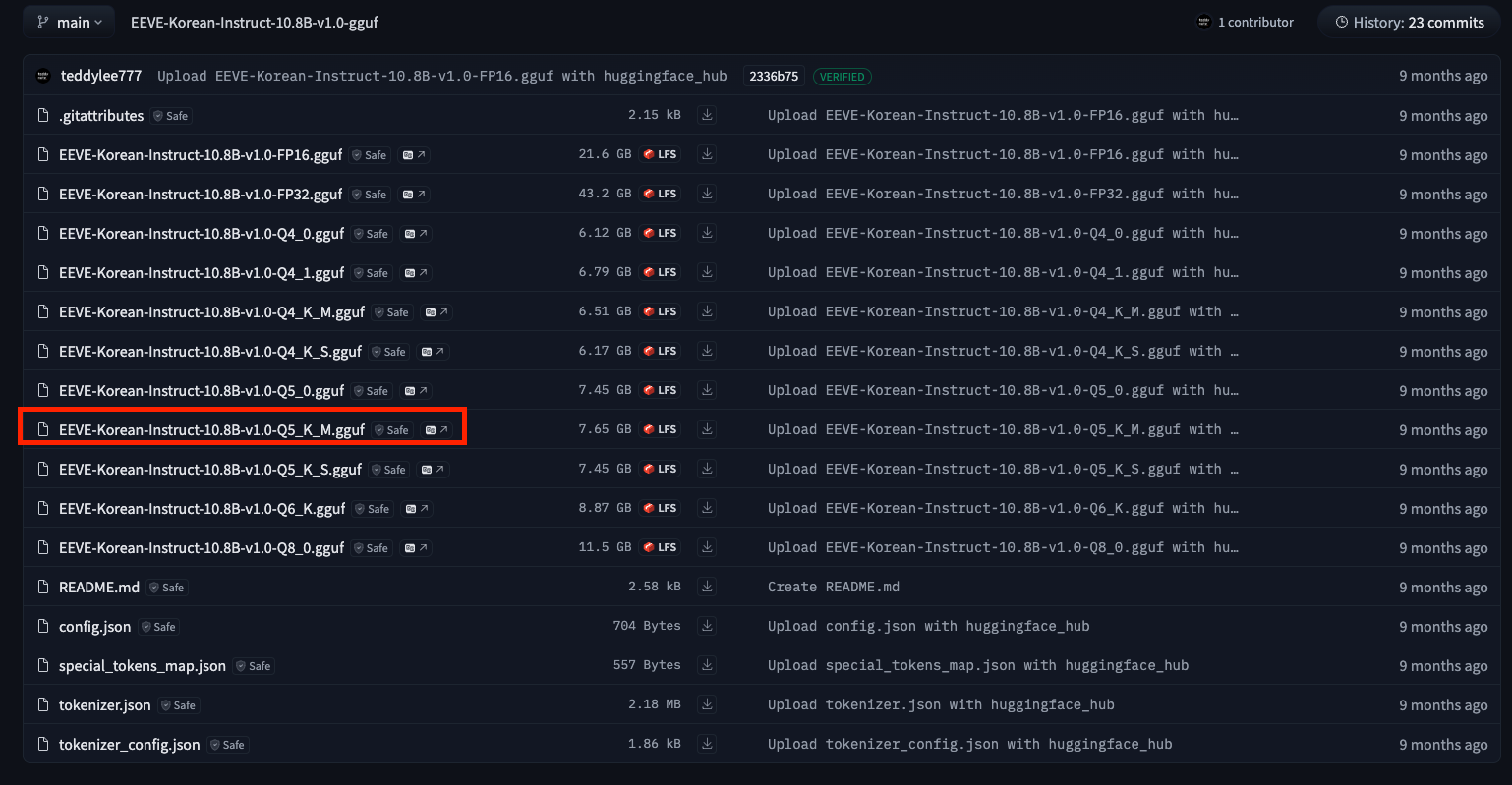
Open source LLM 설치: EEVE 모델
- 기반 LLM을 양자화한 GGUF 버전으로 사용
- 사이트 : https://huggingface.co/teddylee777/EEVE-Korean-Instruct-10.8B-v1.0-gguf/tree/main
- EEVE 폴더 내부에 Modelfile.txt 작성 후 다음과 같이 저장
FROM EEVE-Korean-Instruct-10.8B-v1.0-Q5_K_M.gguf
TEMPLATE """{{- if .System }}
<s>{{ .System }}</s>
{{- end }}
<s>Human:
{{ .Prompt }}</s>
<s>Assistant:
"""
SYSTEM """A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's Questions."""
PARAMETER temperature 0
PARAMETER num_predict 3000
PARAMETER num_ctx 4096
PARAMETER stop <s>
PARAMETER stop </s>
- EEVE 폴더로 이동

- Ollama 모델 이름 설정 및 모델 로드
- Ollama를 응용 프로그램으로 위치 이동 및 실행
- 다음을 터미널에서 실행
- 로드하기
ollama create EEVE-Korean-10.8B -f Modelfile.txt
- 모델이 잘 로드되었는지 확인
ollama list
- 기본 체인 구성
주의 : 코랩이 아닌, 로컬에서 실행해야 함
from langchain_ollama import ChatOllama
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
llm = ChatOllama(model="EEVE-Korean-10.8B:latest")
prompt = ChatPromptTemplate.from_template("{topic}에 대한 짧은 농담을 들려주세요. ")
chain = prompt | llm | StrOutputParser()
print(chain.invoke({"topic": "우주여행"}))
- 모든 요소를 Open Source로 RAG 체인 구축하기
Chroma().delete_collection()from langchain.document_loaders import PyPDFLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import Chroma
from langchain_ollama import ChatOllama
from langchain import hub
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
loader = PyPDFLoader(r"../대한민국헌법(헌법)(제00010호)(19880225).pdf")
pages = loader.load_and_split()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
docs = text_splitter.split_documents(pages)
model_name = "jhgan/ko-sbert-nli"
model_kwargs = {'device': 'CUDA'}
encode_kwargs = {'normalize_embeddings': True}
embedding = HuggingFaceEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs
)
vectorstore = Chroma.from_documents(docs, embedding)
retriever = vectorstore.as_retriever()
prompt = hub.pull("rlm/rag-prompt")
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
rag_chain = (
{"context": retriever|format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)- rag_chain 답변 스트리밍하기
for chunk in rag_chain.stream("헌법 제 1조 1항이 뭐야"):
print(chunk, end="", flush=True)
언젠가 내 코드로 세상에 기여할 수 있도록, Data Science&BE 개발 기록 노트☘️