
7-1. 들어가며
학습 목표
- 딥러닝 모델의 저장 및 복원 방법 학습
- 모델 학습 시 사용 가능한 콜백 함수 학습
학습 내용
-
MNIST 모델 예제
- 모듈 import
- 데이터 load & 전처리
- 모델 구성
- 모델 컴파일 & 학습
- 모델 평가 & 예측
-
모델 저장과 로드
-
콜백(Callbacks)
- ModelCheckpoint
- EarlyStopping
- LearningRateScheduler
- Tensorboard
7-2. MNIST 딥러닝 모델 예제
MNIST
- 손으로 쓴 숫자들로 이뤄진 이미지 데이터셋
- 고전 데이터셋, 기계 학습 분야 학습과 테스트에 많이 사용됨
keras.datasets에 기본 포함되어 있음

Module import
- Tenserflow
- keras
- models, layers, optimizer, utils
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import models, layers, utilsData loading & Preprocessing
tensorflow.keras.datasets.mnist- MNIST 데이터셋 : 케라스 데이터셋에 내장되어 있음
train_test_split()- 학습용 데이터 : x_train_full, y_train_full로 나누기
- 70% : x_train, y_train(학습 데이터)
- 30% : x_val, y_val(검증 데이터)
- 전체 60,000개
- 70% 학습용 데이터 : 42,000개
- 30% 검증용 데이터 : 10,000개
from tensorflow.keras.datasets import mnist
from sklearn.model_selection import train_test_split
(x_train_full, y_train_full), (x_test, y_test) = mnist.load_data(path='mnist.npz')
x_train, x_val, y_train, y_val = train_test_split(x_train_full, y_train_full,
test_size=0.3,
random_state=123)
print(f"전체 학습 데이터: {x_train_full.shape} 레이블: {y_train_full.shape}")
print(f"학습용 데이터: {x_train.shape} 레이블: {y_train.shape}")
print(f"검증용 데이터: {x_val.shape} 레이블: {y_val.shape}")
print(f"테스트용 데이터: {x_test.shape} 레이블: {y_test.shape}")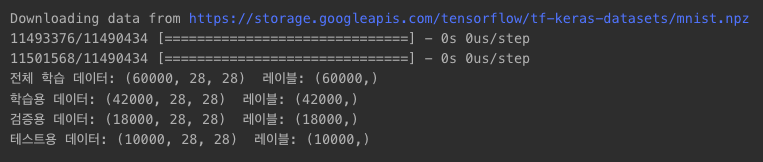
- MNIST 데이터셋 실제 숫자 이미지 구성 확인
- x_train_full과 y_train_full에서 6개 랜덤 확인
import numpy as np
import matplotlib.pyplot as plt
plt.style.use("seaborn-white")
num_sample = 6
random_idxs = np.random.randint(60000, size=num_sample)
plt.figure(figsize=(15, 3))
for i, idx in enumerate(random_idxs):
img = x_train_full[idx, :]
label = y_train_full[idx]
plt.subplot(1, len(random_idxs), i+1)
plt.axis('off')
plt.title(f'Index: {idx}, Label: {label}')
plt.imshow(img)
- y_train 0번째 확인 :
4가 라벨링되어 있음 - x_train 0번째 확인 : 4 이미지 ➡️ 0~255 사이의 값으로 표현
img = x_train[0, :]
plt.axis('off')
plt.imshow(img)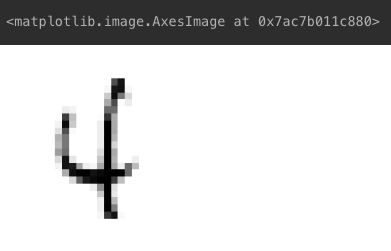
print(x_train[0])
- 전처리
- x_train, x_val, x_test : 255로 나누기
- 0 ~ 1 사이의 값으로 스케일링
- y_train, y_val, y_test : 10개 값을 가지는 범주형 데이터
- 원-핫 인코딩(utils.to_categorical)
- x_train, x_val, x_test : 255로 나누기
x_train = x_train / 255.
x_val = x_val / 255.
x_test = x_test / 255.
y_train = utils.to_categorical(y_train)
y_val = utils.to_categorical(y_val)
y_test = utils.to_categorical(y_test)
print(y_train[0])
print(y_val[0])
print(y_test[0])
Model 구성
- Sequential()로 구성
- shape : (28, 28)
- layers.Flatten : 2차원(28x28)을 1차원(784)로 변형
- layers.Dense : 유닛수 -> 100, 64, 32, 10의 4겹으로
- 활성화 함수로 relu 사용
- MNIST 숫자는 0~9 -> 마지막 레이어는 유닛수 10, 활성화 함수 softmax(카테고리별 확률값)
model = models.Sequential()
model.add(keras.Input(shape=(28, 28), name='input'))
model.add(layers.Flatten(input_shape=[28, 28], name='flatten'))
model.add(layers.Dense(100, activation='relu', name='dense1'))
model.add(layers.Dense(64, activation='relu', name='dense2'))
model.add(layers.Dense(32, activation='relu', name='dense3'))
model.add(layers.Dense(10, activation='softmax', name='output'))
model.summary()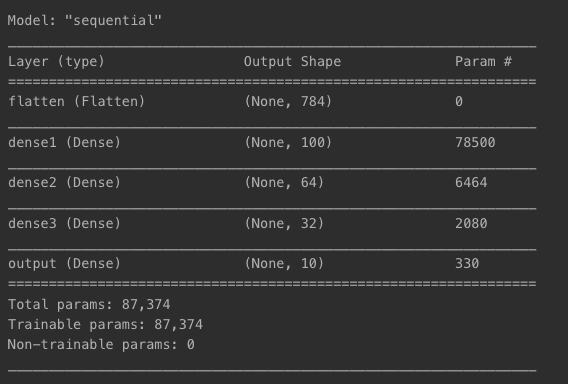
- 모델 구성 확인
utils.plot_model(model)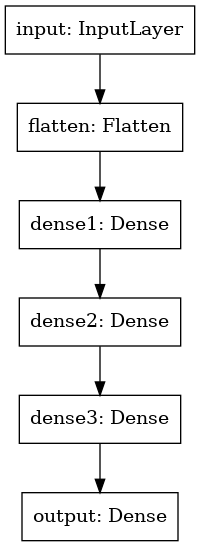
- 레이어 모양까지 확인
utils.plot_model(model, show_shapes=True)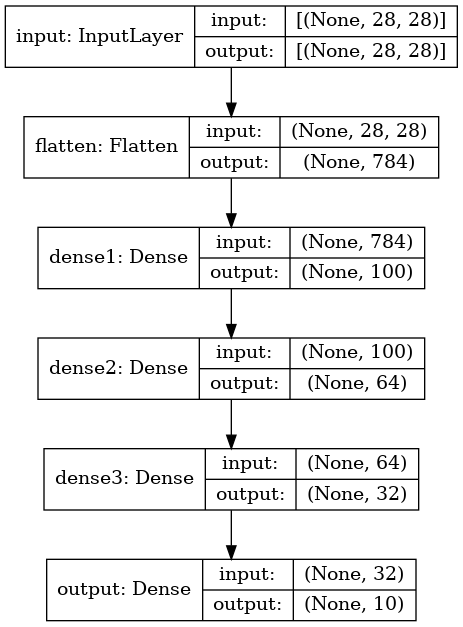
Model Compiling & Training
- categorical_crossentropy
- 다중 분류 손실 함수
- 클래스가 원-핫 인코딩 방식일 때 사용
- 성능 확인 지표 : accracy
model.compile(loss='categorical_crossentropy',
optimizer='sgd',
metrics=['accuracy'])- 딥러닝 모델 학습
- 학습 데이터 : x_train, y_train
- epochs : 학습 반복(40으로 설정)
- batch_size : 128
- 검증 데이터 : x_val, y_val
history = model.fit(x_train, y_train,
epochs=50,
batch_size=128,
validation_data=(x_val, y_val))Epoch 1/50
329/329 [==============================] - 15s 4ms/step - loss: 1.8192 - accuracy: 0.4695 - val_loss: 1.1098 - val_accuracy: 0.7482
Epoch 2/50
329/329 [==============================] - 1s 3ms/step - loss: 0.7379 - accuracy: 0.8174 - val_loss: 0.5498 - val_accuracy: 0.8444
Epoch 3/50
329/329 [==============================] - 1s 3ms/step - loss: 0.4628 - accuracy: 0.8732 - val_loss: 0.4161 - val_accuracy: 0.8817
Epoch 4/50
329/329 [==============================] - 1s 3ms/step - loss: 0.3782 - accuracy: 0.8939 - val_loss: 0.3691 - val_accuracy: 0.8954
Epoch 5/50
329/329 [==============================] - 1s 3ms/step - loss: 0.3350 - accuracy: 0.9047 - val_loss: 0.3266 - val_accuracy: 0.9023
Epoch 6/50
329/329 [==============================] - 1s 3ms/step - loss: 0.3070 - accuracy: 0.9120 - val_loss: 0.3063 - val_accuracy: 0.9080
Epoch 7/50
329/329 [==============================] - 1s 3ms/step - loss: 0.2867 - accuracy: 0.9176 - val_loss: 0.2840 - val_accuracy: 0.9148
Epoch 8/50
329/329 [==============================] - 1s 3ms/step - loss: 0.2700 - accuracy: 0.9222 - val_loss: 0.2689 - val_accuracy: 0.9188
Epoch 9/50
329/329 [==============================] - 1s 3ms/step - loss: 0.2563 - accuracy: 0.9260 - val_loss: 0.2753 - val_accuracy: 0.9151
Epoch 10/50
329/329 [==============================] - 1s 3ms/step - loss: 0.2443 - accuracy: 0.9293 - val_loss: 0.2538 - val_accuracy: 0.9241
Epoch 11/50
329/329 [==============================] - 1s 3ms/step - loss: 0.2332 - accuracy: 0.9330 - val_loss: 0.2367 - val_accuracy: 0.9280
Epoch 12/50
329/329 [==============================] - 1s 3ms/step - loss: 0.2240 - accuracy: 0.9354 - val_loss: 0.2288 - val_accuracy: 0.9303
Epoch 13/50
329/329 [==============================] - 1s 3ms/step - loss: 0.2152 - accuracy: 0.9380 - val_loss: 0.2344 - val_accuracy: 0.9302
Epoch 14/50
329/329 [==============================] - 1s 3ms/step - loss: 0.2076 - accuracy: 0.9403 - val_loss: 0.2244 - val_accuracy: 0.9333
Epoch 15/50
329/329 [==============================] - 1s 3ms/step - loss: 0.2001 - accuracy: 0.9417 - val_loss: 0.2102 - val_accuracy: 0.9371
Epoch 16/50
329/329 [==============================] - 1s 3ms/step - loss: 0.1929 - accuracy: 0.9447 - val_loss: 0.2046 - val_accuracy: 0.9373
Epoch 17/50
329/329 [==============================] - 1s 3ms/step - loss: 0.1863 - accuracy: 0.9459 - val_loss: 0.1972 - val_accuracy: 0.9405
Epoch 18/50
329/329 [==============================] - 1s 3ms/step - loss: 0.1802 - accuracy: 0.9482 - val_loss: 0.1975 - val_accuracy: 0.9403
Epoch 19/50
329/329 [==============================] - 1s 3ms/step - loss: 0.1745 - accuracy: 0.9498 - val_loss: 0.1927 - val_accuracy: 0.9404
Epoch 20/50
329/329 [==============================] - 1s 3ms/step - loss: 0.1692 - accuracy: 0.9511 - val_loss: 0.1832 - val_accuracy: 0.9449
Epoch 21/50
329/329 [==============================] - 1s 3ms/step - loss: 0.1640 - accuracy: 0.9525 - val_loss: 0.1840 - val_accuracy: 0.9434
Epoch 22/50
329/329 [==============================] - 1s 3ms/step - loss: 0.1586 - accuracy: 0.9546 - val_loss: 0.1819 - val_accuracy: 0.9463
Epoch 23/50
329/329 [==============================] - 1s 3ms/step - loss: 0.1542 - accuracy: 0.9559 - val_loss: 0.1733 - val_accuracy: 0.9469
Epoch 24/50
329/329 [==============================] - 1s 3ms/step - loss: 0.1498 - accuracy: 0.9579 - val_loss: 0.1693 - val_accuracy: 0.9483
Epoch 25/50
329/329 [==============================] - 1s 3ms/step - loss: 0.1454 - accuracy: 0.9586 - val_loss: 0.1688 - val_accuracy: 0.9472
Epoch 26/50
329/329 [==============================] - 1s 3ms/step - loss: 0.1414 - accuracy: 0.9597 - val_loss: 0.1656 - val_accuracy: 0.9484
Epoch 27/50
329/329 [==============================] - 1s 3ms/step - loss: 0.1377 - accuracy: 0.9607 - val_loss: 0.1748 - val_accuracy: 0.9467
Epoch 28/50
329/329 [==============================] - 1s 3ms/step - loss: 0.1340 - accuracy: 0.9626 - val_loss: 0.1586 - val_accuracy: 0.9522
Epoch 29/50
329/329 [==============================] - 1s 3ms/step - loss: 0.1303 - accuracy: 0.9630 - val_loss: 0.1537 - val_accuracy: 0.9529
Epoch 30/50
329/329 [==============================] - 1s 3ms/step - loss: 0.1271 - accuracy: 0.9642 - val_loss: 0.1679 - val_accuracy: 0.9486
Epoch 31/50
329/329 [==============================] - 1s 3ms/step - loss: 0.1239 - accuracy: 0.9650 - val_loss: 0.1507 - val_accuracy: 0.9531
Epoch 32/50
329/329 [==============================] - 1s 3ms/step - loss: 0.1206 - accuracy: 0.9661 - val_loss: 0.1484 - val_accuracy: 0.9551
Epoch 33/50
329/329 [==============================] - 1s 3ms/step - loss: 0.1174 - accuracy: 0.9672 - val_loss: 0.1437 - val_accuracy: 0.9566
Epoch 34/50
329/329 [==============================] - 1s 3ms/step - loss: 0.1145 - accuracy: 0.9680 - val_loss: 0.1481 - val_accuracy: 0.9548
Epoch 35/50
329/329 [==============================] - 1s 3ms/step - loss: 0.1115 - accuracy: 0.9685 - val_loss: 0.1401 - val_accuracy: 0.9569
Epoch 36/50
329/329 [==============================] - 1s 3ms/step - loss: 0.1088 - accuracy: 0.9694 - val_loss: 0.1418 - val_accuracy: 0.9577
Epoch 37/50
329/329 [==============================] - 1s 3ms/step - loss: 0.1063 - accuracy: 0.9702 - val_loss: 0.1369 - val_accuracy: 0.9584
Epoch 38/50
329/329 [==============================] - 1s 3ms/step - loss: 0.1035 - accuracy: 0.9708 - val_loss: 0.1382 - val_accuracy: 0.9570
Epoch 39/50
329/329 [==============================] - 1s 3ms/step - loss: 0.1012 - accuracy: 0.9712 - val_loss: 0.1323 - val_accuracy: 0.9594
Epoch 40/50
329/329 [==============================] - 1s 3ms/step - loss: 0.0984 - accuracy: 0.9719 - val_loss: 0.1386 - val_accuracy: 0.9572
Epoch 41/50
329/329 [==============================] - 1s 3ms/step - loss: 0.0964 - accuracy: 0.9728 - val_loss: 0.1304 - val_accuracy: 0.9599
Epoch 42/50
329/329 [==============================] - 1s 3ms/step - loss: 0.0939 - accuracy: 0.9739 - val_loss: 0.1367 - val_accuracy: 0.9584
Epoch 43/50
329/329 [==============================] - 1s 3ms/step - loss: 0.0917 - accuracy: 0.9740 - val_loss: 0.1275 - val_accuracy: 0.9612
Epoch 44/50
329/329 [==============================] - 1s 3ms/step - loss: 0.0893 - accuracy: 0.9752 - val_loss: 0.1264 - val_accuracy: 0.9614
Epoch 45/50
329/329 [==============================] - 1s 3ms/step - loss: 0.0875 - accuracy: 0.9752 - val_loss: 0.1261 - val_accuracy: 0.9603
Epoch 46/50
329/329 [==============================] - 1s 3ms/step - loss: 0.0855 - accuracy: 0.9759 - val_loss: 0.1246 - val_accuracy: 0.9619
Epoch 47/50
329/329 [==============================] - 1s 3ms/step - loss: 0.0832 - accuracy: 0.9771 - val_loss: 0.1220 - val_accuracy: 0.9628
Epoch 48/50
329/329 [==============================] - 1s 3ms/step - loss: 0.0813 - accuracy: 0.9772 - val_loss: 0.1256 - val_accuracy: 0.9616
Epoch 49/50
329/329 [==============================] - 1s 3ms/step - loss: 0.0792 - accuracy: 0.9782 - val_loss: 0.1208 - val_accuracy: 0.9622
Epoch 50/50
329/329 [==============================] - 1s 3ms/step - loss: 0.0776 - accuracy: 0.9783 - val_loss: 0.1314 - val_accuracy: 0.9600- 에폭마다의 지표 결과 저장
- history : loss, accuracym val_loss, val_accuracy
history.history.keys()
- 시각화
- history에 저장된 결과값 -> 에폭 진행되는 동안의 변화 추이를 보기 위함
- 첫번째 차트 : loss, val_loss
- 두번째 차트 : accuracy, val_accuracy
history_dict = history.history
loss = history_dict['loss']
val_loss = history_dict['val_loss']
epochs = range(1, len(loss) + 1)
fig = plt.figure(figsize=(12, 5))
ax1 = fig.add_subplot(1, 2, 1)
ax1.plot(epochs, loss, color='blue', label='train_loss')
ax1.plot(epochs, val_loss, color='red', label='val_loss')
ax1.set_title('Train and Validation Loss')
ax1.set_xlabel('Epochs')
ax1.set_ylabel('Loss')
ax1.grid()
ax1.legend()
accuracy = history_dict['accuracy']
val_accuracy = history_dict['val_accuracy']
ax2 = fig.add_subplot(1, 2, 2)
ax2.plot(epochs, accuracy, color='blue', label='train_accuracy')
ax2.plot(epochs, val_accuracy, color='red', label='val_accuracy')
ax2.set_title('Train and Validation Accuracy')
ax2.set_xlabel('Epochs')
ax2.set_ylabel('Accuracy')
ax2.grid()
ax2.legend()
plt.show()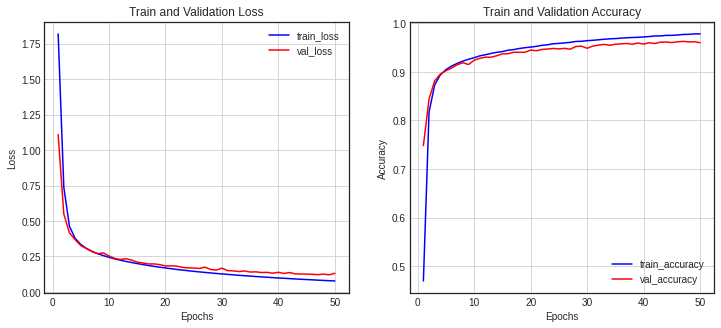
Model 평가 & 예측
- x_test, y_test 대상 evaluate() 함수 사용
model.evaluate(x_test, y_test)
- 예측
- x_test 넣기 -> 예측 결과를 받아 0번째 결과 확인
pred_ys = model.predict(x_test)
print(pred_ys.shape)
print(pred_ys[0])
- np.argmax() : 가장 큰 수가 있는 위치값 구하기
- arg_pred_y[0] : 예측한 레이블 값
- x_test[0] : 실제 숫자 이미지
arg_pred_y = np.argmax(pred_ys, axis=1)
plt.title(f'Predicted label: {arg_pred_y[0]}')
plt.imshow(x_test[0])
plt.show()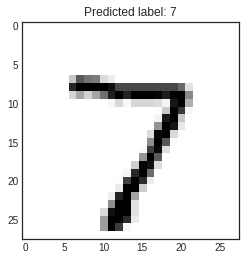
- classification_report를 이용한 지표 파악
from sklearn.metrics import classification_report
print(classification_report(np.argmax(y_test, axis=-1), np.argmax(pred_ys, axis=-1)))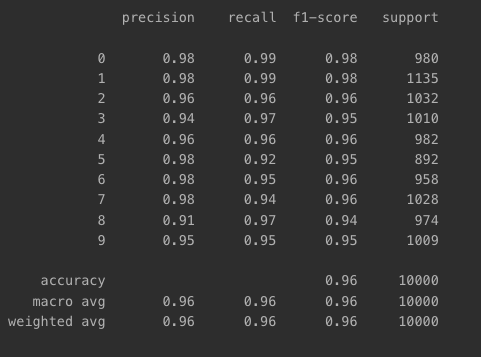
- Confusion Matrix 시각화
from sklearn.metrics import confusion_matrix
import seaborn as sns
sns.set(style='white')
plt.figure(figsize=(8, 8))
cm = confusion_matrix(np.argmax(y_test, axis=1), np.argmax(pred_ys, axis=-1))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.xlabel('Predicted Label')
plt.ylabel('True Label')
plt.show()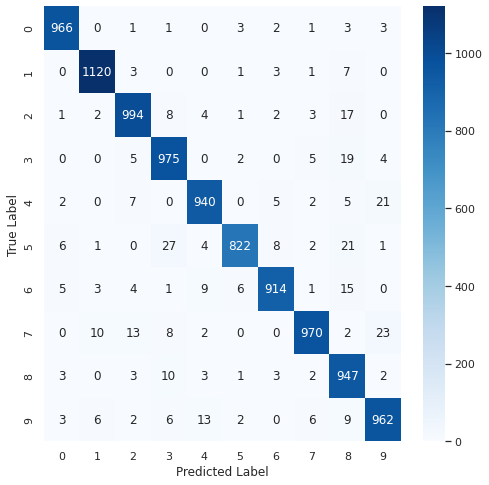
분석
- True Label 숫자 5가 -> 숫자 3과 가장 많이 혼동(27회)
- True Label 숫자 7이 -> 숫자 2와 가장 많이 혼동(13회)
- True Label 숫자 9가 -> 숫자 4와 가장 많이 혼동(13회)
7-3. 모델 저장과 로드
모델 저장 및 로드
- 모델 학습 후 저장을 하지 않으면 다시 처음부터 학습해야 하는 문제가 있음
save()함수로 저장load_model()함수로 불러오기
- 모델 저장 및 로드에서 중요한 점
- Sequencial API, Functional API 등을 사용한 경우 저장 및 로드 가능
- Subclassing API는 저장 및 로드 불가능
save_weights,load_weights()로 모델 파라미터만 저장 가능
- JSON 형식으로 모델 저장
to_json()으로 저장model_from_json()를 이용해 로드
- YAML로 직렬화해 저장
to_yaml()로 저장model_from_yaml()으로 로드
실습
모델 저장 : mnist_model.h5
model.save('mnist_model.h5')mnist_model.h5 모델 로드하여 가져오기
loaded_model = models.load_model('mnist_model.h5')
loaded_model.summary()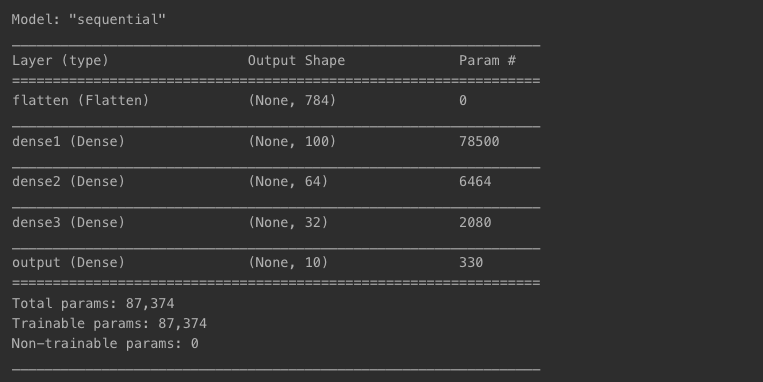
로드한 모델로 예측 가능
pred_ys2 = loaded_model.predict(x_test)
print(pred_ys2.shape)
print(pred_ys2[0])
로드한 모델이 예측한 결과값 시각화
import matplotlib.pyplot as plt
arg_pred_y2 = loaded_model.predict(x_test)
flattened_pred = arg_pred_y2.flatten()
plt.hist(flattened_pred, bins=30, color='blue', alpha=0.7, label='Predicted Values')
plt.title('Histogram of All Predicted Values')
plt.xlabel('Predicted Value')
plt.ylabel('Frequency')
plt.legend()
plt.show()
Q. to_json() 함수로 모델 저장 및 실행 결과 확인
- 결과가 다름

7-4. 콜백 (Callbacks)
콜백
- 모델을
fit()함수로 학습시키는 동안 ➡️callbacks매개변수로 학습 - 콜백 대표 예시 : ModelCheckpoint, EarlyStopping, LearningRateScheduler, Tensorboard
- 콜백 임포트
from tensorflow.keras import callbacksModelCheckpoint
- tf.keras.callbacks.ModelCheckpoint
- 모델 체크포인트 저장, 문제 발생 시 복구에 사용
check_point_cb = callbacks.ModelCheckpoint('keras_mnist_model.h5')
history = model.fit(x_train, y_train, epochs=10,
callbacks=[check_point_cb])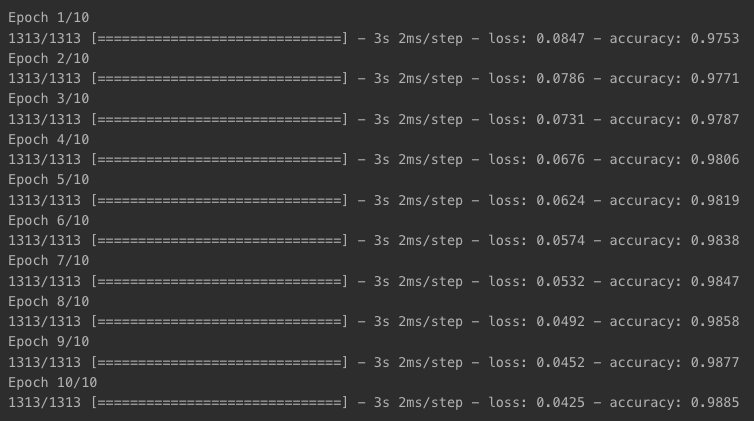
- save_best_only=True
- 최상 모델만 저장
check_point_cb = callbacks.ModelCheckpoint('keras_mnist_model.h5', save_best_only=True)
history = model.fit(x_train, y_train, epochs=10,
validation_data=(x_val, y_val),
callbacks=[check_point_cb])Epoch 1/10
1313/1313 [==============================] - 4s 3ms/step - loss: 0.0396 - accuracy: 0.9896 - val_loss: 0.1014 - val_accuracy: 0.9705
Epoch 2/10
1313/1313 [==============================] - 4s 3ms/step - loss: 0.0367 - accuracy: 0.9899 - val_loss: 0.1033 - val_accuracy: 0.9696
Epoch 3/10
1313/1313 [==============================] - 4s 3ms/step - loss: 0.0341 - accuracy: 0.9911 - val_loss: 0.1009 - val_accuracy: 0.9699
Epoch 4/10
1313/1313 [==============================] - 4s 3ms/step - loss: 0.0312 - accuracy: 0.9923 - val_loss: 0.0998 - val_accuracy: 0.9707
Epoch 5/10
1313/1313 [==============================] - 4s 3ms/step - loss: 0.0292 - accuracy: 0.9921 - val_loss: 0.0998 - val_accuracy: 0.9706
Epoch 6/10
1313/1313 [==============================] - 4s 3ms/step - loss: 0.0267 - accuracy: 0.9934 - val_loss: 0.1042 - val_accuracy: 0.9697
Epoch 7/10
1313/1313 [==============================] - 4s 3ms/step - loss: 0.0247 - accuracy: 0.9943 - val_loss: 0.1046 - val_accuracy: 0.9698
Epoch 8/10
1313/1313 [==============================] - 4s 3ms/step - loss: 0.0236 - accuracy: 0.9942 - val_loss: 0.1019 - val_accuracy: 0.9702
Epoch 9/10
1313/1313 [==============================] - 4s 3ms/step - loss: 0.0211 - accuracy: 0.9951 - val_loss: 0.1094 - val_accuracy: 0.9686
Epoch 10/10
1313/1313 [==============================] - 4s 3ms/step - loss: 0.0193 - accuracy: 0.9959 - val_loss: 0.1013 - val_accuracy: 0.9716EarlyStopping
- tf.keras.callbacks.EarlyStopping
- 성능이 개선을 멈추면 -> 학습을 바로 중단
- 일정 patience동안 검증 세트 점수가 오르지 않으면 학습 중단
- epochs 숫자가 커도 무방
- 학습이 끝난 후 최상 가중치를 복원 -> 모델 복원 과정 별도 필요 없음
check_point_cb = callbacks.ModelCheckpoint('keras_mnist_model.h5', save_best_only=True)
early_stopping_cb = callbacks.EarlyStopping(patience=3, monitor='val_loss',
restore_best_weights=True)
history = model.fit(x_train, y_train, epochs=10,
validation_data=(x_val, y_val),
callbacks=[check_point_cb, early_stopping_cb])Epoch 1/10
1313/1313 [==============================] - 4s 3ms/step - loss: 0.0176 - accuracy: 0.9963 - val_loss: 0.1029 - val_accuracy: 0.9717
Epoch 2/10
1313/1313 [==============================] - 4s 3ms/step - loss: 0.0166 - accuracy: 0.9968 - val_loss: 0.1049 - val_accuracy: 0.9713
Epoch 3/10
1313/1313 [==============================] - 4s 3ms/step - loss: 0.0154 - accuracy: 0.9971 - val_loss: 0.1029 - val_accuracy: 0.9711
Epoch 4/10
1313/1313 [==============================] - 4s 3ms/step - loss: 0.0138 - accuracy: 0.9974 - val_loss: 0.1018 - val_accuracy: 0.9716
Epoch 5/10
1313/1313 [==============================] - 3s 3ms/step - loss: 0.0125 - accuracy: 0.9978 - val_loss: 0.1018 - val_accuracy: 0.9723
Epoch 6/10
1313/1313 [==============================] - 3s 3ms/step - loss: 0.0118 - accuracy: 0.9982 - val_loss: 0.1077 - val_accuracy: 0.9702
Epoch 7/10
1313/1313 [==============================] - 4s 3ms/step - loss: 0.0112 - accuracy: 0.9981 - val_loss: 0.1058 - val_accuracy: 0.9717LearningRateScheduler
- tf.keras.callbacks.LearningRateSchduler
- 최적화 시의 학습률을 동적으로 변경
- 에폭 수가 10 미만일 때 -> 학습률 유지
- 에폭 수가 10 이상일 때 -> -0.1%씩 학습률 감소
def scheduler(epoch, learning_rate):
if epoch < 10:
return learning_rate
else:
return learning_rate * tf.math.exp(-0.1)round(model.optimizer.lr.numpy(), 5)
lr_scheduler_cb = callbacks.LearningRateScheduler(scheduler)
history = model.fit(x_train, y_train, epochs=15,
callbacks=[lr_scheduler_cb], verbose=0)
round(model.optimizer.lr.numpy(), 5)
Tensorboard
- tf.keras.callbacks.TensorBoard
- 모델 경과 모니터링
- logs 폴더를 만들어 학습 진행 시의 로그 파일 생성
log_dir = './logs'
tensor_board_cb = [callbacks.TensorBoard(log_dir=log_dir, histogram_freq=1, write_graph=True, write_images=True)]
model.fit(x_train, y_train, batch_size=32, validation_data=(x_val, y_val),
epochs=30, callbacks=tensor_board_cb)Epoch 1/30
1313/1313 [==============================] - 4s 3ms/step - loss: 0.0039 - accuracy: 0.9999 - val_loss: 0.1100 - val_accuracy: 0.9721
Epoch 2/30
1313/1313 [==============================] - 4s 3ms/step - loss: 0.0037 - accuracy: 0.9999 - val_loss: 0.1115 - val_accuracy: 0.9719
Epoch 3/30
1313/1313 [==============================] - 4s 3ms/step - loss: 0.0037 - accuracy: 0.9999 - val_loss: 0.1110 - val_accuracy: 0.9717
Epoch 4/30
1313/1313 [==============================] - 4s 3ms/step - loss: 0.0035 - accuracy: 1.0000 - val_loss: 0.1120 - val_accuracy: 0.9719
Epoch 5/30
1313/1313 [==============================] - 3s 3ms/step - loss: 0.0034 - accuracy: 0.9999 - val_loss: 0.1123 - val_accuracy: 0.9720
Epoch 6/30
1313/1313 [==============================] - 3s 3ms/step - loss: 0.0033 - accuracy: 1.0000 - val_loss: 0.1133 - val_accuracy: 0.9721
Epoch 7/30
1313/1313 [==============================] - 4s 3ms/step - loss: 0.0032 - accuracy: 1.0000 - val_loss: 0.1132 - val_accuracy: 0.9715
Epoch 8/30
1313/1313 [==============================] - 4s 3ms/step - loss: 0.0031 - accuracy: 1.0000 - val_loss: 0.1127 - val_accuracy: 0.9721
Epoch 9/30
1313/1313 [==============================] - 4s 3ms/step - loss: 0.0029 - accuracy: 1.0000 - val_loss: 0.1139 - val_accuracy: 0.9720
Epoch 10/30
1313/1313 [==============================] - 4s 3ms/step - loss: 0.0029 - accuracy: 1.0000 - val_loss: 0.1146 - val_accuracy: 0.9722
Epoch 11/30
1313/1313 [==============================] - 4s 3ms/step - loss: 0.0028 - accuracy: 1.0000 - val_loss: 0.1140 - val_accuracy: 0.9718
Epoch 12/30
1313/1313 [==============================] - 4s 3ms/step - loss: 0.0027 - accuracy: 1.0000 - val_loss: 0.1141 - val_accuracy: 0.9724
Epoch 13/30
1313/1313 [==============================] - 4s 3ms/step - loss: 0.0026 - accuracy: 1.0000 - val_loss: 0.1148 - val_accuracy: 0.9718
Epoch 14/30
1313/1313 [==============================] - 4s 3ms/step - loss: 0.0026 - accuracy: 1.0000 - val_loss: 0.1156 - val_accuracy: 0.9721
Epoch 15/30
1313/1313 [==============================] - 4s 3ms/step - loss: 0.0025 - accuracy: 1.0000 - val_loss: 0.1153 - val_accuracy: 0.9718
Epoch 16/30
1313/1313 [==============================] - 4s 3ms/step - loss: 0.0024 - accuracy: 1.0000 - val_loss: 0.1160 - val_accuracy: 0.9721
Epoch 17/30
1313/1313 [==============================] - 4s 3ms/step - loss: 0.0024 - accuracy: 1.0000 - val_loss: 0.1160 - val_accuracy: 0.9722
Epoch 18/30
1313/1313 [==============================] - 4s 3ms/step - loss: 0.0023 - accuracy: 1.0000 - val_loss: 0.1163 - val_accuracy: 0.9723
Epoch 19/30
1313/1313 [==============================] - 4s 3ms/step - loss: 0.0023 - accuracy: 1.0000 - val_loss: 0.1188 - val_accuracy: 0.9721
Epoch 20/30
1313/1313 [==============================] - 4s 3ms/step - loss: 0.0022 - accuracy: 1.0000 - val_loss: 0.1174 - val_accuracy: 0.9723
Epoch 21/30
1313/1313 [==============================] - 4s 3ms/step - loss: 0.0022 - accuracy: 1.0000 - val_loss: 0.1166 - val_accuracy: 0.9724
Epoch 22/30
1313/1313 [==============================] - 4s 3ms/step - loss: 0.0021 - accuracy: 1.0000 - val_loss: 0.1178 - val_accuracy: 0.9722
Epoch 23/30
1313/1313 [==============================] - 4s 3ms/step - loss: 0.0021 - accuracy: 1.0000 - val_loss: 0.1180 - val_accuracy: 0.9719
Epoch 24/30
1313/1313 [==============================] - 4s 3ms/step - loss: 0.0020 - accuracy: 1.0000 - val_loss: 0.1182 - val_accuracy: 0.9723
Epoch 25/30
1313/1313 [==============================] - 4s 3ms/step - loss: 0.0020 - accuracy: 1.0000 - val_loss: 0.1181 - val_accuracy: 0.9719
Epoch 26/30
1313/1313 [==============================] - 4s 3ms/step - loss: 0.0019 - accuracy: 1.0000 - val_loss: 0.1185 - val_accuracy: 0.9722
Epoch 27/30
1313/1313 [==============================] - 4s 3ms/step - loss: 0.0019 - accuracy: 1.0000 - val_loss: 0.1188 - val_accuracy: 0.9724
Epoch 28/30
1313/1313 [==============================] - 4s 3ms/step - loss: 0.0018 - accuracy: 1.0000 - val_loss: 0.1190 - val_accuracy: 0.9721
Epoch 29/30
1313/1313 [==============================] - 4s 3ms/step - loss: 0.0018 - accuracy: 1.0000 - val_loss: 0.1194 - val_accuracy: 0.9722
Epoch 30/30
1313/1313 [==============================] - 4s 3ms/step - loss: 0.0018 - accuracy: 1.0000 - val_loss: 0.1202 - val_accuracy: 0.9723
- LMS에서는 나타나지 않음
%load_ext tensorboard
%tensorboard --logdir {log_dir}
Colab 코드 작성 : Node07-모델저장과-콜백.ipynb
7-5. 마무리하며
Q. Keras에서의 모델 저장 파일 형식
- .h5 : model.save('model.h5')
# 모델 저장
model.save('model.h5')
# 모델 로드
from tensorflow.keras.models import load_model
loaded_model = load_model('model.h5')- JSON : model.to_json()
from keras.models import model_from_json
# 모델 구조를 JSON 형식으로 저장
model_json = model.to_json()
with open("model.json", "w") as json_file:
json_file.write(model_json)- YAML : model.to_yaml()
from keras.models import model_from_yaml
# 모델 구조를 YAML 형식으로 저장
model_yaml = model.to_yaml()
with open("model.yaml", "w") as yaml_file:
yaml_file.write(model_yaml)- 기존에 사용했던 mnist의 데이터들을 활용 -> 모델에 checkpoint를 만들고, Earlystopping 설정
# 체크포인트 설정
check_point_cb = callbacks.ModelCheckpoint(
filepath='best_model.keras',
monitor='val_loss',
save_best_only=True,
save_weights_only=False,
verbose=1
)
# EarlyStopping 설정
early_stopping_cb = callbacks.EarlyStopping(
monitor='val_loss',
patience=3,
restore_best_weights=True,
verbose=1
)
history = model.fit(
x_train, y_train,
epochs=10,
validation_data=(x_val, y_val),
callbacks=[check_point_cb, early_stopping_cb]
)Epoch 1/10
1313/1313 [==============================] - 4s 3ms/step - loss: 0.0017 - accuracy: 1.0000 - val_loss: 0.1200 - val_accuracy: 0.9723
Epoch 00001: val_loss improved from inf to 0.11998, saving model to best_model.keras
Epoch 2/10
1313/1313 [==============================] - 4s 3ms/step - loss: 0.0017 - accuracy: 1.0000 - val_loss: 0.1206 - val_accuracy: 0.9720
Epoch 00002: val_loss did not improve from 0.11998
Epoch 3/10
1313/1313 [==============================] - 4s 3ms/step - loss: 0.0017 - accuracy: 1.0000 - val_loss: 0.1204 - val_accuracy: 0.9723
Epoch 00003: val_loss did not improve from 0.11998
Epoch 4/10
1313/1313 [==============================] - 4s 3ms/step - loss: 0.0016 - accuracy: 1.0000 - val_loss: 0.1211 - val_accuracy: 0.9724
Epoch 00004: val_loss did not improve from 0.11998
Restoring model weights from the end of the best epoch.
Epoch 00004: early stopping
언젠가 내 코드로 세상에 기여할 수 있도록, Data Science&BE 개발 기록 노트☘️