[MiniProject] Node 05. 시계열 분류
AIFFELBaggingBoostingLog functionRandomforestXGBoostensemblefeature importancekurtosisnormal distributionskewness데싸데싸 3기데이터 사이언스데이터 사이언티스트데이터 사이언티스트 3기로그 함수배깅부스팅시계열 분류아이펠앙상블왜도정규 분포첨도특성 중요도
☺️ AIFFEL 데이터사이언티스트 3기
목록 보기
65/115

Code
🔗 github.com/hayannn/AIFFEL_MAIN_QUEST/MiniProject3
프로젝트 목표
Objective 1
- 비정상 데이터를 정상 데이터로 만들기
Objective 2
- 분류 모델의 성능 높이기
순서 정리
- 비정상 데이터를 정상 데이터로 만들기
- 분산을 일정하게(로그 변환, log transformation)
- 차분으로 추세 제거
- 계절 차분으로 계절성 제거
- 검정: 정상성 확인
- 시계열 분류 진행
- 데이터 전처리(다운로드, 가공, 나누기)
- Feature extraction
- impute
- 모델 적용: RandomForest,XGBoost -> score로 평가
- 추가) Logistic Regression
- 시각화: XGBoost plot_importance
- Classification report(검증 및 분석)
비정상 데이터를 정상 데이터로 만들기
라이브러리, 데이터셋 불러오기 및 확인
- 라이브러리 불러오기
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np- 데이터셋 불러오기 & 확인
ap = pd.read_csv('/content/drive/MyDrive/시계열/AirPassengers.csv')
ap.head()
컬럼 삭제
Month컬럼 삭제
ap.drop('Month', axis=1, inplace=True)
ap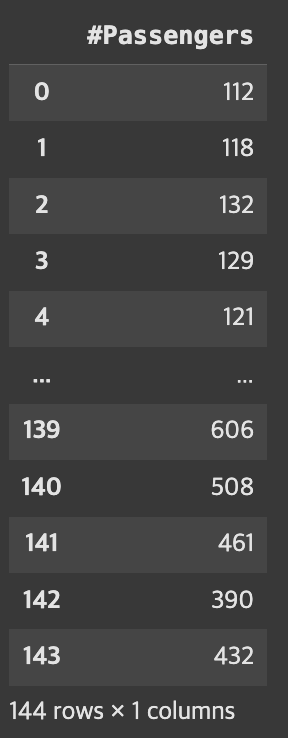
원본 데이터 시각화
- 상승 추세
- 분산 폭이 큰 상태
plt.figure()
plt.plot(ap)
plt.show()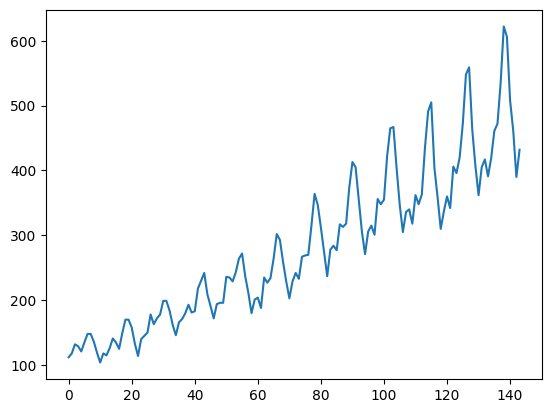
분산을 일정하게(로그 변환, log transformation)
로그 변환
log_transformed = np.log(ap)
log_transformed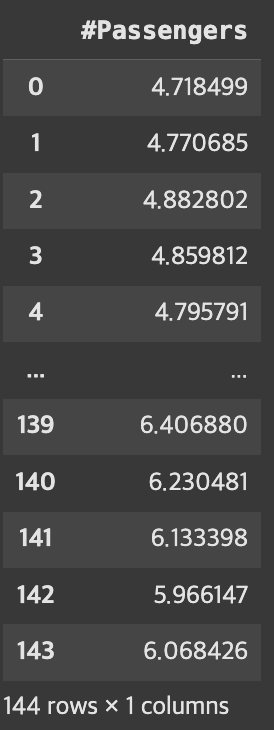
로그 변환 후 데이터 시각화
- 분산이 일정해진 상태
- 뾰족하게 올라온 정도가 이전 그래프에 비해 일정해짐
plt.figure()
plt.plot(log_transformed)
plt.show()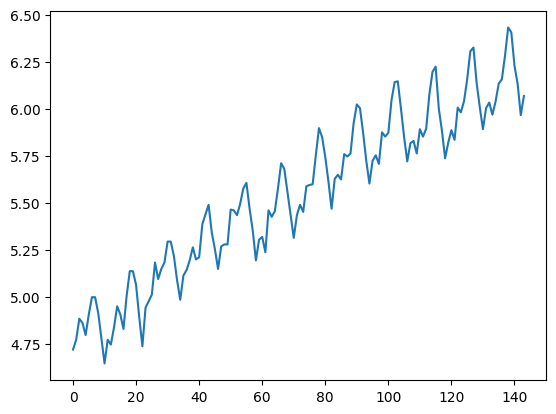
차분으로 추세 제거
diff 함수 사용
- 차분 사용 시, 데이터 길이 자체가 짧아져 데이터를 잘라 사용해야함
diffed = log_transformed.diff()[1:]
diffed
차분 후 데이터 시각화
- 분산이 커지는 것과 더불어 상승 추세까지 모두 제거되었는지 시각화해 확인
- 평균은 0, 분산이 더 커지지 않는 형태로 정리됨
plt.figure()
plt.plot(diffed)
plt.show()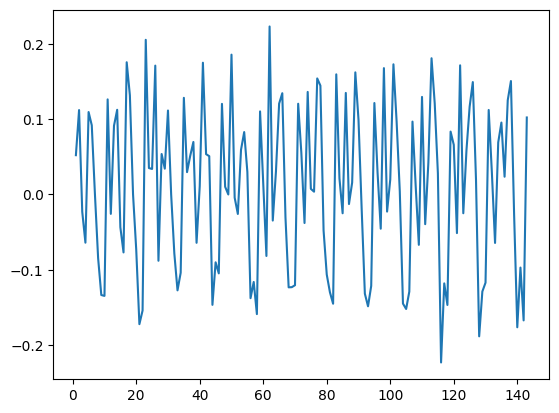
계절 차분으로 계절성 제거
사용하는 데이터셋
- AirPassengers
- 12개월(1년) 주기 -> 계절성 포함
- 계절 차분을 통해 계절성 제거 필요
계절 차분 적용
- diff에 12 적용
- 주기를 12하는 계절 차분을 의미
- 이 역시, 차분할 경우 데이터 길이가 짧아지니 NaN 값 제거 필수
seasonally_diffed = diffed.diff(12)
seasonally_diffed.dropna(inplace = True)
seasonally_diffed
계절 차분 적용 후 데이터 시각화
- 분산이 일정한지 그렇지 않은지 + 스테이블한지 아닌지에 대해 애매한 지점이 있음
- 검정으로 확인 필요
plt.figure()
plt.plot(seasonally_diffed)
plt.show()
검정: 정상성 확인
adfuller
- statsmodels 모듈의 ADF Test 도구
관찰값
adf- 단위근 검정
p-value- 유의 검정
- 관찰 데이터가 귀무가설이 맞을 경우 -> 통계값 1이 실제 관측 값 이상일 확률을 구함
usedlag- 시차 수(사용된 경우를 뜻함)
nobs- ADF 회귀, 임계값 계산에 사용된 관측치 수
- critical values
임계값- 1%, 5%, 10% 수준
icbest- lag 길이 자동 결정: autolag
- autolag를 none으로 지정하지❌ -> 최대화된 정보를 기준으로 함
ADF 검정 통계량, P-value 2가지만 확인
- 판별 기준
- ADF statistics 절댓값 기준 : 크면 클수록 귀무가설 기각 확률 높아짐
- P-value : 귀무가설 기각 확률(0.05보다 작으면 귀무가설 기각, 시계열은 정상적이라고 판단)
from statsmodels.tsa.stattools import adfuller
def adf_test(x):
stat, p_value, lags, nobs, crit, icb = adfuller(x)
print('ADF statistics')
print(stat)
print('P-value')
print(p_value)
adf_test(seasonally_diffed)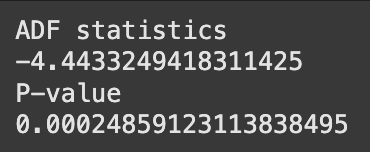
결론
- 귀무가설(단위근이 존재한다, 시계열 데이터가 비정상성을 가진다)을 기각
- 즉, 시계열 데이터는 정상성을 가진다라고 결론(대립가설 채택)
시계열 분류 진행
데이터 전처리(다운로드, 가공, 나누기)
데이터 다운로드 및 확인
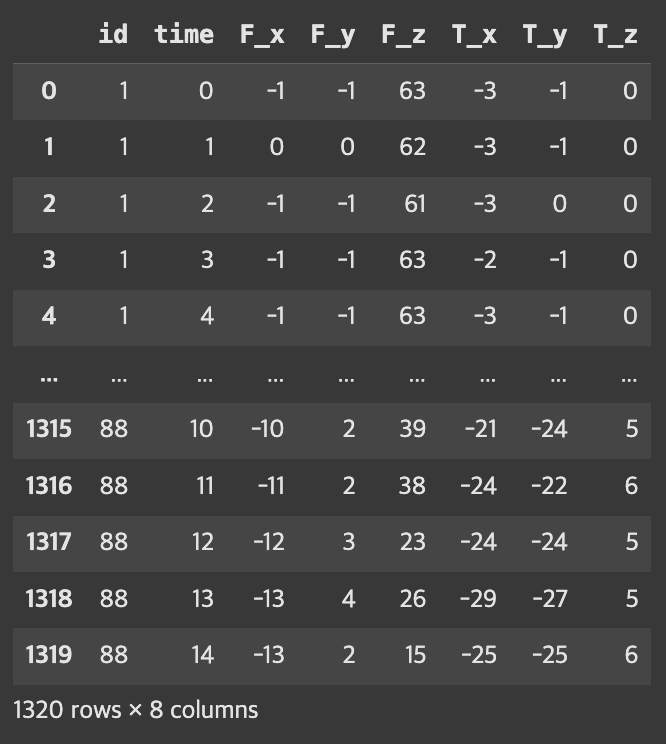
- id 및 time 제외 6개 컬럼 X 변수 확인
from tsfresh.examples.robot_execution_failures import download_robot_execution_failures, load_robot_execution_failures
download_robot_execution_failures()
timeseries, y = load_robot_execution_failures()-
timeseries
-
y
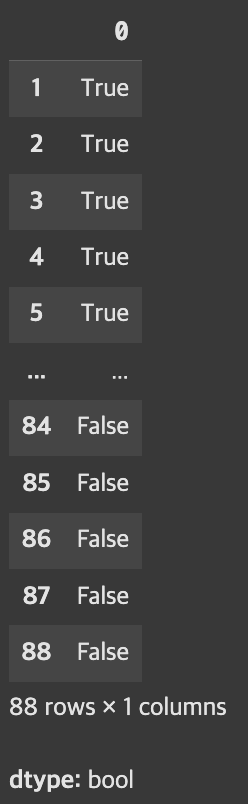
데이터셋 가공
def custom_classification_split(x,y,test_size=0.3):
num_true = int(y.sum()*test_size)
num_false = int((len(y)-y.sum())*test_size)
id_list = y[y==False].head(num_false).index.to_list() + y[y==True].head(num_true).index.to_list()
y_train = y.drop(id_list)
y_test = y.iloc[id_list].sort_index()
X_train = timeseries[~timeseries['id'].isin(id_list)]
X_test = timeseries[timeseries['id'].isin(id_list)]
return X_train, y_train, X_test, y_test데이터셋 나누기
- 테스트 데이터셋 비율을 0.25로 저장
X_train, y_train, X_test, y_test = custom_classification_split(timeseries, y, test_size=0.25)- EfficientParameters 사용
- 계산 비용이 높은 calculator 제외해 생성
from tsfresh import extract_features
from tsfresh.feature_extraction import EfficientFCParameters
from tsfresh.utilities.dataframe_functions import impute
settings = EfficientFCParameters()Feature extraction
train 데이터
comprehensive_features_train = extract_features(
X_train,
column_id="id",
column_sort="time",
default_fc_parameters=settings
)
test 데이터
comprehensive_features_test = extract_features(
X_test,
column_id="id",
column_sort="time",
default_fc_parameters=settings
)
impute
impute 사용
- 이 라이브러리로 간단히 데이터 전처리 진행
# train 데이터
impute(comprehensive_features_train)
# test 데이터
impute(comprehensive_features_test)

모델 적용: RandomForest, XGBoost -> score로 평가
RandomForest
from sklearn.ensemble import RandomForestClassifier
rf_clf = RandomForestClassifier(n_estimators = 10, max_depth = 3)
rf_clf.fit(comprehensive_features_train, y_train)
- 성능 확인
- 코랩에서는 강의에서와 달리 0.85정도로 추출됨(랜덤포레스트 버전 차이)
rf_clf.score(comprehensive_features_test, y_test)
XGB
import xgboost as xgb
xgb_clf = xgb.XGBClassifier(n_estimators = 10, max_depth = 3)
xgb_clf.fit(comprehensive_features_train, y_train)
- 성능 확인
- 1.0(100%로 분류 문제가 해결되었음을 의미)
xgb_clf.score(comprehensive_features_test, y_test)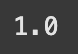
추가) Logistic Regression
학습 & 성능 확인
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
log_reg_clf = LogisticRegression(max_iter=1000)
log_reg_clf.fit(comprehensive_features_train, y_train)
log_reg_clf.score(comprehensive_features_test, y_test)
시각화: XGBoost plot_importance
- 어떤 피쳐가 가장 유의미한지 확인
xgb.plot_importance(xgb_clf, importance_type = 'gain')
plt.show()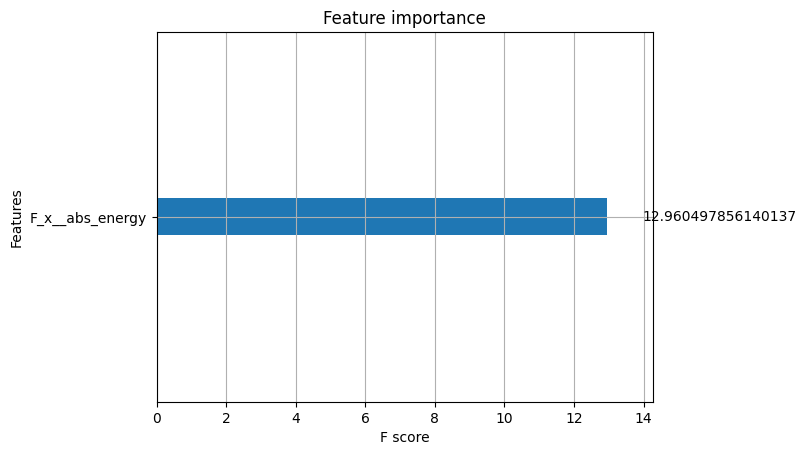
- 수치로도 확인
sum(xgb_clf.feature_importances_ != 0)
Classification report(검증 및 분석)
고장 유무 판별 기준
- 위의 결과에 따라서
F_X_abs_energyfeature임을 알 수 있음
Classification report
from sklearn.metrics import classification_report
classification_report(y_test, xgb_clf.predict(comprehensive_features_test), target_names = ['true', 'false'], output_dict = True)
결과 해석
-
Precision
- 정밀도: 모델이 양성 예측한 것 중에서 실제 양성 비율을 측정
- True, False 모두 1.0
- 모든 예측이 정확하게 맞았다는 것을 의미
-
Recall
- 재현율 : 실제 양성 데이터 중 모데링 양성으로 예측한 비율을 측정
- True, False 모두 1.0
- 모든 실제 데이터가 정확히 분류되었음을 의미
-
F1-Score
- 정밀도 및 재현율읠 균형 측정
- True, False 모두 1.0
- 정밀도, 재현율 모두가 완벽하게 이루어져 이 역시 완벽하게 나옴
-
Accuracy
- 정확도
- 이 역시 1.0이 나왔음 -> 모든 데이터가 정확하게 잘 분류됨
-
support
- True : 총 16개 데이터
- False : 총 5개 데이터
- 모든 예측에 성공
-
Macro Avg
- 성능 지표 평균
- 1.0으로 추출됨
-
Weighted Avg
- 가중치 평균
- 1.0으로 추출됨
회고
-
시계열 데이터
- 비정상 데이터로 정의하는 이유 : 상승 추세, 분산이 일정하지 않고 큼
- 비정상 데이터를 정상 데이터로 가공 후 시각화 : 직관적으로는 그래프가 더 복잡해져 분석에 어려움을 겪음
- 분산이 일정한 것인지, 스테이블한 형태인건지는 아직 그래프만 보고 판단하기 어려웠음
-
정상성 확인
- adf 테스트를 수행하여 귀무가설이 채택될 것인지 대립가설이 채택될 것인지에 대한 수치적 확인을 통해 이해
-
모델 적용부터는 크게 어려운 내용은 없었음

언젠가 내 코드로 세상에 기여할 수 있도록, Data Science&BE 개발 기록 노트☘️