
4-1. 들어가며
학습 목표
- 시계열 데이터 특징 파악하기
- tsfresh 라이브러리 파악 & feature 추출하기
Tsfresh 라이브러리
- 시계열 데이터 feature 추출 및 검증에 사용
- target 예측 & 분류에 강함
- 병렬 연산, 사이킷런 호환 가능
4-2. 시계열 데이터의 특징
용어 정리
- Maximum(최댓값)
- 한 집합 내 가장 큰 값
- Minimum(최솟값)
- 한 집합 내 가장 작은 값
- Local minimum(국소적 최소)
- 함수값이 인근에서는 가장 작음
- 멀리 있는 수와 비교할 경우에는 최소가 아닐 수도 있는 지점
- Smoothness(평활 정도)
- 무작위적 변화를 줄이기 위한 기법
- ex) 주어진 시계열 자료에 평균값을 취하는 것
- Time series cycle(시계열 주기성)
- 시계열의 증가 및 감소 패턴이 반복적이나, 빈도 고정이 되지 않은 경우 -> 시계열에 주기가 있다고 표현
- Linear(선형성)
- 어떤 함수가 진행하는 모양이 -> '직선'적이라는 의미
- Non-linear(비선형성)
- 독립변수와 종속변수 사이 직선 혹은 직접 관게가 없는 상황
- feature extraction(특징 추출)
- 원본 특징 조합으로 -> 새로운 특징 추출
- 그룹화 및 정렬 기준에 따라 추출 가능
시계열 요약 통계 특징
- 평균, 분산
- 최댓값, 최솟값
- 시작값, 마지막 값 차이
- 국소적 최소 및 최대 개수
- 시계열 평활 정도
- 시계열 주기성, 자기상관
tsfresh 라이브러리(시계열 feature 자동 추출)
- 63개 시계열 추출 방법론으로 -> 794개 특징 포착 가능
- 1200개 이상의 특징 지원중
사용법
- tsfresh 라이브러리 설치
!pip install tsfresh- 런타임 재시작
import os
os.kill(os.getpid(), 9)- 데이터셋 불러오기
robot execution
from tsfresh.examples.robot_execution_failures import download_robot_execution_failures, load_robot_execution_failures
download_robot_execution_failures()- 불러온 데이터 확인
timeseries: 데이터 피쳐 값(독립 변수)
timeseries, y = load_robot_execution_failures()
timeseries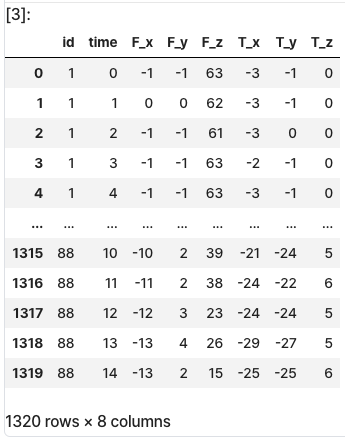
y: 종속변수
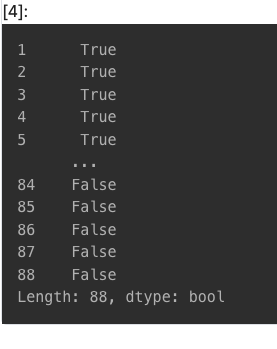
- 특징 추출
- id별로 time 정보를 순서 정렬하여 추출
from tsfresh import extract_features
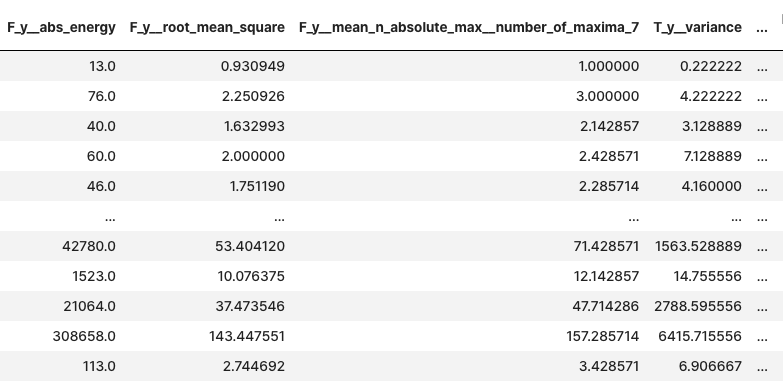
extracted_features = extract_features(timeseries, column_id="id", column_sort="time")
extracted_features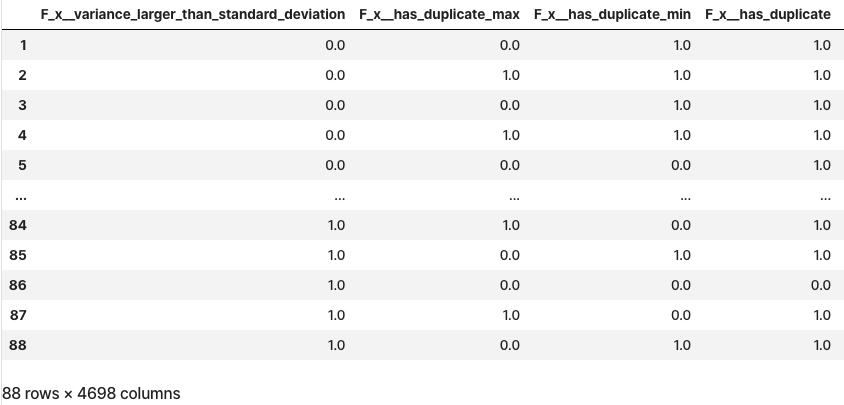

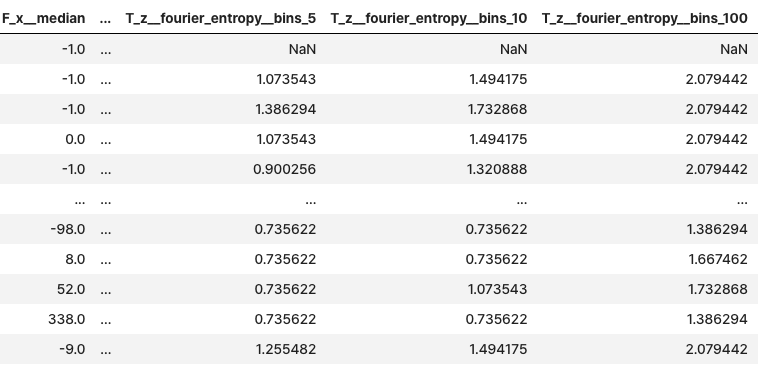
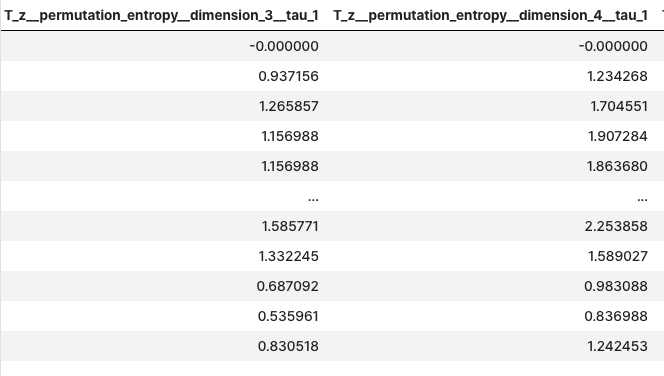

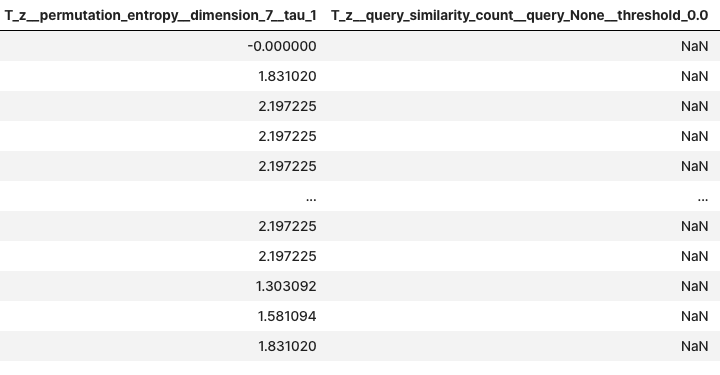
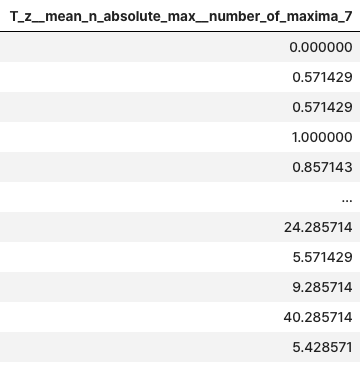
- impute
- 피쳐 추출된 값 -> 동일한 열 중앙값 및 극단값으로 변경
-inf->min+inf->maxNaN->median
- 피쳐 추출된 값 -> 동일한 열 중앙값 및 극단값으로 변경
- 필터링
select_features(X, y)- 관련 특징만 포함하도록 축소
from tsfresh import select_features
from tsfresh.utilities.dataframe_functions import impute
# impute
impute(extracted_features)
# select_features(X, y)
features_filtered = select_features(extracted_features, y)features_filtered
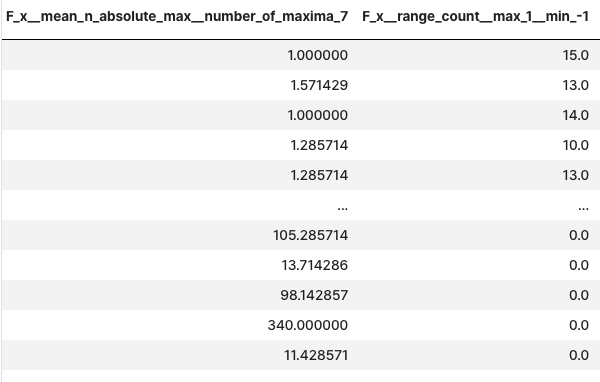
4-3. 시계열 데이터 분류
용어 정리
-
Sum of Squares for Error(오차제곱합)
- 딥러닝 손실 함수 중 하나
- 모델 성능이 얼마나 나쁜지 확인하는 지표로 분류됨
- 정답과 예측값 차이를 제곱 -> 총합 구한 값
- SSE
-
Accuracy(정확도)
- 전체 데이터 중, 정확히 예측한 데이터 수
- 불균형 데이터의 경우 -> 적합 지표가 아님!
-
Precision(정밀도)
- 양성 판단값 중 진짜 양성 비율
-
Recall(재현율)
- 진짜 양성 중 올바르게 양성 판별한 비율
- 양성 결과 예측이 정확한지를 따지는 지표
-
F1-score(조화 평균)
- 불균형 분류 문제에서의 평가 척도
- 편향을 줄인 상태로 평가하기 좋음
실습
데이터셋 불러오기
robot_execution_failures데이터셋 사용
from tsfresh.examples.robot_execution_failures import download_robot_execution_failures, load_robot_execution_failures
download_robot_execution_failures()
timeseries, y = load_robot_execution_failures()추가 라이브러리 import
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report데이터셋 가공
-
클래스별 테스트 데이터 개수 계산
y.sum(): True 값 개수 반환(양성 클래스 총 개수)len(y) - y.sum(): False 값 개수 반환(음성 클래스 총 개수)
-
테스트 데이터 인덱스 선택
- False 클래스 중
num_false만큼의 상위 데이터 선택 - 그 인덱스를 리스트로 변환
- True도 동일하게 처리
- False 클래스 중
def custom_classification_split(x, y, test_size=0.3):
# 클래스별 테스트 데이터 개수 계산
num_true = int(y.sum()*test_size) # int(21 * 0.3) = 6
num_false = int((len(y)-y.sum())*test_size) # int((88 - 21)*0.3) = 20
# 테스트 데이터 인덱스 선택
id_list = y[y==False].head(num_false).index.to_list() + y[y==True].head(num_true).index.to_list()
y_train = y.drop(id_list)
y_test = y.iloc[id_list].sort_index()
X_train = x[~x['id'].isin(id_list)]
X_test = x[x['id'].isin(id_list)]
return X_train, y_train, X_test, y_test데이터셋에 어떠한 차이가 있는지 확인하기
X_train, y_train, X_test, y_test = custom_classification_split(timeseries, y)
print(X_train)
print('-'*50)
print(y_train)
print('-'*50)
print(X_test)
print('-'*50)
print(y_test)- X_train
- 원본 데이터셋
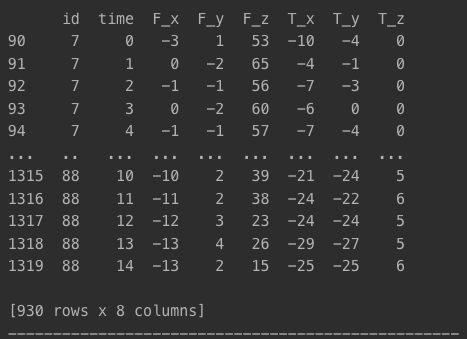
- 원본 데이터셋
- y_train
- 원본 데이터셋
- y_test와 True, False 값 자치의 비율은 동일하게 유지되고 있음
- X_test
- 테스트 데이터로 선택된 id의 데이터만 포함
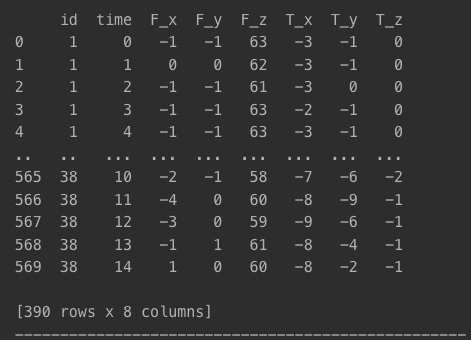
- 테스트 데이터로 선택된 id의 데이터만 포함
- y_test
- id_list에 포함된 id값 레이블만 포함
- 비율 조정됨

feature 추출
MinimalFCParameters- feature를 최소로 설정해 계산 수행(데이터셋이 크기 때문)
from tsfresh import extract_features
from tsfresh.feature_extraction import MinimalFCParameters
settings = MinimalFCParameters()
minimal_features_train = extract_features(
X_train,
column_id="id",
column_sort="time",
default_fc_parameters=settings
)
minimal_features_test = extract_features(
X_test,
column_id="id",
column_sort="time",
default_fc_parameters=settings
)
추출된 feature 확인
- minimal_features_train

- minimal_features_train.columns

feature 시각화
- F_x__sum_values
- 원본 시계열 데이터의 F_x 값에 대한 합계 결과
plt.plot(minimal_features_train['F_x__sum_values'])
plt.show()
➡️ 앞 부분은 잘 유지되나, x=60 이후부터 값 변동이 심하기 때문에, 이 부분부터 데이터 노이즈가 있음을 알 수 있음
- T_z__maximum
- T_z의 최댓값
plt.plot(minimal_features_train['T_z__maximum'])
plt.show()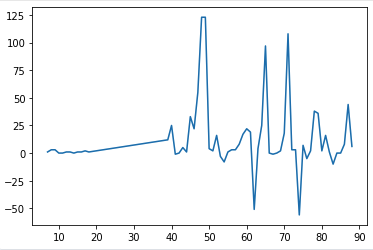
➡️ 위와 비슷한 형태, 극단값에 해당되어서 이런 형태가 나타나는 건지?
Logistic Regression
- 이진 분류 문제에 사용
- x >= 0.5 -> 1
- x < 0.5 -> 0
Logistic Regression 사용
logistic = LogisticRegression()
logistic.fit(minimal_features_train, y_train)Logistic Regression 스코어 확인
- 약 69%
logistic.score(minimal_features_test, y_test)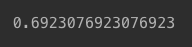
성능 평가 지표 확인
macro avg: 매크로 평균(평균의 평균), 각 클래스별 평균 / 클래스- *클래스: minimal_feature_train feature를 의미
- 현재 feature 개수 : 60개
weighted avg: 가중 산술 평균(가중치 부여하여 구한 평균)
classification_report(y_test, logistic.predict(minimal_features_test), target_names=['true', 'false'], output_dict=True)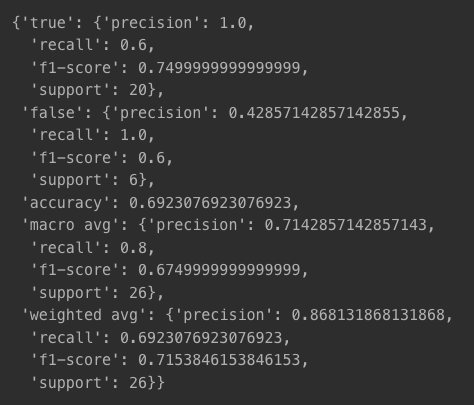
해석
Precision
- false에 대해서는 잘못된 결과를 내는 경우가 많음(False 예측값 중 실제 Falserk 42.8%)
Recall
- True의 재현율이 다소 낮음
F1-Score
- False는 좋지 않은 성능
Accuracy
- 정확도는 70% 수준(중간 정도)
Macro Avg
- 클래스 간 불균형이 고려되지 않아서 좋지 못함
Weighted Avg
- 클래스 불균형을 반영한 값이라, 조금 더 나은 값을 보임

언젠가 내 코드로 세상에 기여할 수 있도록, Data Science&BE 개발 기록 노트☘️