
9-1. 들어가며
- 학습목표
- 윈도우 함수를 통한 데이터 분석 능력 키우기
- 그룹 함수를 통해 빠른 자료 정리하기
- JSON 데이터 처리하기
9-2. 윈도우 함수(1): 함수 구조와 순위 함수
윈도우 함수란? 함수 구조 살펴보기
- 함수 구조 :
OVER구문 필수 사용!ARGUMENTS: 윈도우 함수에 따라 필요한 인수PARTITION BY: 전체 집합에 대해 소그룹을 나누는 기준ORDER BY: 소그룹 정렬 기준WINDOWING: 행 범위 기준
SELECT 컬럼명,
WINDOW_FUNCTION(ARGUMENTS) OVER ([PARTITION BY 컬럼] [ORDER BY 절] [WINDOWING 절])
FROM 테이블 명;순위 함수: RANK, DENSE_RANK, ROW_NUMBER
- 함수 구조 : 인수를 별도로 넣지 않음!
RANK(): 동일한 값에 동일 순위DENSE_RANK(): 동일한 값에 동일 순위, 단! 한 건으로 취급ROW_NUMBER(): 동일한 값이어도 고유 순위 부여(PK 오름차순)
1등 1명, 2등 2명이 존재한다면?
RANK(): 다음 순위는 4DENSE_RANK(): 다음 순위는 3ROW_NUMBER(): 중복 순위 없이 고유 순위로 나옴!
실습
- 데이터 생성
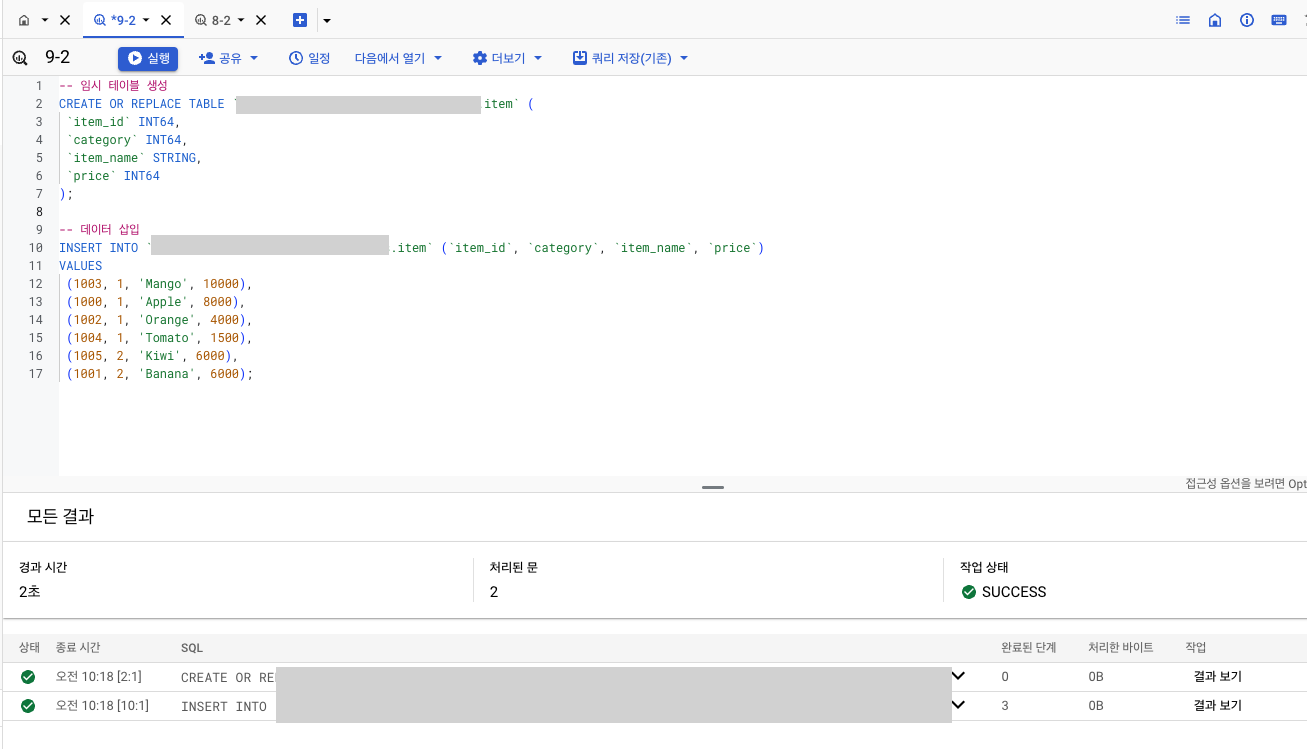
-
쿼리문

-
결과
-
기준 : price
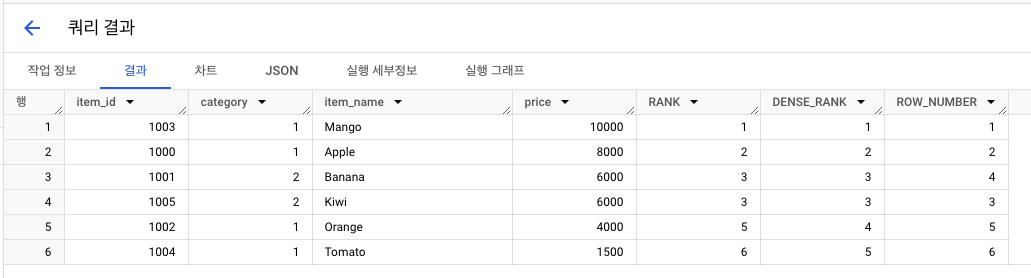
-
소그룹 :category, 기준 : price
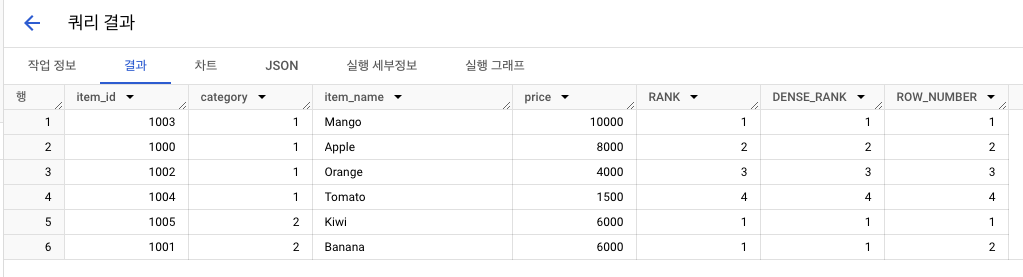
-
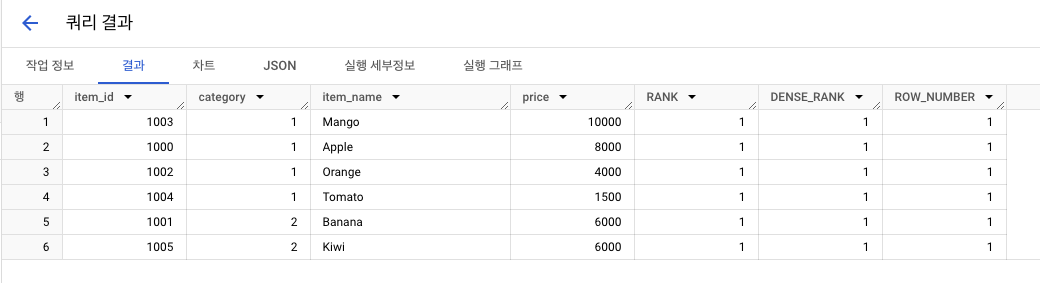
소그룹 : item_id, 기준 : price
9-3. 윈도우 함수(2): 집계 함수
9-3. 윈도우 함수(2): 집계 함수
- 함수 구조 : 일반 집계 함수의 경우 반드시 인수를 넣어야 함!
SUM(컬럼): 컬럼 기준 합계AVG(컬럼): 컬럼 기준 평균MAX(컬럼): 컬럼 기준 최댓값MIN(컬럼): 컬럼 기준 최솟값
SELECT 컬럼명,
집계 함수(컬럼) OVER ([PARTITION BY 절] [ORDER BY 절] [WINDOWING 절])
FROM 테이블명- 일반 집계 함수 사용
SELECT
그룹,
SUM(가격) AS 합계,
AVG(가격) AS 평균,
MAX(가격) AS 최대,
MIN(가격) AS 최소
FROM ITEM A
GROUP BY 그룹- 윈도우 함수의 집계 함수 사용
SELECT
상품ID, 상품명, 가격, 그룹,
SUM(가격) OVER (PARTITION BY 그룹) 합계,
AVG(가격) OVER (PARTITION BY 그룹) 평균,
MAX(가격) OVER (PARTITION BY 그룹) 최대,
MIN(가격) OVER (PARTITION BY 그룹) 최소,
FROM ITEM;🚨 집계함수를 쓰면 Subquery를 사용하는 것보다 쿼리문 길이를 많이 줄일 수 있다!
예시
- 판매 분석
SELECT *,
SUM(판매량) OVER (PARTITION BY 상품ID) 1Q_판매량_합계,
AVG(판매량) OVER (PARTITION BY 상품ID) 1Q_판매량_평균,
FROM 판매
WHERE 기준월 BETWEEN 2024-01 AND 2024-03| 상품ID | 기준월 | 판매량 | 1Q판매량합계 | 1Q판매량평균 |
|---|---|---|---|---|
| 1001 | 2024-01 | 100 | 360 | 120 |
| 1001 | 2024-02 | 120 | 360 | 120 |
| 1001 | 2024-03 | 140 | 360 | 120 |
| 1002 | 2024-01 | 120 | 390 | 130 |
| 1002 | 2024-02 | 130 | 390 | 130 |
| 1002 | 2024-03 | 140 | 390 | 130 |
- 웹사이트 트래픽 분석
SELECT *,
MAX(방문자수) OVER (PARTITION BY 기준연월) 월_최대_방문자수,
AVG(방문자수) OVER (PARTITION BY 기준연월) _평균_방문자수,
FROM 트래픽| 기준연월 | 기준연월일 | 방문자수 | 월최대방문자수 | 월평균방문자수 |
|---|---|---|---|---|
| 2024-01 | 2024-01-01 | 100 | 140 | 125 |
| 2024-01 | 2024-01-02 | 120 | 140 | 125 |
| 2024-01 | 2024-01-03 | 140 | 140 | 125 |
| 2024-01 | 2024-01-04 | 120 | 140 | 125 |
| 2024-01 | 2024-01-05 | 130 | 140 | 125 |
| 2024-01 | 2024-01-06 | 140 | 140 | 125 |
실습
- 데이터 생성
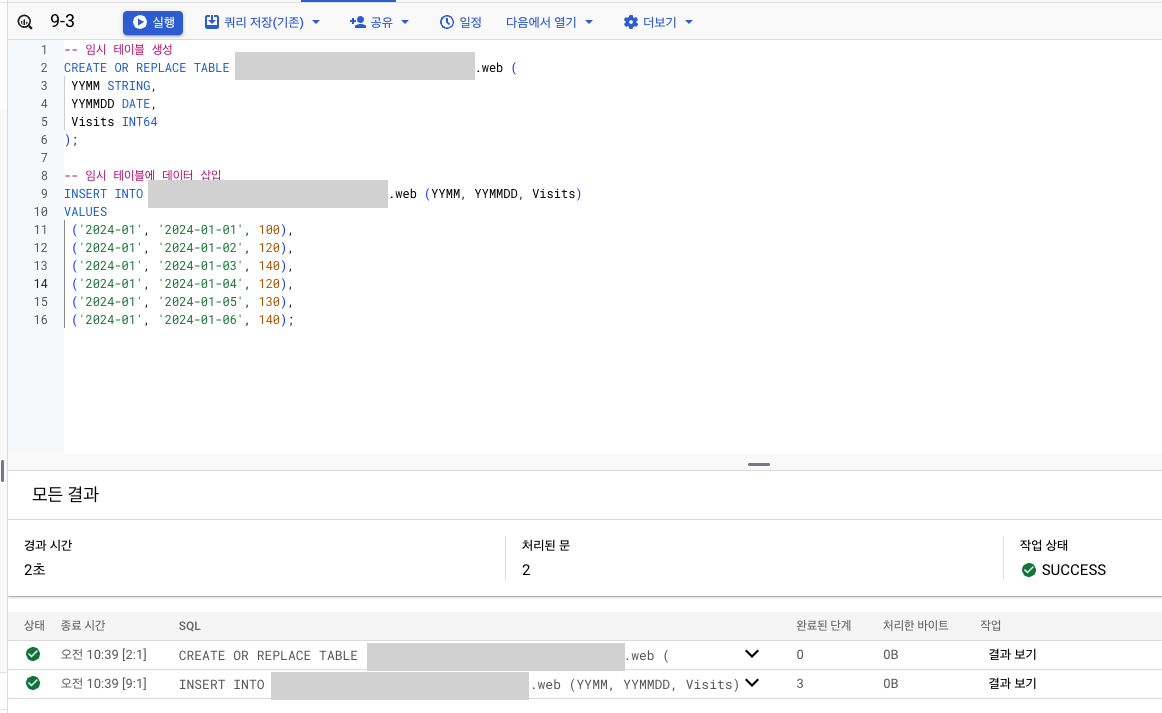
- 결과
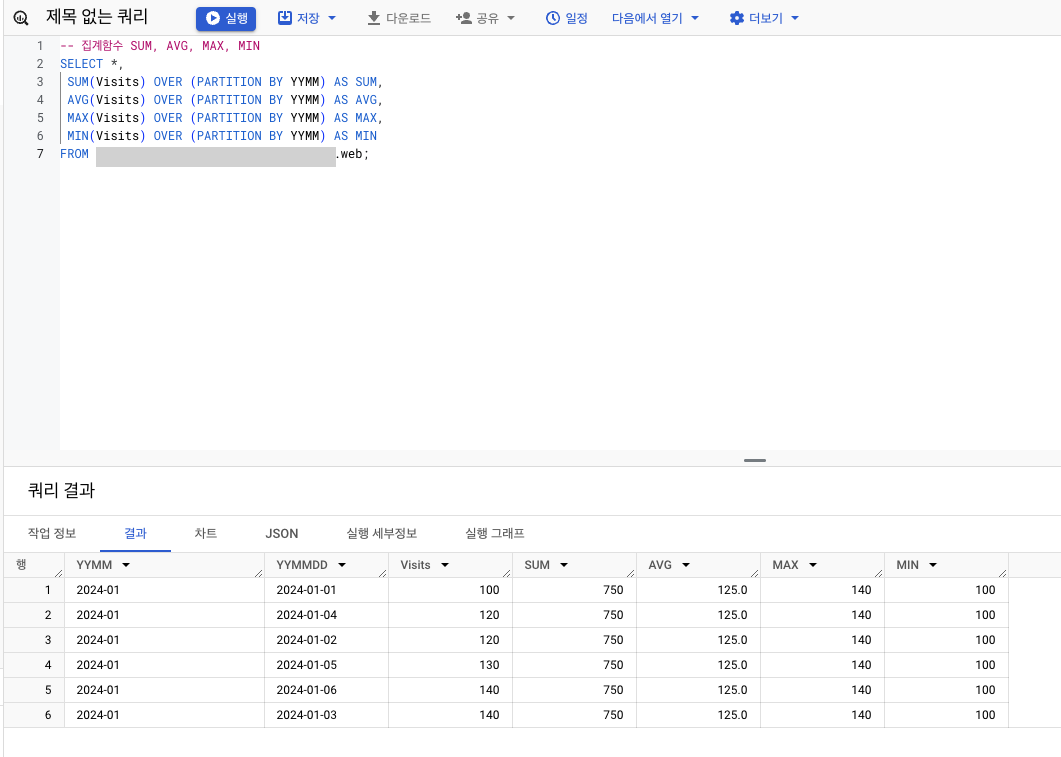
행 순서 집계함수: FIRST_VALUE, LAST_VALUE, LAG, LEAD
- 함수 구조
FIRST_VALUE(컬럼): 조건 충족하는 가장 1번째 값LAST_VALUE(컬럼): 조건 충족하는 가장 마지막 값LAG(컬럼, n): 해당 컬럼 이전 n번째 행LEAD(컬럼, n): 해당 컬럼 이후 n번째 행
SELECT 컬럼명,
행 순서 함수(기준 컬럼) OVER ([PARTITION BY 절] [ORDER BY 절] [WINDOWING 절])
FROM 테이블명- WINDOWING절
- 행 범위 기준
ROWS BETWEEN A AND B형태
SELECT 컬럼명, 행 순서 함수(기준 컬럼) OVER ([PARTITION BY 절] [ORDER BY 절] [ROWS BETWEEN A AND B]) FROM 테이블명CURRENT ROW: 현재 행을 의미UNBOUNDED PRECEDING: 윈도우 시작 위치 -> 1번째 행!UNBOUNDED FOLLOWING: 윈도우 최종 위치 -> 마지막 행!n PRECEDING: n행 앞이라는 의미n FOLLOWING: n행 뒤라는 의미
예시
- 경쟁자 기록 분석
SELECT *,
LAG(기록, 1) OVER (PARTITION BY 종목 ORDER BY 기록) LAG_기록,
LEAD(기록, 1) OVER (PARTITON BY 종목 ORDER BY 기록) LEAD_기록
FROM 경기결과| 종목 | 선수 | 기록 | LAG_기록 | LEAD_기록 |
|---|---|---|---|---|
| 수영 | A | 05:10 | NULL | 05:12 |
| 수영 | B | 05:12 | 05:10 | 05:14 |
| 수영 | C | 05:14 | 05:12 | NULL |
| 달리기 | D | 00:11 | NULL | 00:12 |
| 달리기 | E | 00:12 | 00:11 | 00:15 |
| 달리기 | F | 00:15 | 00:12 | NULL |
SELECT *,
LAG(선수, 1) OVER (PARTITION BY 종목 ORDER BY 기록) LAG_선수,
LEAD(선수, 1) OVER (PARTITON BY 종목 ORDER BY 기록) LEAD_선수
FROM 경기결과| 종목 | 선수 | 기록 | LAG_선수 | LEAD_선수 |
|---|---|---|---|---|
| 수영 | A | 05:10 | NULL | B |
| 수영 | B | 05:12 | A | C |
| 수영 | C | 05:14 | B | NULL |
| 달리기 | D | 00:11 | NULL | E |
| 달리기 | E | 00:12 | D | F |
| 달리기 | F | 00:15 | E | NULL |
실습
- 데이터 생성
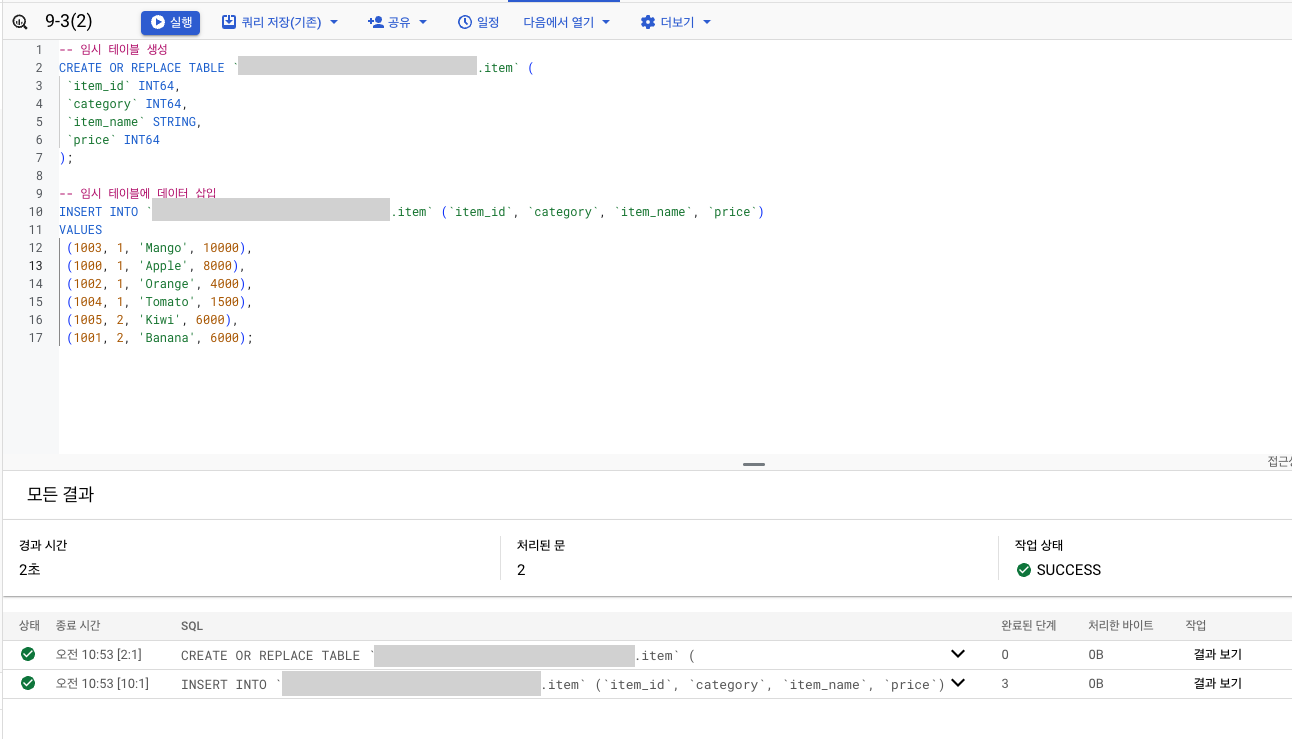
- 결과1

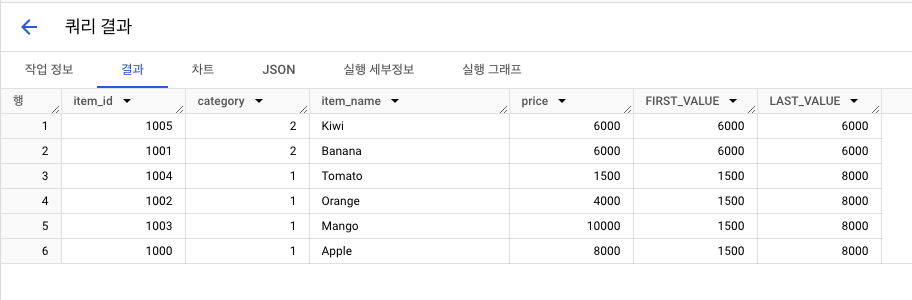
- 결과2

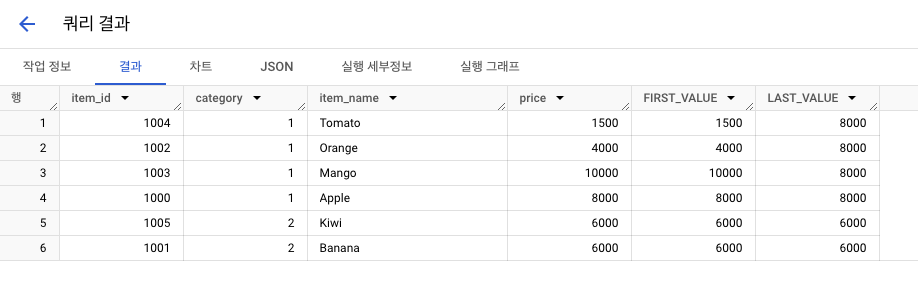
- 결과3

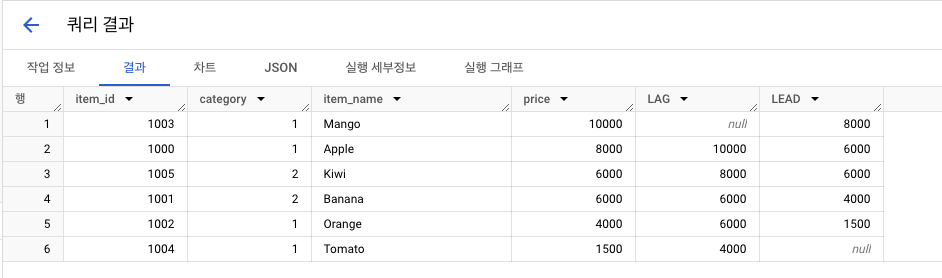
- 결과4
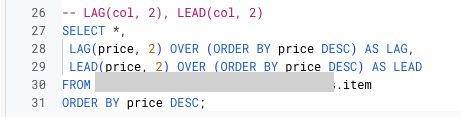
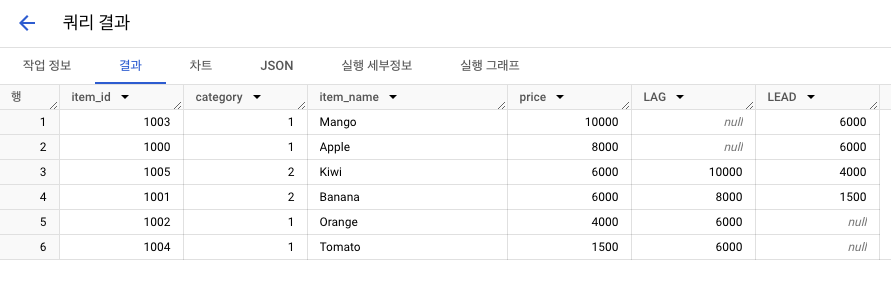
9-4. 그룹함수
그룹함수란? 함수 구조 살펴보기
- 함수 구조 : 데이터의 통계를 내기 위한 소계, 중계 구하기!
ROLLUP: 소그룹 간 소계CUBE: 다차원적 소계GROUPING SETS: 특정 항목(그룹) 소계
ROLLUP, CUBE, GROUPING SETS
- 기존 GROUP BY 구문
SELELCT
상품 ID, 기준월, SUM(매출액) AS 매출액_합계
FROM 월별매출
GROUP BY 상품ID, 기준월;- ROLLUP
SELELCT
상품 ID, 기준월, SUM(매출액) AS 매출액_합계
FROM 월별매출
GROUP BY ROLLUP(상품ID, 기준월);| 상품ID | 기준월 | 매출액_합계 |
|---|---|---|
| 1001 | 2024.01 | 1000 |
| 1001 | 2024.02 | 1000 |
| 1001 | 2024.03 | 2000 |
| 1001 | NULL | 4000 |
| 1002 | 2024.01 | 1500 |
| 1002 | 2024.02 | 1500 |
| 1002 | 2024.03 | 2500 |
| 1002 | NULL | 5500 |
| NULL | NULL | 9500 |
- CUBE
SELELCT
상품 ID, 기준월, SUM(매출액) AS 매출액_합계
FROM 월별매출
GROUP BY CUBE(상품ID, 기준월);| 상품ID | 기준월 | 매출액_합계 |
|---|---|---|
| NULL | NULL | 9500 |
| NULL | 2024.01 | 2500 |
| NULL | 2024.02 | 2500 |
| NULL | 2024.03 | 4500 |
| 1001 | 2024.01 | 1000 |
| 1001 | 2024.02 | 1000 |
| 1001 | 2024.03 | 2000 |
| 1001 | NULL | 4000 |
| 1002 | 2024.01 | 1500 |
| 1002 | 2024.02 | 1500 |
| 1002 | 2024.03 | 2500 |
| 1002 | NULL | 5500 |
- GROUPING SETS
SELELCT
상품 ID, 기준월, SUM(매출액) AS 매출액_합계
FROM 월별매출
GROUP BY GROUPING SETS(상품ID, 기준월);| 상품ID | 기준월 | 매출액_합계 |
|---|---|---|
| NULL | 2024.01 | 2500 |
| NULL | 2024.02 | 2500 |
| NULL | 2024.03 | 4500 |
| 1001 | NULL | 4000 |
| 1002 | NULL | 5500 |
실습
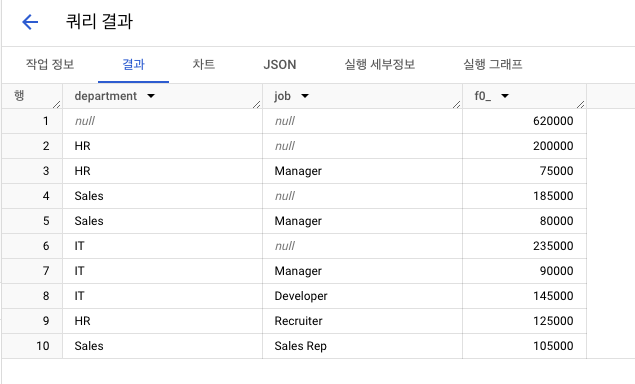
-
데이터 생성
-
결과 1 : 기존 GROUP BY

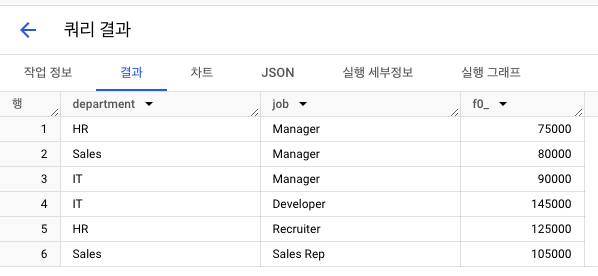
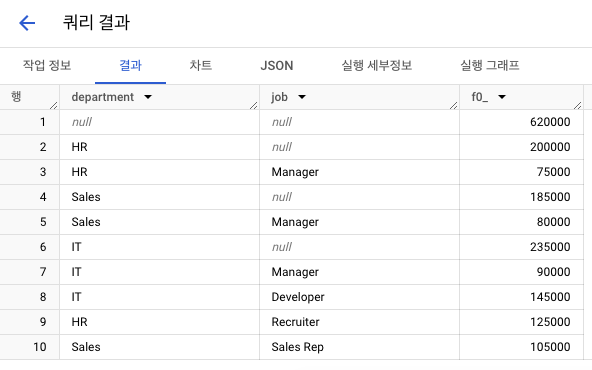
-
결과 2 : ROLLUP

- 결과 3 : CUBE

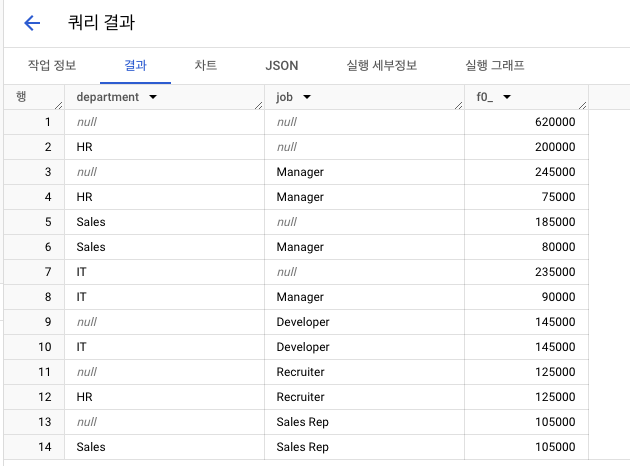
- 결과 4 : GROUPING SETS

9-5. 복잡한 데이터 처리(JSON Formatting)
로그 데이터란? JSON 구조의 로그 데이터 살펴보기
- JSON Formatting하기
- 로그 데이터 : 웹페이지, 애플리케이션, 응응 프로그램 등에서 수집된 동작 및 활동 정보
[{"user": "user1", "action": "login", "timestamp": "2023-11-01T08:00:00"}, {"user": "user2", "action": "logout", "timestamp": "2023-11-01T09:30:00"}, {"user": "user1", "action": "purchase", "timestamp": "2023-11-01T10:15:00"}]
JSON 뜯어서 분석하기
-
DBMS 종류에 따른 JSON 함수 형태가 다름.
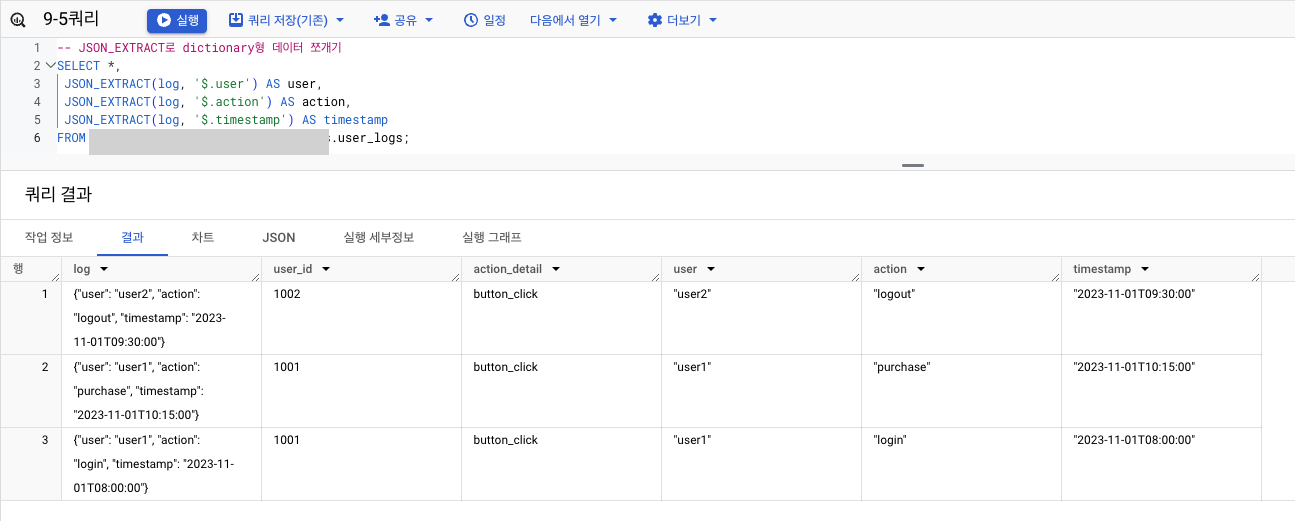
BigQuerySELECT JSON_EXTRACT(log, '$.user') AS user, JSON_EXTRACT(log, '$.action') AS action, JSON_EXTRACT(log, '$.timestamp') AS timestamp FROM table;- JSON_EXTRACT 함수 사용!
log user action timestamp {"user": "user1", "action": "login", "timestamp": "2023-11-01T08:00:00"} user1 login 2023-11-01T08:00:00 {"user": "user2", "action": "logout", "timestamp": "2023-11-01T09:30:00"} user2 logout 2023-11-01T09:30:00 {"user": "user1", "action": "purchase", "timestamp": "2023-11-01T10:15:00"} user1 purchase 2023-11-01T10:15:00
PostgreSQLSELECT log->>'user' AS user, log->>'action' AS action, log->>'timestamp' AS timestamp FROM table;
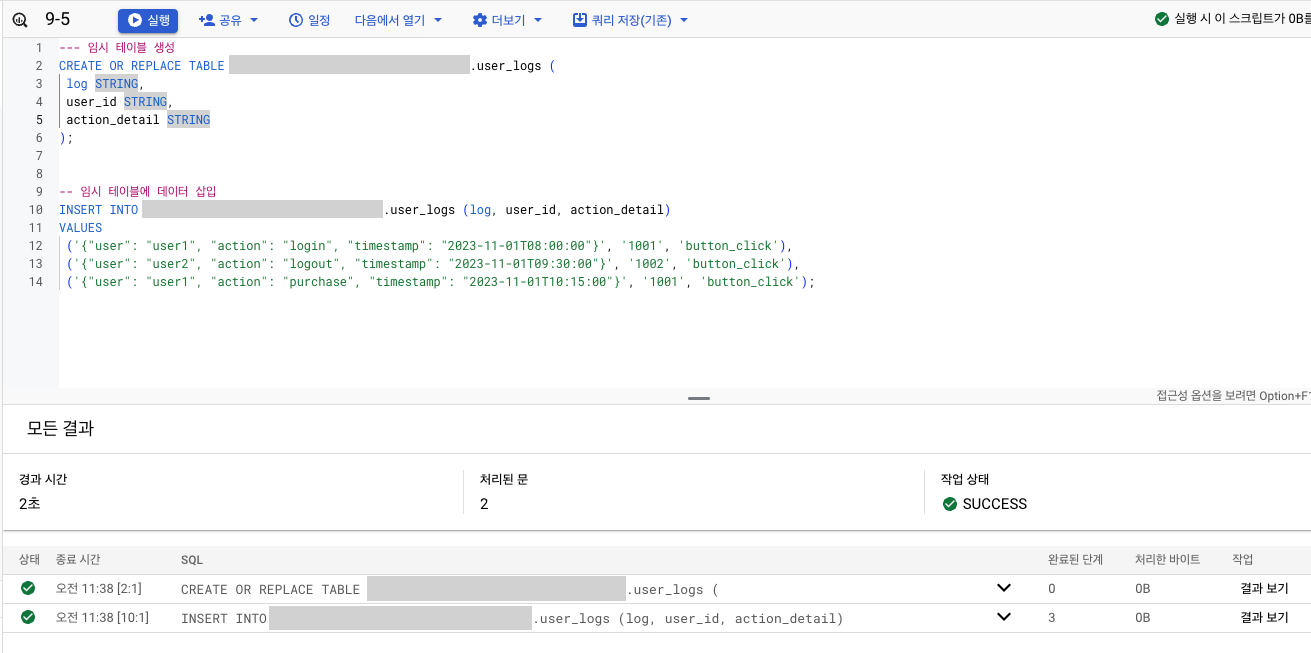
실습
-
데이터 생성
-
결과
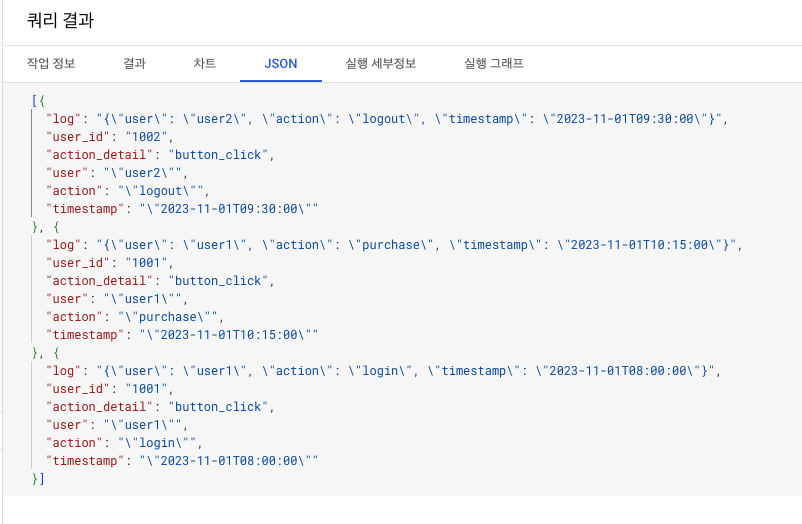
- 참고) JSON
⭐️ TIP
TMI) 저도 이 " "가 영 거슬려서..찾아보니 스칼라 이용하면 된다고 그래서 음 그렇구나..하고 그냥 혼자만 알고 넘어갔는데 다른 팀 그루분께서 전파해주셔서 놀랐..😮 앞으로 저도 이런 부분이 있으면 말씀드려야 할 것 같아요..! 같이 알아야죠!!
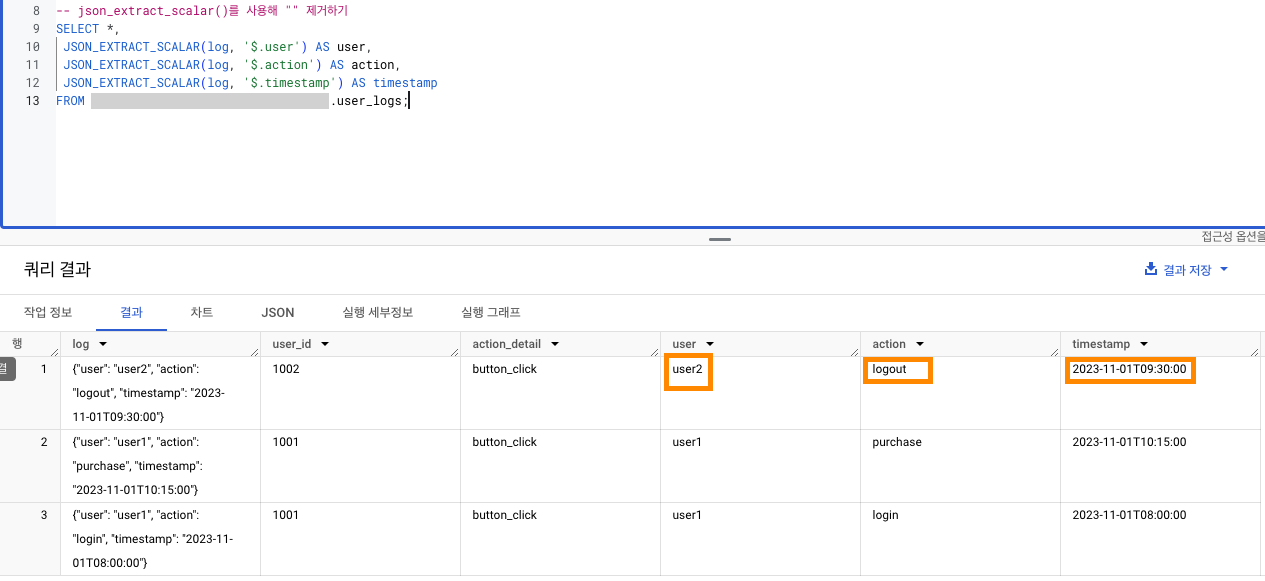
JSON_EXTRACT_SCALAR사용 시 불필요한 " " 제거해서 그 안의 스칼라만 뽑아낼 수 있다!
- 기존의 JSON_EXTRACT를 이용하면, 추후 데이터 가공 시 결과에서 " "를 제거하는 쿼리문을 또 작성해야하기 때문에 비효율적!
- 결과 차이보기
- 이전과 달리 앞 뒤의 " "가 사라짐.

언젠가 내 코드로 세상에 기여할 수 있도록, Data Science&BE 개발 기록 노트☘️