
이미지 출처는 링크 or 아이펠 교육 자료입니다.
4-1. Airflow 소개
학습 목표
- Airflow 소개
- 데이터 워크플로우 관리 도구에 대한 학습
- 예제 학습
- Airflow의 구성 및 예제를 통한 실습
- 데이터 워크플로우
- MLOps에서의 데이터 워크 플로우의 관리 이유 설명
- 데이터 아키텍쳐
- 실제 환경에서의 데이터 처리를 위한 아키텍쳐 학습
Apache Airflow 소개

- https://airflow.apache.org/
- 데이터 워크플로우 관리 및 스케줄링
- 작업 순서 및 종속성 관계를 DAG로 정의하는 방식을 사용
- 데이터 처리 과정을 워크 플로우로 구성해 실행하는 환경 제공
*Directed Acyclic Graph(DAG)
- 순환 노드가 없는 방향성 있는 그래프
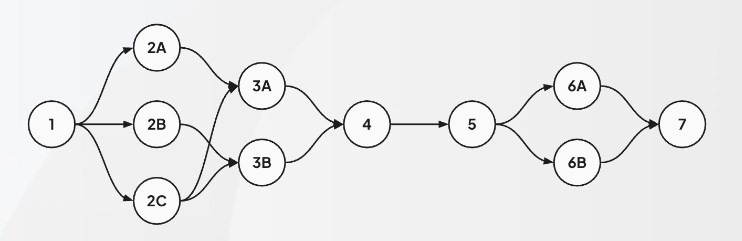
실제 DAG 모습
- DAG 렌더링
- 파란색 노드: 노드 그룹을 의미
- 하위 노드가 있음
- 파란색 노드: 노드 그룹을 의미
- 왼쪽과 오른쪽이 같은 형태의 DAG임!
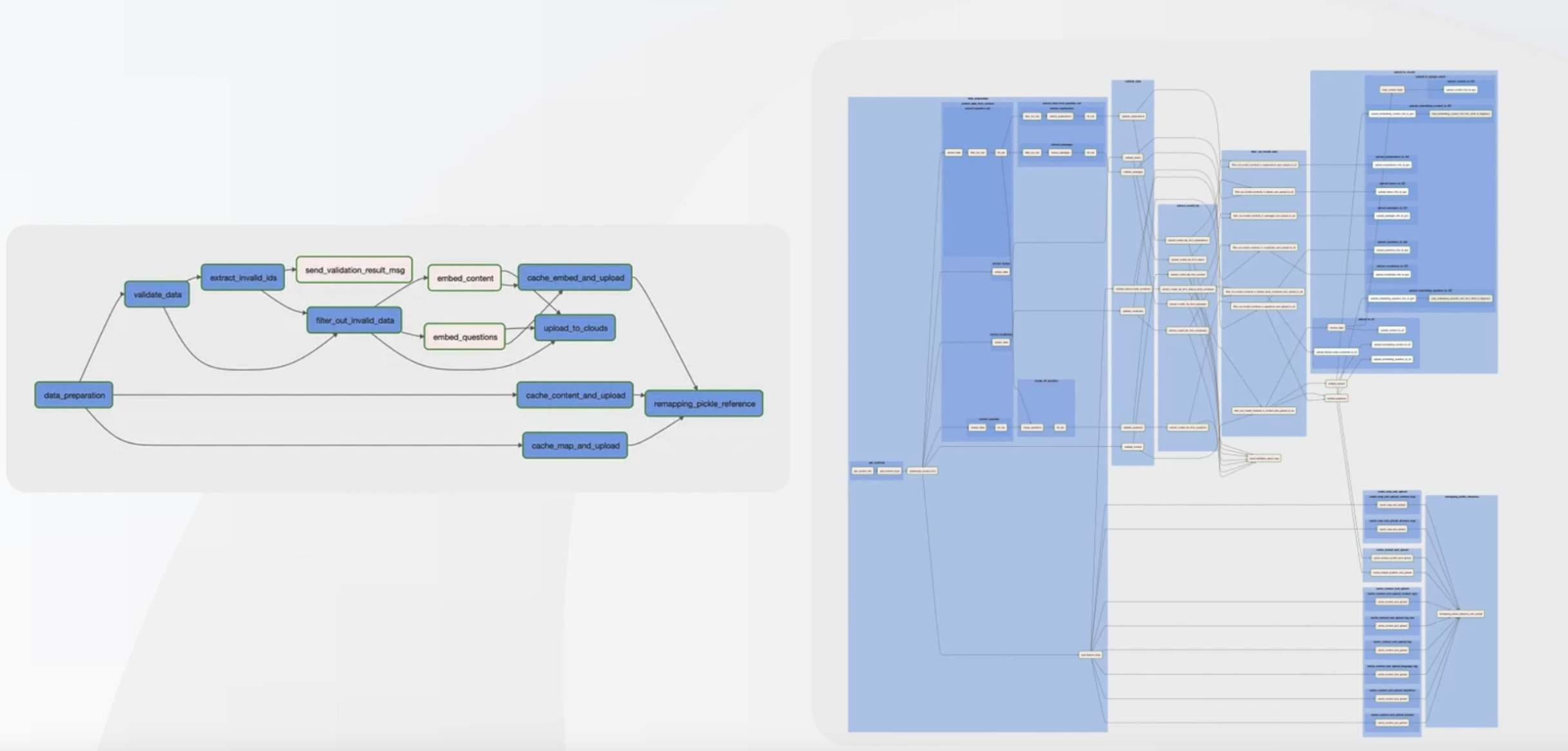
현재 노드에서는 강의 자료 github에 Airflow 사용 가이드가 올라와 있어, clone 진행
- docker-compose.yaml로 한번에 설치 예정
4-2. Airflow 구성하기 - 예제1
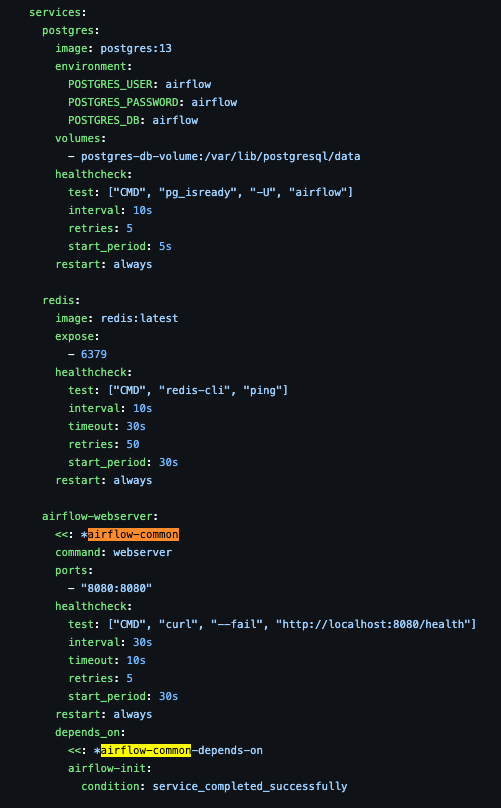
docker-compose.yaml
x-airflow-common- &airflow-common 앵커를 사용해 중복되어 있는 설정들을 미리 지정한다음 사용하기 위함
- 이러한 설정들을 다른 단계에서도 사용함

- postgres db, redis, webserver 사용
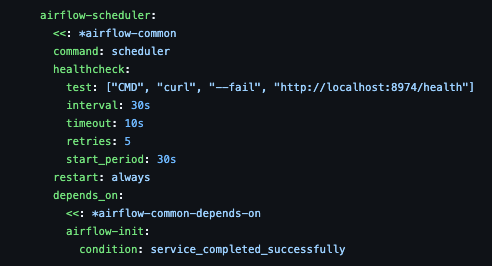
- airflow-scheduler
- 스케줄러가 DAG 상태 관리
- 실제 스케줄링은 worker가 담당
- 다중 worker를 잘 처리함
- airflow-worker
- celery로 지정
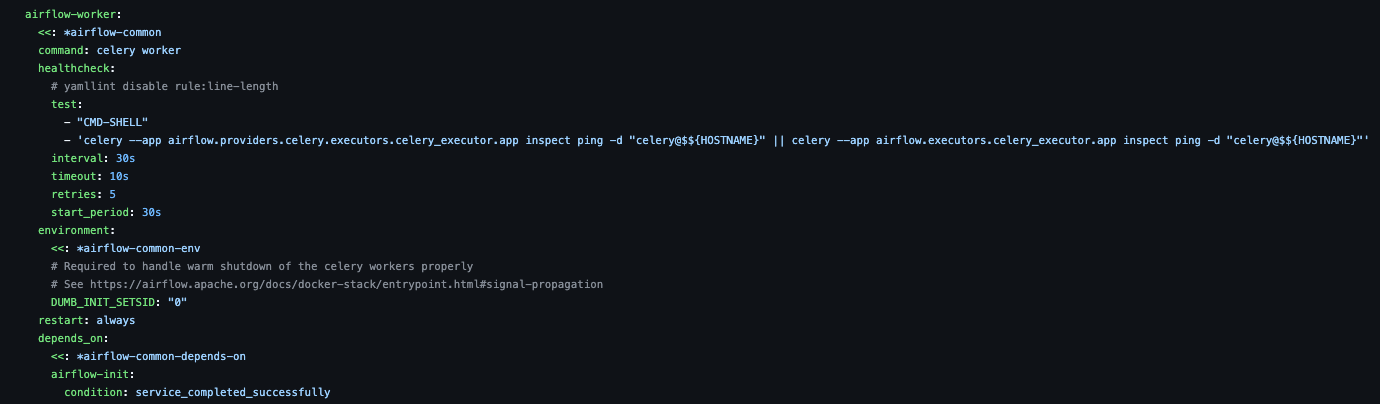
- celery로 지정
- 링크 정보 없이 서비스 이름만 명시해도 docker-compose 내에 존재할 경우 바로 사용 가능

1. 도커 컴포즈 파일 올리기
$ docker compose up # 이후, -d 옵션으로 백그라운드 실행하기
2. localhost:8080으로 접속
-
별도 설정을 하지 않았을 경우
- 아이디 : airflow
- 비밀번호 : airflow
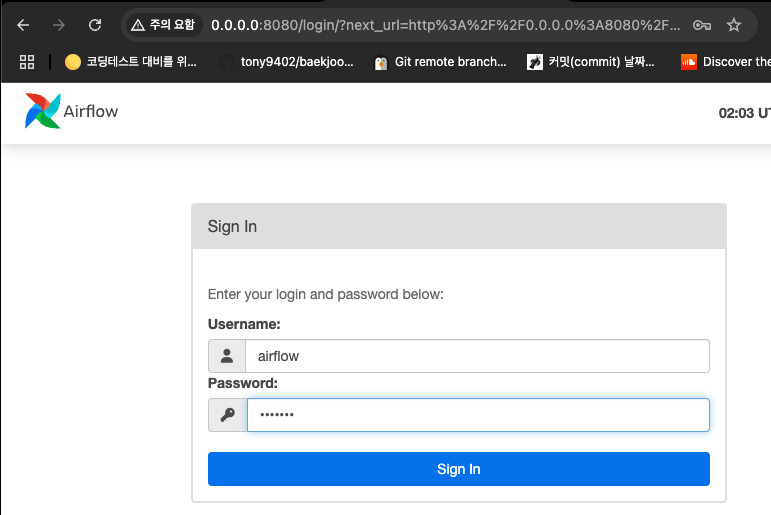
-
사용할 DAG

dags/bigquery_airflow_example.py
- 현재의 DAG는 노드가 1개(
bq_query_task) - 이렇게 DAG 객체를 전역변수로 작성하면, airflow에서 인식(렌더링)
from airflow import DAG
from airflow.utils.dates import days_ago
from airflow.contrib.operators.bigquery_operator import BigQueryOperator
default_args = {
"owner": "airflow",
"depends_on_past": False,
"start_date": days_ago(1),
"email_on_failure": False,
"email_on_retry": False,
"retries": 1,
}
dag = DAG(
"bigquery_airflow_example",
default_args=default_args,
description="A simple BigQuery Airflow example",
schedule_interval="@daily",
)
bq_query_task = BigQueryOperator(
task_id="bq_query_example",
sql="""SELECT * FROM `bigquery-public-data.samples.github_nested`""",
use_legacy_sql=False,
dag=dag,
)용어 정리
- DAG: Airflow의 최상위 작업으로 정의
- task를 단위로 가짐(==노드)
- Operator: task 정의
- 이외에도,
@task어노테이션을 통해 커스터마이징 가능- operator 자체가 task를 의미
- Hook
- task로 인정되지는 않으나, task안에서 실행될 수 있는 내용
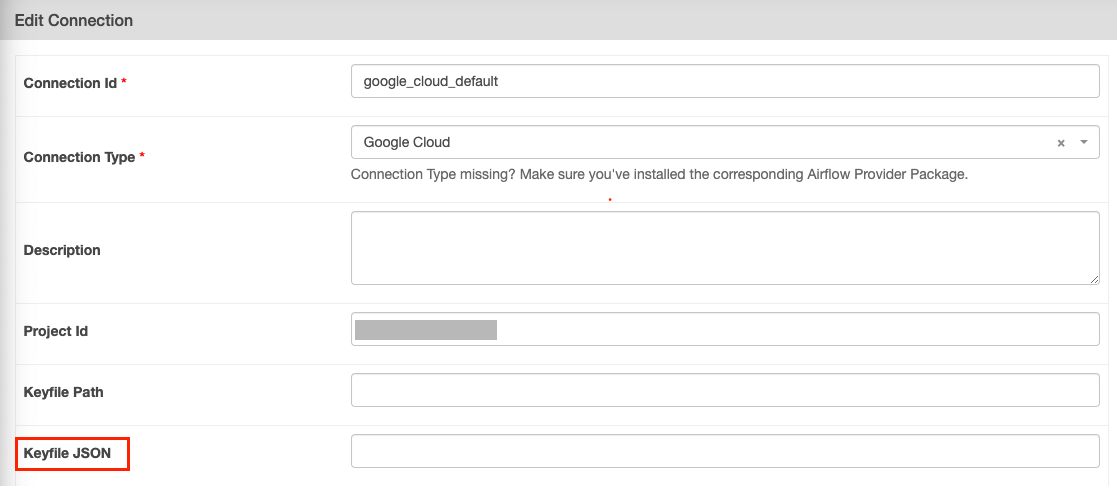
3. Google Cloud를 이용해 Airflow에 connection하기
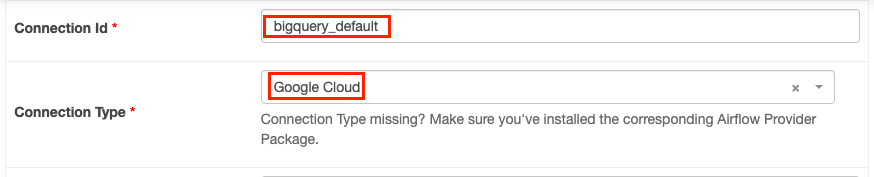
-
Google Cloud
-
iam검색
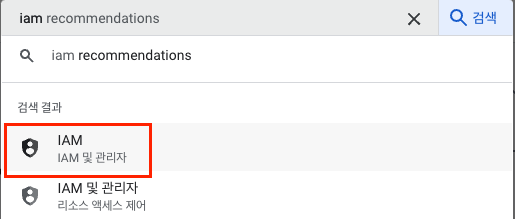
-
서비스 계정클릭

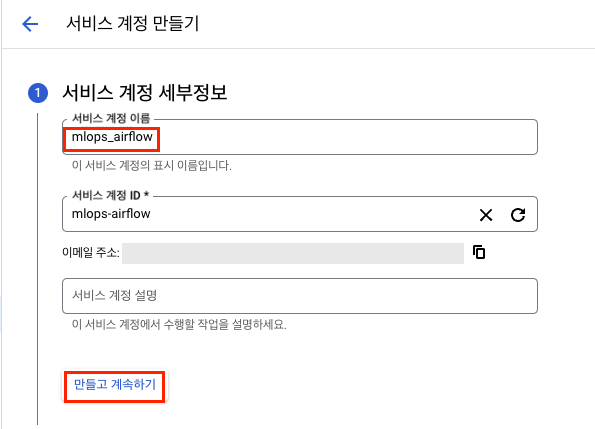
-
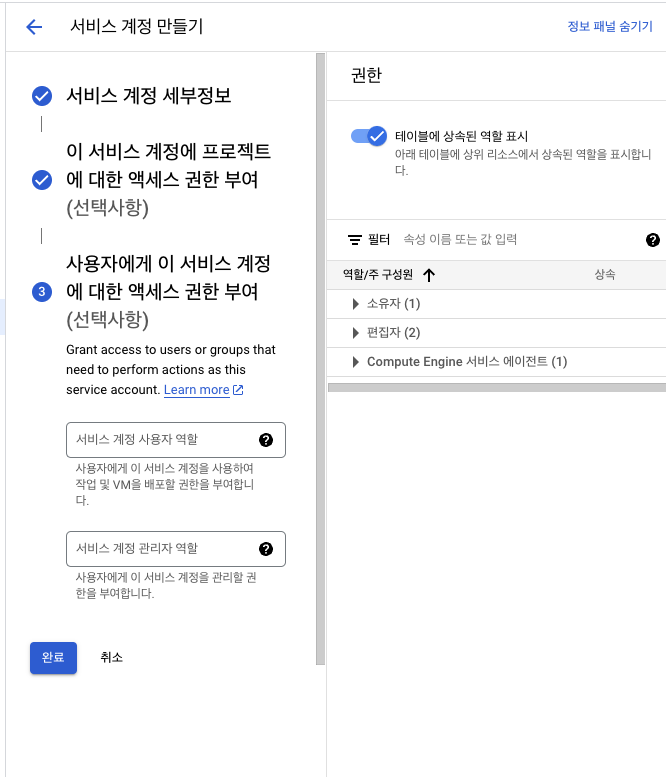
서비스 계정 만들기
- 서비스 계정 이름: mlops-airflow
만들고 계속하기클릭
- 역할 선택에서
BigQuery 관리자선택
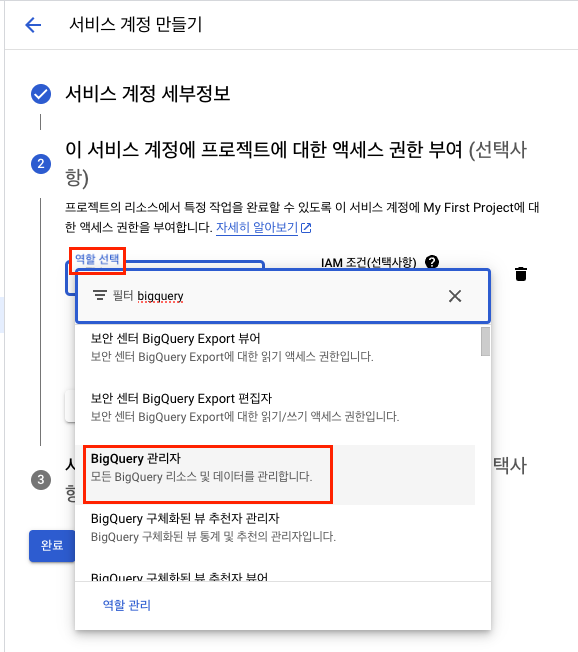
- 완료 클릭
-
만든 계정에 접속 >
키클릭 >키 추가>새 키 만들기

-
JSON으로 되어있는지 확인 후, 완료 버튼 클릭

-
키가 컴퓨터 내부에 저장됨!
-
Airflow로 돌아와서 JSON 정보를
Keyfile JSON항목에 붙여넣기

-
google cloud의 프로젝트 ID ->
Project Id에 붙여넣기

-
Save 후, 다시 DAG run

-
Last run클릭하여 상태 확인
-
정보 교체: connectionID를
google_cloud_default로 교체

-
Auto-refresh가 켜져 있어 업데이트 될 예정(기다리기)
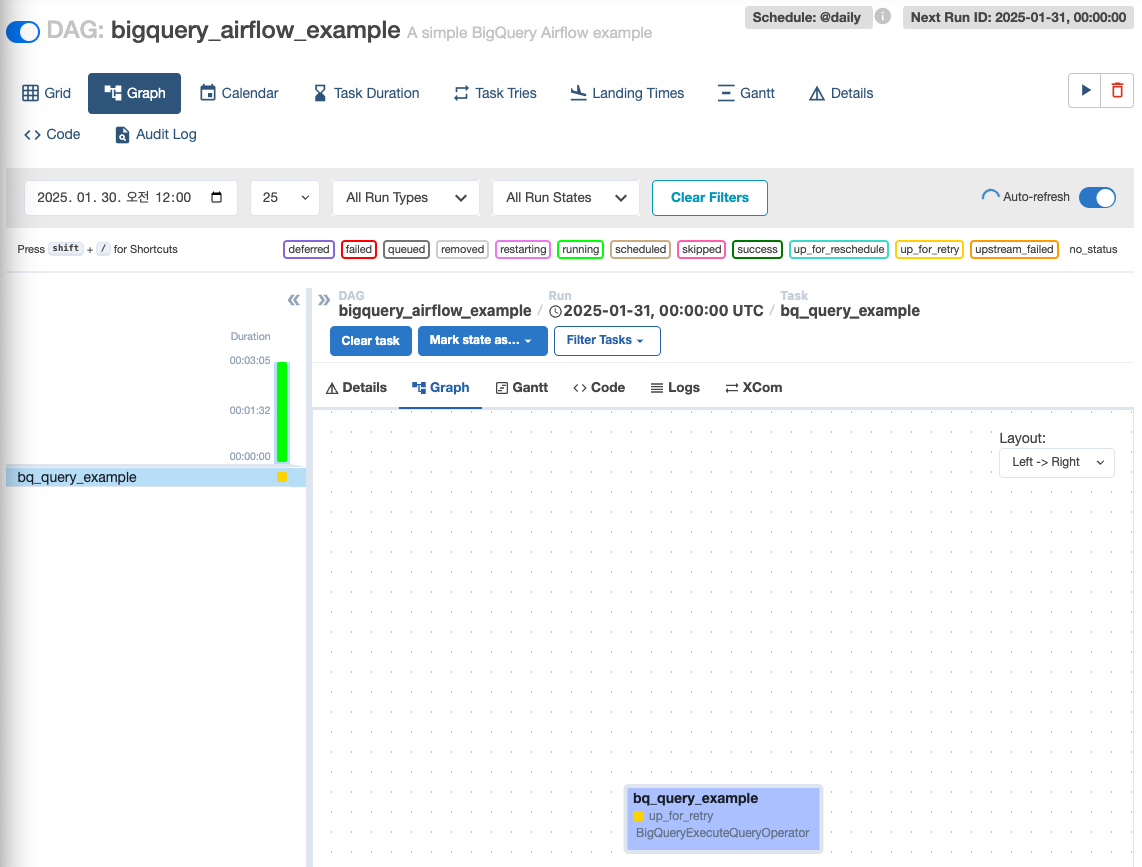

Your default credentials were not found. 에러 발생 시
- ConnectionId를 바꾸면서 keyfile JSON 정보가 초기화되어 발생한 문제
- 다시 붙여넣어 해결
- 또한, Google cloud IAM 설정이
BigQuery 관리자로 잘되어 있는지도 재확인

4. Airflow 초기화하기
- .../airflow/basic으로 폴더 이동
- docker down
$ docker compose down --volumes데이터 관리의 중요성
데이터 드리프트
- 시간에 따른 데이터 변화 -> 모델 드리프트 발생
- 모델 품질에 영향을 줌
- 데이터 드리프트의 감지는 데이터 품질에 있어 아주 중요한 요소!
데이터 드리프트 현상
- 시간 흐름에 따른 기존 데이터 분포 -> 현재 데이터 분포로 변경
- 분포가 변화하면 -> 모델 정확도 하락
- 현재의 분포를 잘 반영할 수 있도록 모델 재학습 및 업데이트 필요!
4-3. Airflow 구성하기-예제 2_Part.1
데이터 워크플로우
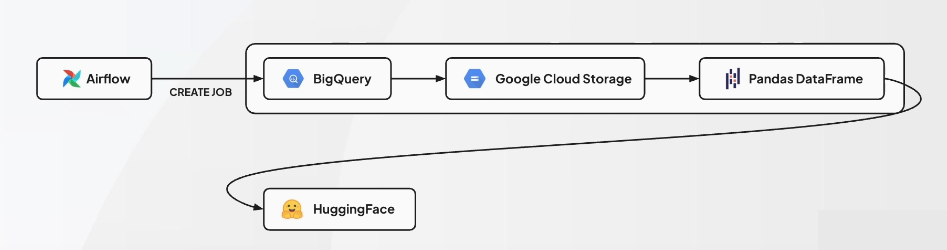
Hugging Face
-
Settings>Access Tokens클릭

-
Create new token클릭
-
설정
- Token name :
mlops_quicklab - 토큰 권한 : Write로 변경
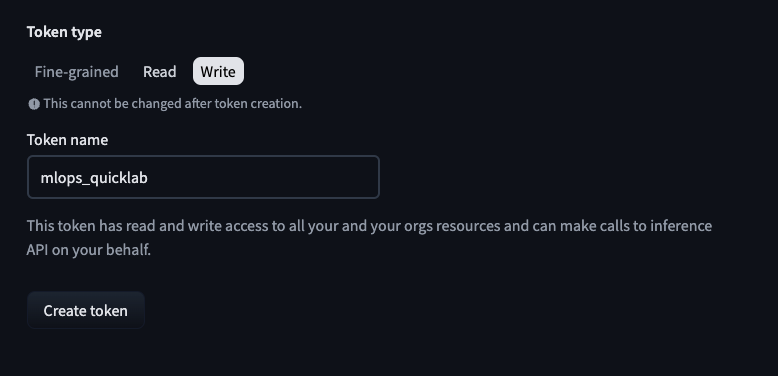
- Token name :
토큰이 발급되면, 노출되지 않도록 잘 관리할 것
Aiflow 2.0.0 이상
Airflow taskflow API 사용 가능
- https://airflow.apache.org/docs/apache-airflow/stable/tutorial/taskflow.html
@task,@dag형태로 바로 사용 가능함
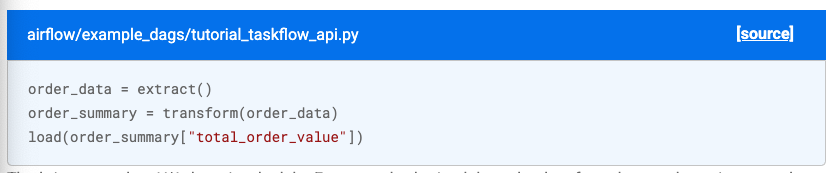
1. 허깅페이스 정보 등록
-
Airflow 구동 후, Admin > Variables 접속
-
허깅 페이스 토큰 추가하기
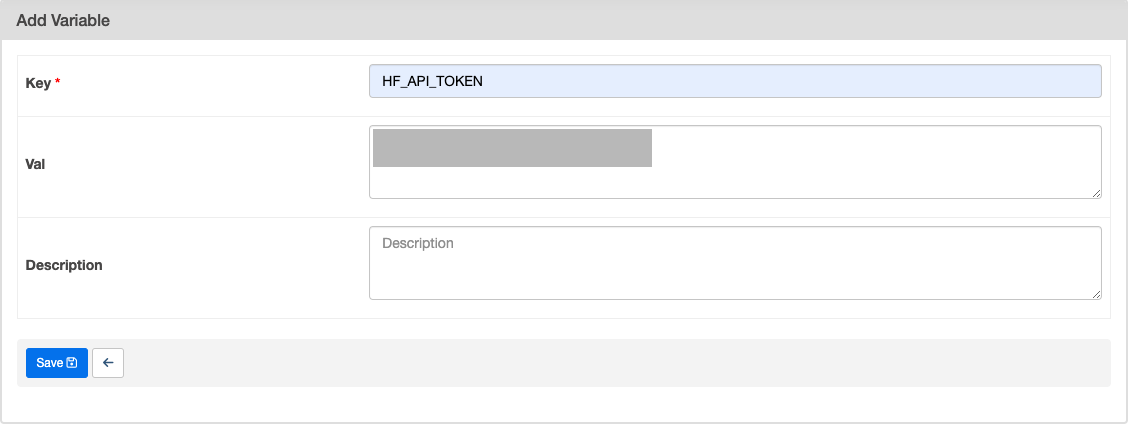
-
이렇게 등록하면, 실제 토큰값이 보이지 않아 안전

-
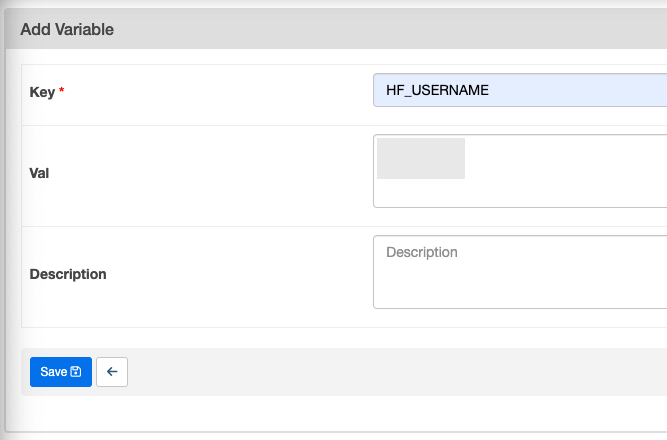
HF_USERNAME도 추가
- 사용자 이름 아래에 있는 고유 이름으로 넣어야 함!
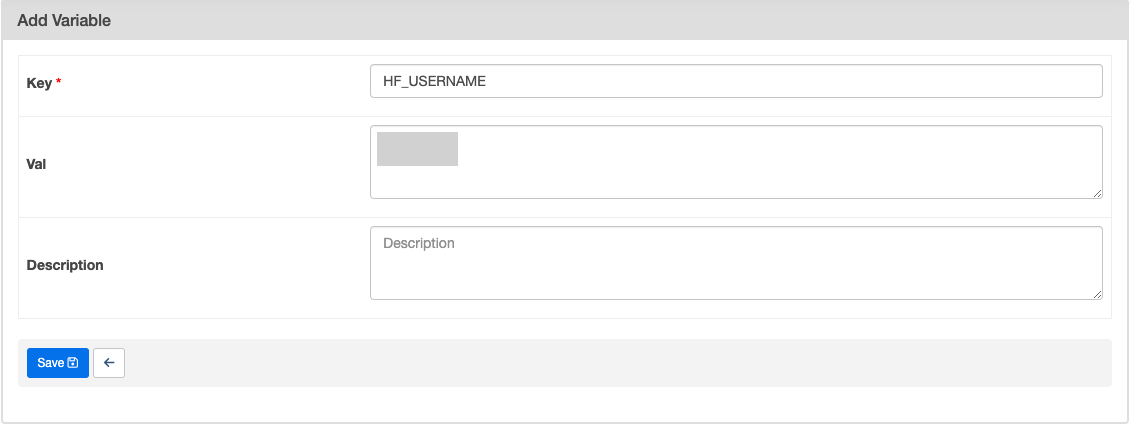
- 사용자 이름 아래에 있는 고유 이름으로 넣어야 함!
2. 프로젝트에서의 현 문제점
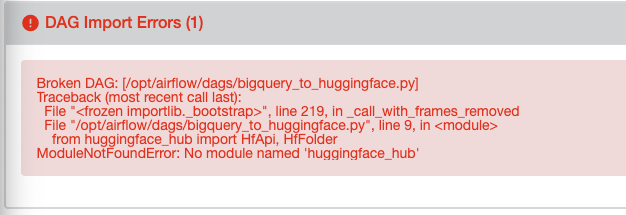
huggingface_hub를 환경변수에 넣어줘야 함!
$ echo "_PIP_ADDITIONAL_REQUIREMENTS=huggingface_hub" >> .env- 실행중이던 docker compose 내리기 & 다시 띄우기
$ docker compose down --volumes
$ docker compose up -d- 에러 사라짐
3. bigquery_to_huggingface 실행
- 곧, 에러가 날 것(아직 모든 설정이 완료되지 않은 상태이기 때문)

4. 에러 확인하기
- 첫번째 task: conn_id가 없음
raise AirflowNotFoundException(f"The conn_id `{conn_id}` isn't defined")이미 저장했는데요?
- docker compose down 시
--volumes옵션을 사용했기 때문에 모두 날아간 상태!- 다시 등록할 것
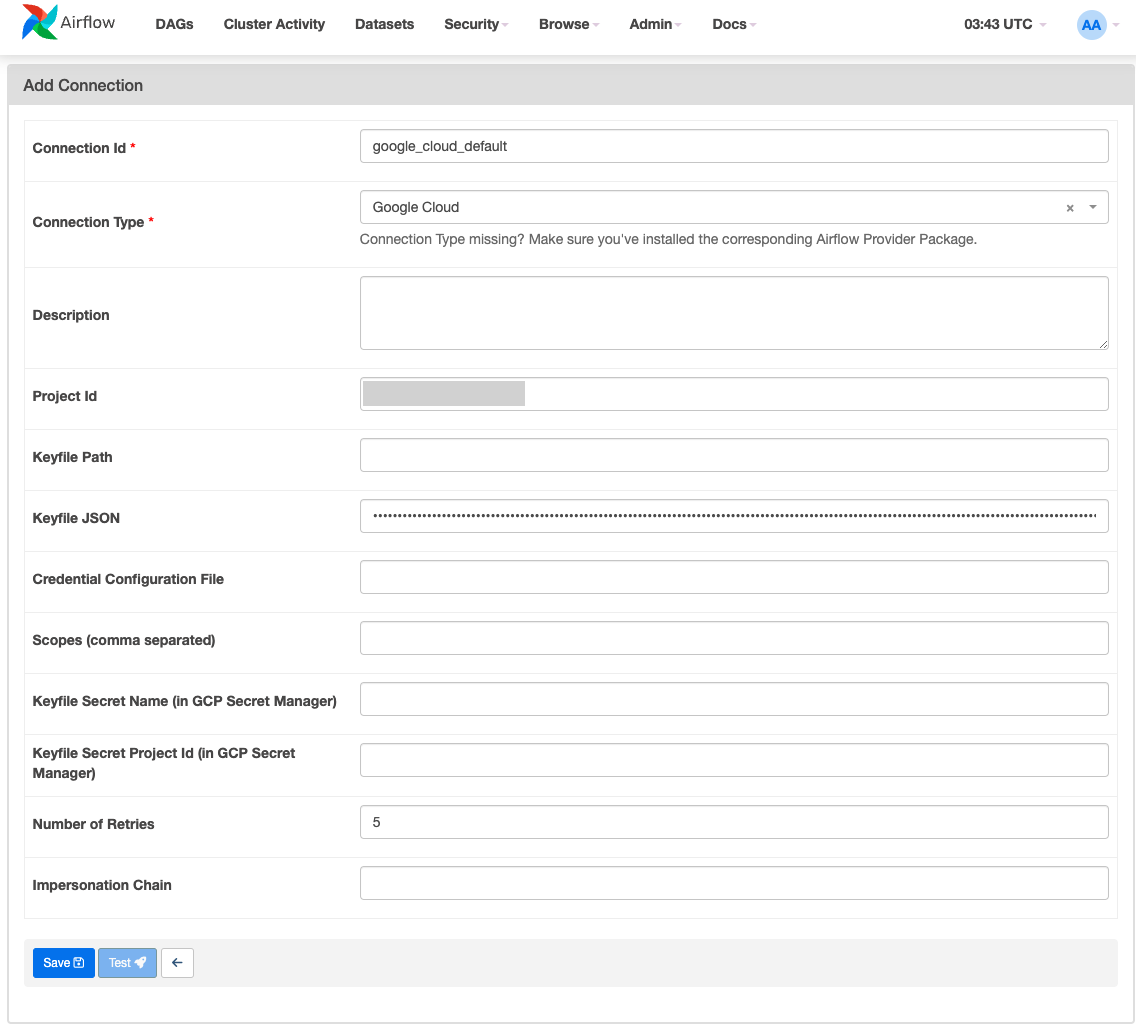
5. 재실행
Not found: Table...에러가 날 것임- 현재, 연결된 BigQuery에 실제 테이블이 없기 때문
6. BigQuery에서 테이블 생성하기
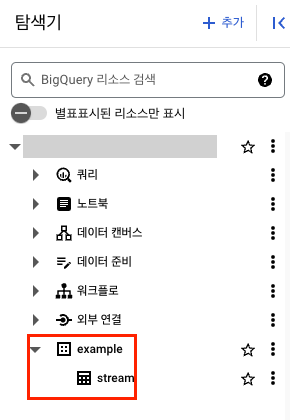
- example 폴더에
gcod만들기- BigQuery 공개 데이터셋에서 사용할 예정
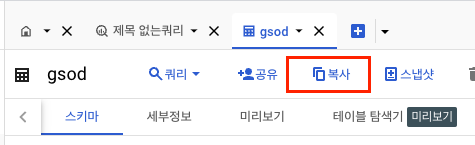
- 이름 클릭 시 바로 살펴보기 가능

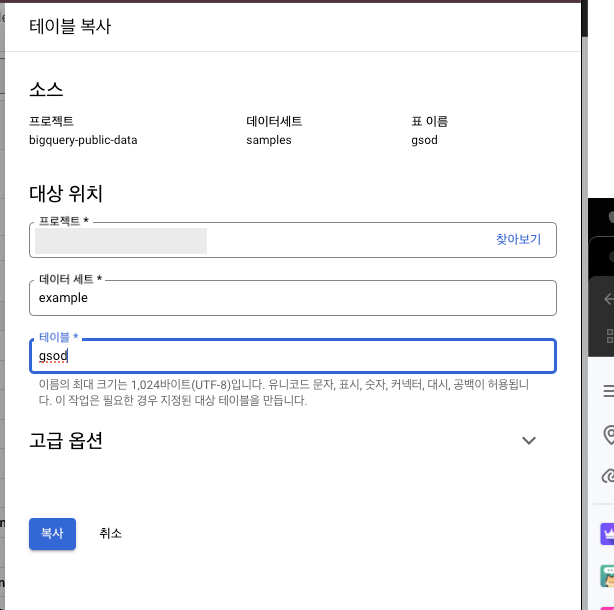
- 복사 > 대상 위치 프로젝트를 가져올 프로젝트로 지정
- 데이터 세트 : example
- 테이블 : gsod
7. Airflow 재실행
- 이제 이러한 에러를 보게 될 것
does not have storage.objects.create access to the Google Cloud Storage object
8. Google Cloud storage 설정
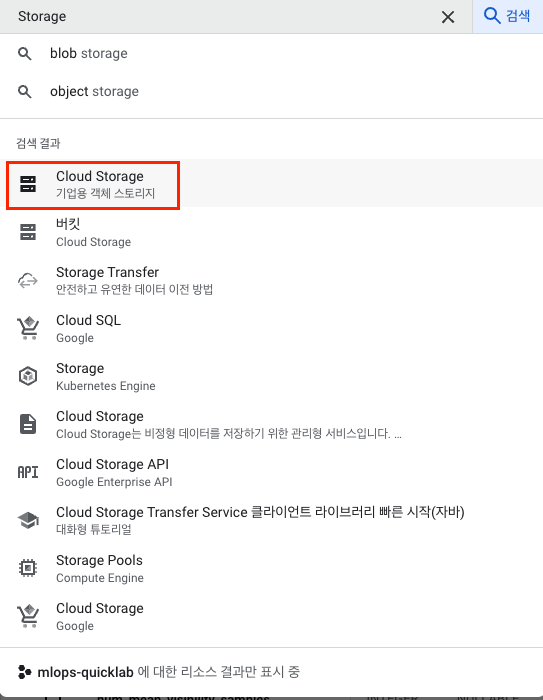
-
버킷 만들기 클릭

-
이름 설정 : mlops_airflow_2
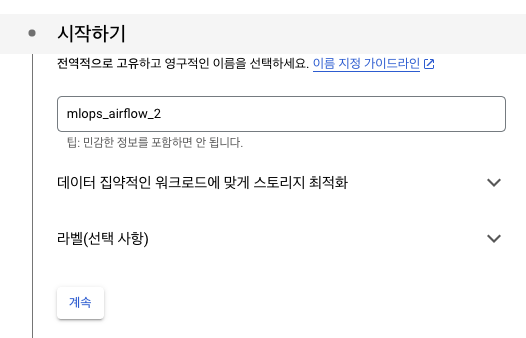
-
리전 : Multi-region
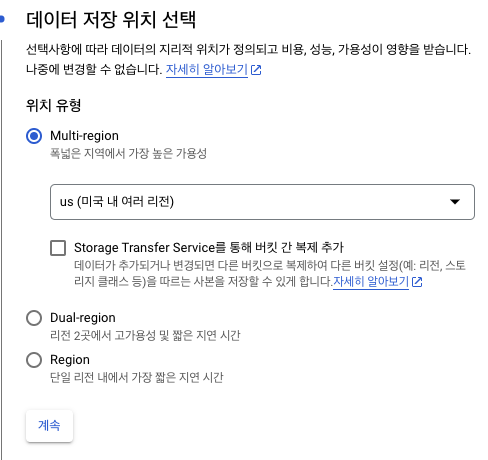
-
확인 클릭 후 기다리기

-
버킷 이름을 코드에 업데이트할 것

- bigquery_to_huggingface.py
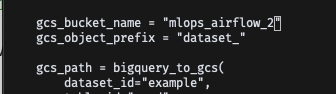
- bigquery_to_huggingface.py
-
Airflow에서 적용 확인 가능
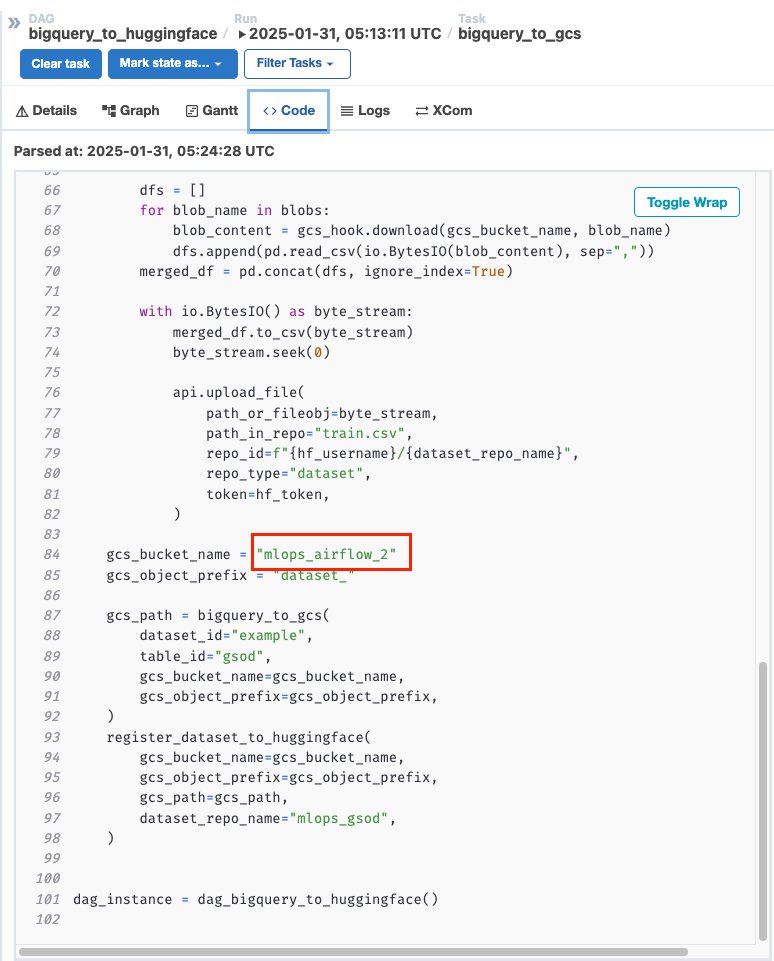
-
추가 설정: 권한 설정에서 storage 접근 권한 부여 필요
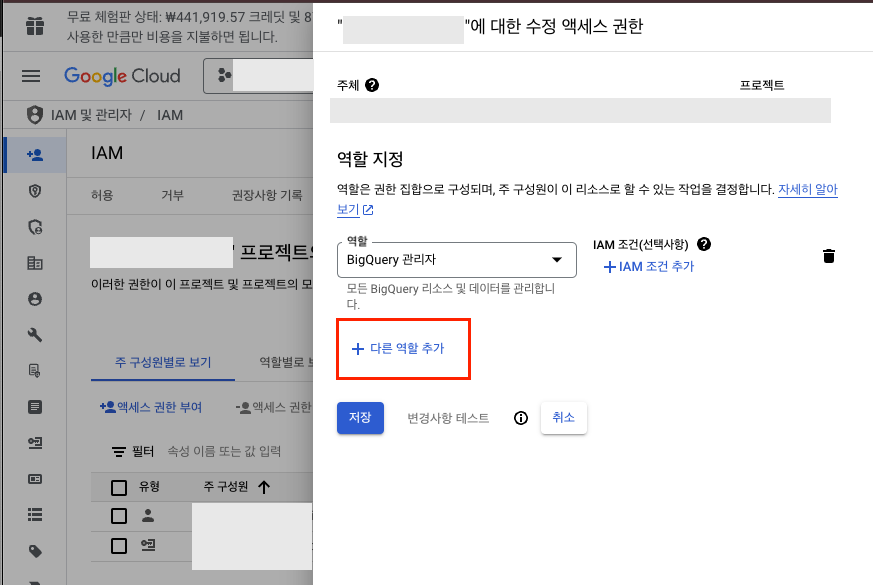
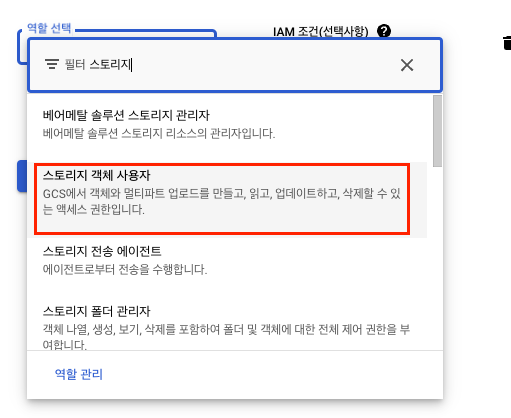

9. Airflow DAG 재실행
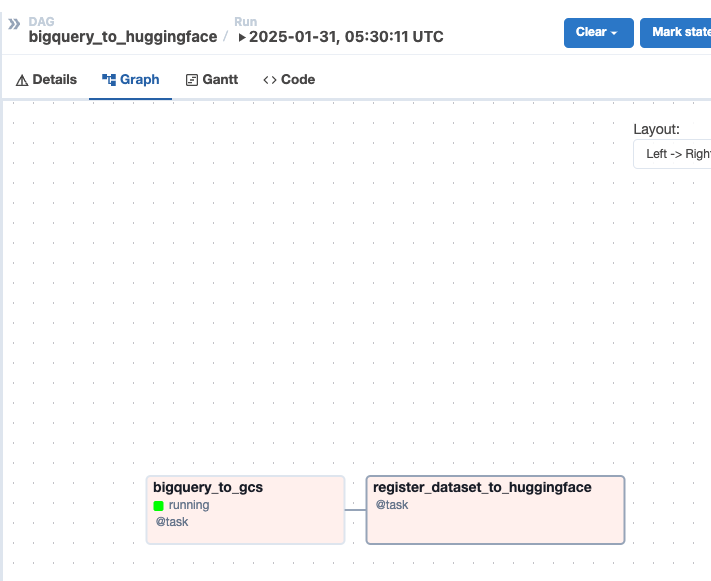
- bigquery_to_gcs까지는 잘 작업되었음을 확인

에러: KeyError: 'Variable HF_USERNAME does not exist'
- docker를 다시 올리는 과정에서 Variable 설정이 초기화되었기 때문
4-4. Airflow 구성하기-예제 2 _Part.2
- 설정 바꾸기 이전, GCP Storage에서의 객체 삭제부터(비용)
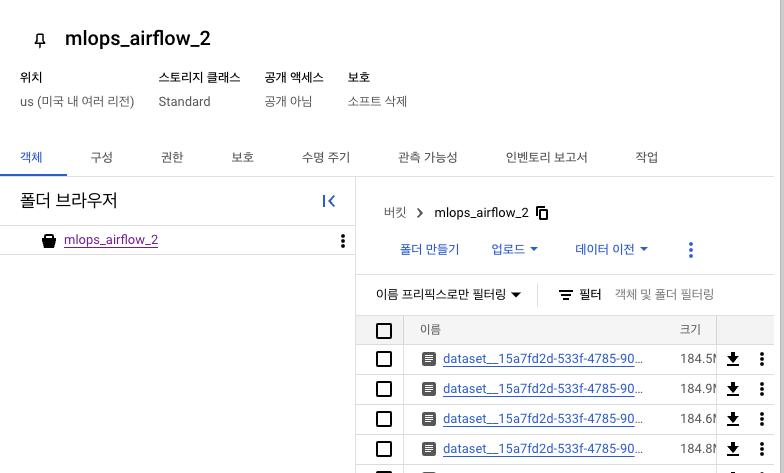
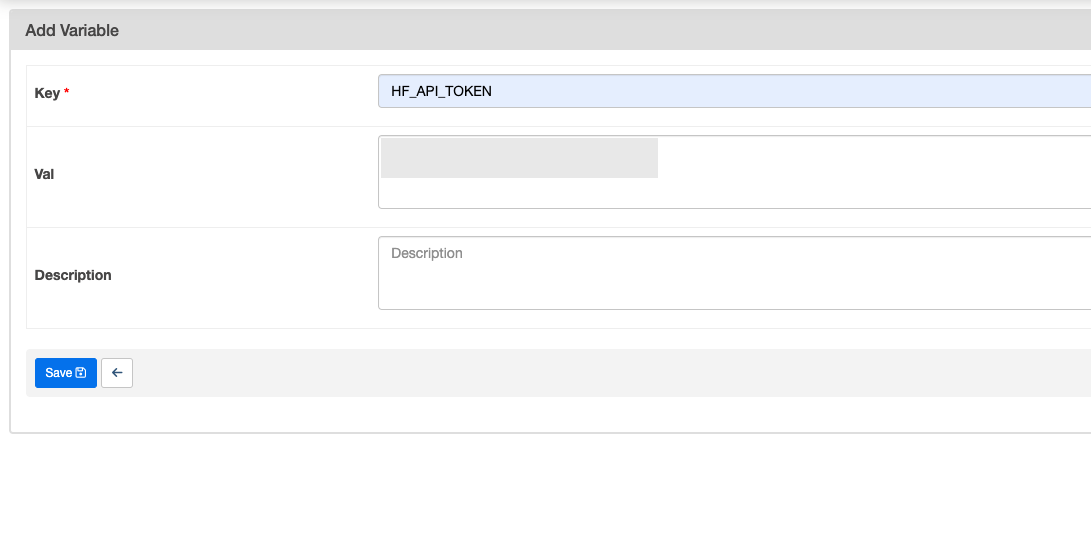
1. 허깅 페이스 설정
- Variable >
HF_API_TOKEN,HF_USERNAME
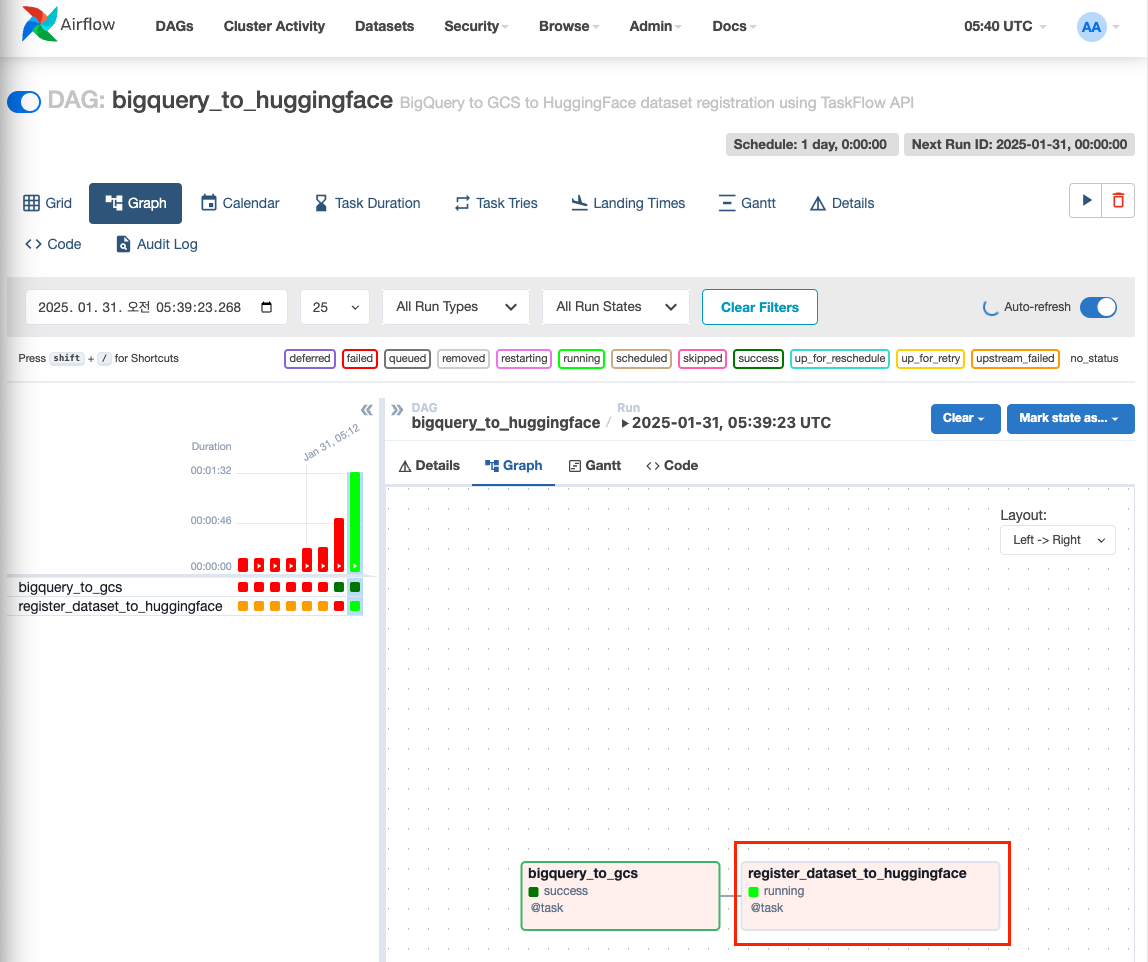
2. Airflow DAG 재실행
- 첫번째 task가 잘 실행되고, 두번째 task 실행중
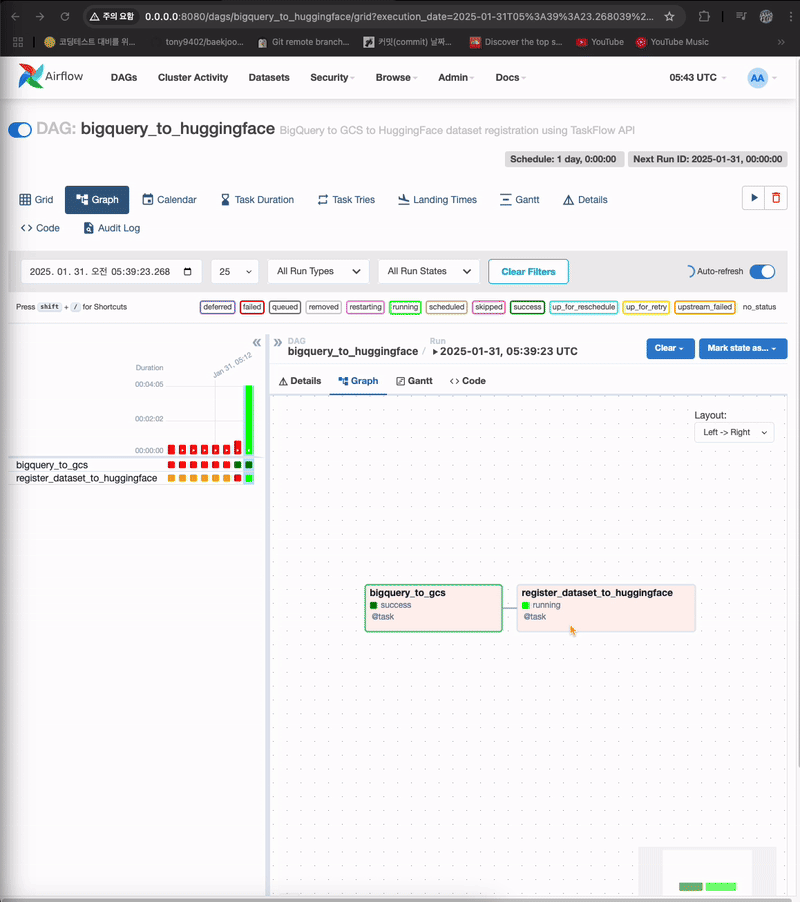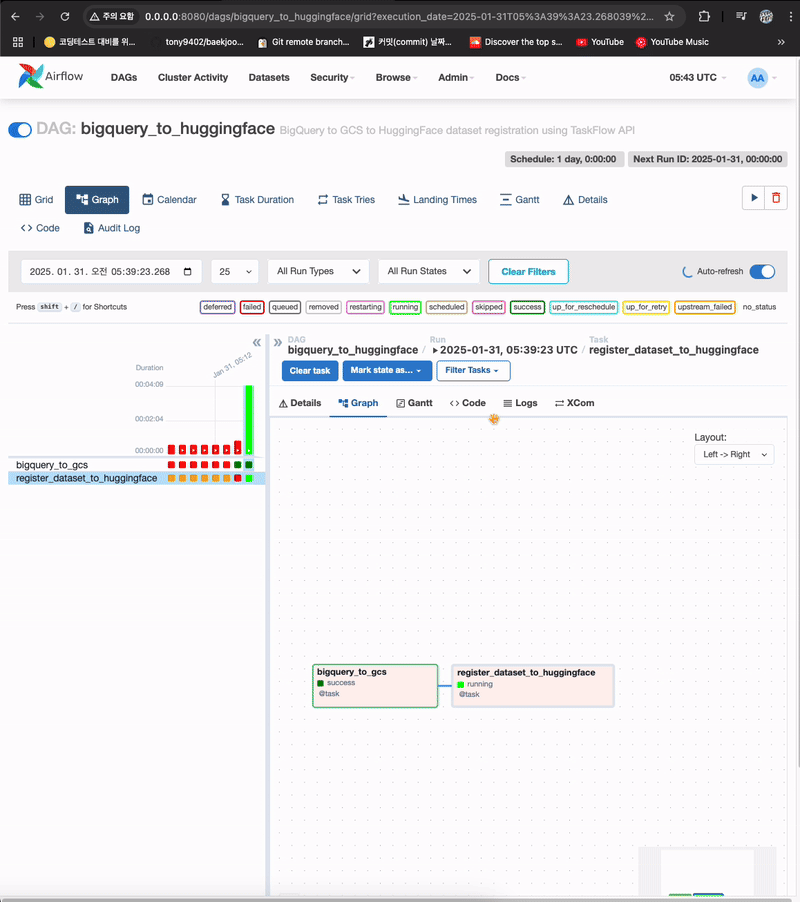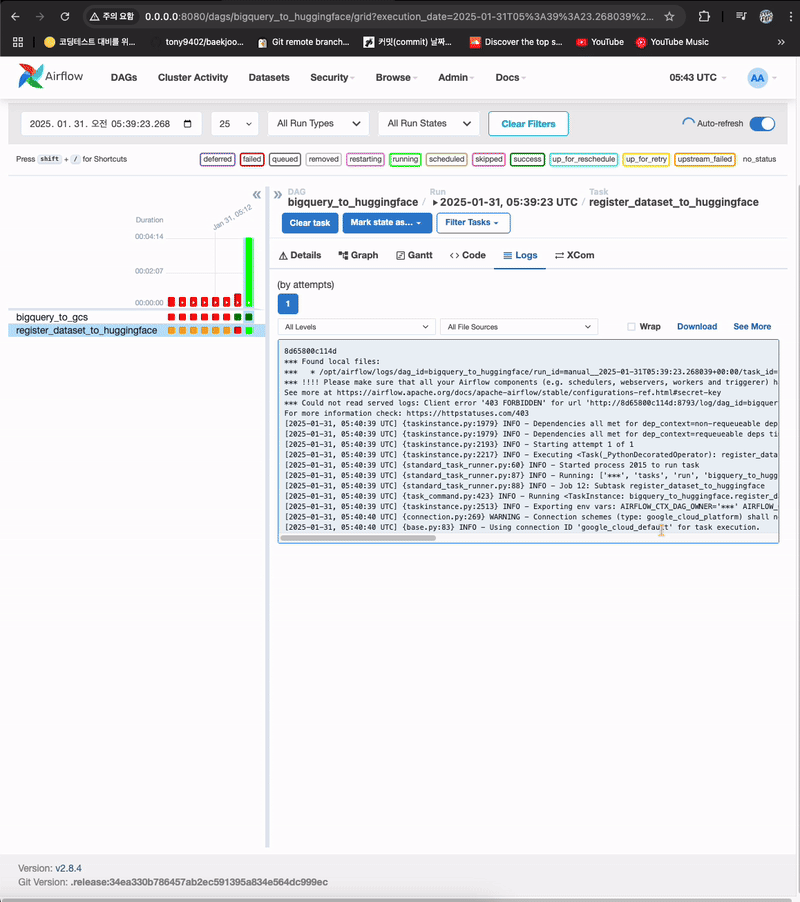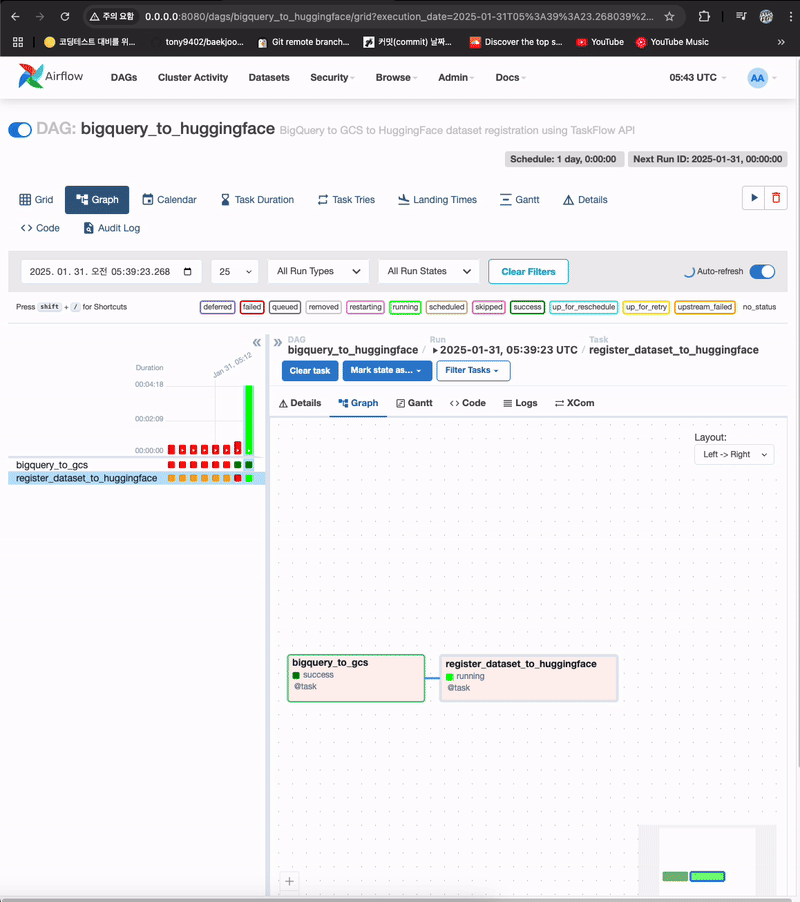
- 허깅페이스에서 확인
4-5. 데이터 아키텍처
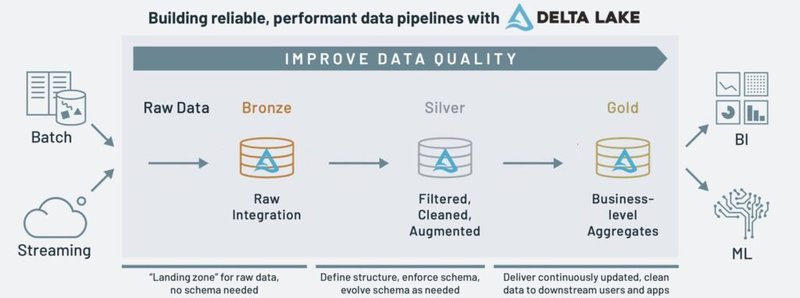
메달리온 아키텍처
- 원시 데이터인 Raw Data를 분석에 적합한 데이터로 점진 개선
- 데이터의 쳬계적 관리 및 정제로 데이터 신뢰성 및 가치 향상
메달리온 아키텍처가 필요한 이유
-
데이터 품질 향상
- 레이어를 거치는 과정을 통해 데이터가 정제, 검증, 보강되어 품질 향상 효과가 있음
-
데이터 거버넌스 강화
- 데이터 흐르 및 책임 소재가 명확해짐
-
데이터 민주화
- 정제 데이터의 경우, 사용자가 더 쉽게 접근 및 활용 가능
-
분석 속도 향상
- 분석에 적합한 형태로 데이터 제공 가능
-
비용 절감
- 중복 데이터, 불필요한 프로세스 등이 제거됨
-
데이터 신뢰도 향상
- 데이터 출처, 변환, 품질 정보 및 이력이 투명하게 관리됨
품질 단계
-
https://www.databricks.com/kr/glossary/medallion-architecture
-
Bronze
- Raw Data를 DW로 적재하기 위한 정형화 혹은 스키마 타입 맞추기 등의 작은 변환만 거친 거의 원본 상태인 데이터
- 변경 불가능
- 데이터의 출처 추적
- 구조화, 반구조화, 비구조화 데이터 모두 수용 가능
- 데이터 레이크 형식: AWS S3, Azure Data Lake Storage, Google Cloud Storage 등의 클라우드 스토리지에 저장됨
- 파일 형식: JSON, CSV, Parquet, Avro 등 자유롭게 적용 가능
-
Silver
- Cleaning 적용
- 데이터 정제
- 데이터 검증
- 데이터 보강
- 데이터 변환
- 스키마 적용
- Invalid Vlaue 필터링 결과물
- 일부 데이터 손실 O
- 건드리지 않은 부분에 한해서는 원본과 다르지 않음
- 데이터 레이크하우스 테이블: Delta Lake, Apache Hudi, Apache Iceberg 등을 통한 테이블 형태 저장
- ACID 트랜잭션 사용 가능
- Cleaning 적용
-
Gold
- Business Insight
- Silver 데이터를 Join, Aggregation 등으로 가공
- 비즈니스 혹은 프로젝트에 필요한 데이터로 정제한 최종 결과물임
- 정제 과정으로 대부분의 데이터 손실 발생을 피할 수는 없음
- 데이터 모델링, 머신러닝 모델 학습, 사용자 친화적 데이터 제공이 가능한 단계
- 데이터 레이크하우스 테이블: Silver와 동일
- 데이터 웨어하우스: Snowflake, Amazon Redshift, Google BigQuery 등으로 데이터 로드 가능
- API, 대시보드, 보고서: 사용자 친화적이기 때문에 다양하게 적용 가능
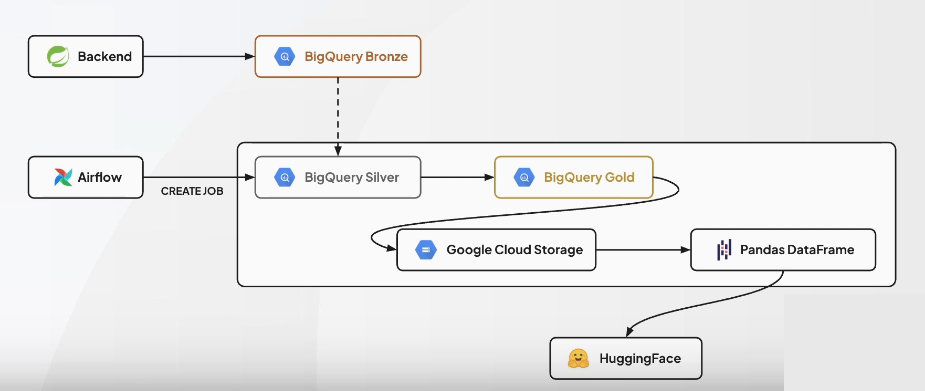
메달리온 아키텍쳐
-
구성 요소
-
데이터 레이크 : 원시 데이터 저장 공간
- AWS S3, Azure Data Lake Storage, Google Cloud Storage
-
데이터 레이크하우스 : 데이터 레이크 + 테이블, ACID 트랜잭션, 스키마 관리 등 제공
- Delta Lake, Apache Hudi, Apache Iceberg
-
데이터 처리 엔진
- Apache Spark, Apache Flink, Databricks
-
데이터 카탈로그: 메타 데이터 관리 및 검색
- AWS Glue Data Catalog, Azure Data Catalog
-
데이터 거버넌스 도구: 데이터 접근 제어, 데이터 품질 관리, 데이터 lineage 등을 추적
- Apache Ranger, Apache Atlas
-
오케스트레이션 도구: 데이터 파이프라인의 자동화 & 관리
- Apache Airflow, AWS Step Functions, Azure Data Factory
-
BI 및 분석 도구: 데이터 시각화 및 분석
- Tableau, Power BI, Looker
-
Airflow 한계
-
Runner 분산에 최적화되지 않은 상태
- Dataflow 분산 프로세싱 처리의 연동이 반드시 필요함
-
Streamming 미지원
- Dataflow 스트리밍 프로세스를 이용해야 함
-
Task 사이의 데이터 전송이 효율적이지 않음
- Dataflow 파이프라인으로 데이터 프로세싱 전과정을 덮어줘야 함
-
데이터 보안에 약함
- Dataflow Google Managed Encrpytion Key를 활용해야 함
참고 자료
