
이미지 출처는 링크 or 아이펠 교육 자료입니다.
5-1. 파이프라인 개요
학습 목표
- CI/CD 소개
- 모델 학습 파이프라인 개요
- 모델 배포 파이프라인 개요
- 예제 학습
CI/CD
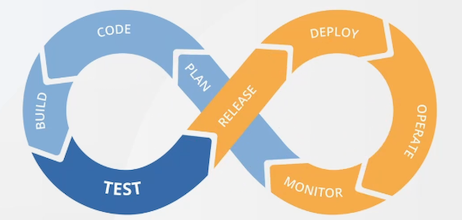
- 소프트웨어 개발 생애 주기에서의 CI(지속 통합), CD(지속 배포)로 코드 변경점을 자동화, 검증, 배포까지의 프로세스를 운영하는 것
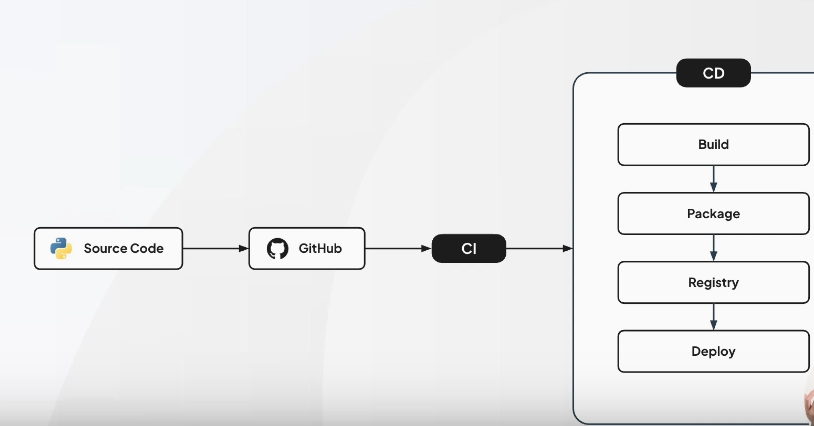
CI(Continuous Integration)
Linting: Lint 설정을 통해 코드 스타일이 지켜지지 않을 경우, 코드 베이스에 병합하지 못하도록 할 수 있음Testing: 코드의 양이 많아질수록 반드시 필요Validation: 검증 없이 적용할 경우, 추후 문제가 많이 발생할 수 있음(보안 이슈 등)Docs: 파라미터에 대한 설명이 필수임

CD(Continuous Delivery)
BuildPackageRegistryDeploy
GitHub Actions
- GitHub에서 제공하는 CI/CD 워크 플로우 자동화 파이프라인 도구
- yaml로 쉽게 구성 및 관리 가능
5-2. 예제 실습: CI/CD 파이프라인 Part.1
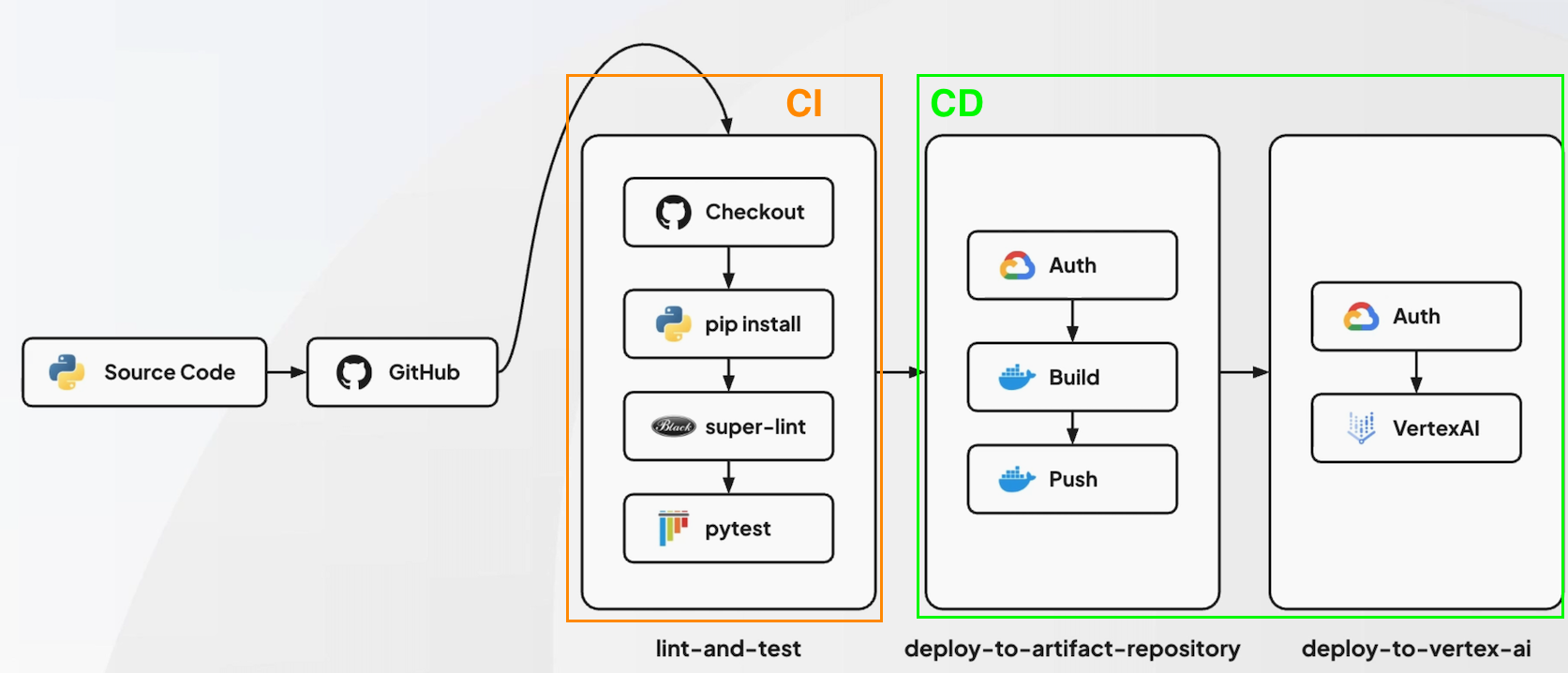
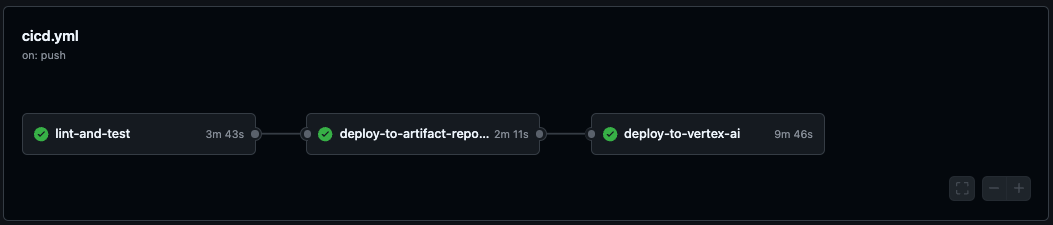
CI/CD 워크플로우 구조
- 코드 구현(모델링) 및 테스팅 :
lint-and-test - deploy:
deploy-to-artifact-repository - 모델 최종 배포 :
vertex AI
GitHub Actions
1. Repository Fork & Clone
$ git clone https://github.com/hayannn/mlops-quicklab-cicd.git
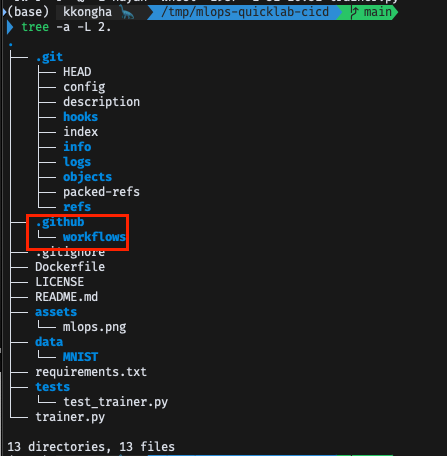
. 파일은 기본적으로 보이지 않도록 설정되어 있음
$ls -al
$ tree -a -L 2.


2. cicd.ymal
lint-and-test- 대부분의 기초적인 세팅과 라이브러리 등은 GitHub Actions에서 지원해줌
jobs:
lint-and-test:
runs-on: ubuntu-latest
steps:
- name: Checkout code
uses: actions/checkout@v2
- name: Set up Python
uses: actions/setup-python@v2
with:
python-version: "3.11"
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install -q -r requirements.txt
pip install -q black isort mypy pytest pytest-cov
- name: Run Super-Linter with Black
uses: super-linter/super-linter@v6.4.1
env:
DEFAULT_BRANCH: main
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
VALIDATE_PYTHON_BLACK: true
PYTHON_BLACK_CONFIG: "--check --diff"
- name: Train model for testing
run: python trainer.py
- name: Run tests with Pytest
run: PYTHONPATH=$(pwd) pytest tests/Super-Linter?
- https://github.com/super-linter/super-linter
- super linter를 이용하면 다양한 기능을 강력하게 사용 가능
- 해당 프로젝트에서는 Black을 사용하기 위해 끌어옴
3. trainer.py
- MNIST 사용
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
input_size = 784
hidden_size = 128
num_classes = 10
num_epochs = 5
batch_size = 100
learning_rate = 0.001
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
train_dataset = datasets.MNIST(
root="data", train=True, transform=transforms.ToTensor(), download=True
)
test_dataset = datasets.MNIST(root="data", train=False, transform=transforms.ToTensor())
train_loader = DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=False)
class NeuralNet(nn.Module):
def __init__(self):
super(NeuralNet, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(hidden_size, num_classes)
def forward(self, x):
out = self.fc1(x)
out = self.relu(out)
out = self.fc2(out)
return out
model = NeuralNet().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
def train():
total_step = len(train_loader)
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(train_loader):
images = images.reshape(-1, 28 * 28).to(device)
labels = labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i + 1) % 100 == 0:
print(
f"Epoch [{epoch+1}/{num_epochs}], Step [{i+1}/{total_step}], Loss: {loss.item():.4f}"
)
def save_model():
model_path = "model.pth"
torch.save(model.state_dict(), model_path)
print(f"Model saved to {model_path}")
if __name__ == "__main__":
train()
save_model()코드 실행해보기
$ conda activate quicklab-modu $ pip3 install -r requirements.txt
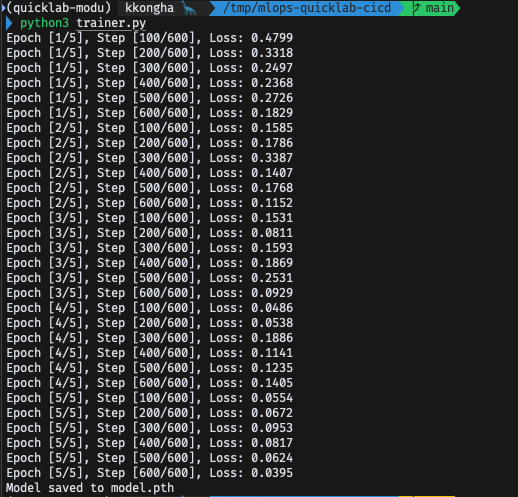
- model.pth가 저장되었을 것 -> 추후 작업을 위해 우선 삭제
$ rm -rf model.pth4. Rulesets 적용
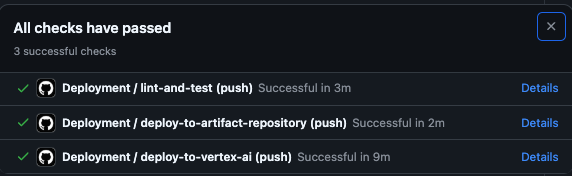
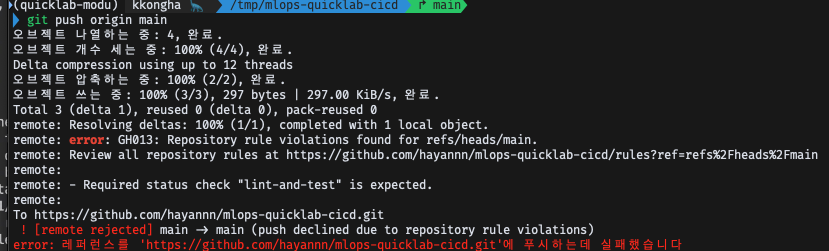
lint-and-test가 정상적으로 실행된 후에만, Push 작업이 이뤄질 수 있도록 설정
테스트
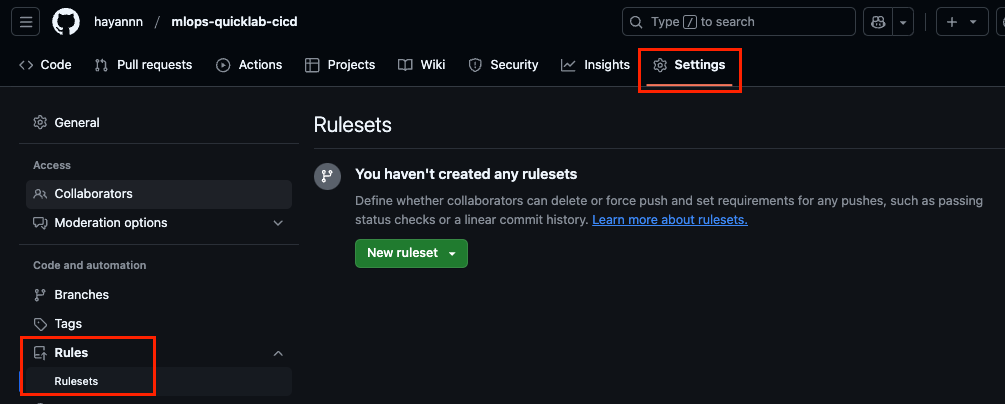
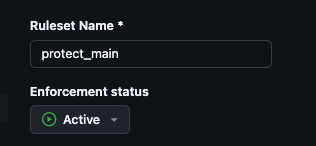
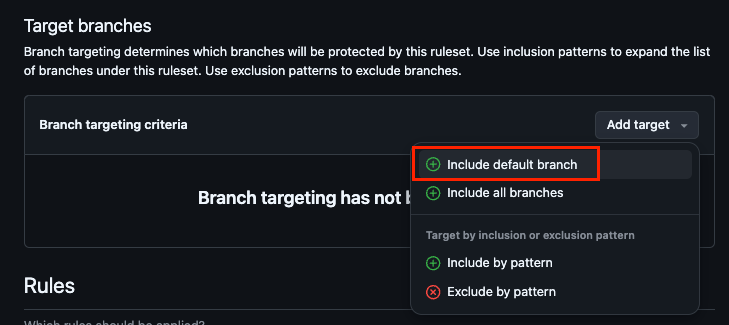
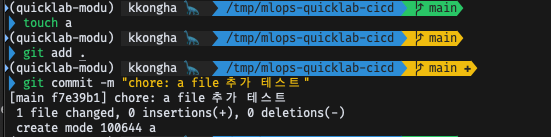
- GitHub Actions Rulesets 설정(Enforcement Active로 설정)
- a 파일 생성 후, commit
- push 시도 ➡️ reject 되어야 함!
- 이전 커밋으로 원복

5. 새로운 작업 추가
- MNIST의 파라미터 입력 사이즈를 조정했다고 가정
- 새 브랜치 생성
$ git switch -c feat/update-nueron-size-
trainer.py의 input size 변경 후 저장

-
add&commit
$ git add .
$ git commit -m "feat: change input size from 784 to 812"- 만든 브랜치 push
$ git push origin feat/update-nueron-size
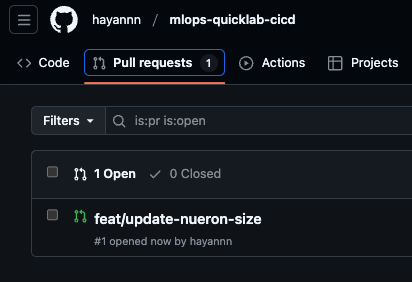
- PR & Merge
- 깃허브 CLI 기능 이용
- 사용을 위해서는 설치해야함(Mac의 경우 brew로 설치)
$ gh auth login

$ gh pr create --title "$(git rev-parse --abbrev-ref HEAD)"
-
보통은 바로 Merge가 활성화되지만, 위의 Ruleset 설정에 의해 바로 설정되지 않는 모습
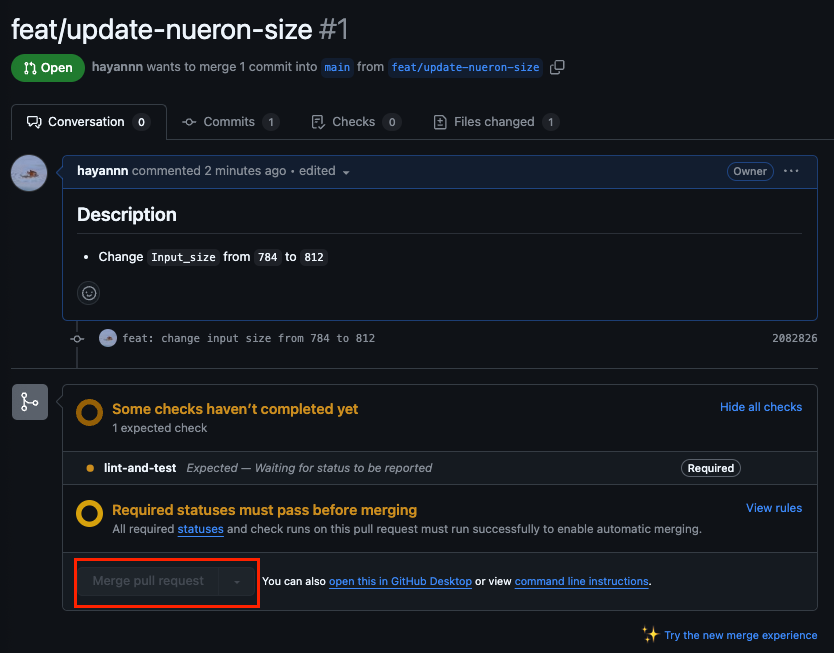
-
우선은 close하여 PR 취소하기 & 브랜치까지 삭제하기

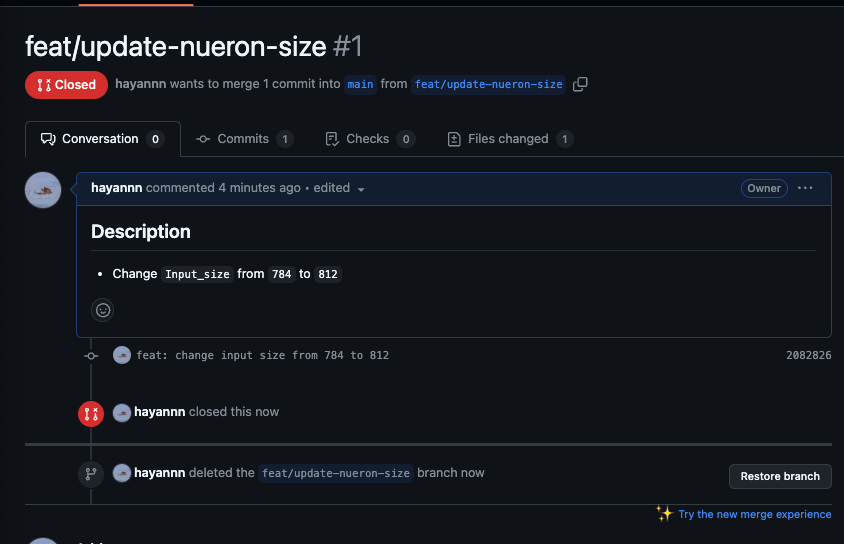
-
CLI에서도 main 브랜치로 돌아가, 만든 브랜치 삭제
$ git checkout main
$ git branch -D feat/update-nueron-size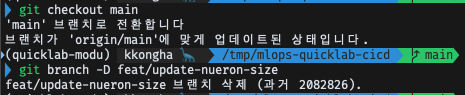
5-3. 예제 실습: CI/CD 파이프라인 파트 2
1. cicd.yaml_deploy-to-vertex-ai
google-github-actions: 별도 추가 설정 없이 이용할 수 있도록 해줌
deploy-to-artifact-repository:
runs-on: ubuntu-latest
needs: lint-and-test
steps:
- name: Checkout code
uses: actions/checkout@v3
- name: Get short SHA
id: slug
run: echo "::set-output name=sha::$(git rev-parse --short HEAD)"
- id: auth
uses: google-github-actions/auth@v2
with:
credentials_json: "${{ secrets.GCP_SA_KEY }}"
- name: Set up Cloud SDK
uses: google-github-actions/setup-gcloud@v2
- name: Build and push Docker image to Artifact Registry
run: |
gcloud auth configure-docker $REGION-docker.pkg.dev
docker build -t $REGION-docker.pkg.dev/$PROJECT_ID/$ARTIFACT_REPO_NAME/$CUSTOM_IMAGE:${{ steps.slug.outputs.sha }} .
docker push $REGION-docker.pkg.dev/$PROJECT_ID/$ARTIFACT_REPO_NAME/$CUSTOM_IMAGE:${{ steps.slug.outputs.sha }}2. GCP_IAM 키 생성
서비스 계정 만들기로 생성
-
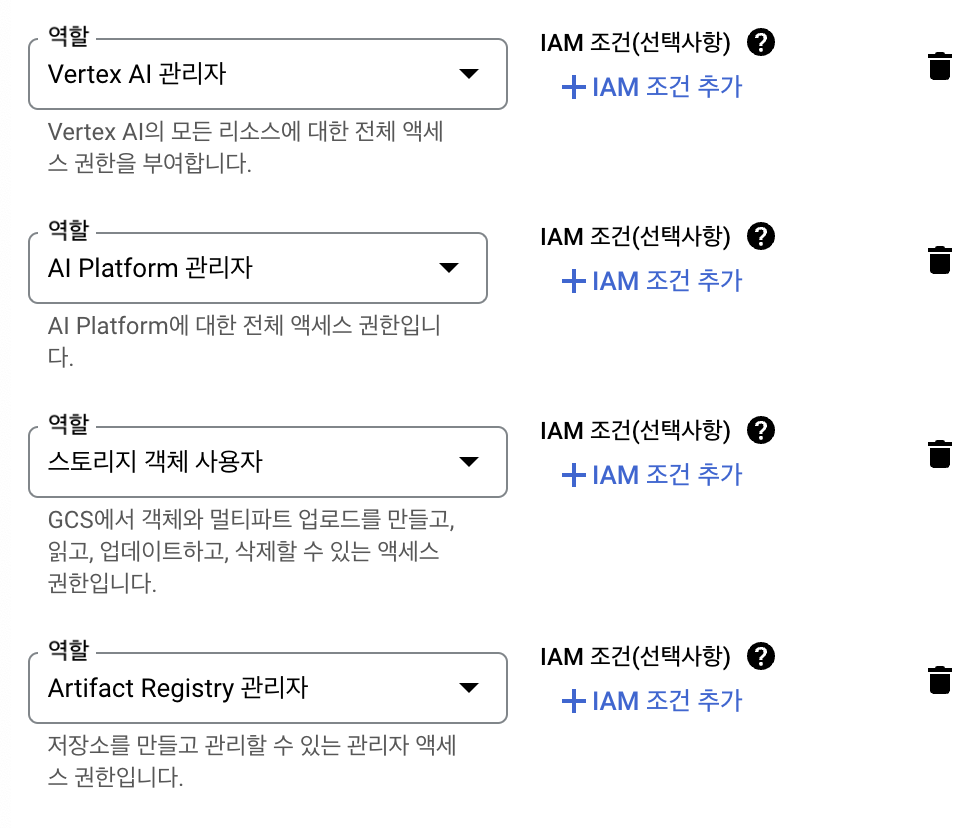
⭐️역할 선택⭐️
- Vertex AI 관리자
- AI Platform 관리자
- 스토리지 객체 사용자
- Artifact Registry 관리자
-
키 생성
- 키 > 키 추가 > 새로 만들기
- 키 > 키 추가 > 새로 만들기
- 다운받은 키(JSON) 내용 copy & 깃허브 액션 시크릿 키 등록(
GCP_SA_KEY)


GCP_PROJECT_ID: GCP 프로젝트 IDGCP_BUCKET_NAME: GCP 스토리지에서 버킷 생성 -> 그 이름을 넣어주면 됨

- 이름 : mlops-cicd와 같은 이름
- Multi region
- 만들기
GCP_ARTIFACT_REPO_NAME: 만든 저장소 이름- artifact registry
- 저장소 만들기
- 이름 자유롭게 설정
- 형식 :
Docker - 리전 :
asia-northeast3(서울) - 나머지는 기본 옵션으로 지정하고, 만들기
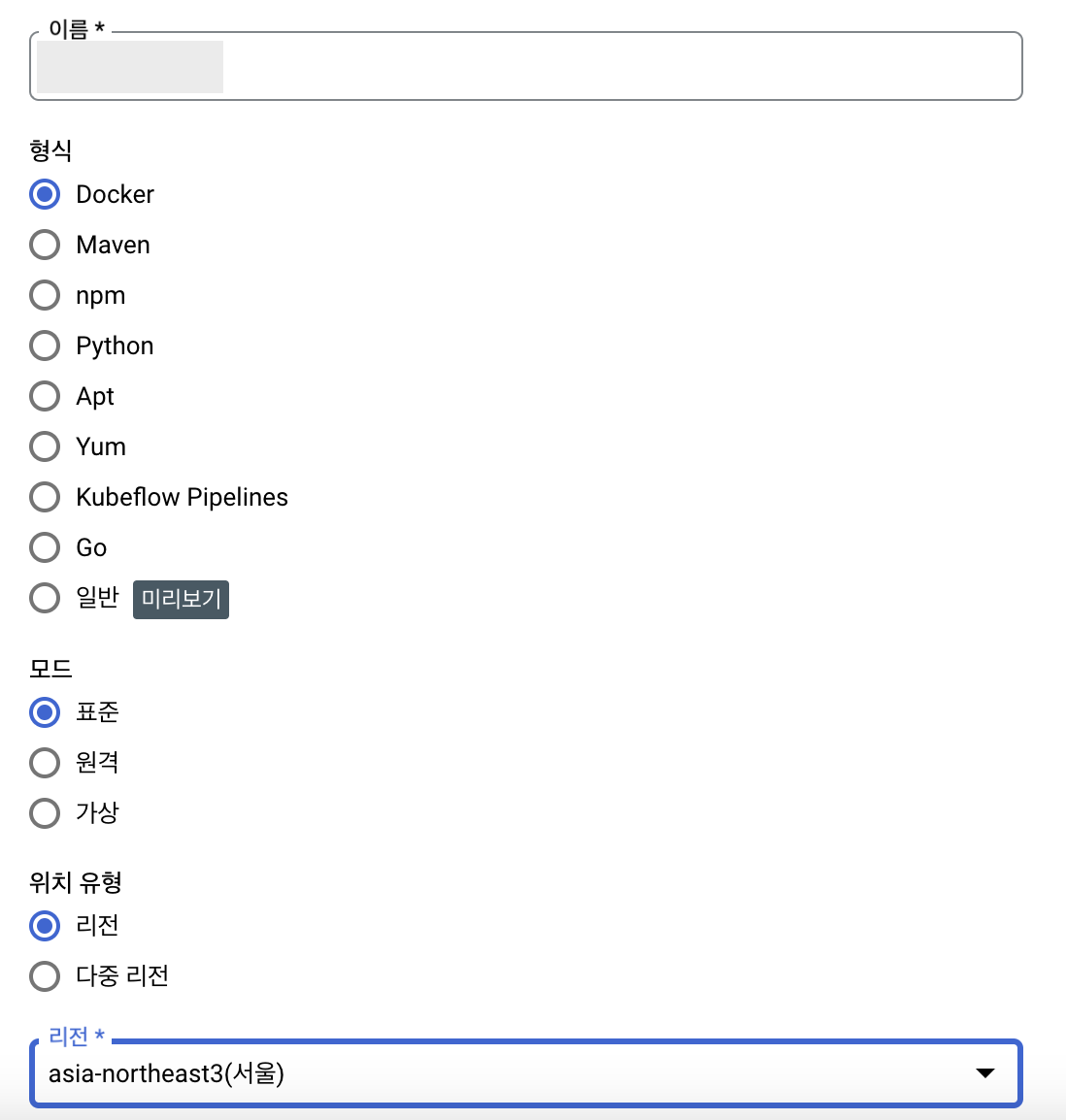
- artifact registry
5-4. 예제 실습: CI/CD 파이프라인 Part.3
1. cicd.yaml
-
deploy-to-artifact-repository- gcloud auth configure-docker를 이용해 Docker 바로 적용
- MNIST 트레이닝 코드가 포함되어 있는 각종 환경들을 패키징
-
deploy-to-vertex-ai- 앞서 생성한 도커 이미지를 이용해 vertex ai를 구동하고, training job을 실행
- ⭐️
Free disk space⭐️- Docker에서 기본으로 제공해주는 모든 코드를 날리는 형식
- GitHub Actions를 유료로 사용하고 있지 않다보니, 다른 필요 없는 코드들을 삭제함으로써 공간 확보
deploy-to-artifact-repository:
runs-on: ubuntu-latest
needs: lint-and-test
steps:
- name: Checkout code
uses: actions/checkout@v3
- name: Get short SHA
id: slug
run: echo "::set-output name=sha::$(git rev-parse --short HEAD)"
- id: auth
uses: google-github-actions/auth@v2
with:
credentials_json: "${{ secrets.GCP_SA_KEY }}"
- name: Set up Cloud SDK
uses: google-github-actions/setup-gcloud@v2
- name: Build and push Docker image to Artifact Registry
run: |
gcloud auth configure-docker $REGION-docker.pkg.dev
docker build -t $REGION-docker.pkg.dev/$PROJECT_ID/$ARTIFACT_REPO_NAME/$CUSTOM_IMAGE:${{ steps.slug.outputs.sha }} .
docker push $REGION-docker.pkg.dev/$PROJECT_ID/$ARTIFACT_REPO_NAME/$CUSTOM_IMAGE:${{ steps.slug.outputs.sha }}
deploy-to-vertex-ai:
runs-on: ubuntu-latest
needs: deploy-to-artifact-repository
steps:
- name: Free disk space
run: |
sudo docker rmi $(docker image ls -aq) >/dev/null 2>&1 || true
sudo rm -rf \
/usr/share/dotnet /usr/local/lib/android /opt/ghc \
/usr/local/share/powershell /usr/share/swift /usr/local/.ghcup \
/usr/lib/jvm || true
sudo apt install aptitude -y >/dev/null 2>&1
sudo aptitude purge aria2 ansible azure-cli shellcheck rpm xorriso zsync \
esl-erlang firefox gfortran-8 gfortran-9 google-chrome-stable \
google-cloud-sdk imagemagick \
libmagickcore-dev libmagickwand-dev libmagic-dev ant ant-optional kubectl \
mercurial apt-transport-https mono-complete libmysqlclient \
unixodbc-dev yarn chrpath libssl-dev libxft-dev \
libfreetype6 libfreetype6-dev libfontconfig1 libfontconfig1-dev \
snmp pollinate libpq-dev postgresql-client powershell ruby-full \
sphinxsearch subversion mongodb-org azure-cli microsoft-edge-stable \
-y -f >/dev/null 2>&1
sudo aptitude purge google-cloud-sdk -f -y >/dev/null 2>&1
sudo aptitude purge microsoft-edge-stable -f -y >/dev/null 2>&1 || true
sudo apt purge microsoft-edge-stable -f -y >/dev/null 2>&1 || true
sudo aptitude purge '~n ^mysql' -f -y >/dev/null 2>&1
sudo aptitude purge '~n ^php' -f -y >/dev/null 2>&1
sudo aptitude purge '~n ^dotnet' -f -y >/dev/null 2>&1
sudo apt-get autoremove -y >/dev/null 2>&1
sudo apt-get autoclean -y >/dev/null 2>&1
sudo rm -rf ${GITHUB_WORKSPACE}/.git
- id: auth
uses: google-github-actions/auth@v2
with:
credentials_json: "${{ secrets.GCP_SA_KEY }}"
- name: Set up Cloud SDK
uses: google-github-actions/setup-gcloud@v2
- name: Submit Vertex AI training job
run: |
gcloud auth configure-docker $REGION-docker.pkg.dev
gcloud ai custom-jobs create \
--project ${{ env.PROJECT_ID }} \
--region=${{ env.REGION }} \
--display-name=mnist-training-job \
--worker-pool-spec=machine-type=n1-standard-4,executor-image-uri=asia-docker.pkg.dev/vertex-ai/training/pytorch-gpu.1-13.py310:latest,output-image-uri=$REGION-docker.pkg.dev/$PROJECT_ID/$ARTIFACT_REPO_NAME/$JOB_IMAGE,local-package-path=.,python-module=trainer \
--args="--model-dir=gs://${{ secrets.GCP_BUCKET_NAME }}/models"5-5. Vertex AI 파이프라인_Part.1
모델 학습 과정
데이터 웨어하우스
- 데이터 취득
오프라인 모델 모니터링 시스템
- 데이터 검증
- 데이터 전처리
- 모델 학습
- 모델 검증
- 모델 최적화
모델 레지스트리
- 모델 등록
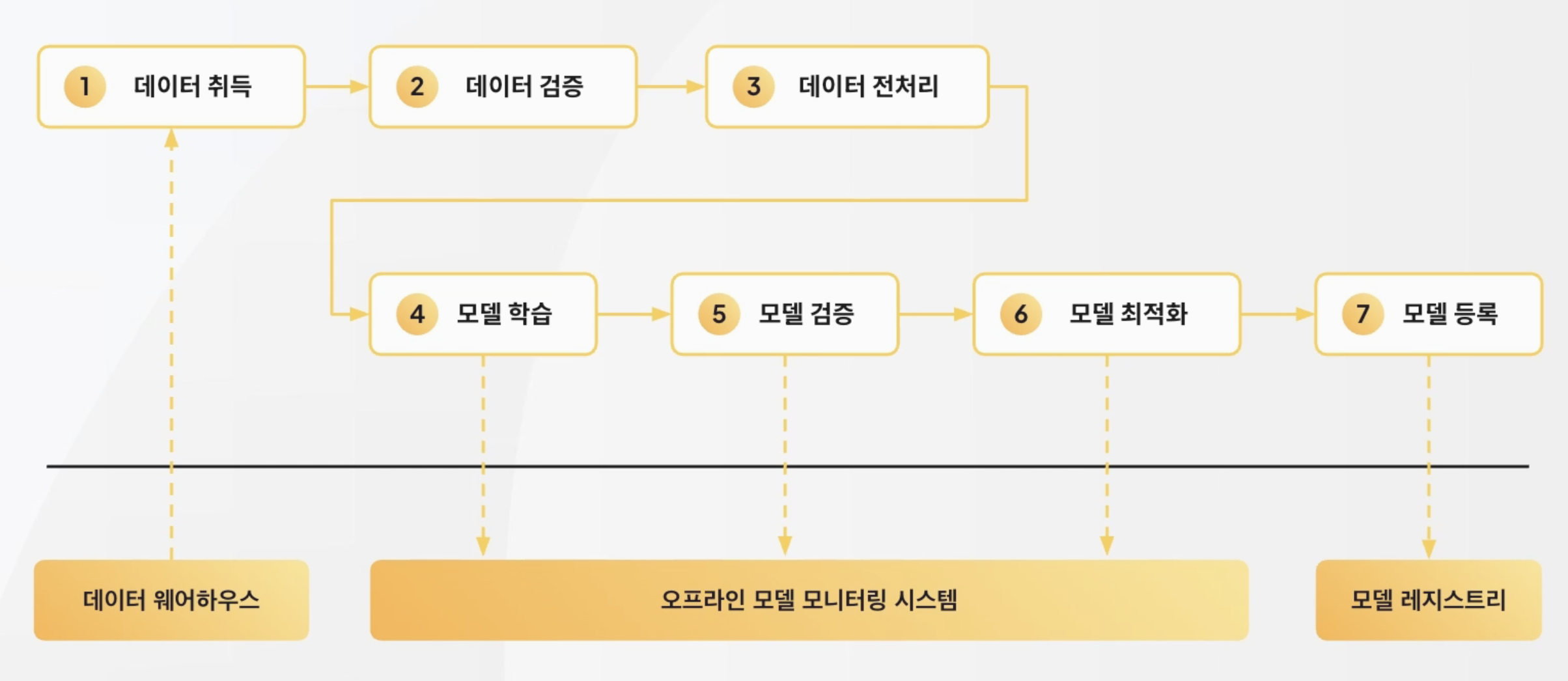
모델 학습 과정_1. 데이터 취득

- 모델에 필요한 데이터 ➡️ 중앙 데이터 저장소 or 데이터셋 보관 장소로 Load
- 데이터 검증, 전처리를 위한 객체(인터페이스) 정의
모델 학습 과정_2. 데이터 검증

- 데이터 검증 과정
- 데이터의 Feature, 타입 일치 여부, 누락된 값이 있는지 여부 등을 검증
- 무결성 검증은 아님(데이터 파이프라인에서 무결성 검증함)
모델 학습 과정_3. 데이터 변환

- 데이터 전처리
- Feature 전처리
- 필요한 데이터만 필터링, 피쳐 스케일링, 정규화 등 필요한 단계 진행
- 데이터가 Numpy or Tensor로 변환(data loader로 split을 진행함)
모델 학습 과정_4. 모델 학습

- 모델 아키텍쳐에 학습 프로세스를 진행하는 단계
- 모델 파라미터 업데이트 & 학습 step별 로그 기록(모델 학습에 고성능 컴퓨터가 필요함)
모델 학습 과정_5. 모델 검증

- 학습 시 사용한 test 데이터셋과는 다른 validation 데이터셋 사용 -> 특정 시나리오 or 파티션에서 모델 품질의 적절성 평가
- 데이터 bias 예방을 위함
- 서비스에 제공이 가능한 최소 기준을 통과하는지 여부를 파악하기 위함
모델 학습 과정_6. 모델 최적화

- 모델 가중치 및 아키텍쳐의 경량화
- 경량화 : Pruning, Quantization, 파라미터 사이즈가 적은 모델에는 Knowledge Distillation 적용
- 경량화 후 추가 검증까지 마침
모델 학습 과정_7. 모델 등록
- 학습된 모델 가중치 + 모델 아키텍쳐 + 아티팩트
- 모델 성능 지표와 같이 모델 저장소에 등록(그 체크 포인트의)
- 모델에 버전 정보 및 구분자 지정 -> 모델 배포 단계에서 이 내용으로 구분해 모델을 로드
모델 배포 방식_수동 배포
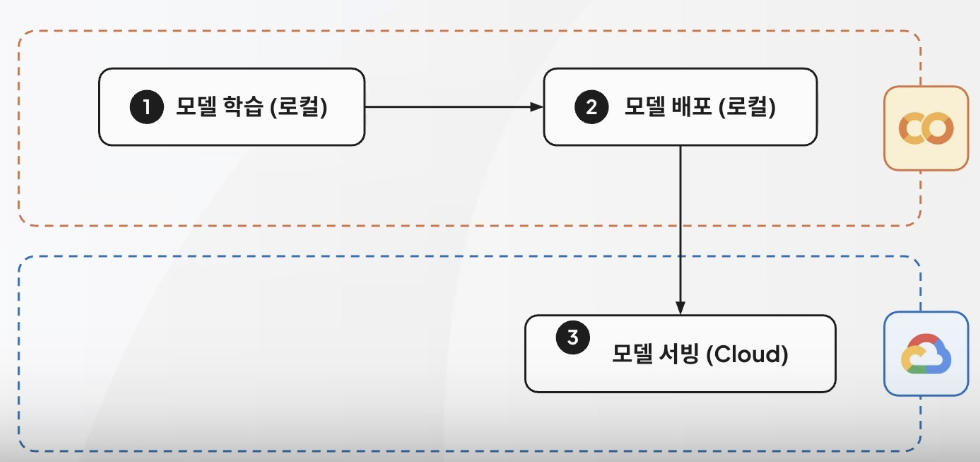
5-6. Vertex AI 파이프라인_Part.2
주의: T4 GPU 사용할 것!
필요한 라이브러리 설치
!pip install datasets torchserve torch-model-archiver torch-workflow-archiver nvgpu
라이브러리 import & news 데이터셋 기초 설정
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import seaborn as sns
from torch.utils.data import DataLoader
from transformers import BatchEncoding, BertTokenizer, BertForSequenceClassification, AdamW
from sklearn.metrics import confusion_matrix
from datasets import load_dataset
from tqdm import tqdm
from typing import TypedDict
import matplotlib.pyplot as plt- 모델 트레이닝 설정
dataset = load_dataset("ag_news")
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
model = BertForSequenceClassification.from_pretrained("bert-base-uncased", num_labels=4)
optimizer = AdamW(model.parameters(), lr=5e-5)
criterion = torch.nn.CrossEntropyLoss()
class DatasetItem(TypedDict):
text: str
label: str
def preprocess_data(dataset_item: DatasetItem) -> dict[str, torch.Tensor]:
return tokenizer(dataset_item["text"], truncation=True, padding="max_length", return_tensors="pt")
train_dataset = dataset["train"].select(range(1200)).map(preprocess_data, batched=True)
test_dataset = dataset["test"].select(range(800)).map(preprocess_data, batched=True)
train_dataset.set_format("torch", columns=["input_ids", "attention_mask", "label"])
test_dataset.set_format("torch", columns=["input_ids", "attention_mask", "label"])
train_loader = DataLoader(train_dataset, batch_size=8, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=8, shuffle=False)
모델 학습
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
num_epochs = 3
losses: list[float] = []
for epoch in range(num_epochs):
model.train()
total_loss = 0
for batch in tqdm(train_loader, desc=f"Epoch {epoch + 1}"):
inputs = {key: batch[key].to(device) for key in batch}
labels = inputs.pop("label")
outputs = model(**inputs, labels=labels)
loss = outputs.loss
total_loss += loss.item()
losses.append(loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
average_loss = total_loss / len(train_loader)
print(f"Epoch {epoch + 1}, Average Loss: {average_loss}")
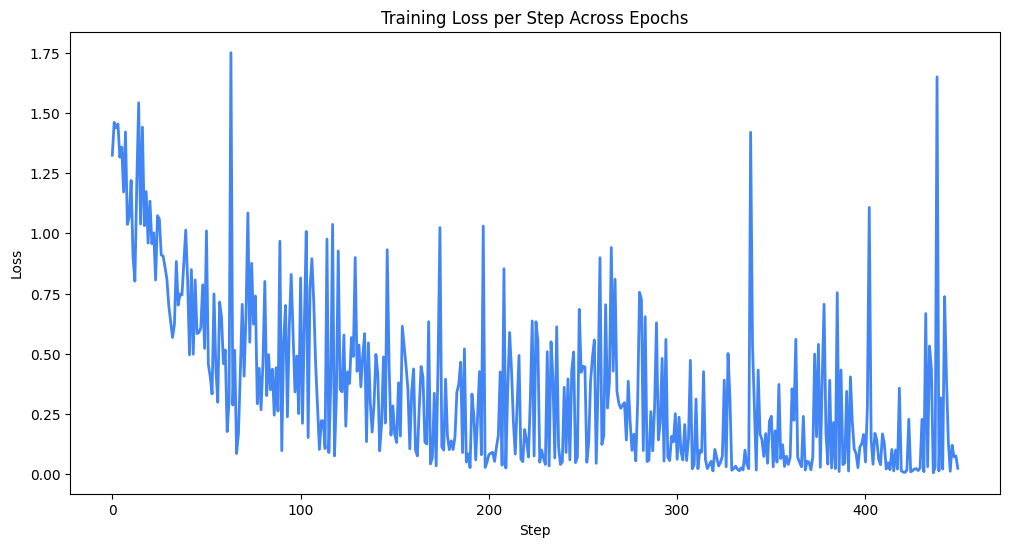
모델 평가
model.eval()
correct = 0
total = 0
with torch.no_grad():
for batch in tqdm(test_loader, desc="Evaluating"):
inputs = {key: batch[key].to(device) for key in batch}
labels = inputs.pop("label")
outputs = model(**inputs, labels=labels)
logits = outputs.logits
predicted_labels = torch.argmax(logits, dim=1)
correct += (predicted_labels == labels).sum().item()
total += labels.size(0)
accuracy = correct / total
print("")
print(f"Test Accuracy: {accuracy * 100:.2f}%")
모델 테스트
test_input = "[Official] 'Legendary Coach Resigns → Appoints New Commander' Suwon Completes Coaching Staff... Scout Bae Ki-jong Joins + Coach Shin Hwa-yong Remains"
test_input_processed = tokenizer(test_input, truncation=True, padding="max_length", return_tensors="pt").to(device)
logits = model(**test_input_processed).logits
print(logits)
predicted_labels = torch.argmax(logits, dim=1)
labeling_mapper = ["world", "sports", "business", "sci/tech"]
print(labeling_mapper[predicted_labels[0]])
혼동 행렬 확인

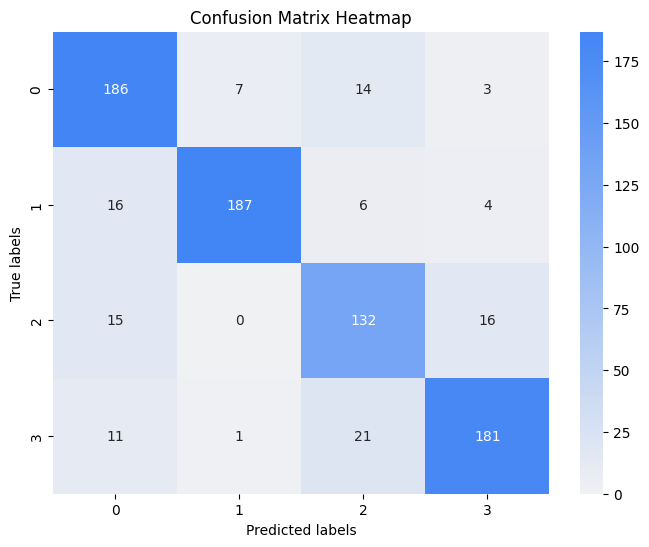
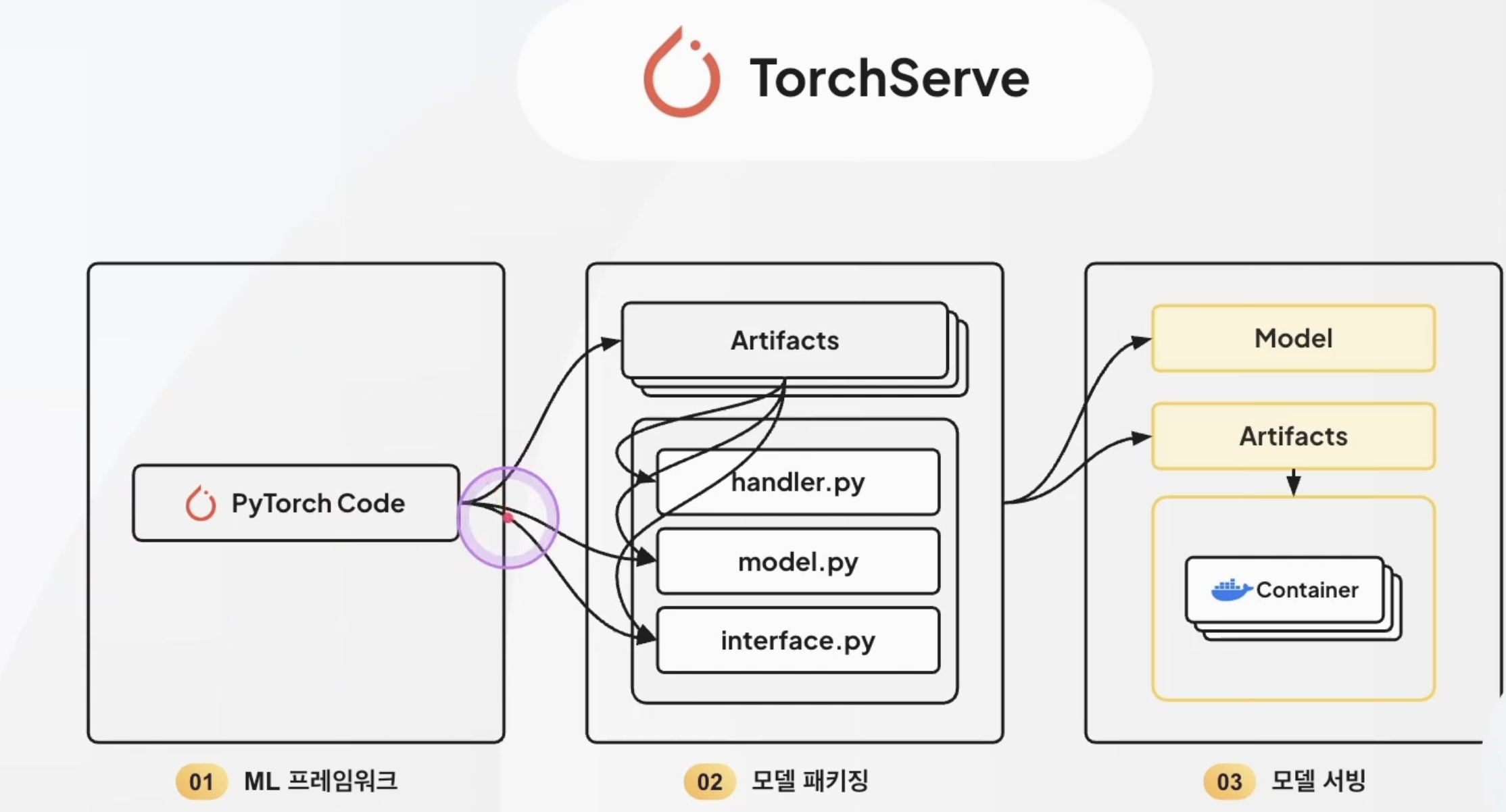
TorchServe로 Archive하기
# 모델 체크포인트 저장
model_save_path = "model.pth"
torch.save(model.state_dict(), model_save_path)- 모델 핸들러 등록
%%writefile handler.py
import json
import logging
import torch
from ts.context import Context
from ts.torch_handler.base_handler import BaseHandler
from transformers import BatchEncoding, BertTokenizer, BertForSequenceClassification
logging.basicConfig(level=logging.INFO)
class ModelHandler(BaseHandler):
def __init__(self):
self.initialized = False
self.tokenizer = None
self.model = None
def initialize(self, context: Context):
properties = context.system_properties
model_dir = properties.get("model_dir")
self.initialized = True
self.tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
self.model = BertForSequenceClassification.from_pretrained("bert-base-uncased", num_labels=4)
model_path = model_dir + "/model.pth"
self.model.load_state_dict(torch.load(model_path))
self.model.to(torch.device("cuda" if torch.cuda.is_available() else "cpu"))
self.model.eval()
def preprocess(self, texts: list[str]) -> BatchEncoding:
logging.info("preprocess", texts)
inputs = self.tokenizer(texts, truncation=True, padding=True, max_length=512, return_tensors="pt")
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
return inputs.to(device)
def inference(self, input_batch: BatchEncoding) -> torch.Tensor:
with torch.no_grad():
outputs = self.model(**input_batch)
logging.info("inference", outputs)
return outputs.logits
def postprocess(self, inference_output: torch.Tensor) -> list[dict[str, float]]:
logging.info("postprocess", inference_output)
probabilities = torch.nn.functional.softmax(inference_output, dim=1)
return [{"label": int(torch.argmax(prob)), "probability": float(prob.max())} for prob in probabilities]- bert vocab 파일을 아티팩트
!wget https://raw.githubusercontent.com/microsoft/SDNet/master/bert_vocab_files/bert-base-uncased-vocab.txt \
-O bert-base-uncased-vocab.txt- Torch serve archiver 저장 위치 생성
!mkdir -p model-store- 아카이빙 진행
!torch-model-archiver \
--model-name model \
--version 1.0 \
--serialized-file model.pth \
--handler ./handler.py \
--extra-files "bert-base-uncased-vocab.txt" \
--export-path model-store \
-f
- 맞춤 GCE VM에 연결해서 사용할 경우
# from google.colab import auth auth.authenticate_user()
GCP_서비스 account 생성
5-5에서 생성한 정보 사용
Colab에 credentials.json 등록
- 루트 폴더에 drag & drop
- 파일 이름을
credentials.json으로 변경

- 파일 이름을
GCP 정보를 Colab에 등록
PROJECT_ID = "gde-project-aicloud" # @param {type: "string"}
LOCATION = "asia-northeast3" # @param {type: "string"}
BUCKET_NAME = "mlops-quicklab" # @param {type: "string"}
MODEL_FILE_NAME = "model.mar" # @param {type: "string"}스토리지 클라이언트 등록
storage_client = storage.Client(credentials=credentials)
bucket = storage_client.bucket(BUCKET_NAME)로컬 코드 파일을 GCP로 옮기기
def upload_blob(source_file_name: str, destination_blob_name: str) -> None:
blob = bucket.blob(destination_blob_name)
blob.upload_from_filename(source_file_name)
print(f"File {source_file_name} uploaded to {destination_blob_name}.")upload_blob("model-store/model.mar", f"models/{MODEL_FILE_NAME}")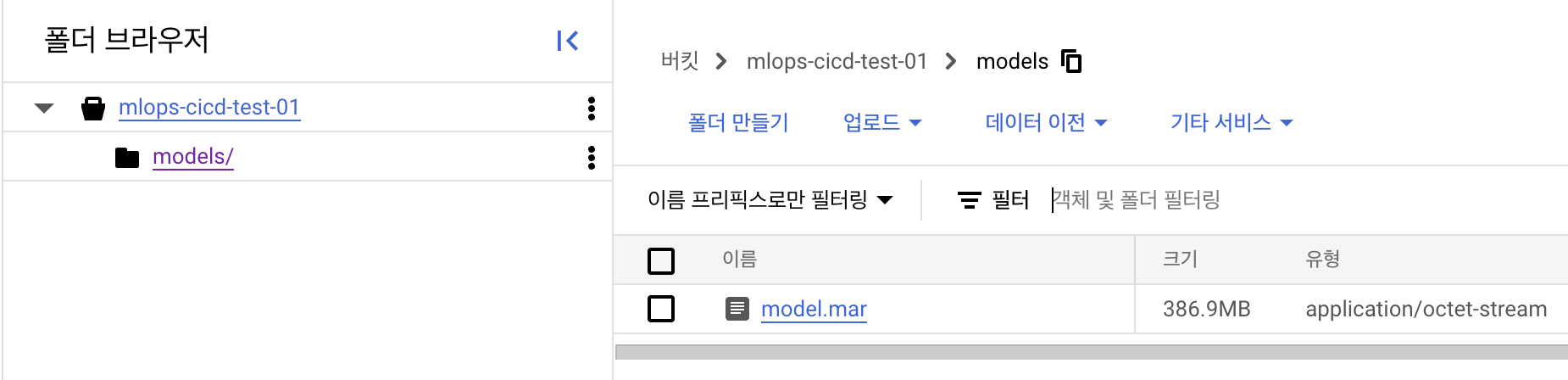
5-7. Vertex AI 파이프라인_Part.3
serving_container_image_uri 만들기
aiplatform.init(
project=PROJECT_ID,
location=LOCATION,
credentials=credentials,
)model_path = f"gs://{BUCKET_NAME}/models"
registry_model = aiplatform.Model.upload(
display_name="AG News Classification",
artifact_uri=model_path,
serving_container_image_uri="asia-northeast3-docker.pkg.dev/gde-project-aicloud/mlops-quicklab/trainer:1.0.3",
is_default_version=True,
version_aliases=["v1"],
version_description="A news category classification model",
serving_container_predict_route="/predictions/model",
serving_container_health_route="/ping",
)mlops-quicklab/vertexai/predictions로 이동

- 내부의 Dockerfile이 image uri 설정에 사용될 것
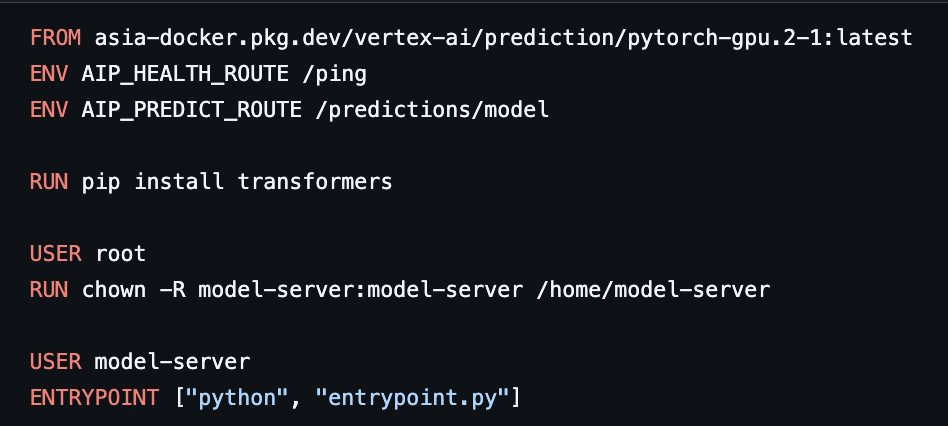
- ENV 파트 지우고 다시 저장
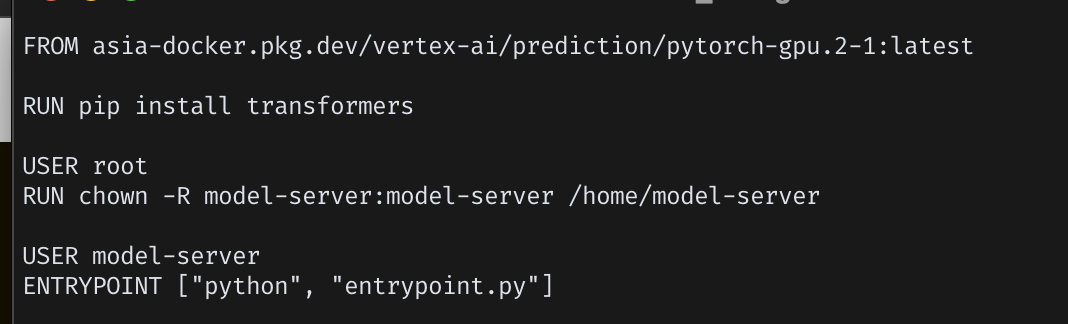
- 내부의 Dockerfile이 image uri 설정에 사용될 것
- docker build
$ docker build . \
-t {실제 내용 입력}/trainer:1.0.0
- image 확인
$ docker images | grep trainer
- gcloud를 이용해 GCP 프로젝트 연결
- gcloud 설치(for MAC):
brew install google-cloud-sdk
- gcloud 설치(for MAC):
$ gcloud auth login


- GCP 프로젝트 연결
$ gcloud config set project {PROJECT_ID}
- Docker 로그인
$ gcloud auth configure-docker asia-northeast3-docker.pkg.dev
- Docker Push
$ docker push asia-northeast3-docker.pkg.dev/mlops-quicklab-449207/mlops-cicd/trainer:1.0.0
Colab에서 실행
model_path = f"gs://{BUCKET_NAME}/models"
registry_model = aiplatform.Model.upload(
display_name="AG News Classification",
artifact_uri=model_path,
serving_container_image_uri="{복사해서 붙여넣기}/trainer:1.0.0",
is_default_version=True,
version_aliases=["v1"],
version_description="A news category classification model",
serving_container_predict_route="/predictions/model",
serving_container_health_route="/ping",
)
- 리전을 서울로 맞춰서 확인

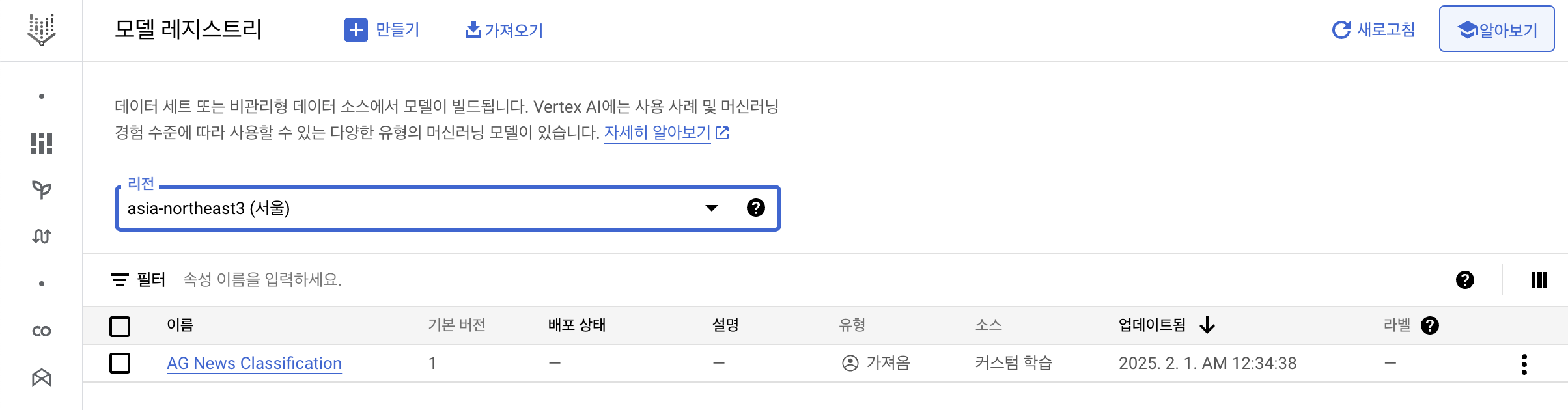
5-8. Vertex AI 파이프라인_Part.4
모델 배포 및 결과 확인
Deploy 설정
DEPLOY_COMPUTE = "n1-standard-2"
DEPLOY_ACCELERATOR = "NVIDIA_TESLA_T4"Endpoint 설정(2-3분 소요)
endpoint = aiplatform.Endpoint.create(
display_name="ag-news-category-classification",
project=PROJECT_ID,
location=LOCATION,
)- Vertex AI의
온라인 예측부분을 보면 endpoint 확인 가능(리전 서울로 설정)
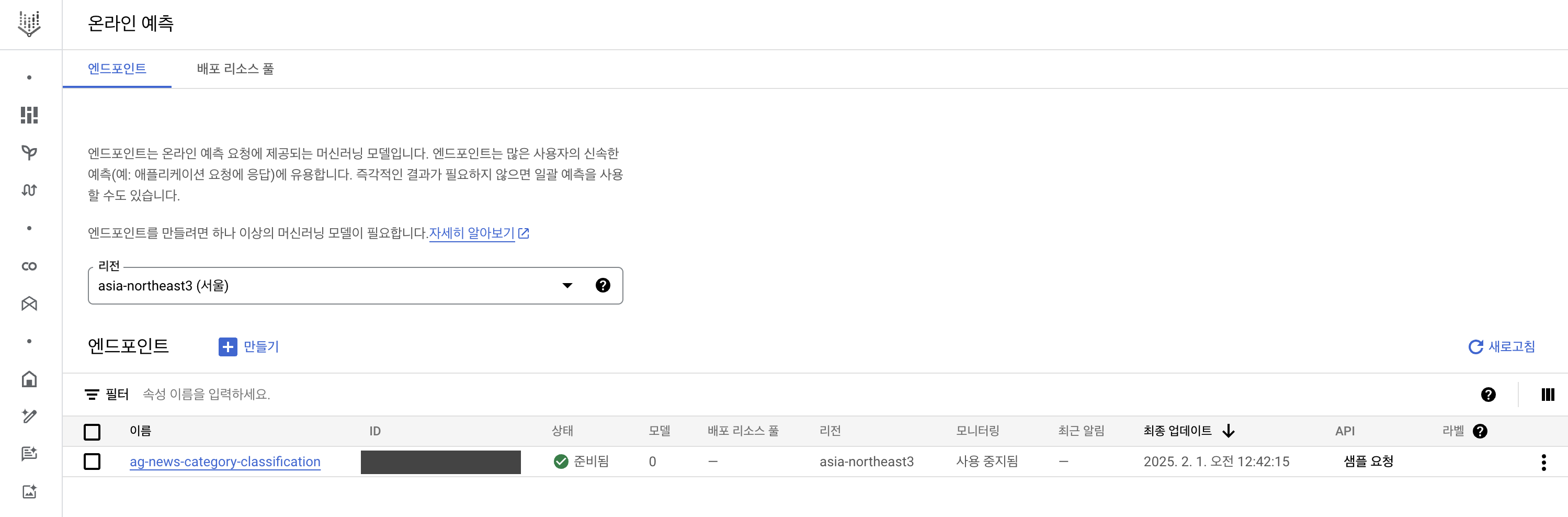
deployment 설정(약 15분 ~ 20분 정도 소요)
deployment = registry_model.deploy(
endpoint=endpoint,
machine_type=DEPLOY_COMPUTE,
min_replica_count=1,
max_replica_count=1,
accelerator_type=DEPLOY_ACCELERATOR,
accelerator_count=1,
traffic_percentage=100,
sync=True,
)
- 모델 predict
endpoint.predict(instances=[
"OpenAI releases AI video generator Sora to all customers"
])
⭐️비용이 청구될 수 있으니, Clean Up 진행⭐️
endpoint.undeploy_all()
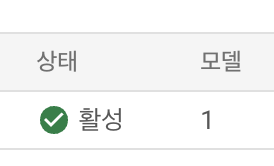
endpoint.delete()registry_model.delete()- GCP Vertex AI에서 잘 지워졌는지 확인(모델 레지스트리 혹은 온라인 예측에서 확인)
최종 정리: TorchServe 구조
Vertex AI를 통한 Serving 장점
- GPU 자원 효율적 설정
- 필요한 만큼 지정할 수 있기 때문
- 클러스터 설정 등의 초기 비용 및 시간의 단축 효과
- 기본 제공되는 기능이 있어, 모니터링 혹은 로깅 검색 등의 설정을 하지 않아도 이용할 수 있음
- A/B 테스트 기능이 있음(ex. 트래픽 분할)

언젠가 내 코드로 세상에 기여할 수 있도록, Data Science&BE 개발 기록 노트☘️