11-1. 들어가며
해당 프로젝트의 목표
- 데이터에 근거해 고객 분류 및 시각화
- 각 타겟에 따른 타겟팅 전략 수립 가능!
학습 목표
- 빅쿼리를 이용한 SQL 쿼리문 작성을 통해 원하는 결과 내기
- SQL 쿼리문 작성 활용
- RFM 분석에 대한 설명
- 데이터 전처리, 고객 세그먼테이션을 위한 분석, 통계 이론 이해 및 설명
- SQL 쿼리문 및 파이썬 코드 결과 해석
- 결과로부터 인사이트 및 마케팅 전략 세우기
Recency, Frequency, Monetary에 기반한 고객 분류
-
Recency: 고객의 마지막 구매 시점
- 최신성 점수가 높은지 고려!
-
Frequency: 특정 기간 내 고객의 제품 또는 서비스 구매 빈도 측정
- 충성도가 높은 고객을 찾기 위해 -> 빈도 점수를 고려!
-
Monetary: 고객의 총 지출 금액
- 금액 ⬆️ -> 가치가 높은 충성 고객(가치 점수 고려!)
어떻게 분석하지?
Part1. SQL을 이용한 데이터 가공
- 데이터 불러오기(Dataset Download(Import))
- 데이터 전처리
a. 결측치 제거
b. 중복값 및 오류값 처리 - RFM 스코어 계산
- 추가 feature 추출(구매 제품의 다양성, 평균 구매 주기, 구매 취소 경향성)
Part2. Python을 이용한 클러스터링
- 이상 데이터의 처리
- 변수 간의 상관관계를 분석
- Feature Scaling - 서로 다른 변수의 값 범위를 일정한 수준으로 맞춰주는 작업!
- 차원 축소
- K-Means 클러스터링
- 시각화 & 결과 분석(고객 세그먼테이션으로 얻은 인사이트 그리고 추후 전략)
고객 세그먼테이션 시각화 결과(실제 분석 결과)
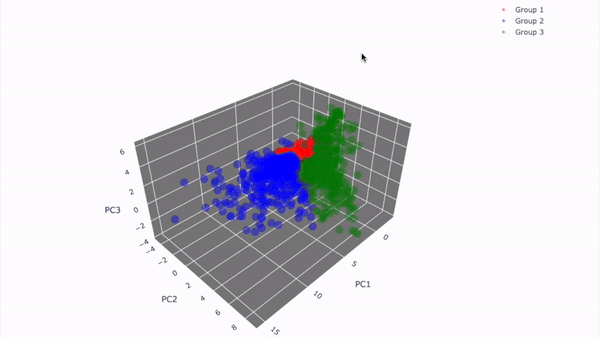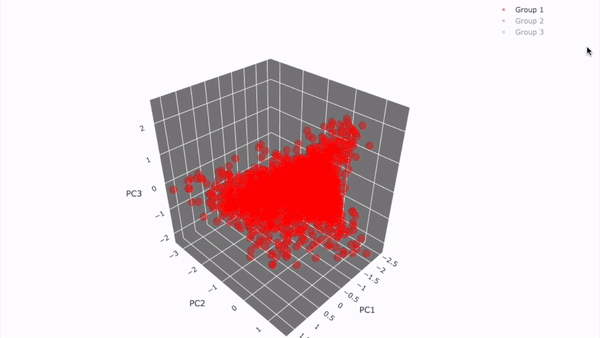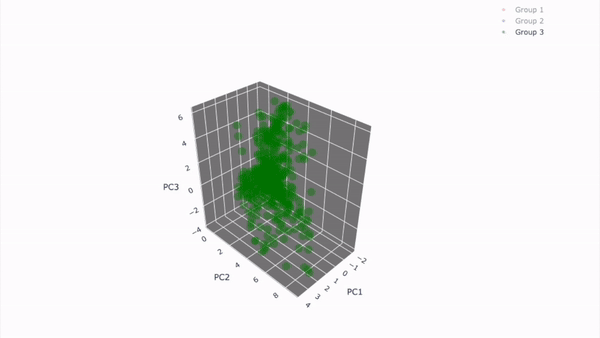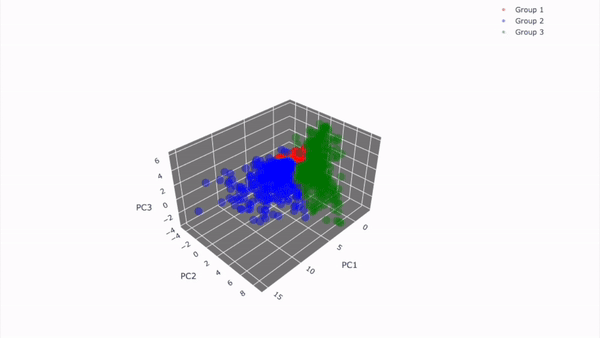
11-2. 데이터 불러오기
데이터 불러오기
데이터셋 다운로드
- E-Commerce Data
- Kaggle 유명 데이터
- UCI Machine Learing Repository가 공개한 2010-2011년 이커머스 데이터셋
빅쿼리에 데이터 업로드
data.csv파일 업로드하기- 다운로드 받은 zip 파일을 압축해제하면 -> data.csv라는 파일이 있음!
- 탐색기 옆의
+추가>로컬 파일클릭
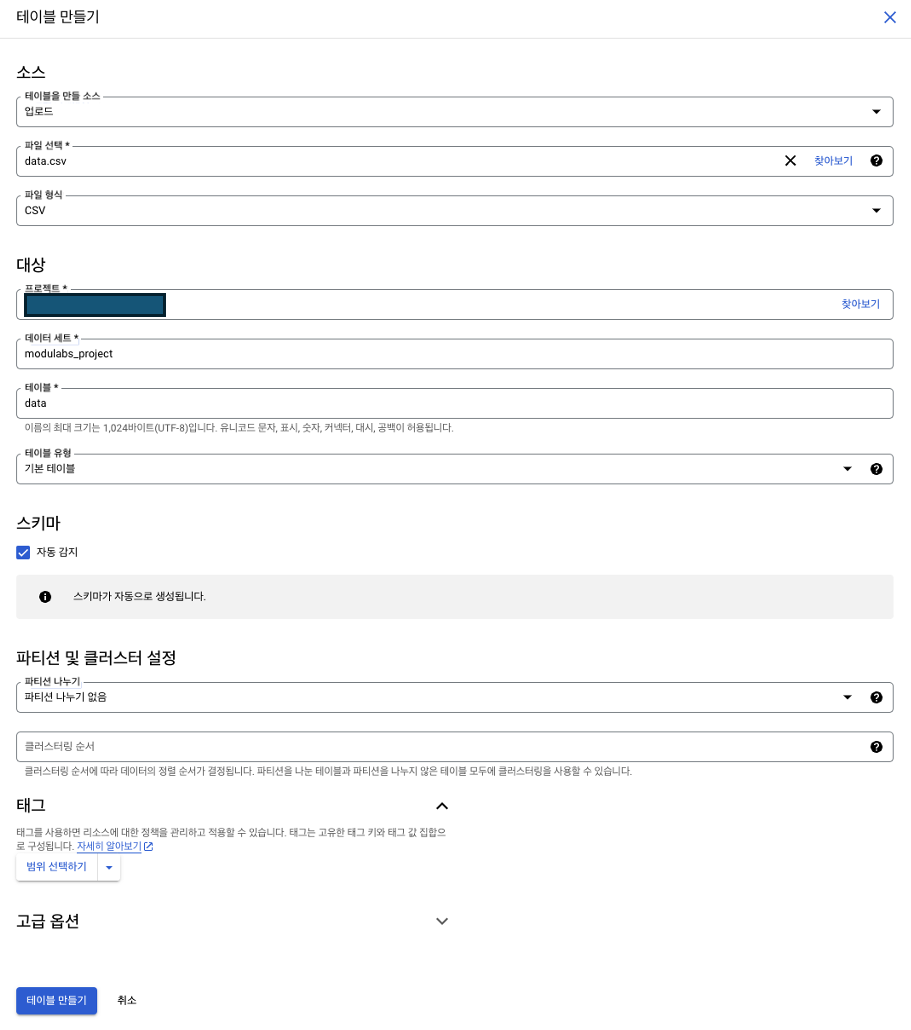
- 테이블 만들기
- 테이블을 만들 소스 =
업로드 - 파일 선택 =
data.csv - 파일 형식 =
CSV - 프로젝트 = 이미 본인 프로젝트명으로 등록되어 있음.
- 데이터 세트 =
새 데이터 세트 만들기- 데이터 세트 ID =
modulabs_project
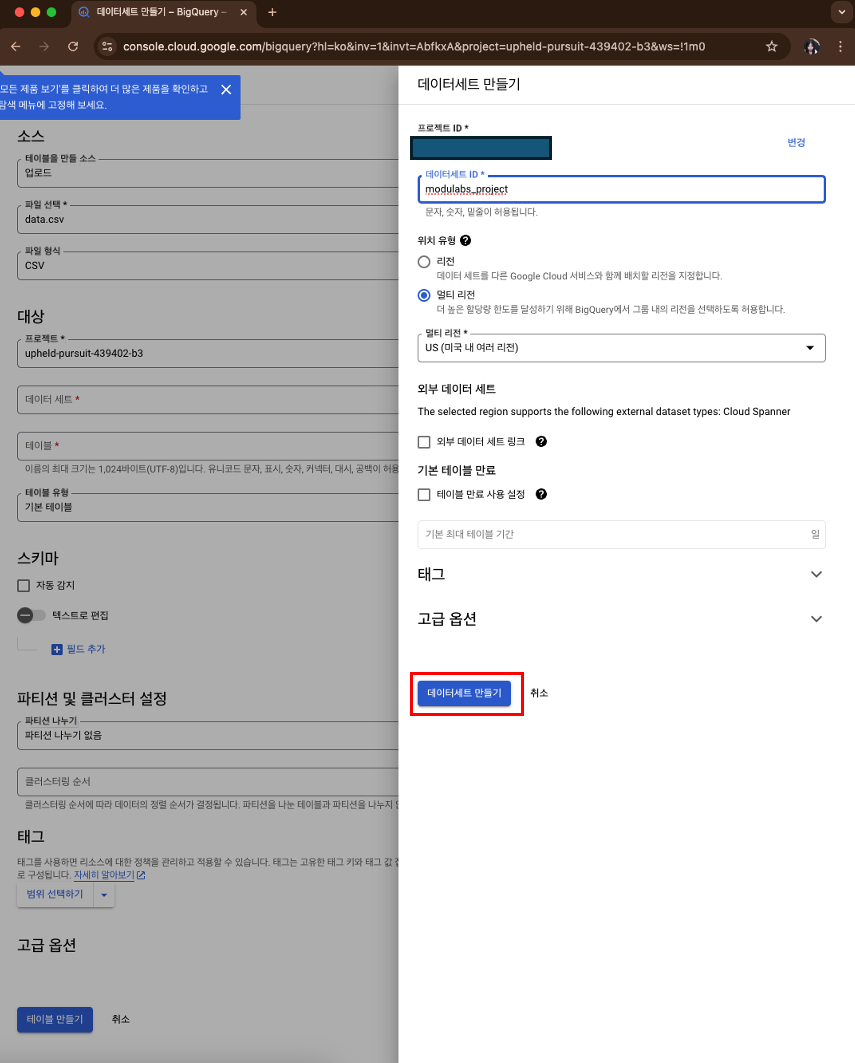
- 데이터 세트 ID =
- 테이블 =
data - 테이블 유형 =
기본 테이블 - 스키마 =
자동 감지체크하기 - 파티션 및 클러스터 설정 = 디폴트(건드리지 않기)
- 테이블을 만들 소스 =
데이터 살펴보기
- 테이블에 있는 10개 행 출력
- 이 데이터셋은 총 8개의 컬럼으로 구성되어 있음.
SELECT *
FROM `프로젝트명.modulabs_project.data`
LIMIT 10;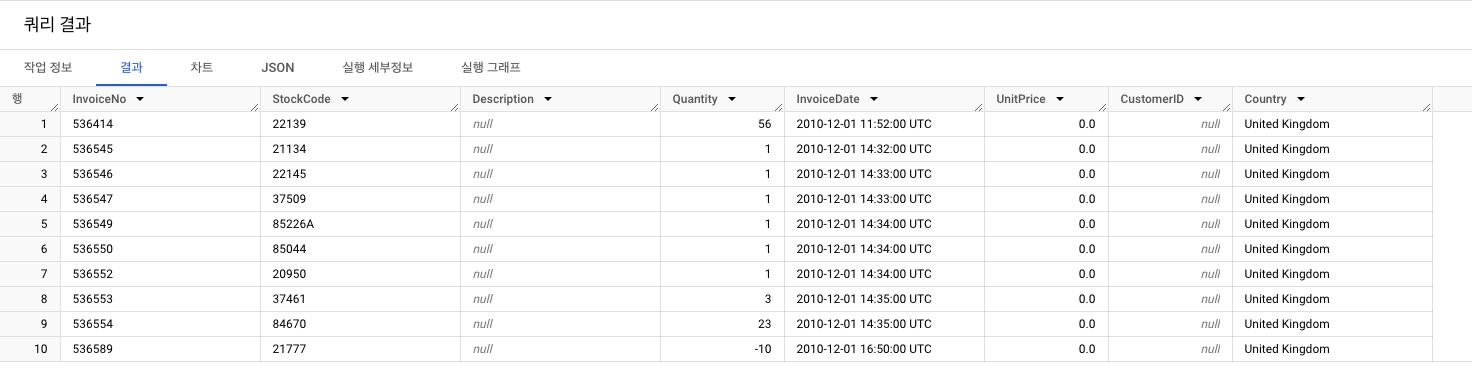
- 전체 데이터가 몇 행인지 확인 => 541,909개
SELECT COUNT(*)
FROM `프로젝트명.modulabs_project.data`;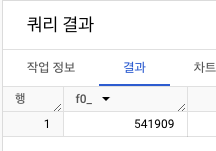
- 데이터셋의 구조를 파악할 때에는...
- LIMIT을 넣어서 데이터 일부를 빠르게 확인하고
- LIMIT을 제거하여 전체 데이터셋에 적용하는 순서로 진행
- E-Commerce Dataset 특징
| 컬럼명 | 설명 |
|---|---|
| InvoiceNo | 각각의 고유 거래 코드(C로 시작 = 취소, 거래 1개에 제품이 여러개라면 1개의 InvoiceNo에 여러 개의 StockCode 연결됨.) |
| StockCode | 제품 고유 코드 |
| Description | 제품 설명 |
| Quantity | 제품 구매 개수 단위 수 |
| InvoiceDate | 거래 날짜 및 시간 |
| UnitPrice | 제품 당 단위 가격(파운드) |
| CustomerID | 고객 고유 코드 |
| Country | 주문 국가 |
데이터 수 세기
- COUNT 함수를 이용해 각 컬럼별 데이터 포인트 수 계산

결측치와 이상치 알아보기
결측치(Missing Values)
- 데이터 집합에서 값의 누락 또는 미기록된 경우
NaN또는null로 표기- 실제 값이 존재하지 않음 또는 기록되지 않음(데이터 수집 과정 중 발생)
- 처리 방법 : 삭제, 대체, 예측
이상치(Outliers)
- 데이터 집합에서 크게 다른 값을 띄는 관측치
- 오류, 측정 오류, 드문 사건 등이 원인
- 이상치 탐지 방법 : 통계적 방법, 시각화 도구, 머신러닝 알고리즘
해당 데이터셋에서는 Description, CustomerID 이 두개의 컬럼에 결측치가 있음!
11-3. 데이터 전처리 방법
결측치 처리
- 데이터가 비어있기 때문에 즉, 결측치가 많은(sparse) 데이터셋일 가능성 ⬆️
- 결측치 처리 대표 방법 : 결측치 행 삭제 or 그 값을 제외한 평균, 중앙값, 최빈값으로 대체
중복값 처리
- 동일한 정보를 가진 반복 행
- 데이터 일관성 및 정확성 유지를 위해 필요
- 데이터 특성에 따라서 중복 데이터를 유지해야할 수도 있음!
정규화 및 표준화
- 데이터 범위의 조정 또는 데이터 스케일 변경 가능
- 데이터 분포 조정
- 일반적으로 영향을 더 많이 끼치는 데이터가 있을 수 있기 때문에, 비슷한 범위 내의 숫자로 변경하는 스케일링을 하거나, 로그 변환, 제곱근 변환 등 수행
범주형(명목형) 데이터 인코딩
- 범주형(명목형) 데이터 == 성별, 구매 지역 등
- 이 데이터를 수치형으로 변환하는 전처리를 말함.
데이터 종류
범주형: 그룹으로 나뉜 데이터- 명목형
- 성별, 색, 혈액형, 주거지역 등 단순 분류 데이터
- 순서 ❌, 개수 및 퍼센트로 표현
- 순서형
- 만족도, 병의 단계, 성적 등 이산적인 값들 사이 순서 있는 데이터
- 평균을 구함.
- 명목형
수치형(양적): 수치적 의미가 있다 == 즉, 연산이 되는 데이터를 의미- 이산형
- 횟수, 차량 수, 사고 건수 등 이산적 값 데이터
- 정수 값 -> 퍼센트로 표현
- 연속형
- 키, 몸무게, 온도 등 연속 값 데이터
- 평균, 표준편차, 분산, 퍼센트 등으로 다양하게 표현
- 이산형
이상치 분석 및 처리
- 통계적 방법, 시각화 도구를 이용한 이상치(outlier) 분석 및 필요에 따른 제거 및 수정 과정 이후 사용

11-4. 데이터 전처리 방법(1): 결측치 제거
컬럼별 누락된 값의 비율 계산
- 각 컬럼별 누락 값 비율 계산1 :
CASE WHEN사용- 각 컬럼에 대한 누락 값을 계산
- 누락 값 결과를
UNION ALL으로 통합
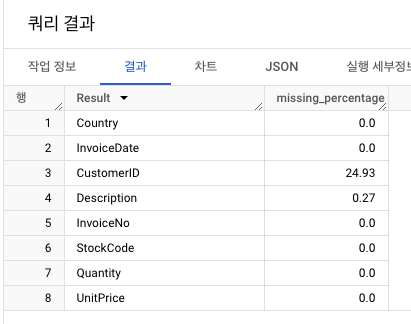
- 각 컬럼별 누락 값 비율 계산2 : ROUND를 이용한 구성
결측치 처리 전략
CustomerID(24.93%)- 결측치 비중이 약 4분의 1에 육박
- 대체 : 분석에 편향 발생 가능성이 높고, 노이즈 발생 우려
- 제거하는 것으로!
데이터 편향
- 데이터의 특정 경향으로 인해 전체 분석 또는 결과의 왜곡 발생
데이터 노이즈
- 관련 없는 정보로 인해 데이터 질 저하 및 분석 정확도 하락
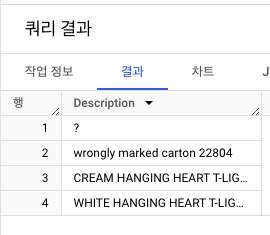
Description (0.27%)- 결측치는 적지만, 같은 StockCode가 같지 않은 Description을 가지고 있는 일관성 위배 문제 발생
StockCode = '85123A'의Description추출하기- 동일한 데이터임에도 설명이 각기 달라 일관성 위배
- 일관성 결여를 고려한다면, 대체의 경우 신뢰성이 떨어짐.
- 누락 비율도 0.27%로 다소 낮은 편이니 제거하기!
결측치 처리
- 결측치 제거는 DELETE 구문으로 작성 + WHERE절로 데이터 제거 조건

11-5. 데이터 전처리(2): 중복값 처리
중복값 확인
-
중복행 개수 세기
- 모든 칼럼 : 그룹 함수를 적용
- COUNT를 1보다 크게 적용
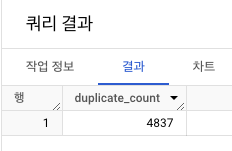
-
중복행은 총
4,837개!
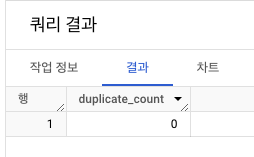
중복값 처리
- 중복값 제거
CREATE OR REPLACE TABLE- 모든 컬럼 DISTINCT

- 중복값 사라짐 확인

11-6. 데이터 전처리(3): 오류값 처리
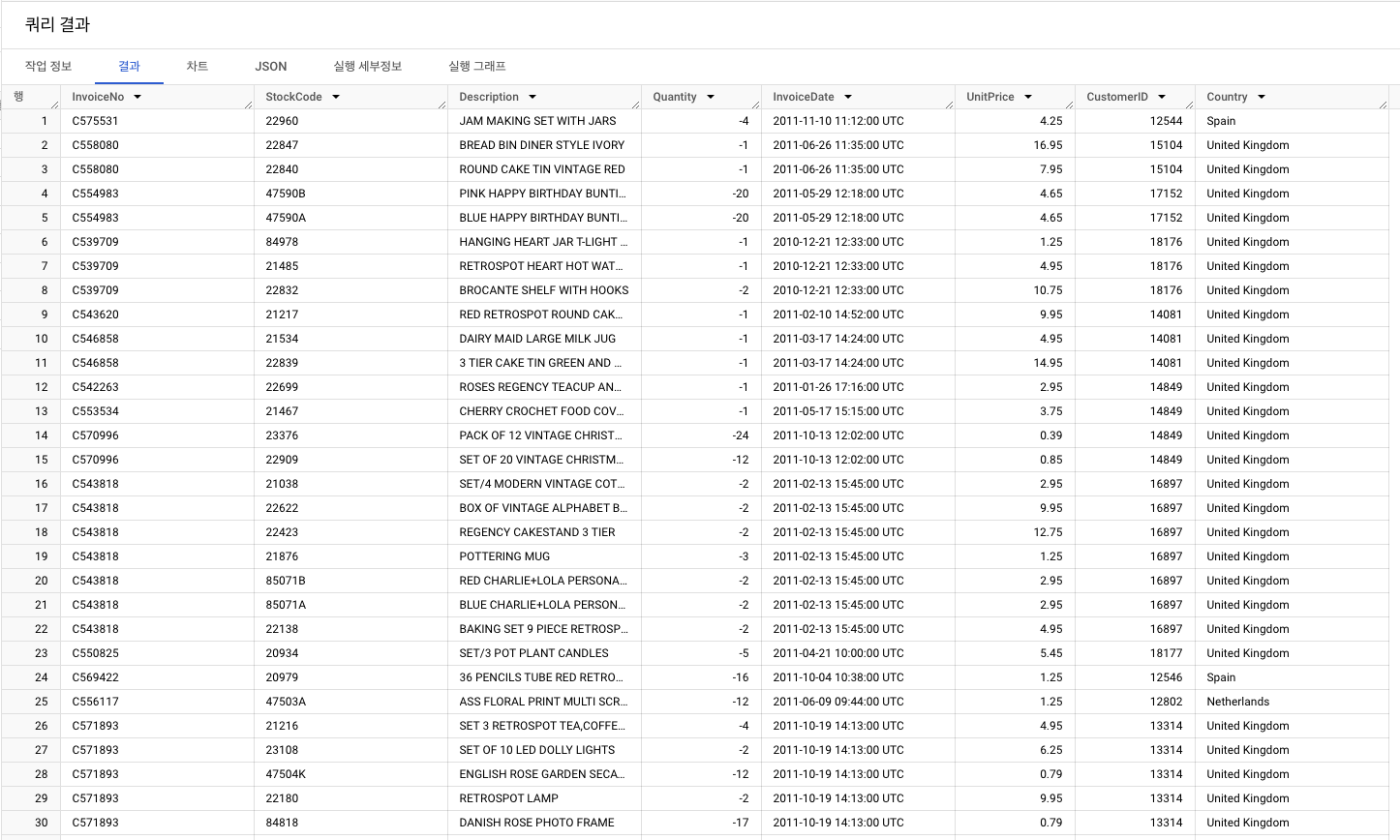
1️⃣ InvoiceNo
- unique한
InvoiceNo의 개수 출력 : 총 22,190개
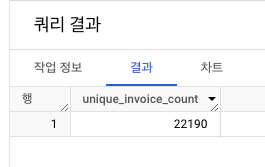
- 유니크
InvoiceNo100개 출력- 취소 거래의 특징
- 'C'로 시작
- 취소 거래의 특징
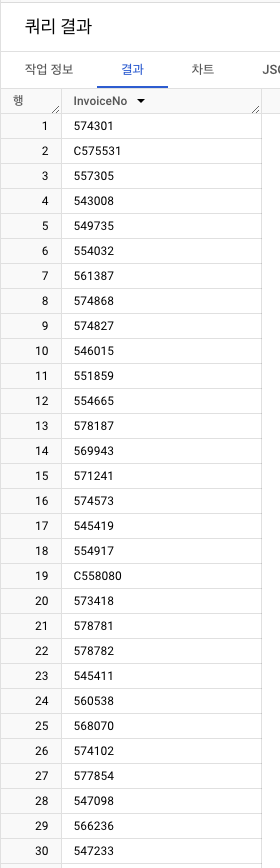

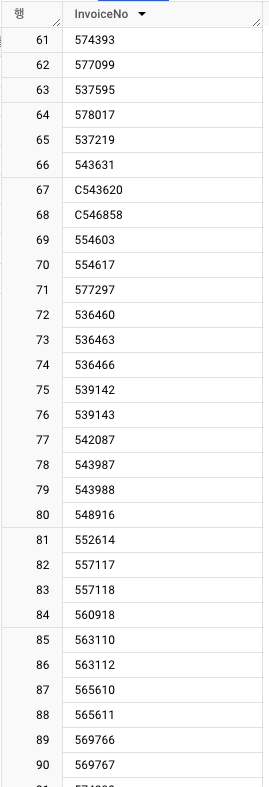
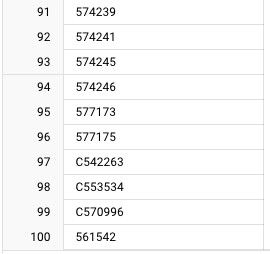
InvoiceNo-> 'C'로 시작하는 행 필터링하기(100개)- 취소 거래 건의 경향성 :
Quantity가 음수값!
- 취소 거래 건의 경향성 :

구매 건 상태 = Canceled비율(%)- 소수점 첫번째 자리까지 정리
- 결과 : 2.2%

InvoiceNo 결과 분석
- 취소 거래의 기준 : InvoiceNo 컬럼의 'C'로 시작 + Quantitiy가 음수!
- 취소 거래를 삭제하지는 않고, 유지하되 명확히 표시해 추가적인 분석이 필요할 경우 사용하기
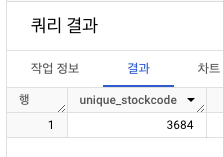
2️⃣ StockCode
- unique한
StockCode개수 출력 : 총 3,684개
StockCode별 등장 빈도 출력(상위 10개)- 경향성 분석
- 대부분은 5-6가지의 숫자로 구성되어 있으나, 'POST'는 이상치!
- 경향성 분석

- 이상치 개수를 명확히 파악하기
- (해당 내용은 기본 코드 제공)
- 'POST'와 같은 이상치 데이터가 몇 개 있는지 파악하는 것 ==
StockCode문자열 내의 숫자 길이 살펴보기!
코드 분석
REGEXP_REPLACE
- 텍스트 처리 정규 표현식
- 특정 조건에 부합하는 텍스트를 다른 텍스트로 대체!
StockCode, r’[0-9]’, ‘’의 의미
- StockCode 컬럼 내부 값 중 0~9 사이의 숫자를 빈 값으로 대체
LENGTH연산
- StockCode 안에 있는 숫자 수를 세고, number_count 컬럼으로 저장
- 숫자가 0~1개인 값에는 어떤 코드가 있는지 확인
- POST, D, C2, M, BANK CHARGES, PADS, DOT, CRUK 존재
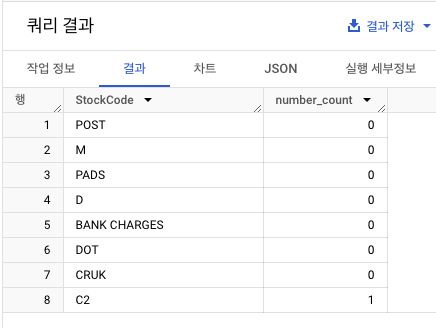
- 전체 데이터 수 대비 몇 퍼센트?(소수점 두번째 자리까지)
- 결과 : 0.48%
- 제품과 관련되지 않은 거래 기록 제거
3️⃣ Description
- unique한 Description별 출현 빈도 계산(상위 30개)
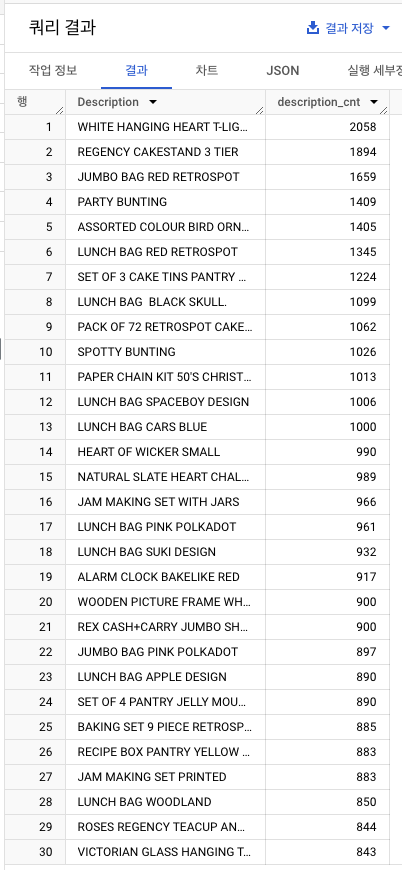
- 대소문자 혼합 데이터를 살펴보고
- 서비스 관련 정보를 포함하는 행들을 제거하기
- 대소문자 혼용 데이터 -> 대문자로 표준화
4️⃣ UnitPrice
- 단위 가격 요약 통계량 보기(단위 가격은 상품 1개당 가격)
- UnitPrice 최솟값, 최댓값, 평균 확인
- 단가가 0인 데이터가 있음!

- 단가가 0인 데이터 패턴 더 살펴보기
- 단가가 0원인
- 거래 개수
- 구매 수량(
Quantity)의 최솟값, 최댓값, 평균
- 단가가 0원인

데이터 수가 지나치게 작음 -> 무료 제품보단 데이터 오류일 듯!
- UnitPrice = 0 제거 작업 진행

11-7. RFM 스코어
1️⃣ Recency
-
DATE 함수를 사용해
InvoiceDate자료형 변경- 기존 : YYYY-MM-DD HH:MM:SS
- 변경 : YYYY-MM-DD
-
전체 399573행
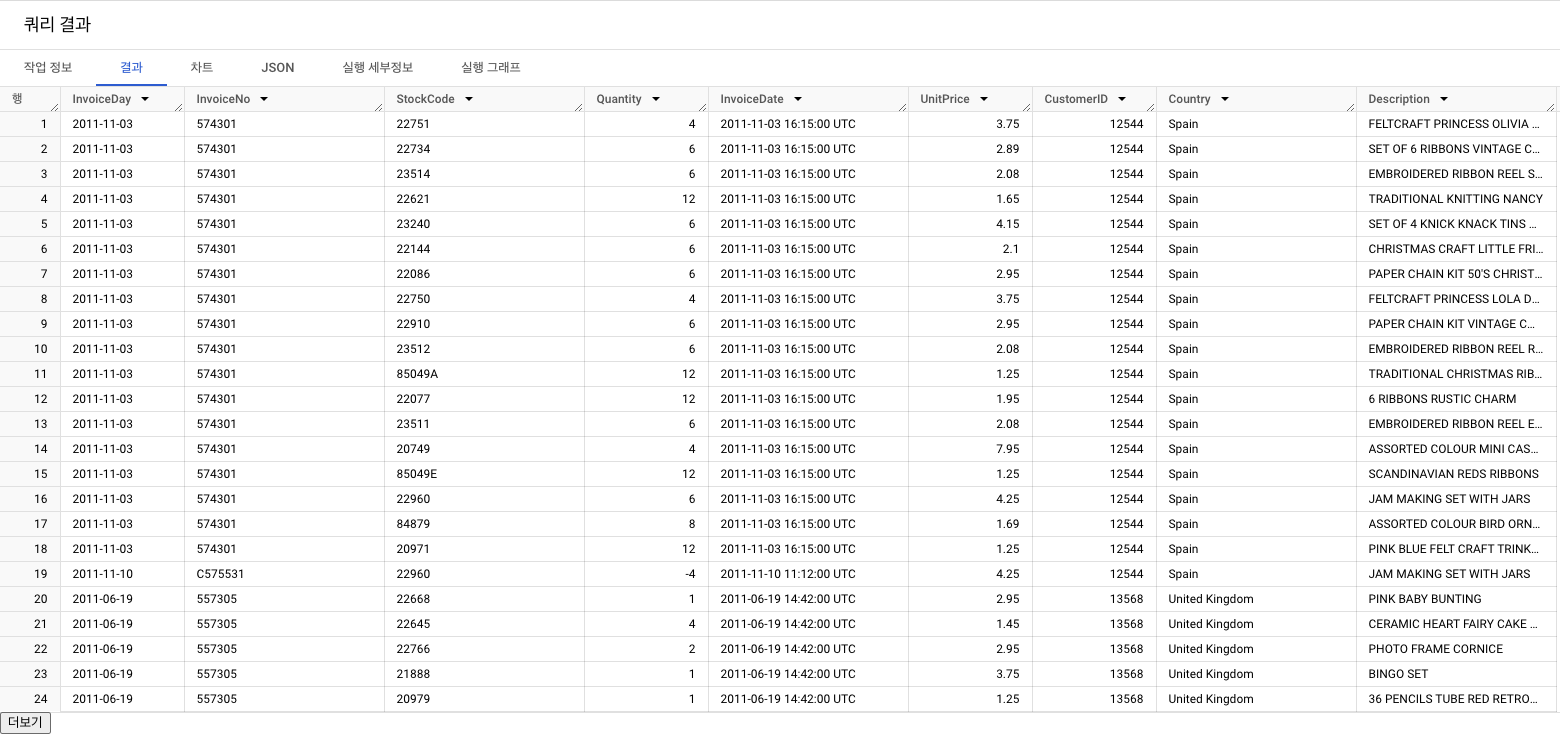
- 가장 최근 구매 일자 기준 Recency 구하기
- MAX() 함수
- 가장 최근 구매일은? : 2011년 12월 9일!
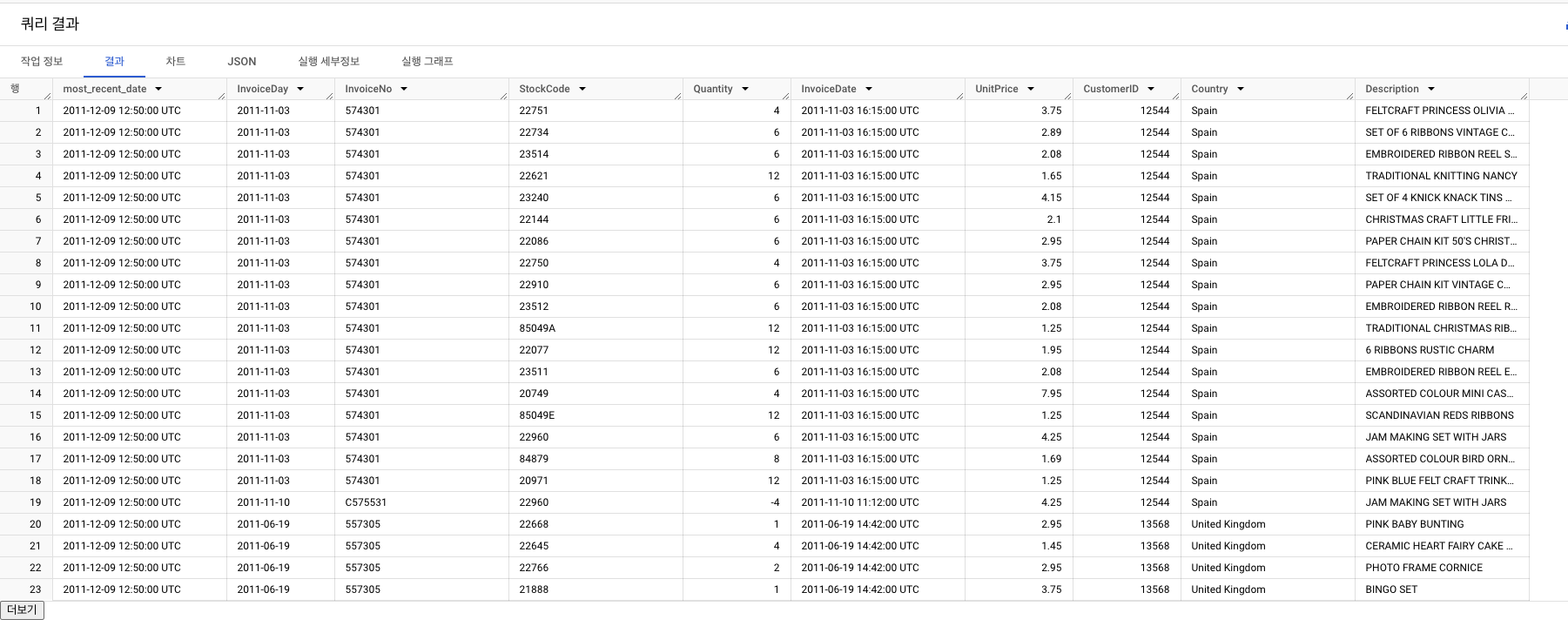
-
유저별로 가장 최근 일어난 구매 정보 정리
- 유저별 가장 큰 InvoiceDay 찾기 -> 가장 최근 구매일로!
-
most_recent_date와 InvoiceDay 차이 계산
user_r테이블- 지금까지의 결과 저장하기
- 지금까지의 결과 저장하기
2️⃣ Frequency
1. 전체 거래 건수 계산
- 거래건 = InvoiceNo 기준 -> 고객 고유 InvoiceNO 수 세기

2. 구매한 아이템 총 수량 계산
- 고객별 구매 아이템 총 수량 합산
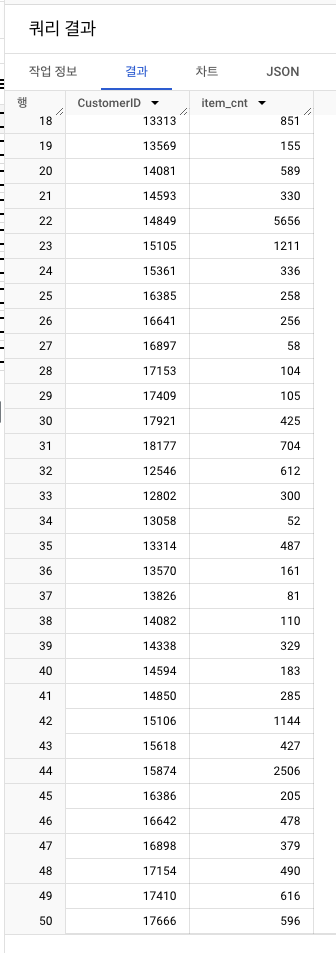
3. 1과 2의 결과를 합쳐서 user_rf 테이블에 저장
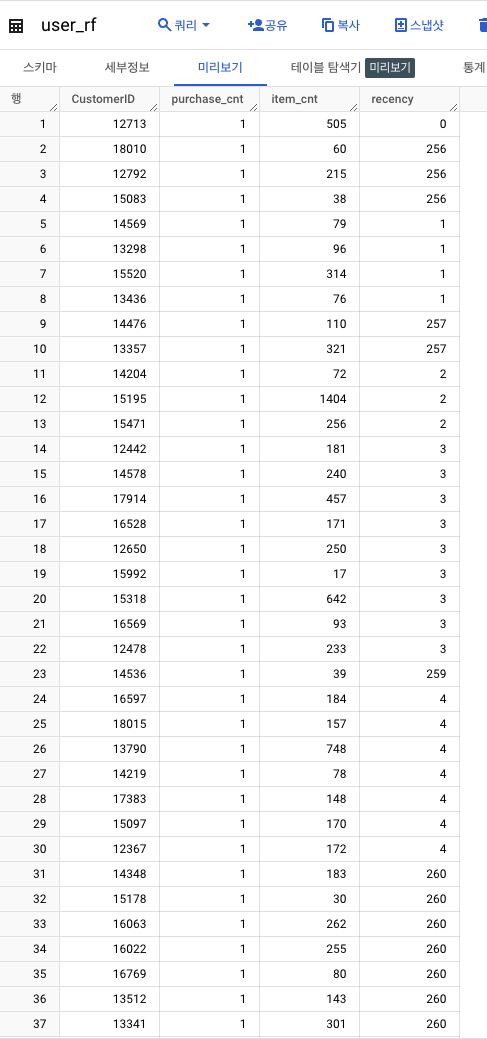
3️⃣ Monetary
- 결제 금액은 낮지만 구매가 잦은 고객
- 한번 결제를 할 때 큰 금액을 결제하는 고객
- 행동 패턴이 달라지므로 분석 필요!
- 이를 위해
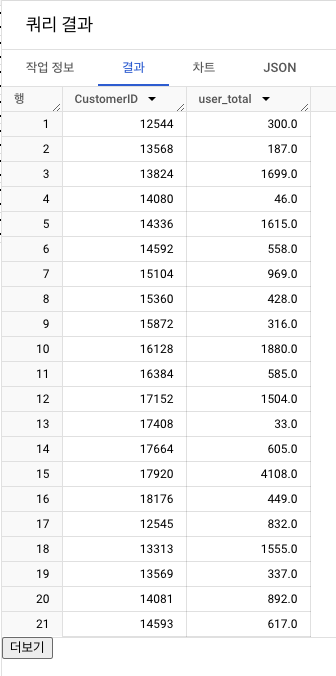
고객별 총 지출액,평균 거래 금액으로 계산
- 고객별 총 지출액 계산(소수점 첫째 자리에서 반올림)
- 고객별 평균 거래 금액 계산
a.data테이블,user_rf테이블 LEFT JOIN
b.purchase_cnt로 나눠 ->user_rfm테이블

4️⃣ RFM 통합 테이블 출력
- 고유 유저 수 : 4,362명
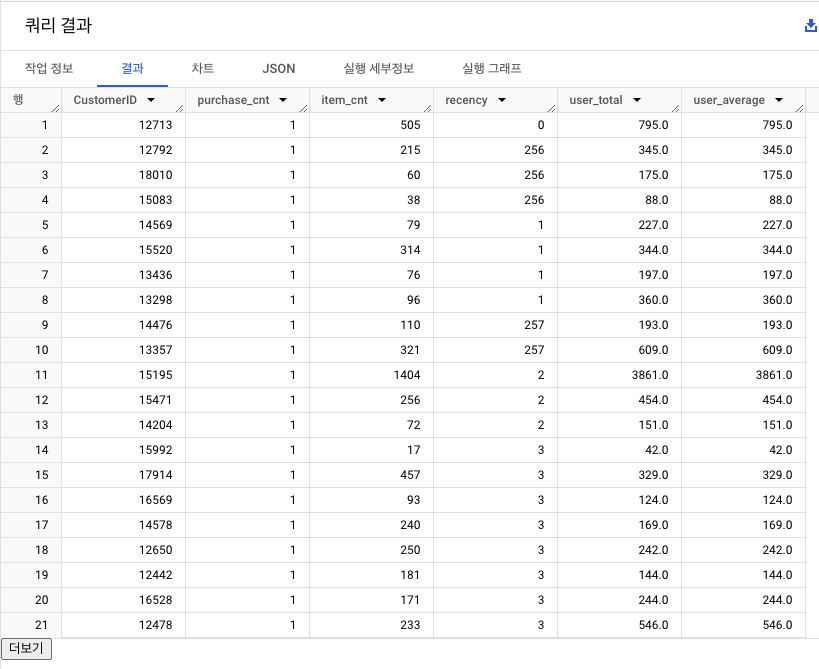
11-8. 추가 Feature 추출
RFM 분석 방법의 허점
- 사이트 방문 횟수 동일, 유사 금액 지출했으나 구매 패턴 다른 사람 -> 분류를 못한다!
- 즉, 유저 구매 패턴의 추가 feature를 살펴봐야 함.
클러스터링 알고리즘?
- 유사 특성을 가진 데이터 포인트를 그룹화
- 종류 : K-Means, 계층적 클러스터링, DBSCAN...
- 활용 사례
- 고객 세그먼테이션
- 고객 데이터 기반 유사 구매 패턴, 선호도를 가지는 고객 그룹 찾기
- 이미지 분류
- 유사 특징 이미지 그룹화 -> 이미지 검색, 분류 개선
- 자연어 처리
- 유사 주제 문서 그룹화 -> 정보 검색, 텍스트 분석
- 의학 분야
- 유사 진단 패턴 또는 환자 그룹 식별 -> 질병 진단
- 이상 탐지
- 정상 데이터 그룹 vs 이상 데이터 그룹 -> 보안, 이상 탐지
1. 구매하는 제품의 다양성
- 고객 별 구매한 상품 고유 수 계산
user_rfm테이블과의 결과 합산 ->user_data테이블 생성


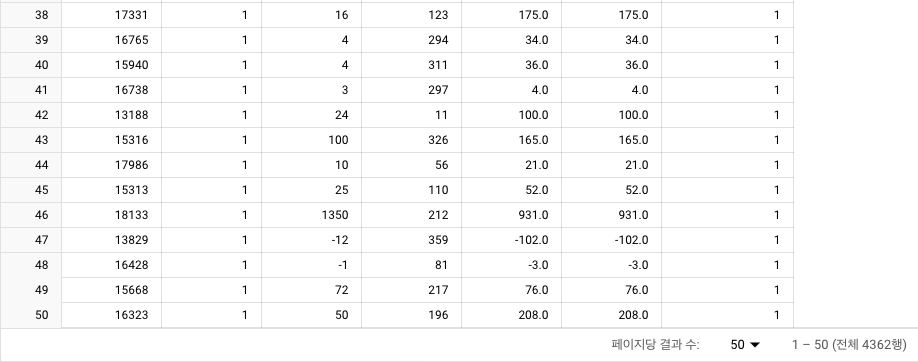
2. 평균 구매 주기
- 고객들의 쇼핑 패턴 이해 -> 재방문 주기를 보는 것!
- 평균 구매 소요 일수를 계산 ->
user_data에 합산
- 평균 구매 소요 일수를 계산 ->
코드 분석
- 구매와 구매 사이 소요 일수 계산
ROUND(AVG(interval_), 2) IS NULL: 1개의 구매 건 내 '바로 직전' 구매일이 없는 경우- CASE 부분의 ELSE 조건을 통해 interval_ 평균 계산 -> average_interval에 넣음!

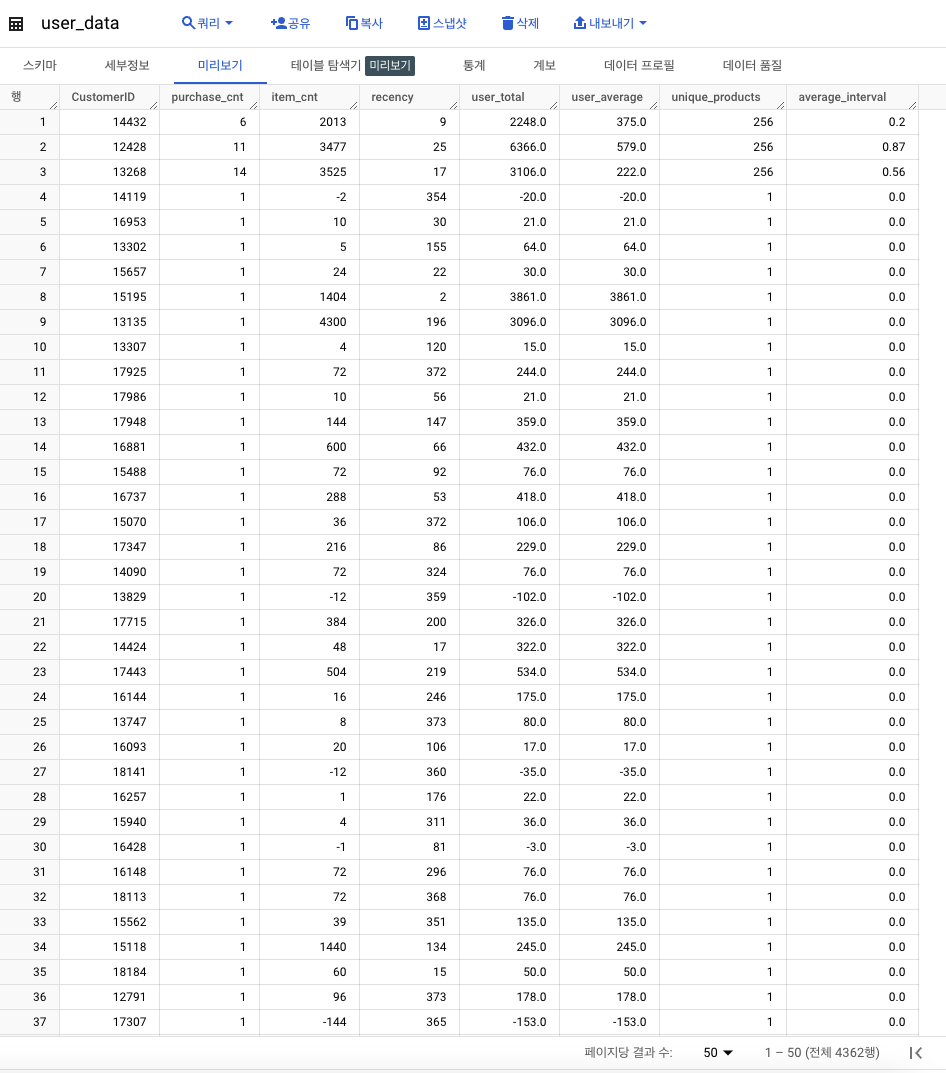
3. 구매 취소 경향성
고객 취소 패턴 파악하는 3가지 방법
- 취소 빈도(cancel_frequency)
a. 고객별 취소 거래 총 횟수
b. 거래 취소 가능성이 높은 고객 식별 가능!
c. 불만족 정도 또는 다른 문제 지표일 수 있음.
- 취소 비율(cancel_rate)
a. 각 고객의 모든 거래 중 취소 거래의 비율
b. 원래 취소를 잘하는 고객 등과 같은 특징 지표
- 취소 빈도 및 취소 비율(소수점 두번째 자리까지) 계산 ->
user_data업데이트

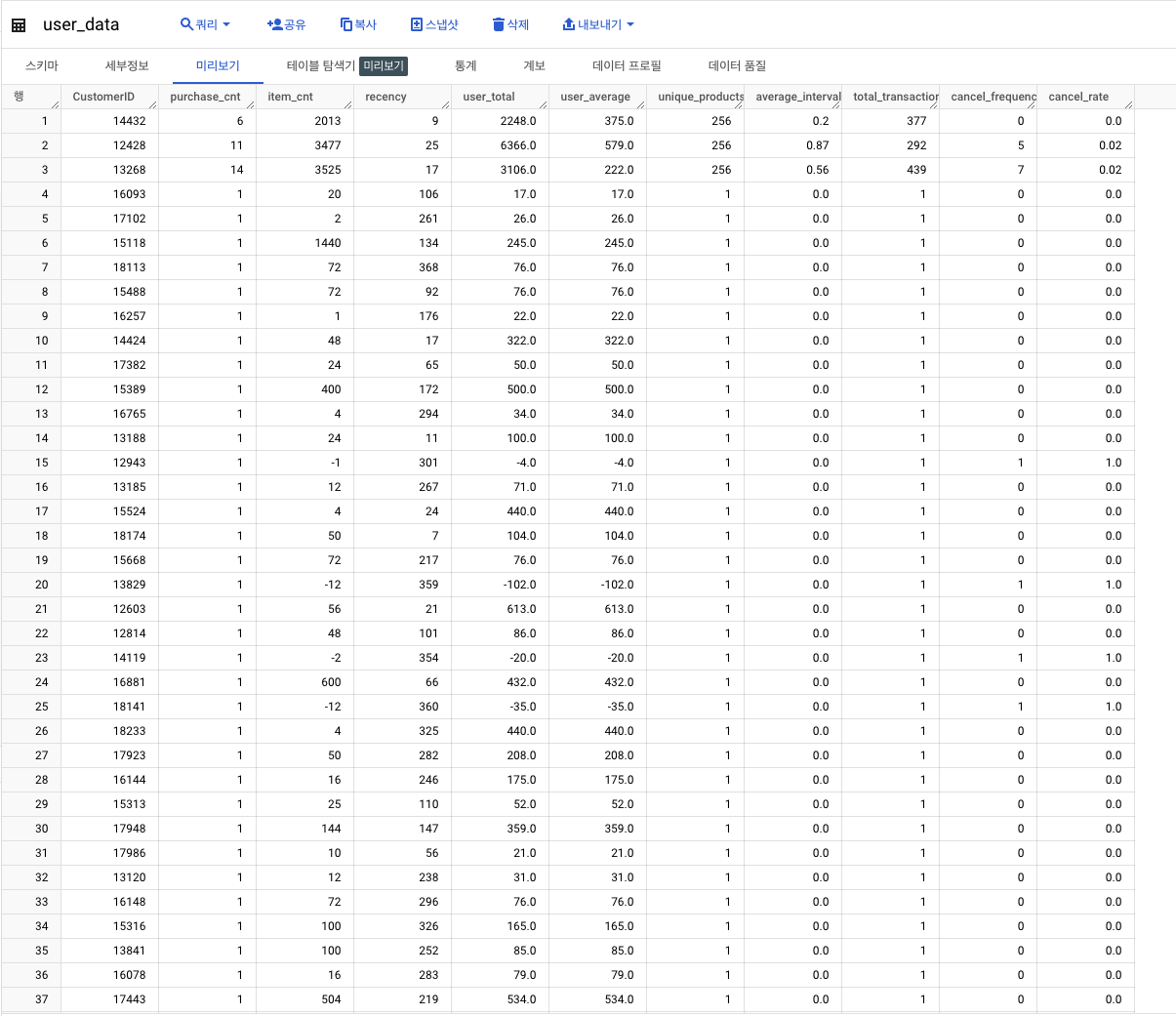
최종 결과
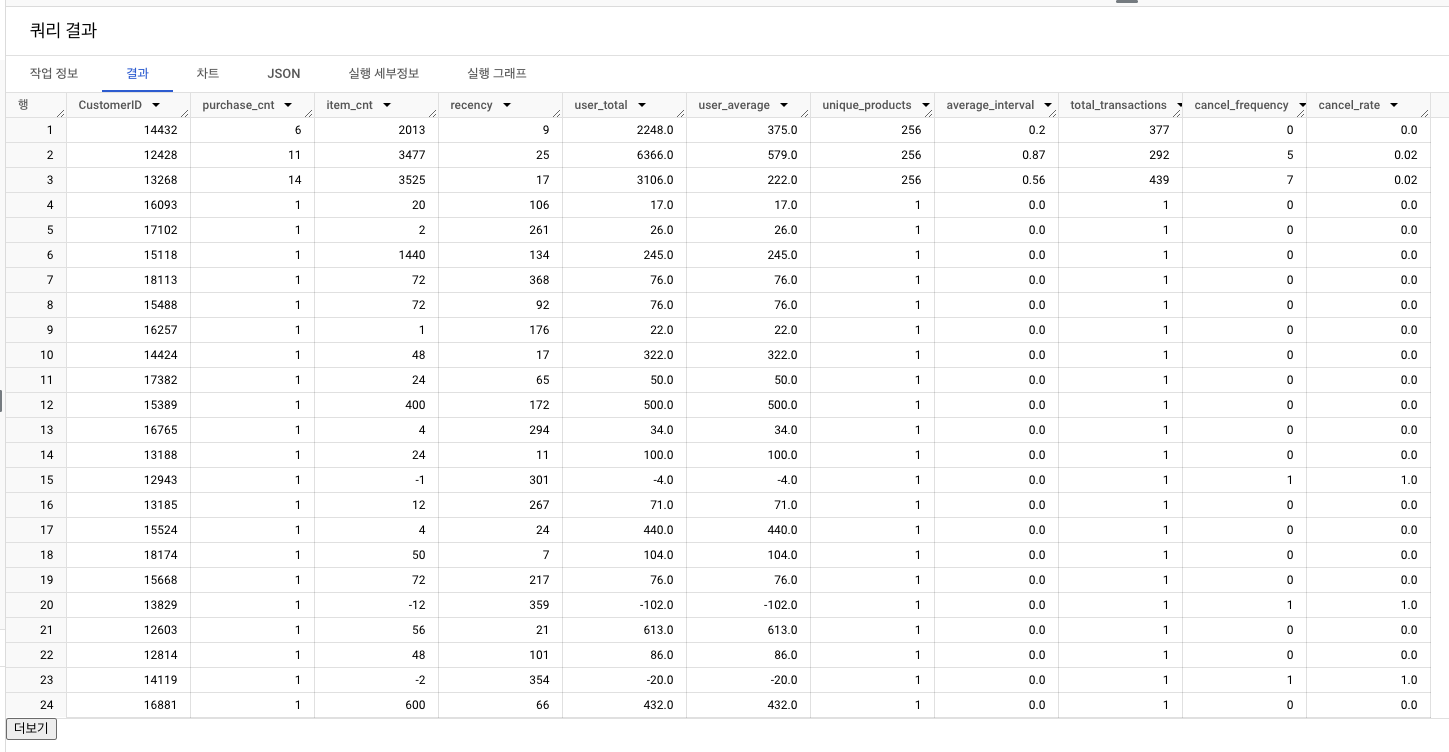
- 컬럼이 많아 실제로 계산이 잘 되었는지 확인하기 위해 LMS 결과 예시의 특정 컬럼을 조회해 잘 나오는지 확인! (CustomerID가 13185)

프로젝트 URL
github.com/hayannn/AIFFEL_MAIN_QUEST

언젠가 내 코드로 세상에 기여할 수 있도록, Data Science&BE 개발 기록 노트☘️