
5-1. 들어가며
학습 목표
- 비지도학습 이해
- PCA 실습
- 군집(클러스터링) 학습: 비계층적 클러스터링(K-means), 계층적 클러스터링(전통적)
5-2. 차원 축소
차원 축소란?
-
PCA(Principal Component Analysis)
- 차원 축소의 대표적 기법
- 고차원 to 저차원 축소(선형 투영 기법)
- 차원 ⬆️ -> 거리 ⬆️, 오버피팅 가능성 ⬆️
-
PCA 단계
- 1: 데이터에서 분산 최대 축 찾기 (첫번째 축)
- 2: 첫번째 축과 직교 + 분산 최대 축 찾기 (두번째 축)
- 3 : 첫번째 and 두번째 축 직교 + 분산 최대 축 찾기 (세번째 축)
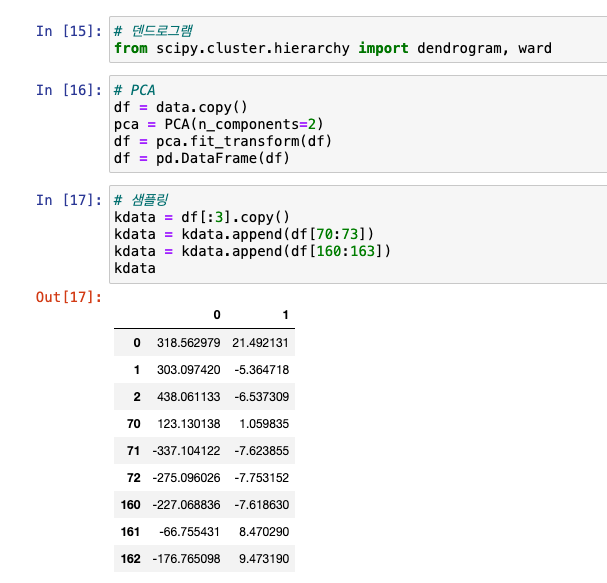
실습
- 데이터셋 준비

스탠다드 스케일링
- PCA 이전 해야할 것
- 특성별 데이터 스케일이 다를 경우 데이터 스케일링응로 데이터 범위 및 분포를 동일하게 만들어야 함
- 표준 정규 분포 형태를 가지도록 스케일링(평균, 분산 1)
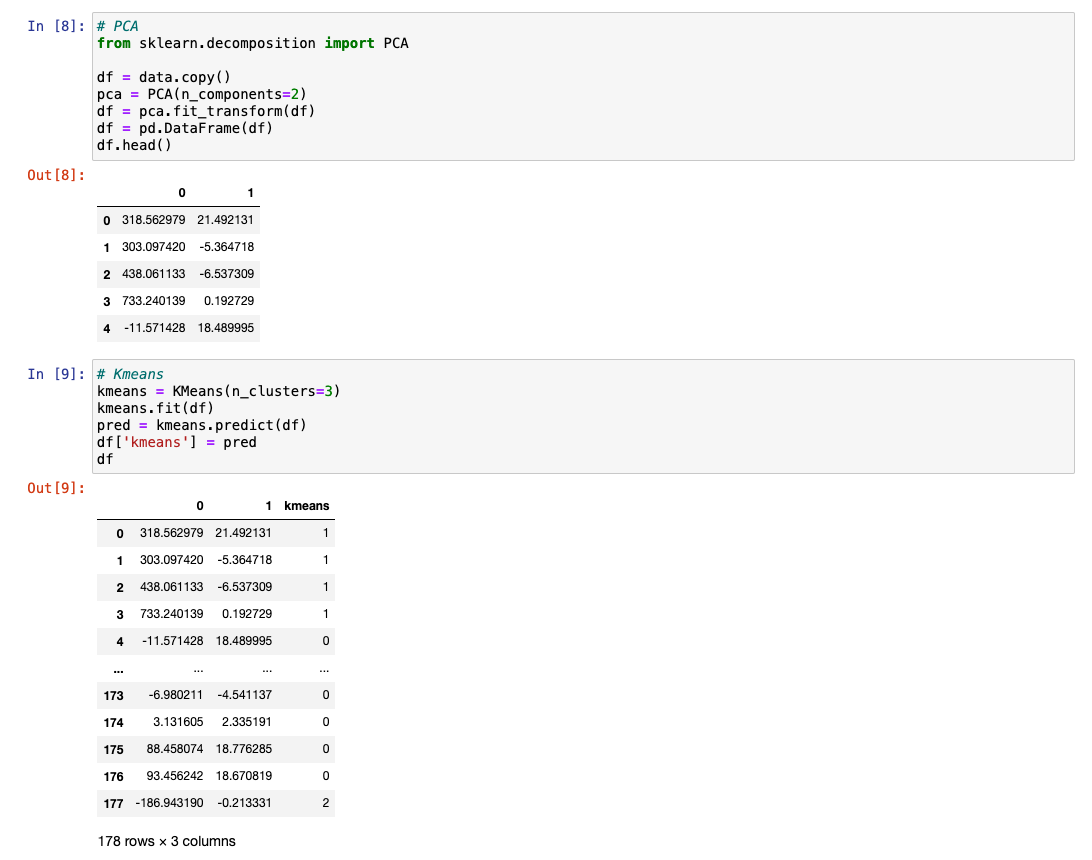
PCA
- 2차원 or 3차원으로 축소하면 시각화 가능
PCA(2차원) 시각화
-
라이브러리 :
from sklearn.decomposition import PCA -
n_components: 피쳐를 몇 개로 줄일 건지 설정


-
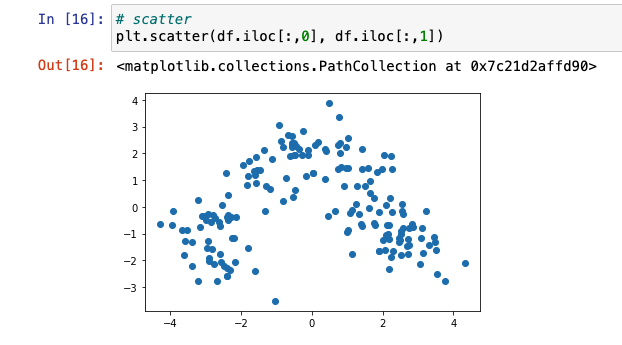
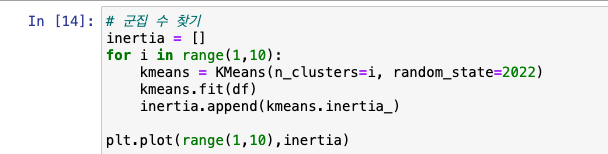
scatter 이용해 시각화
-
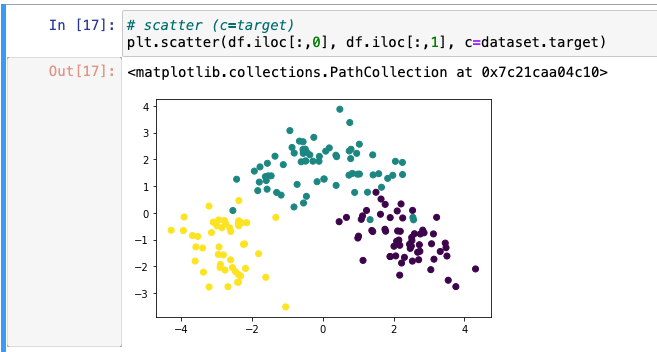
target 데이터별로 색을 넣어 한눈에 알아볼 수 있게 작업
-
데이터의 설명력이 몇 %인지 확인해보기
- 첫 번째 : 약 36%
- 두 번째 : 약 20%
- 13개에서 2개로 줄였을 때의 설명력 : 100%

지도 학습 (PCA 전후 비교)
- 차원 축소 시 수치가 비슷하기 때문에, 큰 문제 없음을 확인

PCA(3차원) 시각화

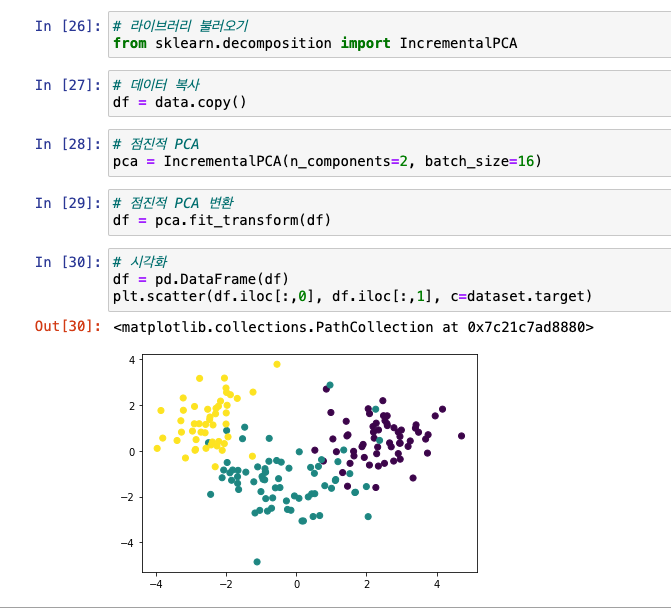
점진적 PCA
-
데이터셋 사이즈가 클 경우 사용(배치로 수행)
-
라이브러리 :
from sklearn.decomposition import IncrementalPCA
-
데이터 설명력 확인 : 부분이기 때문에 설명력이 조금 떨어짐

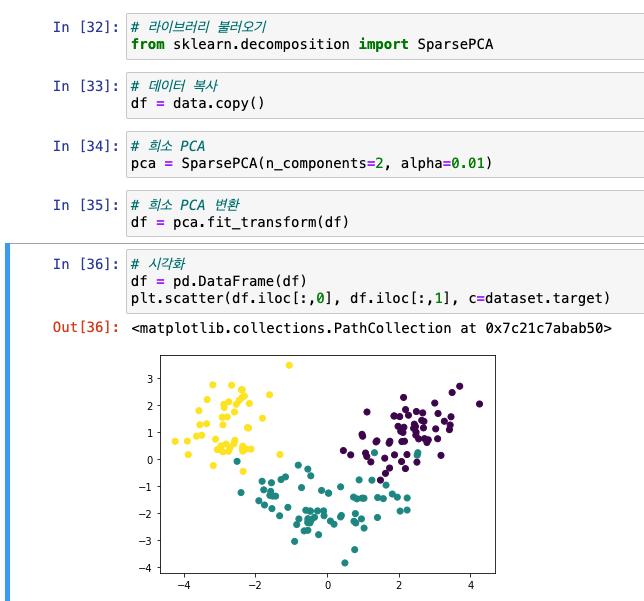
희소PCA
- alpha를 조정해 적절한 희소성 유지
- 오버피팅 방지
- 라이브러리 :
from sklearn.decomposition import SparsePCA
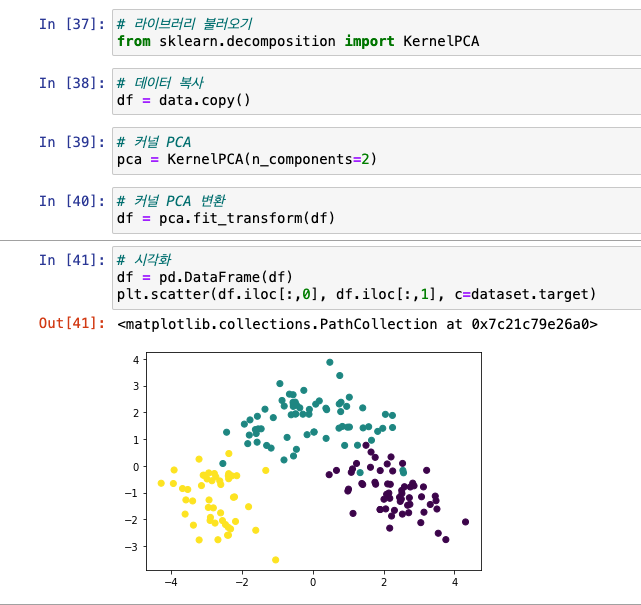
커널 PCA
- 비선형 차원 축소
- 라이브러리 :
from sklearn.decomposition import KernelPCA - 알파 값 필요없고, 컴포넌트만 적으면 됨
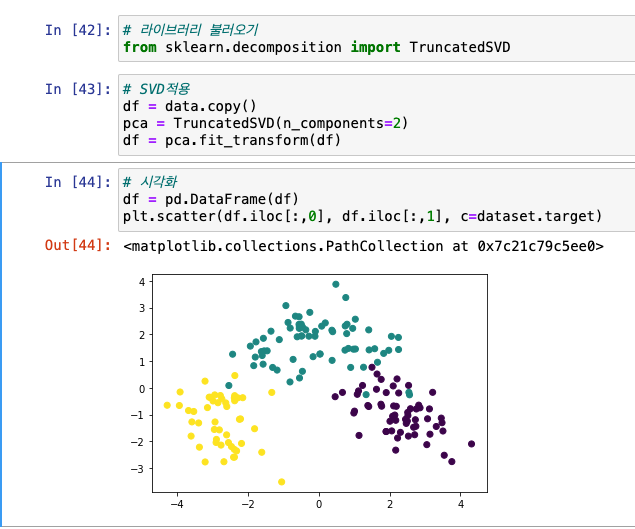
SVD 특이값 분해
- Singular Value Decomposition
- 행렬 -> 특정 구조로 분해
- 신호 처리, 통계학 등 분야
- 라이브러리 :
from sklearn.decomposition import TruncatedSVD
5-3. 군집(클러스터링)
군집(Clustering)
- 유사성 높은 대상 집단 분류
- 계층적 군집분석 : 전통적, 군집 개수 추후 선정
- 비계층적 군집분석 : K-means(초기 중심값 임의 선정 및 중심 값 이동 형태), 군집 개수 먼저 선정
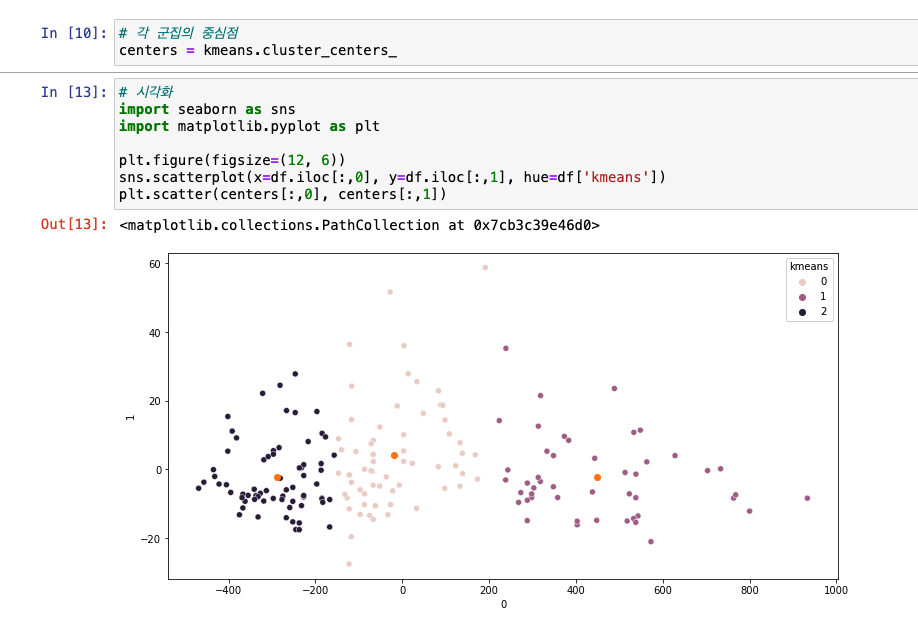
군집 분석 평가 지표
- 실루엣(Silhouette), Dunn Index 등
비계층적 군집분석
- 대표 방법 : K-means
- K-평균군집(centroid): 임의 지점 K개 선택 -> 해당 중심에 밀접해 있는 데이터 군집화
- 하이퍼파라미터 중
n_clusters반드시 설정 - 라이브러리 :
from sklearn.cluster import KMeans

PCA -> 군집 -> 시각화
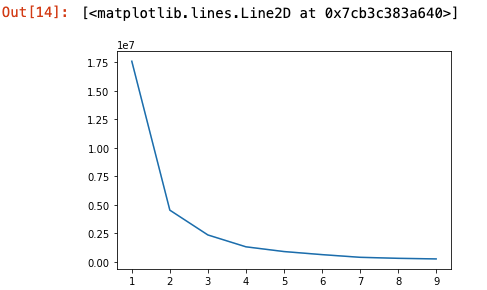
엘보우 방법(클러스터 개수 찾기)
- elbow method
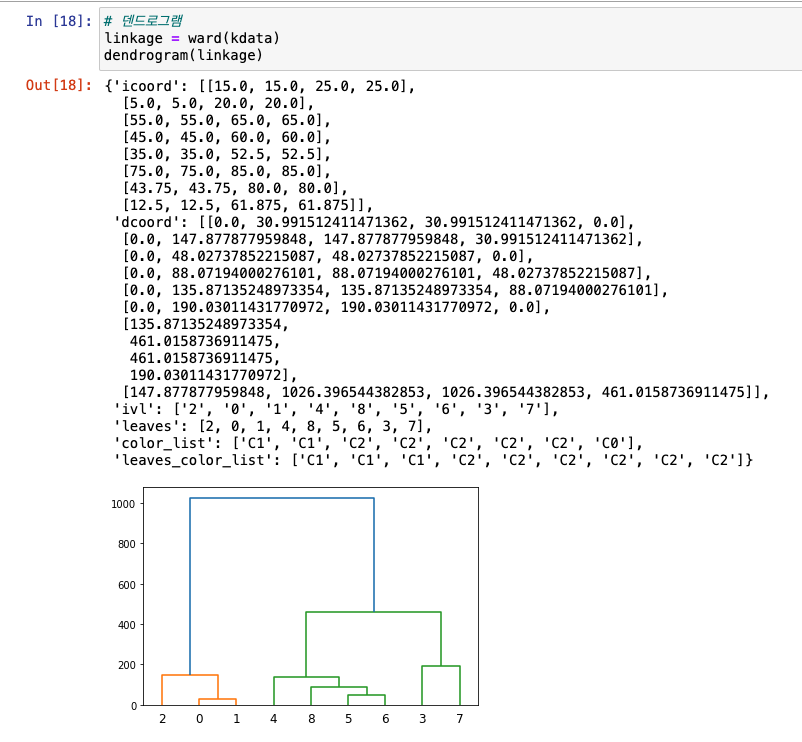
계층적 군집분석
- 대표 방법 : 덴드로그램(개체간 결합 순서, 트리 형식 다이어그램)
- 군집 개수 사전 설정 없음
- 덴드로그램 라이브러리 :
from scipy.cluster.hierarchy import dendrogram, ward
PCA -> 타겟별 샘플링 -> 덴드로그램

언젠가 내 코드로 세상에 기여할 수 있도록, Data Science&BE 개발 기록 노트☘️