[이론 내용만] Node 03. Data transformation - 연봉 데이터 다루기
☺️ AIFFEL 데이터사이언티스트 3기

3-1. 들어가며
학습 목표
- 데이터의 병합 및 변환
- 데이터 스케일 변환
- 카테고리형 데이터 -> 숫자로 변환
- 데이터 차원 축소
3-2. Data merge(데이터 병합)
- 임의 데이터 만들기

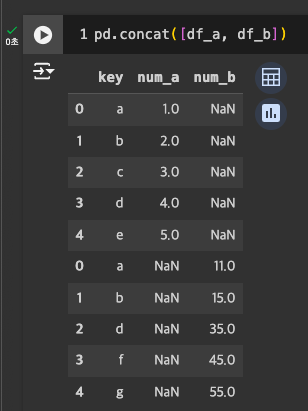
concat: 데이터프레임 병합
-
2개
-
df_a, df_b
-
df_b, df_c

-
인덱스는 새로 들어가지 않고, 기존값 그대로 가져옴 -> 새로 지정하려면 인덱스 리셋 필요

- 3개

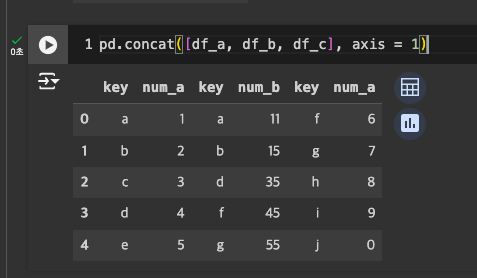
- 수평 결합도 가능 : axis = 1
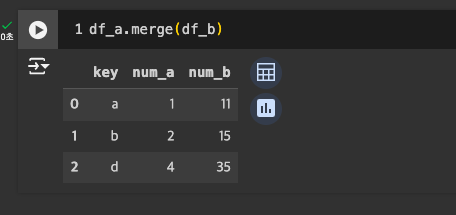
merge: key 기반 결합
- concat과 달리 key가 하나로 합쳐짐.
Join
🔗 Node 05. 여러 개의 테이블 사용하기-JOIN 종류 4가지 참고
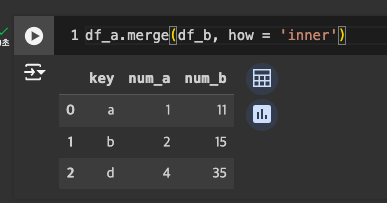
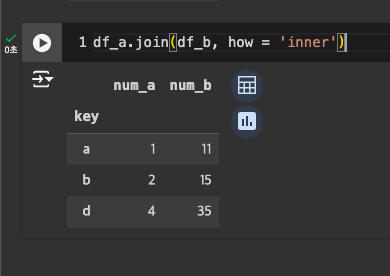
- Inner join: 공통키(디폴트)
- Left join: 왼쪽 기준으로 모든 행, 오른쪽은 일치하는 것만
- Right join: 오른쪽 기준으로 모든 행, 왼쪽은 일치하는 것만
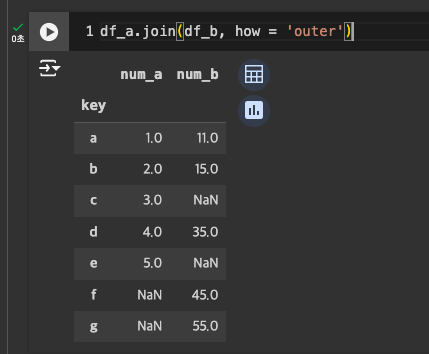
- Outer join: 모두, 불일치는 NaN으로
-
기본은 inner join
-
outer join
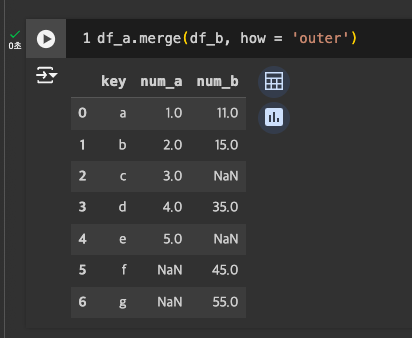
-
left join

-
right join
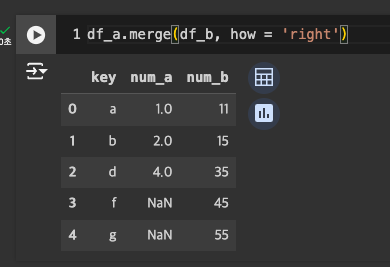
-
기준 컬럼 지정: on = '컬렴명'

-
key가 아닌 다른 이름의 컬럼 실험하기
-
겹치는 내용이 없으니, 아무것도 나오지 않음.(∵디폴트는 완전히 겹치는 것만)
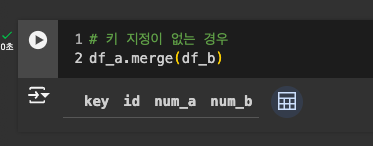
-
컬럼명 : key
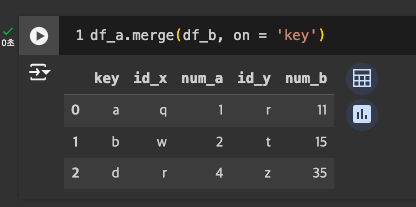
-
컬럼명 : id
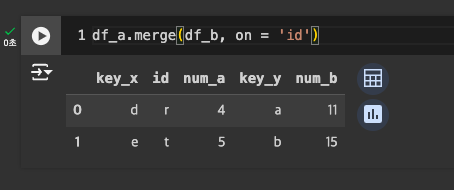
-
-
join type까지 지정하면

- 다른 컬럼을 합치는 방법 : left_on = '컬럼명', right_on = '컬럼명'
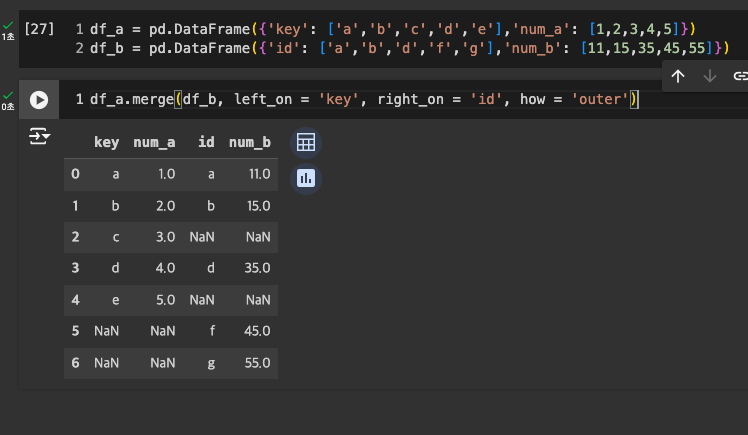
join
- 이 function을 사용할 때에는 지정 필요
- lsuffix = '_a', rsuffix = '_b'
- concat과 같은 모양(그냥 가져다 붙임) -> join은 key를 index 값으로 잡기 때문

-
원하는 컬럼 지정 : .set_index('컬럼명')
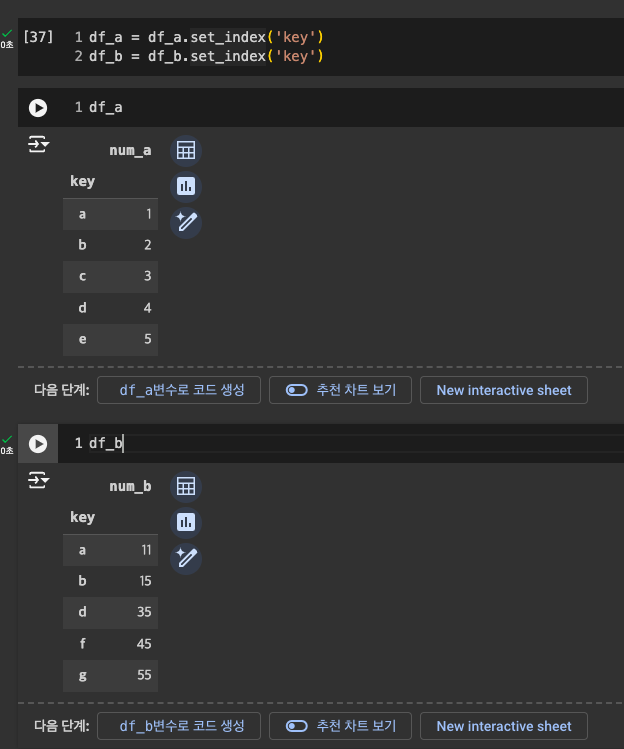
-
join은 디폴트 : Left!

-
outer join
-
inner join
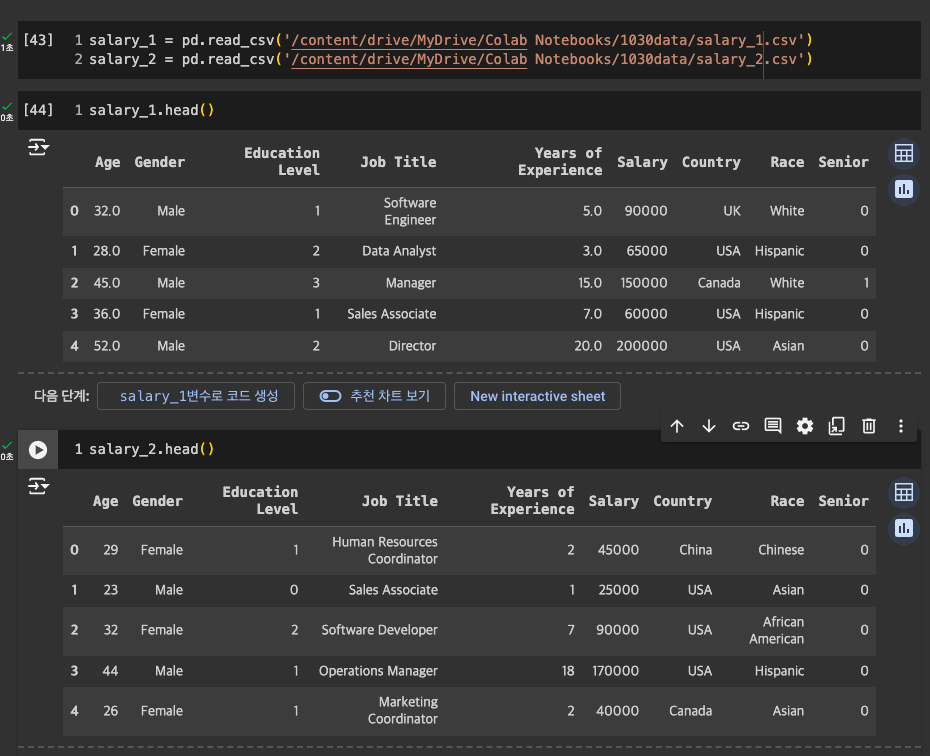
연봉 데이터 불러와서 실습
-
두 데이터 파일이 내용만 다르고 컬럼은 일치!
-
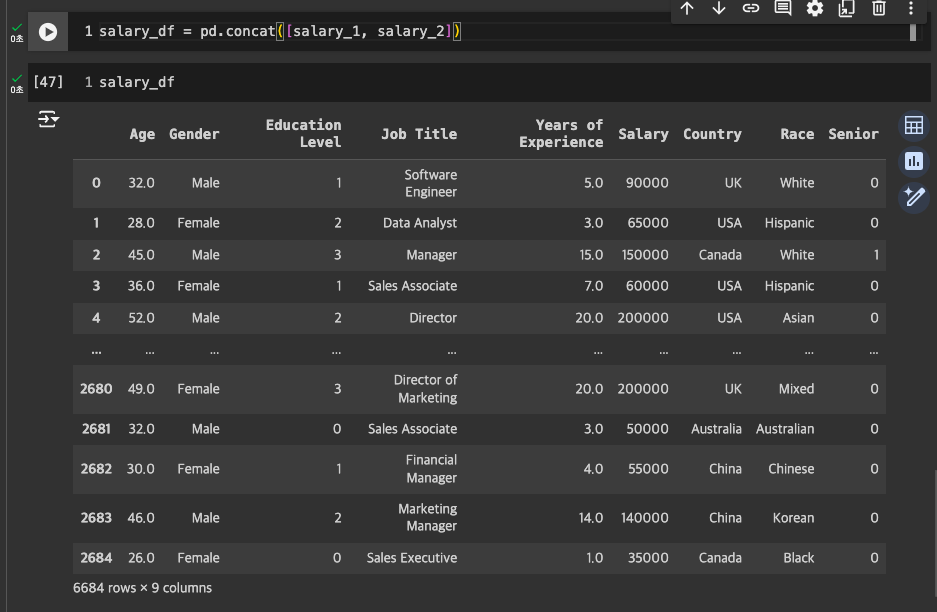
concat으로 이어붙이기 -> salary_df로 저장
-
인덱스 중복 발생했을 것임.
reset_index
- 별도 컬럼이 또 생기기 때문에,
drop = True, inplace = True사용해서 드랍하기
국가별 연봉이 다를테니 cpi 데이터 합치기
-
국가 표현이 조금 다른 부분이 있어 변경 후 합칠 것.
-
고유값 확인 후 변경
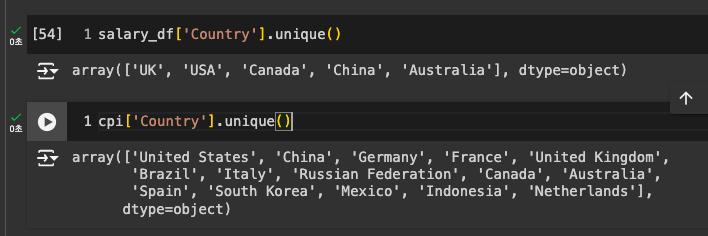

-
데이터 합치기 : merge
- salary_df가 중심이기 때문에 left
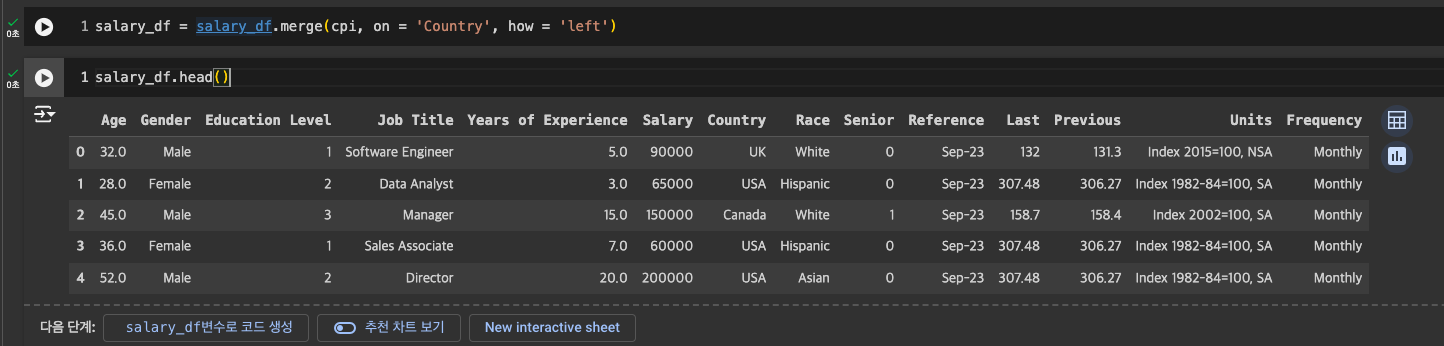
- salary_df가 중심이기 때문에 left
-
cpi에서는 Last만 필요하므로 나머지 드랍해서 정리
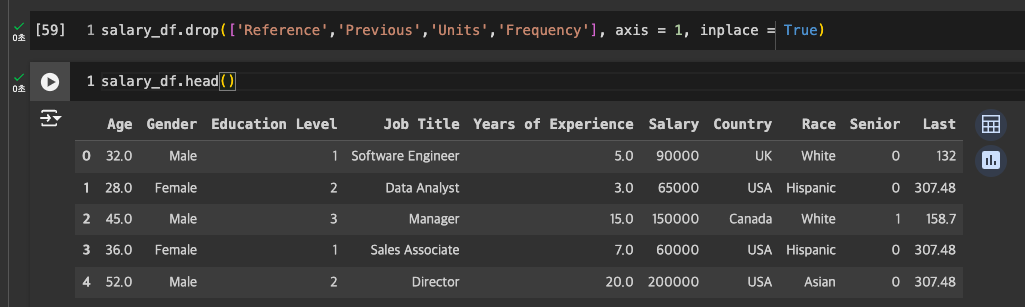
-
cpi 지수라는 것을 명확히 표현하기 위해 Last -> CPI

merge, join 추가 특징
- merge: 공통 컬럼 -> suffix 자동 생성(SQL 스타일)
- join: 공통 컬럼 -> suffix 수동 생성
3-3. 개요, 결측치&이상치(Missing Value & Outlier), 집계 및 그룹화(Aggregation and Group by), 피벗테이블(Pivot)
-
Age에 Null Value가 있고, CPI가 숫자가 아닌 object로 되어 있음.
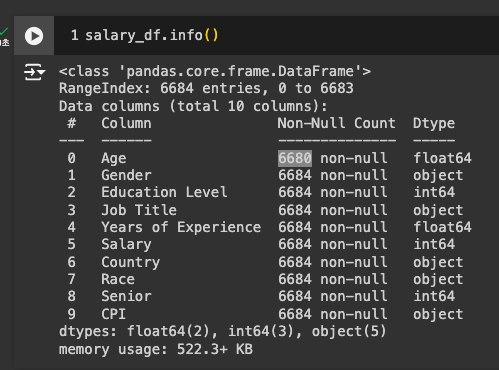
-
CPI를 숫자형으로 변경 : pd.to_numeric

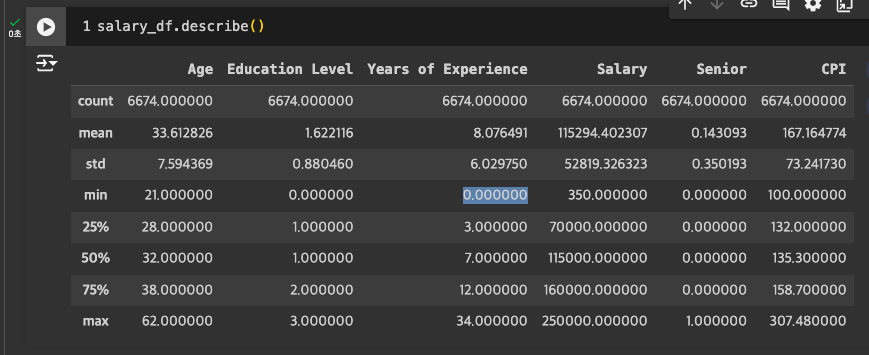
결측치, 이상치 파악
- Age에 약간의 Missing Value 존재
- Experience(경력)에 잘못된 값(음수) 존재 -> 드랍 또는 대체 예정
- max 값도 82년이 가능한 수치인지 의문.
- salary에도 350으로 너무 낮은 수치가 있어 -> 아웃라이어 확인
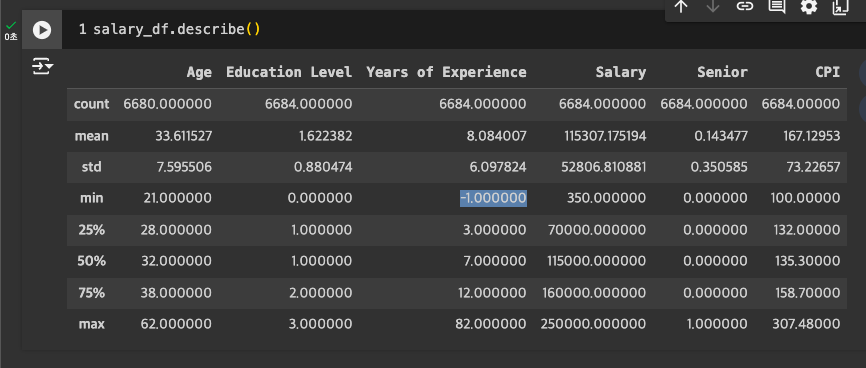
Missing Value
-
확인
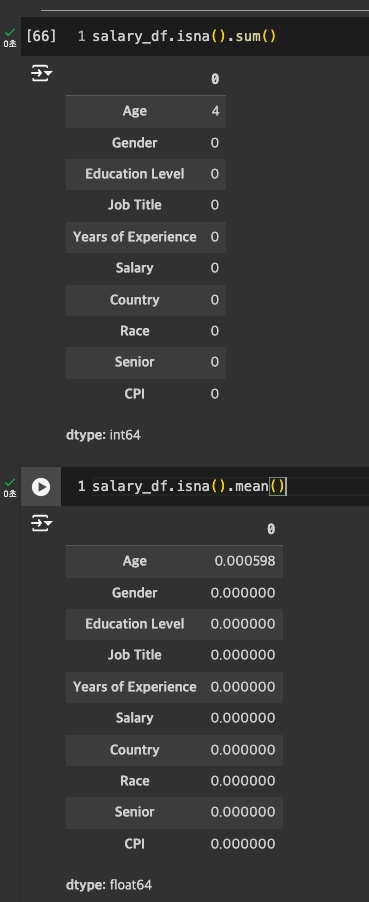
-
Age
- 4건 발견
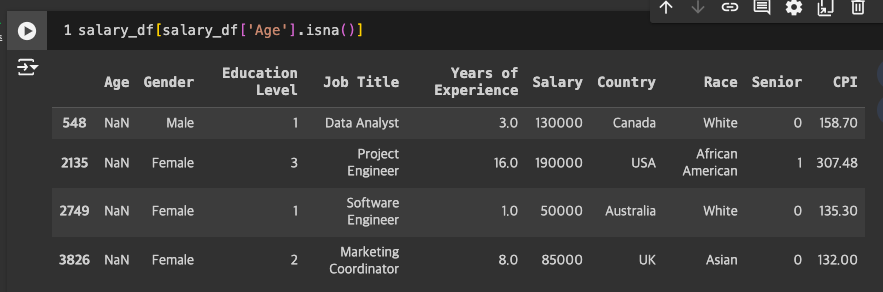
- 평균값 나이로 넣으면 -> 노이즈가 낄 수 있을 것 같아서 Drop하는 것으로 결정.

- 4건 발견
-
Years of Experience 음수 처리
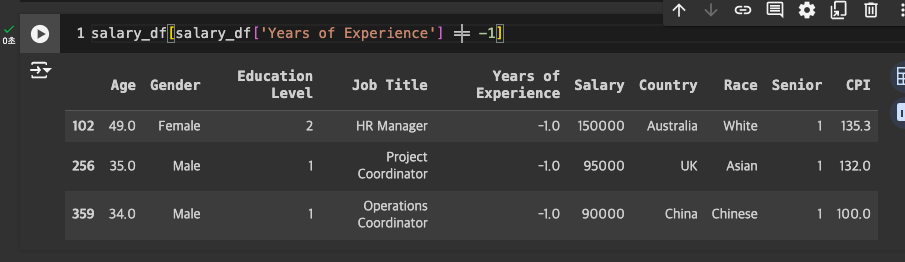
- 음수 제거

- 음수 제거
-
Years of Experience가 82년?
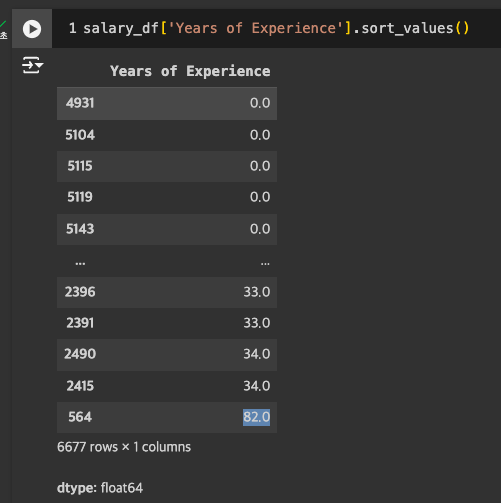
- 25세인데 경력이 말이 안되는 수치.

- 15세부터 일을 하는 것도 무리가 있어보임 -> 제거
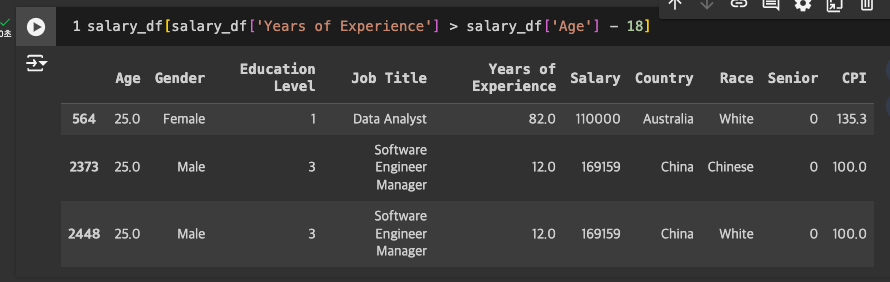

- 25세인데 경력이 말이 안되는 수치.
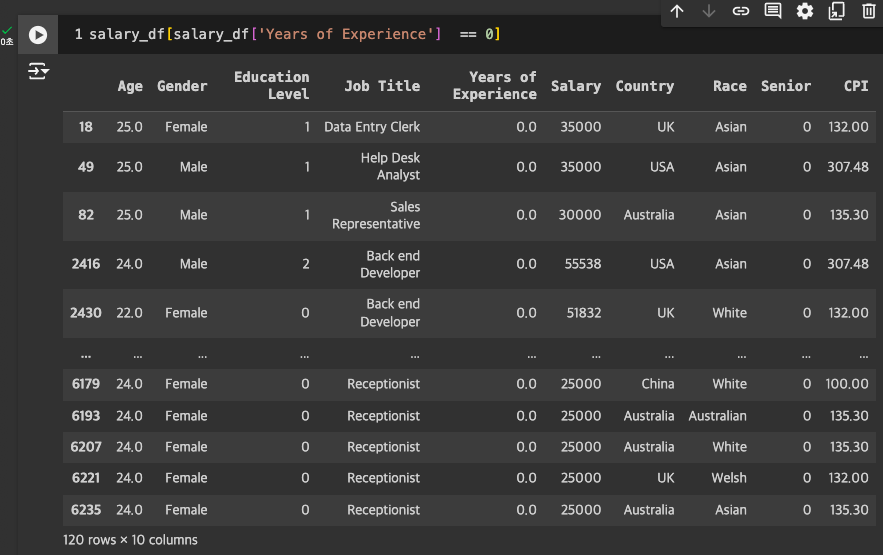
- Years of Experience에 0이 있는 것도 확인
- Age를 고려했을 때 불가능한 수치는 아닌 것으로 파악
- Age를 고려했을 때 불가능한 수치는 아닌 것으로 파악
groupby
-
groupby를 쓰지 않는 일반적 방법
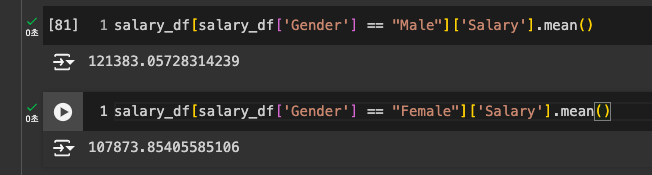
-
groupby
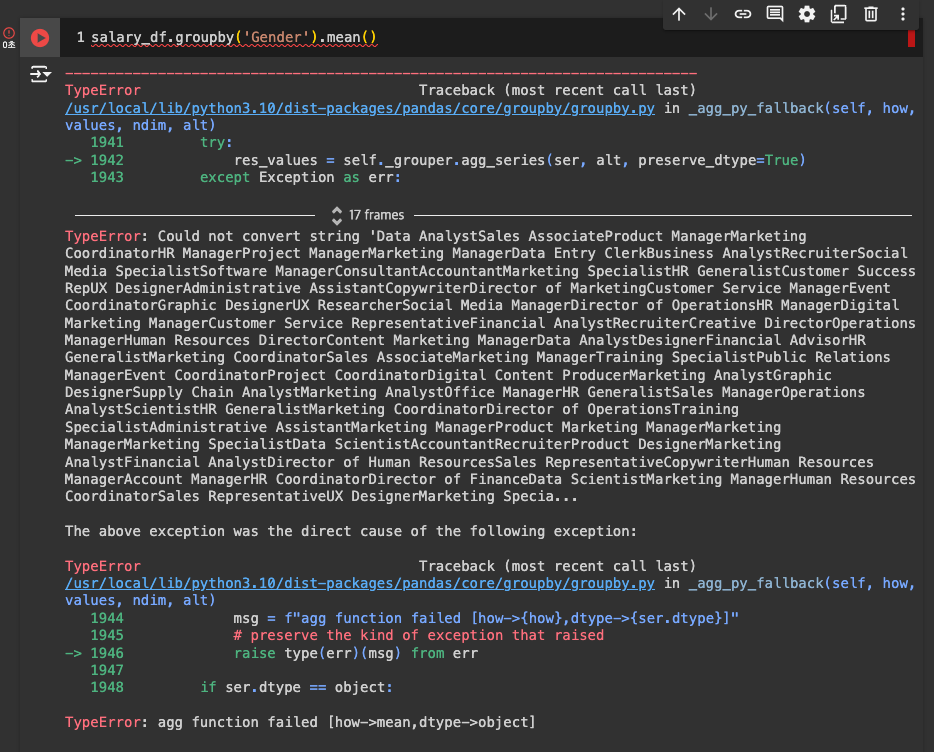
-
우선 숫자만 반영해서 출력해보기
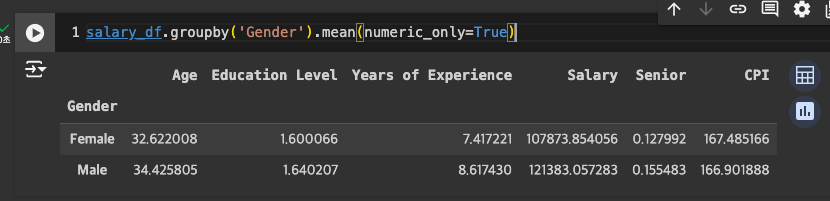
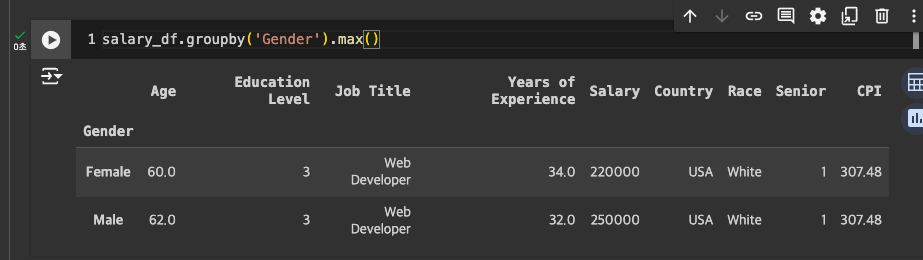
-
Salary만 보고 싶다면

-
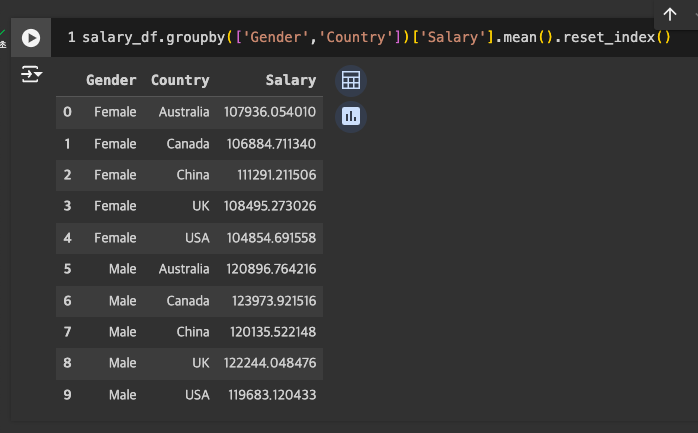
국가별 평균 연봉이 알고 싶다면
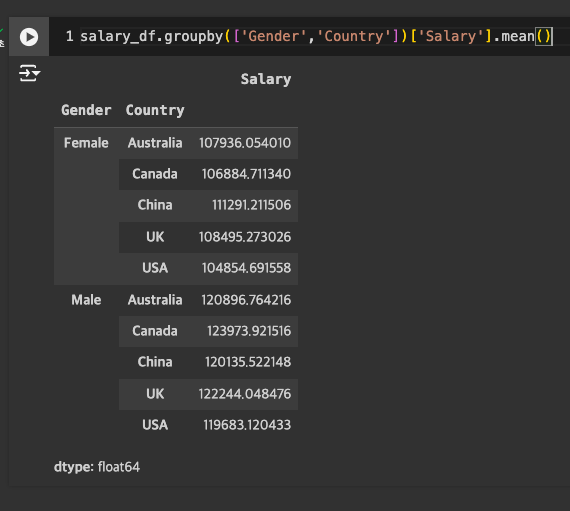
-
min, sum 한꺼번에 : agg
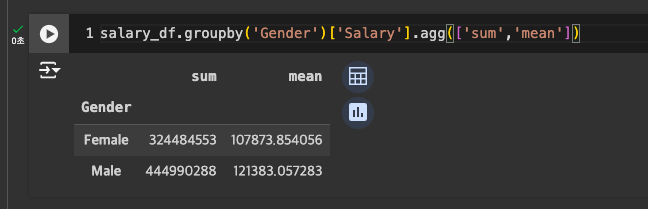
-
reset_index()로 각 컬럼으로 만들어 편하게 확인
-
pivot table

-
원하는 연산 지정 : aggfunc = '연산명'
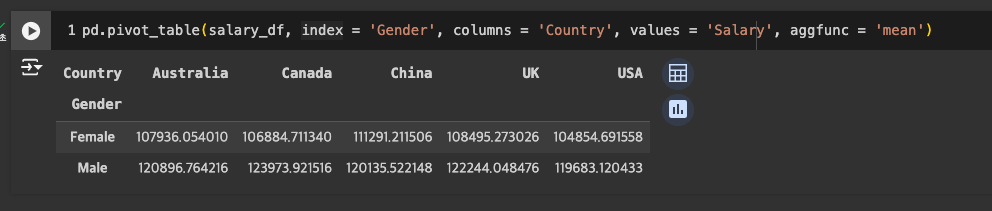
-
numby 연산 불러오기도 가능
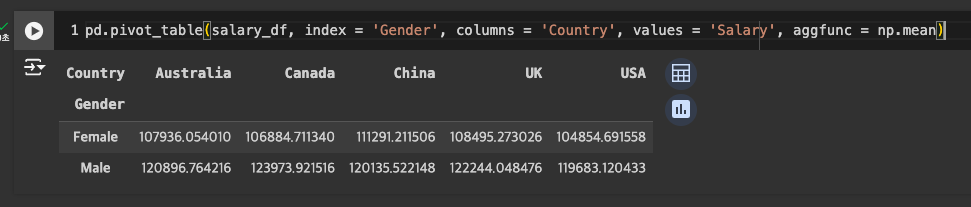
-
sum

- 3개 컬럼도 가능
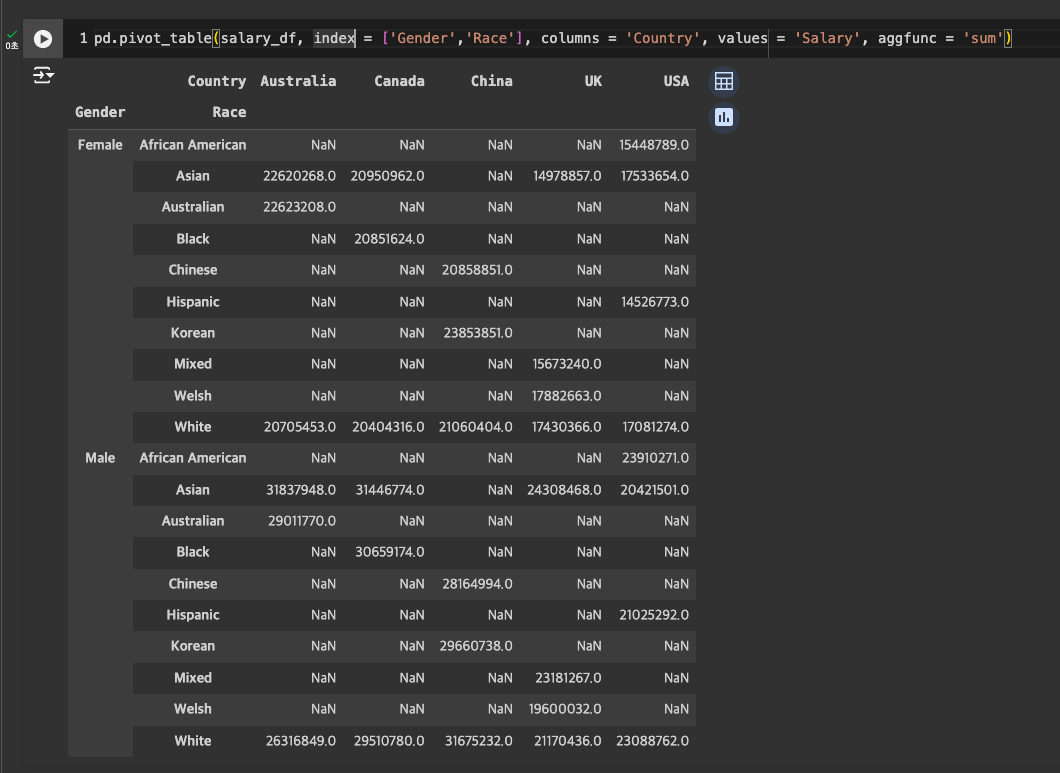
- 3개 컬럼도 가능
table로 pivot table 뽑기
-
임의 데이터 만들기
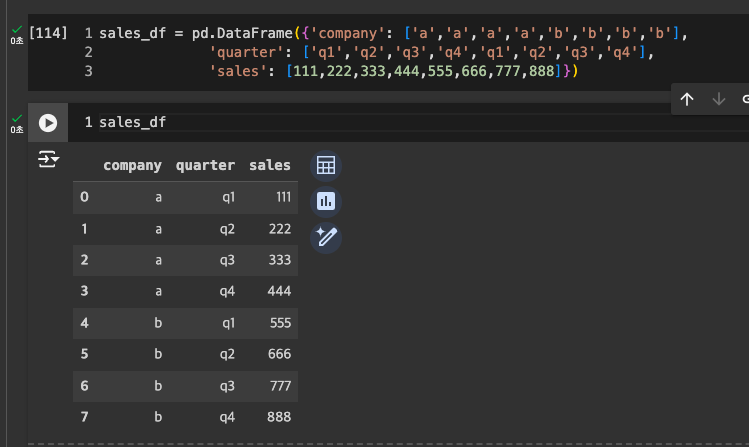
-
pivot table 생성

-
quarter 제거 -> new_sales_df로 저장

pivot table을 다시 원래의 table로 원상복구는?
- melt 사용

3-4. 로그(Log), 원-핫 인코딩 (One hot encoding)
log
-
임의 데이터 작성
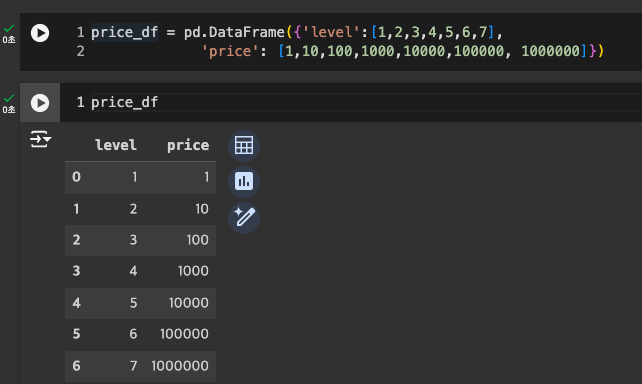
-
seabon 불러오기(Warnings 무시)
-
log를 사용해서 스케일 잡아주기
-
기존
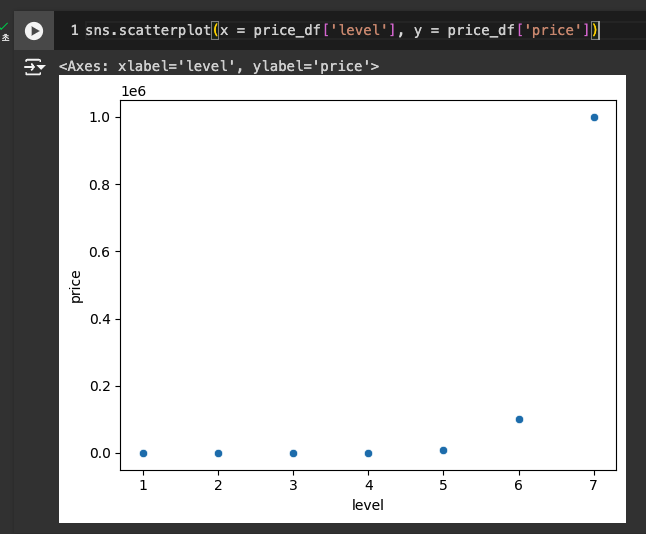
-
log 적용
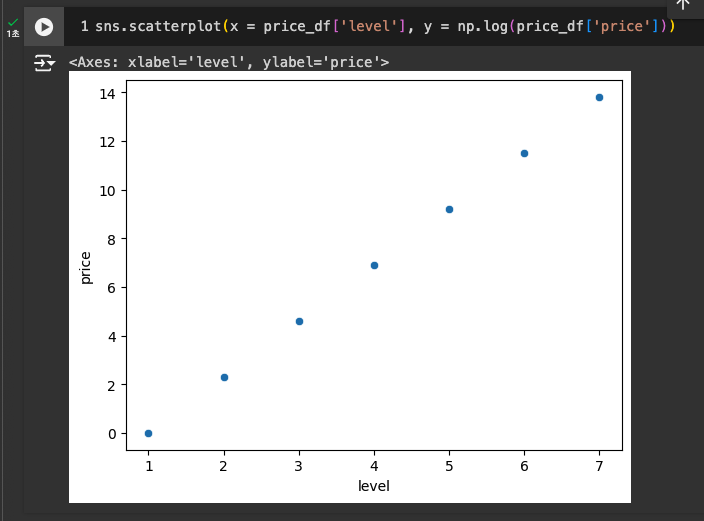
-
np.log() -> 로그 적용, np.exp() -> 로그를 다시 숫자로 되돌리기
원-핫 인코딩 (One hot encoding)
- 카테고리형 데이터(문자로 구성) : Gender, Joub Title, Country, Race

참고: 인코딩을 왜 해?
- 대부분의 머신 러닝 모델은 숫자가 아니면 제대로 인식하지 않음 -> 인코딩 필요
- 문자열의 경우, 실제로는 그렇지 않더라도 수치로 매핑을 잘못하면 크기를 비교할 수 있음.
- 1과 2로 사용하면 안됨.
- 0과 1로 매핑할 것!
- salary_df의
Senior컬럼도 그런 형태!
- 3개 이상의 컬럼이 있다면..
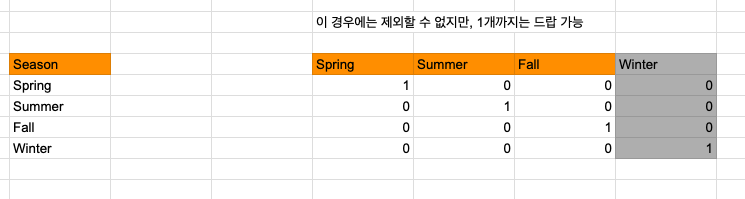
- Salary를 모델에서 예측
- 선형 모델의 경우, 0과 1이 바뀌면 해당 연산을 맞춰 변경하면 됨.
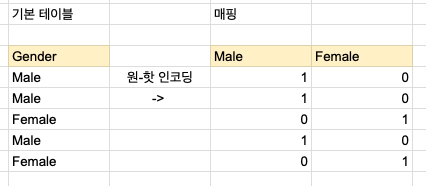
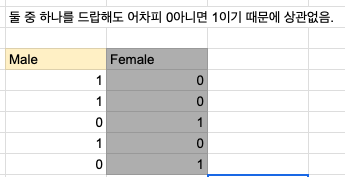
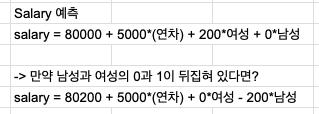
get_dummies
- 둘 중의 컬럼 하나는 없어도 무방하다고 했으니 -> drop_first = True 사용!
- 구글 코랩에서는 값이 True, False로 출력되어 타입을 int로 강제변환하여 확인해보기

- 구글 코랩에서는 값이 True, False로 출력되어 타입을 int로 강제변환하여 확인해보기
🧐 왜 구글 코랩에서는 True, False로 나올까?
- pandas 업데이트로 인해 값이 True, False로 변경되었다고 함!
원핫 인코딩에서 0,1이 아니고 False,True가 나옴
unique 값 최소화
-
고유값 확인하기

- Job Title의 경우 과하게 많아서 줄이기로 결정.
-
Job Title 살펴보기
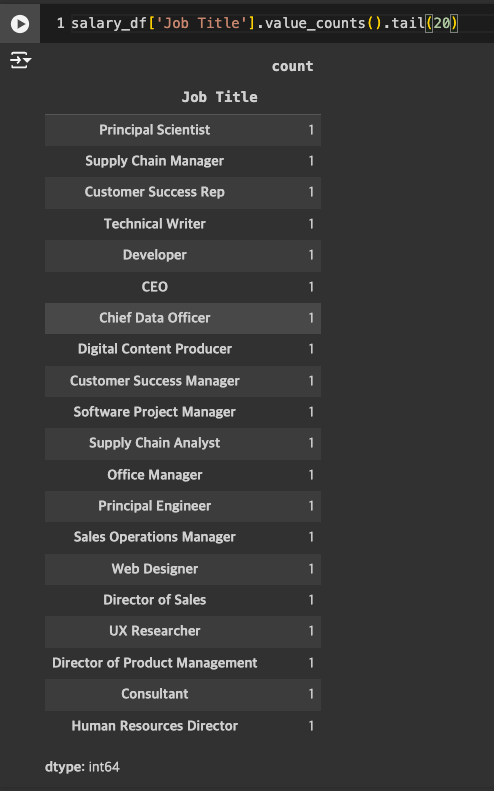
- 머신러닝 모델링을 할 때에는 케이스가 1개인 경우는 큰 영향을 미치지 않음 -> 처리 필요!
-
고유값들이 상당히 많은 편
- Manager, CEO와 같은 직급도 있고, HR 같은 경우도 HR 또는 Human Resources 같이 여러 이름으로 적혀 있는 경우가 많음.
- 실제 일을 할 때에는 이 부분을 오랜 시간을 들여 분석하고 값을 정리해서 csv로 다시 만들어 merge 해야함.
-
값을 정리한 job.csv 사용

-
merge로 값 합치기(key를 기준으로 하는 것이 좋기 때문)
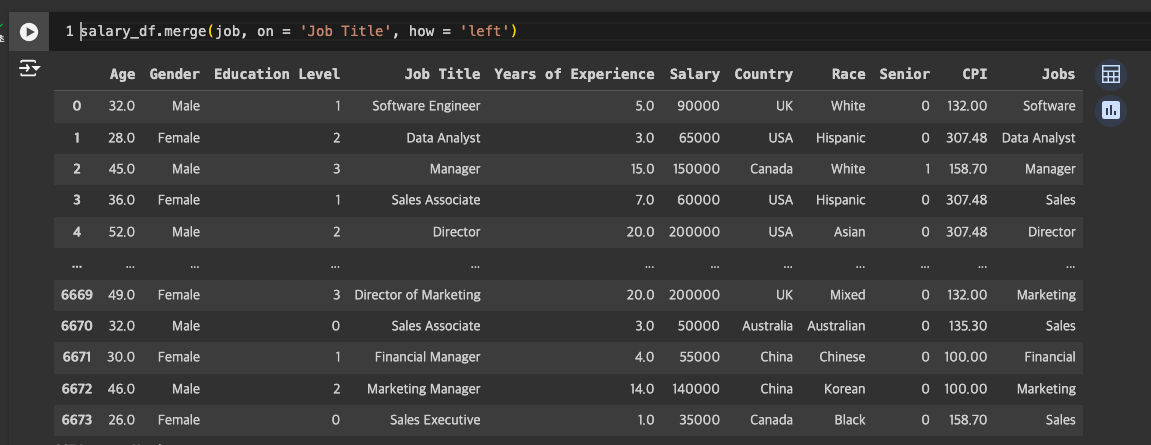
-
Job Title은 더이상 사용하지 않으니, 드랍
-
이전보다는 정리가 잘 되었음.
- 그러나, 10 이하의 값들은 무의미할 가능성 높음.
- 1에 해당하는 값은 -> others로 바꿔줘도 됨.
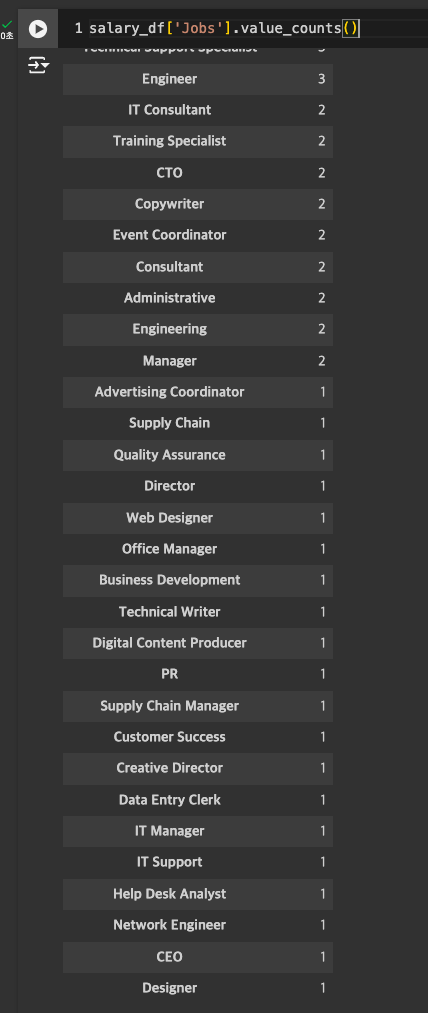
-
원핫 인코딩 재진행


3-5. 스케일링 (Scaling)
Scale
- 데이터 단위의 크기(범위)
Scaling
- 데이터 범위 조정 과정
- 종류
- Standard Scaling : 평균 0, 분산 1 형태로 데이터 재배열
- Robust Scaling : 스탠다드와 비슷, 아웃라이어 영향 덜 받음.
- Min-Max Scaling : 최댓값 1, 최솟값 0
- 스케일링은 언제 쓰지?
- 각 변수 Scale이 중요하게 작용하는 경우(머신러닝 알고리즘 KNN 등)
Age 컬럼으로 연산 실습
-
평균

-
표준 편차
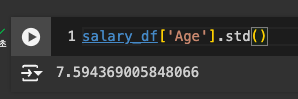
Standard Scaling

Robust Scaling
- q1, q2, q3가 필요
- quantile 사용

- quantile 사용
Min-Max Scaling
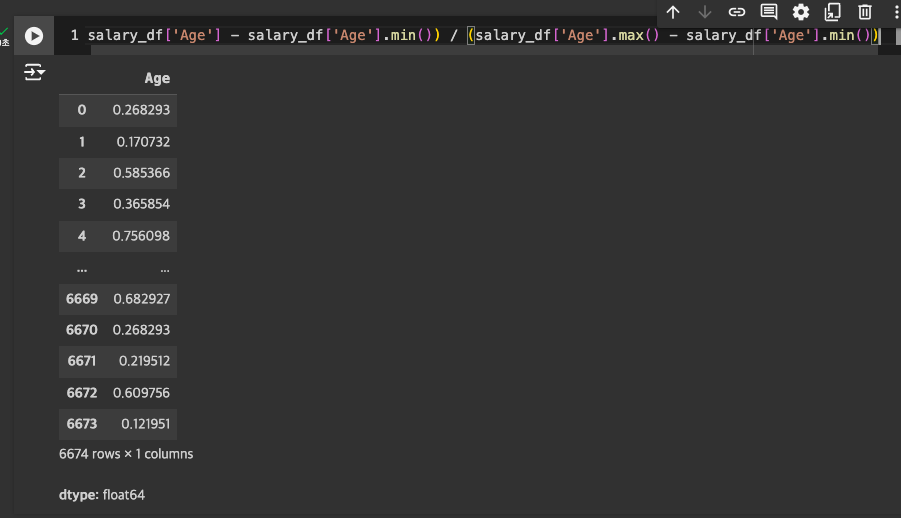
79개의 칼럼을 모두 일일이 스케일링하기엔 무리가 있음.
sklearn 라이브러리를 이용한 자동 스케일링
- StandardScaler, RobustScaler, MinMaxScaler

StandardScaler
-
학습
-
기본적으로 데이터프레임으로 감싸도, 컬럼 이름은 사라지기 때문에 적용
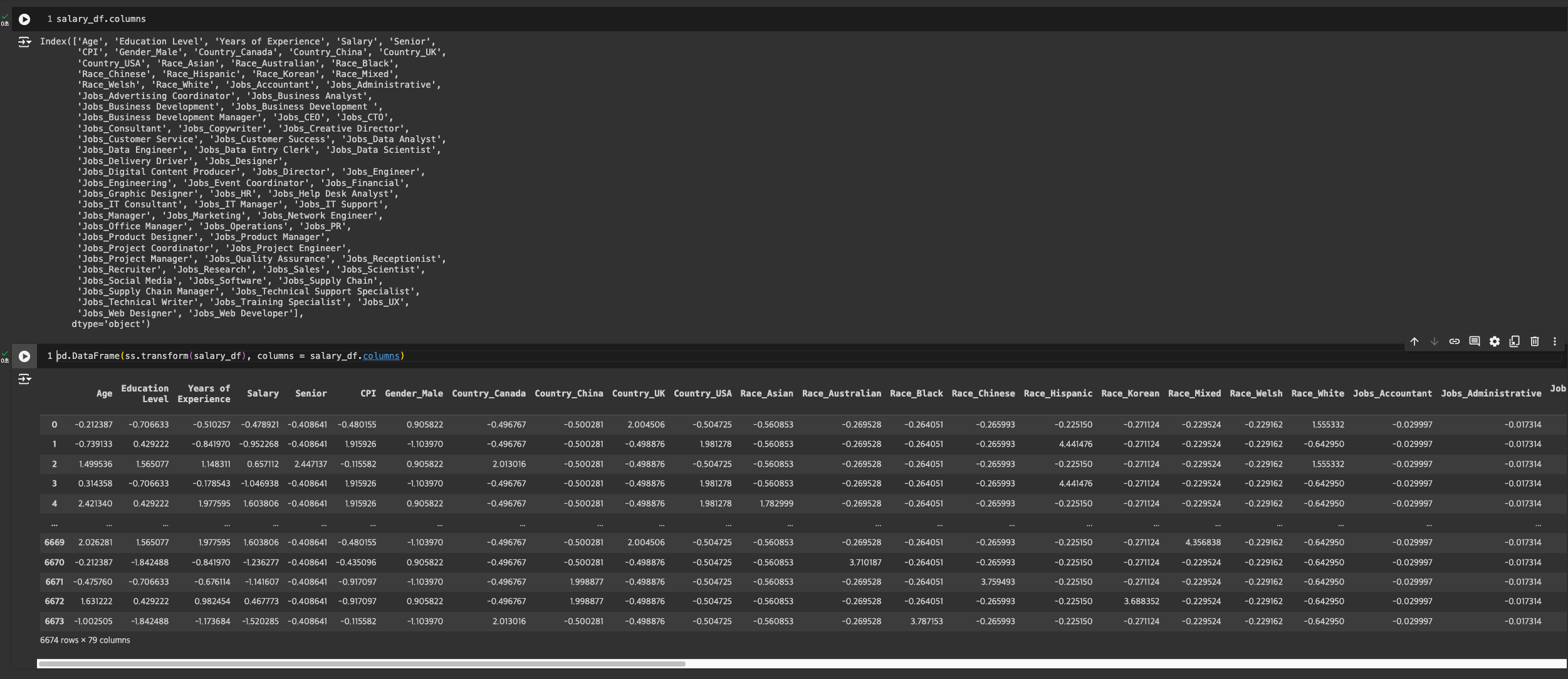
RobustScaler
-
학습
-
데이터 프레임 적용

MinMaxScaler
-
학습
-
데이터 프레임 적용

결과 보기
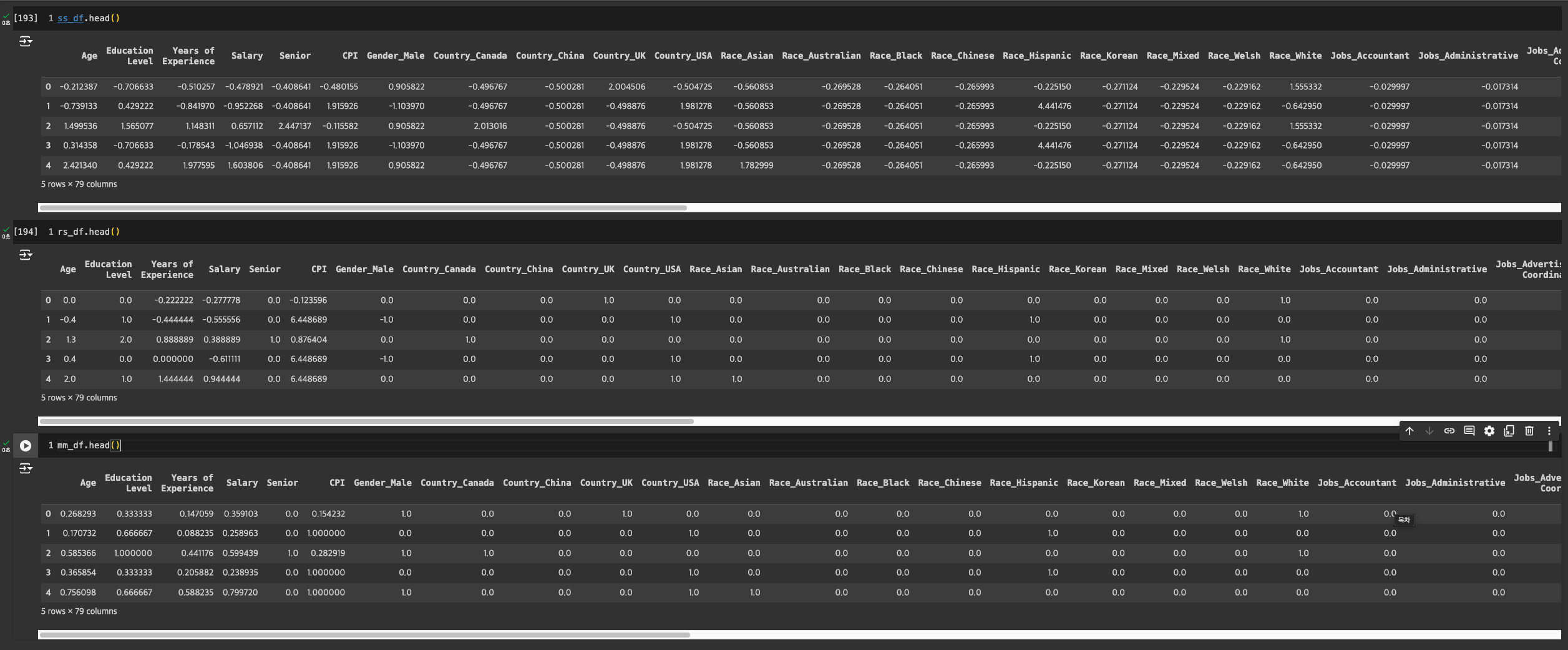
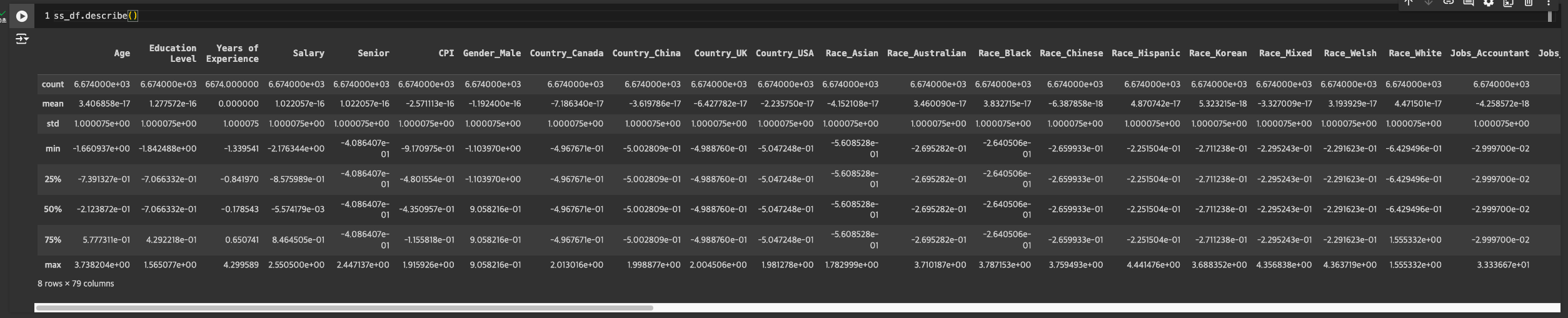


참고 : 값의 의미
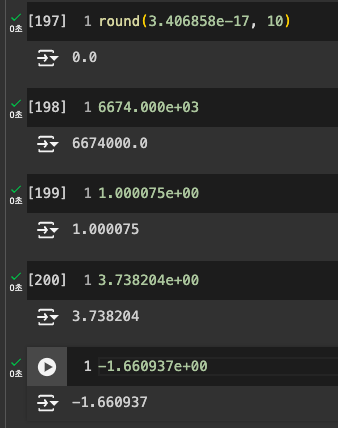
어떤 스케일링 기법을 적용하면 좋을까?
-
Standard Scaling
- 아웃라이어가 적은 데이터일 경우 사용하기 좋음.
- 변수 분포가 정규 분포를 따를 때 적합
- ex) Linear Regression(연속 값 예측), Logistic Regression(로지스틱 회귀, 독립 변수 선형 결합을 통한 적합한 확률 결과를 제공, 분류 문제에 적합), SVM(support vector machine, 이진 또는 다중 클래스 분류, 회귀)
-
Robust Scaling
- 아웃라이어가 많은 데이터에 적합
- 정규분포를 따르지 않는 데이터가 많을 경우에도 유용
-
Min-Max Scaling
- 스케일링 결과값의 범위를 제한하고 싶을 때
- 딥러닝에 유용
스케일링의 단점
- 원핫인코딩을 한 값의 경우 0과 1로 차이가 더 큼.
- 그렇지 않은 경우 더 작게 차이가 남(원래 데이터이기 때문)
- 거리 기반 모델 사용 시, 원핫인코딩을 한 데이터들이 변환값이 더 큰 차이를 보일 수밖에 없음.
학습과 결과를 한번에 연산하면 안돼?
- fit_transform 사용
3-6. 주성분 분석 (PCA), 복습 (Recap)
PCA
-
Principal Component Analysis
-
주성분 분석
-
데이터 차원(=변수의 개수) 축소
-
데이터 주요 특성은 유지 -> 차원 축소 -> 계산에 효율성 부여
-
기존의 변수 개수만큼 주성분을 뽑아낸다!
- 주로 직교하게끔 만들어 주성분을 분석함.
- 분산이 가장 큰 축을 찾아 모두를 커버함!
- 100% 커버가 가능하게끔 해야하기 때문
- 주로 직교하게끔 만들어 주성분을 분석함.
-
마지막 주성분일수록 적은 데이터를 가지고 있음.
PCA 분석 실습
-
decomposition 사용
-
학습

-
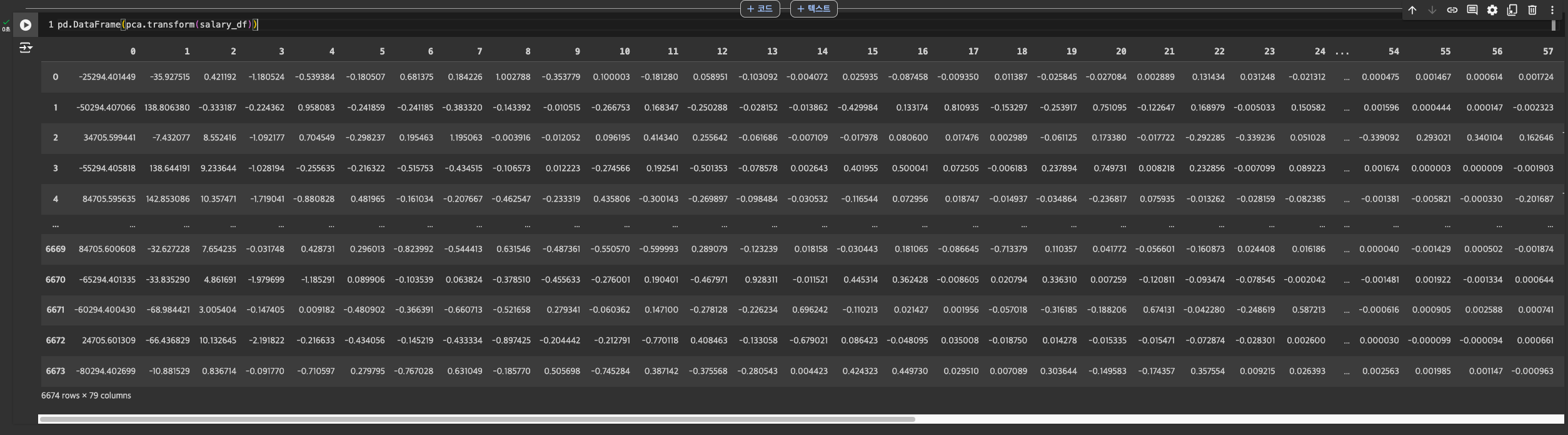
변환(데이터 프레임 적용)
-
이것도 학습&변환 한번에 가능 : fit_transform
특정 개수의 주성분만 뽑고 싶은 경우
- PCA에 그 숫자를 넣어주면 됨.

정보 손실률 파악하기
explained_variance_ratio_- 각 주성분이 -> 원본 데이터 variance(분산)을 얼마나 잘 설명하는지 비율!

-> 거의 정보 손실이 없다고 봐도 무방
- 각 주성분이 -> 원본 데이터 variance(분산)을 얼마나 잘 설명하는지 비율!
PCA 장점
- 시각화에 용이
- 다중공선성 처리 가능
- ex) 상관관계가 높은 경우 : 우리 데이터에서 나이와 경력 -> 나이가 많을수록 경력이 많을 수밖에 없음.
- corr로 상관관계 보기
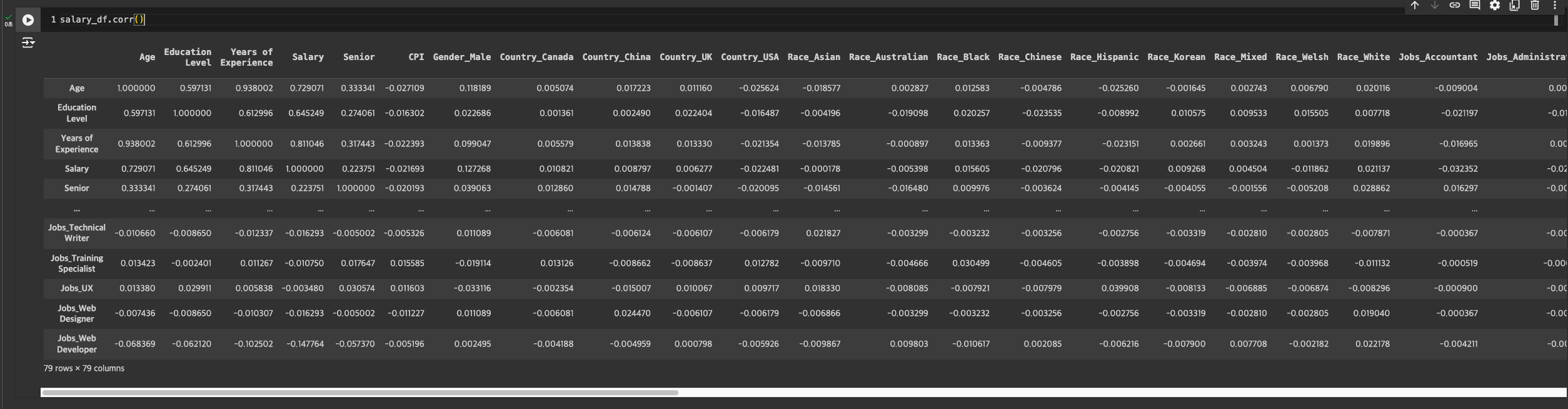
PCA 단점
- PC1, PC2와 같이 지정한 컬럼이 어떤 값을 가지고 있는지 알 수 없음. -> 변수의 특성을 설명할 수 없게 됨.
- 컬럼의 특성을 합친 것이기 때문에 명확한 특성을 말할 수 없는 것
