Node 01. 사이킷런을 활용한 추천 시스템 입문
☺️ AIFFEL 데이터사이언티스트 3기

1-1. 들어가며
학습 목표
- 추천 시스템 기본 개념
- 추천 시스템의 종류 학습 및 사이킷런을 이용한 연습
- 실제 추천 시스템 이해
학습 내용
- 추천 시스템이란?
- 코사인 유사도
- 추천 시스템 종류
- 콘텐츠 기반 필터링
- 협업 필터링
- 사용자 기반
- 아이템 기반
- 잠재요인 협업 필터링
- 실제 추천 시스템
사전 준비
- 클라우드 주피터 이용 시 설정 필요
$ mkdir -p ~/aiffel/movie_recommendation1-2. 추천 시스템이란?
추천 시스템
-
사용자에게 관련 아이템을 추천해 주는 것
-
예시) 영화 추천
- A: 한국 드라마/영화, 로맨스물
- B: 미국 드라마/영화, 액션물
- "부부의 세계", "스파이터맨 파프롬 홈", "타짜"가 상영중일 경우, 각각 어떤 영화를 추천해주면 좋을지?
- A : 부부의 세계, B : 스파이터맨 파프롬 홈
-
실제 추천 시스템 ➡️ 영화를 좌표 평면에 표현
- 거리가 좁을수록 유사도가 높음!
-
예시) 취향 부분에 체크를 하지 않고 가입한 C
- A: 32살/여성/대한민국/마케팅/인천
- B: 41살/남성/미국/군인/용산
- C: 21살/여성/대한민국/학생/서울
- C와 비슷한 사람인 A가 선호했던 것을 위주로 먼저 추천!
-
추천 로직
- 범주형, 이산적 데이터를 숫자 벡터로 변환
- 숫자 벡터 유사도 계산을 통해 유사도가 높은 제품 추천
1-3. 코사인 유사도
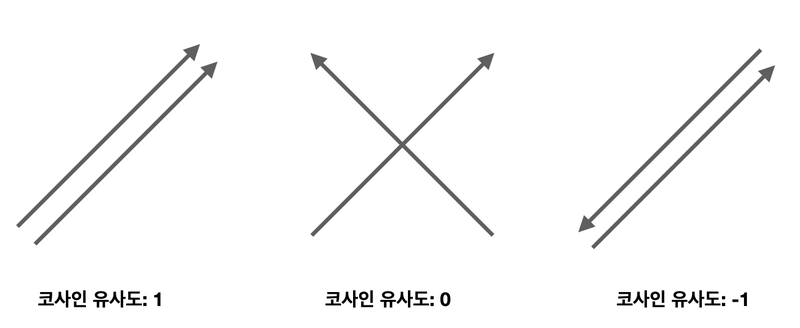
코사인 유사도(Cosine Similarity)
- 두 벡터 간 코사인 값으로 두 벡터 유사도 계산
- 두 벡터의 방향이 이루는 각에 코사인을 취함
- 코사인 유사도 :
-1 ~ 1, 1에 가까울수록 유사도가 높음
- 수식
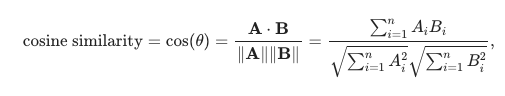
코사인 유사도 계산 실습
NumPy
- 숫자 벡터
import numpy as np
t1 = np.array([1, 1, 1])
t2 = np.array([2, 0, 1])- 코사인 유사도 구하기
from numpy import dot
from numpy.linalg import norm
def cos_sim(A, B):
return dot(A, B)/(norm(A)*norm(B))
cos_sim(t1, t2)
사이킷런
cosine_similarity모듈로 바로 계산 가능!
from sklearn.metrics.pairwise import cosine_similarity- 2차원 배열로 정의
t1 = np.array([[1, 1, 1]])
t2 = np.array([[2, 0, 1]])
cosine_similarity(t1,t2)
- 코사인 유사도 0
t1 = np.array([[1, 1, 1]])
t2 = np.array([[1, -1, 0]])
cosine_similarity(t1,t2)
- 코사인 유사도 -1
t1 = np.array([[1, 1, 1]])
t2 = np.array([[-1, -1, -1]])
cosine_similarity(t1,t2)
기타 유사도
- 유클리드 거리
- 자카드 유사도
- 피어슨 상관계수...
1-4. 추천시스템의 종류
추천 시스템 종류 정리
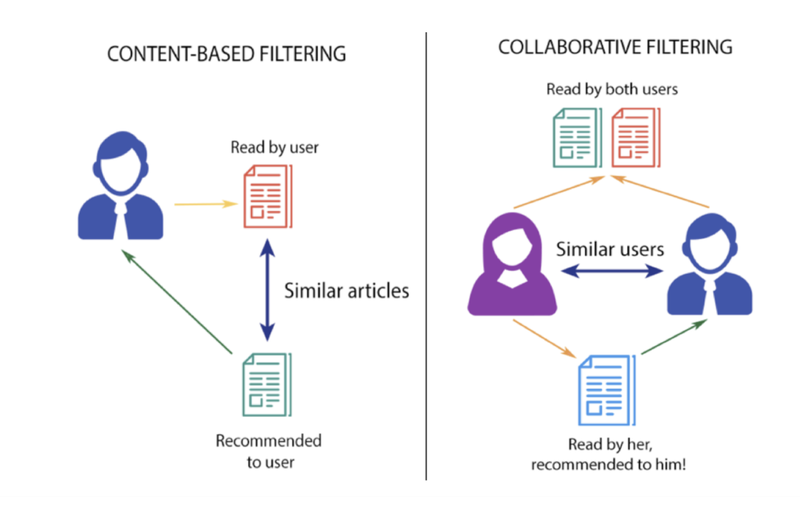
- 콘텐츠 기반 필터링(Content Based Filtering)
- 협업 필터링(Collaborative Filtering)
a. 사용자 기반
b. 아이템 기반
c. 잠재요인 협업 필터링(latent factor collaborative filtering)을 이용한 행렬 인수분해(matrix factorization) - 딥러닝 적용
- Hybrid 방식
1-5. 콘텐츠 기반 필터링
콘텐츠 기반 필터링(Content Based Filtering)
- 순수하게 콘텐츠 내용만 비교해 추천해줌
- 비슷한 콘텐츠 아이템을 추천
- 특성(Feature) : 영화의 경우 장르, 배우, 감독 등 정보들
- 콘텐츠가 비슷하다고 말할 수 있는 요인이 바로 특성!
실습
모듈 import
import pandas as pd
import numpy as np
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.metrics.pairwise import cosine_similarity데이터 Load
- 데이터 :
movie_dataset다운로드 후 저장
import os
csv_path = os.getenv('HOME')+'/aiffel/movie_recommendation/movie_dataset.csv'
df = pd.read_csv(csv_path)
df.head()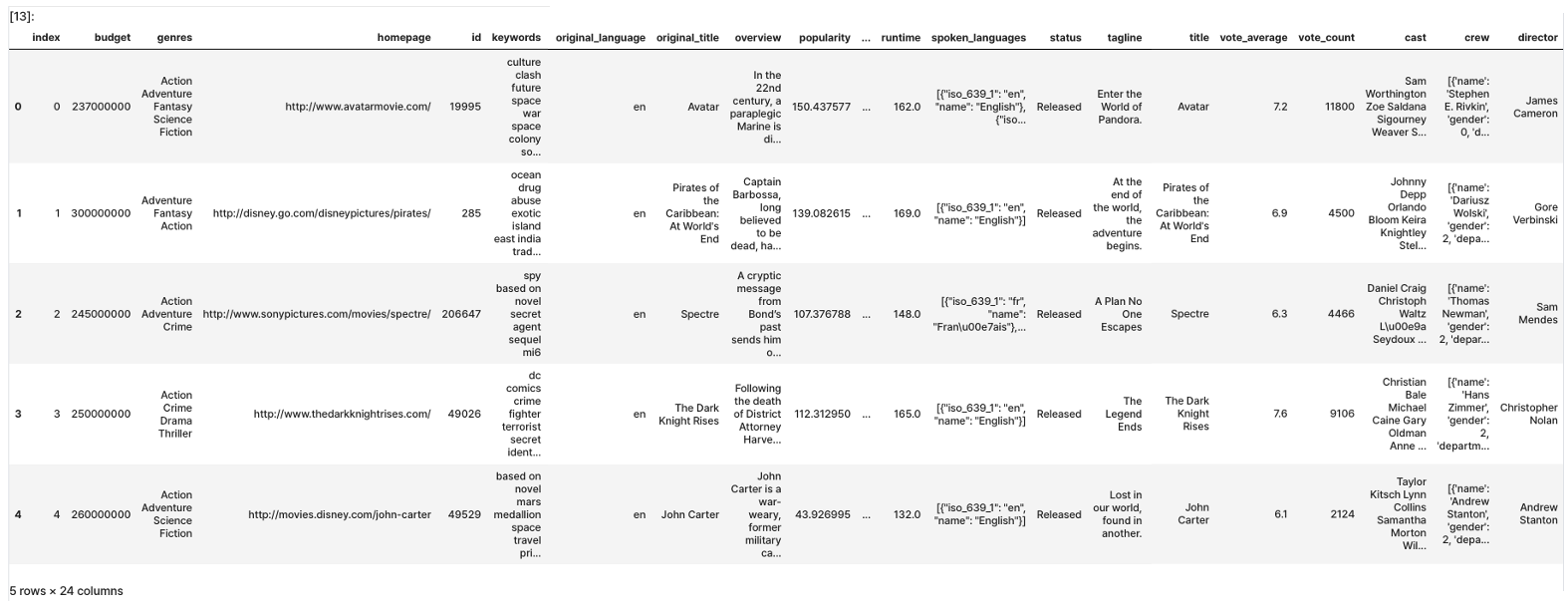
특성 선택
df.columns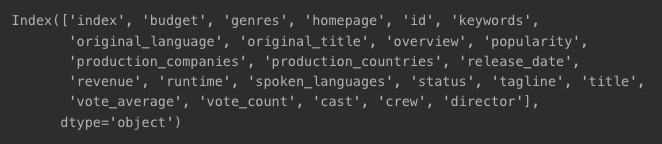
- 일부 특성을 이용해 영화 유사도 계산 및 추천
features = ['keywords','cast','genres','director']
features
- featire combine
def combine_features(row):
return row['keywords']+" "+row['cast']+" "+row['genres']+" "+row['director']
combine_features(df[:5])
- 전체 확인
for feature in features:
df[feature] = df[feature].fillna('')
df["combined_features"] = df.apply(combine_features,axis=1)
df["combined_features"]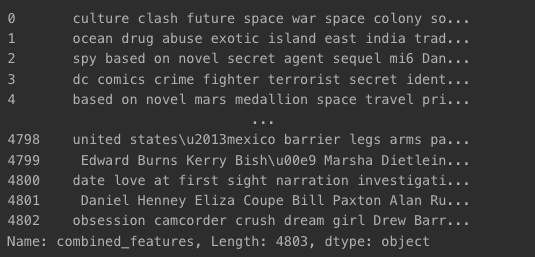
벡터화 및 코사인 유사도 계산
- 범주형 데이터를 숫자 데이터로 변환
- 장르, 배우명, 감독명 텍스트 데이터의 등장 횟수 이요
CountVectorizer()사용
cv = CountVectorizer()
count_matrix = cv.fit_transform(df["combined_features"])
print(type(count_matrix))
print(count_matrix.shape)
print(count_matrix)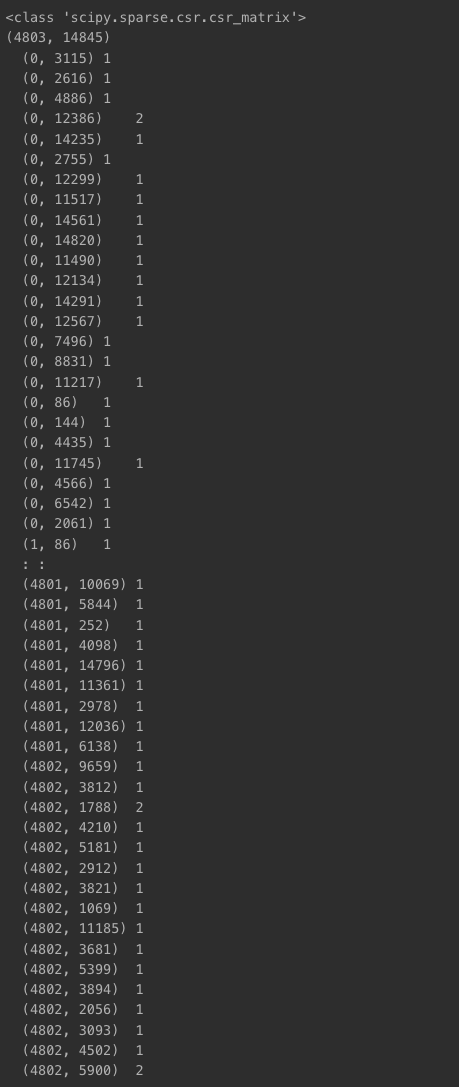
분석
count_matrix
- 데이터 구조 : CSR Matrix
- 0이 아닌 유효 데이터로 채워지는 데이터 값 + 좌표 정보로 구성
- Sparse한 matrix와 동일 행렬 표현 가능
cosine_similaritymatrix 구하기- 4803X4803
cosine_sim = cosine_similarity(count_matrix)
print(cosine_sim)
print(cosine_sim.shape)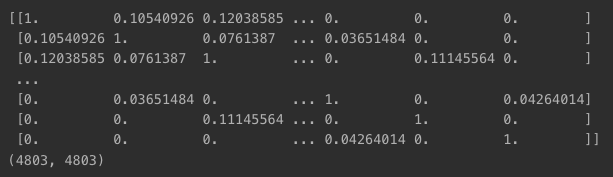
추천
- 비슷한 영화 3편 추천
- 아바타와 유사한 영화는?
- Guardians of the Galaxy
- Aliens
- Star Wars: Clone Wars: Volume 1
- 아바타와 유사한 영화는?
def get_title_from_index(index):
return df[df.index == index]["title"].values[0]
def get_index_from_title(title):
return df[df.title == title]["index"].values[0]
movie_user_likes = "Avatar"
movie_index = get_index_from_title(movie_user_likes)
similar_movies = list(enumerate(cosine_sim[movie_index]))
sorted_similar_movies = sorted(similar_movies,key=lambda x:x[1],reverse=True)[1:]
i=0
print(movie_user_likes+"와 비슷한 영화 3편은 "+"\n")
for item in sorted_similar_movies:
print(get_title_from_index(item[0]))
i=i+1
if i==3:
break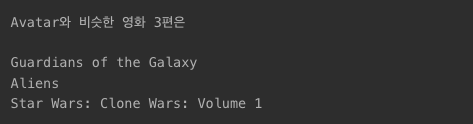
- Q. 타이타닉과 유사한 영화 5편은?
def get_title_from_index(index):
return df[df.index == index]["title"].values[0]
def get_index_from_title(title):
return df[df.title == title]["index"].values[0]
movie_user_likes = "Titanic"
movie_index = get_index_from_title(movie_user_likes)
similar_movies = list(enumerate(cosine_sim[movie_index]))
sorted_similar_movies = sorted(similar_movies,key=lambda x:x[1],reverse=True)[1:]
i=0
print(movie_user_likes+"와 비슷한 영화 5편은 "+"\n")
for item in sorted_similar_movies:
print(get_title_from_index(item[0]))
i=i+1
if i==5:
break
1-6. 협업 필터링 (1) 협업 필터링의 종류
협업 필터링(Collaborative Filtering)
- 과거 User Behavior 데이터 기반 추천 방식
- 잠재 요인 기법을 활용해 행동 양식을 데이터로 나타냄
협업 필터링의 원리
-
영화 추천
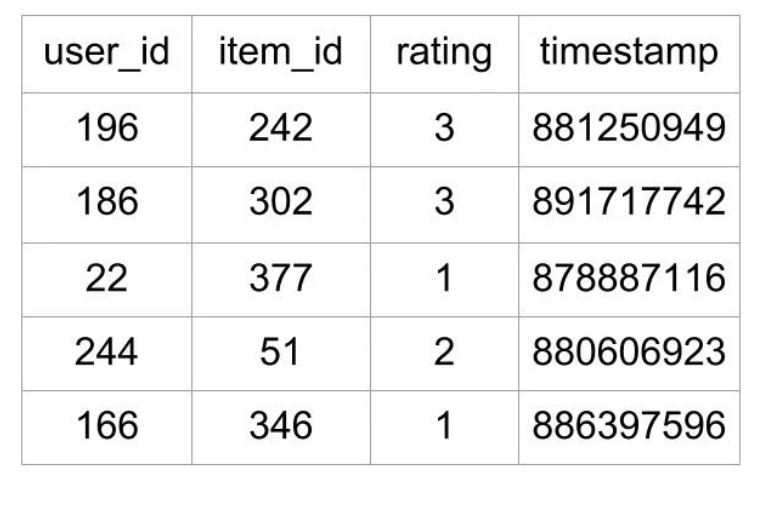
-
이 데이터를
interaction matrix로 변환- 사용자와 아이템 간의 평점
- 행렬 데이터로 평점을 넣음(==평점 행렬)
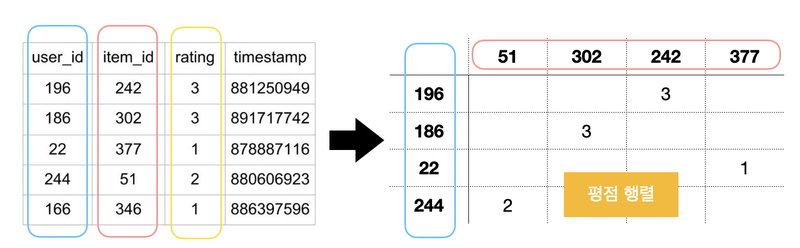
-
희소 행렬 형태
- 몇 억개의 동영상과 사용자가 있는 만큼, 자연스러운 현상
-
평점 행렬로 변환한 후 ➡️ 평점행렬 유사도를 계산 및 추천 : 사용자 기반, 아이템 기반 필터링
-
평점 행렬을 분해한 후 ➡️ 더 많은 정보 고려 : 잠재요인 필터링
사용자 기반
-
최근접 이웃 협업 필터링 : 동일 제품에 대해 매긴 평점 데이터 분석 및 추천
- 사용자 기반
- 아이템 기반
-
예시) 어떤 제품을 추천해줄 수 있을까?
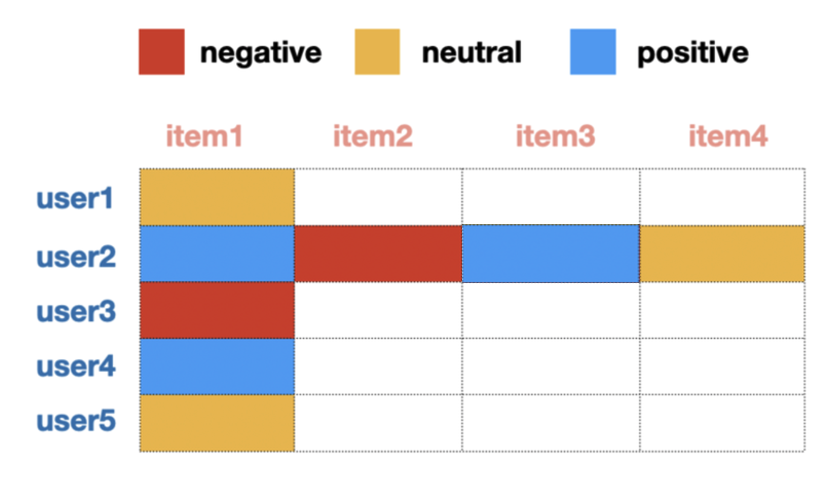
- User4가 item1 구매, User4와 가장 유사한 User2가 item 1~4까지 매긴 평점
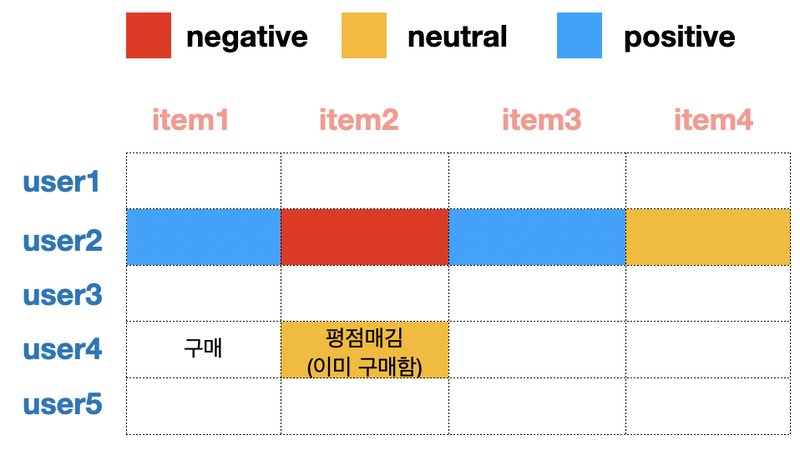
User2가 선호한 item3 ➡️ User4에게 추천!
- User4가 item1 구매, User4와 가장 유사한 User2가 item 1~4까지 매긴 평점
아이템 기반
-
아이템 간 유사도 측정
-
사용자 기반보다 정확도가 더 높음!(일반적으로
-
예시) 어떤 제품을 추천해줄 수 있을까?
- User2가 선호하는 아이템 : item1
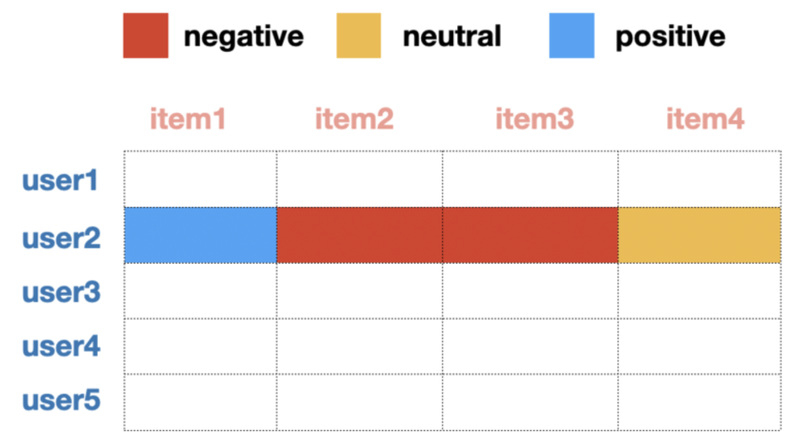
- 그 아이템(item1)에 대한 타 유저 선호도 조사
- 결론: item1을 선호한 User4 ➡️ User4에게 User2가 선호한 item3을 추천
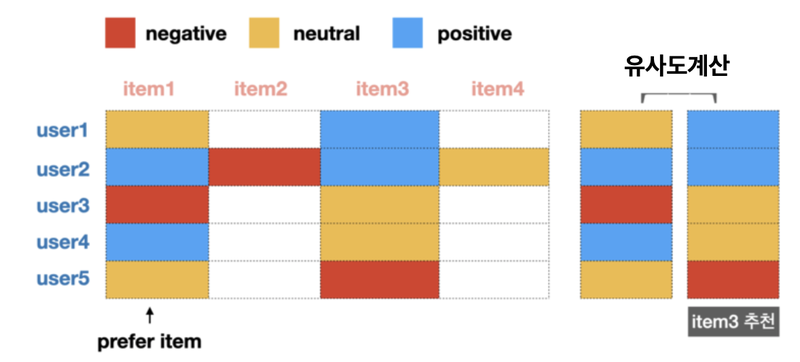
- User2가 선호하는 아이템 : item1
사용자 기반 : "당신과 비슷한 고객들이 다음 상품을 구매했습니다."
아이템 기반: "이 상품을 선택한 다른 고객들은 다음 상품을 구매했습니다."
1-7. 협업 필터링 (2) 행렬 인수분해
행렬 인수분해 기법
-
(잠재 요인 협업 필터링: 행렬 인수분해를 이용해 잠재 요인 분석)
-
기법
- SVD(Singular Vector Decomposition)
- ALS(Alternating Least Squares)
- NMF(Non-negative Matrix Factorization)
SVD
- SVD(Singular Vector Decomposition) : 특이값 분해
M X N행렬 A를 분해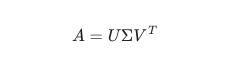
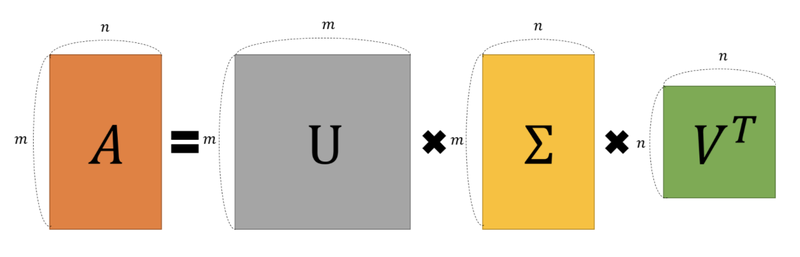
내용 참고 및 이미지 출처
-
특이값 분해의 기하학적 의미
- 직교하는 벡터 집합에 대해 선형 변환 후 크기는 변하더라도 여전히 직교하는 직교 집합은 무엇인지?
- 선형 변환 후 결과는 무엇인지?
-
SVD를 사용하는 이유
- 임의의 행렬의 정보량에 따라 여러 layer로 나누어 생각할 수 있도록 해주기 때문
- 특이값 크기에 따라 A 정보량이 결정되니, 값이 큰 몇 개의 특이값만으로도 충분히 유용한 정보를 유지할 수 있음
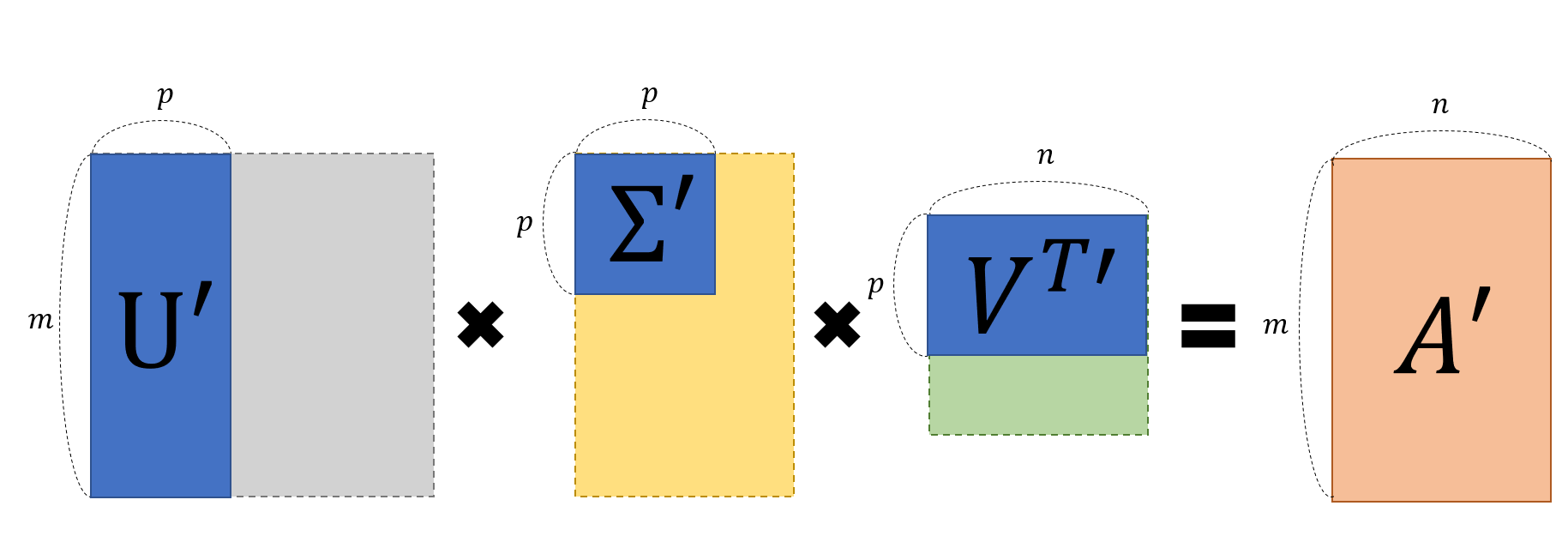
- 특이값 분해를 통해 얻은 U, Sigma, V 행렬 ➡️ 일부 내용으로 적당한 A'를 부분복원
SVD 실습
numpy.linelg svd모듈 사용
import numpy as np
from numpy.linalg import svd- 4 x 4 행렬 A -> SVD 수행
np.random.seed(30)
A = np.random.randint(0, 100, size=(4, 4))
A
- 전치 행렬 생성됨: 행렬 U, 행렬 Σ, 행렬 V
svd(A)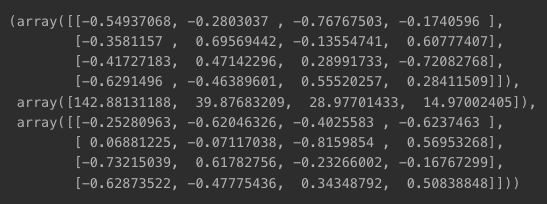
- unpacking
U, Sigma, VT = svd(A)
print('U matrix: {}\n'.format(U.shape),U)
print('Sigma: {}\n'.format(Sigma.shape),Sigma)
print('V Transpose matrix: {}\n'.format(VT.shape),VT)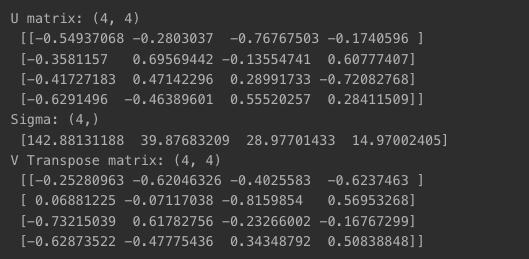
- 다시 복원
- U, Σ, 내적
- Σ의 경우, 1차원이기 때문에 0을 포함한 대각 행렬 변화 후 내적!
- U, Σ, 내적
Sigma_mat = np.diag(Sigma)
A_ = np.dot(np.dot(U, Sigma_mat), VT)
A_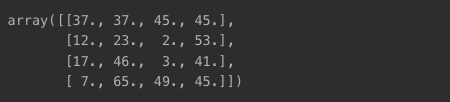
원본 A와 값 동일!
Truncated SVD
- 추천 시스템에서의 행렬 인수분해 사용 방식
- 잘린 SVD
- 잠재 의미 분석으로 번역(LSA)
- 차원 축소 후 행렬 분해 ➡️ SVD보다는 불완전한 행렬이 나옴
- 사이킷런
TruncatedSVD로 사용 가능
내용 참고 : SVD: Optimal Truncation [Python]
1-8. 협업 필터링 (3) 행렬 인수분해와 잠재요인 협업 필터링
SVD를 평가 행렬에 적용해 잠재요인을 분석
-
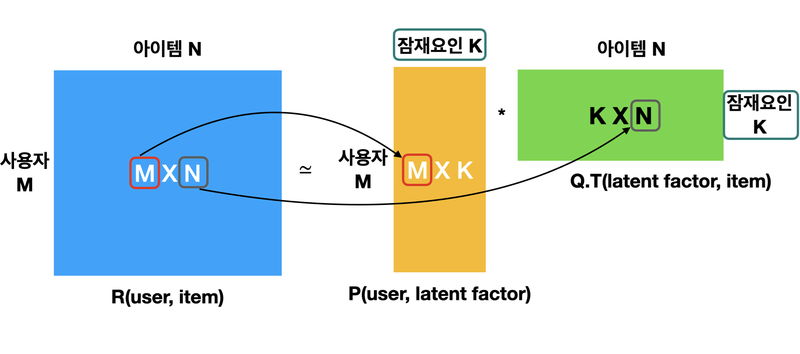
R : 사용자 - 아이템 간 행렬
-
P : 사용자 - 잠재요인 간 행렬
-
Q : 아이템 - 잠재요인 간 행렬(전치 행렬)
-
사용자가 매기는 아이템 평점 요인 항목 ➡️ 지극히 주관적!
- 배우가 마음에 들어서
- 감독이 좋아서
- 좋아하는 장르, 분위기
- 영화 가격이 저렴해서..등등
-
추천 방식
- 사용자가 평점을 매기는 요인을 잠재요인으로 두기
- SVD로 그 잠재요인을 분해 및 복원하여 영화에 평점을 매긴 이유를 벡터화
- 이를 기반으로 추천
- 넷플릭스, 왓챠, 유튜브 등에서 사용
-
잠재요인을 고려하여 행렬 인수 분해 수행 시 파라미터 수는 "잠재요인 수"로 감소!
👍 행렬 인수 분해의 추천 시스템 도입 : How does Netflix recommend movies? Matrix Factorization
1-9. 실제 추천 시스템
더 고려하는 부분
-
Footprint(디지털 발자국), Digital Shadow(디지털 그림자)
- 시청 시간 or 웹사이트에 머무른 시간
- 유입
- 시청 후 구매까지의 시간들의 족적들을 모두 분석
-
클릭률
- CTR(Click Through Rate)
- 클릭률 그리고 추천 시스템, 기술과 가치의 조화
-
데이터를 모아 추천하고, 아이템이 적절한 추천인지 평가
-
추천한 제품이 구매로 이어졌는지 여부 확인도 중요
-
모델 단계에서 추천 결과를 평가하기도 함
-
사용자와 연관성이 있고 + 구매 직결 데이터를 수집 및 정렬 + 순위를 매겨 평가하는 작업의 반복 ➡️ 적합한 데이터 및 추천 시스템의 중요 요소
