본 내용은 RAG 시스템 구축을 위한 랭체인 실전 가이드 교재 및 강의 자료, 실습 자료를 사용했음을 알립니다.
- 강의 : [모두의AI] Langchain 강의
- 실습 : Kane0002/Langchain-RAG
학습 목표
- LangChain 개념
- LangChain을 써야 하는 이유
- LangChain 구조
- ChatPDF: LangChain으로 구축 가능한 서비스
Langchain이 뭘까?
Langchain의 거의 모든 것
학습 목차
-
ChatGPT의 개념과 원리
a. LLM이란?
b. ChatGPT는 왜 가장 유명해졌을까?
c. ChatGPT말고 다른 LLM! -
LangChain의 개념과 원리
a. ChatGPT의 한계를 보완하는 알고리즘
b. LangChain의 종류와 역할
c. LangChain으로 할 수 있는 것 -
LangChain으로 나만의 챗봇 만들기
a. PDF 챗봇 구축하기
b. Word 챗봇 구축하기
c. Youtube 내용 요약하기
학습 목표
- LLM 구동 원리에 대한 이해
- LangChain을 통한 실무 활용 가능한 챗봇 구축
LangChain의 개념
- LangChain 공식 문서
- 언어 모델을 더 잘 활용할 수 있게끔 도움을 주는 도구로 이해하기

- 언어 모델을 더 잘 활용할 수 있게끔 도움을 주는 도구로 이해하기
LangChain을 왜 써야할까?
- ChatGPT의 한계
-
정보 접근 제한
a. ChatGPT(GPT-3.5)는 2021년까지의 데이터를 학습한 LLM(초거대언어모델) ➡️ 2022년부터의 정보에 대해서는 거짓 답변 or 답변 불가 -
토큰 제한
a. GPT-3.5, GPT-4는 각각 4096, 8152 입력 토큰 제한 존재 -
환각현상(Hallucination)
a. Fact 질문 ➡️ 엉뚱한 대답, 거짓말
한계점을 랭체인이 해결
- ChatGPT 개량
- Fine-tuning : 기존 딥러닝 모델 weight 조정으로 원하는 용도의 모델로 업데이트
- N-shot Learning : 0 ~ n개 출력 예시 제시(딥러닝이 용도에 맞는 출력을 하도록 조정)
- In-context Learning : 문맥 제시, 문맥 기반 모델 출력 조정
LangChain은 In-context Learning의 도구
- 정보 접근 제한 : Vectorstore 기반 정보 탐색 or Agent 활용 검색 결합
- 토큰 제한 : TextSplitter 활용 문서 분할
- 환각현상 : 주어진 문서에 대한 대답만 하도록 prompt 입력
LangChain의 종류와 역할
LangChain 구조
-
LLM
- 초거대 언어 모델
- 생성 모델 엔진과 같은 역할을 하는 핵심 구성 요소
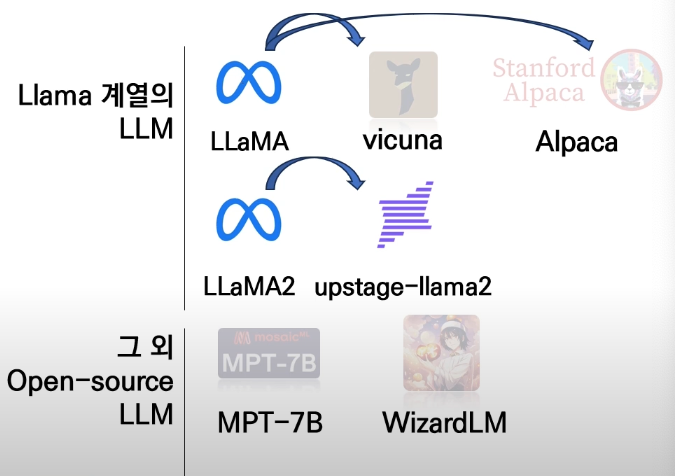
- ex) GPT-3.5, PALM-2, LLAMA, StableVicuna, WizardLM, MPT, ...
-
Prompts
- 초거대 언어모델에게 지시하는 명령문
- 요소 : Prompt Templates, Chat Prompt Template, Example Selectors, Output Parsers
-
Index
- LLM이 문서를 쉽게 탐색할 수 있도록 구조화하는 모듈
- ex) Document Loaders, Text Splitters, Vectorstores, Retrievers, ...
-
Memory
- 채팅 이력을 기억하도록 하여 메모리 기반 대화가 되도록 하는 모듈
- ex) ConversationBufferMemory, Entity Memory, Conversation Knowledge Graph Memory, ...
-
Chain
- LLM 사슬을 형성해 연속적 LLM 호출이 가능하도록 하는 핵심 구성 요소
- ex) LLM Chain, Question Answering, Summarization, Retrieval Question/Answering, ...
-
Agents
- LLM이 기존 Prompt Template으로 수행할 수 없는 작업 가능하게 하는 모듈
- ex) Custom Agent, Custom MultiAction Agent, Conversation Agent, ...
ex) PDF 챗봇 구축
- 문서 기반 챗봇 구축을 통해 대화가 가능해지는 과정
- 문서 업로드 :
Document Loader
a.PyPDFLoader를 활용한 문서 가져오기

- 문서 분할 :
Text Splitter
a. PDF 문서를 여러 문서로 분할

- 문서 임베딩 :
Embed to Vectorstore
a. LLM이 이해할 수 있게 문서 수치화

- 임베딩 검색 :
VectorStore Retriever
a. 질문과 연관성 높은 문서 추출

- 답변 생성 :
QA Chain
LLM 초간단 설명
초거대 언어모델 초간단 알아보기
Transformer 아키텍처
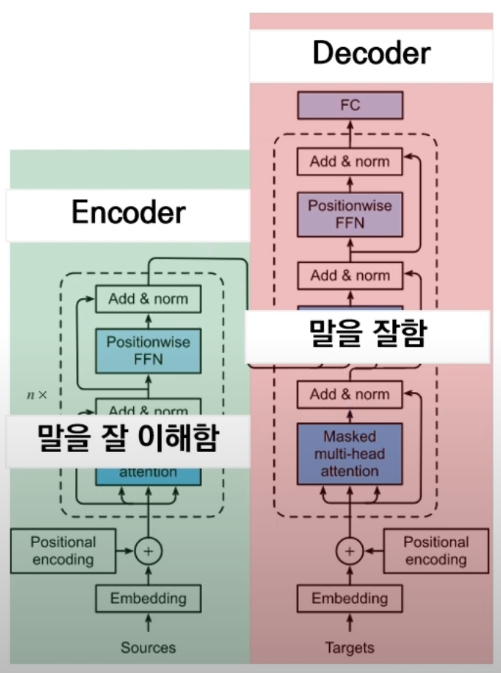
- 현재 NLP 모델의 거의 대부분
- 모델 용도에 따라 트랜스포머의 Encoder, Decoder를 개별 or 통합 사용
LLM의 발전 양상
- Decoder 중심의 빠른 발전
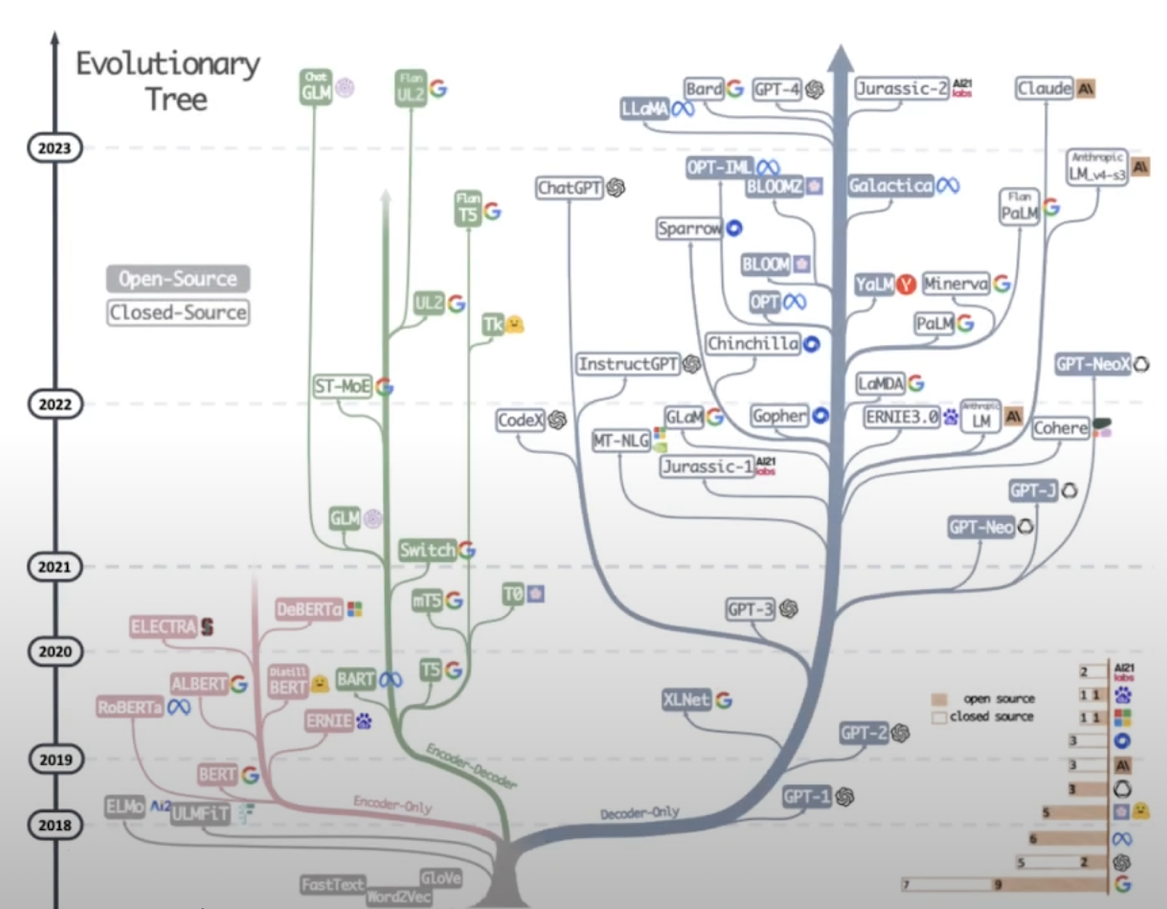
LLM 살펴보기
-
Closed Source
- 장점 : 뛰어난 성능, API 방식(사용성 좋음)
- 단점 : 보안 보장 불가, API 호출 비용 발생

-
Open Source
- 장점 : Closed Source에 준하는 성능, 높은 보안성, 낮은 비용
- 단점 : 개발 난이도 hard, 사용을 하기 위한 GPU 서버 필요
LangChain으로 ChatGPT API 활용하기
알아야 하는 부분
- API를 통해 ChatGPT와 대화하기
- ChatGPT API의 기본 구조 알아보기
ChatGPT API의 특징
- 기본 OpenAI LLM들과 다른 Input 형식을 가지고 있음
- 독특한 2가지 매개변수
- SystemMessage: ChatGPT에게 역할을 부여하여, 대화의 맥락을 설정하는 메세지
- HumanMessage: 사용자가 ChatGPT에게 대화 또는 요청을 위해 보내는 메세지
위 두가지 형식을 적절히 활용하면, LLM을 더욱 효과적으로 사용할 수 있음
라이브러리 설치
- langchain
- langchain-openai
API Key 설정
import os
os.environ["OPENAI_API_KEY"] = '{발급받은 API 키}'
API의 GPT 3.5 turbo, ChatGPT와 대화
- text-davinci-003은 2024년 1월 4일부터 shutdown 될 예정
- 이미 사용이 불가한 상태
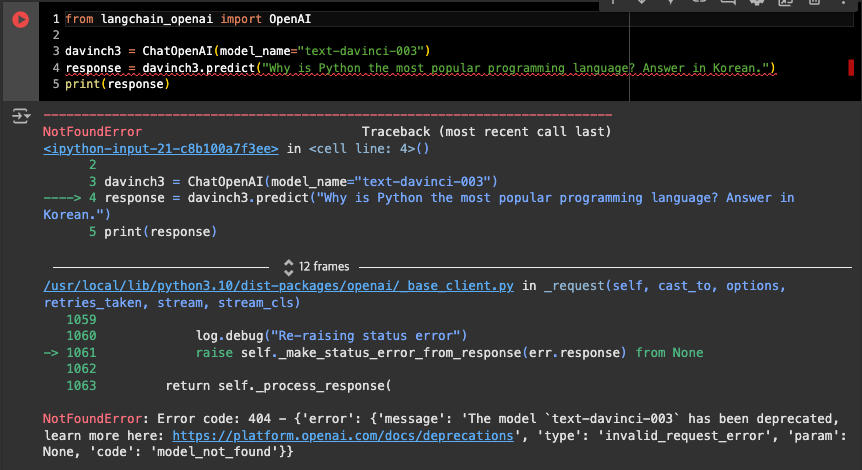
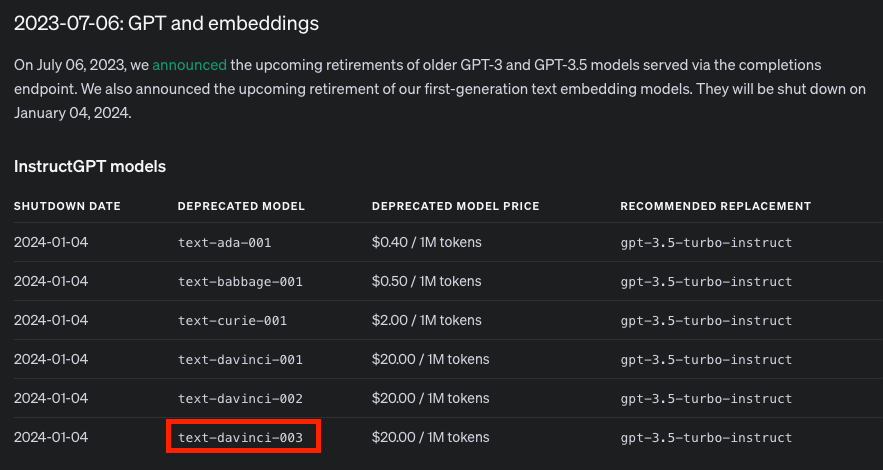
- GPT 3.5 turbo로 대체하여 사용
ChatOpenAI임포트하여 사용
from langchain_openai import ChatOpenAI
davinch3 = ChatOpenAI(model_name="gpt-3.5-turbo")
response = davinch3.predict("Why is Python the most popular programming language? Answer in Korean.")
print(response)파이썬이 가장 인기 있는 프로그래밍 언어인 이유는 다양한 이유가 있습니다. 첫째, 파이썬은 배우기 쉽고 읽기 쉬운 문법을 가지고 있어 초보자들도 쉽게 프로그래밍을 시작할 수 있습니다. 둘째, 파이썬은 다양한 분야에서 사용되는 범용 프로그래밍 언어로서 데이터 분석, 인공지능, 웹 개발 등 다양한 분야에서 활용될 수 있습니다. 또한, 파이썬은 커뮤니티가 활발하고 다양한 라이브러리와 프레임워크를 제공하여 개발자들이 효율적으로 프로그램을 작성할 수 있도록 도와줍니다. 이러한 이유들로 파이썬은 가장 인기 있는 프로그래밍 언어 중 하나로 자리 잡았습니다.- 한글로 질문
from langchain_openai import OpenAI
llm = OpenAI()
result = llm.invoke('왜 파이썬이 가장 인기있는 프로그래밍 언어야?')
print(result)1. 간결하고 쉬운 문법: 파이썬은 간결하고 직관적인 문법을 가지고 있어 학습하기 쉽고 읽기 쉽습니다. 이는 프로그래밍을 처음 배우는 사람들에게 매우 유용하며, 빠르게 개발할 수 있도록 도와줍니다.
2. 다양한 분야에서 활용 가능: 파이썬은 데이터 분석, 인공지능, 웹 개발, 과학 및 공학 분야 등 다양한 분야에서 활용이 가능합니다. 또한, 간결한 문법과 다양한 라이브러리를 제공하기 때문에 빠른 개발이 가능합니다.
3. 무료 오픈소스: 파이썬은 무료로 이용할 수 있는 오픈소스 프로그래밍...매개변수 사용
max_tokens = -1: 토큰 수 제한을 두지 않음
from langchain_openai import OpenAI
llm = OpenAI()
llm = OpenAI(model_name = 'gpt-3.5-turbo-instruct', max_tokens = -1)
result = llm.invoke('왜 파이썬이 가장 인기있는 프로그래밍 언어야?')
print(result)1. 쉽고 간결한 문법: 파이썬은 문법이 간결하고 읽기 쉬워서 쉽게 배울 수 있습니다. 또한 들여쓰기를 강제함으로써 코드의 가독성을 높여줍니다.
2. 다양한 용도로 사용 가능: 파이썬은 데이터 분석, 인공지능, 웹 개발, 게임 개발 등 다양한 분야에서 사용될 수 있기 때문에 범용적으로 사용할 수 있습니다.
3. 대중적인 인기: 파이썬은 대중적으로 인기 있는 언어이기 때문에 다양한 개발자들이 사용하고 있습니다. 따라서 온라인에서도 다양한 커뮤니티와 자료를 찾아볼 수 있어서 학습에 용이합니다.
4. 오픈 소스: 파이썬은 오픈 소스 언어이기 때문에 무료로 사용할 수 있습니다. 또한 개발자들 사이에서 지속적으로 발전하고 있기 때문에 항상 최신 기술을 적용할 수 있습니다.
5. 다양한 라이브러리와 프레임워크: 파이썬은 다양한 라이브러리와 프레임워크가 존재하기 때문에 개발 속도가 빠르고 효율적으로 작업할 수 있습니다.
6. 크로스 플랫폼 지원: 파이썬은 윈도우, 맥, 리눅스 등 다양한 운영체제에서 동일한 코드를 실행할 수 있어서 플랫폼에 구애받지 않고 개발할 수 있습니다.
7. 배우기 쉬운 언어: 파이썬은 객체 지향 언어이지만 다른 언어들에 비해 배우기 쉬운 언어입니다. 따라서 프로그래밍 입문자들에게도 적합한 언어입니다.
8. 빠른 개발 속도: 파이썬은 컴파일 언어가 아니기 때문에 코드를 작성하고 실행하는 시간이 짧습니다. 또한 간결한 문법으로 인해 개발 속도가 빠르고 생산성이 높아집니다.
9. 커뮤니티의 지속적인 지원: 파이썬은 개발자들 사이에서 지속적인 지원과 업데이트가 이루어지고 있기 때문에 문제 발생 시 해결하기 쉽습니다.
10. 쉽게 확장 가능: 파이썬은 C나 C++ 등의 언어와의 인터페이스가 쉽게 구축될 수 있기 때문에 다른 언어와 쉽게 협업하거나 기존 코드를 확장할 수 있습니다.max_tokens =512
from langchain_openai import ChatOpenAI
chatgpt = ChatOpenAI(model_name="gpt-3.5-turbo", max_tokens = 512)
answer = chatgpt.invoke("왜 파이썬이 가장 인기있는 프로그래밍 언어야?")
print(answer.content)파이썬이 가장 인기 있는 프로그래밍 언어가 되었을 이유는 여러 가지가 있습니다.
1. 쉬운 문법: 파이썬은 다른 프로그래밍 언어에 비해 문법이 간단하고 직관적이기 때문에 초보자도 쉽게 배울 수 있습니다.
2. 다양한 용도: 파이썬은 웹 개발, 데이터 분석, 인공지능, 기계 학습 등 다양한 분야에서 사용되기 때문에 많은 사람들이 파이썬을 배우고 있습니다.
3. 강력한 커뮤니티: 파이썬은 오픈 소스이며 전 세계적으로 활발한 커뮤니티가 형성되어 있어서 도움을 받기 쉽고 다양한 라이브러리와 프레임워크를 사용할 수 있습니다.
4. 크로스 플랫폼 지원: 파이썬은 윈도우, 맥, 리눅스 등 다양한 운영 체제에서 사용할 수 있으며 이식성이 뛰어나기 때문에 다양한 환경에서 사용할 수 있습니다.
이러한 이유들로 인해 파이썬은 많은 프로그래머들에게 인기 있는 프로그래밍 언어가 되었습니다.- 실제 답변 형태
AIMessage(content='파이썬이 가장 인기 있는 프로그래밍 언어가 되었을 이유는 여러 가지가 있습니다. \n\n1. 쉬운 문법: 파이썬은 다른 프로그래밍 언어에 비해 문법이 간단하고 직관적이기 때문에 초보자도 쉽게 배울 수 있습니다.\n\n2. 다양한 용도: 파이썬은 웹 개발, 데이터 분석, 인공지능, 기계 학습 등 다양한 분야에서 사용되기 때문에 많은 사람들이 파이썬을 배우고 있습니다.\n\n3. 강력한 커뮤니티: 파이썬은 오픈 소스이며 전 세계적으로 활발한 커뮤니티가 형성되어 있어서 도움을 받기 쉽고 다양한 라이브러리와 프레임워크를 사용할 수 있습니다.\n\n4. 크로스 플랫폼 지원: 파이썬은 윈도우, 맥, 리눅스 등 다양한 운영 체제에서 사용할 수 있으며 이식성이 뛰어나기 때문에 다양한 환경에서 사용할 수 있습니다.\n\n이러한 이유들로 인해 파이썬은 많은 프로그래머들에게 인기 있는 프로그래밍 언어가 되었습니다.', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 403, 'prompt_tokens': 32, 'total_tokens': 435, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_name': 'gpt-3.5-turbo-0125', 'system_fingerprint': None, 'finish_reason': 'stop', 'logprobs': None}, id='run-b5b70212-b08c-42b1-aeee-4e26da40e4b3-0', usage_metadata={'input_tokens': 32, 'output_tokens': 403, 'total_tokens': 435, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}})Temperature- 0 ~ 2 : 숫자가 클수록 답변의 랜덤성이 커짐
chatgpt_temp0_1 = ChatOpenAI(model_name="gpt-3.5-turbo", temperature = 0, max_tokens = 512)
chatgpt_temp0_2 = ChatOpenAI(model_name="gpt-3.5-turbo", temperature = 0, max_tokens = 512)
chatgpt_temp1_1 = ChatOpenAI(model_name="gpt-3.5-turbo", temperature = 1, max_tokens = 512)
chatgpt_temp1_2 = ChatOpenAI(model_name="gpt-3.5-turbo", temperature = 1, max_tokens = 512)
model_list = [chatgpt_temp0_1, chatgpt_temp0_2, chatgpt_temp1_1, chatgpt_temp1_2]
for i in model_list:
answer = i.invoke("왜 파이썬이 가장 인기있는 프로그래밍 언어야?", max_tokens = 128)
print("-"*100)
print(">>>",answer.content)
ChatGPT처럼 실시간 응답 출력하기
StreamingStdOutCallbackHandler사용
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
chatgpt = ChatOpenAI(model_name="gpt-3.5-turbo", streaming=True, callbacks=[StreamingStdOutCallbackHandler()], temperature = 1)
answer = chatgpt.predict("왜 파이썬이 가장 인기있는 프로그래밍 언어야?")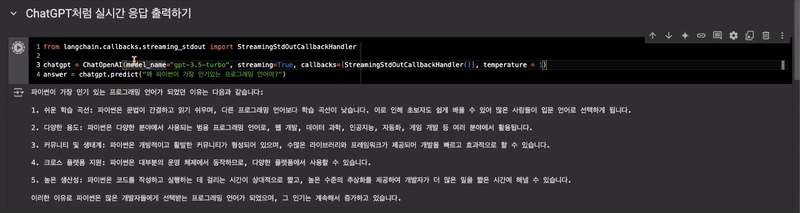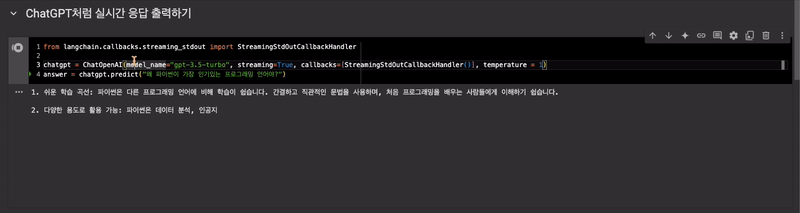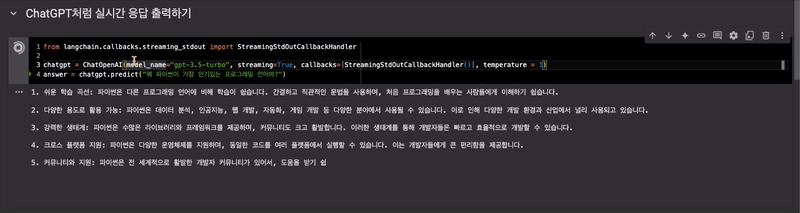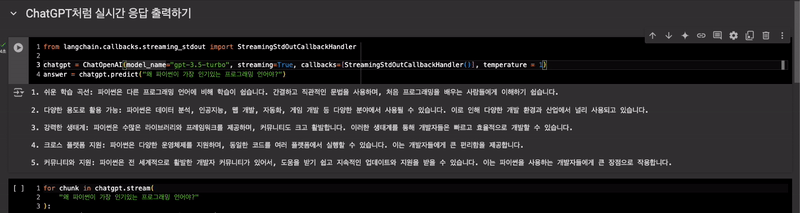
ChatGPT에게 역할 부여하기
- HumanMessage, SystemMessage를 넣어주면 ➡️ 답변은 AIMessage로 돌아옴
from langchain.chat_models import ChatOpenAI
from langchain.schema import AIMessage, HumanMessage, SystemMessage
chatgpt = ChatOpenAI(model_name="gpt-3.5-turbo", temperature = 1)
messages = [
SystemMessage(
content="너는 20년차 시니어 개발자야. 사용자의 질문에 매우 건방지게 대답해줘."
),
HumanMessage(
content="파이썬의 장점에 대해서 설명해줘."
),
]
response_langchain = chatgpt.invoke(messages)
response_langchain.content
LLM 응답 캐싱하여 같은 질문에 더 빠르게 응답받기
- 사전 준비
!pip install -U langchain-community- 실행
from langchain.globals import set_llm_cache
from langchain_openai import OpenAI
# To make the caching really obvious, lets use a slower model.
llm = OpenAI(model_name="gpt-3.5-turbo-instruct", n=2, best_of=2)%%time
from langchain.cache import InMemoryCache
set_llm_cache(InMemoryCache())
# The first time, it is not yet in cache, so it should take longer
llm.predict("Tell me a joke")
- 캐싱되고나면 ➡️ 속도가 빨라짐
%%time
# The second time it is, so it goes faster
llm.predict("Tell me a joke")
실습해보기
from langchain_openai import ChatOpenAI
from langchain.schema import HumanMessage, SystemMessage, AIMessage
chat = ChatOpenAI(model_name = "gpt-4-0125-preview", temperature = 1,
streaming=True, callbacks=[StreamingStdOutCallbackHandler()])
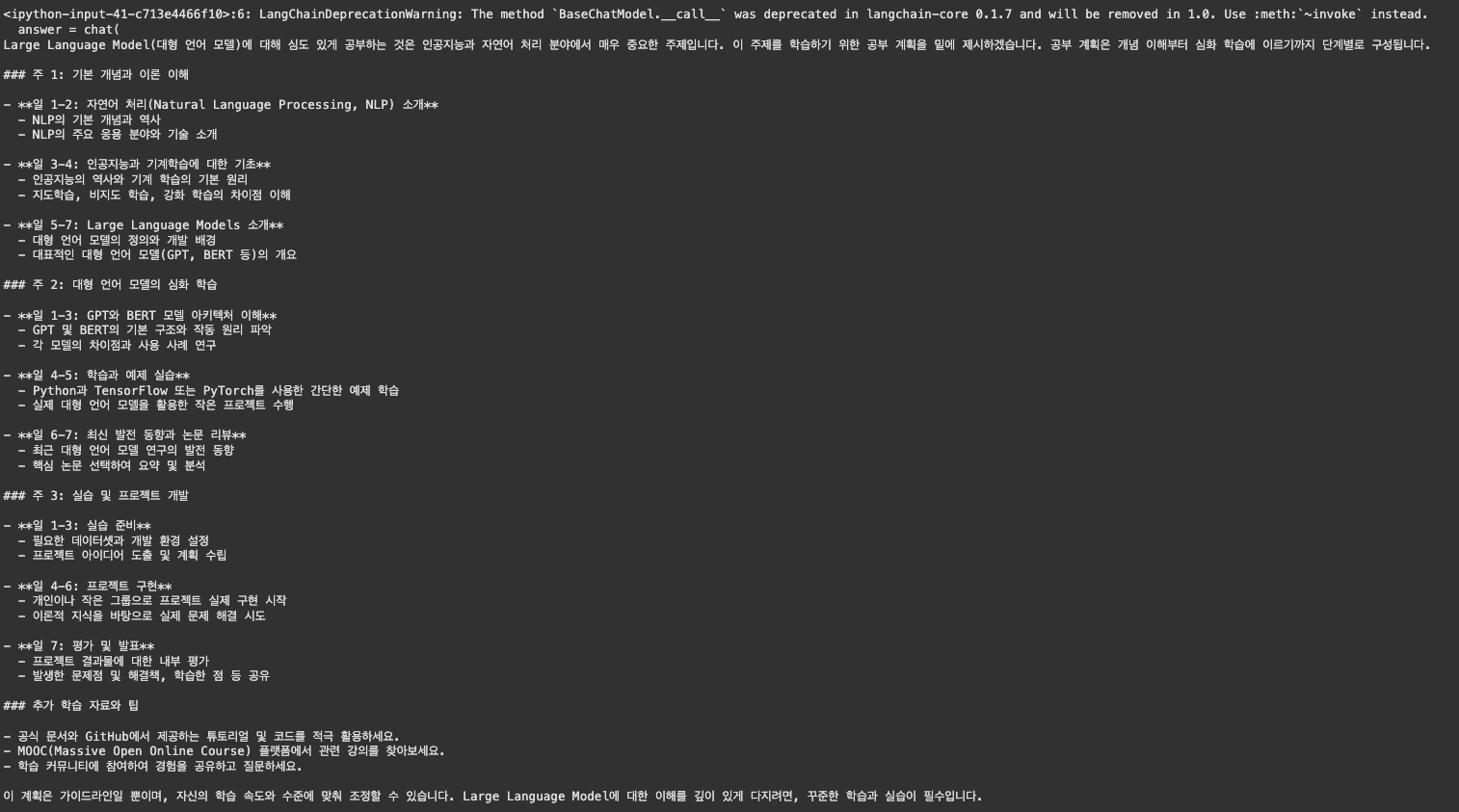
answer = chat(
[
SystemMessage(content="""당신은 공부 계획을 세워주는 스터디 플래너 머신입니다.
사용자의 공부 주제를 입력 받으면, 이를 학습하기 위한 공부 계획을 작성합니다."""),
HumanMessage(content="Large Language Model에 대해서 공부하고 싶어요.")
]
)
- AIMessage 형태
answer
- text만 보고 싶을 경우
print(answer.content)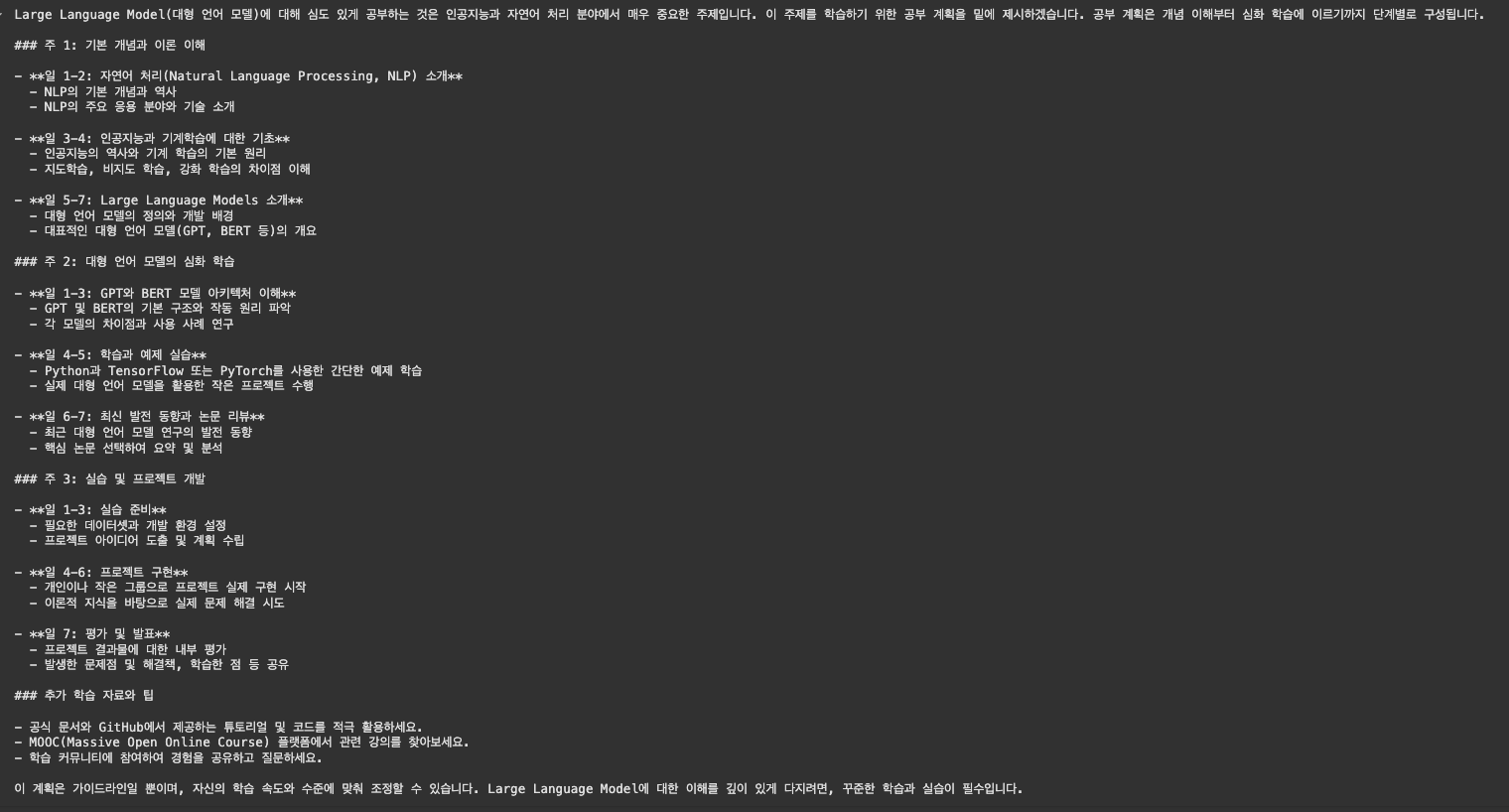
Langchain - PromptTemplate, LLM 프롬프트 입력을 더 편하게
실습 코드 : textbook/LLM/Day01/PromptTemplate,LLM프롬프트입력을더편하게실습.ipynb
Prompt?
- 모델에 대한 입력을 의미
- 입력이 하드 코딩되는 경우는 거의 없으나, 여러 구성 요소로 구성되는 경우가 많음
- 프롬프트 템플릿
- 입력 구성을 담당
- LangChain : 프롬프트의 쉬운 구성 및 작업이 가능하도록 여러 클래스 및 함수 제공
실습
라이브러리 import
- 설치
!pip install -q openai langchain langchain-openai
!pip install -U langchain-community- import
#API KEY 저장을 위한 os 라이브러리 호출
import os
#기본 LLM 로드를 위한 라이브러리 호출
from langchain.llms import OpenAI
#채팅 LLM 로드를 위한 라이브러리 호출
from langchain.chat_models import ChatOpenAI
from langchain_community.chat_models import ChatOpenAIAPI Key 설정
#OPENAI API키 저장
os.environ["OPENAI_API_KEY"] = '{발급 받은 키}'Davinch-003 Model 설정 ➡️ gpt-3.5-turbo로 교체
gpt3 = ChatOpenAI(
model_name="gpt-3.5-turbo",
max_tokens=1000
)프롬프트 템플릿의 종류
- Prompt Template : 일반적인 프롬프트 템플릿 생성 시 활용
- Chat Prompt Template : 채팅 LLM에 프롬프트 전달 시 활용(특화 프롬프트 템플릿)
- Prompt Template
from langchain.prompts import PromptTemplate, ChatPromptTemplate
#프롬프트 템플릿을 통해 매개변수 삽입 가능한 문자열로 변환
string_prompt = PromptTemplate.from_template("tell me a joke about {subject}")
#매개변수 삽입한 결과를 string_prompt_value에 할당
string_prompt_value = string_prompt.format_prompt(subject="soccer")
#채팅LLM이 아닌 LLM과 대화할 때 필요한 프롬프트 = string prompt
string_prompt_value
to_string()- prompt template으로 생성한 문장 raw_text 반환 가능
print(string_prompt_value.to_string())
- Chat Prompt Template
chat_prompt = ChatPromptTemplate.from_template("tell me a joke about {subject}")
chat_prompt_value = chat_prompt.format_prompt(subject="soccer")
chat_prompt_value
to_string()
chat_prompt_value.to_string()
프롬프트 템플릿 활용
-
프롬프트 반복 삽입
- Prompt Template를 통해 간편하게 LLM 활용 가능
-
GPT-3와 프롬프트 템플릿을 활용하여 대화해보기
input_variables에 리스트 형태로 담기prompt_template.format으로 입력값 넣기
from langchain.prompts.prompt import PromptTemplate
template = """
너는 요리사야. 내가 가진 재료들을 갖고 만들 수 있는 요리를 추천하고, 그 요리의 레시피를 제시해줘.
내가 가진 재료는 아래와 같아.
<재료>
{재료}
"""
prompt_template = PromptTemplate(
input_variables = ['재료'],
template = template
)print(prompt_template.format(재료 = '양파, 계란, 사과, 빵'))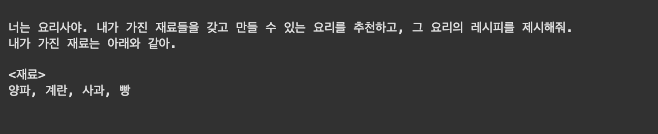
- gpt3 모델
response = gpt3.predict(
prompt_template.format(재료="양파, 계란, 사과, 빵")
)
print(response)
ChatGPT와 프롬프트 템플릿을 활용하여 대화해보기
- 필요한 템플릿 프롬프트 import
- 스키마도 import
from langchain.prompts import (
ChatPromptTemplate,
PromptTemplate,
SystemMessagePromptTemplate,
AIMessagePromptTemplate,
HumanMessagePromptTemplate,
)
from langchain.schema import (
AIMessage,
HumanMessage,
SystemMessage
)- ChatGPT API에 ChatPromptTemplate 입력 시, human message의 매개변수인 '재료'를 할당해 전달
-> ChatGPT는 ChatPromptTemplate의 system message와 human message를 전달받아 -> 대답 생성에 활용
# ChatGPT 모델 로드
chatgpt = ChatOpenAI(temperature=0)
# 역할 부여(위에서 정의한 Template 사용)
system_message_prompt = SystemMessagePromptTemplate.from_template(template)
# 사용자가 입력할 매개변수 template 선언
human_template = "{재료}"
human_message_prompt = HumanMessagePromptTemplate.from_template(human_template)
#ChatPromptTemplate에 system message와 human message 템플릿 삽입
chat_prompt = ChatPromptTemplate.from_messages([system_message_prompt, human_message_prompt])
answer = chatgpt(chat_prompt.format_prompt(재료="양파, 계란, 사과, 빵").to_messages())
print(answer.content)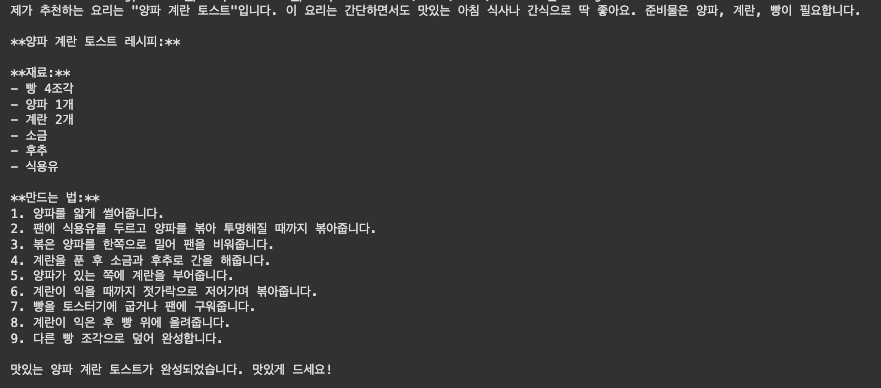
Few-shot
- 딥러닝 모델이 결과물을 출력할 때 예시 결과물을 제시함으로써 원하는 결과물로 유도하는 방법론
- LLM에 Few-shot 예제를 제공하면 예제와 유사한 형태의 결과물을 출력함
- 내가 원하는 결과물의 형태가 특수하거나, 구조화된 답변을 원할 경우 사용
- 결과물의 예시를 여러 개 제시 ➡️ 결과물의 품질 향상 가능
from langchain.prompts.few_shot import FewShotPromptTemplate
from langchain.prompts.prompt import PromptTemplate
examples = [
{
"question": "아이유로 삼행시 만들어줘",
"answer":
"""
아: 아이유는
이: 이런 강의를 들을 이
유: 유가 없다.
"""
},
{
"question": "김민수로 삼행시 만들어줘",
"answer":
"""
김: 김치는 맛있다
민: 민달팽이도 좋아하는 김치!
수: 수억을 줘도 김치는 내꺼!
"""
}
]example_prompt = PromptTemplate(input_variables=["question", "answer"], template="Question: {question}\n{answer}")
print(example_prompt.format(**examples[0]))
prompt = FewShotPromptTemplate(
examples=examples,
example_prompt=example_prompt,
suffix="Question: {input}",
input_variables=["input"]
)
print(prompt.format(input="호날두로 삼행시 만들어줘"))
- 프롬프트 템플릿 미지정 시 gpt3 답변
- 예제가 없어 바뀜
print(gpt3.predict("호날두로 삼행시 만들어줘"))
- 프롬프트 템플릿 지정
formatted_prompt = prompt.format(input="호날두로 삼행시 만들어줘")
response = gpt3([{"role": "user", "content": formatted_prompt}])
print(response.content)
4. Example Selector를 이용한 동적 Few-shot 러닝
-
Example Selector활용 -
LLM이 여러 작업을 수행하면서도 원하는 범위의 대답을 출력하도록 하려면..
- 사용자의 입력에 동적으로 반응해야함
- 이와 동시에, 예제를 모두 학습시키는 것이 아니라 적절한 예시만 포함하도록 함으로써 입력 prompt의 길이를 제한하고, 이를 통해 오류가 발생하지 않도록 조절할 수 있음
-
SemanticSimilarityExampleSelector- 사용자 입력과 예제 사이의 유사성 비교 ➡️ 사용자 입력과 비슷한 예제부터 가져오도록 하는 것
from langchain.prompts.example_selector import SemanticSimilarityExampleSelector
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
from langchain.prompts import FewShotPromptTemplate, PromptTemplate
example_prompt = PromptTemplate(
input_variables=["input", "output"],
template="Input: {input}\nOutput: {output}",
)
# These are a lot of examples of a pretend task of creating antonyms.
examples = [
# 감정 비교
{"input": "행복", "output": "슬픔"},
{"input": "흥미", "output": "지루"},
{"input": "불안", "output": "안정"},
# 대소 단위 비교
{"input": "긴 기차", "output": "짧은 기차"},
{"input": "큰 공", "output": "작은 공"},
]- chromadb, tiktoken 다운로드
!pip install chromadb
!pip install tiktoken- 주어진 예시들을 바탕으로 반대 의미를 가진 단어를 출력하는 템플릿 생성
example_selector: 입력과 유사한 예시를 찾기 위해 OpenAI 임베딩과 Chroma를 사용하여 가장 비슷한 예시를 선택FewShotPromptTemplate: 선택된 예시를 바탕으로, "반대 의미를 가진 단어"를 출력하는 프롬프트를 생성- 입력 : 사용자가 제공한 단어에 대해 모델이 반대 의미를 출력하도록 유도
example_selector = SemanticSimilarityExampleSelector.from_examples(
examples,
OpenAIEmbeddings(),
Chroma,
k=1
)
similar_prompt = FewShotPromptTemplate(
example_selector=example_selector,
example_prompt=example_prompt,
prefix="주어진 입력에 대해 반대의 의미를 가진 단어를 출력해줘",
suffix="Input: {단어}\nOutput:",
input_variables=["단어"],
)- 반의어 세트를 잘 출력하는지 확인
- 감정: "무서운"
print(similar_prompt.format(단어="무서운"))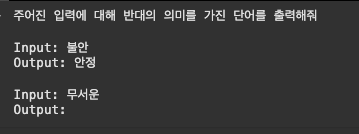
- 대소 단위 비교: "큰 비행기"
print(similar_prompt.format(단어="큰 비행기"))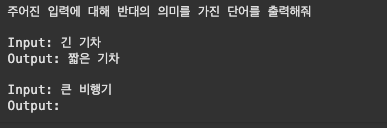
- gpt 모델 활용하여 반의어 세트 확인
query = "큰 비행기"
print(gpt3(
similar_prompt.format(단어=query)
))
5. Output Parser를 활용한 출력값 조정
OutputParser- LLM의 답변을 내가 원하는 형태로 고정
- 리스트, JSON 형태 등 다양한 형식의 답변을 고정하여 출력 가능
CommaSeparatedListOutputParser- 콤마로 구분된 리스트 형태로 답변을 받을 때 사용
from langchain.output_parsers import CommaSeparatedListOutputParser
from langchain.prompts import PromptTemplate, ChatPromptTemplate, HumanMessagePromptTemplate
from langchain.llms import OpenAI
from langchain.chat_models import ChatOpenAIoutput_parser = CommaSeparatedListOutputParser()get_format_instructions: 기본 형태 파악
format_instructions = output_parser.get_format_instructions()
format_instructions
- 프롬프트 템플릿에 넣기
prompt = PromptTemplate(
template="{주제} 5개를 추천해줘.\n{format_instructions}",
input_variables=["주제"],
partial_variables={"format_instructions": format_instructions}
)- 모델 설정
model = OpenAI(temperature=0)- 가변 요소(input, output)만 입력 & 확인
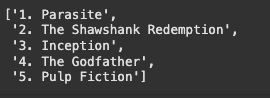
_input = prompt.format(주제="영화")
output = model(_input)
output
- 설정한 output parser를 통해 parse
output_parser.parse(output)