Day 02. LLM 챗봇 ,랭체인의 핵심 Retrieval - Document Loaders, Text Splitters
☺️ AIFFEL 데이터사이언티스트 3기
목록 보기
92/115

본 내용은 RAG 시스템 구축을 위한 랭체인 실전 가이드 교재 및 강의 자료, 실습 자료를 사용했음을 알립니다.
- 강의 : [모두의AI] Langchain 강의
- 실습 : Kane0002/Langchain-RAG
LLM 챗봇 ,랭체인의 핵심 Retrieval - Document Loaders
RAG란?
- Retrieval Augmented Generation
- LLM 답변에 외부 데이터 참조하는 프레임워크
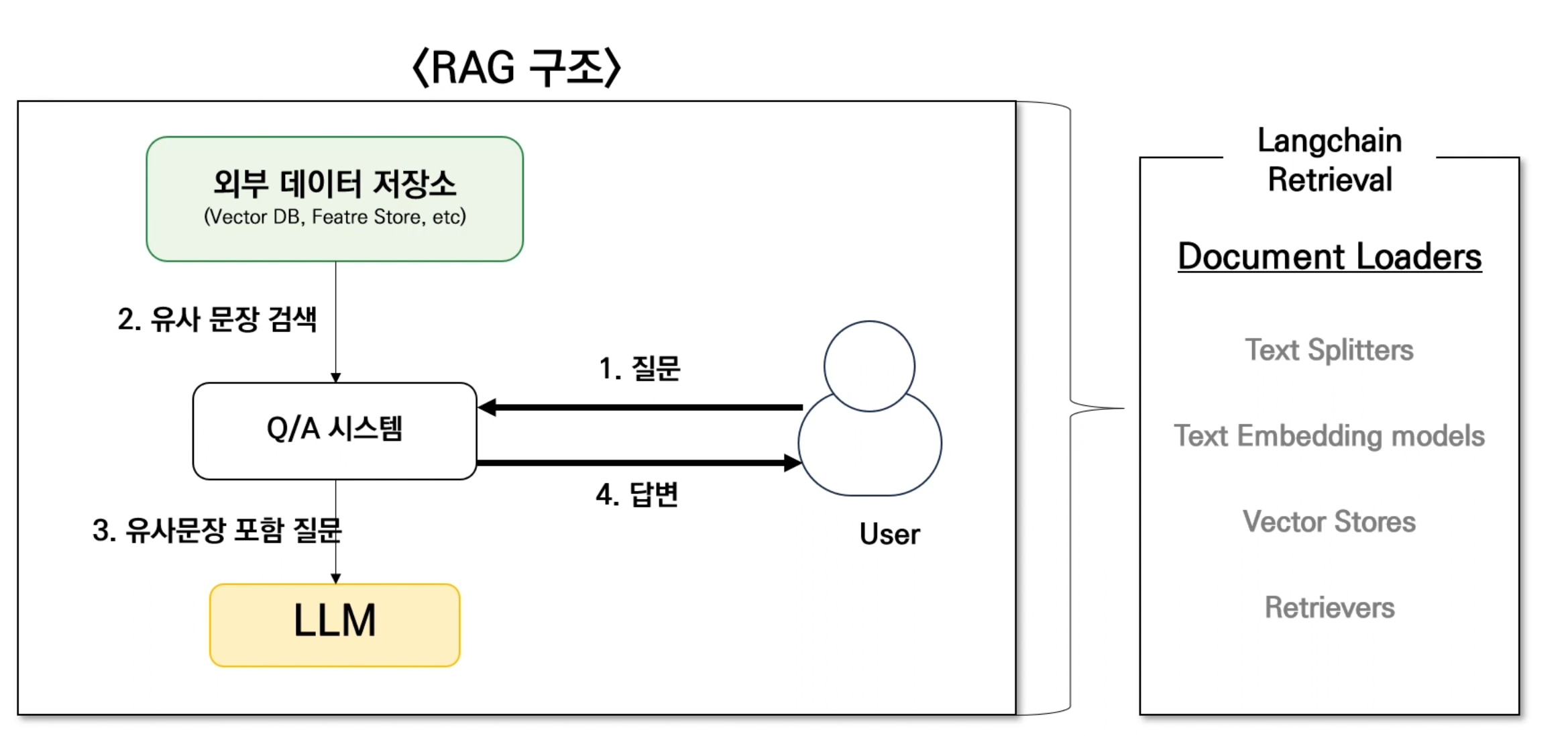
- 랭체인의 Retrieval
- RAG의 대부분 구성 요소 아우름
- 구성 요소 하나하나 ➡️ RAG 품질에 중요한 영향을 미침
[순서]
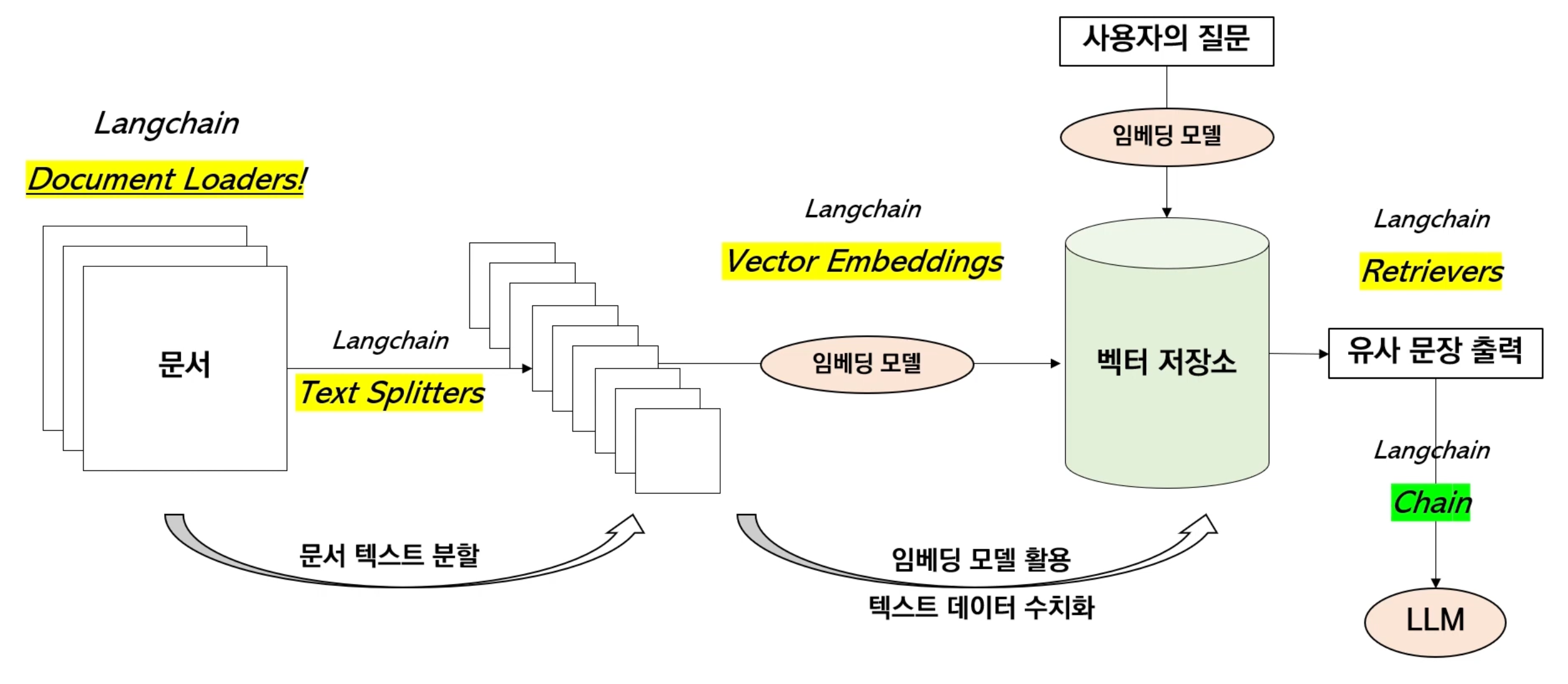
1. Langchain의 Document Loaders : 문서 불러오기
2. Langchain의 Text Splitters : 문서 텍스트 분할
3. Langchain의 Vector Embeddings : 임베딩 모델을 통해 수치화된 값들을 벡터에 저장
4. 수치화된 텍스트 데이터 ➡️ 벡터 저장소에 저장
5. Langchain의 Retrievers : 사용자 질문과 가장 유사한 문장을 검색
6. Langchain의 Chain : LLM이 문장을 생성
Document Loaders?
- 다양한 형태의 문서를 RAG 전용 객체로 불러들이는 모듈
- Document Loaders로 불러오면 갖게되는 구조
- Page_content : 문서 내용
- Metadata : 문서 위치, 제목, 페이지 넘버, ...
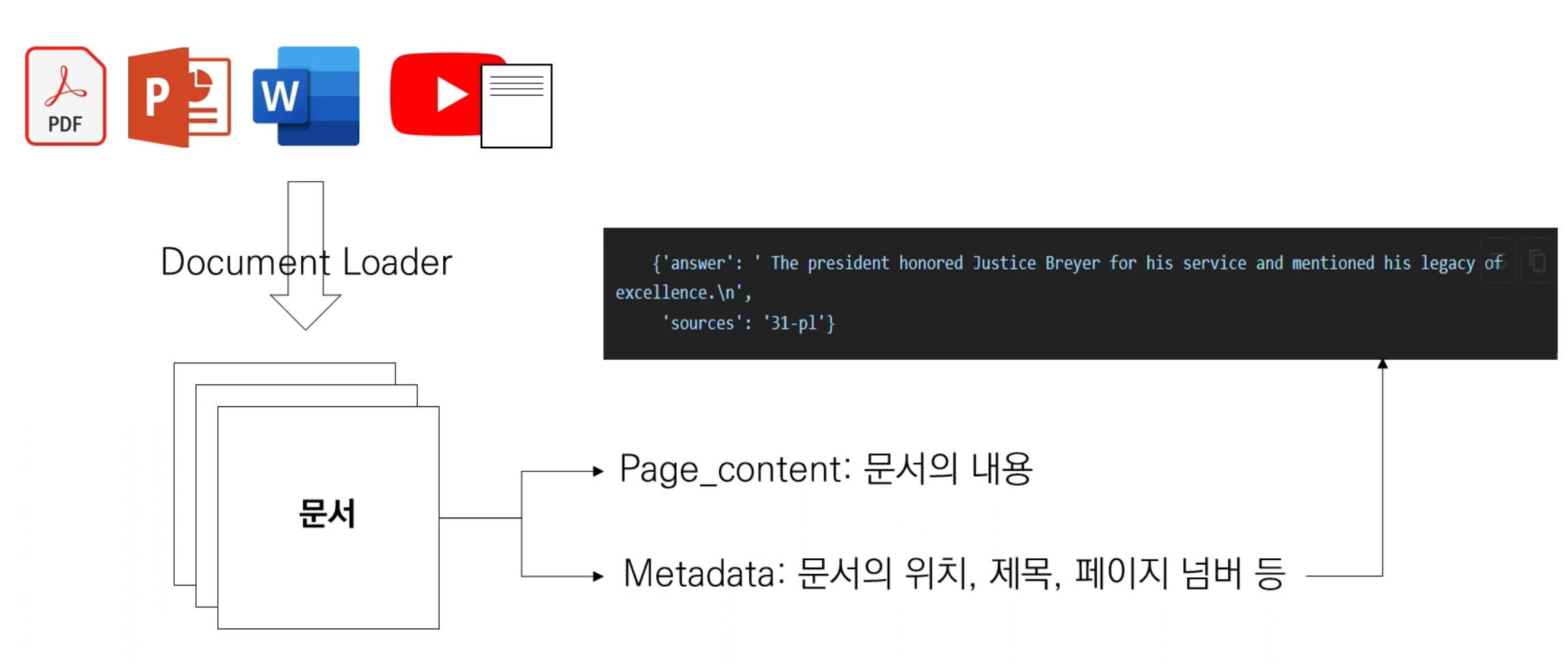
- Document Loaders로 불러오면 갖게되는 구조
실습: Documnet Loaders
실습 코드 : Documnet Loaders 기초.ipynb
필수 라이브러리 설치
- langchain
- unstructured
- pypdf
- pdf2image
- docx2txt
- pdfminer
- langchain-community
!pip install langchain unstructured pypdf pdf2image docx2txt pdfminer
!pip install -U langchain-communityDocument Loaders
다양한 형식의 문서 불러오기 & Langchain에 결합하기 쉬운 텍스트 형태로 변환
txt, pdf, word, ppt, xlsx, csv 등의 거의 모든 형식 문서를 기반으로 LLM 구동 가능
URL Document Loader
웹에 기록된 글도 텍스트 형식으로 가져와 LLM에 활용 가능
ex) WebBaseLoader, UnstructuredURLLoader
- WebBaseLoader
from langchain.document_loaders import WebBaseLoader
loader = WebBaseLoader("https://n.news.naver.com/mnews/article/092/0002307222?sid=105")
data = loader.load()
print(data[0].page_content)
...
- UnstructuredURLLoader
from langchain.document_loaders import UnstructuredURLLoader
urls = [
"https://n.news.naver.com/mnews/article/092/0002307222?sid=105",
"https://n.news.naver.com/mnews/article/052/0001944792?sid=105"
]
loader = UnstructuredURLLoader(urls=urls)
data = loader.load()
data
PDF Document Loader
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("/content/drive/MyDrive/NLP톺아보기/file/BOK이슈노트제2023-26호_수출입경로를 통한 해외 기후변화 물리적 리스크의 국내 파급영향.pdf")
pages = loader.load_and_split()- 첫번째 페이지만 확인
pages[0]
- 전체 페이지
pages
- page_conent로 첫번째 페이지 확인하기
print(pages[1].page_content)
Word Document Loader
from langchain.document_loaders import Docx2txtLoader
loader = Docx2txtLoader("/content/drive/MyDrive/NLP톺아보기/file/1등_통계+바로쓰기+공모전+수상작.docx")
data = loader.load()data
- metadata 확인
data[0].metadata
- page_content로 내용 확인
data[0].page_content
CSV Document Loader
delimiter: 필드(열) 구분자 지정quotechar: 텍스트를 어떻게 묶을 것인지
ex) " : 큰따옴표로 묶인 텍스트를 하나의 값으로 처리fieldnames: 열 이름 설정
from langchain.document_loaders.csv_loader import CSVLoader
loader = CSVLoader(file_path='/content/drive/MyDrive/NLP톺아보기/file/mlb_teams_2012.csv', csv_args={
'delimiter': ',',
'quotechar': '"',
# 'fieldnames': ['ID', 'Name', 'Position', 'Height', 'Weight', 'Sponsorship Earnings', 'Shoe Sponsor', 'Career Stage', 'Age']
'fieldnames' : ['Team', 'Payroll (millions)', 'Wins']
})
data = loader.load()data[:10]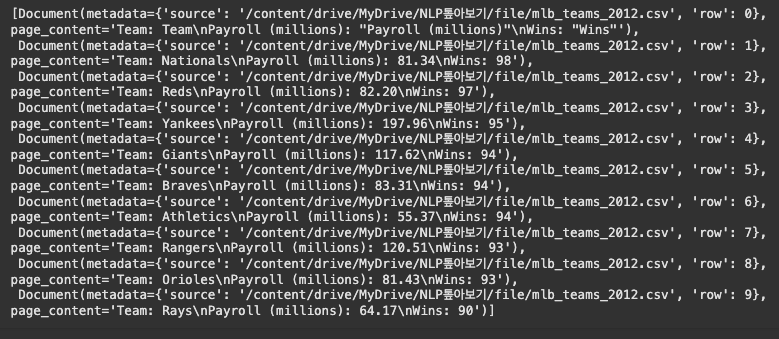
LLM 챗봇 ,랭체인의 핵심 Retrieval - Text Splitters
Text Splitter?
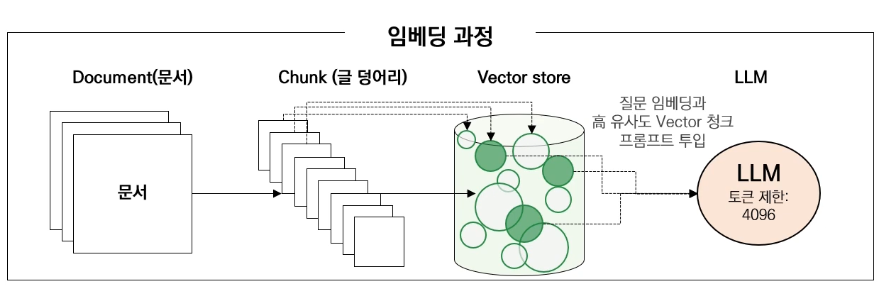
- 토큰 제한이 있는 LLM이 여러 문장 참고해서 답변할 수 있게 문서를 분할
- Chunk 1개당 하나의 Vector가 매칭됨
- vector store에 들어있는 여러 개의 임베딩 벡터들 == 청크들이 수치로 변환된 것
여러 개의 청크로 나누는 이유
- Vector store에서 사용자가 질문한 것의 임베딩과 유사도가 높은 벡터들을 매칭하고, 그 청크가 무엇인지 찾아서 LLM에게 보내 답을 찾도록 하는 것

- 대부분
RecursiveCharctorTextSplitter로 분할- CharctorTextSplitter
- 구분자 1개 기준 분할
- max_token을 못지키는 경우가 있음
- RecursiveCharctorTextSplitter
- 줄바꿈, 마침표, 쉼표순의 재귀적 분할
- max_token을 지킬 수 있게 됨

- CharctorTextSplitter
chunk_overlap?
-
문단 기준으로 청크 사이즈를 나누게 될 경우

-
chunk_overlap
- 이전 청크 끝 부분을 오버랩하는 것을 말함(뒷 부분과 앞 부분이 겹치게)
- 문맥 정보를 잃지 않기 위함

실습: Text Splitter
실습 코드 : Text_Splitters.ipynb
CharacterTextSplitter
- 단순 글자수 기반 문서 분할
- 가장 간단한 텍스트 분할기
- 특정 구분자 기준 텍스트 분할
- 파일 불러오기
with open('/content/drive/MyDrive/NLP톺아보기/file/state_of_the_union.txt') as f:
state_of_the_union = f.read()state_of_the_union
- CharacterTextSplitter 선언
- separator : 구분자
- chunk_size : 청크 사이즈 제한
- chunk_overlap : 이전 청크 끝 부분을 오버랩(뒷 부분과 앞 부분이 겹치게해서 문맥 정보를 잃지 않기 위함)
- length_function : 청크 사이즈의 기준
ex) len = 글자 수 기준
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(
separator = "\n\n",
chunk_size = 1000,
chunk_overlap = 100,
length_function = len,
)texts = text_splitter.split_text(state_of_the_union)
print(texts[0])
print("-"*100)
print(texts[1])
print("-"*100)
print(texts[2])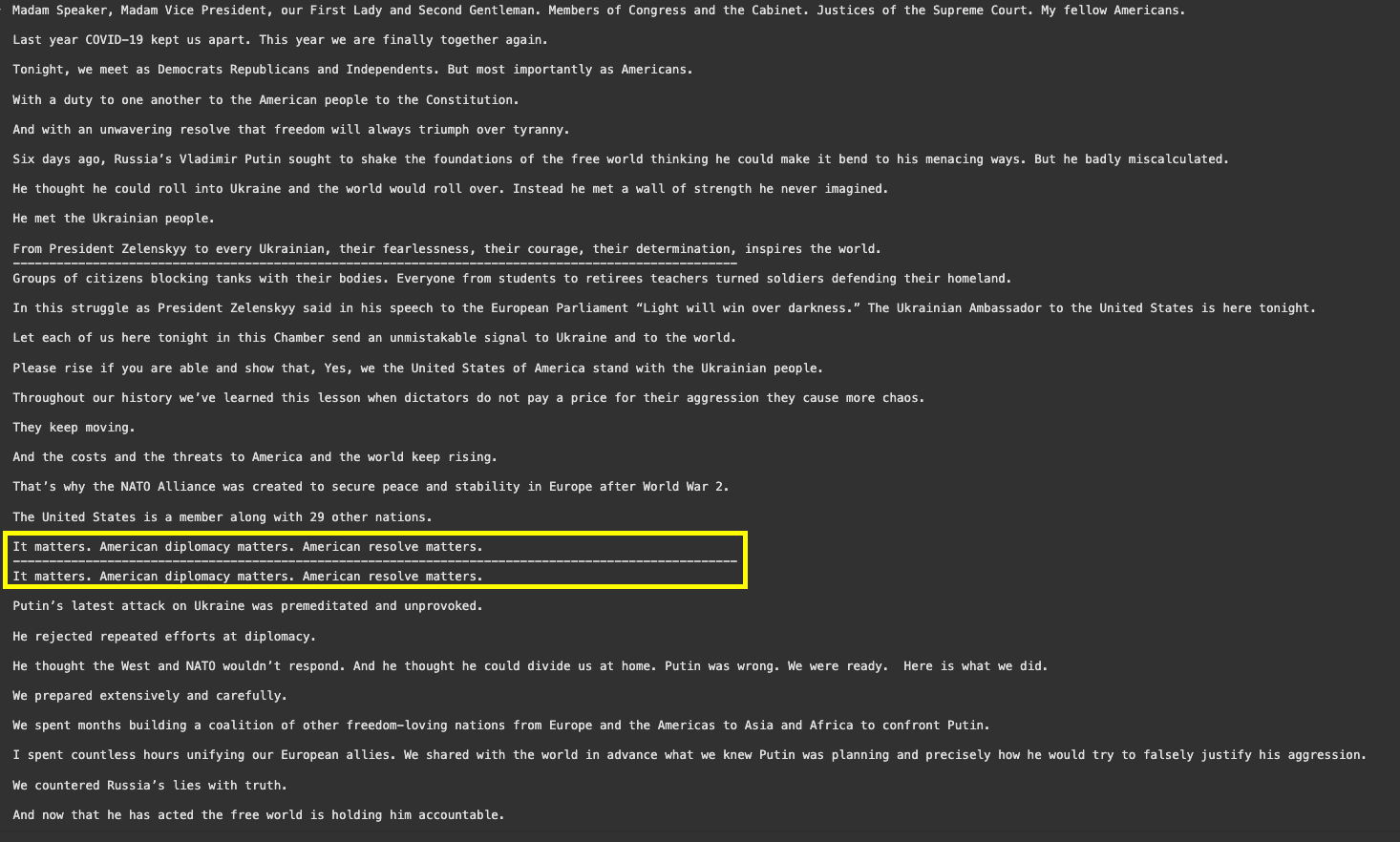
- 어떻게 나눠졌는지 확인
char_list = []
for i in range(len(texts)):
char_list.append(len(texts[i]))
print(char_list)
- 나눈 문서들을 바탕으로 documents 만들기
text_splitter.create_documents([state_of_the_union])
한글 문서로 실습해보기
- PyPDFLoader로 불러오기
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("/content/drive/MyDrive/NLP톺아보기/file/[이슈리포트 2022-2호] 혁신성장 정책금융 동향.pdf")
pages = loader.load_and_split()- 페이지 수 확인
len(pages)
- 두 번째 페이지 내용만 확인
print(pages[1].page_content)| 2 | CIS이슈리포트 2022-2호
▶혁신성장 ICT 산업의 정책금융 공급규모 및 공급속도를 종합적으로 분석한 결과, 차세대무선통신미디어, 능동형컴퓨팅(이상 정보통신 테마), 차세대반도체(전기전자 테마) 및 객체탐지(센서측정 테마) 기술분야로 혁신성장 정책금융이 집중되고 있음[ICT 산업 내 주요 기술분야 혁신성장 정책금융 공급 현황] (단위: 억 원, %)테마(대분류) 주요 기술분야(중분류) 정책금융 공급규모연평균 공급액 증가율(%)테마 내 공급 점유율(%)2017년 말2021년 말정보통신차세대무선통신미디어7,82027,86537.445.1능동형컴퓨팅35216,032159.810.1전기전자차세대반도체12,01953,77945.458.5센서측정객체탐지1,2786,71151.448.5▶주요 기술분야별 세부 품목단위로는 5G 이동통신시스템, 인공지능(AI), 시스템반도체 및 스마트센서에 정책금융 공급량이 높은 것으로 확인됨○정부가 미래 먹거리산업으로 선정한 인공지능(AI)의 미래성장율(CAGR: 41.0%)이 가장 높으며, 시장규모는 시스템반도체(3,833.8억 달러, 2025년)가 가장 큰 것으로 분석됨○4대 품목은 공통적으로 수요기반이 크고, 각국 정부가 중점적으로 육성을 지원하고 있어 시장이 지속 성장할 것으로 전망되나, 원천기술 미확보 및 높은 해외 의존도가 약점으로 지적되어 국내 기업의 경쟁력 강화가 시급한 것으로 평가됨[혁신성장 ICT 주요 품목 시장전망] (단위: 억 달러, %)주요 기술분야(중분류)주요 품목(소분류) 시장규모 전망시장 촉진·저해요인2020년2025년(E)CAGR(%)차세대무선통신미디어5G이동통신시스템494.41,982.032.0Ÿ(촉진) 정부의 국제표준 확보 의지Ÿ(저해) 소재에 대한 높은 해외 의존도능동형컴퓨팅인공지능(AI)398.42,223.741.0Ÿ(촉진) 정부의 미래먹거리 산업 선정Ÿ(저해) 국내 기술의 낮은 완성도차세대반도체시스템반도체2,723.63,833.87.1Ÿ(촉진) 반도체 강국 실현을 위한 정책Ÿ(저해) 글로벌 경쟁강도 심화객체탐지스마트센서366.5875.819.0Ÿ(촉진) 스마트팜 등 연관 산업의 성장Ÿ(저해) 설계 기술의 높은 해외 의존도▶산업의 경쟁력 강화를 위해 혁신성장 유망산업 분야로의 금융지원을 지속적으로 추진해야 함○빠른 산업변화를 반영한 혁신성장산업 기업발굴 가이드라인의 내실화·최신화에 노력을 기해야 함○또한, 미래 성장성은 유망하나 단기 수익 창출이 어려운 산업의 지원 강화를 위해 정책금융 뿐만 아니라 민관주도의 역동적 금융으로 혁신성장 금융지원 영역을 확대할 필요가 있음- CharacterTextSplitter 사용
- 줄바꿈을 한 부분까지만 출력
from langchain_text_splitters import CharacterTextSplitter
text_splitter = CharacterTextSplitter(
separator = "\n",
chunk_size = 1000,
chunk_overlap = 100,
length_function = len,
)
texts = text_splitter.split_documents(pages)
print(texts[1].page_content)
😶🌫️ PyPDFium2Loader 사용해보기
from langchain.document_loaders import PyPDFium2Loader
loader = PyPDFium2Loader(r"/content/drive/MyDrive/NLP톺아보기/file/[이슈리포트 2022-2호] 혁신성장 정책금융 동향.pdf")
pages = loader.load()
from langchain_text_splitters import CharacterTextSplitter
text_splitter = CharacterTextSplitter(
separator="\n",
chunk_size=500,
chunk_overlap=100,
length_function=len
)
texts = text_splitter.split_documents(pages)
print(texts[0])
- 2페이지 확인
print(texts[1])
- 분할 기준 바꿔서 시도
loader = PyPDFium2Loader(r"/content/drive/MyDrive/NLP톺아보기/file/[이슈리포트 2022-2호] 혁신성장 정책금융 동향.pdf")
pages = loader.load()
from langchain_text_splitters import CharacterTextSplitter
text_splitter = CharacterTextSplitter(
separator="\n\n",
chunk_size=500,
chunk_overlap=100,
length_function=len,
is_separator_regex=False,
)
texts = text_splitter.split_documents(pages)
print(texts[0])
- 길이 확인
print([len(i.page_content) for i in texts])
RecursiveCharacterTextSplitter
- 재귀적 문서 분할
\n\n: 줄바꿈 기준 문서 분할- 나눈 청크가 여전히 클 경우 ➡️
\n(문장 단위) 기준 문서 분할 - 그럼에도 작아지지 않을 경우 ➡️ 문장을 단어 단위로 분할
- 의미 보존에 용이하기 때문에 다수의 청크를 LLM에 활용함에 있어 맥락 유지가 용이해짐!
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter (
chunk_size = 1000,
chunk_overlap = 200,
length_function=len,
)texts = text_splitter.create_documents([state_of_the_union])
print(texts[0].page_content)
print("-"*500)
print(texts[1].page_content)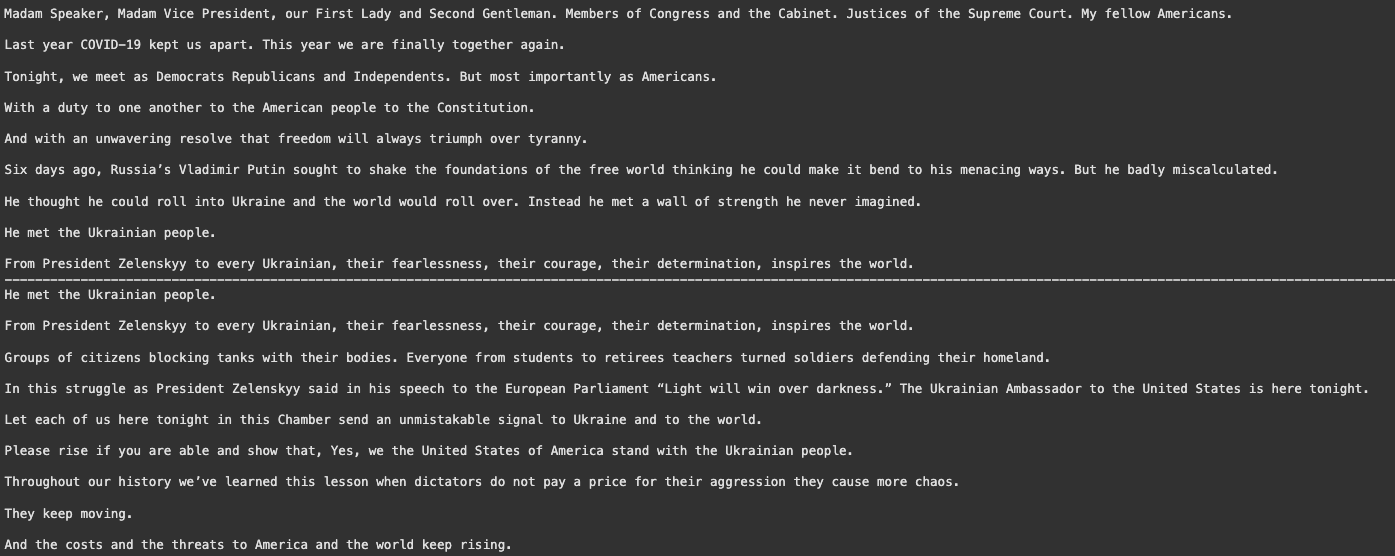
- 글자 수 확인
- 청크 사이즈가 1000을 넘어가는 것이 없어짐!
char_list = []
for i in range(len(texts)):
char_list.append(len(texts[i].page_content))
print(char_list)
한글 문서로 실습해보기
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("/content/drive/MyDrive/NLP톺아보기/file/[이슈리포트 2022-2호] 혁신성장 정책금융 동향.pdf")
pages = loader.load_and_split()
len(pages)
print(pages[1].page_content)| 2 | CIS이슈리포트 2022-2호
▶혁신성장 ICT 산업의 정책금융 공급규모 및 공급속도를 종합적으로 분석한 결과, 차세대무선통신미디어, 능동형컴퓨팅(이상 정보통신 테마), 차세대반도체(전기전자 테마) 및 객체탐지(센서측정 테마) 기술분야로 혁신성장 정책금융이 집중되고 있음[ICT 산업 내 주요 기술분야 혁신성장 정책금융 공급 현황] (단위: 억 원, %)테마(대분류) 주요 기술분야(중분류) 정책금융 공급규모연평균 공급액 증가율(%)테마 내 공급 점유율(%)2017년 말2021년 말정보통신차세대무선통신미디어7,82027,86537.445.1능동형컴퓨팅35216,032159.810.1전기전자차세대반도체12,01953,77945.458.5센서측정객체탐지1,2786,71151.448.5▶주요 기술분야별 세부 품목단위로는 5G 이동통신시스템, 인공지능(AI), 시스템반도체 및 스마트센서에 정책금융 공급량이 높은 것으로 확인됨○정부가 미래 먹거리산업으로 선정한 인공지능(AI)의 미래성장율(CAGR: 41.0%)이 가장 높으며, 시장규모는 시스템반도체(3,833.8억 달러, 2025년)가 가장 큰 것으로 분석됨○4대 품목은 공통적으로 수요기반이 크고, 각국 정부가 중점적으로 육성을 지원하고 있어 시장이 지속 성장할 것으로 전망되나, 원천기술 미확보 및 높은 해외 의존도가 약점으로 지적되어 국내 기업의 경쟁력 강화가 시급한 것으로 평가됨[혁신성장 ICT 주요 품목 시장전망] (단위: 억 달러, %)주요 기술분야(중분류)주요 품목(소분류) 시장규모 전망시장 촉진·저해요인2020년2025년(E)CAGR(%)차세대무선통신미디어5G이동통신시스템494.41,982.032.0Ÿ(촉진) 정부의 국제표준 확보 의지Ÿ(저해) 소재에 대한 높은 해외 의존도능동형컴퓨팅인공지능(AI)398.42,223.741.0Ÿ(촉진) 정부의 미래먹거리 산업 선정Ÿ(저해) 국내 기술의 낮은 완성도차세대반도체시스템반도체2,723.63,833.87.1Ÿ(촉진) 반도체 강국 실현을 위한 정책Ÿ(저해) 글로벌 경쟁강도 심화객체탐지스마트센서366.5875.819.0Ÿ(촉진) 스마트팜 등 연관 산업의 성장Ÿ(저해) 설계 기술의 높은 해외 의존도▶산업의 경쟁력 강화를 위해 혁신성장 유망산업 분야로의 금융지원을 지속적으로 추진해야 함○빠른 산업변화를 반영한 혁신성장산업 기업발굴 가이드라인의 내실화·최신화에 노력을 기해야 함○또한, 미래 성장성은 유망하나 단기 수익 창출이 어려운 산업의 지원 강화를 위해 정책금융 뿐만 아니라 민관주도의 역동적 금융으로 혁신성장 금융지원 영역을 확대할 필요가 있음texts = text_splitter.split_documents(pages)len(texts)
- 사이즈 확인
char_list = []
for i in range(len(texts)):
char_list.append(len(texts[i].page_content))
print(char_list)
- PyPDFium2Loader
from langchain.document_loaders import PyPDFium2Loader
loader = PyPDFium2Loader(r"/content/drive/MyDrive/NLP톺아보기/file/[이슈리포트 2022-2호] 혁신성장 정책금융 동향.pdf")
pages = loader.load()
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter (
separators=["\n\n", "\n", " ", ""],
chunk_size=500,
chunk_overlap=100,
length_function=len,
is_separator_regex=False,
)
texts = text_splitter.split_documents(pages)
print([len(i.page_content) for i in texts])
기타 Splitter
- 일반 글 문서 : textsplitter로 분할 가능
- 코드, latex 같은 컴퓨터 언어 문서 : 해당 언어를 특별하게 구분할 수 있는 splitter가 필요함
- ex) Python 문서 분할
def,class같은 묶음 담위를 기준으로 문서 분할 필요
from langchain.text_splitter import (
RecursiveCharacterTextSplitter,
Language,
)RecursiveCharacterTextSplitter.get_separators_for_language(Language.PYTHON)
- 2개의 documents로 분할됨
PYTHON_CODE = """
def hello_world():
print("Hello, World!")
# Call the function
hello_world()
"""
python_splitter = RecursiveCharacterTextSplitter.from_language(
language = Language.PYTHON, chunk_size = 50, chunk_overlap = 0
)
python_docs = python_splitter.create_documents([PYTHON_CODE])
python_docs
토큰 단위 텍스트 분할기
- ChatGPT : tiktoken이라는 토크나이저를 기반으로 텍스트 토큰화
- 토큰 수 기준 텍스트 분할 필요
!pip install tiktokencl100k_base: GPT 모델들을 인코딩할 경우 사용tiktoken_len: 토큰을 세는 함수
import tiktoken
tokenizer = tiktoken.get_encoding("cl100k_base")
def tiktoken_len(text):
tokens = tokenizer.encode(text)
return len(tokens)- 토큰 개수 확인
tiktoken_len(texts[1].page_content)
length_function = tiktoken_len
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 1000, chunk_overlap = 0, length_function = tiktoken_len
)
texts = text_splitter.split_documents(pages)print(len(texts[1].page_content))
print(tiktoken_len(texts[1].page_content))
- 개수 확인
token_list = []
for i in range(len(texts)):
token_list.append(tiktoken_len(texts[i].page_content))
print(token_list)
Semantic Chunker
- 문맥 파악 통한 문서 분할
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader(r"/content/drive/MyDrive/NLP톺아보기/file/BOK 이슈노트 제2022-38호 인공지능 언어모형을 이용한 인플레이션 어조지수 개발 및 시사점.pdf")
pages = loader.load_and_split()
from langchain_experimental.text_splitter import SemanticChunker
from langchain_openai.embeddings import OpenAIEmbeddings
text_splitter = SemanticChunker(OpenAIEmbeddings(openai_api_key = "YOUR_OPENAI_API_KEY"))
texts = text_splitter.split_documents(pages)
print("-"*100)
print("[첫번째 청크]")
print(texts[0].page_content)
print("-"*100)
print("[두번째 청크]")
print(texts[1].page_content)
print([len(i.page_content) for i in texts])

언젠가 내 코드로 세상에 기여할 수 있도록, Data Science&BE 개발 기록 노트☘️
회사에서 랭체인관련 찾아보다 좋은 글이 있어 들립니다. 제 블로그에 퍼가도 될까요??