Day 03. LLM 챗봇 ,랭체인의 핵심 Retrieval - Text Embeddings, Vectorstores, Retriever
AIFFELLLMLLM 챗봇Text EmbeddingsVectorstoreslangChainretriever데싸데싸 3기데이터 사이언스데이터사이언티스트데이터사이언티스트 3기랭체인아이펠
☺️ AIFFEL 데이터사이언티스트 3기
목록 보기
93/115

본 내용은 RAG 시스템 구축을 위한 랭체인 실전 가이드 교재 및 강의 자료, 실습 자료를 사용했음을 알립니다.
- 강의 : [모두의AI] Langchain 강의
- 실습 : Kane0002/Langchain-RAG
핵심 로직
-
데이터 준비 단계
원본 텍스트 → 텍스트 임베딩 → 벡터 스토어에 저장 -
검색 단계
사용자 쿼리 → 임베딩 변환 → Retriever가 벡터 스토어에서 검색 → 관련 문서 반환
랭체인의 핵심, Retrieval-Text Embeddings
Text Embeddings?
-
텍스트를 숫자로 변환해 문장 간 유사성 비교가 가능하도록 하는 것

-
대부분의 경우, 대용량 말뭉치를 통해 사전학습된 모델로 쉽게 임베딩
- 임베딩 모델 : 비정형 데이터를 수치화해서 좌표 상에 위치할 수 있도록 해줌
- 다차원의 벡터를 통해 비정형 언어를 정형 데이터로 바꾸는 역할을 담당하는 것
- 임베딩 모델이 학습되지 않은 문장에 대해서도 수치화하는 것을 잘할 수 있게 됨
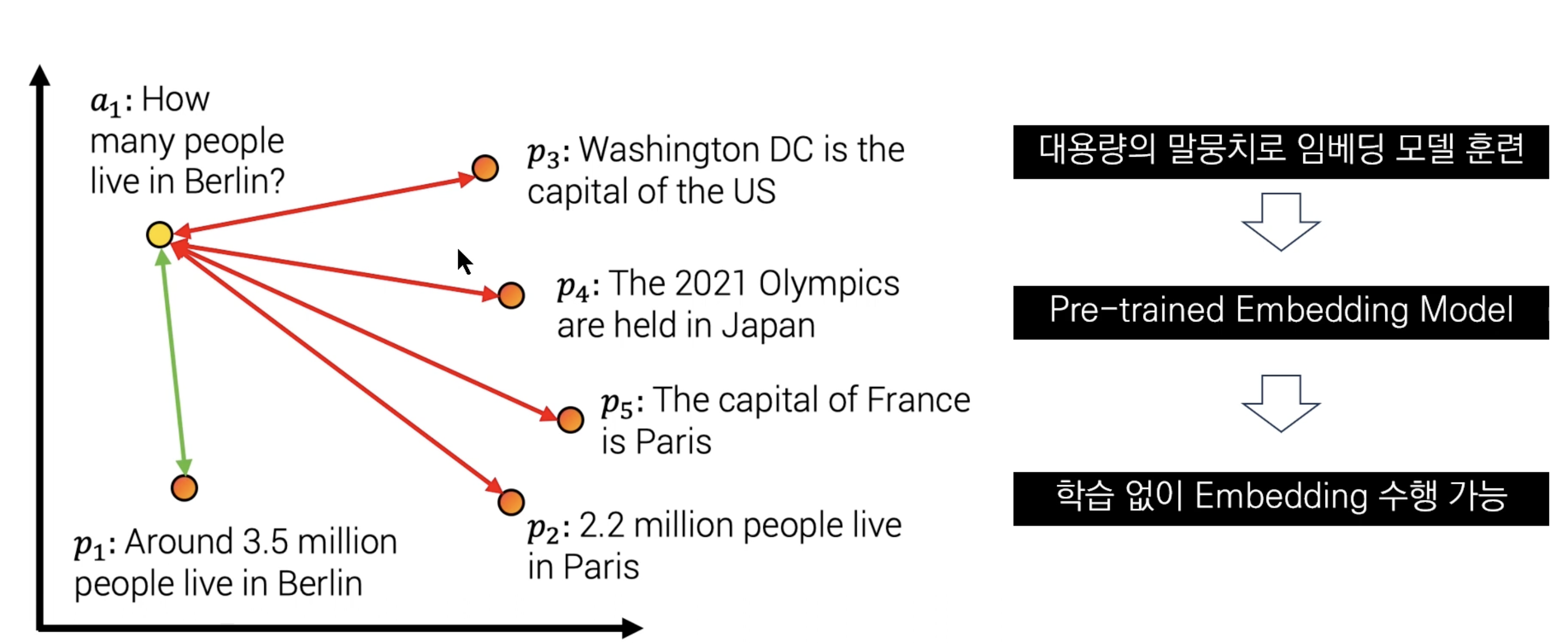
사전학습 임베딩 모델
- OpenAI에서 제공하는 ada 모델, HuggingFace 모델 등
- 사용 목적 및 요구 사항에 따른 적절한 임베딩을 고르는 것이 RAG의 가장 주요한 부분
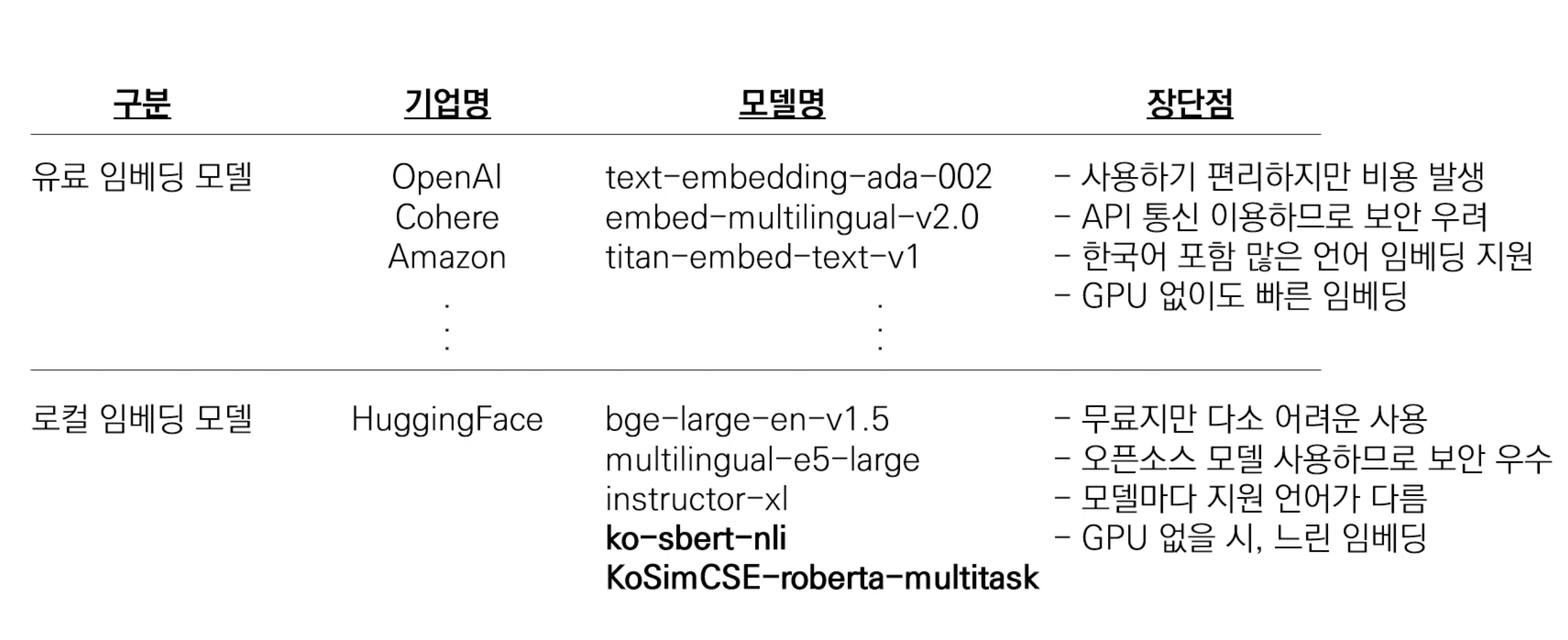
실습: Text Embeddings
실습 코드 : Text Embedding.ipynb
OpenAI Embeddings - ada-002
OpenAIEmbeddings: OpenAI 임베딩 모델embeddings_model.embed_documents: 여러 개의 문장을 한꺼번에 임베딩- 한글 문장을
embeddings에 저장
from langchain_openai import OpenAIEmbeddings
embeddings_model = OpenAIEmbeddings(openai_api_key = '{API KEY}')
embeddings = embeddings_model.embed_documents(
[
"안녕하세요",
"제 이름은 이하얀입니다.",
"이름이 무엇인가요?",
"랭체인은 유용합니다.",
"Hello World!"
]
)
len(embeddings), len(embeddings[0])
하나의 문장이 1536개의 차원을 가진 하나의 행이 된다는 의미
- 유사도 확인
- 지금 넣은 2문장도 1536차원으로 임베딩되었음을 알 수 있음
embedded_query_q = embeddings_model.embed_query("이 대화에서 언급된 이름은 무엇입니까?")
embedded_query_a = embeddings_model.embed_query("이 대화에서 언급된 이름은 이하얀입니다.")
print(len(embedded_query_q), len(embedded_query_a))
- 벡터 간 유사도 확인
- 코사인 유사도 사용
- 순서 : 질문-답변, 질문-두 번째 문장, 질문-네 번째 문장
from numpy import dot
from numpy.linalg import norm
import numpy as np
def cos_sim(A, B):
return dot(A, B) / (norm(A)*norm(B))
print(cos_sim(embedded_query_q, embedded_query_a))
print(cos_sim(embedded_query_q, embeddings[1]))
print(cos_sim(embedded_query_q, embeddings[3]))
오픈 소스 - HuggingFaceEmbeddings
sentence-transformers라이브러리 다운
!pip install sentence-transformers1. BAAI/bge-small-en 임베딩 모델
- 주의 : 구글 코랩 환경일 경우
런타임 > 런타임 유형 변경 > GPU로 변경하여 사용
from langchain_community.embeddings import HuggingFaceEmbeddings
model_name = "BAAI/bge-small-en"
bge_embedding= HuggingFaceEmbeddings(
model_name=model_name
)
- 한글 문장 테스트
examples = bge_embedding.embed_documents(
[
"안녕하세요",
"제 이름은 홍두깨입니다.",
"이름이 무엇인가요?",
"랭체인은 유용합니다.",
]
)
embedded_query_q = bge_embedding.embed_query("이 대화에서 언급된 이름은 무엇입니까?")
embedded_query_a = bge_embedding.embed_query("이 대화에서 언급된 이름은 홍길동입니다.")
print(cos_sim(embedded_query_q, embedded_query_a))
print(cos_sim(embedded_query_q, examples[1]))
print(cos_sim(embedded_query_q, examples[3]))
- 영어 문장 테스트
examples2 = bge_embedding.embed_documents(
[
"today is tuesday",
"weather is nice today",
"what's the problem?",
"langchain in useful",
"Hello World!",
"my name is morris"
]
)
embedded_query_q = bge_embedding.embed_query("Hello? who is this?")
embedded_query_a = bge_embedding.embed_query("hi this is harrison")
print(cos_sim(embedded_query_q, embedded_query_a))
print(cos_sim(embedded_query_q, examples2[1]))
print(cos_sim(embedded_query_q, examples2[3]))
- 여러개 문장 비교
sentences = [
"안녕하세요",
"제 이름은 홍길동입니다.",
"이름이 무엇인가요?",
"랭체인은 유용합니다.",
"홍길동 아버지의 이름은 홍상직입니다."
]
examples3 = bge_embedding.embed_documents(sentences)
embedded_query_q = bge_embedding.embed_query("홍길동은 아버지를 아버지라 부르지 못하였습니다. 홍길동 아버지의 이름은 무엇입니까?")
embedded_query_a = bge_embedding.embed_query("홍길동의 아버지느 엄했습니다.")
print("질문: 홍길동은 아버지를 아버지라 부르지 못하였습니다. 홍길동 아버지의 이름은 무엇입니까? \n", "-"*100)
print("홍길동의 아버지는 엄했습니다. \t\t 문장 유사도: ", round(cos_sim(embedded_query_q, embedded_query_a),2))
print(sentences[1] + "\t\t 문장 유사도: ", round(cos_sim(embedded_query_q, examples3[1]),2))
print(sentences[3] + "\t\t 문장 유사도: ", round(cos_sim(embedded_query_q, examples3[3]),2))
print(sentences[4] + "\t 문장 유사도: ", round(cos_sim(embedded_query_q, examples3[4]),2))
2. jhgan/ko-sroberta-multitask
from langchain.embeddings import HuggingFaceEmbeddings
#HuggingfaceEmbedding 함수로 Open source 임베딩 모델 로드
model_name = "jhgan/ko-sroberta-multitask"
ko_embedding= HuggingFaceEmbeddings(
model_name=model_name
)
examples = ko_embedding.embed_documents(
[
"안녕하세요",
"제 이름은 홍두깨입니다.",
"이름이 무엇인가요?",
"랭체인은 유용합니다.",
]
)
embedded_query_q = ko_embedding.embed_query("이 대화에서 언급된 이름은 무엇입니까?")
embedded_query_a = ko_embedding.embed_query("이 대화에서 언급된 이름은 홍길동입니다.")
print(cos_sim(embedded_query_q, embedded_query_a))
print(cos_sim(embedded_query_q, examples[1]))
print(cos_sim(embedded_query_q, examples[3]))
3. OpenAI 임베딩 모델 - text-embedding-3-small
import os
import openai
from langchain_openai import OpenAIEmbeddings
from google.colab import userdata
openai.api_key = userdata.get('OPENAI_API_KEY')
embeddings_model = OpenAIEmbeddings(model = 'text-embedding-3-small')
embeddings = embeddings_model.embed_documents(
[
"Hi there!",
"Oh, hello!",
"What's your name?",
"My friends call me World",
"Hello World!"
]
)
len(embeddings), len(embeddings[0])
- OpenAI 임베딩 모델로 청크들을 임베딩 변환
from langchain_community.document_loaders import PyPDFium2Loader
from langchain_text_splitters import RecursiveCharacterTextSplitter
#임베딩 모델 API 호출
embeddings_model = OpenAIEmbeddings(model = 'text-embedding-3-small')
#PDF 문서 로드
loader = PyPDFium2Loader("/content/drive/MyDrive/NLP톺아보기/file/[이슈리포트 2022-2호] 혁신성장 정책금융 동향.pdf")
pages = loader.load()
#PDF 문서를 여러 청크로 분할
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=100
)
texts = text_splitter.split_documents(pages)
embeddings = embeddings_model.embed_documents([i.page_content for i in texts])
len(embeddings), len(embeddings[0])
랭체인의 핵심, Retrieval - Vectorstores
Vectorstore?
- 자연어를 수치화한 후 이들을 저장하는 벡터 저장소
- 벡터 저장소 : 임베딩된 데이터를 인덱싱, input으로 받아들이는 query와의 유사도를 빠르게 출력
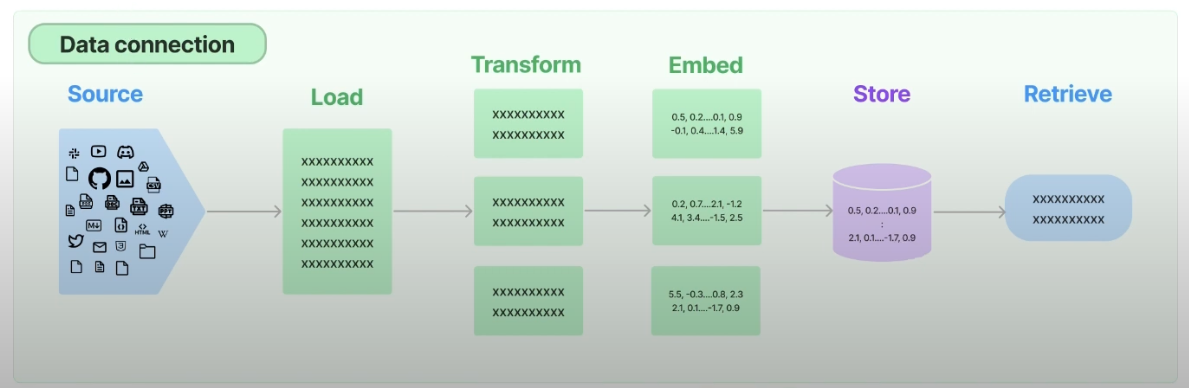
Vectorstore 종류
- 대표 : Chroma, FAISS
- Pure vector databases : DB들이 가지고 있는 유용한 툴들(저장, 삭제, 이동,...) 및 기능들이 들어가 있음
- Vector libraries : 벡터 유사도 계산에 특화되어 있음

실습: Vector Stores
실습 코드 : Vector_Stores.ipynb
1. Chroma DB
- 오픈소스 벡터 저장소
- Vectorstore : 벡터를 일시적으로 저장
- 텍스트 및 임베딩 함수를 지정해
from_documents()함수에 보내면 ➡️ 지정된 임베딩 함수를 통해 텍스트를 벡터로 변환 + 임시 DB 생성 similarity_search()함수에 쿼리를 지정 ➡️ 벡터 유사도가 높은 벡터를 찾고 자연어 형태로 출력
- 텍스트 및 임베딩 함수를 지정해
- OpenAI 모델 사용
# API KEY 환경변수 등록
import os
os.environ['OPENAI_API_KEY'] = '{api key}'import os
import openai
from langchain.document_loaders import PyPDFLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from google.colab import userdata
openai.api_key = userdata.get('OPENAI_API_KEY')
openai_embedding=OpenAIEmbeddings(model = 'text-embedding-3-small')
loader = PyPDFLoader(r"/content/drive/MyDrive/NLP톺아보기/file/대한민국헌법(헌법)(제00010호)(19880225).pdf")
pages = loader.load_and_split()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
docs = text_splitter.split_documents(pages)
db = Chroma.from_documents(docs, openai_embedding)- 쿼리
query = "대통령의 임기는?"
#유사 문서 검색
docs = db.similarity_search(query)
print(docs[0])
similarity_search_with_score: 벡터 간 거리(낮을수록 유사)를 계산해 함께 제공
db.similarity_search_with_score(query)
벡터DB를 로컬 디스크에 저장하고 로드
- 데이터베이스를 처음 상태로 초기화(위에서 사용했기 때문)
Chroma().delete_collection()- jhgan/ko-sroberta-multitask 모델 사용
from langchain.document_loaders import TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain.embeddings import HuggingFaceEmbeddings
from langchain_chroma import Chroma
loader = PyPDFLoader(r"/content/drive/MyDrive/NLP톺아보기/file/대한민국헌법(헌법)(제00010호)(19880225).pdf")
pages = loader.load_and_split()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
docs = text_splitter.split_documents(pages)
model_name = "jhgan/ko-sroberta-multitask"
ko_embedding= HuggingFaceEmbeddings(
model_name=model_name
)
- 디스크에 저장 & 로드
Chroma.from_documents: 저장Chroma(persist_directory="./chroma_db"): 로드
#save to disk
db2 = Chroma.from_documents(docs, ko_embedding, persist_directory="./chroma_db")
# load from disk
db3 = Chroma(persist_directory="./chroma_db", embedding_function=ko_embedding)
query = "대통령의 임기는?"
result = db3.similarity_search(query)
print(result[0].page_content)
2. Chroma DB API를 활용한 문서 관리
- Collection 객체 생성과 문서 저장
- Collection : 텍스트 임베딩을 포함하는 상위 개념의 폴더
import chromadb
#collection을 저장할 경로 지정
client = chromadb.PersistentClient(path="collection_example")
#client가 잘 연결되어 있는지 확인
client.heartbeat()
잘 연결된 경우, 나노초로 출력됨
- Collection 생성
embedding_function: 문서를 임베딩 변환할 모델
from chromadb.utils import embedding_functions
from chromadb.utils.embedding_functions import OpenAIEmbeddingFunction
#OpenAI 임베딩 모델
embedding_function = openai_embedding=OpenAIEmbeddings(model = 'text-embedding-3-small')
#Huggingface 오픈소스 임베딩 모델
embedding_function = embedding_functions.SentenceTransformerEmbeddingFunction(model_name="jhgan/ko-sbert-nli")
collection = client.create_collection(name="korean_law", embedding_function=embedding_function)
- Collection에 문서 임베딩 저장
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.document_loaders import PyPDFLoader
# load the document and split it into chunks
loader = PyPDFLoader(r"/content/drive/MyDrive/NLP톺아보기/file/대한민국헌법(헌법)(제00010호)(19880225).pdf")
pages = loader.load_and_split()
# split it into chunks
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
docs = text_splitter.split_documents(pages)
collection.add(
ids = [str(i) for i in range(len(docs))],
documents=[i.page_content for i in docs],
metadatas=[i.metadata for i in docs]
)
- Collection 로드
- name : collection 이름
- embedding_function : collection 저장 시 지정한 임베딩 모델
collection = client.get_collection(name="korean_law", embedding_function=embedding_function)
collection
- Collection 내 문서 검색
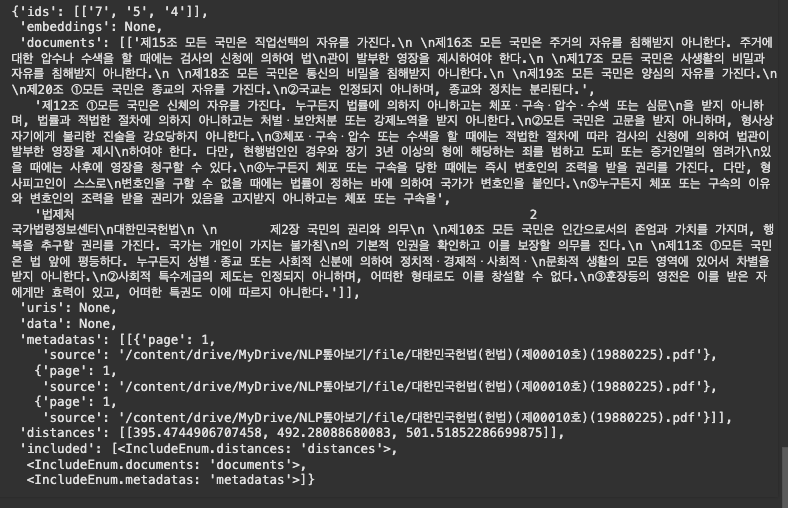
- 1 페이지에서 직업 선택의 자유와 유사한 청크 3개 검색
collection.query(
query_texts=["직업 선택의 자유"],
n_results=3,
where={"page": 1},
)
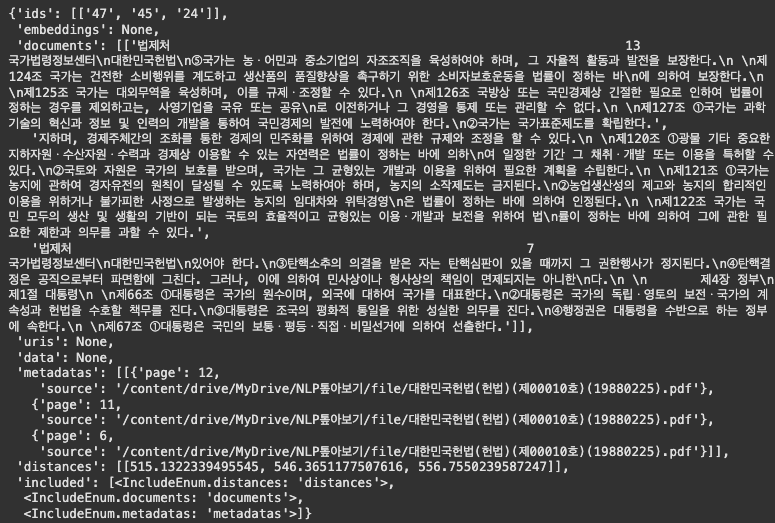
- 조건부 문서 검색
- 5 페이지 이후의 청크 중에서 직업 선택의 자유와 관련한 문서 3개 검색
기본 문법
$eq- 일치 (string, int, float)
$ne- 불일치 (string, int, float)
$gt- 초과 (int, float)
$gte- 이상 (int, float)
$lt- 미만 (int, float)
$lte- 이하 (int, float)
collection.query(
query_texts=["직업 선택의 자유"],
n_results=3,
where={"page": {"$gte": 5}}
)
collection.query(
query_texts=["직업 선택의 자유"],
n_results=3,
where={"page": 1},
where_document={"$contains": "직업"}
)
3. FAISS
- Facebook AI 유사성 검색
- 고밀도 벡터의 효율적인 유사성 검색 및 클러스터링을 위한 라이브러리
- 모든 크기의 벡터 집합에서 검색하는 알고리즘 포함
- RAM에 맞지 않는 벡터까지 검색 가능
- 평가 및 매개변수 조정을 위한 지원 코드도 포함
# from langchain.vectorstores import FAISS
from langchain_community.vectorstores.faiss import FAISS
loader2 = PyPDFLoader(r"/content/drive/MyDrive/NLP톺아보기/file/[이슈리포트 2022-2호] 혁신성장 정책금융 동향.pdf")
pages = loader2.load_and_split()
# Split it into chunks
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0, length_function = tiktoken_len)
docs = text_splitter.split_documents(pages)
from langchain_community.embeddings import HuggingFaceEmbeddings
model_name="jhgan/ko-sbert-nli"
model_kwargs = {'device': 'cpu'}
encode_kwargs = {'normalize_embeddings': True}
ko = HuggingFaceEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs
)# Query the FAISS vector store
query = "인공지능 산업 구조가 어떻게 이루어져 있는지 알려줘."
docs = faiss_db.similarity_search(query)
# Print the page content in multiple lines
page_content = docs[0].page_content
# Split the page content into multiple lines
for i in range(0, len(page_content), 80):
print(page_content[i:i+80])
docs_and_scores = faiss_db.similarity_search_with_score(query)
docs_and_scores
faiss_db.save_local("faiss_index")new_db = FAISS.load_local("faiss_index", ko, allow_dangerous_deserialization=True)
query = "인공지능 산업 구조가 어떻게 이루어져 있는지 알려줘."
docs = new_db.similarity_search_with_relevance_scores(query, k=3)
print("질문: {} \n".format(query))
for i in range(len(docs)):
print("{0}번째 유사 문서 유사도 \n{1}".format(i+1,round(docs[i][1],2)))
print("-"*100)
print(docs[i][0].page_content)
print("\n")
print(docs[i][0].metadata)
print("-"*100)질문: 인공지능 산업 구조가 어떻게 이루어져 있는지 알려줘.
1번째 유사 문서 유사도
0.5
----------------------------------------------------------------------------------------------------
▶인공지능 산업의 value chain은 ‘AI 플랫폼 공급업체 → AI 어플리케이션 개발 → AI 응용솔루션 개발 → 이용자’로 구성되며, 동 산업은 ①성장기 산업, ②대체재로부터의 위협이 낮은 산업, ③기술집약적 산업 등의 특징을 가짐○알고리즘, 하드웨어 기술개발과 응용솔루션 서비스 상용화가 활발히 진행 중인 성장기 산업이며, 수요 기업의 요구사항에 따라 운영플랫폼을 선택할 수 있는 구매자의 교섭력이 높은 산업임○직접적인 대체 기술이 없어 대체재로부터 위협이 낮은 편이며, 알고리즘의 동작원리를 이해하고 맞춤형 서비스를 지원하기 위한 솔루션 개발 능력이 뒷받침 되어야 하는 기술집약적 산업임▶시장조사전문기관 BCC research에 따르면 세계 인공지능 시장규모는 2020년 398.4억 달러에서 연평균 41.0% 성장하여 2025년에는 2,223.7억 달러의 시장을 형성할 것으로 전망됨○세부 솔루션 분문별로는 2020년 기준
{'source': '/content/drive/MyDrive/NLP톺아보기/file/[이슈리포트 2022-2호] 혁신성장 정책금융 동향.pdf', 'page': 9}
----------------------------------------------------------------------------------------------------
2번째 유사 문서 유사도
0.49
----------------------------------------------------------------------------------------------------
주: 스마트물류시스템 품목은 2021년부터 신규 품목으로 편임▶인공지능은 인간의 학습능력과 추론·지각능력, 자연언어 이해능력 등을 프로그램으로 구현한 기술로, 컴퓨터가 인간의 지능적인 행동을 모방하는 방향으로 발전하고 있음○인공지능은 사람의 두뇌가 복잡한 연산을 수행하는 점을 모방해 뉴런(Neuron)을 수학적으로 모방한 알고리즘인 퍼셉트론(Perceptron)을 이용하여 컴퓨터의 연산 로직을 처리하는 원리로 동작함[인공지능 동작 개념]구분 구조뉴런Ÿ세포체의 자극이 임계치를 넘으면 신경전달물질 발화
인공지능(퍼셉트론)Ÿ활성함수의 계산 결과를 출력
자료: 디지에코
{'source': '/content/drive/MyDrive/NLP톺아보기/file/[이슈리포트 2022-2호] 혁신성장 정책금융 동향.pdf', 'page': 7}
----------------------------------------------------------------------------------------------------
3번째 유사 문서 유사도
0.49
----------------------------------------------------------------------------------------------------
▶다양한 데이터나 복잡한 자료 속에서 핵심적인 특징을 요약하는 ①데이터 추상화 기술, 방대한 지식체계를 이용하는 ②빅데이터 기술, 빅데이터를 처리하기 위한 ③고성능 컴퓨팅 기술이 인공지능 구현의 핵심임○데이터를 추상화하는 방법은 크게 인공신경망(ANN), 심층신경망(DNN), 합성곱신경망(CNN) 및 순환신경망(RNN) 등으로 구분됨[인공지능 데이터 추상화 기술]구분특징장점단점인공신경망(ANN)Artificial Neural Network사람의 신경망 원리와 구조를 모방하여 만든 기계학습 알고리즘으로, 입력층, 출력층, 은닉층으로 구성 모든 비선형 함수 학습이 가능알고리즘을 최적화하기 어려운 학습 환경 발생심층신경망(DNN)Deep Neural Network입력층과 출력층 사이에 2개 이상의 은닉층들로 이뤄진 인공신경망ANN의 문제점 개선학습환경에 따라 높은 시간 복잡도 문제 발생합성곱신경망(CNN)Convolution Neural Network데이터의 특징을 추출하여 특징들의 패턴을 파악하는 인공신경망이미지, 영상 데이터 판별에 강점특징추출 과정에서 정보손실 발생순환신경망(RNN)Recurrent Neural
{'source': '/content/drive/MyDrive/NLP톺아보기/file/[이슈리포트 2022-2호] 혁신성장 정책금융 동향.pdf', 'page': 8}
----------------------------------------------------------------------------------------------------query = "5G 이동통신 시스템은?"
docs = new_db.max_marginal_relevance_search(query, k=3)
print("질문: {} \n".format(query))
for i in range(len(docs)):
print("{}번째 유사 문서:".format(i+1))
print("-"*100)
print(docs[i].page_content)
print("\n")
print(docs[i].metadata)
print("-"*100)질문: 5G 이동통신 시스템은?
1번째 유사 문서:
----------------------------------------------------------------------------------------------------
▶5G 이동통신 시스템은 ITU(International Telecommunication Union)가 정의한 5세대 이동통신 규격을 만족시키는 무선 이동통신 네트워크 기술로, 2019년부터 국내 서비스를 시작함○4G 이동통신 시스템(LTE)과 비교할 때 전송속도의 향상(1Gbps→20Gbps), 이동성 향상(350km/h→500km/h에서 끊김없는 데이터 전송 가능), 최대 연결가능 기기수 증가(10만 대 →100만 대 이상), 데이터 전송지연 감소(10ms→1ms) 등의 향상된 기능을 제공함○5G는 전송속도 향상, 다수기기 접속 및 지연시간 단축을 위해 ①밀리미터파 통신이 가능한 주파수 확장, ②스몰셀(Small cell)을 도입한 기지국, ③다중안테나 송수신(Massive MIMO), ④네트워크 슬라이싱(Network Slicing) 등의 기술을 도입함[5G 주요 요소기술 특징]
자료: 삼정 KPMG
{'source': '/content/drive/MyDrive/NLP톺아보기/file/[이슈리포트 2022-2호] 혁신성장 정책금융 동향.pdf', 'page': 5}
----------------------------------------------------------------------------------------------------
2번째 유사 문서:
----------------------------------------------------------------------------------------------------
혁신성장 정책금융 동향 : ICT 산업을 중심으로
CIS이슈리포트 2022-2호 | 5 |
{'source': '/content/drive/MyDrive/NLP톺아보기/file/[이슈리포트 2022-2호] 혁신성장 정책금융 동향.pdf', 'page': 4}
----------------------------------------------------------------------------------------------------
3번째 유사 문서:
----------------------------------------------------------------------------------------------------
규모의 약 50% 수준을 점유하고 있으며, 이는 사물인터넷 기반의 네트워크 구축을 위한 요소기술로 객체탐지 기술·제품에 대한 사업화가 활발함에 따른 것으로 분석됨
{'source': '/content/drive/MyDrive/NLP톺아보기/file/[이슈리포트 2022-2호] 혁신성장 정책금융 동향.pdf', 'page': 14}
----------------------------------------------------------------------------------------------------- fetch_k : 벡터 데이터베이스에서 가져올 문서 개수
- 내부적으로 상위 10개 문서를 가져와, 그 중 가장 관련성 높은 3개 문서를 반환하는 형식
- lambda_mult : 가중치
query = "인공지능 산업 구조가 어떻게 이루어져 있는지 알려줘."
docs = new_db.similarity_search(query, k=3, fetch_k=10, lambda_mult=0.3)
print("질문: {} \n".format(query))
for i in range(len(docs)):
print("{}번째 유사 문서:".format(i+1))
print("-"*100)
print(docs[i].page_content)
print("\n")
print(docs[i].metadata)
print("-"*100)
print("\n\n")질문: 인공지능 산업 구조가 어떻게 이루어져 있는지 알려줘.
1번째 유사 문서:
----------------------------------------------------------------------------------------------------
▶인공지능 산업의 value chain은 ‘AI 플랫폼 공급업체 → AI 어플리케이션 개발 → AI 응용솔루션 개발 → 이용자’로 구성되며, 동 산업은 ①성장기 산업, ②대체재로부터의 위협이 낮은 산업, ③기술집약적 산업 등의 특징을 가짐○알고리즘, 하드웨어 기술개발과 응용솔루션 서비스 상용화가 활발히 진행 중인 성장기 산업이며, 수요 기업의 요구사항에 따라 운영플랫폼을 선택할 수 있는 구매자의 교섭력이 높은 산업임○직접적인 대체 기술이 없어 대체재로부터 위협이 낮은 편이며, 알고리즘의 동작원리를 이해하고 맞춤형 서비스를 지원하기 위한 솔루션 개발 능력이 뒷받침 되어야 하는 기술집약적 산업임▶시장조사전문기관 BCC research에 따르면 세계 인공지능 시장규모는 2020년 398.4억 달러에서 연평균 41.0% 성장하여 2025년에는 2,223.7억 달러의 시장을 형성할 것으로 전망됨○세부 솔루션 분문별로는 2020년 기준
{'source': '/content/drive/MyDrive/NLP톺아보기/file/[이슈리포트 2022-2호] 혁신성장 정책금융 동향.pdf', 'page': 9}
----------------------------------------------------------------------------------------------------
2번째 유사 문서:
----------------------------------------------------------------------------------------------------
주: 스마트물류시스템 품목은 2021년부터 신규 품목으로 편임▶인공지능은 인간의 학습능력과 추론·지각능력, 자연언어 이해능력 등을 프로그램으로 구현한 기술로, 컴퓨터가 인간의 지능적인 행동을 모방하는 방향으로 발전하고 있음○인공지능은 사람의 두뇌가 복잡한 연산을 수행하는 점을 모방해 뉴런(Neuron)을 수학적으로 모방한 알고리즘인 퍼셉트론(Perceptron)을 이용하여 컴퓨터의 연산 로직을 처리하는 원리로 동작함[인공지능 동작 개념]구분 구조뉴런Ÿ세포체의 자극이 임계치를 넘으면 신경전달물질 발화
인공지능(퍼셉트론)Ÿ활성함수의 계산 결과를 출력
자료: 디지에코
{'source': '/content/drive/MyDrive/NLP톺아보기/file/[이슈리포트 2022-2호] 혁신성장 정책금융 동향.pdf', 'page': 7}
----------------------------------------------------------------------------------------------------
3번째 유사 문서:
----------------------------------------------------------------------------------------------------
▶다양한 데이터나 복잡한 자료 속에서 핵심적인 특징을 요약하는 ①데이터 추상화 기술, 방대한 지식체계를 이용하는 ②빅데이터 기술, 빅데이터를 처리하기 위한 ③고성능 컴퓨팅 기술이 인공지능 구현의 핵심임○데이터를 추상화하는 방법은 크게 인공신경망(ANN), 심층신경망(DNN), 합성곱신경망(CNN) 및 순환신경망(RNN) 등으로 구분됨[인공지능 데이터 추상화 기술]구분특징장점단점인공신경망(ANN)Artificial Neural Network사람의 신경망 원리와 구조를 모방하여 만든 기계학습 알고리즘으로, 입력층, 출력층, 은닉층으로 구성 모든 비선형 함수 학습이 가능알고리즘을 최적화하기 어려운 학습 환경 발생심층신경망(DNN)Deep Neural Network입력층과 출력층 사이에 2개 이상의 은닉층들로 이뤄진 인공신경망ANN의 문제점 개선학습환경에 따라 높은 시간 복잡도 문제 발생합성곱신경망(CNN)Convolution Neural Network데이터의 특징을 추출하여 특징들의 패턴을 파악하는 인공신경망이미지, 영상 데이터 판별에 강점특징추출 과정에서 정보손실 발생순환신경망(RNN)Recurrent Neural
{'source': '/content/drive/MyDrive/NLP톺아보기/file/[이슈리포트 2022-2호] 혁신성장 정책금융 동향.pdf', 'page': 8}
----------------------------------------------------------------------------------------------------LLM 챗봇, 랭체인의 핵심 Retriever
Chain 종류 4가지
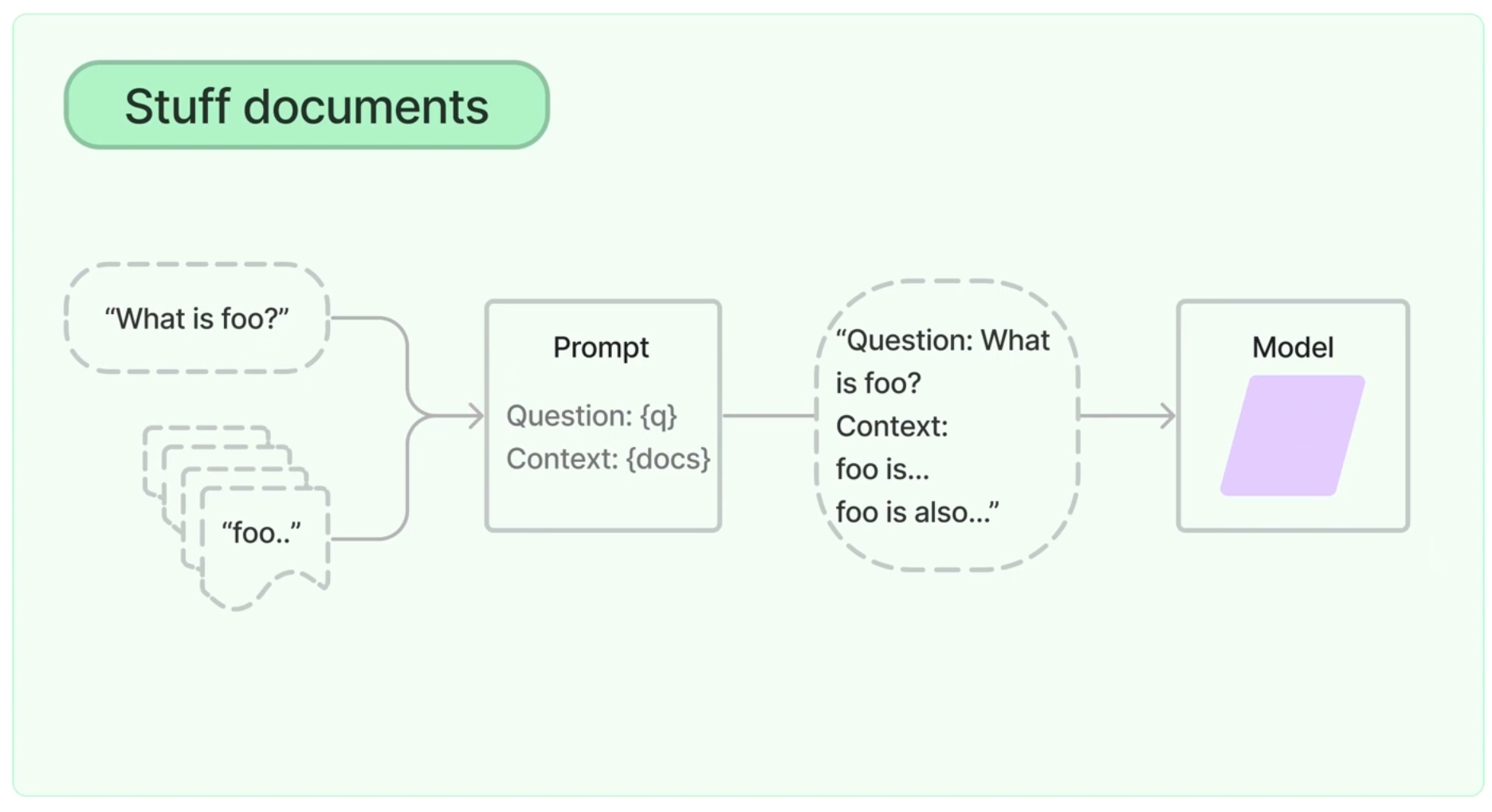
Stuff
- 분할된 텍스트 청크를 Context에 그대로 주입
- 토큰 이슈 발생 우려(주의)
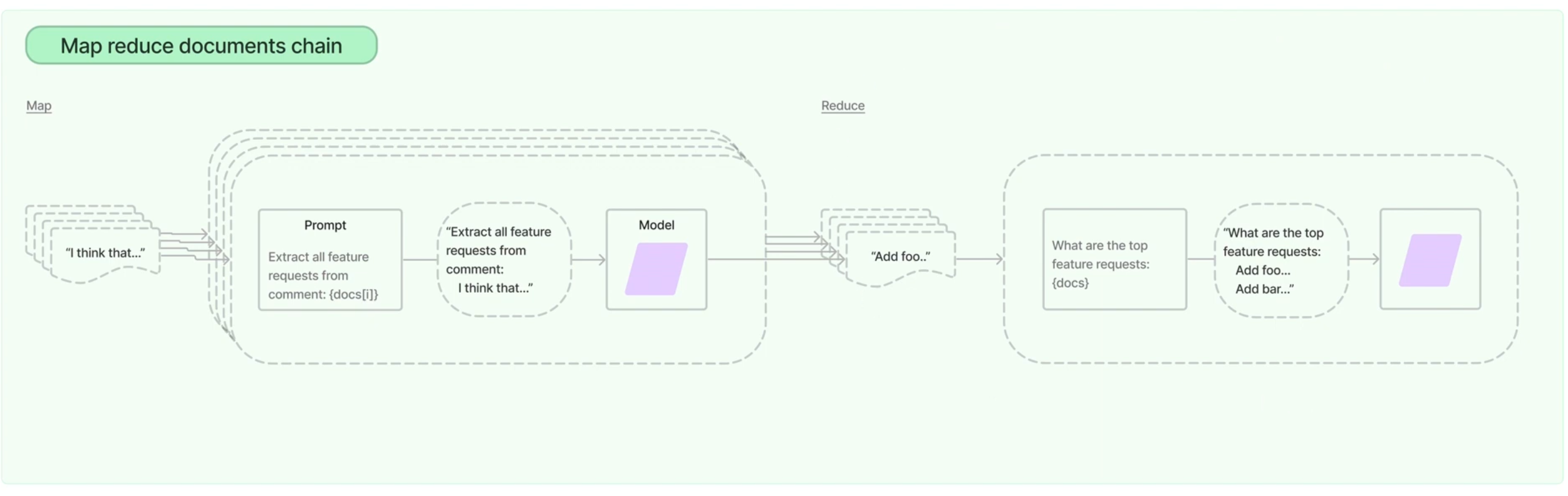
Map_reduce
- 분할된 텍스트 청크마다 요약 생성
- 요약을 합친 최종 요약을 생성하기 위해 다수 호출이 필요
- 속도 느림
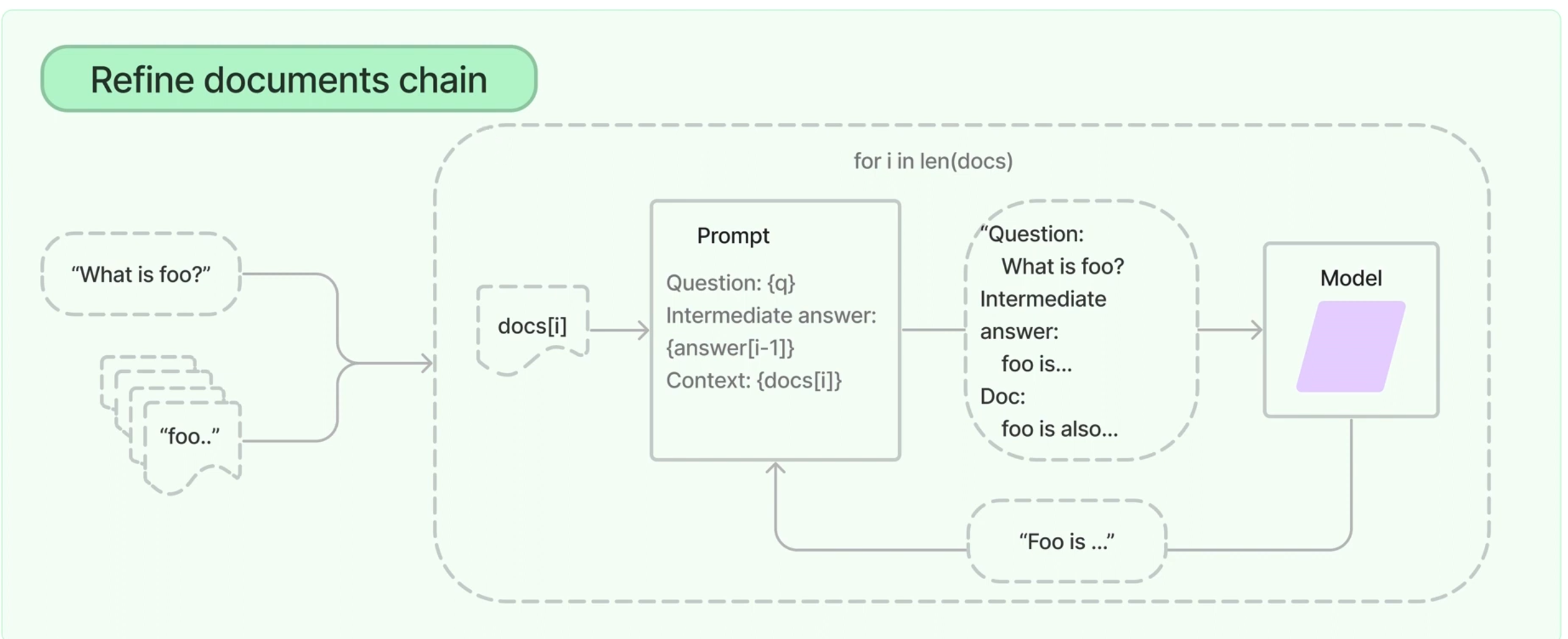
Refine
- 좋은 품질의 답변을 얻기 위해 사용
- 분할된 텍스트 청크를 순회하며 누적 답변 생성
- 품질은 뛰어나나, 시간이 오래걸리는 문제가 있음
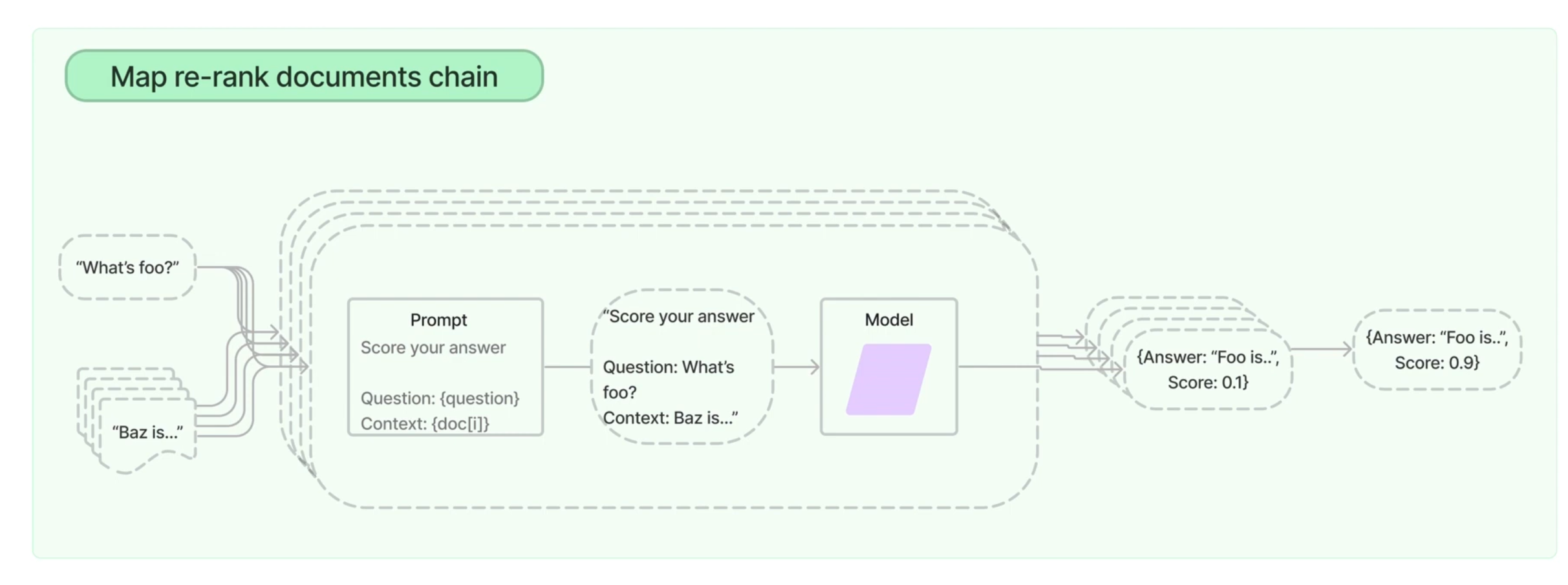
Map_rerank
- 분할된 텍스트 청크를 순회하며 누적 답변 생성
- 품질 뛰어나지만, 시간이 오래 걸림
실습: Retriever
실습 코드 : Retriever.ipynb
1. RetrievalQA
- tiktoken 설정
import tiktoken
tokenizer = tiktoken.get_encoding("cl100k_base")
def tiktoken_len(text):
tokens = tokenizer.encode(text)
return len(tokens)- 라이브러리 import
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.document_loaders import PyPDFLoader- 임베딩 모델
loader = PyPDFLoader("/content/drive/MyDrive/NLP톺아보기/file/[이슈리포트 2022-2호] 혁신성장 정책금융 동향.pdf")
pages = loader.load_and_split()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50, length_function = tiktoken_len)
texts = text_splitter.split_documents(pages)
from langchain.embeddings import HuggingFaceEmbeddings
model_name = "jhgan/ko-sbert-nli"
model_kwargs = {'device': 'cpu'}
encode_kwargs = {'normalize_embeddings': True}
hf = HuggingFaceEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs
)
docssearch = Chroma.from_documents(texts, hf)
- MMR 검색 방식 활용
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
openai = ChatOpenAI(model_name="gpt-3.5-turbo",
streaming=True, callbacks=[StreamingStdOutCallbackHandler()],
temperature = 0)
qa = RetrievalQA.from_chain_type(llm = openai,
chain_type = "stuff",
retriever = docssearch.as_retriever(
search_type="mmr",
search_kwargs={'k':3, 'fetch_k': 10}),
return_source_documents = True)
query = "혁신성장 정책금융에 대해서 설명해줘"
result = qa(query)혁신성장 정책금융은 기업 성장을 지원하고 건강한 혁신산업 생태계를 조성하기 위해 정부나 정책금융기관이 제공하는 금융 지원 제도를 말합니다. 이를 통해 혁신성장을 이루고 있는 기업들이 자금을 지원받아 더욱 발전하고 성장할 수 있도록 돕습니다. 이러한 정책금융은 혁신성장을 위한 정책금융 가이드라인에 따라 운영되며, 특정 테마와 분야, 품목을 중심으로 지원이 이루어집니다. 최근에는 ICT 산업을 중심으로 혁신성장 정책금융이 활발히 이루어지고 있습니다.2. Retriever의 기본형, 벡터DB 기반 Retriever
- Chroma 벡터 DB 기반 기본 유사 문서 검색
from langchain.document_loaders import PyPDFLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
from langchain_chroma import Chroma
import os
import openai
from google.colab import userdata
Chroma().delete_collection()
openai.api_key = userdata.get('OPENAI_API_KEY')
#헌법 PDF 파일 로드
loader = PyPDFLoader(r"/content/drive/MyDrive/NLP톺아보기/file/대한민국헌법(헌법)(제00010호)(19880225).pdf")
pages = loader.load_and_split()
#PDF 파일을 500자 청크로 분할
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
docs = text_splitter.split_documents(pages)
#ChromaDB에 청크들을 벡터 임베딩으로 저장(OpenAI 임베딩 모델 활용)
db = Chroma.from_documents(docs, OpenAIEmbeddings(model = 'text-embedding-3-small'))
#Chroma를 Retriever로 활용
retriever = db.as_retriever()
retriever.invoke("국회의원의 의무")
- 유사도 점수 함께 출력
result_score = db.similarity_search_with_score("국회의원의 의무")
result_r_score = db.similarity_search_with_relevance_scores("국회의원의 의무")
print("[유사 청크 1순위]")
print(result_score[0][0].page_content)
print("\n\n[점수]")
print(result_score[0][1])
print(result_r_score[0][1])
- 유사 청크 1개만 반환
retriever = db.as_retriever(search_kwargs={"k": 1})
retriever.invoke("국회의원의 의무")
- MMR 검색 방식
from langchain.document_loaders import PyPDFLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
from langchain_chroma import Chroma
#헌법 PDF 파일 로드
loader = PyPDFLoader(r"/content/drive/MyDrive/NLP톺아보기/file/대한민국헌법(헌법)(제00010호)(19880225).pdf")
pages = loader.load_and_split()
#PDF 파일을 500자 청크로 분할
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
docs = text_splitter.split_documents(pages)
#ChromaDB에 청크들을 벡터 임베딩으로 저장(OpenAI 임베딩 모델 활용)
db = Chroma.from_documents(docs, OpenAIEmbeddings(model = 'text-embedding-3-small'))#Chroma를 Retriever로 활용
retriever = db.as_retriever(
search_type="mmr",
search_kwargs = {"lambda_mult": 0, "fetch_k":10, "k":3}
)
retriever.invoke("국회의원의 의무")
- 일반 유사도 검색
retriever = db.as_retriever(search_kwargs = {"k":3})
retriever.get_relevant_documents("국회의원의 의무")
3. MultiQueryRetriever
- 사용자의 쿼리를 재해석하여 검색
- Chroma DB에 문서 벡터 저장
from langchain.document_loaders import PyPDFLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
from langchain_chroma import Chroma
#헌법 PDF 파일 로드
loader = PyPDFLoader(r"/content/drive/MyDrive/NLP톺아보기/file/대한민국헌법(헌법)(제00010호)(19880225).pdf")
pages = loader.load_and_split()
#PDF 파일을 500자 청크로 분할
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
docs = text_splitter.split_documents(pages)
#ChromaDB에 청크들을 벡터 임베딩으로 저장(OpenAI 임베딩 모델 활용)
db = Chroma.from_documents(docs, OpenAIEmbeddings(model = 'text-embedding-3-small'))- 질문을 여러 버전으로 재해석
from langchain.retrievers.multi_query import MultiQueryRetriever
from langchain_openai import ChatOpenAI
#질문 문장 question으로 저장
question = "국회의원의 의무는 무엇이 있나요?"
#여러 버전의 질문으로 변환하는 역할을 맡을 LLM 선언
llm = ChatOpenAI(model_name="gpt-4o-mini",
temperature = 0)
#MultiQueryRetriever에 벡터DB 기반 Retriever와 LLM 선언
retriever_from_llm = MultiQueryRetriever.from_llm(
retriever=db.as_retriever(), llm=llm
)
# 여러 버전의 문장 생성 결과를 확인하기 위한 로깅 과정
import logging
logging.basicConfig()
logging.getLogger("langchain.retrievers.multi_query").setLevel(logging.INFO)
#여러 버전 질문 생성 결과와 유사 청크 검색 개수 출력
unique_docs = retriever_from_llm.invoke(input=question)
len(unique_docs)
4. MultiVectorRetriever
- 문서를 여러 벡터로 재해석
- Chroma DB에 문서 벡터 저장
from langchain.retrievers.multi_vector import MultiVectorRetriever
from langchain.storage import InMemoryByteStore
from langchain_chroma import Chroma
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain.document_loaders import PyPDFLoader
loaders = PyPDFLoader(r"/content/drive/MyDrive/NLP톺아보기/file/대한민국헌법(헌법)(제00010호)(19880225).pdf"),
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=2000)
docs = text_splitter.split_documents(docs)- Multi Vector 생성
InMemoryByteStore(): 상위 문서 저장을 위한 레이어- 상위 문서와 하위 문서를 연결할 키값으로 doc_id 사용
uuid: 문서 id로 고유한 값을 지정
from langchain.embeddings import HuggingFaceEmbeddings
model_name = "jhgan/ko-sbert-nli"
model_kwargs = {'device': 'cpu'}
encode_kwargs = {'normalize_embeddings': True}
embedding = HuggingFaceEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs
)
vectorstore = Chroma(
collection_name="full_documents", embedding_function=embedding
)
store = InMemoryByteStore()
id_key = "doc_id"
retriever = MultiVectorRetriever(
vectorstore=vectorstore,
byte_store=store,
id_key=id_key,
)
import uuid
doc_ids = [str(uuid.uuid4()) for _ in docs]child_text_splitter: 하위 청크로 쪼개기 위함- 상위 청크들을 순회하며 하위 청크로 분할한 후 상위 청크 id 상속
vectorstore.add_documents(sub_docs): vectorstore에 하위 청크 추가- docstore에 상위청크 저장할 때, doc_ids 지정
child_text_splitter = RecursiveCharacterTextSplitter(chunk_size=400)
sub_docs = []
for i, doc in enumerate(docs):
_id = doc_ids[i]
_sub_docs = child_text_splitter.split_documents([doc])
for _doc in _sub_docs:
_doc.metadata[id_key] = _id
sub_docs.extend(_sub_docs)
retriever.vectorstore.add_documents(sub_docs)
retriever.docstore.mset(list(zip(doc_ids, docs)))- 하위 청크 및 상위 청크 출력
print("[하위 청크] \n")
print(retriever.vectorstore.similarity_search("국민의 권리")[0].page_content)
print("-"*50)
print("[상위 청크] \n")
print(retriever.invoke("국민의 권리")[0].page_content)[하위 청크]
③공공필요에 의한 재산권의 수용ㆍ사용 또는 제한 및 그에 대한 보상은 법률로써 하되, 정당한 보상을 지급하여야
한다.
제24조 모든 국민은 법률이 정하는 바에 의하여 선거권을 가진다.
제25조 모든 국민은 법률이 정하는 바에 의하여 공무담임권을 가진다.
제26조 ①모든 국민은 법률이 정하는 바에 의하여 국가기관에 문서로 청원할 권리를 가진다.
②국가는 청원에 대하여 심사할 의무를 진다.
제27조 ①모든 국민은 헌법과 법률이 정한 법관에 의하여 법률에 의한 재판을 받을 권리를 가진다.
②군인 또는 군무원이 아닌 국민은 대한민국의 영역 안에서는 중대한 군사상 기밀ㆍ초병ㆍ초소ㆍ유독음식물공급
ㆍ포로ㆍ군용물에 관한 죄중 법률이 정한 경우와 비상계엄이 선포된 경우를 제외하고는 군사법원의 재판을 받지
--------------------------------------------------
[상위 청크]
법제처 3 국가법령정보센터
대한민국헌법
제21조 ①모든 국민은 언론ㆍ출판의 자유와 집회ㆍ결사의 자유를 가진다.
②언론ㆍ출판에 대한 허가나 검열과 집회ㆍ결사에 대한 허가는 인정되지 아니한다.
③통신ㆍ방송의 시설기준과 신문의 기능을 보장하기 위하여 필요한 사항은 법률로 정한다.
④언론ㆍ출판은 타인의 명예나 권리 또는 공중도덕이나 사회윤리를 침해하여서는 아니된다. 언론ㆍ출판이 타인의
명예나 권리를 침해한 때에는 피해자는 이에 대한 피해의 배상을 청구할 수 있다.
제22조 ①모든 국민은 학문과 예술의 자유를 가진다.
②저작자ㆍ발명가ㆍ과학기술자와 예술가의 권리는 법률로써 보호한다.
제23조 ①모든 국민의 재산권은 보장된다. 그 내용과 한계는 법률로 정한다.
②재산권의 행사는 공공복리에 적합하도록 하여야 한다.
③공공필요에 의한 재산권의 수용ㆍ사용 또는 제한 및 그에 대한 보상은 법률로써 하되, 정당한 보상을 지급하여야
한다.
제24조 모든 국민은 법률이 정하는 바에 의하여 선거권을 가진다.
제25조 모든 국민은 법률이 정하는 바에 의하여 공무담임권을 가진다.
제26조 ①모든 국민은 법률이 정하는 바에 의하여 국가기관에 문서로 청원할 권리를 가진다.
②국가는 청원에 대하여 심사할 의무를 진다.
제27조 ①모든 국민은 헌법과 법률이 정한 법관에 의하여 법률에 의한 재판을 받을 권리를 가진다.
②군인 또는 군무원이 아닌 국민은 대한민국의 영역 안에서는 중대한 군사상 기밀ㆍ초병ㆍ초소ㆍ유독음식물공급
ㆍ포로ㆍ군용물에 관한 죄중 법률이 정한 경우와 비상계엄이 선포된 경우를 제외하고는 군사법원의 재판을 받지
아니한다.
③모든 국민은 신속한 재판을 받을 권리를 가진다. 형사피고인은 상당한 이유가 없는 한 지체없이 공개재판을 받을
권리를 가진다.
④형사피고인은 유죄의 판결이 확정될 때까지는 무죄로 추정된다.
⑤형사피해자는 법률이 정하는 바에 의하여 당해 사건의 재판절차에서 진술할 수 있다.
제28조 형사피의자 또는 형사피고인으로서 구금되었던 자가 법률이 정하는 불기소처분을 받거나 무죄판결을 받은 때
에는 법률이 정하는 바에 의하여 국가에 정당한 보상을 청구할 수 있다.
제29조 ①공무원의 직무상 불법행위로 손해를 받은 국민은 법률이 정하는 바에 의하여 국가 또는 공공단체에 정당한
배상을 청구할 수 있다. 이 경우 공무원 자신의 책임은 면제되지 아니한다.
②군인ㆍ군무원ㆍ경찰공무원 기타 법률이 정하는 자가 전투ㆍ훈련등 직무집행과 관련하여 받은 손해에 대하여는
법률이 정하는 보상 외에 국가 또는 공공단체에 공무원의 직무상 불법행위로 인한 배상은 청구할 수 없다.
제30조 타인의 범죄행위로 인하여 생명ㆍ신체에 대한 피해를 받은 국민은 법률이 정하는 바에 의하여 국가로부터 구조
를 받을 수 있다.
제31조 ①모든 국민은 능력에 따라 균등하게 교육을 받을 권리를 가진다.
②모든 국민은 그 보호하는 자녀에게 적어도 초등교육과 법률이 정하는 교육을 받게 할 의무를 진다.
③의무교육은 무상으로 한다.
④교육의 자주성ㆍ전문성ㆍ정치적 중립성 및 대학의 자율성은 법률이 정하는 바에 의하여 보장된다.
⑤국가는 평생교육을 진흥하여야 한다.
⑥학교교육 및 평생교육을 포함한 교육제도와 그 운영, 교육재정 및 교원의 지위에 관한 기본적인 사항은 법률로 정
한다.5. Long-Context Reorder
- 컨텍스트 재정렬
- Long-Context Reorder 없이 유사 문서 출력
from langchain.chains import LLMChain, StuffDocumentsChain
from langchain_chroma import Chroma
from langchain.document_transformers import (
LongContextReorder,
)
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.prompts import PromptTemplate
from langchain_openai import OpenAI
Chroma().delete_collection()
# 한글 임베딩 모델 선언
model_name = "jhgan/ko-sbert-nli"
model_kwargs = {'device': 'cpu'}
encode_kwargs = {'normalize_embeddings': True}
embedding = HuggingFaceEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs
)
texts = [
"바스켓볼은 훌륭한 스포츠입니다.",
"플라이 미 투 더 문은 제가 가장 좋아하는 노래 중 하나입니다.",
"셀틱스는 제가 가장 좋아하는 팀입니다.",
"이것은 보스턴 셀틱스에 관한 문서입니다."
"저는 단순히 영화 보러 가는 것을 좋아합니다",
"보스턴 셀틱스가 20점차로 이겼어요",
"이것은 그냥 임의의 텍스트입니다.",
"엘든 링은 지난 15 년 동안 최고의 게임 중 하나입니다.",
"L. 코넷은 최고의 셀틱스 선수 중 한 명입니다.",
"래리 버드는 상징적인 NBA 선수였습니다.",
]
# Chroma Retriever 선언(10개의 유사 문서 출력)
retriever = Chroma.from_texts(texts, embedding=embedding).as_retriever(
search_kwargs={"k": 10}
)
query = "셀틱에 대해 설명해줘"
# 유사도 기준으로 검색 결과 출력
docs = retriever.invoke(query)
docs
- Long-Context Reorder 활용하여 유사 문서 출력
- 검색된 유사문서 중 관련도가 높은 문서를 맨앞과 맨뒤에 재정배치
reordering = LongContextReorder()
reordered_docs = reordering.transform_documents(docs)
reordered_docs

언젠가 내 코드로 세상에 기여할 수 있도록, Data Science&BE 개발 기록 노트☘️