Node 06. MLOps 프로젝트
AIFFELMLOps 프로젝트mlops관리데싸데싸 3기데이터 사이언스데이터 웨어하우스데이터사이언티스트데이터사이언티스트 3기모니터링모델모델 성능 평가모델 운영배포 파이프라인성능성능 평가아이펠통합 파이프라인
☺️ AIFFEL 데이터사이언티스트 3기
목록 보기
114/115

이미지 출처는 링크 or 아이펠 교육 자료입니다.
6-1. 프로젝트 개요 및 환경 설정
프로젝트 주제
Netflix 점수 예측 문제
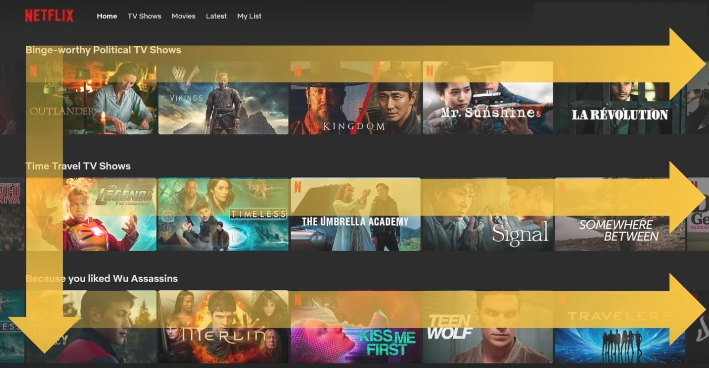
- 추천 시스템 동작 방식
왼쪽 ➡️ 오른쪽: 가장 관심사일 것으로 예측되는 경우의 작품을 가장 왼쪽에 배치위 ➡️ 아래: 시리즈 중 가장 관심 있을만한 시리즈를 가장 상단에 배치이미지: 이미지도 추천을 해줌!- 추천 시스템의 동작에 따라 여러 썸네일 중 1개를 골라 추천
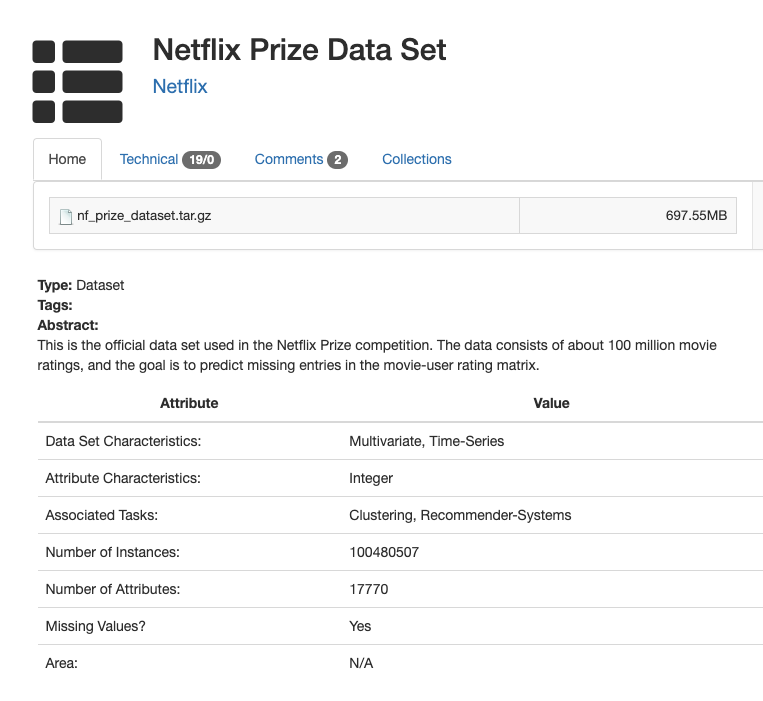
Netflix 리뷰 점수 예측 데이터셋
- Netflix Prize Data Set
- 시계열 데이터
- 항목 수 : 100,480,507
- 영화 항목 수 : 17,770 movies
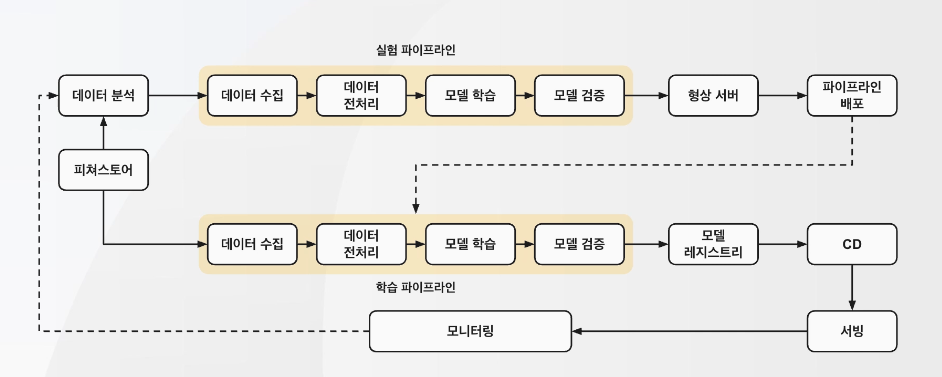
MLOps Level 1 파이프라인
- 실제 구성
- 정해진 아키텍쳐가 있는 것이 아니니, 파이프라인을 고민해보는 것도 방법!
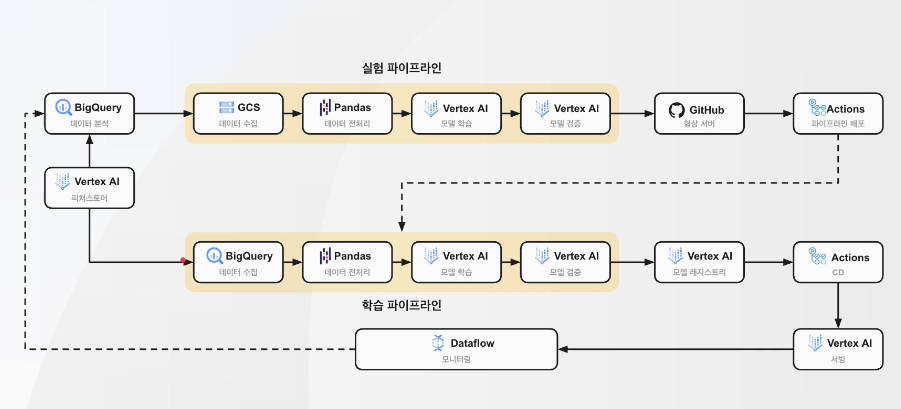
- 정해진 아키텍쳐가 있는 것이 아니니, 파이프라인을 고민해보는 것도 방법!
배포 파이프라인 자동화
- 이전에는 로컬에서 모델 학습을 마친 다음, GCP에 올렸던 형태
- 이번에는 GCP에서 모델 학습부터 할 수 있도록 구성 예정
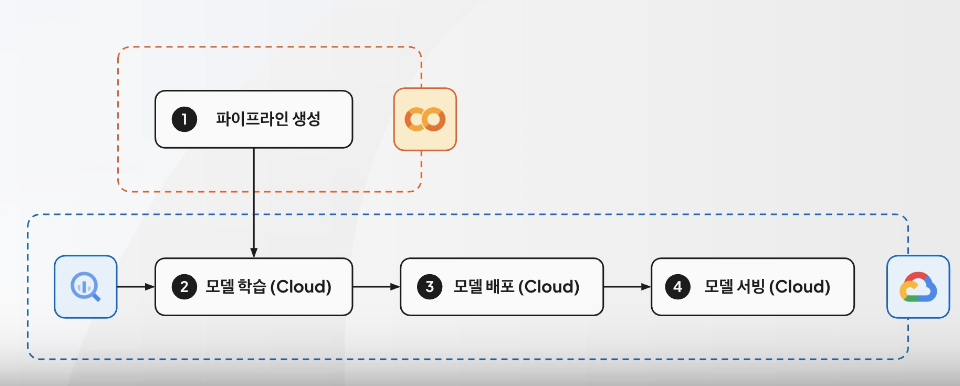
- 이번에는 GCP에서 모델 학습부터 할 수 있도록 구성 예정
Kaggle 토큰 발급
참고 자료 : Kaggle API 사용법
- https://kaggle.com
- kaggle > settings > Account에서
API부분의Create New Token클릭하여 발급
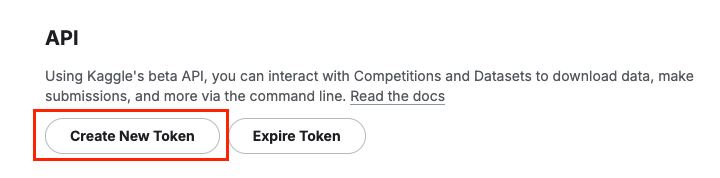
- kaggle > settings > Account에서
데이터셋 다운로드
Colab 사용 설정(GCP)
-
GCP에서 설정함:
market place검색 >colab검색

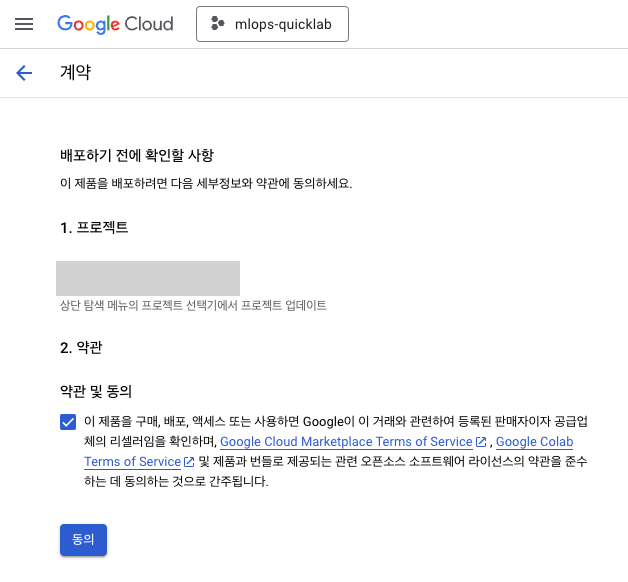
-
필요한 API 사용 설정:
사용 설정클릭하여 설정

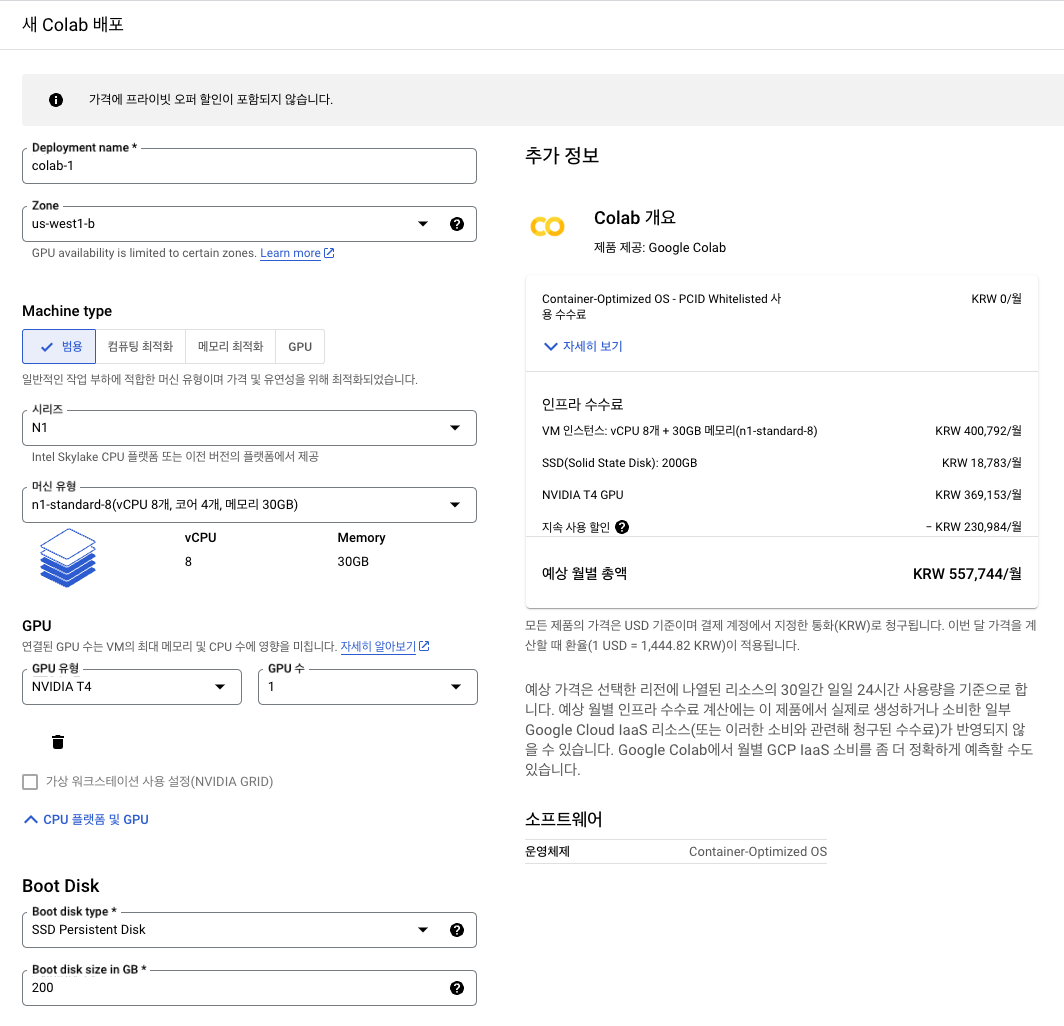
- 새 Colab 배포
- 리전:
us-west4-a - Machine type
- N1
n1-standard-8(vCPU 8개, 코어 4개, 메모리 30GB)
- GPU:
NVIDIA T4
(사진과 상이함, Zone 변경으로 인해 부득이하게 사진 캡쳐 못함)
- 리전:
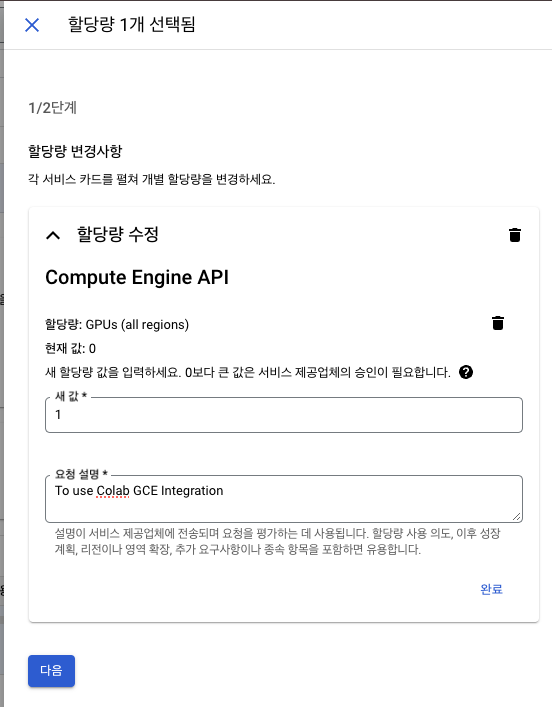
"GPU 글로벌 할당량에서 GPU 1개를 초과했습니다" 경고 해결 방법 ➡️ 유료 계정 활성화 필요!
- "할당량 페이지" 클릭
- 현재 할당량이 0으로 설정되어 있어 발생하는 문제이므로, 1로 늘리기
- 그러나, 유료 계정이 아니면 할당량 조정이 되지 않기 때문에 유료 계정으로 전환
- 활성화 후 조정이 가능해짐





- 배포 완료
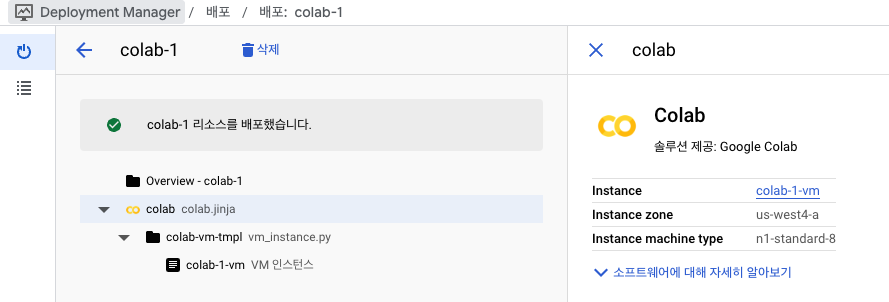

Colab 사용 설정
- 실습 코랩 페이지에서 런타임 연결 >
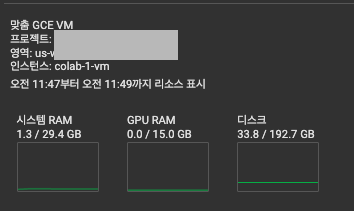
맞춤 GCE VM에 연결- 본인이 설정한 프로젝트 + 영역 + 인스턴스 이름 기입
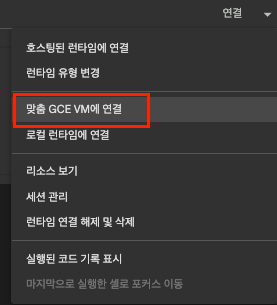
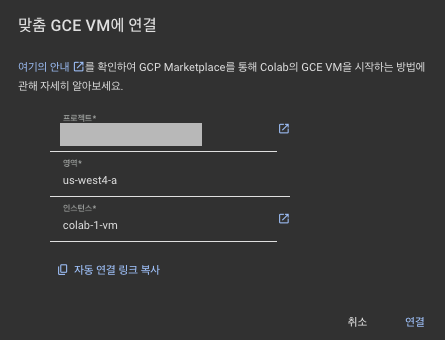
- 본인이 설정한 프로젝트 + 영역 + 인스턴스 이름 기입
- 연결 완료
6-2. 예제 실습:배포 파이프라인_파트1
Colab에서 Kaggle 접근 정보 설정
- 보안 비밀 부분에서 kaggle 키 및 유저 네임 설정하기
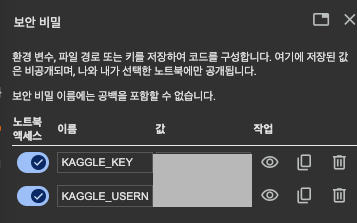
- 연결 완료

데이터셋 다운로드
!pip install kaggle
!kaggle datasets download -d netflix-inc/netflix-prize-data
!unzip "netflix-prize-data.zip" -d netflix-prize-data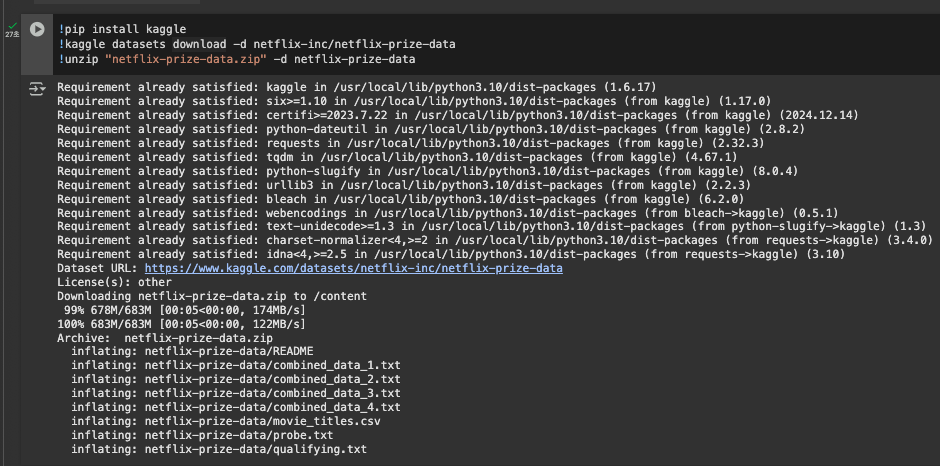
- 데이터셋 확인
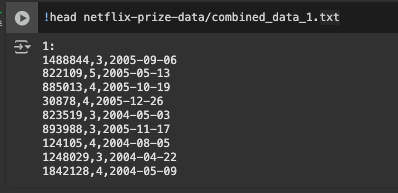
⭐️ 데이터셋 전처리 ⭐️
- 전체 데이터셋을 기준으로 돌리면 Epoch당 6시간에 달하는 시간 요구
- Epoch당 10분 내외로 조절
- User 기준 30분의 1 수준으로 샘플링(사용자 수를 줄이는 것)
모델 정의 함수 작성
- Rating를 GT 데이터로 사용해 예측
NetflixDataset: 데이터셋 로더 정의
- 데이터를 시계열로 처리하기 위한 과정
- User를 기준으로 데이터 Group을 만들어 시퀀싱
- 정렬: 날짜 기준
트랜스포머 기반 모델 아키텍쳐 함수 작성
- 평가 지표는
MSE로 설정 - 트랜스포머 모델 인코더 응용
데이터셋 로드
- 일정 시간 소요됨(약 2분)
data_dir = "netflix-prize-data"
data = load_netflix_data(data_dir)데이터 로더 구성 함수 사용해 실제 구성하기
dataset = NetflixDataset(data)
data_loader = DataLoader(dataset, batch_size=512, shuffle=True)
전체 데이터셋을 이용해 기본 설정
- 파라미터 설정
num_movies = data["Movie_Id"].max()
model = RecommendationNetwork(num_movies=num_movies, emb_size=100).to(device)
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)정확도 계산 함수 설정
def calculate_accuracy(y_pred: torch.Tensor, y_true: torch.Tensor) -> float:
# 평점 반올림 -> 정확도 계산(정수 평점 가정)
y_pred_rounded = torch.round(y_pred)
correct_predictions = (y_pred_rounded == y_true).float().sum()
accuracy = correct_predictions / y_true.shape[0]
return accuracy.item()Loss 값 설정 및 모델 학습 실행
- Epoch은 5로 설정
- 1개의 Epoch당 약 6분 소요 -> 30분 정도 기다려야 함!
loss_values: list[float] = []
accuracy_values: list[float] = []
num_epochs = 5
for epoch in range(num_epochs):
model.train()
total_loss = 0.0
total_accuracy = 0.0
count_batches = 0
for movies, ratings in tqdm(data_loader):
movies = movies.to(device)
ratings = ratings.to(device)
target = ratings[:, -1]
optimizer.zero_grad()
outputs = model(movies)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
accuracy = calculate_accuracy(outputs, target)
total_loss += loss.item()
total_accuracy += accuracy
count_batches += 1
avg_loss = total_loss / count_batches
avg_accuracy = total_accuracy / count_batches
loss_values.append(avg_loss)
accuracy_values.append(avg_accuracy)
print(f"Epoch {epoch+1}: Loss = {avg_loss}, Accuracy = {avg_accuracy}")
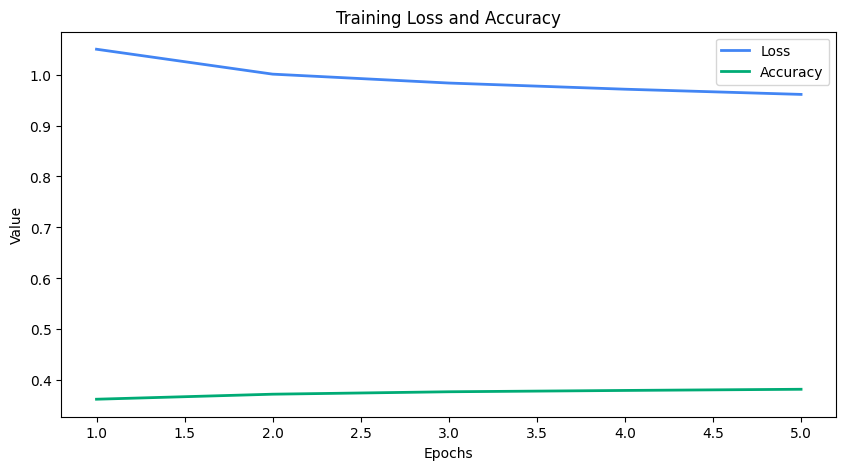
- 모델 학습 완료
- 데이터셋 자체가 크다 보니, loss 값이 줄긴 하지만 유의미하게 줄어들지는 않는 양상
- Accuracy도 우상향하는 경향성을 보이지만 좋은 성능은 아님
GPU 추가 할당량 설정(권장)
GPUs,NVIDIA T4 GPUs를 3정도로 늘리는 것을 추천
- 우선은 1로 진행
Netflix 추천 모델 구성
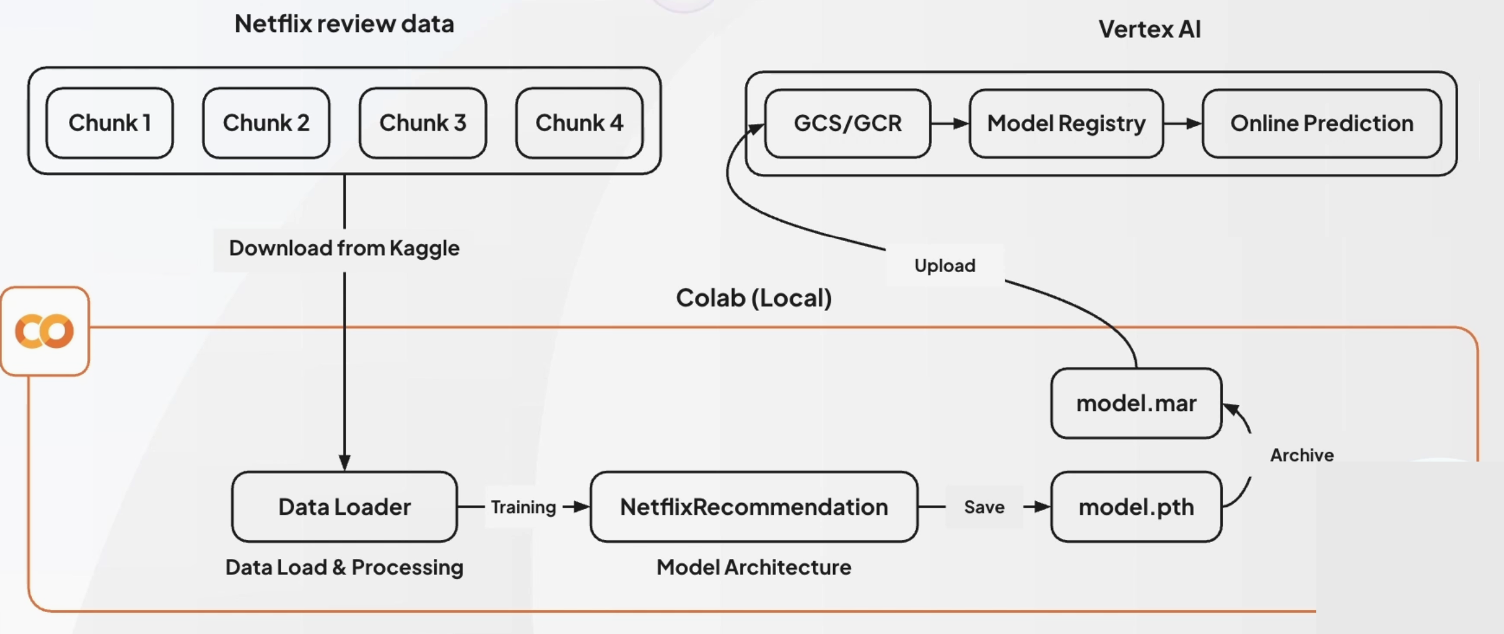
-
Nexflix review data
-
Data Loader- 1/30로 샘플링
- Customer ID 기준으로 리맵핑하여 타임스탬프 기준으로 정렬
- 시퀀스 데이터로의 변환
-
NetflixRecommendation- 위에서 구성한 모델 아키텍쳐를 바탕으로 학습(Epochs 5, 약 30분 소요)
- model.pth가 나오게 될 것
-
model.mar- 모델 서빙을 위한 최종 패키징 파일
-
vertex AI- 구글 클라우드에 올려 모델 레지스트리 등록을 하면 Online Prediction이 가능해짐
Netflix 추천 방식 및 구조
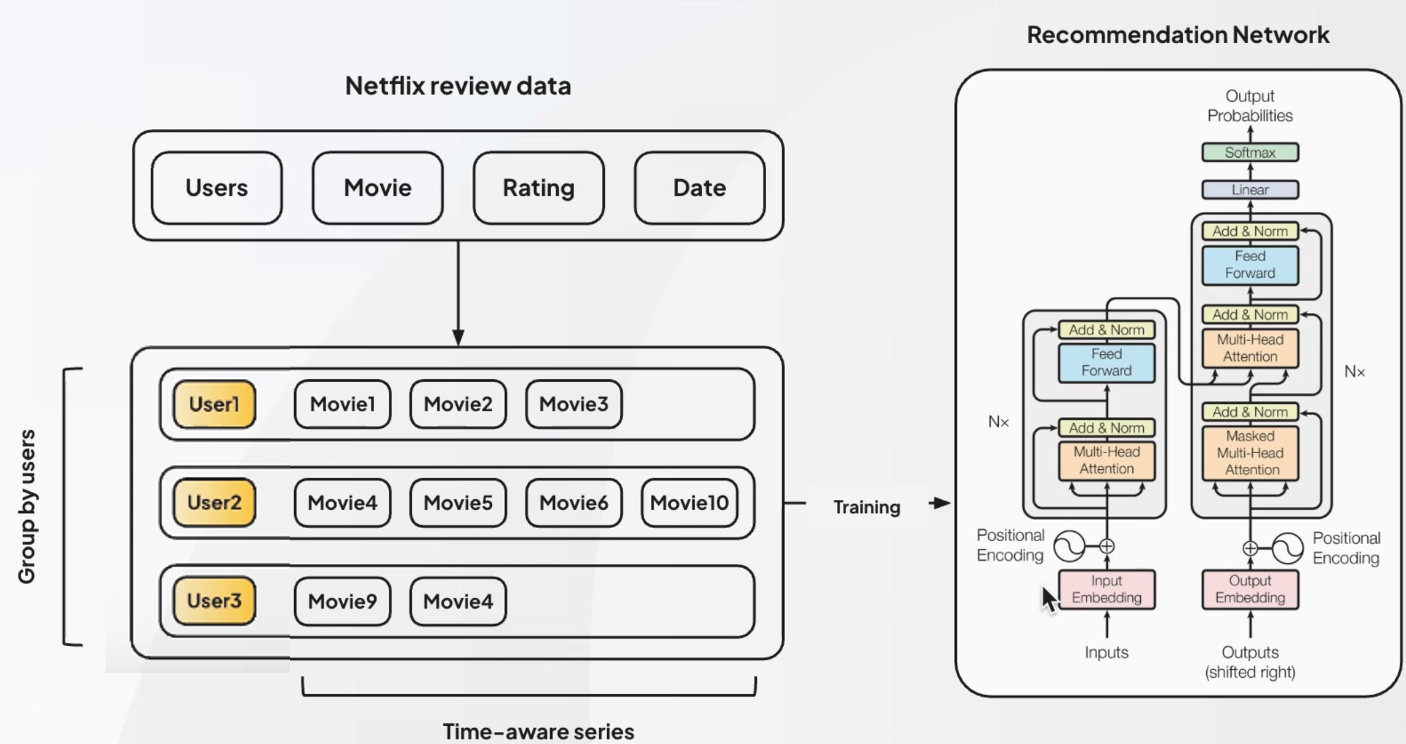
- 주요 Feature 4가지:
Users,Movie,Rating,Date - 추천 네트워크: 인코더와 디코더로 구성
인퍼런스
writefile model.py
writefile handler.py

model.pth 저장
torch.save(model.state_dict(), "model.pth")
가상 Context 생성하여 핸들러 테스트
- 가상 Context 생성
- TorchServe의 context를 모사한 형태임
class Context:
def __init__(self):
self.system_properties = {
"model_dir": "."
}
context = Context()- 모델 아카이버 다운
!pip install torchserve torch-model-archiverPredicted Rating 테스트
from handler import NetflixRecommendation
netflix_recommendation = NetflixRecommendation()
netflix_recommendation.initialize(Context())
sample_input = {"movies": [123, 456, 789, 100, 101, 102, 103, 104, 105, 106]}
preprocessed = netflix_recommendation.preprocess([[sample_input]])
predicted_rating = netflix_recommendation.inference(preprocessed)
result = netflix_recommendation.postprocess(predicted_rating)
print(f"Predicted Rating: {result}")
6-3. 예제 실습:배포 파이프라인_파트2
Vertex AI에 Register
!torch-model-archiver \
--model-name model \
--version 1.0 \
--model-file model.py \
--serialized-file model.pth \
--handler handler.py \
--export-path . \
--force- config.properties 설정
%%writefile config.properties
inference_address=http://0.0.0.0:9080
management_address=http://0.0.0.0:9081
metrics_address=http://0.0.0.0:9082
disable_system_metrics=true
number_of_netty_threads=32
job_queue_size=1000
model_store=/home/model-server/model-store- GCP 연결
from google.cloud import storage, aiplatform
from google.oauth2 import service_account- 서비스 계정 키 발급 후 사용
credentials = service_account.Credentials.from_service_account_file("credentials.json")- 기본 정보 기입 및 스토리지, 버킷 함수 설정
storage_client = storage.Client(credentials=credentials)
bucket = storage_client.bucket(BUCKET_NAME)- 초기화 함수 설정
aiplatform.init(
project=PROJECT_ID,
location=LOCATION,
credentials=credentials,
)- serving_container_image_uri 설정
model_path = f"gs://{BUCKET_NAME}/models"
registry_model = aiplatform.Model.upload(
display_name="Netflix Recommender",
artifact_uri=model_path,
serving_container_image_uri="{}/trainer:1.0.0",
is_default_version=True,
version_aliases=["v1"],
version_description="A netflix rating classification model",
serving_container_predict_route="/predictions/model",
serving_container_health_route="/ping",
)Deploy
- compute, accelerator 지정
DEPLOY_COMPUTE = "n1-standard-2"
DEPLOY_ACCELERATOR = "NVIDIA_TESLA_T4"- 엔드포인트 지정
endpoint = aiplatform.Endpoint.create(
display_name="netflix-recommendation",
project=PROJECT_ID,
location=LOCATION,
)- deployment(약 20분 정도 소요)
deployment = registry_model.deploy(
endpoint=endpoint,
machine_type=DEPLOY_COMPUTE,
min_replica_count=1,
max_replica_count=1,
accelerator_type=DEPLOY_ACCELERATOR,
accelerator_count=1,
traffic_percentage=100,
sync=True,
)- 모델 예측 수행
instances = [{"movies": [100, 101, 102, 103, 104, 105, 106, 107, 108, 400]}]
endpoint.predict(instances=[instances])
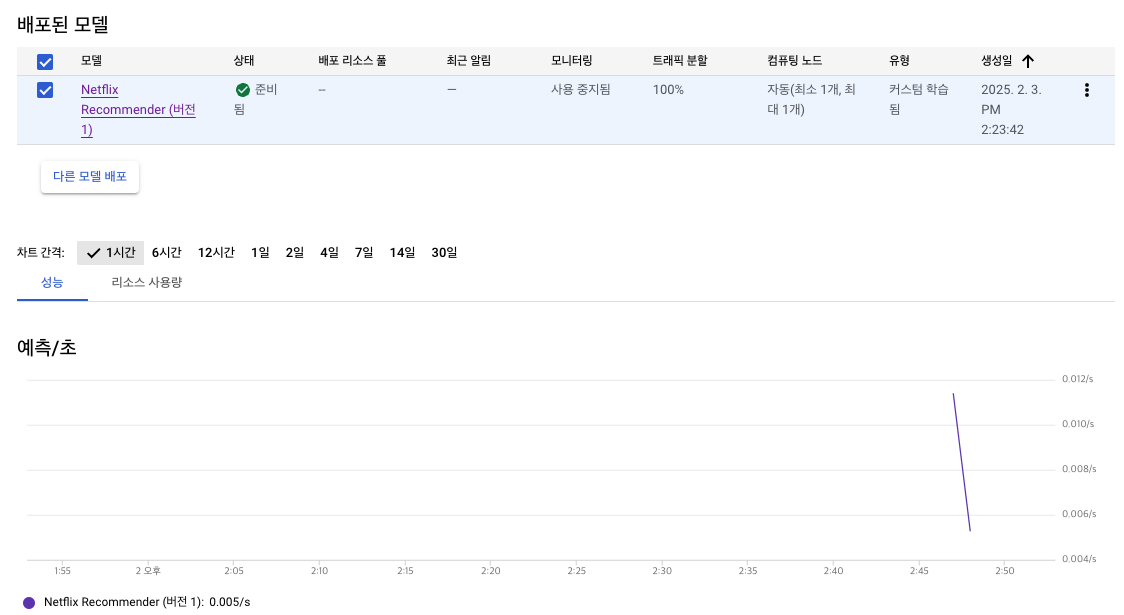
GCP에서 결과 확인
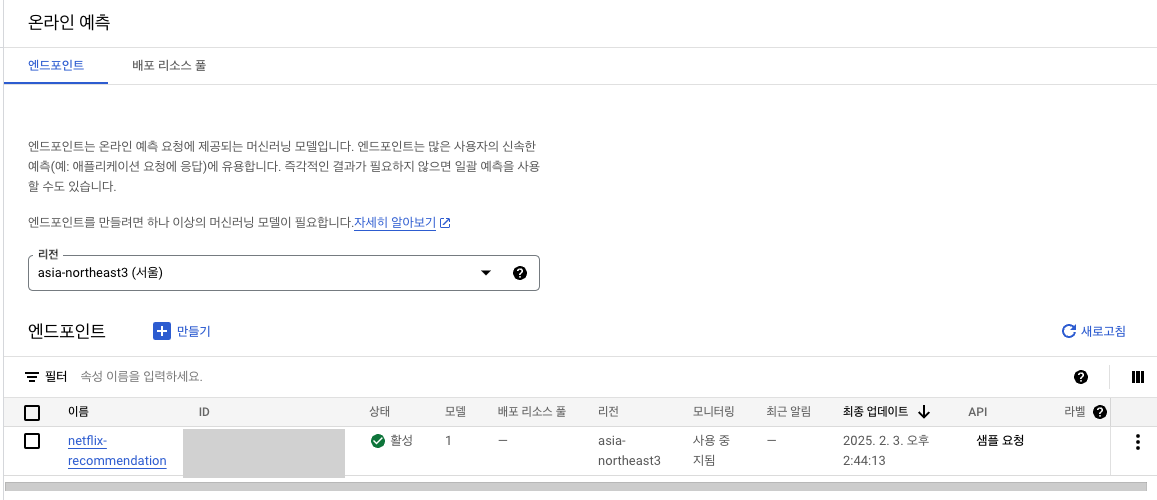
로그 탐색기에서도 확인 가능

- Vertex AI 세부정보
⭐️ Clean Up⭐️
endpoint.undeploy_all()
endpoint.delete()
registry_model.delete()
현재 구조의 문제점
-
지속 학습 ❌
-
데이터 전처리가 Colab에서 진행됨
- 대규모 데이터 처리에는 적합하지 않음
- 런타임 문제가 있음
-
형상 관리의 부재
- 모델 학습 코드가 colab에서 별도로 관리되기 때문
-
Colab 이용 시, 모델이 사용하는 데이터셋이 휘발됨
6-4. 데이터 웨어하우스를 이용한 데이터 관리
자동 배포 이용
- 파이프라인 생성만 Colab에서 하고, 모델 학습부터는 GCP로 이관!
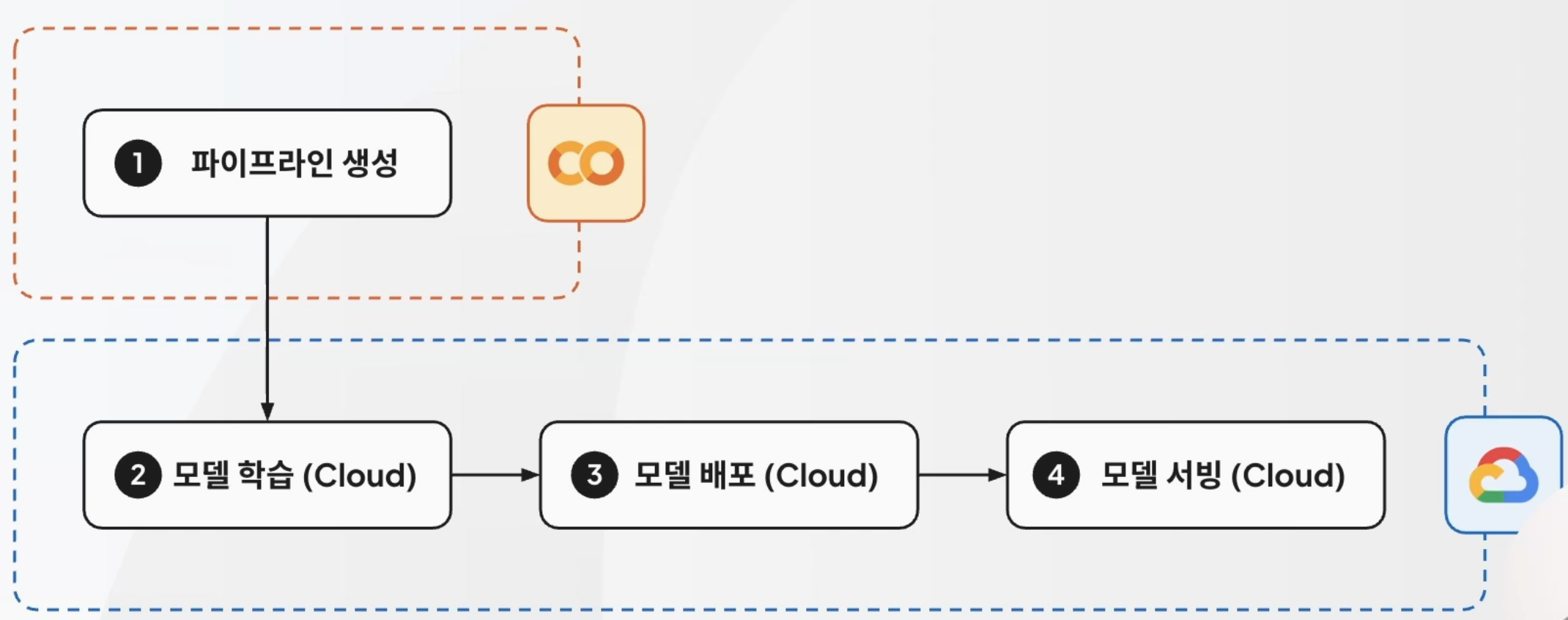
- 또한, 대용량 데이터의 사용을 위해 BigQuery 사용
KFP(KubeFlow Pipeline)
- Docker를 이용한 ML 워크플로우 구성을 돕는 플랫폼
- vertex AI Pipline을 이용하면..
- KFP SDK를 사용해 파이프라인 설계가 가능함!
- vertex AI Pipline을 이용하면..
모델 구조 변경
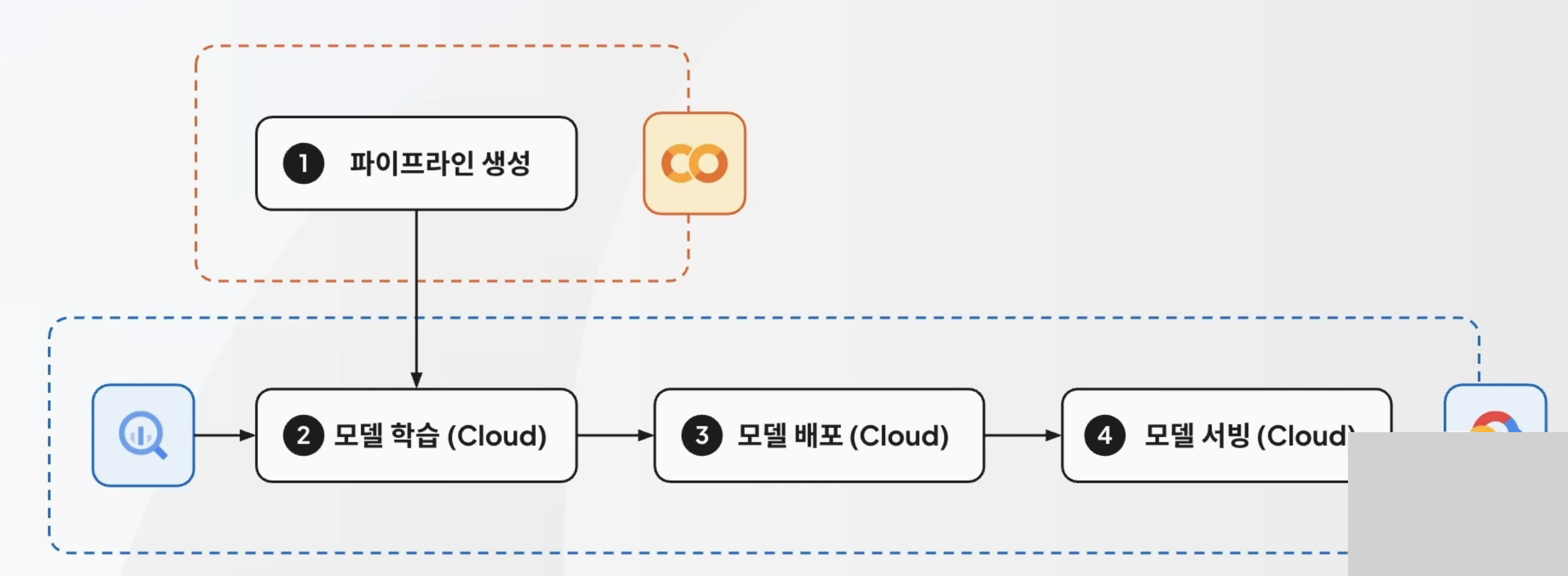
- 파이프라인을 이용해 모델 학습부터의 일련의 과정들을 GCP에서 진행
실습
주의: 이전과 동일하게 런타임을
맞춤 GCE VM에 연결하여 사용해야 함
서비스 계정 권한 목록

credentials 등록
- 서비스 계정 키 발급(.json)해 사용
credentials = service_account.Credentials.from_service_account_file("credentials.json")- 계정 로그인
!gcloud auth login --cred-file=credentials.json설정 정보 기입
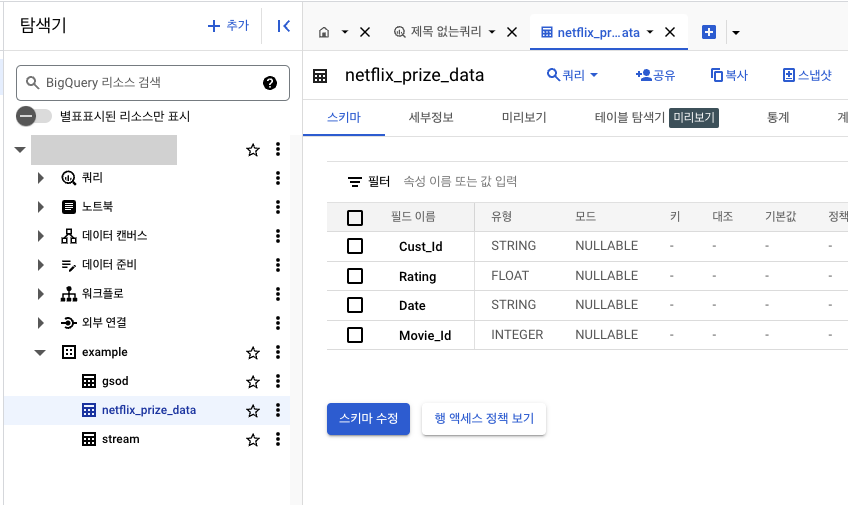
- example의 netflix_prize_data 테이블 사용 예정(BigQuery)
Kaggle에서 데이터 가져다 사용
import os
from google.colab import userdata
os.environ["KAGGLE_USERNAME"] = userdata.get("KAGGLE_USERNAME")
os.environ["KAGGLE_KEY"] = userdata.get("KAGGLE_KEY")!pip install kaggle
!kaggle datasets download -d netflix-inc/netflix-prize-data
!unzip "netflix-prize-data.zip" -d netflix-prize-data파이프라인 실행
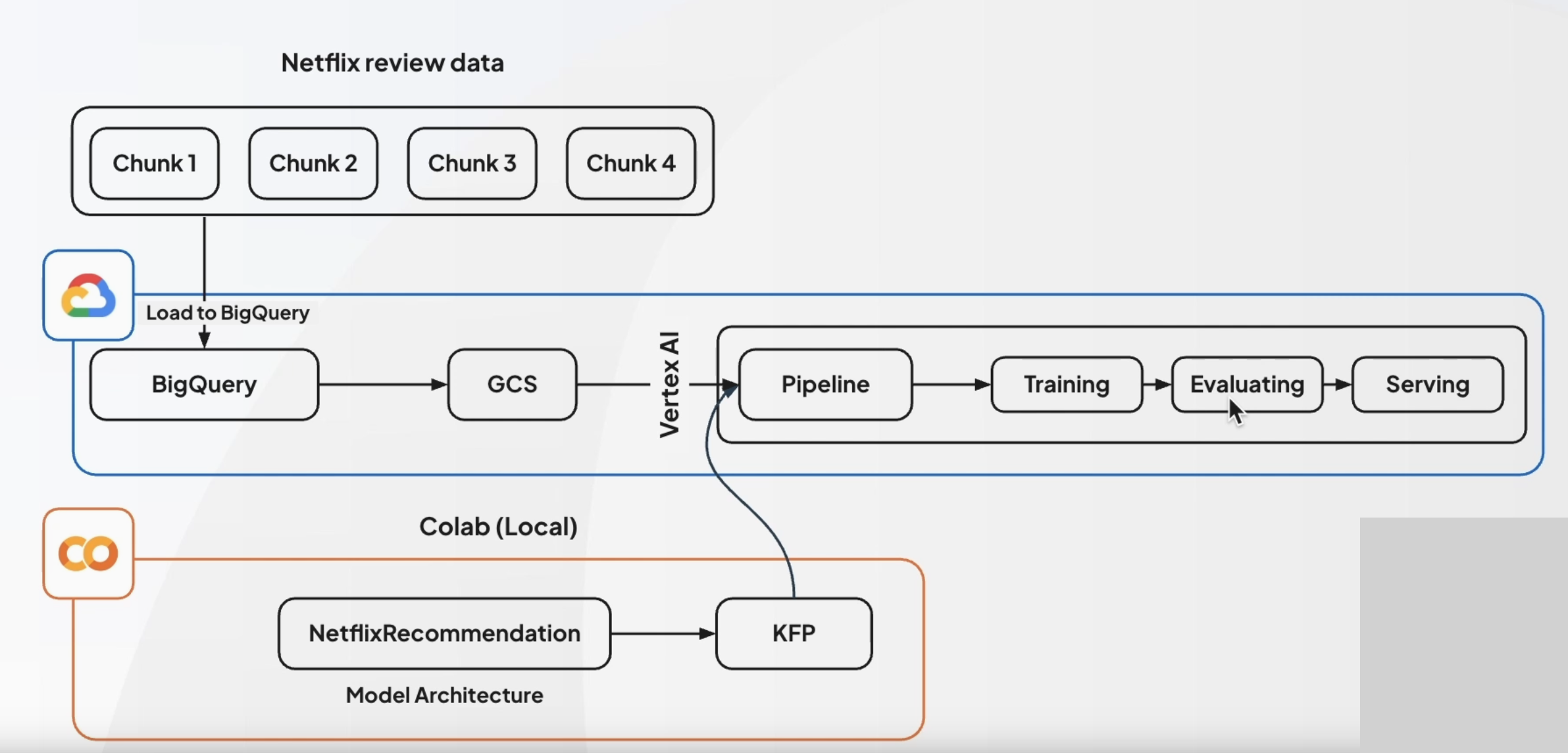
- 기존과 달리 샘플링을 하지 않고, 전체 원본 데이터를 BigQuery에 적재
- 현재 데이터셋은
Gold레벨(메달리온 아키텍쳐)
- 현재 데이터셋은
스토리지 연결
- storage_client 및 bucket 변수 생성
- aiplatform 초기화 함수 지정
upload_blob함수 사용(이전과 동일)
집계된 데이터 생성 및 CSV 저장(일정 시간 소요)
csv_file_name = "netflix_prize_data.csv"
data.to_csv(csv_file_name, index=False)
upload_blob(csv_file_name, csv_file_name)
- 버킷에 저장되었는지 확인

GCP에 업로드
load_to_bigquery(f"gs://{BUCKET_NAME}/{csv_file_name}")
6-5. 예제 실습:통합 파이프라인_파트1
파이프라인 구성 설정
PIPELINE_ROOT = f"gs://{BUCKET_NAME}/pipeline_root"
BUCKET_PATH = f"gs://{BUCKET_NAME}"
MODEL_DIR = f"{BUCKET_PATH}/model"
DATA_DIR = f"{BUCKET_PATH}/data"- deploy
DEPLOY_COMPUTE = "n1-standard-2"
DEPLOY_ACCELERATOR = "NVIDIA_TESLA_T4"컴포넌트
- 각 컴포넌트 당 1개씩의 베이스 이미지를 가짐(Docker image)
- kfp.v2의 컴포넌트를 활용
BigQuery 쿼리 수행
- CPU를 사용해야 하기 때문에 Queta를 2000으로 잡고 진행
- GPU 사용이 가능한 경우에는 더 늘릴 수 있음
모델 학습 스크립트 작성
- 컴포넌트 단위로 작성
모델 Deploy
@component(base_image="python:3.11", packages_to_install=["google-cloud-aiplatform"])
def deploy_model_op(project_id: str, model_path: str):
from google.cloud import aiplatform
DEPLOY_COMPUTE = "n1-standard-2"
DEPLOY_ACCELERATOR = "NVIDIA_TESLA_T4"
model = aiplatform.Model.upload(
project=project_id,
display_name="netflix-recommender",
artifact_uri=model_path,
serving_container_image_uri="asia-northeast3-docker.pkg.dev/gde-project-aicloud/mlops-quicklab/trainer:1.0.3",
)
endpoint = model.deploy(
machine_type=DEPLOY_COMPUTE,
min_replica_count=1,
max_replica_count=1,
accelerator_type=DEPLOY_ACCELERATOR,
accelerator_count=1,
traffic_percentage=100,
)파이프라인 구성
@pipeline(name="netflix-recommender-pipeline", pipeline_root=PIPELINE_ROOT)
def netflix_recommender_pipeline(
project_id: str,
dataset_id: str,
table_id: str,
gcs_bucket_name: str,
gcs_bucket_path: str
):
export_op = export_data_to_gcs(
project_id=project_id,
dataset_id=dataset_id,
table_id=table_id,
gcs_bucket_path=gcs_bucket_path
)
train_op = (
train_model(
project_id=project_id,
gcs_bucket_name=gcs_bucket_name,
gcs_bucket_path=gcs_bucket_path,
data_path=export_op.output,
)
.set_memory_limit("32Gi")
)
deploy_model_op(project_id=project_id, model_path=train_op.output)모델 컴파일
job.submit- GCP의 IAM > 서비스 계정에서 확인 후 수정하여 코드 실행
- 단, 서비스 계정 권한이 반드시
서비스 계정 사용자가 등록되어 있어야 함!
결과 확인
버킷
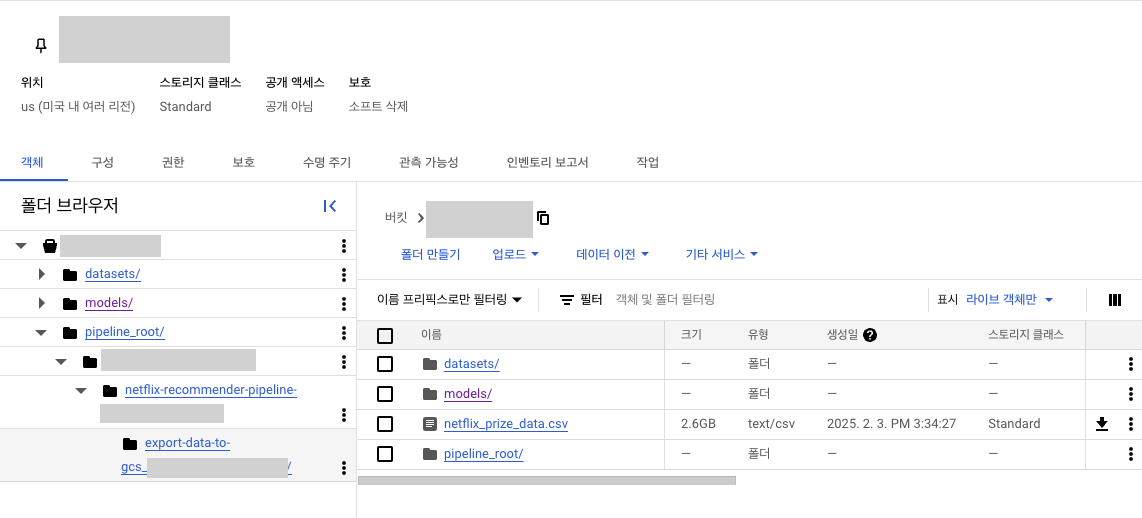
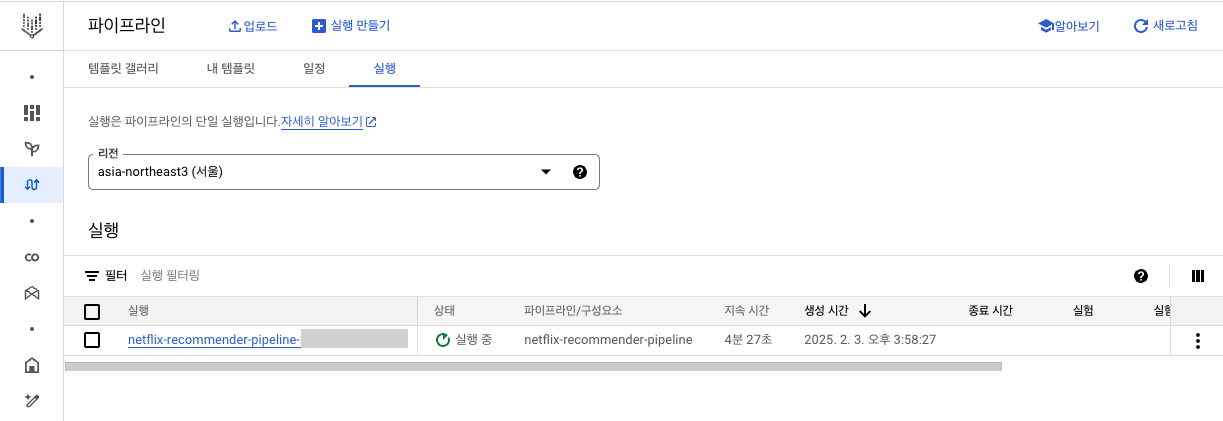
Vertex AI 파이프라인으로 확인
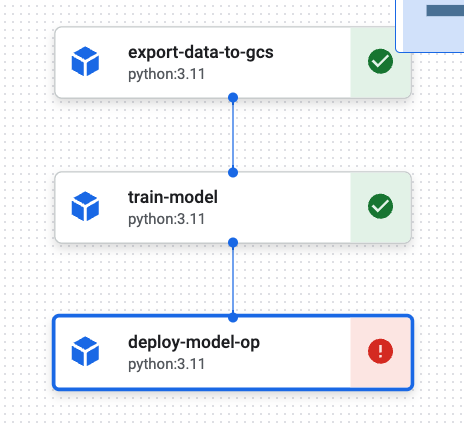
모든 노드가 실행되고 나면, 파이프라인은 종료됨
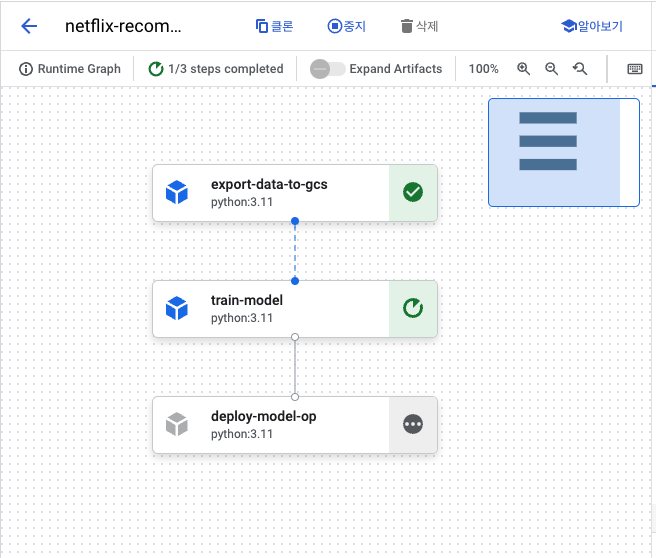
- 노드 정보의 로그 보기로 로그 확인 가능
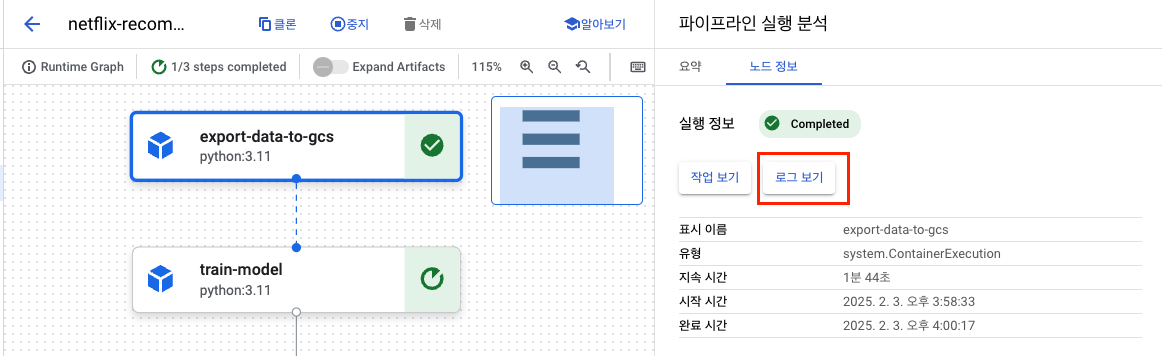
-
2번 노드 진행중
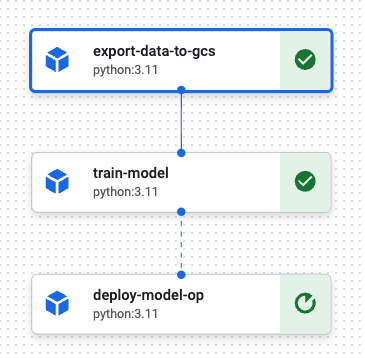
-
최종 노드는 실패
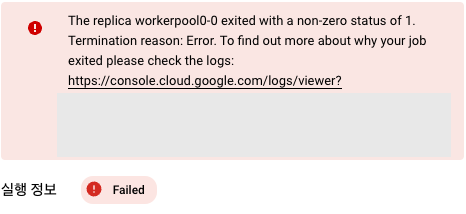
6-7. 생각하기 - 모델 운영 및 모니터링
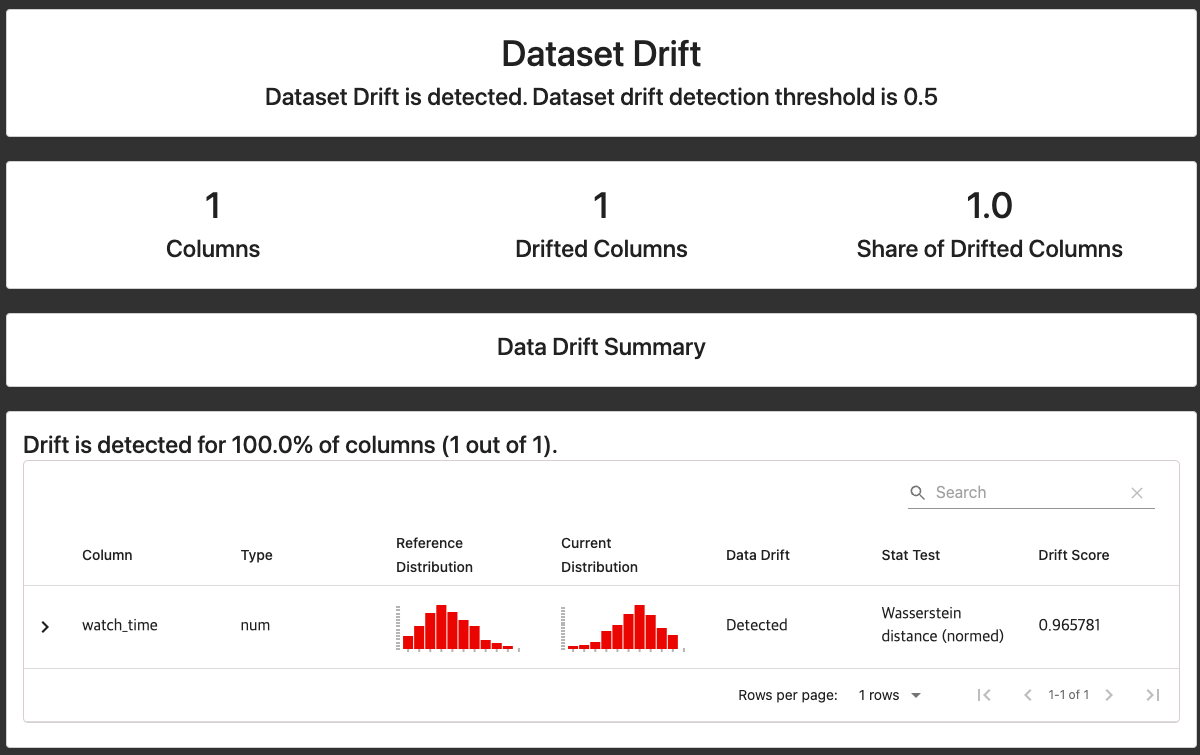
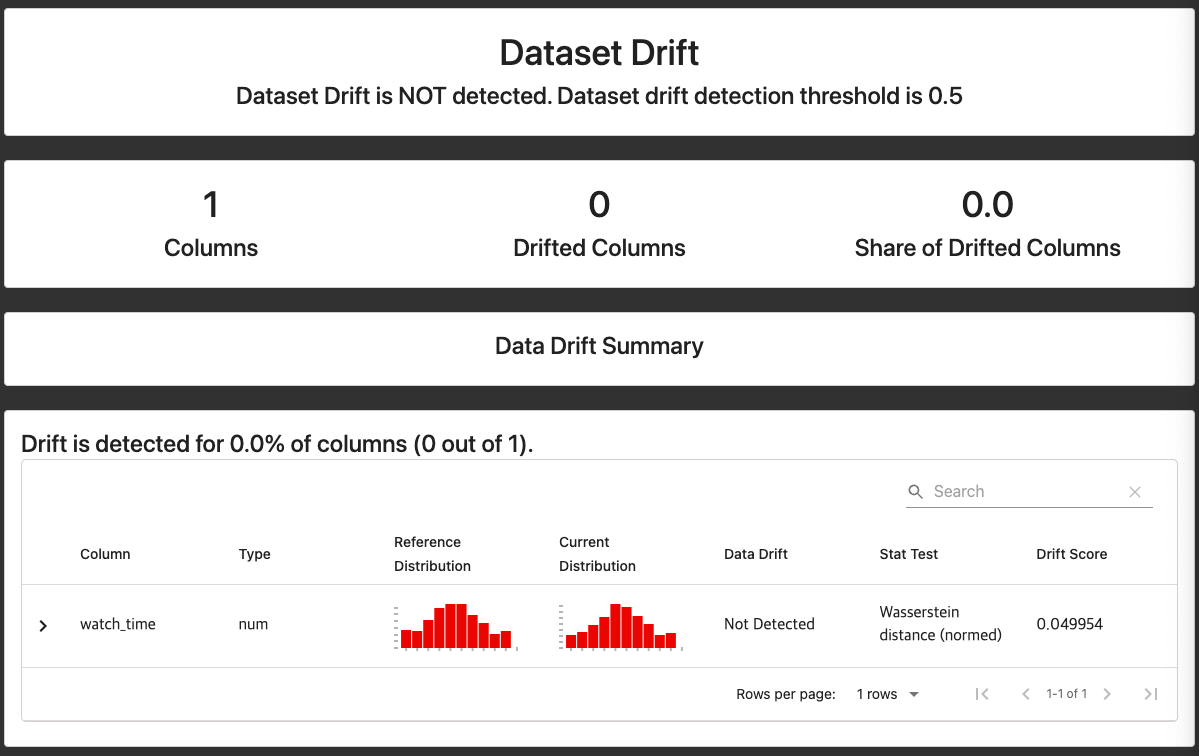
데이터 드리프트
- 시간에 따른 데이터 변화 ➡️ 모델 품질에 큰 영향을 주는 모델 드리프트 발생 가능성 높아짐
- 즉, 데이터 드리프트의 감지가 매우 중요
데이터 드리프트(Data Drift) 현상이란?
- 시간의 흐름에 따라 데이터 분포가 변화됨
- 그로 인해 모델의 정확도가 크게 떨어지는 경우 발생
- 현재의 분포가 잘 반영되는 모델로 재학습을 하면서 업데이트가 잘 되어야 함!
실습
GCP 정보 불러오기
- BigQuery에 example 테이블이 잘 만들어져 있는지 확인할 것
table id 설정
full_table_id = f"{PROJECT_ID}.{DATASET_ID}.{TABLE_ID}"
try:
client.get_table(full_table_id)
print("Table {} already exists.".format(full_table_id))
except:
schema = [
bigquery.SchemaField(name="movie_id", field_type="STRING"),
bigquery.SchemaField(name="watch_time", field_type="INTEGER"),
bigquery.SchemaField(name="date", field_type="INTEGER"),
]
table = bigquery.Table(full_table_id, schema=schema)
client.create_table(table)
print("Created table {}.{}.{}".format(table.project, table.dataset_id, table.table_id))
BigQuery 스트림 이용
def insert_new_line(watch_time: int, current_datetime: datetime.datetime) -> None:
rows_to_insert = [
{
"movie_id": str(uuid.uuid4()),
"watch_time": int(watch_time),
"date": int(current_datetime.timestamp()),
},
]
errors = client.insert_rows_json(full_table_id, rows_to_insert)
if errors != []:
print("Encountered errors while inserting rows: {}".format(errors))특정한 데이터 분포만큼 데이터 드리프트가 발생하도록 의도(약 2분정도 시간 소요)
total_iterations = 10000
current_datetime = datetime.datetime.utcnow()
for i in tqdm(range(total_iterations)):
if i >= total_iterations // 2:
mean, std_dev = 4800, 1200
watch_time = int(np.random.normal(mean, std_dev))
watch_time = np.clip(watch_time, 2400, 7200)
else:
mean, std_dev = 2500, 1250
watch_time = int(np.random.normal(mean, std_dev))
watch_time = np.clip(watch_time, 0, 5000)
insert_new_line(watch_time, current_datetime=current_datetime)
added_seconds = np.random.uniform(1.0, 120.0)
current_datetime += datetime.timedelta(seconds=added_seconds)
BigQuery 데이터를 데이터프레임 형태로 가져와 확인
- 현재 데이터셋 변화 확인
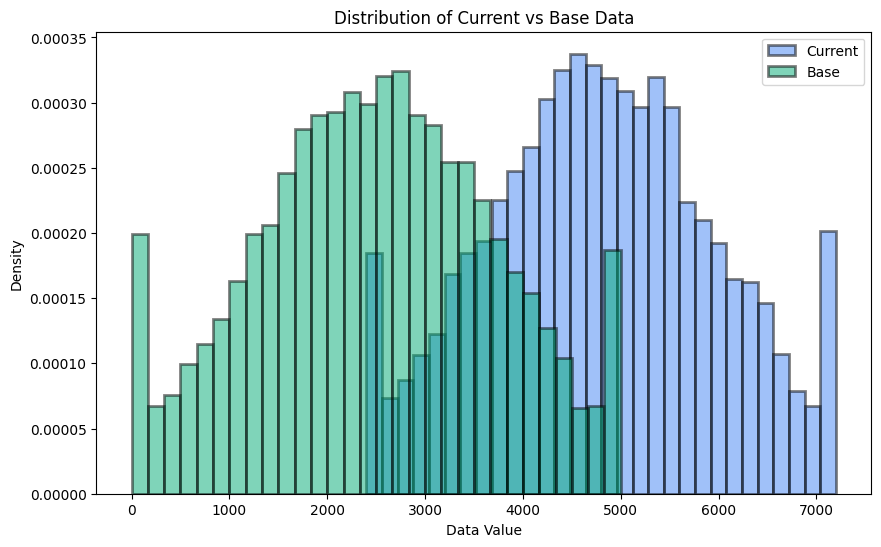
facets으로 세부 확인
import base64
from facets_overview.generic_feature_statistics_generator import GenericFeatureStatisticsGenerator
from IPython.core.display import display, HTML
gfsg = GenericFeatureStatisticsGenerator()
proto = gfsg.ProtoFromDataFrames([
{"name": "current", "table": df_current},
{"name": "base", "table": df_base},
])
protostr = base64.b64encode(proto.SerializeToString()).decode("utf-8")
HTML_TEMPLATE = """
<script src="https://cdnjs.cloudflare.com/ajax/libs/webcomponentsjs/1.3.3/webcomponents-lite.js"></script>
<link rel="import" href="https://raw.githubusercontent.com/PAIR-code/facets/1.0.0/facets-dist/facets-jupyter.html" >
<facets-overview id="elem"></facets-overview>
<script>
document.querySelector("#elem").protoInput = "{protostr}";
</script>"""
html = HTML_TEMPLATE.format(protostr=protostr)
display(HTML(html))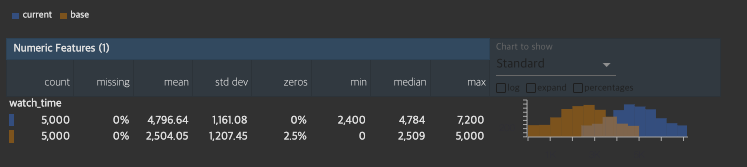
evidently를 통한 데이터 드리프트 감지 및 확인
6-8. 생각하기 - 모델 성능 평가 및 관리
모델 모니터링: MLFlow 사용
- https://mlflow.org
- 제공된 깃허브의
mlflow파트 활용
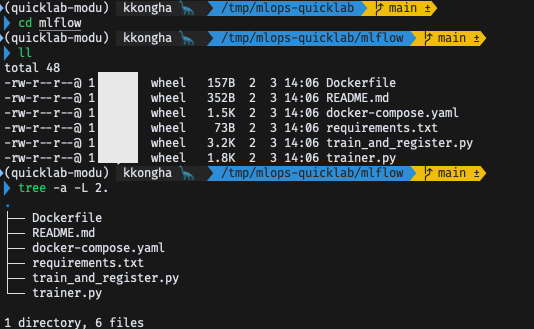
docker-compose.yaml
- MLFlow 관련 설정 스크립트 작성되어 있음
version: "3.8"
services:
mlflow:
image: ghcr.io/mlflow/mlflow:v2.2.1
ports:
- "5000:5000"
environment:
- TZ=UTC
command: ["mlflow", "ui", "--host", "0.0.0.0"]
trainer-image:
image: trainer:latest
build:
context: .
dockerfile: Dockerfile
command: echo "Building trainer image"
trainer1:
image: trainer:latest
depends_on:
- mlflow
- trainer-image
environment:
- MLFLOW_TRACKING_URI=http://mlflow:5000
- BATCH_SIZE=64
- LEARNING_RATE=0.01
- NN_DIM_HIDDEN=128
trainer2:
image: trainer:latest
depends_on:
- mlflow
- trainer-image
environment:
- MLFLOW_TRACKING_URI=http://mlflow:5000
- BATCH_SIZE=32
- LEARNING_RATE=0.02
- NN_DIM_HIDDEN=512
trainer3:
image: trainer:latest
depends_on:
- mlflow
- trainer-image
environment:
- MLFLOW_TRACKING_URI=http://mlflow:5000
- BATCH_SIZE=128
- LEARNING_RATE=0.005
- NN_DIM_HIDDEN=64
trainer4:
image: trainer:latest
depends_on:
- mlflow
- trainer-image
environment:
- MLFLOW_TRACKING_URI=http://mlflow:5000
- BATCH_SIZE=128
- LEARNING_RATE=0.5
- NN_DIM_HIDDEN=256
trainer5:
image: trainer:latest
depends_on:
- mlflow
- trainer-image
environment:
- MLFLOW_TRACKING_URI=http://mlflow:5000
- BATCH_SIZE=16
- LEARNING_RATE=0.05
- NN_DIM_HIDDEN=196Docker 실행
$ docker-compose up
MLFlow CR_PAT 가져오기
- Github 계정
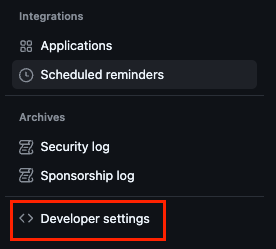
Settings>Developer settings
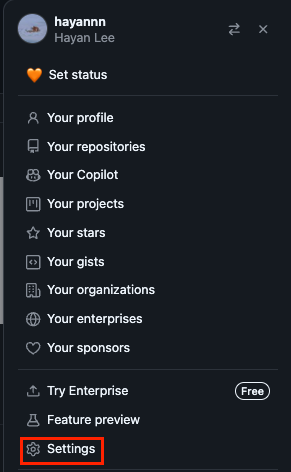
-
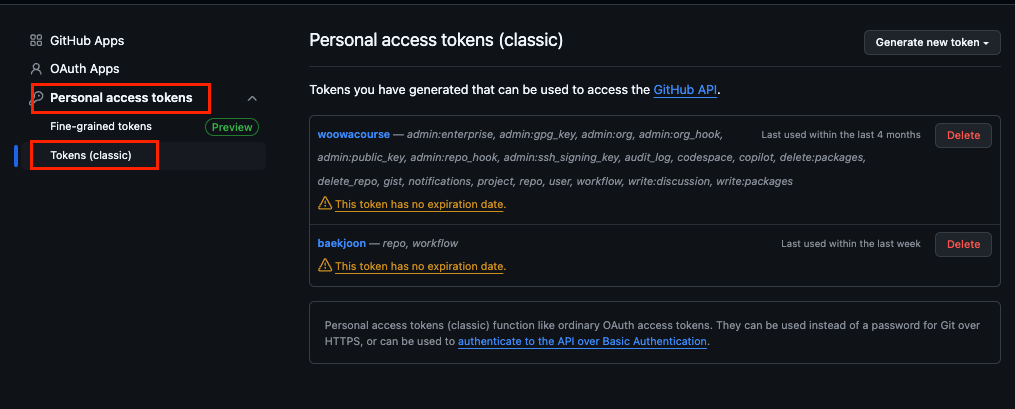
classic Tokens에서
Generate new token클릭
-
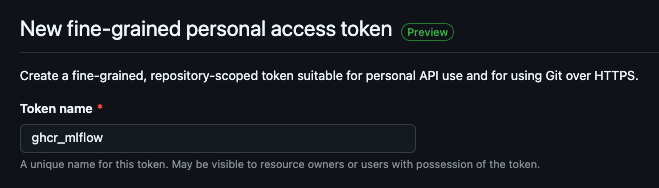
설정
- Permissions도 기본으로 설정하고 바로 Create
- Permissions도 기본으로 설정하고 바로 Create
- 발급받은 토큰 설정하기
$ export CR_PAT={토큰 정보 붙여넣기}
$ echo $CR_PAT | docker login ghcr.io -u USERNAME --password-stdin
- 다시 도커 업
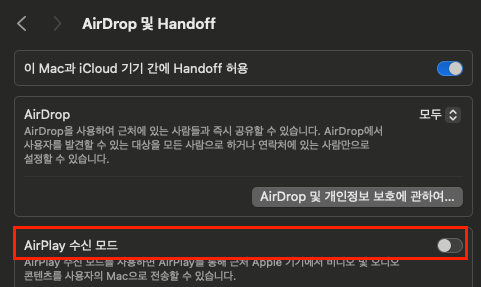
$ docker-compose upMac의 경우, Airplay 수신 모드 해제해야 5000번 포트 사용 가능
- trainer 이미지 다운로드 중

- 완료
MLFlow 접속 확인
- localhost:5000으로 접속
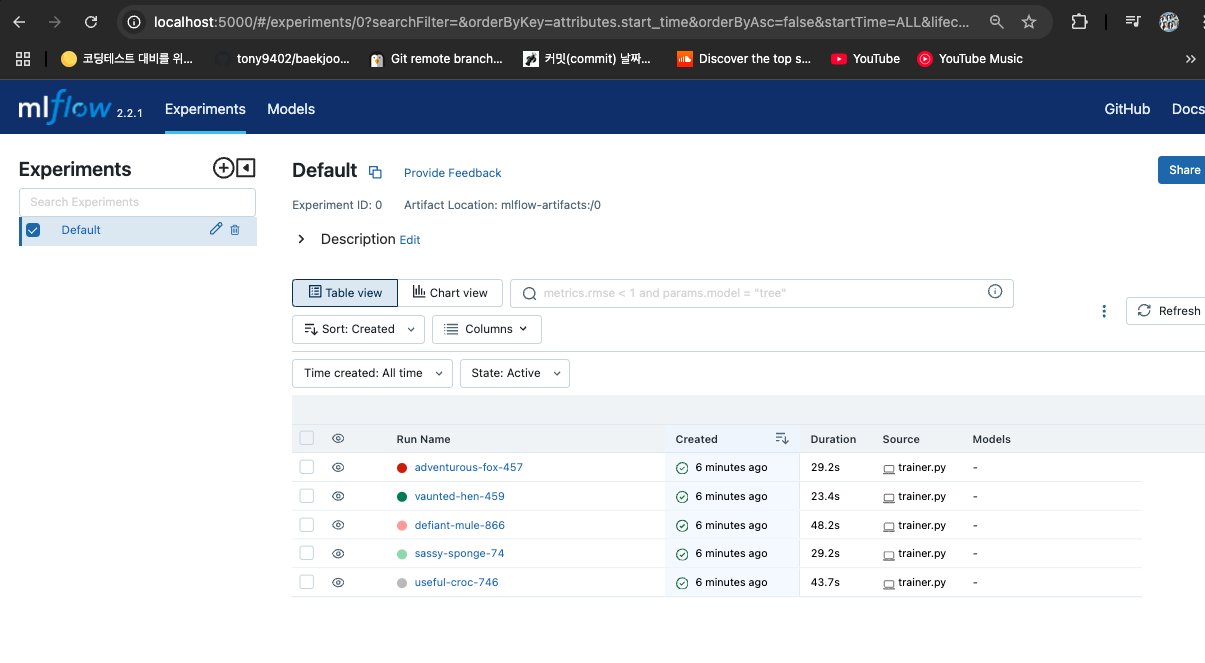
-
트레이닝 완료 시, Duration에 시간 기록됨
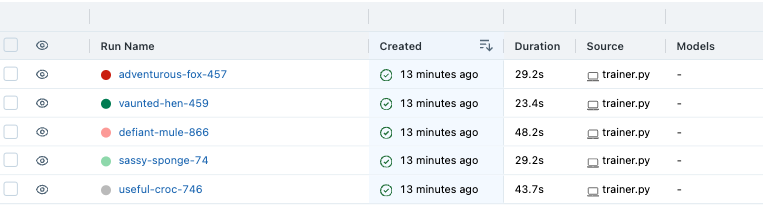
-
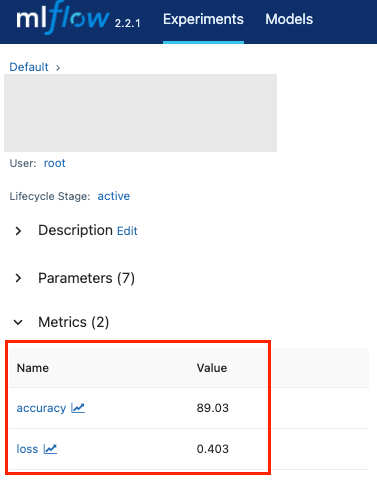
Metrics로 성능 확인 가능
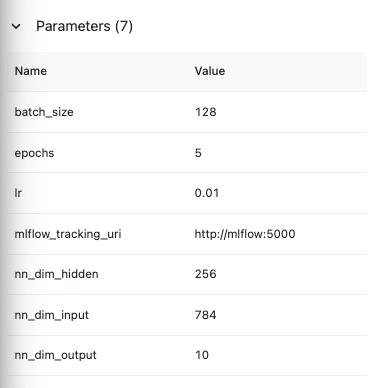
- 사용된 파라미터 값도 확인 가능
htop으로 모니터링할 경우 설치 필요
$ brew install htop
htop입력하면 바로 실행 가능

6-9. 학습 마무리 - 돌아보기 그리고 마무리
토픽 정리
- MLOps 소개
- 도커 활용
- GCP 소개
- Airflow 소개
- 파이프라인
MLOps의 사용 목적
- ML/DL을 비즈니스에 도입한 후의 비용과 시간을 절약할 방법을 고민하며 시작된 분야
MLOps 등장 시기
- 2022년 ~
- 다소 늦은 경향이 있음
MLOps의 경계
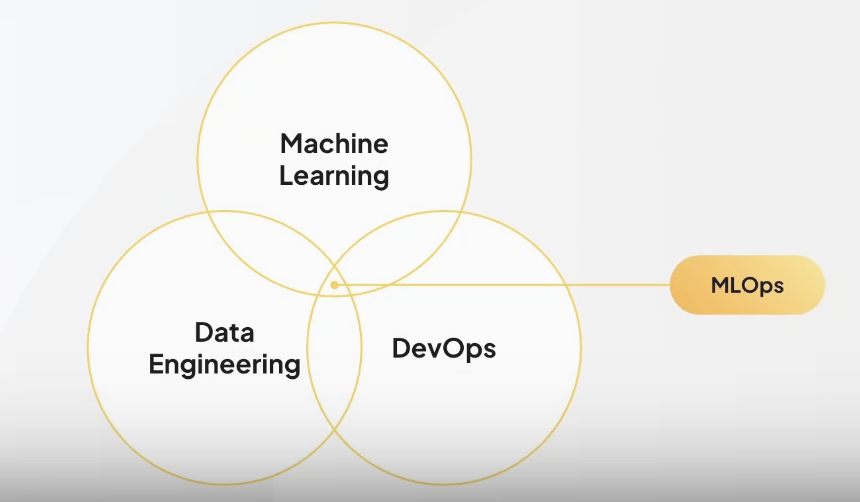
- ML과 Data Engineering, DevOps의 기술을 모두 사용하는 경계에 속해 있음
AI 서비스 개발 과정에서의 고민
1. 모델의 배포 가능 여부
- EDA, 모델 평가, 데이터 드리프트
2. 어떤 데이터를 어떻게 학습시켜야 하는지에 대한 고민
- 모델 학습, 데이터 전처리
3. 사용자 트래픽 증가 시 대응책
- HPA(Horizontal Pod Autoscaler)
4. 학습 프로세스 자동화
- Continuous TrainingPipeline
5. 모델 추론 속도 향상
- Quantization, Pruning
6. 서비스 데이터의 활용
- Data Pipeline, Feature Engineering
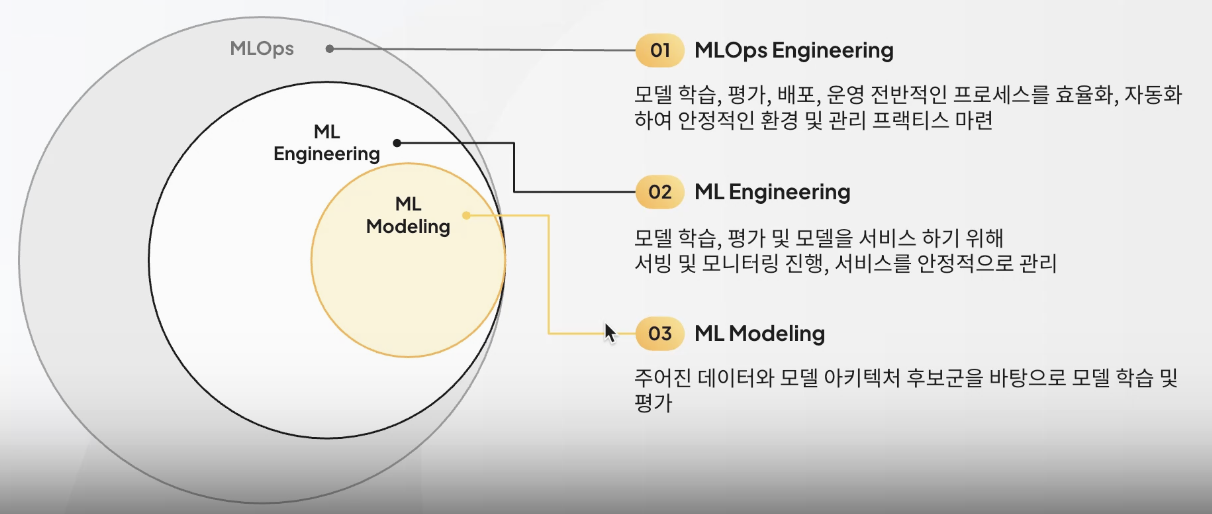
MLOps 생태계
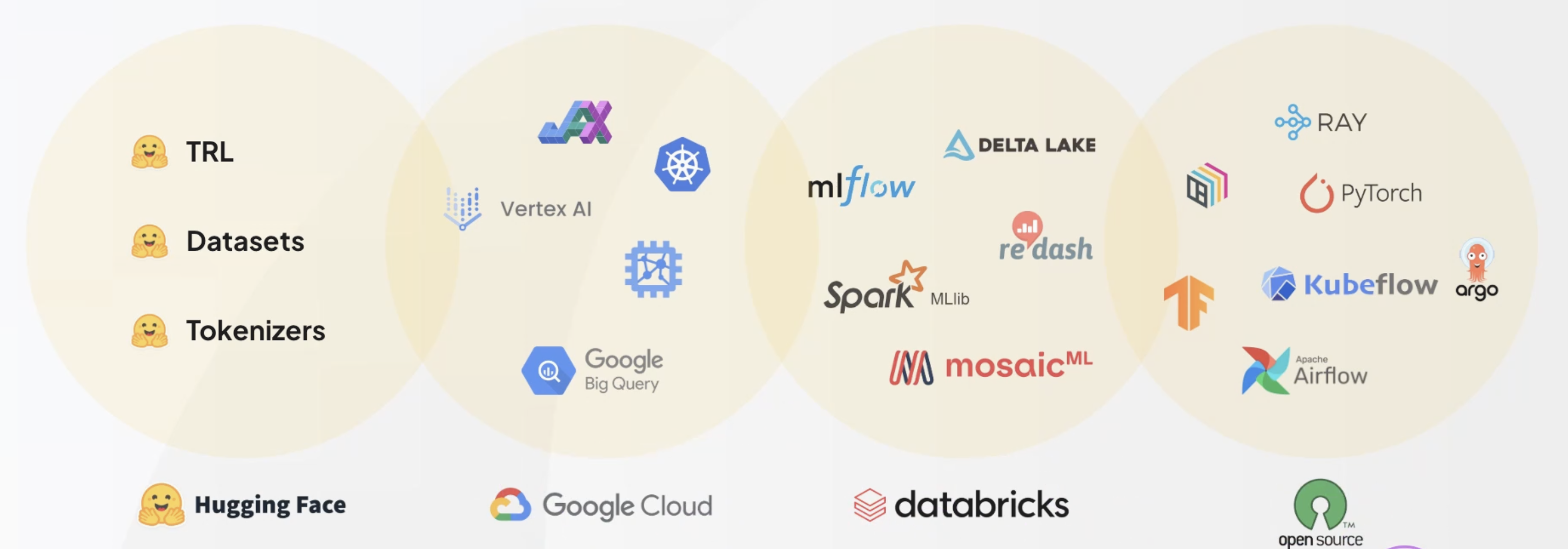
MLOps 범위
Docker 활용
- Docker 기초 사용법
- Docker Swarm
- Docker Compose
- Kubernetes 및 Kuberflow
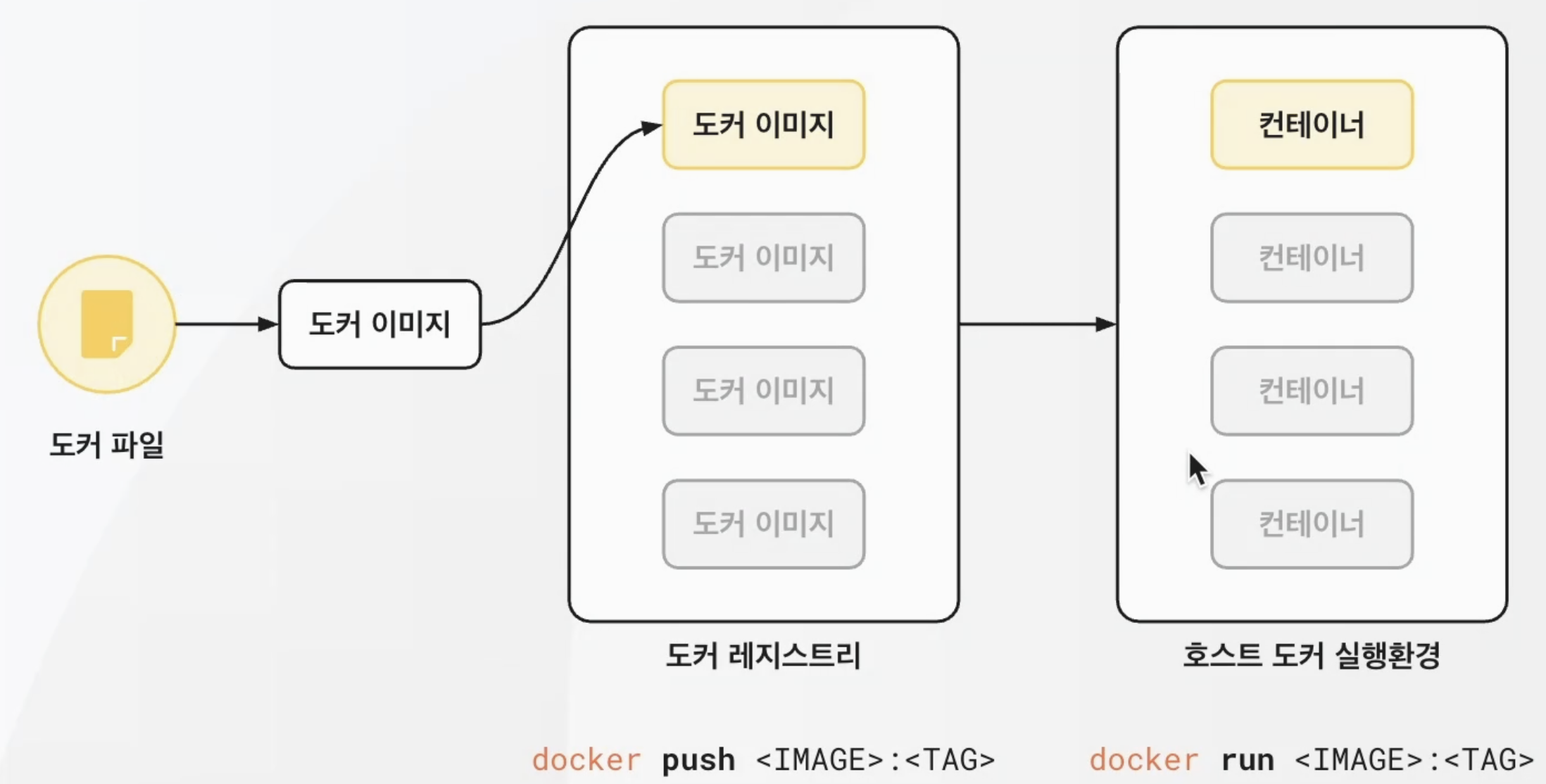
Docker 구조
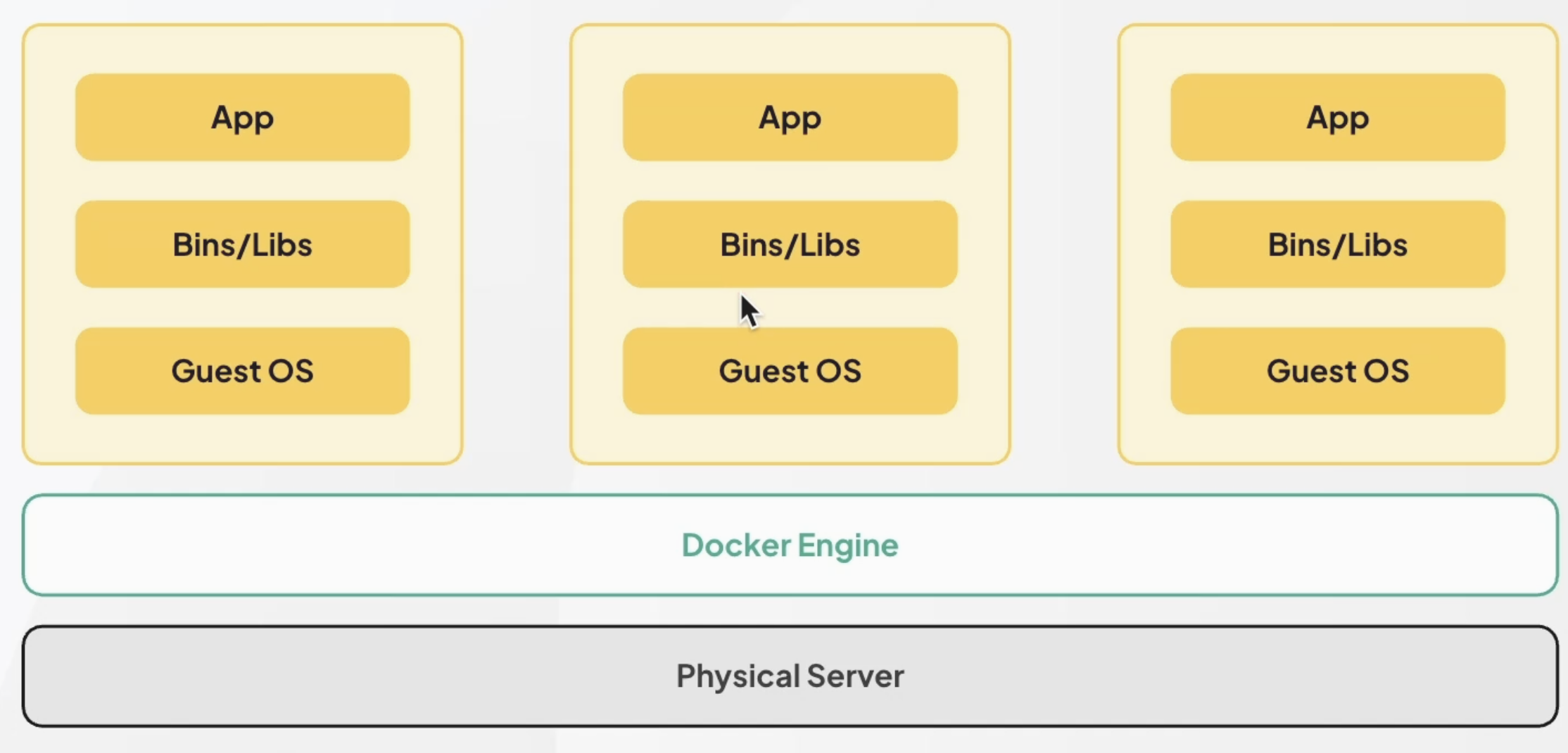
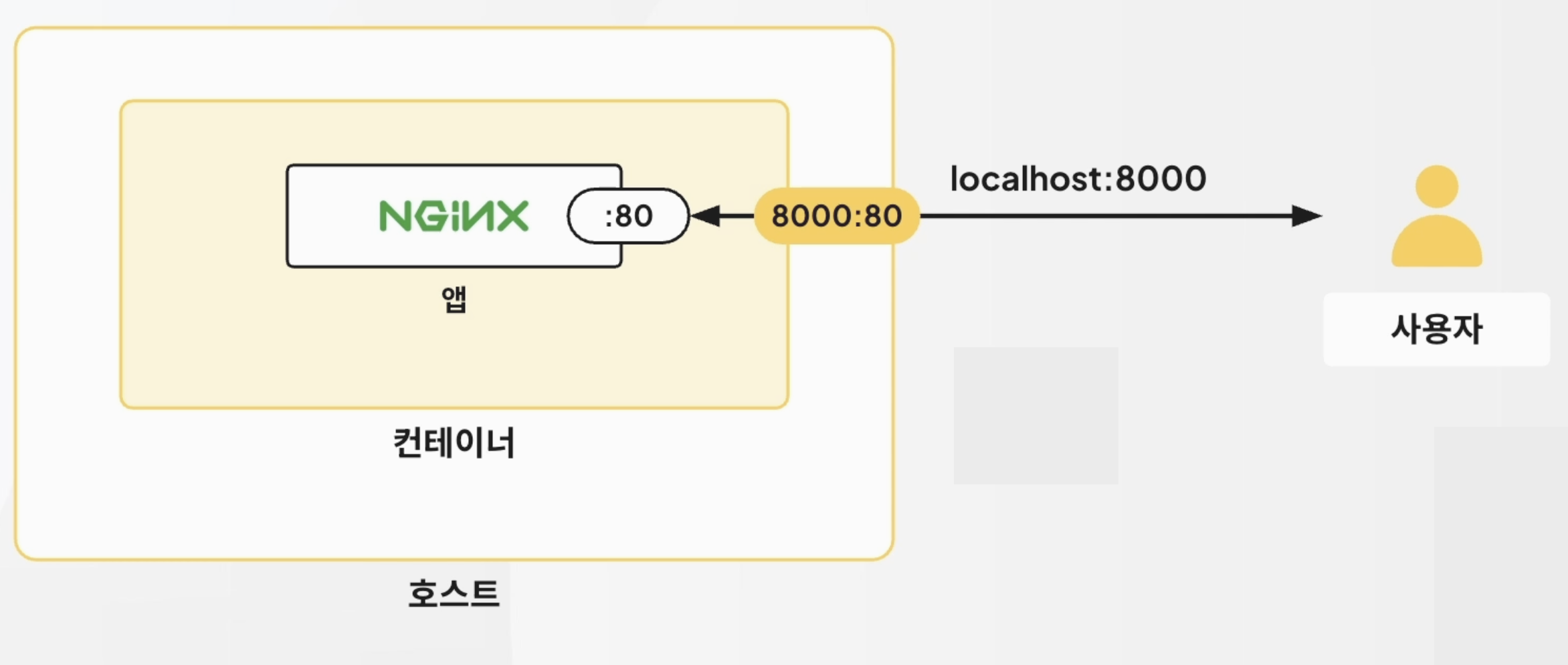
Docker NGINX 컨테이너 구성
Docker Build
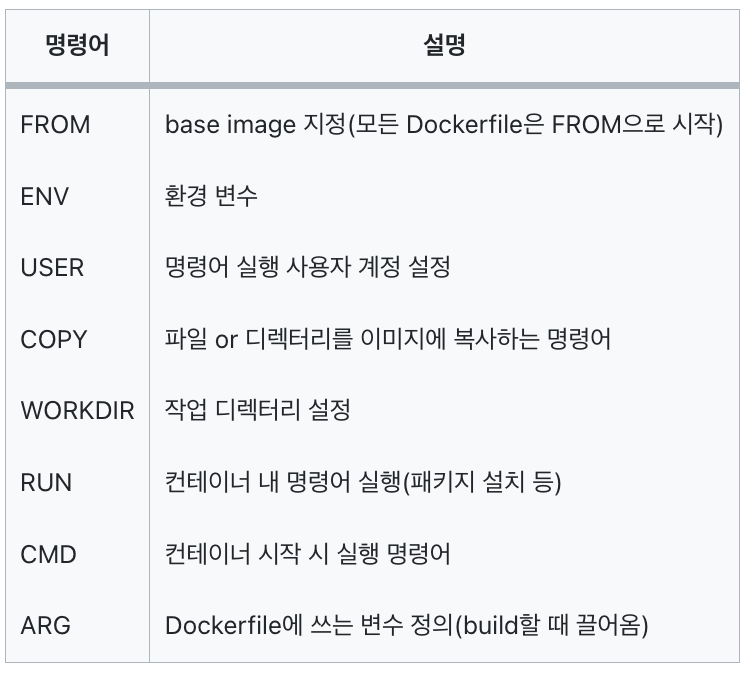
Docker 명령어
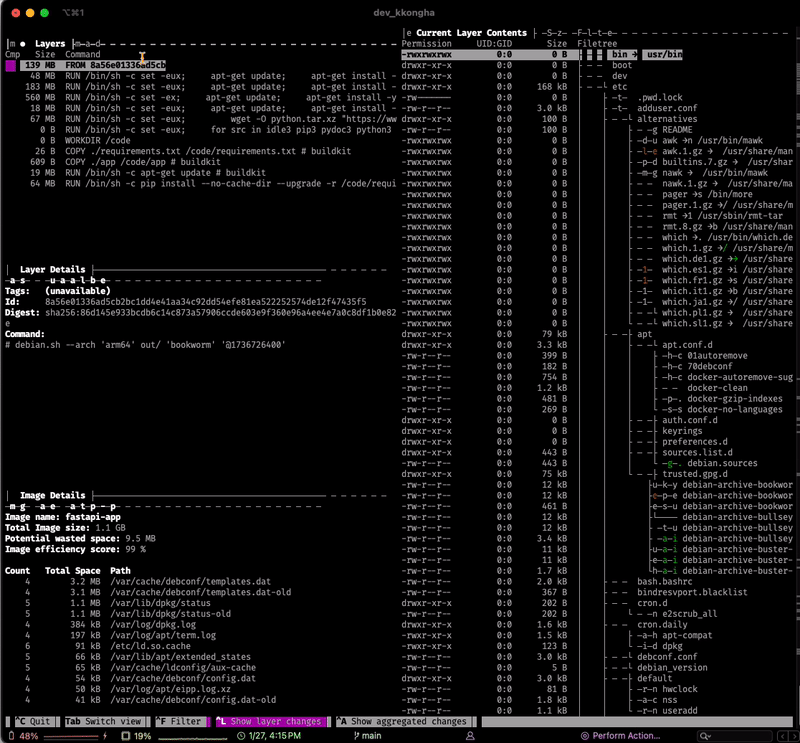
Docker 최적화: Dive
부하분산: Scale-up, Scale-out
참고 : 2-5. 더 나아가기: 부하분산
-
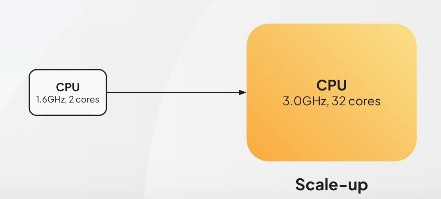
Scale-up
- CPU 코어 증가 등의 방식으로 더 좋은 CPU로 대체
- CPU 교체 과정에서 서버의 down time이 불가피하게 발생
- 단일 요청에 대해서는 응답이 효과적이나, 사용자 증가 시 단일 머신 한계로 인해 효과적인 요청 처리가 어려움
-
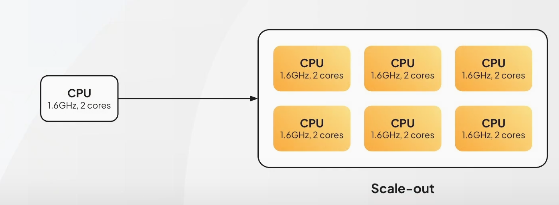
⭐️ Scale-out ⭐️
- 동일 CPU를 여러 개로 늘린 뒤, 하나의 클러스터처럼 동작하도록 함
- 단일 요청 자체가 빨라지지는 않지만, 수많은 요청이 왔을 때의 그 요청이 잘 분배되는 효과가 있는 것
GCP
Google Cloud Platform
- 구글 클라우드에서 제공하는 서비스
- ML, Big Data 분야에서 가장 많이 사용하고 있고, 많은 서비스가 제공되고 있음
Cloud Skill Boost
Google BigQuery
- Google Cloud Platform 데이터 웨어하우스 도구
BigQuery 공개 데이터셋

BigQuery 아키텍쳐
BigQuery로 스트림 데이터 처리
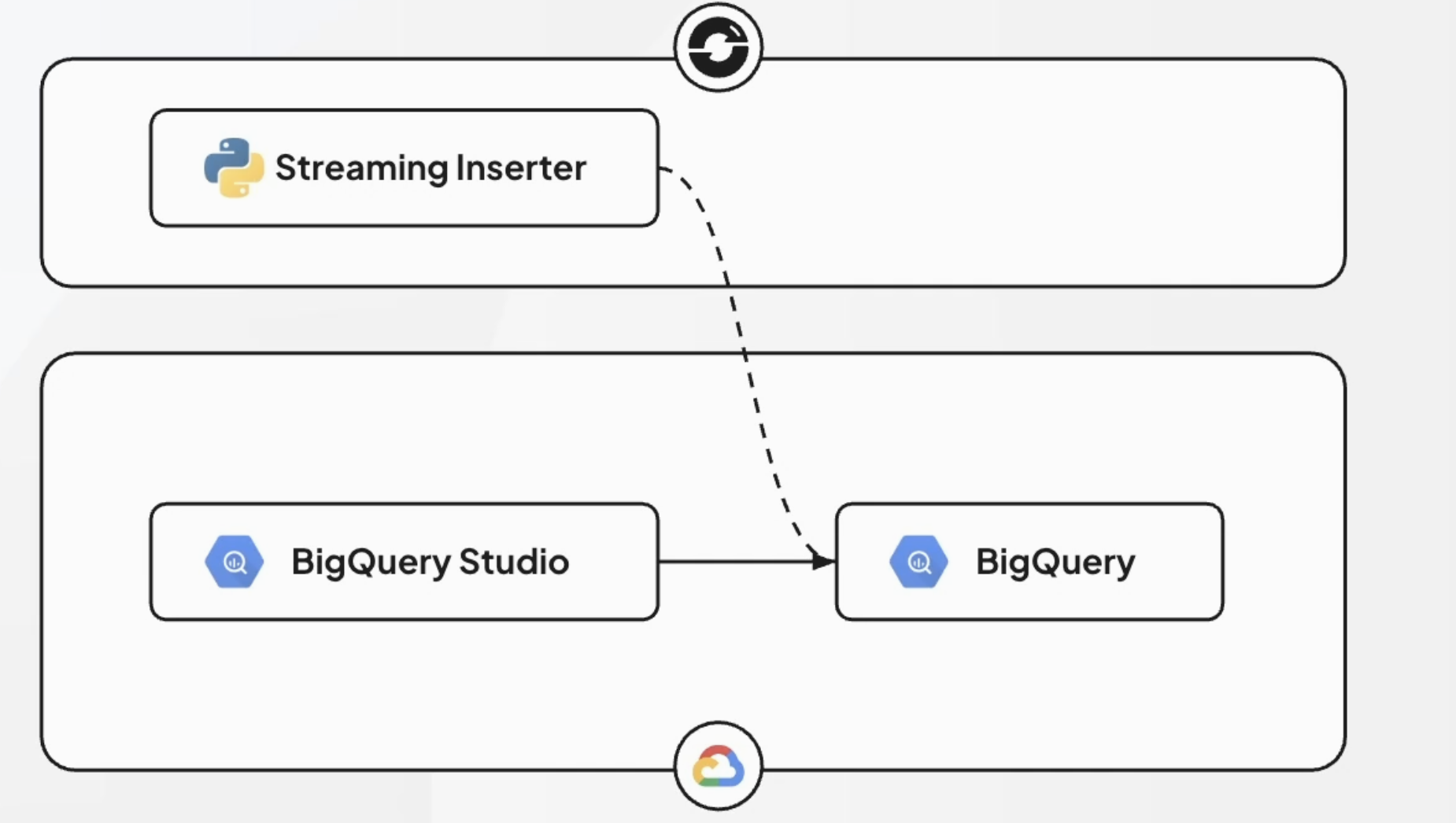
- 스트림 처리는 모델 서빙 시 발생한 로그 데이터를 적재해 지속 학습에 적용
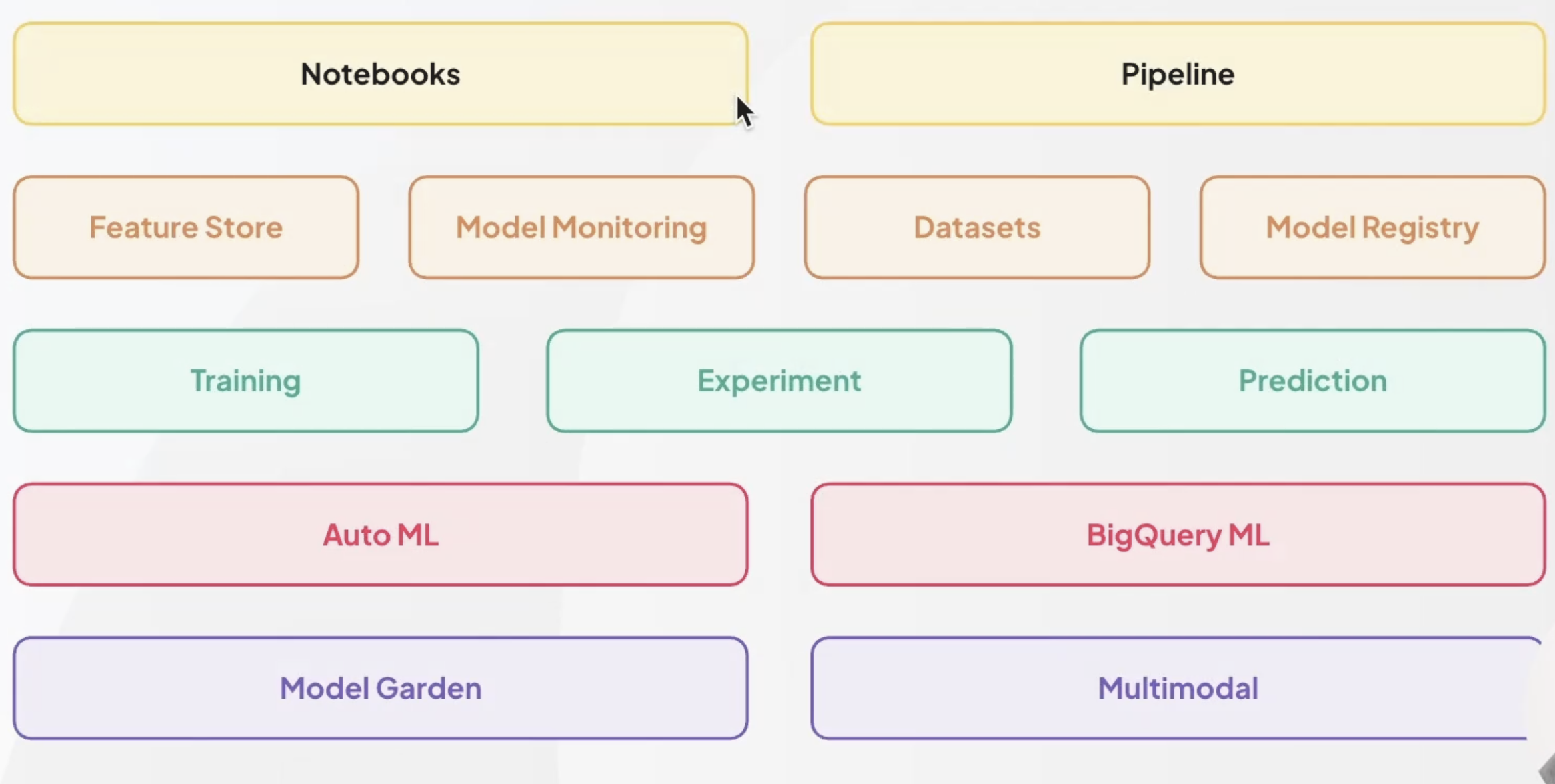
Vertex AI 소개
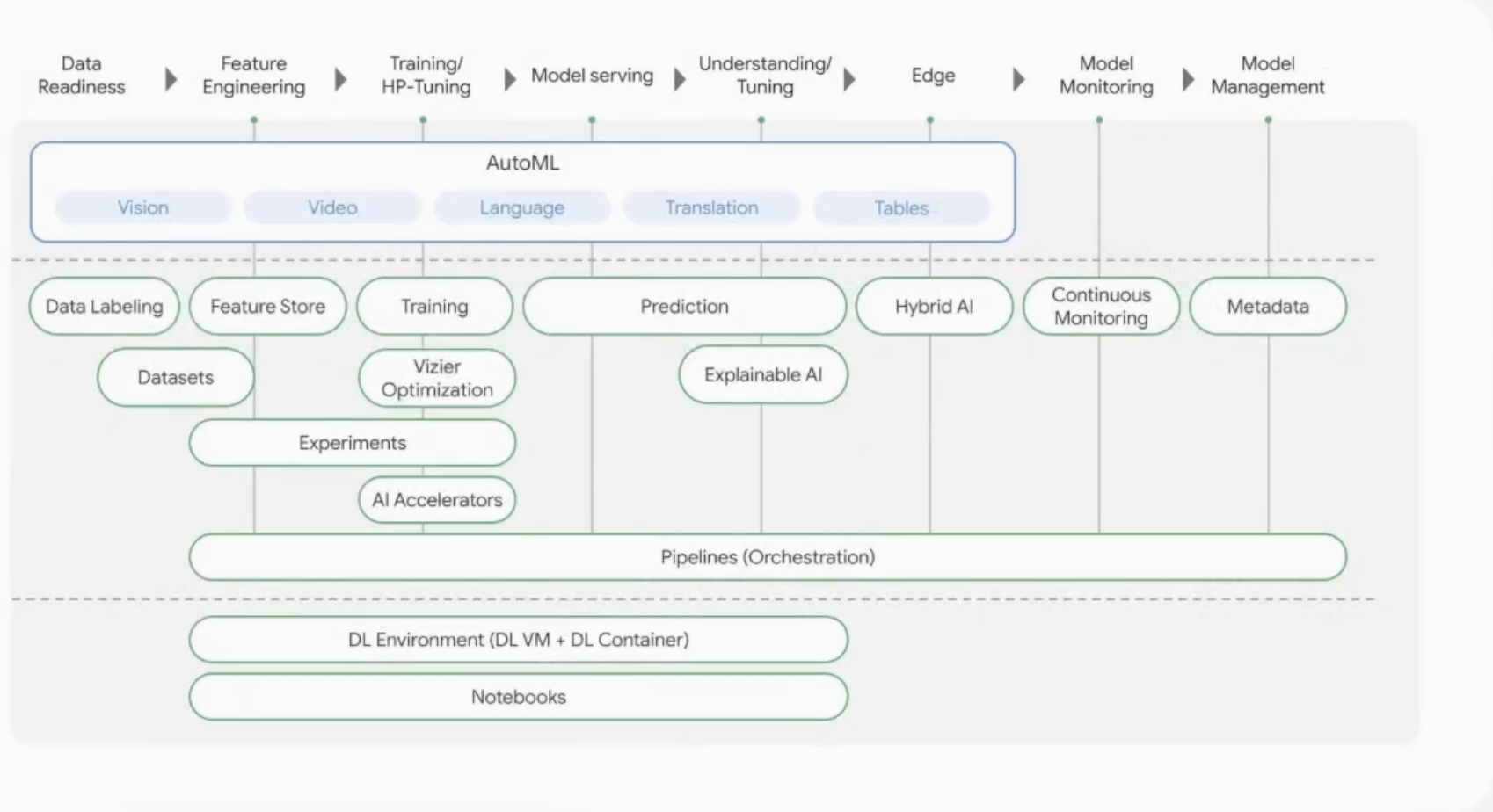
- 컴포넌트
Airflow
- Apache Airflow 사용
DAG 구조 사용
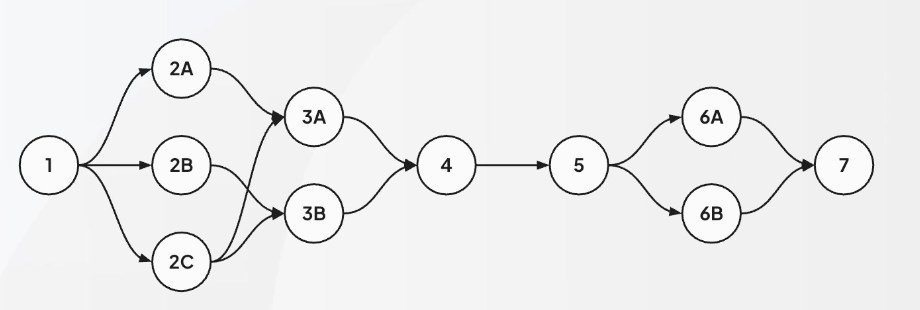
- Directed Acyclic Graph
- 순환 노드가 없음, 방향성 가진 그래프
데이터 드리프트
- 시간에 따른 데이터의 변화를 감지히여 데이터 품질 관리를 해야함!
- 모델 정확도를 지켜야하고, 현재의 분포를 재학습하여 바로바로 반영할 수 있어야 서비스 유지가 될 것
메달리온 아키텍쳐
Airflow 한계점
-
Runner 분산 최적화 ❌
- Dataflow 분산 프로세싱
-
스트리밍 처리 ❌
- Dataflow 스트리밍 프로세스를 이용해서 해결해야 함
-
Task 간 데이터 전송의 비효율 발생
- 데이터 프로세싱 전 과정에 파이프라인 사용
-
데이터 보안 ❌
- Dataflow GME key를 사용해 보호해야 함
파이프라인
- CI/CD
- 모델 학습 파이프라인
- 모델 배포 파이프라인
CI/CD
-
소프트웨어 개발 생애주기의 CI, CD로 코드 변경 사항의 자동화, 검증, 배포까지의 일련의 과정을 진행하는 것
-
CI
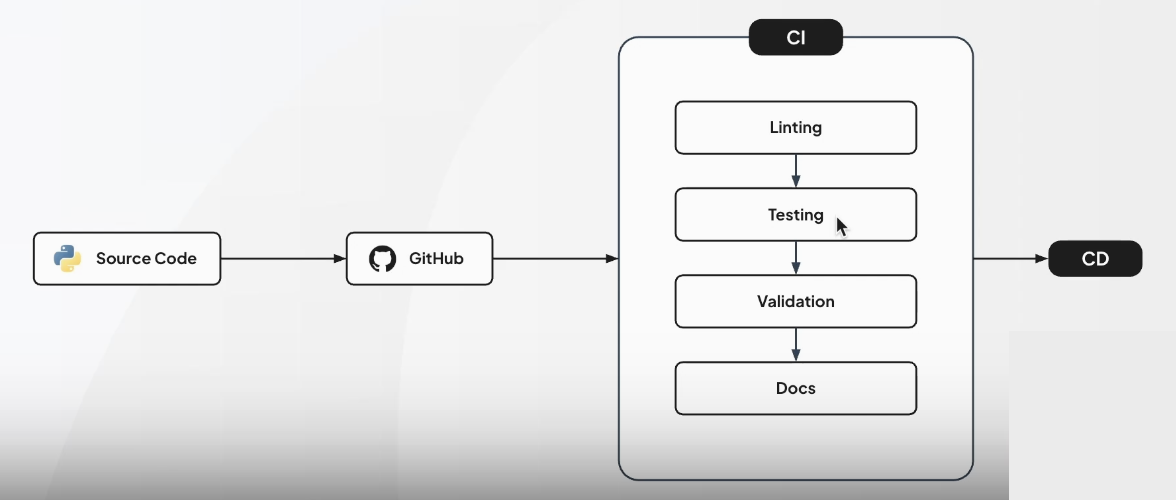
-
CD
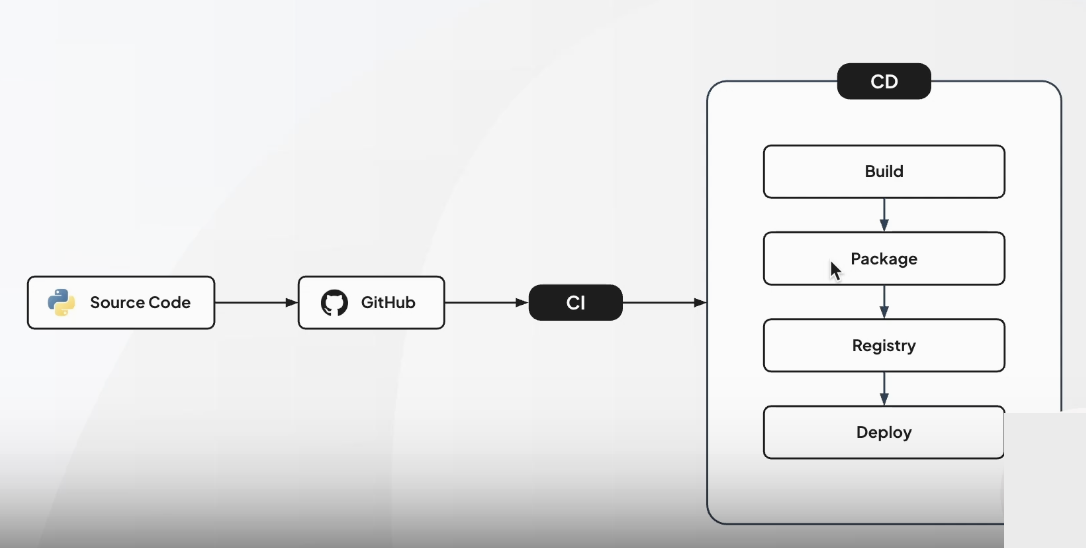
-
CI/CD 워크플로우 구조
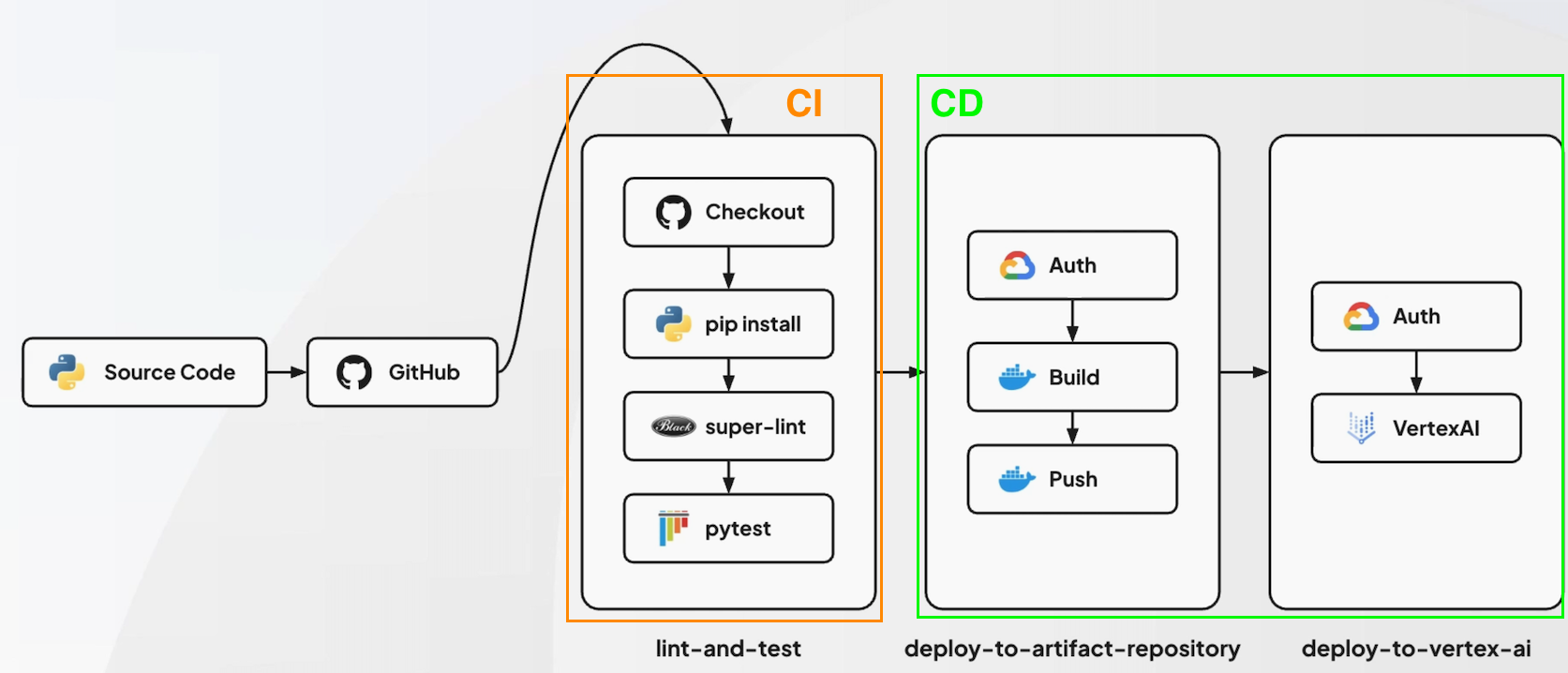
GitHub Actions
- Github에서 제공하는 CI/CD 워크플로우 툴
- yaml로 자동화 파이프라인 구성 가능
Vertex AI 서빙 이점
-
GPU 자원의 효율적 설정
-
초기 비용 및 시간 효율 상승
- 서빙 배포를 하기 위한 클러스터 설정 등에 많은 시간을 할애하지 않아도 됨
-
모니터링, 로깅 등의 검색 설정을 하지 않아도 기본 제공되는 기능으로 해결 가능
-
A/B 테스트 가능

언젠가 내 코드로 세상에 기여할 수 있도록, Data Science&BE 개발 기록 노트☘️