
13-1. 들어가며
학습 목표
- 파이썬에서의 텍스트 데이터 처리 방법 학습
- 파이썬에서의 텍스트 파일 및 디렉터리 접근 방법 학습
- 텍스트 파일 종류와 다루는 방식 학습
학습 내용
-
텍스트 데이터의 문자열 저장
- 인코딩, 디코딩
- 문자열
- 정규 표현식
-
파일, 디렉터리
- 파일
- 디렉터리
- 모듈 및 패키지
-
포맷 파일
- CSV
- XML
- JSON
13-2~4. 텍스트 데이터를 문자열로 저장한다는 것
(1) 인코딩과 디코딩
텍스트 데이터의 표현
- 문자열(string)
- 문자열 리터럴(literal) :
',"로 묶인 문자들
텍스트 데이터의 저장
- 변수에 저장
- 리스트를 이용한 배열 저장
- 따옴표를 이용한 문자열 형태 저장
- 변수에 데이터 할당 시 ➡️ RAM에 저장됨
컴퓨터에서의 데이터 처리
- 컴퓨터에서는 binaray data로 변환되어 다뤄짐(0, 1)
- binaray data
- 최소 단위 : bit(bit 8개 == 1 byte == == 256개의 고유값)
- 메모리에는 byte로 저장
인코딩 & 디코딩
- 인코딩(encoding) : 문자열 ➡️ 바이트 변환
- 디코딩(decoding) : 바이트 ➡️ 문자열 변환
텍스트 데이터 처리 과정
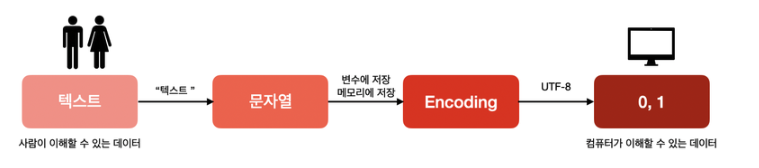
- 사람이 이해할 수 있는 데이터란 : 문자열 데이터(텍스트 데이터)
- 유니코드(Unicode)로 일괄적 변환
- ISO에서 전 세계 문자를 표시할 수 있도록 표준 코드 제정
- 유니코드는 1가지 버전만 존재
🚨 주의 : UTF-8, UFT-16 등은 유니코드로 정의한 텍스트를 메모리에 인코딩하는 방식!
ord(), chr()
- 파이썬 내장 함수
ord(): 해당 문자의 유니코드 숫자 반환chr(): 해당 유니 코드 숫자의 문자 반환
print(ord('a'))
print(ord('A'))
print(chr(97))
print(ord('가'))
print(chr(0xAC00)) #16진수 표현
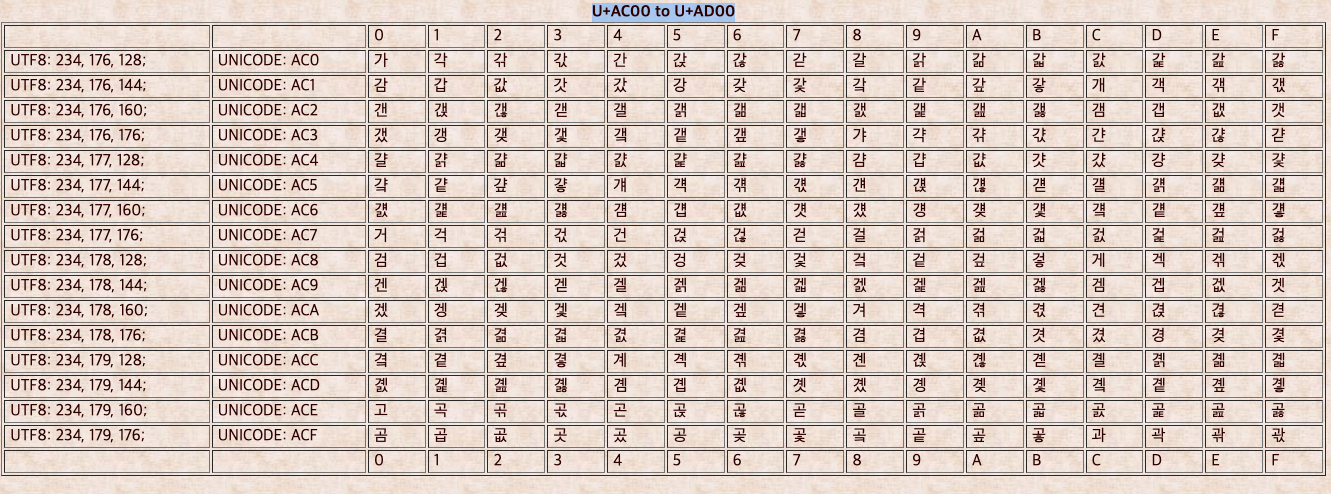
Q. 유니코드 테이블에서의 '가' 코드값은?
A. U+AC00
Python 2 vs Python 3
- 문자열은 python 3부터 유니코드 규약을 따름
- 외부 데이터 or DB로 부터 데이터 read, transfer시 인코딩 또는 디코딩을 해야함
- python 2 : 인코딩 디코딩 여부와 관계없이 (regular) unicolde string으로 사용
- python 3 : 인코딩 or 디코딩 되어 있는지 여부에 따라 구분해 사용
기억해야 할 것
- python 2 : 인코딩 후에도 ascii ➡️ unicode 변환 등 작업 필요
- python 3 : 문자열에 유니코드로 인코딩됨 ➡️ 텍스트의 인코딩 or 디코딩 여부 확인만 하면 됨
(2) 문자열 다루기
s = 'I don't like Python!'➡️ 반드시 작은따옴표만 사용해서 SyntaxError를 해결해야 한다면?
이스케이프 문자
- 문자열 내부에
',",줄바꿈등 특수문자를 포함하되, 이 특수문자가 특수문자가 아닌 것처럼 처리할 떄 사용 \[특정 문자]
| 이스케이프 문자 | 출력 |
|---|---|
| \' | 홑따옴표 ' |
| \" | 겹따옴표 " |
| \t | 탭 |
| \n | 줄바꿈 |
| \ | 백슬래시 \ |
원시 문자열
- 이스케이프 문자 무시하고 싶을 경우 사용
- 따옴표 앞에 r을 붙여 표현
print(r'Please don\'t touch it')
startswith, endswith
-
startswith
- ~로 시작하는 것을 확인하고자 할 때 사용
# OB로 시작하는 직원 ID EmployeeID = ['OB94382', 'OW34723', 'OB32308', 'OB83461', 'OB74830', 'OW37402', 'OW11235', 'OB82345'] Production_Employee = [P for P in EmployeeID if P.startswith('OB')] Production_Employee
-
endswith
- .png, .jpg, .jpeg 등 다양한 확장자 중 .png만 찾고 싶다면?
import os
image_dir_path = os.getenv("HOME") + "/data/pictures"
photo = os.listdir(image_dir_path )
png = [png for png in photo if png.endswith('.png')]
print(png)['image10.png', 'image13.png', 'image14.png', 'image2.png', 'image12.png', 'image8.png', 'image1.png', 'image7.png', 'image11.png', 'image3.png', 'image4.png', 'image6.png', 'image5.png', 'image9.png']trimming: 공백 문자 처리
- 공백 문자
- 스페이스(space) : 한 칸 띄어쓰기
- 탭(tab) : \t(네 칸 띄어쓰기, 가끔 두 칸 띄어쓰기 표기도 됨)
- 줄바꿈(new line)
- 라인 피드 (line feed, 개행) : \n
- 캐리지 리턴 (carriage return, 복귀) : \r(커서를 맨 앞으로 이동 ➡️ 커서의 원위치 return)
- 커서 맨 앞으로 보내기, \r 뒤에 문자가 있다면 그 문자 출력
- 공백 문자 제거
strip(): 양쪽 공백 제거lstrip(): 왼쪽 공백 제거rstrip(): 오른쪽 공백 제거
txt = " Strip white spaces. "
print('[{}]'.format(txt))
print('--------------------------')
print('[{}]'.format(txt.strip()))
print('--------------------------')
print('[{}]'.format(txt.lstrip()))
print('--------------------------')
print('[{}]'.format(txt.rstrip()))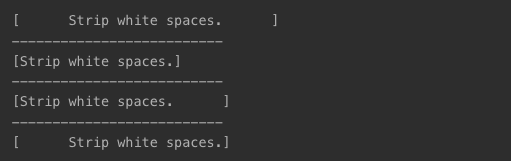
대소문자 변경
upper(): 대문자 변환lower(): 소문자 변환capitalize(): 첫 글자만 대문자로
isX 형태 메서드
boolean 값 반환
isupper()- 문자열이 모두 대문자로 구성된 경우 True
islower()- 문자열이 모두 소문자로 구성된 경우 True
istitle()- 첫 글자만 대문자로 되어 있는 경우 True
isalpha()- 모두 알파벳 문자로만 되어 있는 경우 True
isalnum()- 모두 알파벳 문자와 숫자로만 되어 있는 경우 True
isdecimal()- 모두 숫자로만 되어 있는 경우 True
join()과 split()
- join()
- tuple, list, string 등 iterable(반복 가능)한 객체를 받는 메서드
- 합쳐주는 역할
"구분자".join(stages)
- split()
- 구분자 기준으로 나누는 역할
- 구분자 디폴트 :
,
replace()
replace(s1, s2): s1을 s2로 바꾼다는 의미
불변(immutable)의 문자열
- 가변 객체(mutable object)
- 객체 생성 후 객체 값 수정 ✅
- 변수 : 값 수정된 같은 객체
- list, set, dict
- 불변 객체(immutable object)
- 객체 생성 후 객체 값 수정 ❌
- 변수 : 해당 값을 가진 다른 객체
- int, float, complex, bool, string, tuple, frozen set
id() 메서드
- 객체의 고유 id 확인
Q. 두 개의 id(sent) 값이 다른 이유?
sent = 'I fell into AIFFEL' print(sent) print(id(sent)) sent = sent.upper() print(sent) print(id(sent))A. string은 불변 객체이기 때문에, 변수가 새로운 객체로 대체되었기 때문
(3) 정규 표현식
정규 표현식
- 특정 규칙을 가진 문자열 집합 표현 형식 언어
- 문자열 패턴 정의
- 기존 문자열과 일치 여부 비교(문자열 검색 or 문자열 치환)
- 매번 문자열 메서드를 사용하는 것보다 효율적

- 모듈 :
import re - 단계
- 찾으려는 문자열 패턴 정의(
Compile()) - 그 패턴과 매칭되는 경우를 찾아 처리
- 찾으려는 문자열 패턴 정의(
Complie()
- "찾으려는 문자열 패턴 정의" 단계 :
re.compile("[문자열]")re.findall()로 바로 처리 가능
메서드
- "그 패턴과 매칭되는 경우를 찾아 처리" 단계에 사용되는 메서드
search(): 일치하는 패턴 찾음- 일치 패턴이 있으면 ➡️ MatchObject 반환
match(): 처음부터 패턴이 검색하려는 대상과 일치해야함findall(): 일치하는 모든 패턴 찾음- 패턴들을 리스트에 담아 반환
split(): 패턴으로 나눔sub(): 일치 패턴으로 대체group(): 실제 결과 문자열 반환
src = "My name is..."
regex = re.match("My", src)
print(regex)
if regex:
print(regex.group())
else:
print("No!")
패턴 : 특수문자, 메타 문자
| 패턴 | 설명 |
|---|---|
[ ] | 문자 클래스 - 대괄호 안에 있는 문자 중 하나 |
- | 범위 지정 |
. | 임의의 한 문자 |
? | 0회 또는 1회 반복 |
* | 0회 이상 반복 |
+ | 1회 이상 반복 |
{m, n} | 최소 m회, 최대 n회 반복 |
\d | 숫자 (0-9) |
\D | 비숫자 ([^0-9]) |
\w | 알파벳, 숫자, 밑줄 ([a-zA-Z0-9_]) |
\W | 비 알파벳, 비숫자 ([^a-zA-Z0-9_]) |
\s | 공백 문자 (스페이스, 탭, 개행 등) |
\S | 비공백 문자 ([^ \t\n\r\f\v]) |
\b | 단어 경계 |
\B | 비 단어 경계 |
\t | 가로 탭 (tab) |
\v | 세로 탭 (vertical tab) |
\f | 폼 피드 (페이지 구분 문자) |
\n | 개행 문자 (newline) |
\r | 캐리지 리턴 (줄의 시작으로 이동, Windows에서는 \r\n 조합으로 사용) |
-
예시1 : 1000년 이후의 모든 연도를 찾고 싶다면?
re.compile("[1-2]\d\d\d")- 1000년 이후 -> 맨 앞자리는 1 또는 2
- 나머지 숫자 3개 연달아 -> \d 3개
-
예시2 : 이메일
re.compile("[0-9a-zA-Z]+@[0-9a-z]+\.[0-9a-z]+")[0-9a-zA-Z]+: 숫자 0~9, 알파벳 대소문자(0-9a-zA-Z) 여러 차례(+) 나옴[0-9a-z]+: 숫자 0~9, 알파벳 소문자 여러 차례
정규 표현식 구현 순서
- import re
- re.compile() 함수 ➡️ Regex 객체 생성
- 검색할 문자열 처리 : Regex 객체의 search() , findall() 메서드
13-5~7. 파일과 디렉터리
(1) 파일
write
f = open("hello.txt","w")
for i in range(10):
f.write("안녕")
f.close()
print("완료!")read
- 생성한
hello.txt읽어들이기- with로 오픈된 객체는 with문 종료 시 close가 자동 보장됨
- close 명시 필요 없음
- with로 오픈된 객체는 with문 종료 시 close가 자동 보장됨
with open("hello.txt", "r") as f:
print(f.read())
파일 관련 메서드
f.read(): 파일 읽기f.readline(): 1줄씩 읽기f.readlines(): 모든 줄 읽기 -> 값을 리스트로 반환f.write(str): 입력(문자열 타입을 인자로 받음)f.writelines(str): 인자를 1줄씩 작성f.close(): 파일 닫음f.seek(offset): 파일 위치 찾아서 커서 옮기기(처음 위치는 0)f.tell(): 현재 커서 위치 반환
quotes = ["\n안녕하세요.\n", "반갑습니다.\n", "오랜만입니다.\n"]
with open("hello.txt", "a") as f:
f.writelines(quotes)
with open('hello.txt', 'r') as f:
hello = f.readlines()
print(f'위치 : {f.tell()}')
print(hello)
print("----------------------------------------------------")
f.seek(10)
print(f'위치 : {f.tell()}')
(2) 디렉터리
최상위 폴더
-
루트 디렉터리(root directory)
- windows :
C:\ - Linux 계열 :
/
- windows :
-
- /home : 사용자 계정 정보(사용자 추가 시마다 그 이름으로 디렉터리 생성)
- /bin : 사용자들이 공동으로 사용할 수 있는 실행 파일들을 보관해두는 곳(모든 유저 기준)
- /sbin : Admin 계정이 사용하는 실행 파일들 보관
- /mnt : 장치를 연결해서 사용하는 곳
- /usr : 프로그램 설치
- /etc : 설치된 프로그램 초기 설정 보관
- /var : 프로그램이 실행되면서 만들어지는 값들 저장
- /tmp : 데이터 임시 저장
- /sys : 시스템 설정
(3) 모듈과 패키지
파이썬 디렉터리 관련 표준 라이브러리
- sys
- os
- glob

개념
모듈(module): 파이썬 코드 파일(.py)패키지(package): 라이브러리, 모듈 집합(폴더)라이브러리(library): 모듈, 패키지 집합PIP(Package Installer for Python): 패키지 관리 도구PyPA(Python Packaging Authority): 파이썬 패키지 관리 및 유지 그룹PyPI(The Python Package Index): 파이썬 패키지 저장소
함수
sys.path: 현재 폴더, 파이썬 모듈 저장 위치 ➡️ 리스트로 반환sys.path.append(): 모듈 경로 추가os.chdir(): 디렉터리 위치 변경os.getcwd(): 현재 디렉터리 위치 반환os.mkdir(): 디렉터리 생성os.rmdir(): 디렉터리 삭제(디렉터리 삭제는 그 안이 비어있을 때에만 가능)glob.glob(): 그 경로 안 디렉터리 or 파일 ➡️ 리스트로 반환os.path.join(): path 병합 ➡️ 새 경로 생성os.listdir(): 디렉터리 안 파일, 서브 디렉터리 ➡️ 리스트로 반환os.path.exists(): 파일 or 디렉터리 경로 존재 여부 확인os.path.isfile(): 파일 경로 존재 여부 확인os.path.isdir(): 디렉터리 경로 존재 여부 확인os.path.getsize(): 파일 크기 확인
13-8~10. 여러가지 파일 포맷 다루기
(1) CSV 파일
CSV란?
- Comma Seperated Value
- 컬럼을 쉼표로 구분
CSV 파일과 Pandas

-
to_csv: csv 파일로 저장 가능csv.writer로도 사용 가능
import csv filename = "test.csv" with open(filename, 'w+', newline='\n') as csv_file: csv_writer = csv.writer(csv_file) csv_writer.writerow(fields) csv_writer.writerows(rows) print("완료") -
read_csv: csv 파일을 DataFrame으로 변환
(2) XML 파일
XML?
- Extensible Markup Language
- 다목적 마크업 언어
<>(태그)로 구분<열린 태그> 내용 </닫힌 태그>로 구성- 태그에 속성이 포함되기도 함
- 계층적 구조 : 상위(부모) 태그 - 하위(자식) 태그
- 요소(element)들로 이뤄짐
- API에서 데이터를 요청 및 저장 시 JSON과 함께 사용
XML 파일 생성
-
ElementTree
- 파이썬 표준 라이브러리(XML 관련 기능 제공)
Element(): 태그 생성SubElement(): 자식 태그 생성tag: 태그 이름text: 텍스트 내용 생성attrib: 속성 생성
- 파이썬 표준 라이브러리(XML 관련 기능 제공)
-
dump()
- 생성된 XML 요소 구조 ➡️ 시스템에 사용
- 출력 : 일반 XML
write(): XML 파일로 저장append(),insert(),remove(),pop(): 리스트(list)와 메서드 유사
import xml.etree.ElementTree as ET
person = ET.Element("Person")
name = ET.Element("name")
name.text = "이펠"
person.append(name)
age = ET.Element("age")
age.text = "28"
person.append(age)
ET.SubElement(person, 'place').text = '강남'
ET.dump(person)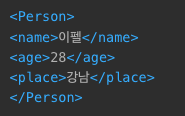
- 속성값, 태그명 변경 :
attrib,tag
person.attrib["id"] = "0x0001"
name.tag = "firstname"
ET.dump(person)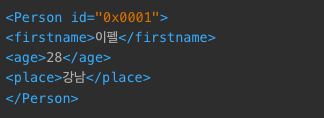
- 새로운 태그 생성 :
.insert- lastname 태그를 firstname 태그 뒤에 삽입
- 속성 : date
lastname = ET.Element('lastname', date='2020-03-20')
lastname.text = '아'
person.insert(1,lastname)
ET.dump(person)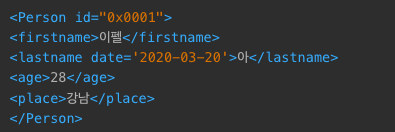
- 태그 삭제 :
remove()orpop()
- remove() : 리스트 요소 제거 시 값으로 제거
- pop() : 리스트 요소 제거 시 인덱스로 제거
XML 파싱
파싱 : 문자열을 의미있는 토큰으로 분해, 문법적 의미 및 구조 반영한 parse tree 생성
- 이미지 출처 : XML의 파싱 - 파스 트리
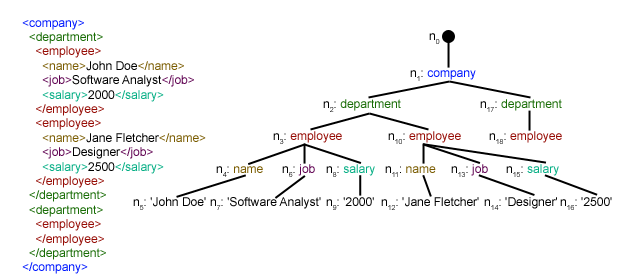
- 파이썬에서의 XML 파싱
- ElementTree
- BeautifulSoup
- BeautifulSoup
- 설치 : beautifulsoup4, lxml
- books.xml 파일에서 "title" 태그 내용만 가져오기
# 클라우드 환경 : 심볼릭 링크 걸어서 aiffel 폴더로 가져오기
$ mkdir -p ~/aiffel/ftext/data/
$ ln -s ~/data/books.xml ~/aiffel/ftext/datafrom bs4 import BeautifulSoup
import os
path = os.getenv("HOME") + "/aiffel/ftext/data/books.xml"
with open(path, "r", encoding='utf8') as f:
booksxml = f.read()
soup = BeautifulSoup(booksxml,'lxml')
for title in soup.find_all('title'):
print(title.get_text())
(3) JSON 파일
- JavaScript Object Notation
- JavaScript 데이터 객체 표현 방식
- 웹 - 애플리케이션의 HTTP 요청으로 데이터 보낼 때 사용(표준 파일 포맷)
- csv 파일보다 유연하게 데이터 표현 가능, xml보다 파일 쉽게 읽고 쓸 수 있음
- JS 기반 프로그램에서 강함
person = {
"first name" : "Yuna",
"last name" : "Jung",
"age" : 33,
"nationality" : "South Korea",
"education" : [{"degree":"B.S degree", "university":"Daehan university", "major": "mechanical engineering", "graduated year":2010}]
} JSON 파싱
- JSON 파일 저장
import json
person = {
"first name" : "Yuna",
"last name" : "Jung",
"age" : 33,
"nationality" : "South Korea",
"education" : [{"degree":"B.S degree", "university":"Daehan university", "major": "mechanical engineering", "graduated year":2010}]
}
with open("person.json", "w") as f:
json.dump(person , f)- JSON 파일 읽기
import json
with open("person.json", "r", encoding="utf-8") as f:
contents = json.load(f)
print(contents["first name"])
print(contents["education"])Yuna
[{'degree': 'B.S degree', 'university': 'Daehan university', 'major': 'mechanical engineering', 'graduated year': 2010}]
언젠가 내 코드로 세상에 기여할 수 있도록, Data Science&BE 개발 기록 노트☘️