[이론 내용만] Node 01. Data cleaning - 타이타닉 데이터 다루기
☺️ AIFFEL 데이터사이언티스트 3기

1-1. 들어가며
학습목표
- 결측치 처리
- 이상치 처리
- 시간 데이터 및 텍스트 데이터 변환하기
1-2. 파이썬으로 데이터 둘러보기
경로 설정 및 데이터 불러오기
-
현재 데이터는 결측치 및 이상치 제거 작업을 위해 일부 가공되어 있음.
-
현재 위치 포함도 가능
- csv 파일을
data로 지정해서 편리하게 불러올 것.
- csv 파일을
data 폴더 안에는 새 파일을 만들 수 없음.
- 그 이유는 뭘까?
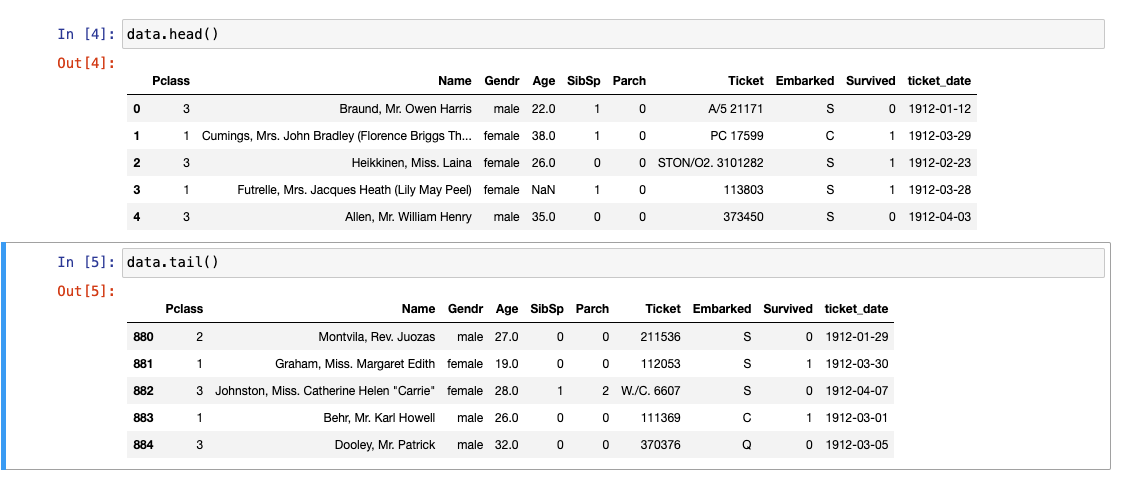
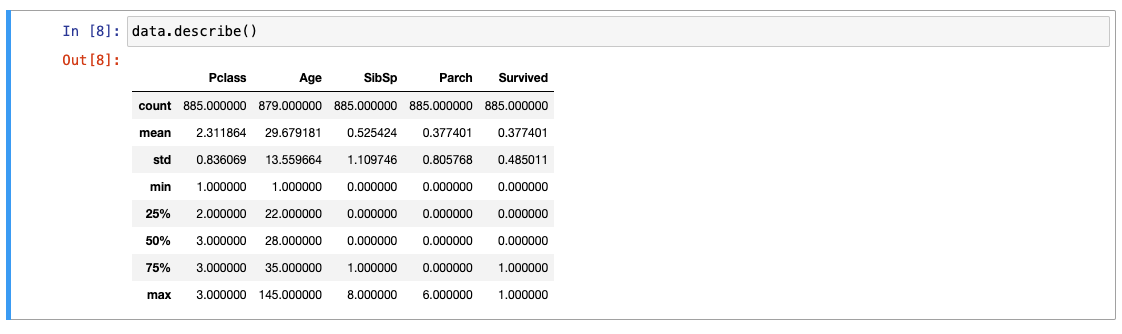
- 원하는 데이터만 확인하기 : head(), tail()
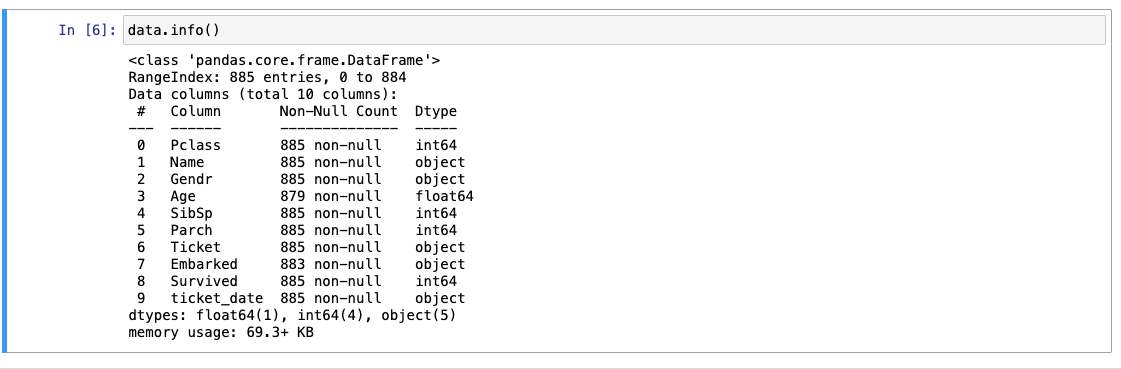
- 정보 확인 : info(), describe()
- Non-Null Count: 빈 값이 없는 데이터가 몇 개인지
- describe는 통계적 요약을 제공
-
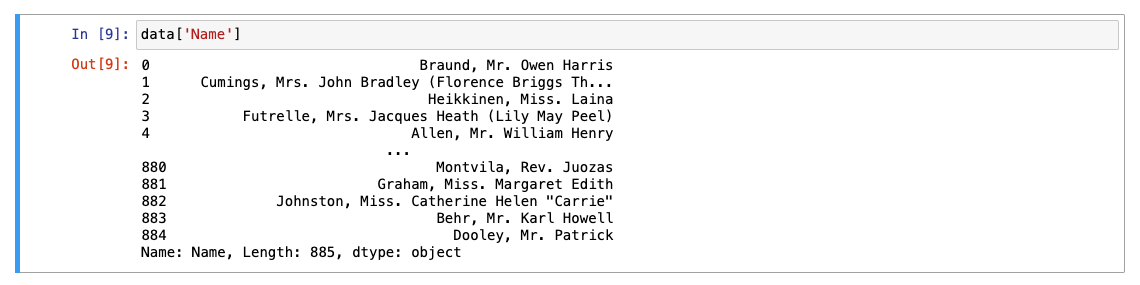
판다스 시리즈 형태: ex)특정 칼럼 볼 때(대신 컬럼 2개 이상 불러올 수 x)
-
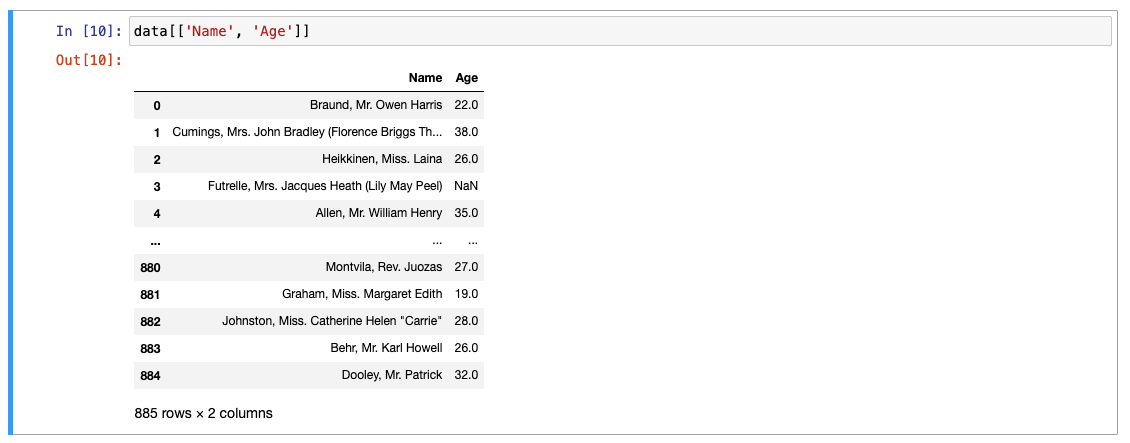
2개 이상 보려면 -> 리스트로 묶기
-
판다스 시리즈 -> 판다스 프레임으로 강제 변경
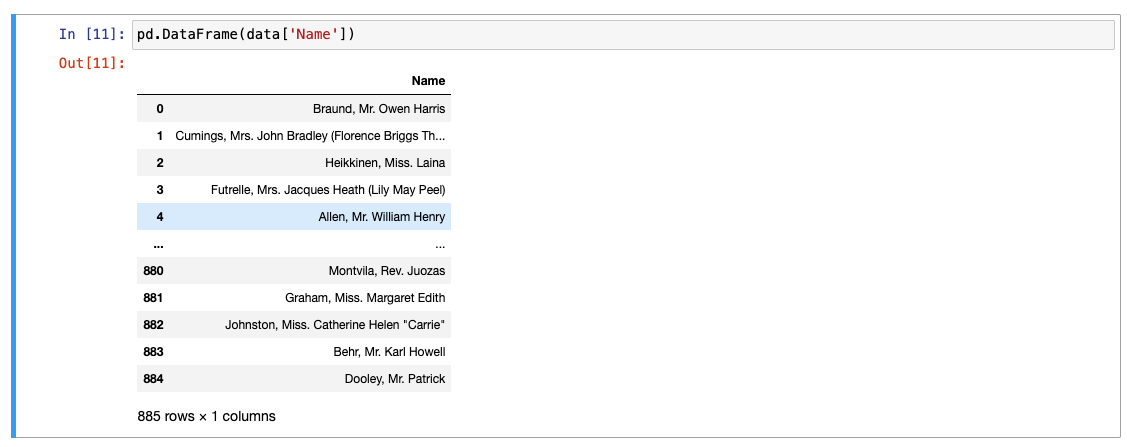
-
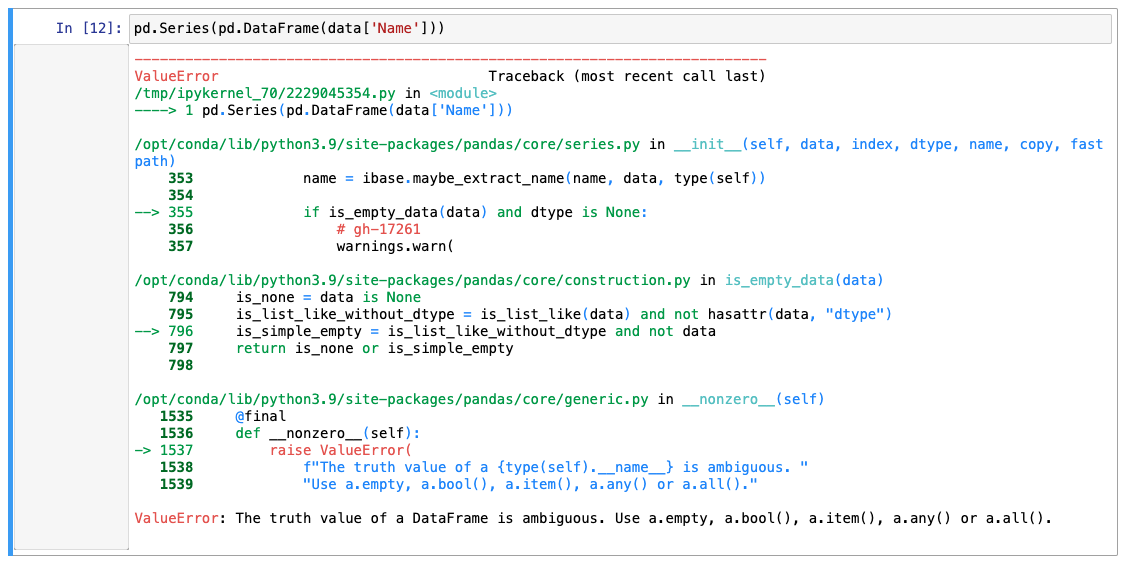
판다스 프레임 -> 판다스 시리즈로 강제 변경
- 시리즈는 기본적으로 1개의 컬럼만 가능
- 프레임의 경우 정의 자체가 1개의 컬럼이 아님 -> 에러!
- 다시 칼럼명으로 인덱싱을 다시 해주면 됨!
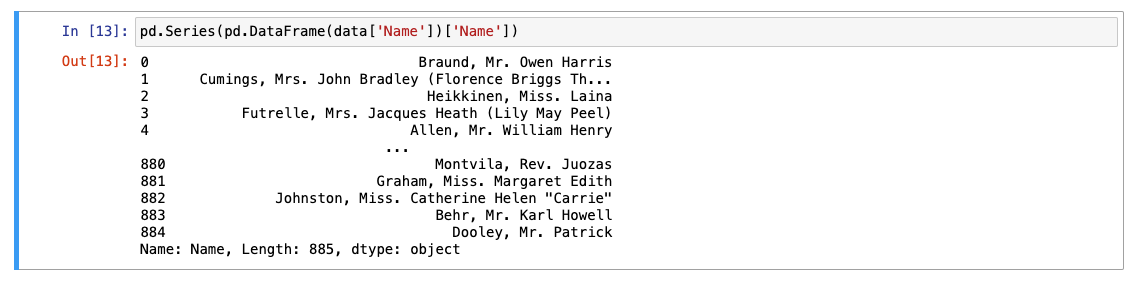
판다스 메서드 대표 10개
-
.describe()- DataFrame 및 Series 객체 요약 통계
-
.apply()- 함수 -> 데이터프레임의 행렬에 적용
-
.sort_values()- DataFrame 및 Series 객체 데이터 정렬(오름차순, 내림차순, 복수열 기준 가능)
-
.tail()- DataFrame 및 Series 객체 끝부터 지정 행 반환
-
.replace()- 특정 값 -> 다른 값으로 대체
-
pd.to_numeric()- 숫자형(정수형 또는 부동소수점형)으로 데이터 변환
-
.get_dummies()- 기존 열을 바탕으로 새로운 이진열 생성
-
Aggregation- 여러 데이터 포인트 요약, 그룹화
- ex) groupby(), 집계 함수, std(), agg()..
-
.merge()- 2개 이상 데이터 프레임 병합
- 특정 공통 열, 인덱스 기준(SQL JOIN과 유사)
-
.value_counts()- 범주형 데이터 요약
1-3. 불필요한 컬럼 삭제 (Dropping columns), 누락된 결측치 처리 (Missing values)
생존 예측에는 랜덤 넘버들(고객 ID, 주민번호, 전화번호) 불필요!
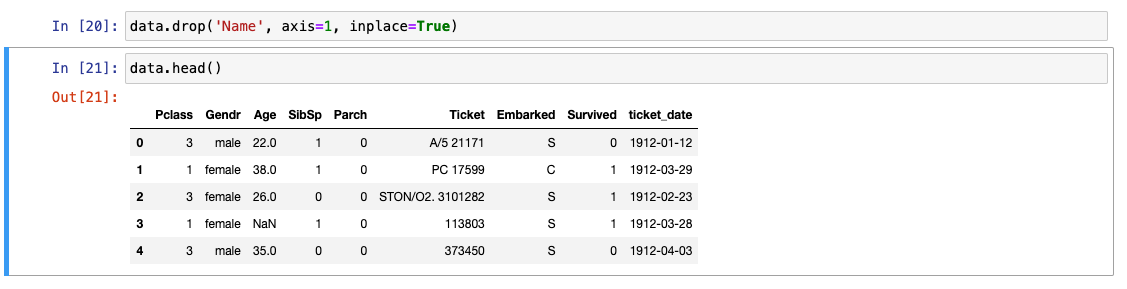
Drop
-
KeyError : 기본적으로 drop은 기본축으로 데이터를 찾음. -> 축 변경해야함!

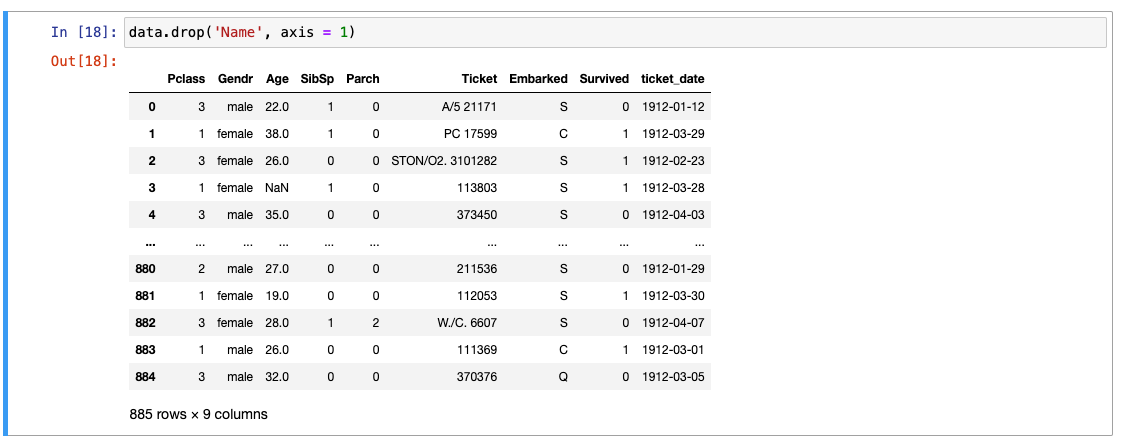
-
하지만, head 찍으면 다시 살아남.
- 기본적으로 바로 덮어쓰기는 안되기 때문

- 기본적으로 바로 덮어쓰기는 안되기 때문
-
덮어쓰기 허용으로 바로 적용하기
-
동시 제거
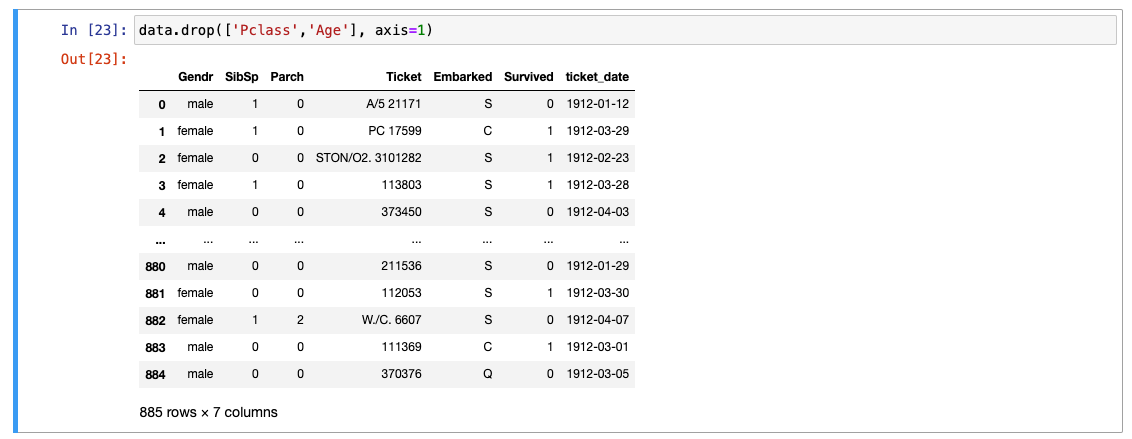
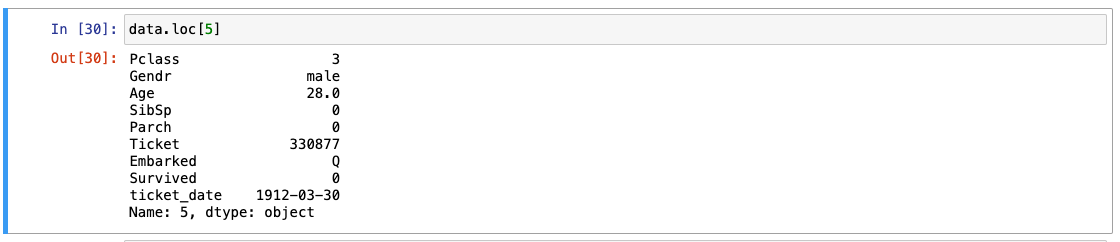
loc, iloc : 특정 줄 소환
-
여러 개는 리스트로 묶자!
-
iloc은 줄의 이름(4, 5, 6 등)을 기반으로 불러옴.

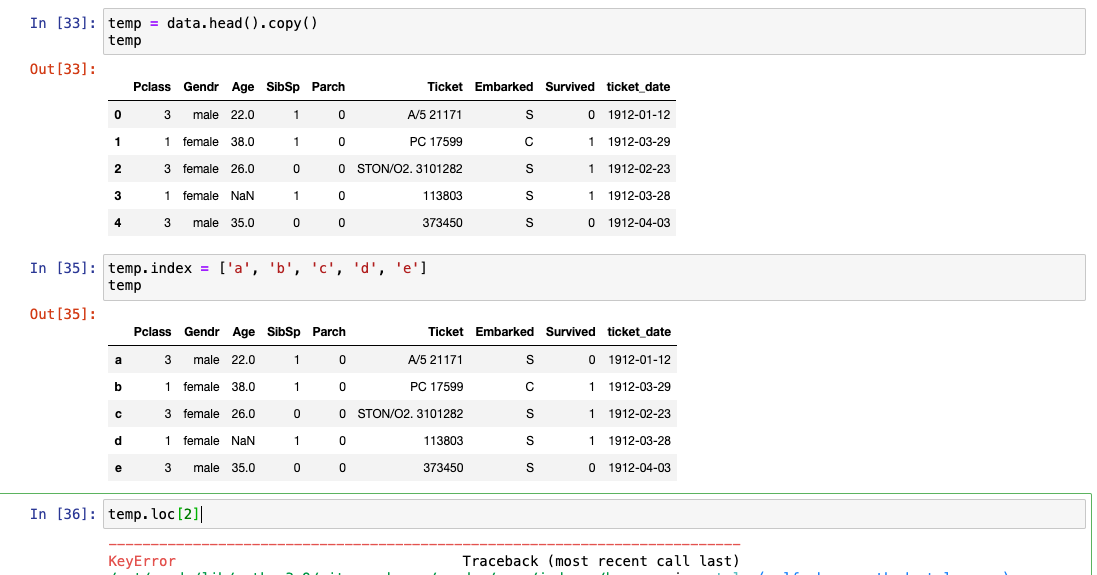
-
이름을 바꿔서 어떻게 다르게 동작하는지 살펴보기
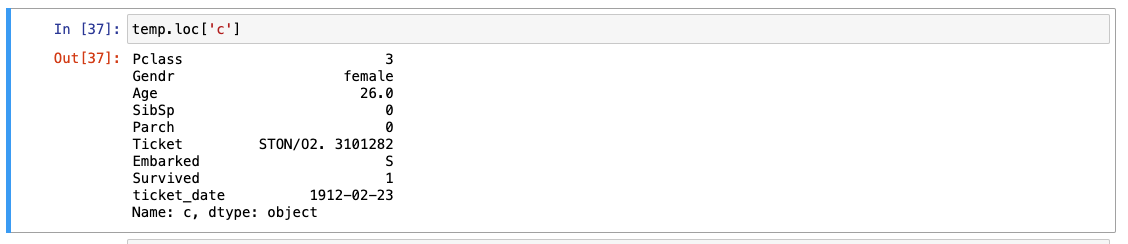
.isna() : 결측치 확인
-
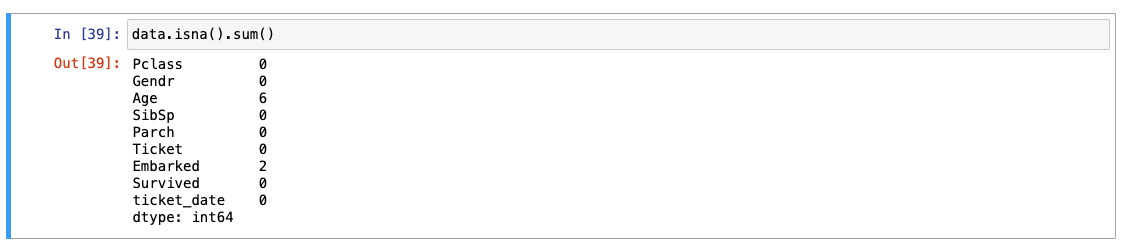
.isna().sum() -> 결측치 개수의 합이 나옴!
-
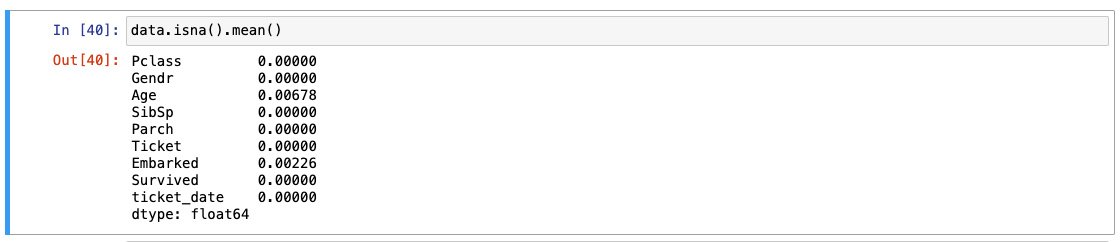
.isna().mean() -> ⭐️비율⭐️
-
Null 값 확인
- 리스트로 묶어서 True만 빠르게 확인

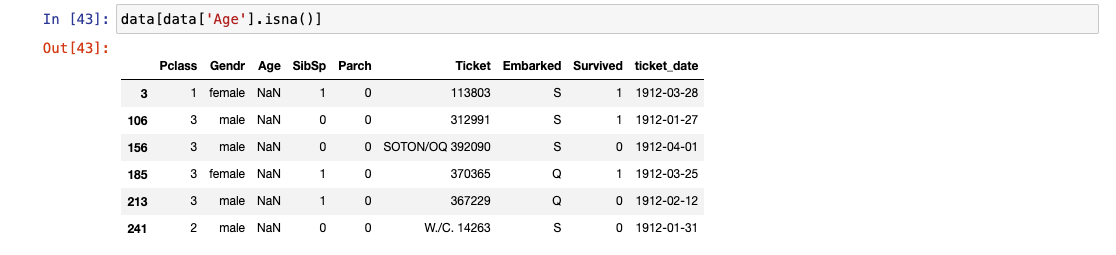
- 리스트로 묶어서 True만 빠르게 확인
-
index로 묶어서 저장

-
Age, Embarked

.dropna()
-
결측치 제거
-
특정 컬럼 기준
.mean(), .median()
- median이 더 안전 -> 아웃라이어(이상치)로 인해 평균이 크게 치우칠 수 있기 때문

fillna
- 가수(가짜 수) 채워넣기


.value_counts()

-
S의 경우, 약 72% 차지

-
가수 채워넣기
1-4. 이상치 탐지 및 처리 (Outliers)
.describe()
- 이상치 어느정도 파악 가능

.sort_values()
-
Age 아웃라이어 의심 -> 145 값
- sort_values로 오름차순 정렬
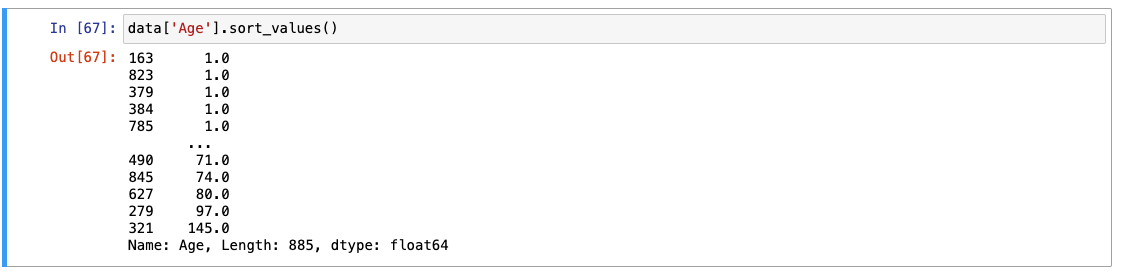
- sort_values로 오름차순 정렬
-
참고) 내림차순 정렬: ascending = False 사용
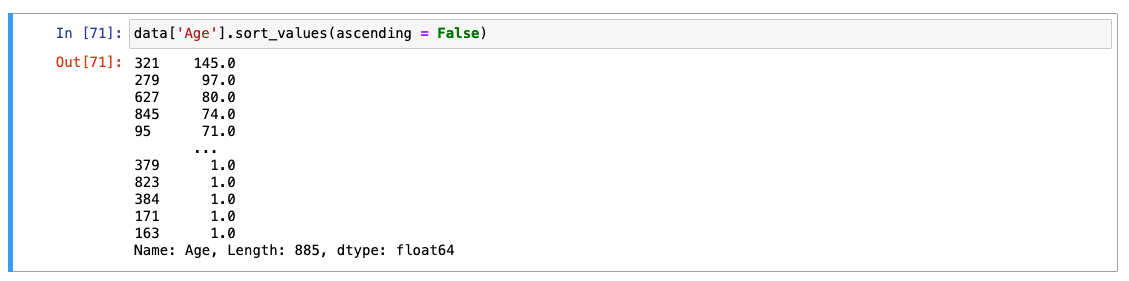
-
SibSp도 확인

pyplot 사용해보기
-
첫번째 방법 : displot
-
SibSp
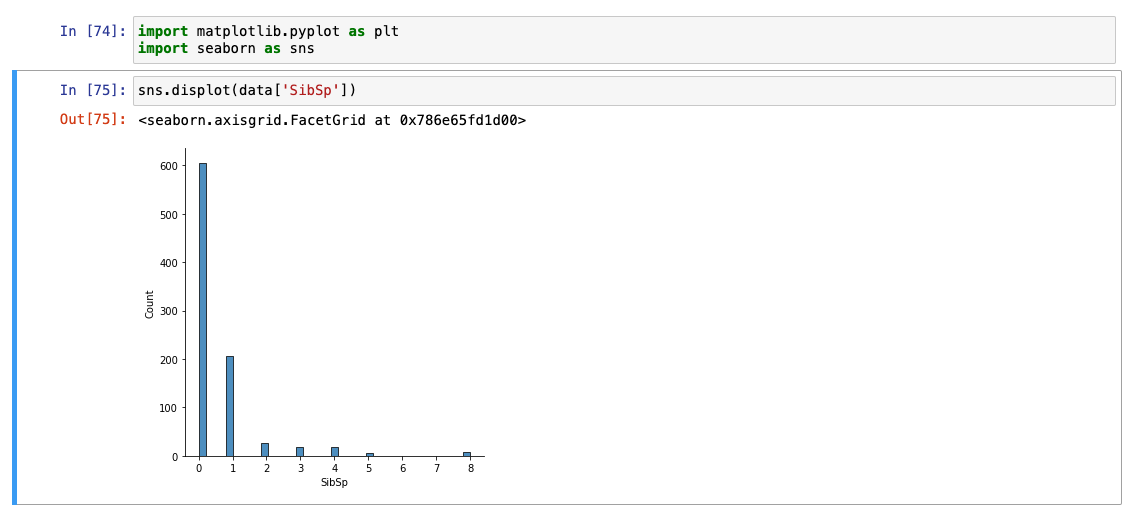
-
Age
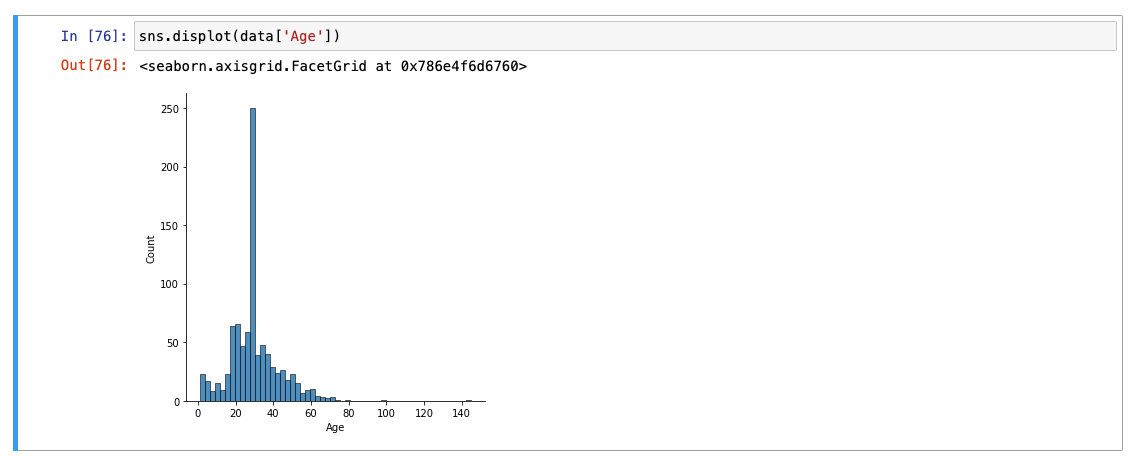
문제점 : x축 값으로 데이터가 어디까지 맥시멈으로 퍼져있는지는 짐작이 가능하지만, x축 값 사이에 몇 개의 데이터가 계속 이어져 있는 것인지 혹은 그 사이 값이 아예 없는지 여부는 바로 알아차리기 어렵다!
-
-
두번째 방법 : scatterplot - 판정도 그리기(x축, y축 값 지정 필요)
-
SibSp
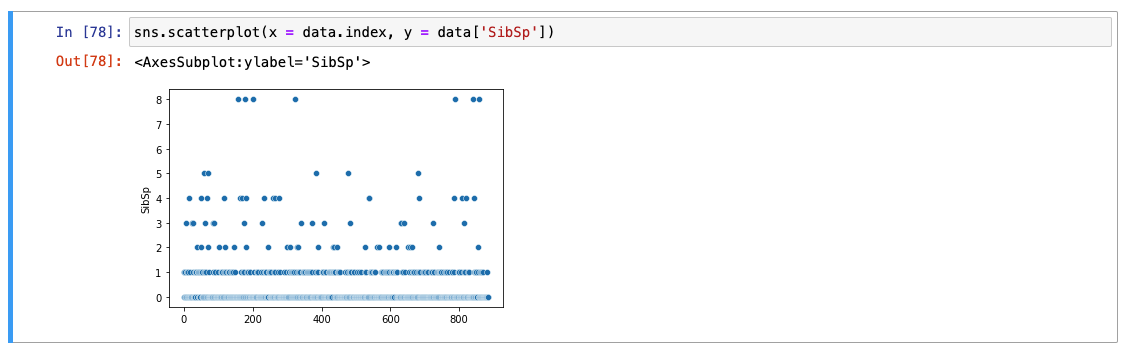
-
Age

-
-
세번째 방법 : boxplot
-
🚨 단점 : 극단적으로 값을 처리해서 이상치를 너무 많이 덜어내는 문제가 있음.
-
SibSp
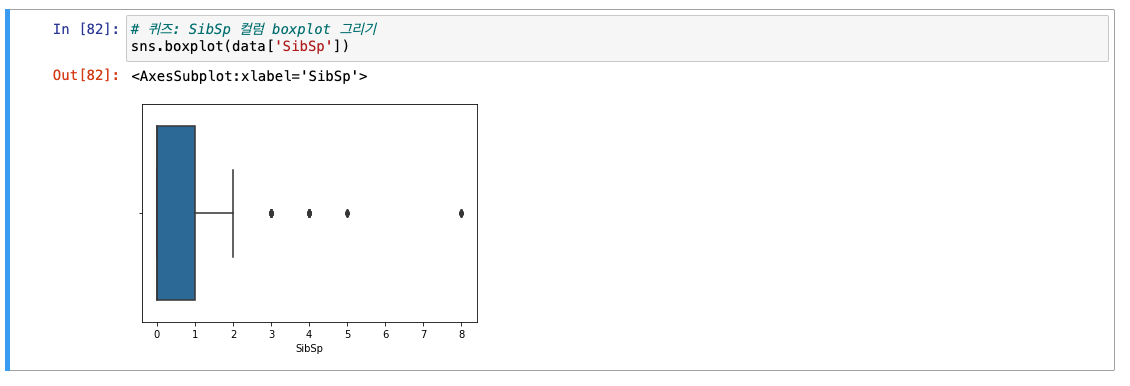
-
Age
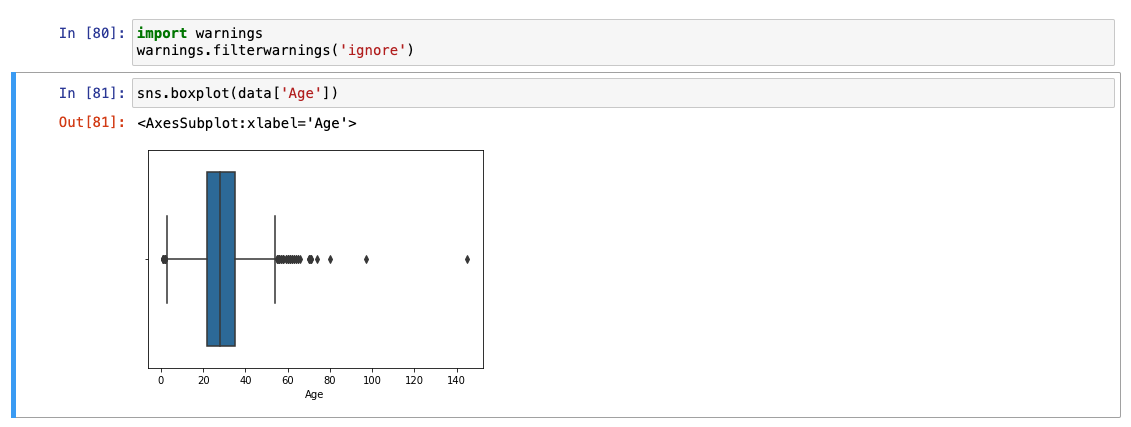
-
보는 방법 : 아래의 그림에서 시작점과 끝점을 벗어나 기준을 벗어나는 값이 아웃라이어!
- IQR : 75% - 25%
- 시작점과 끝점 : IQR * 1.5로 계산
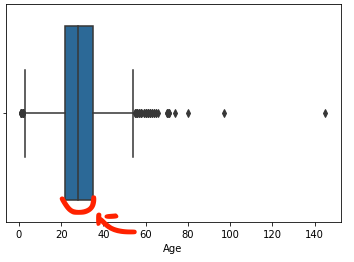
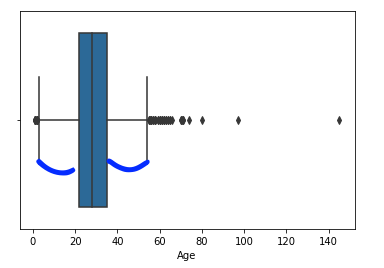
Age의 특정 데이터는 이상치로 판단했기 때문에, 제거!
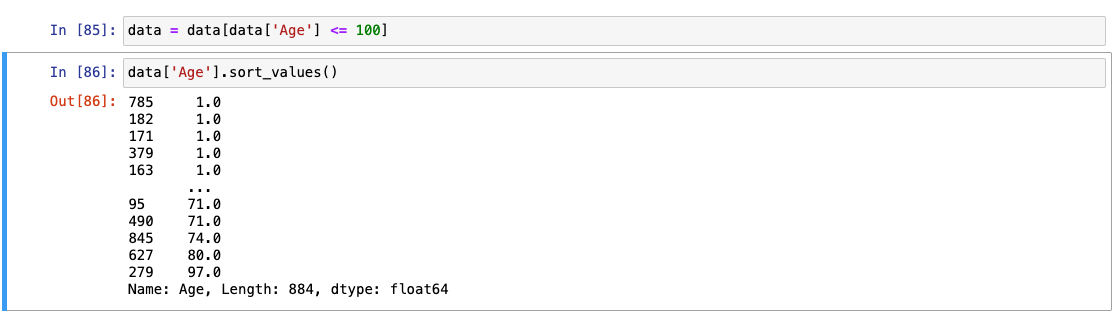
-
간단한 머신러닝 모델을 사용한다고 간주하고 애매한 97값 조정
-
80세 이상 값은 80으로 변환
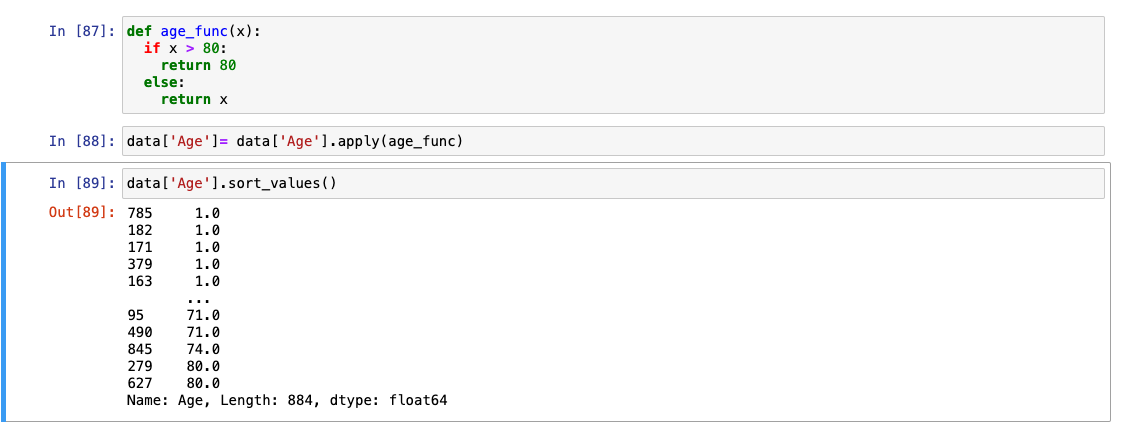
-
70 값도 반영
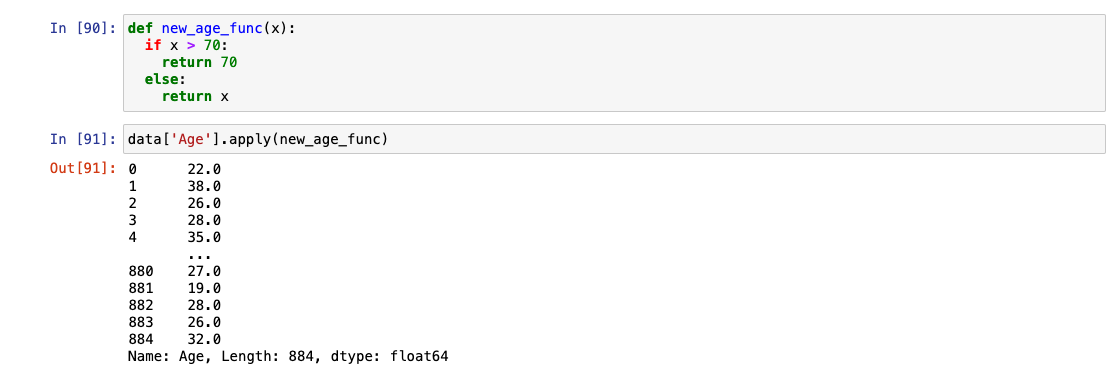
-
바로 적용하는 방법(람다 함수 사용)
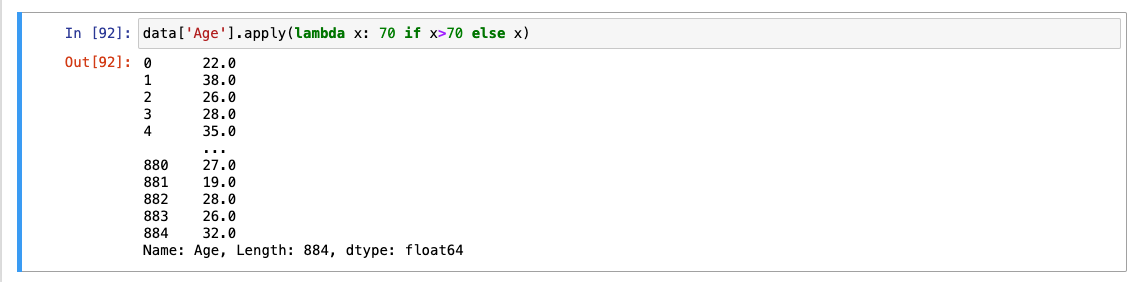
-
1-5. 중복 데이터 처리 및 데이터 형태 변환처리(Removing duplicate data, apply, map, replace, rename)
상황 가정 : 중복된 데이터로 보여 이름을 부득이하게 삭제한 케이스
- 데이터 클리닝 이전 상황으로 돌아와 중복 데이터 확인 및 제거
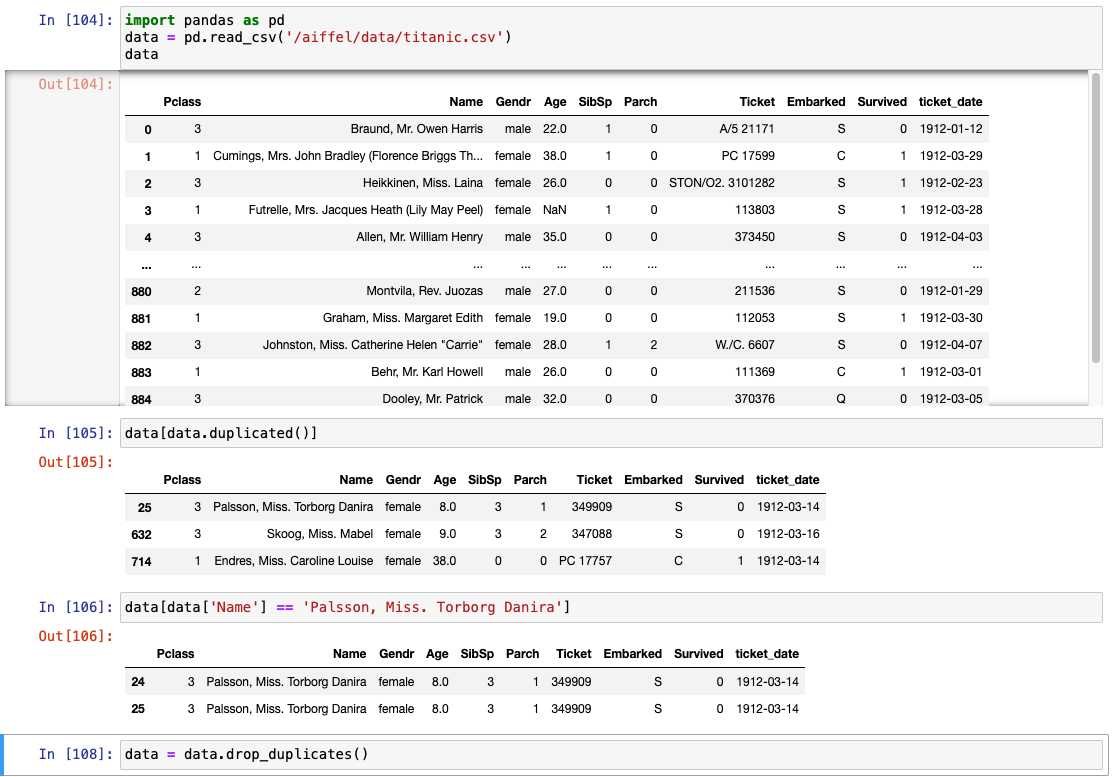
.rename()
- 컬럼명 변경
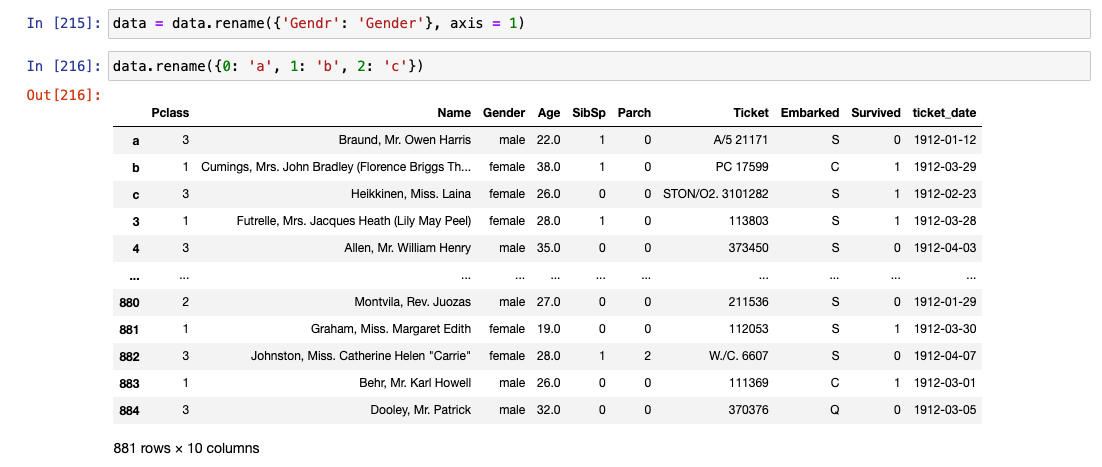
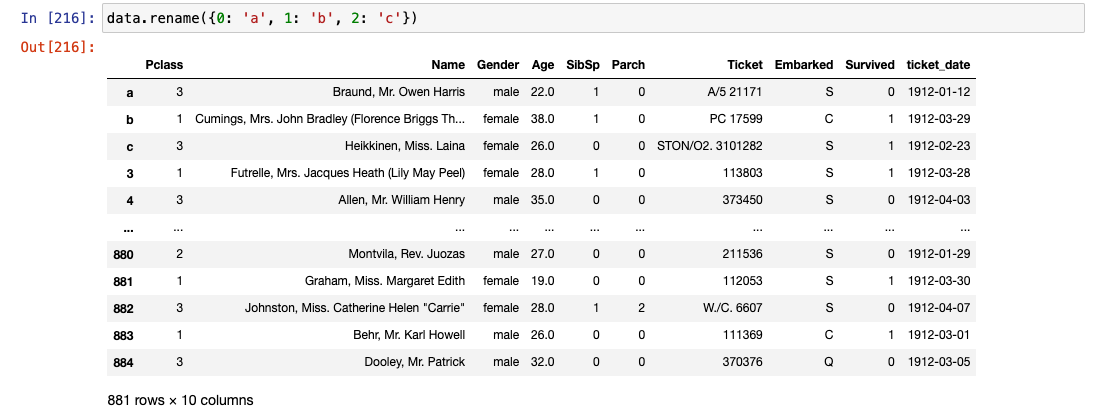
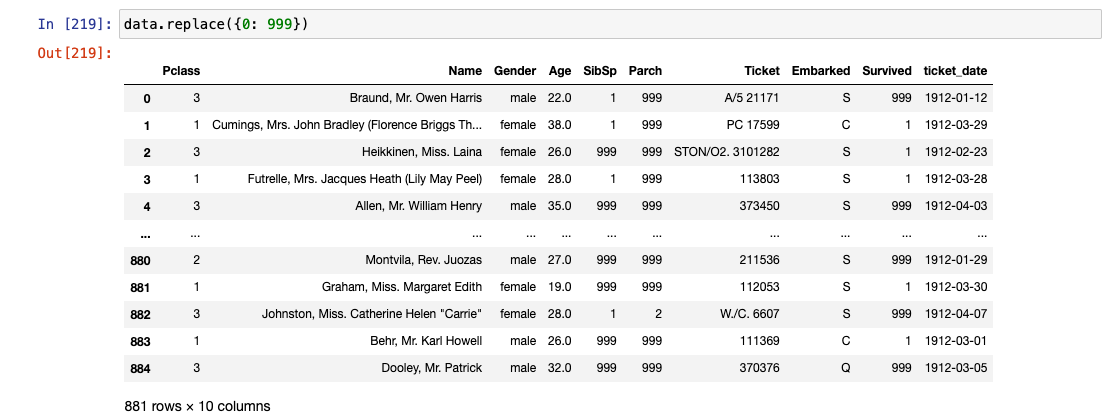
.replace()
- 데이터 값의 이름 변경(숫자 가능)
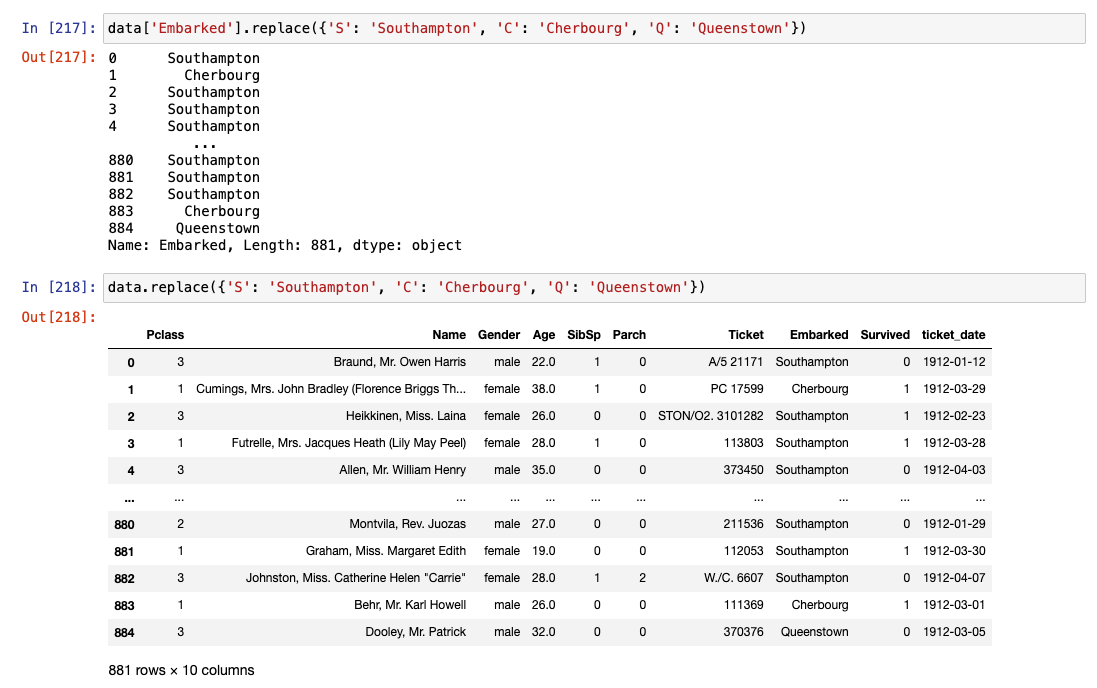
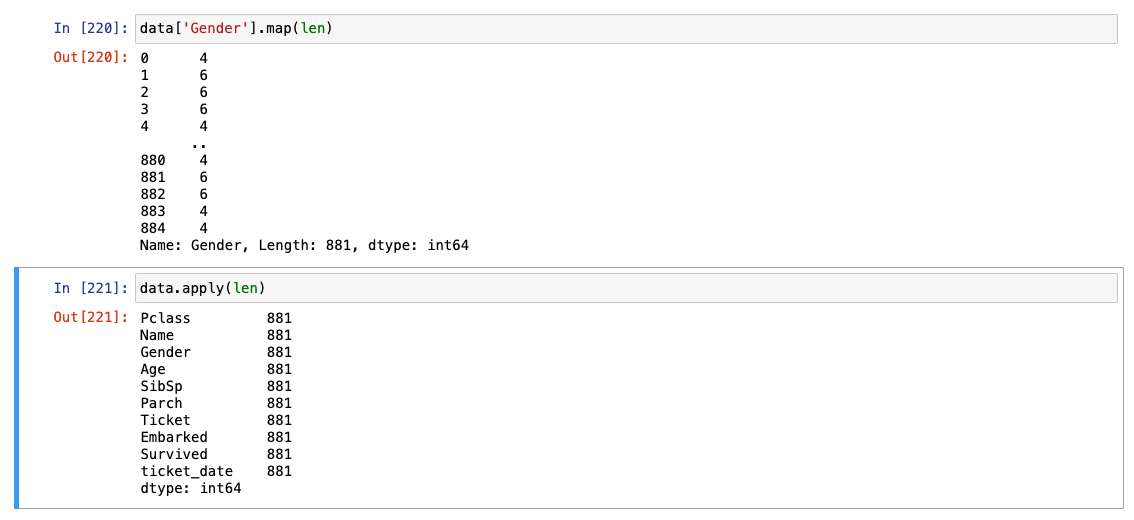
.map()
replace는 판다스 프레임, 시리즈 둘 다 가능하나, map은 시리즈에서만 작동
1-6. 텍스트 처리 (Text handling)
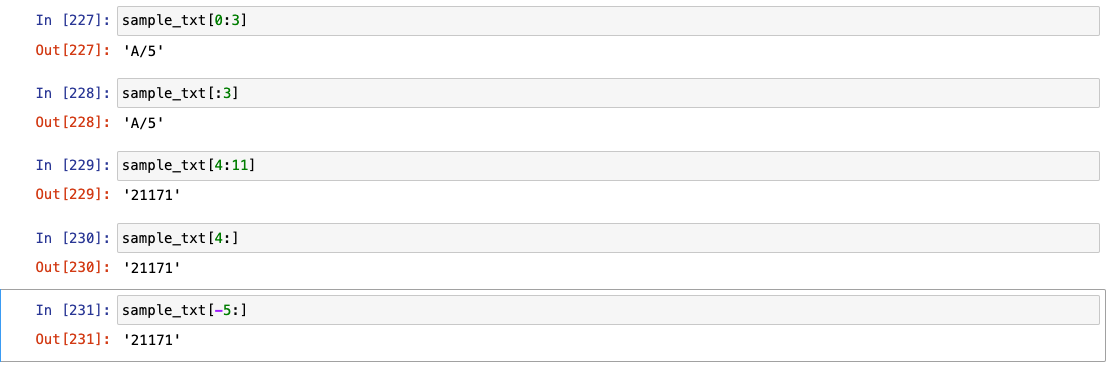
샘플 텍스트로 텍스트 처리 배우기

-
자릿수별로 인덱싱
-
lower : 문자를 소문자로 변경

-
upper : 문자를 대문자로 변경

-
lower로 바꾼 텍스트를 다시 upper로 바꾸기 -> 이어서 작성하면 됨.

-
split : 문자열 자르기

- strip : 무의미한 띄어쓰기 제거

Ticket 컬럼 테스트 처리
-
단순 인덱싱으로 원하는 결과가 안나올 것임.

-
데이터 우선 확인
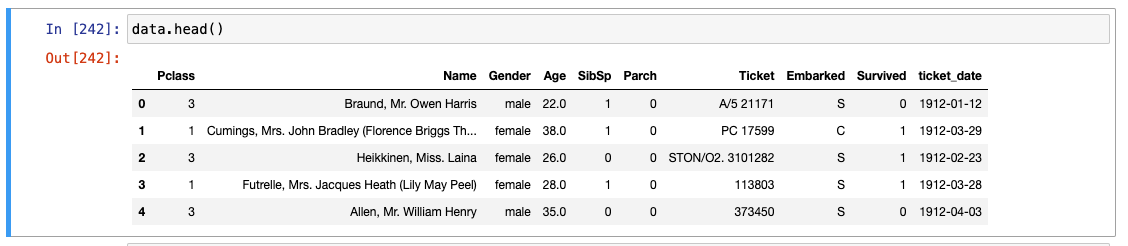
-
띄어쓰기 기준으로 데이터를 나누기(컬럼으로 나눠서 보자)

-
숫자 파트만 볼 수 있게 적용

문자열이 있는지 찾기 : isdigit
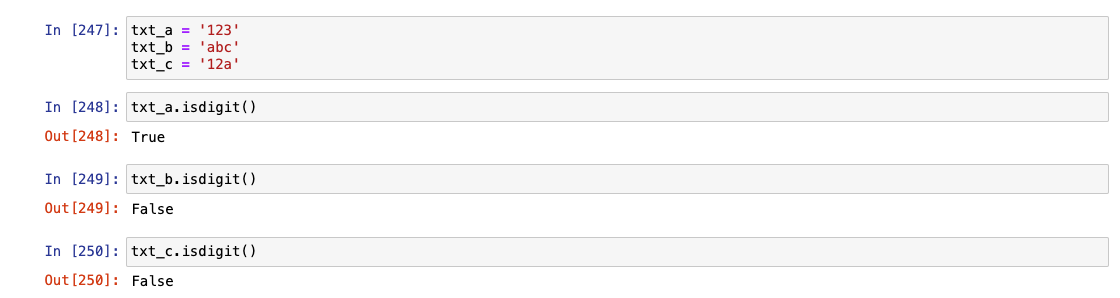
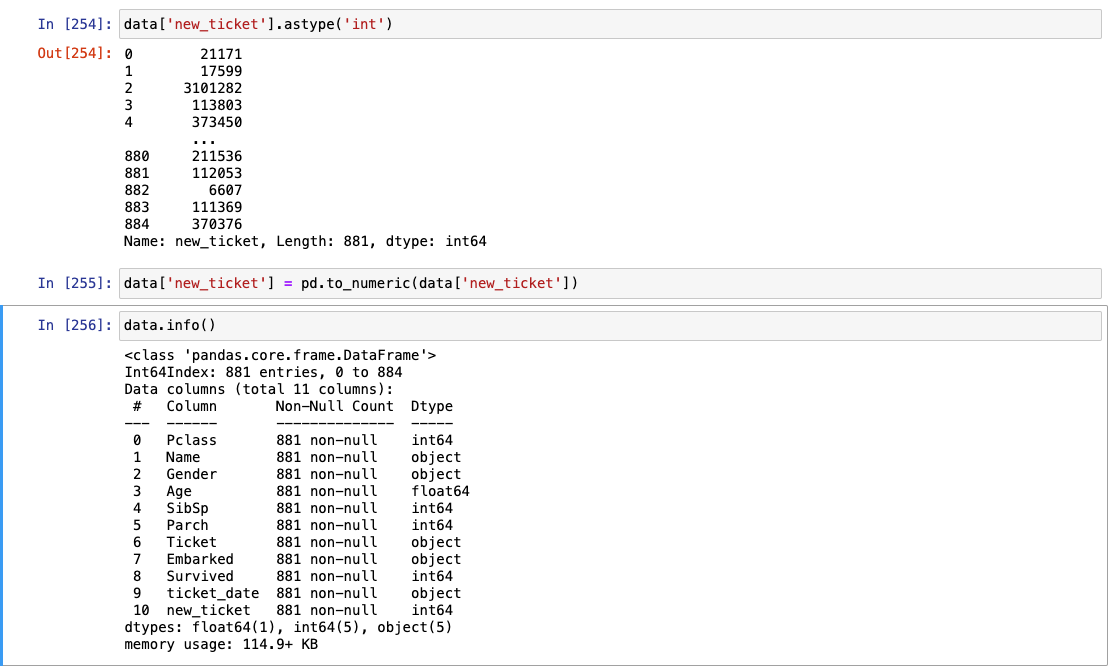
- 문자열 제거

- int형으로 변환하기
1-7. 날짜 및 시간 데이터 처리 (Datetime)
임의 데이터로 연습하기
-
strptime과 strftime
- strptime : 문자열 -> datetime으로 변환
- strftime : datetime -> 문자열로 변환


-
날짜 계산
- sample_date와 next_date의 날짜 차이 계산하기

- sample_date와 next_date의 날짜 차이 계산하기
-
ticket_date 형태 확인
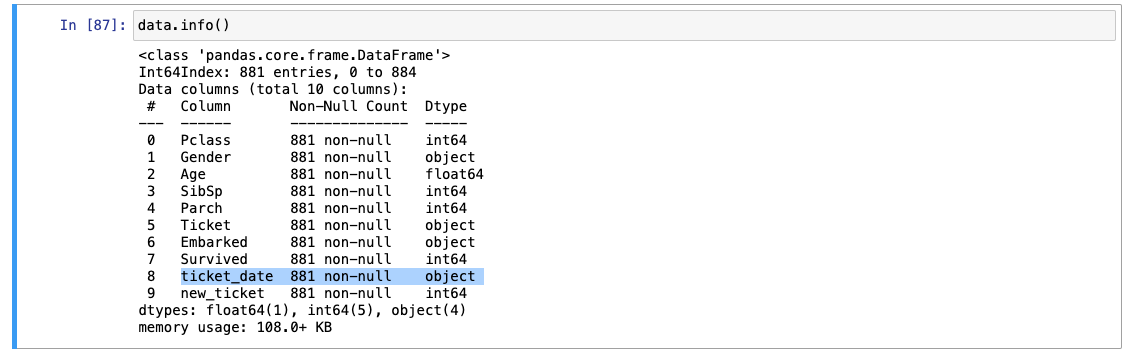
-
datetime형으로 변환
-
날짜 값만 가져와보기
- 앞에 반드시
.dt를 붙이자! - timedelta는 날짜 차이값 형태임.

- 앞에 반드시
-
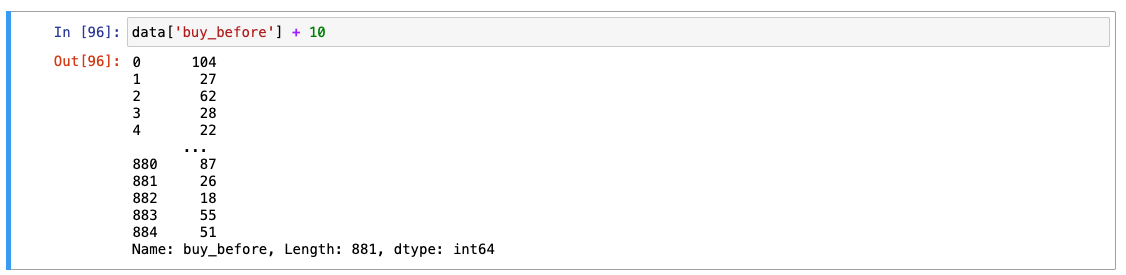
실제 데이터에서 날짜가 며칠인지 계산하기
- 계산된 날짜 값을
buy_before로 저장
- 계산된 날짜 값을
-
날짜를 int형으로 저장해주고
-
계산에 활용하기