
이미지 출처는 링크 or 아이펠 교육 자료입니다.
8-1. 들어가며
학습 내용
-
추천 시스템 논문을 학습하기 전에
- 평가 방법
- 활용 데이터 셋
-
NCF
- 논문 및 코드 리뷰
-
DeepFM
- 논문 및 코드 리뷰
-
AutoInt
- 논문 및 코드 리뷰
-
HAFP
- 논문 리뷰
학습 목표
- 딥러닝 기반 추천 시스템에 대한 다양한 논문에 대한 이해 및 핵심 개념 파악
- 각 논문별 주장과 논리에 대한 정리
- 실제 코드 해석 및 모델별 구조 설명
8-2. 추천 시스템 논문을 학습하기 전에
평가 방법
"5-5. 추천 시스템은 딥러닝 알고리즘만 중요할까요?" 참고
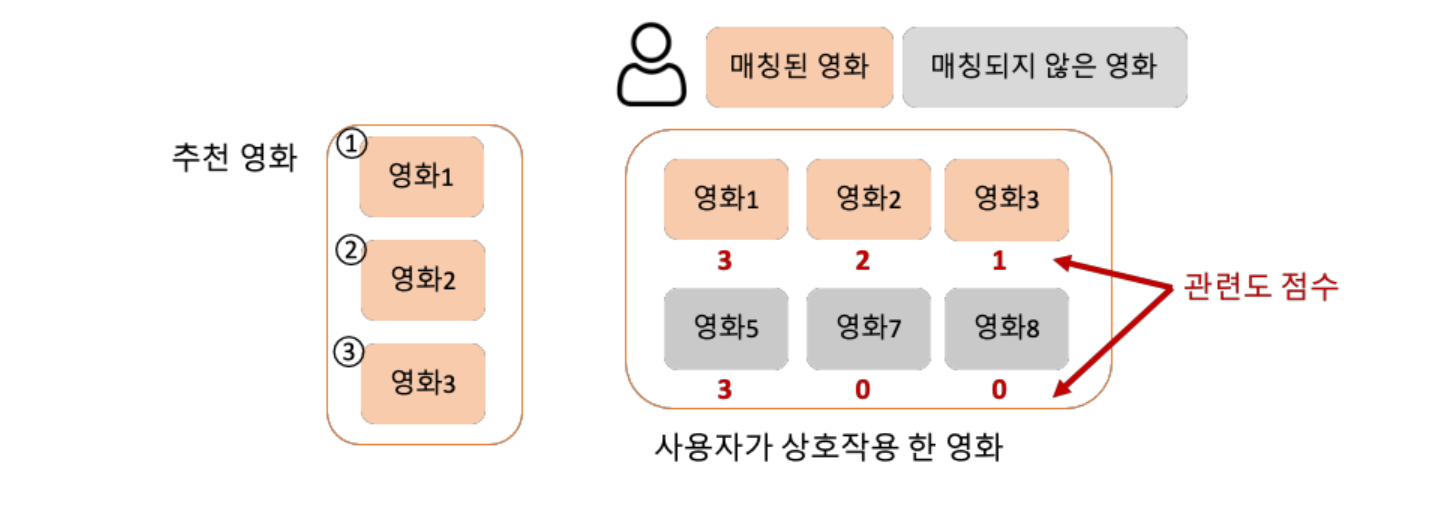
1. 매칭 기반 평가

Precision@K
- 추천 아이템 중 사용자가 선호하는 아이템의 비율을 의미
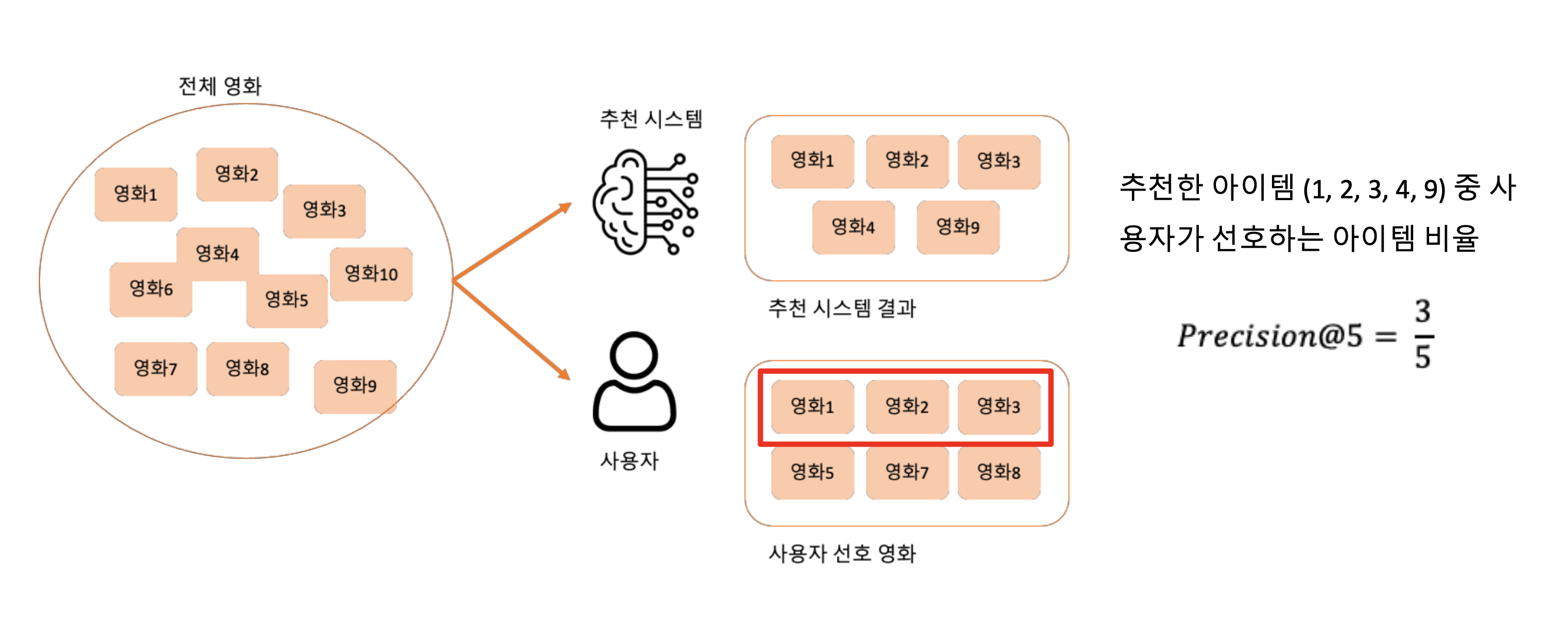
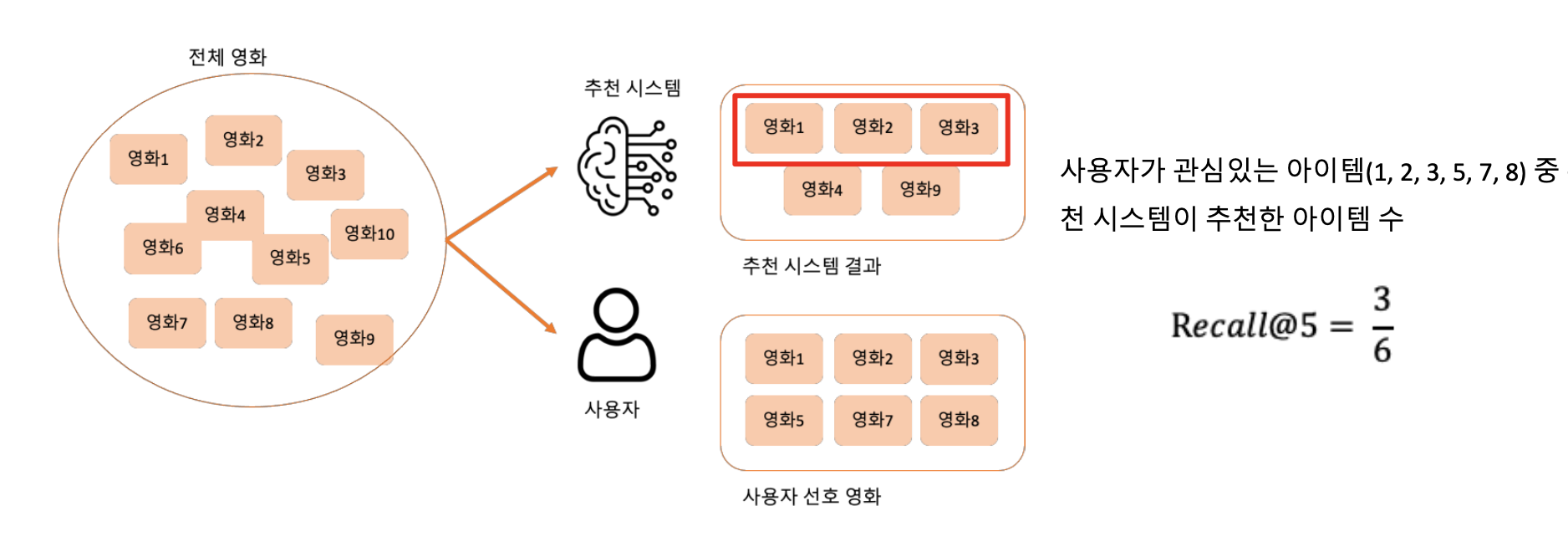
Recall@K
- 사용자가 관심있는 아이템 중 추천 시스템이 추천한 아이템의 수를 의미
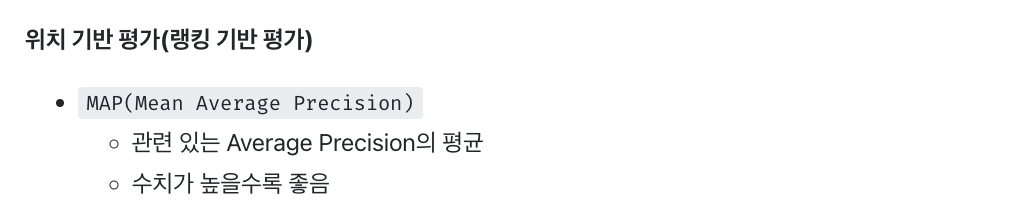
2. 위치 기반 평가(랭킹 기반 평가)
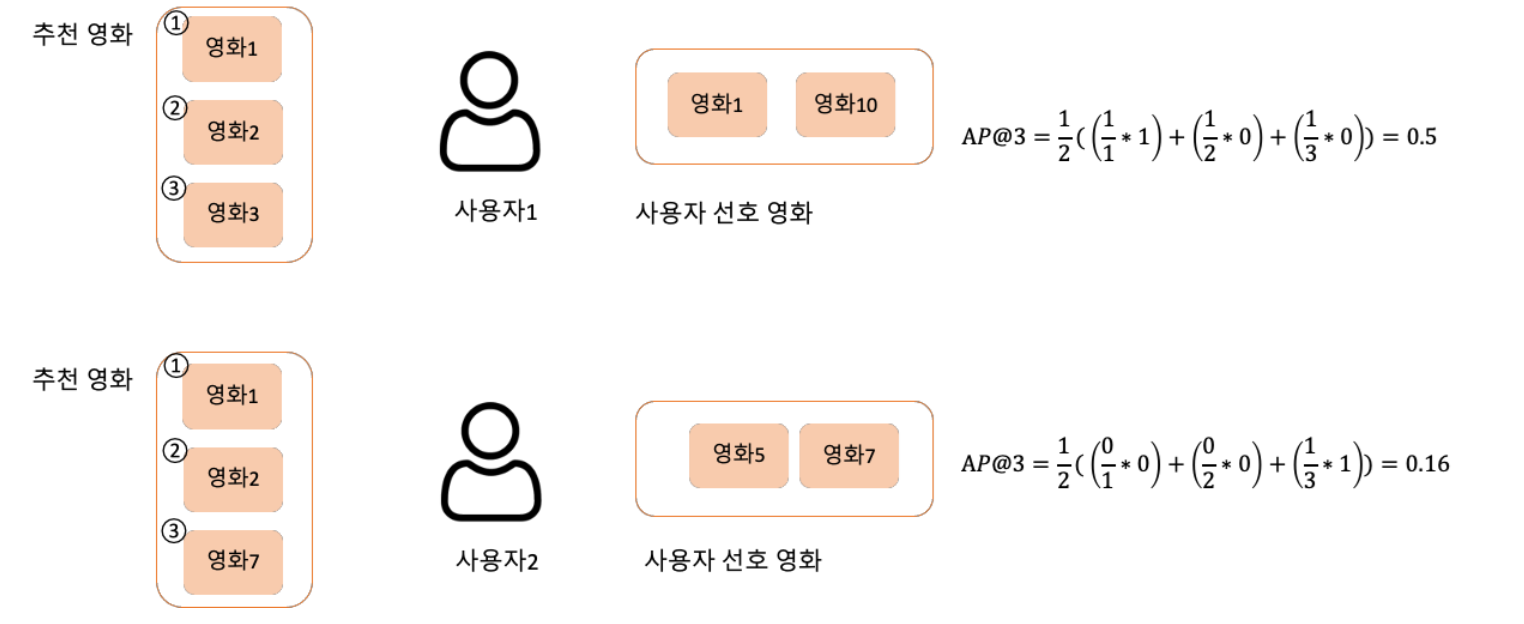
MAP
- Average Precision(AP)
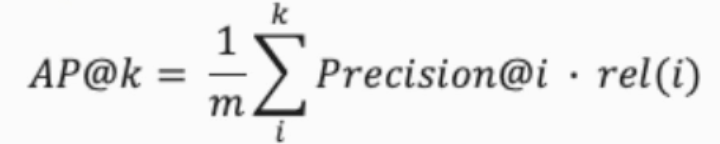
- rel(i): relevance(관련성)
- m : 전체 아이템 중 사용자가 좋아했던 아이템 수
- 매칭된 아이템에만 영향력을 주도록 설정(0 곱하기 방지)
- @k기준 : 선매칭 ➡️ 점수 up
-
연관성 매칭이 선행되어야 하는 이유
- 수치에 큰 영향을 끼침

- 수치에 큰 영향을 끼침
-
Mean Average Precision
- AP 평균
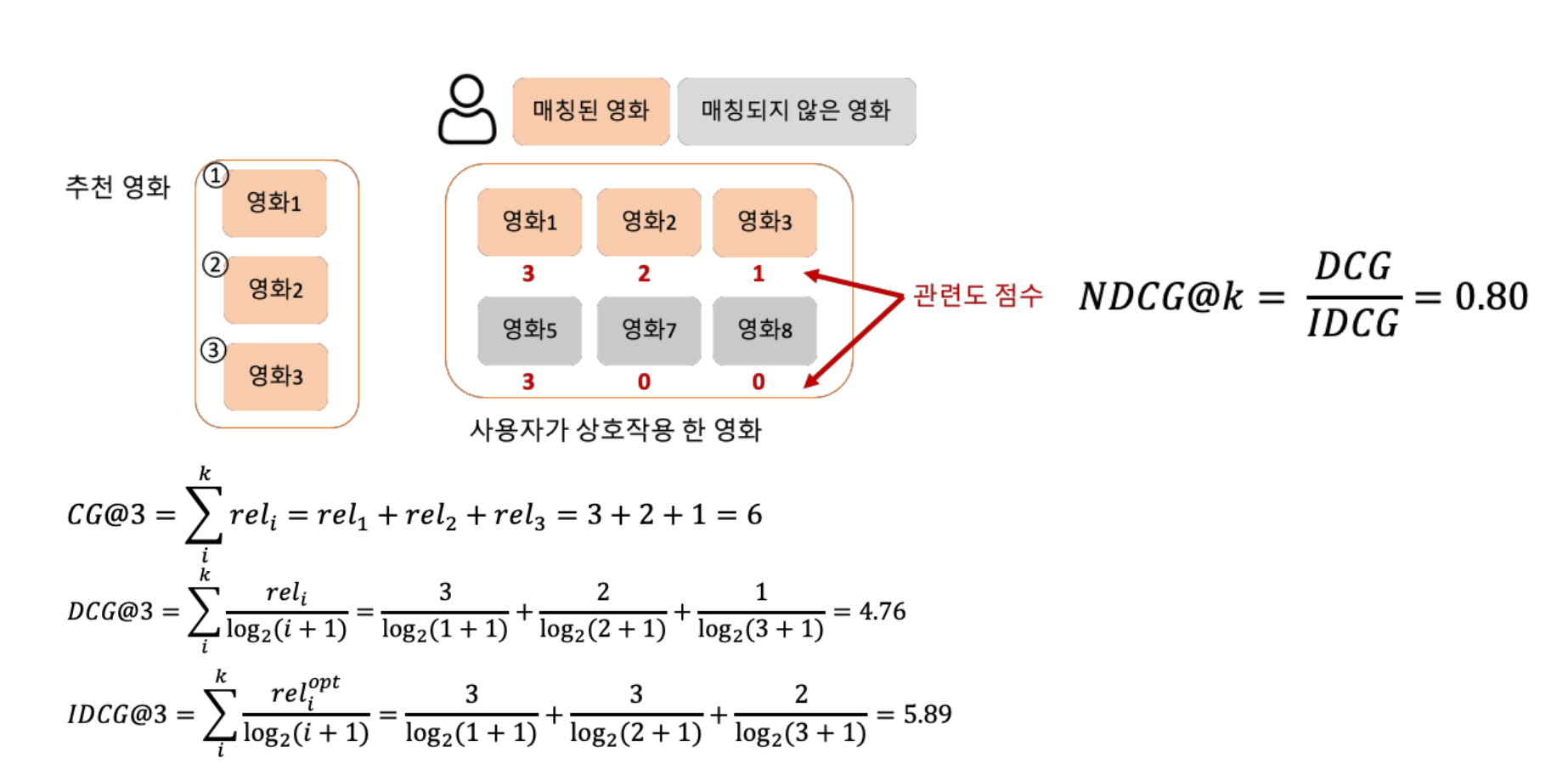
NDCG

- 추천 순위에 가중치를 넣어 평가
- 1에 가까울수록 좋은 성능
- 가중치를 두기 때문에, 순서별로 다르게 적용 가능
- CG: 순서 고려 X, 추천 아이템 관련성 합
- DCG : CG + 순서
- IDCG : 최선의 추천을 한 DCG
- NDCG :
DCG / IDCG
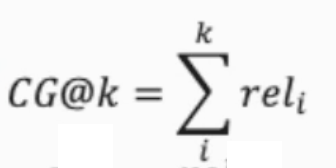
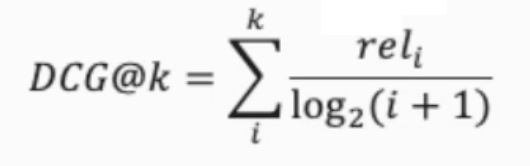
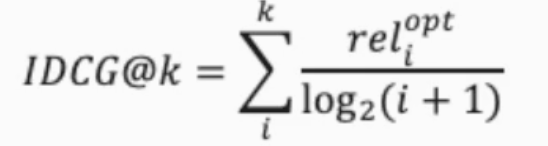
이 지표의 의미 : 가장 이상적으로 추천했을 경우, 랭킹 기반으로 추천이 제대로 제공 되었는가?
NDCG 예시
3. 오차 기반
- MAE(Mean Absolute Error)
- 정답과 예측 사이 절대 오차 평균
- 낮을수록 좋음
- 이상치에 민감

- RMSE(Root Mean Square Error)
- 오차 제곱 평균에 루트를 취한 값
- 오차 왜곡 현상 완화
- 1 미만 오차는 더 작아지고, 1 이상 오차는 더 크게 반영되는 경우를 말함
- 낮을수록 좋음

AUC와 Log loss
- AUC(Area Under the Curve)
- ROC Curve
- 분류 임계값에서 분류 모델 성능을 보여줌
- TPR과 FPR 표시

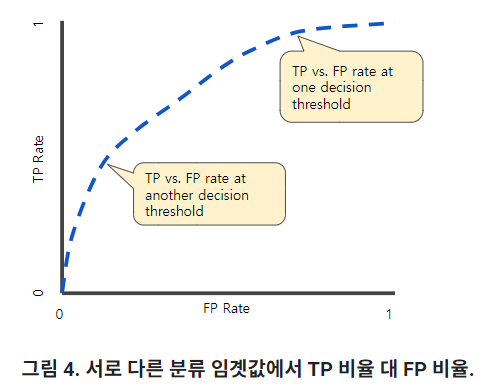
- 높을수록 좋은 지표
- AUC
- ROC Curve의 밑면적!
- 0 ~ 1의 값
- 예측이 100% 틀렸다면 AUC가 0, 예측이 100% 맞다면 AUC가 1인 형태
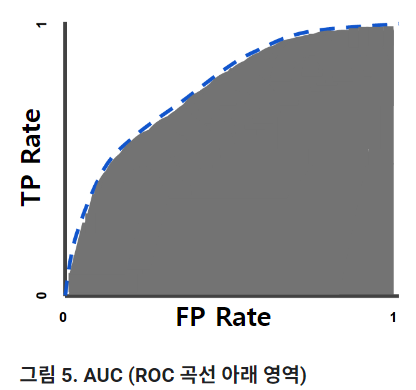
- ROC Curve
- Log loss
- 실제 예측값과 모델 예측값의 손실값을 의미
- 낮을수록 성능이 좋음
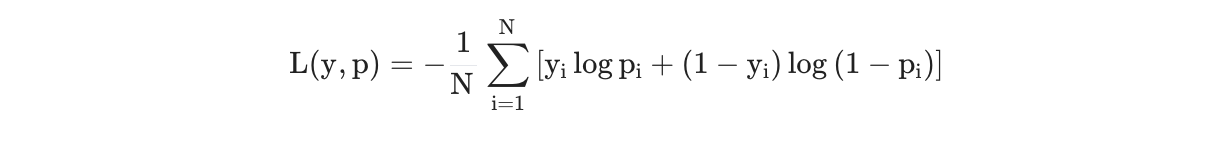
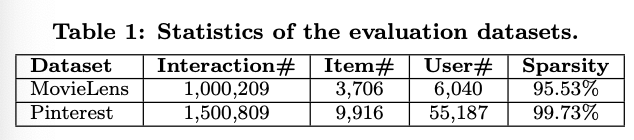
데이터셋
Avazu
-
온라인 광고 CTR 데이터셋
-
사이트 기준
- 사이트 아이디, 도메인, 카테고리
-
앱 기준
- 앱 아이디, 도메인, 카테고리
-
디바이스 기준
- 디바이스 아이디, IP, 모델, 타입
-
그 외
- 배너 위치, 범주형 데이터(익명)
Criteo
- Criteo Labs 온라인 광고 데이터
- 4,500만 명 사용자 클릭 히스토리 제공
- 13개의 Numerical 필드, 26개의 Categorical 필드로 구성
- 광고 클릭률 예측 모델 개발에 사용됨
KDD12
- 텐센트(중국 포털 사이트)에서의 광고 클릭률 예측을 위해 공개
- KDD Cup 2012, Track2로도 많이 알려짐
- 사용자 인구통계학 정보, 행동 패턴 등(익명)
- 광고 정보 : 광고 종류, 광고주, 상품...
- 광고 표시 웹사이트 정보, 검색 쿼리 등도 있음
⭐️ MovieLens
- 미네소타 대학교 GroupLens 연구팀에서 공개
- 추천 시스템 연구에 주로 사용됨
- 사용자, 영화, 평점 정보 등
- 크기에 따른 버전 존재
- 100K, 1M, 10M, 20M...
8-3. NCF
논문 리뷰: Neural Collaborative Filtering
주요 기여 사항
- Collaborative Filtering(CF) ➡️ Neural Network 적용
- Implicit Feedback 활용
- MF: NCF의 스페셜 케이스임
- 사용자 - 아이템 상호작용을 학습하는 목적으로 MLP 구조를 도입

CF에 Neural Network 적용
- Implicit Feedback: 클릭, 구매...

Neural Network 기반 CNF = "NCF" 제안
- MF는 NCF의 스페셜 케이스
- 기존 모델 대비 좋은 성능을 보인다고 함

기존 선형 방법 및 단순 내적 방법들의 단점
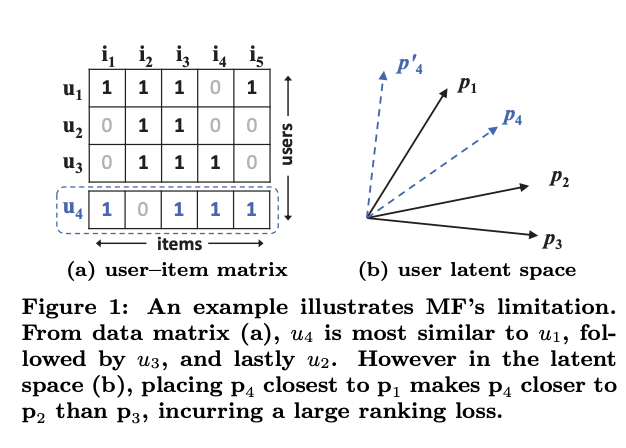
-
(a)
- u2-u3의 유사도가 가장 높음(0.66)
- u1- u2(0.5), u1-u3(0.4)
-
(b)
- u2-u3가 가까움
- u2-u1이 다음으로 가까움
-
새로운 u4가 들어온다면?
- u4-u1(0.6)
- u4-u3(0.4)
- u4-u2(0.2)
-
다만, 이 부분을 잠재 공간에 표현할 수 없기 때문에 DNN을 도입한 것(비선형 구조)
- 잠재 공간에 표현할 수 없게 되면 => 추천 성능 저하, loss 증가
CF에 muiti-layer를 쌓는다는 것
- 사용자 잠재 벡터, 시스템 잠재 벡터를 NCF 레이어에 Input으로 주입
- 하나의 레이어 output -> input이 되는 형태로 인터렉션 모델링
- 최종적으로 output 레이어에서 사용자가 output에 인터렉션할 확률 예측
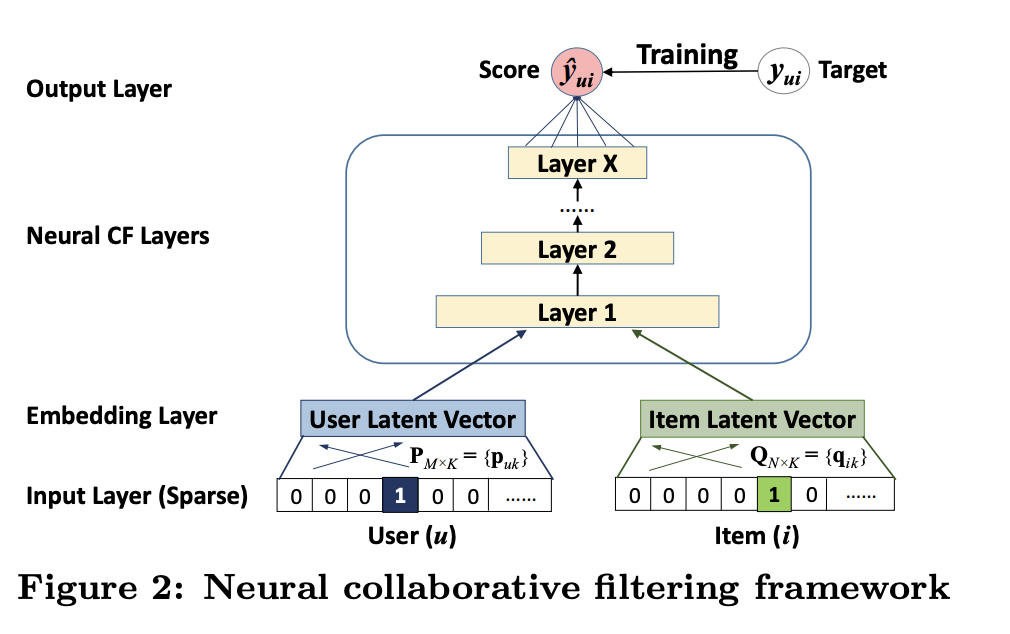
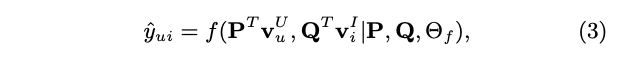
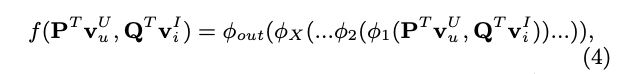
MF(행렬 분해)는 NCF의 스페셜 케이스
- Embedding vector 사용 시 ➡️ 잠재 벡터가 됨
- 사용자 또는 아이템을 고정 저차원 벡터로 매핑하는 것에 그 이유가 있음
- 사용자 잠재 벡터, 아이템 잠재 벡터를 성분별로 곱하기
- Element-wise product(각 행렬 원소끼리의 곱) ➡️ GMF의 결과를 추출할 수 있음

- Element-wise product(각 행렬 원소끼리의 곱) ➡️ GMF의 결과를 추출할 수 있음
최종 모델: GMF + MLP 구조를 합친 모델
- GMP용 임베딩과 MLP용 임베딩 분리 사용

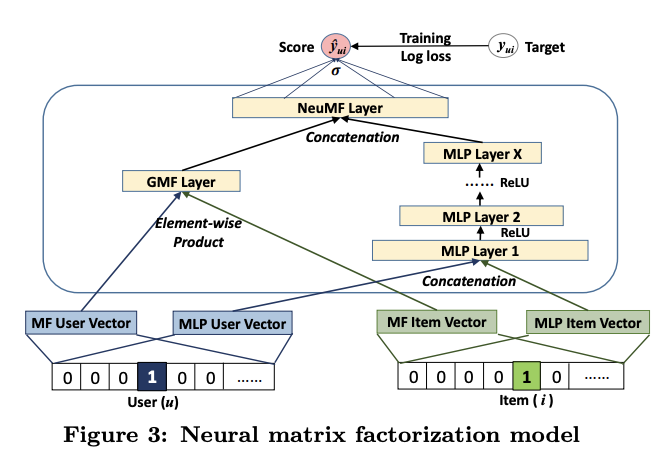
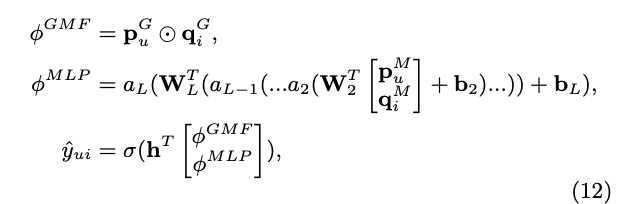
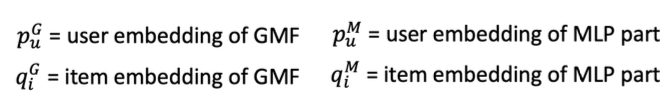
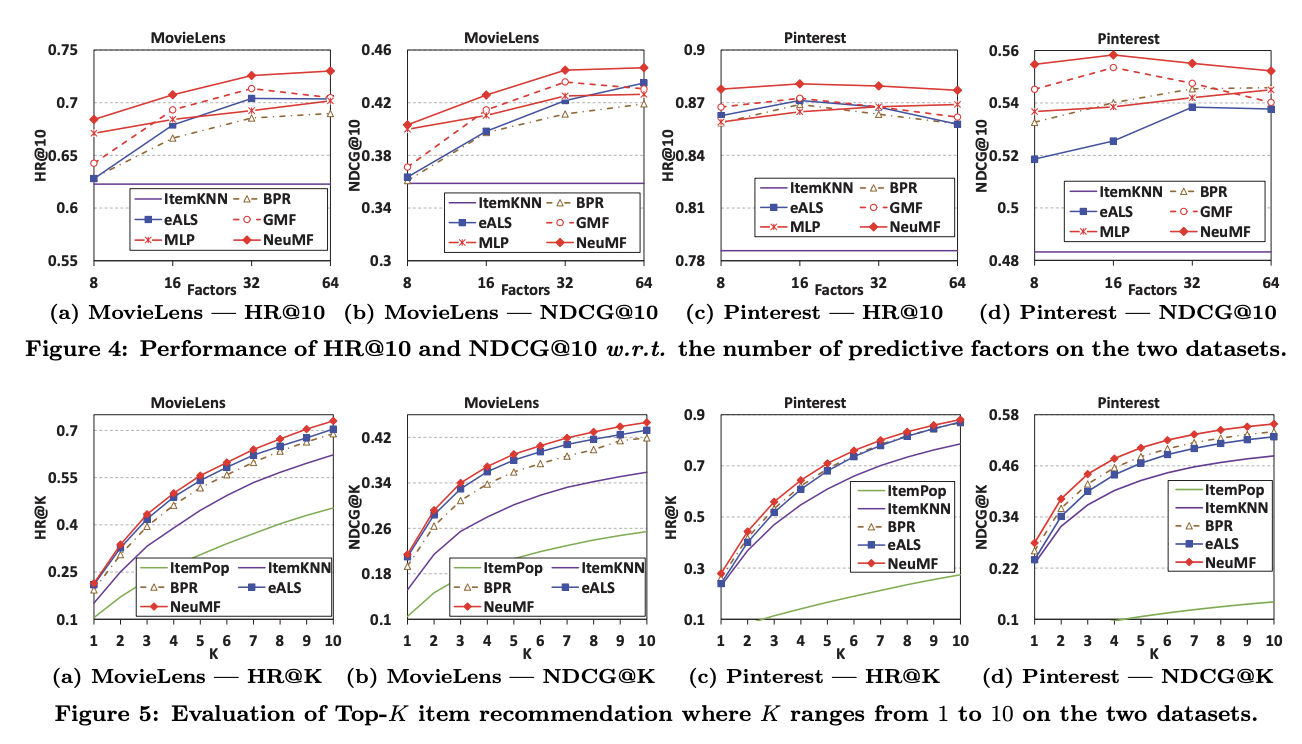
평가
- 좋은 성능을 보임
NDCG@K: Top@K 평가 방법 중 랭킹 기반 평가를 의미- 추천 순위에 가중치!(1에 가까워야 좋은 것)
HitRate@K: Top@K 중 추천 아이템 매칭 여부 파악
코드 리뷰: yihong-chen/neural-collaborative-filtering
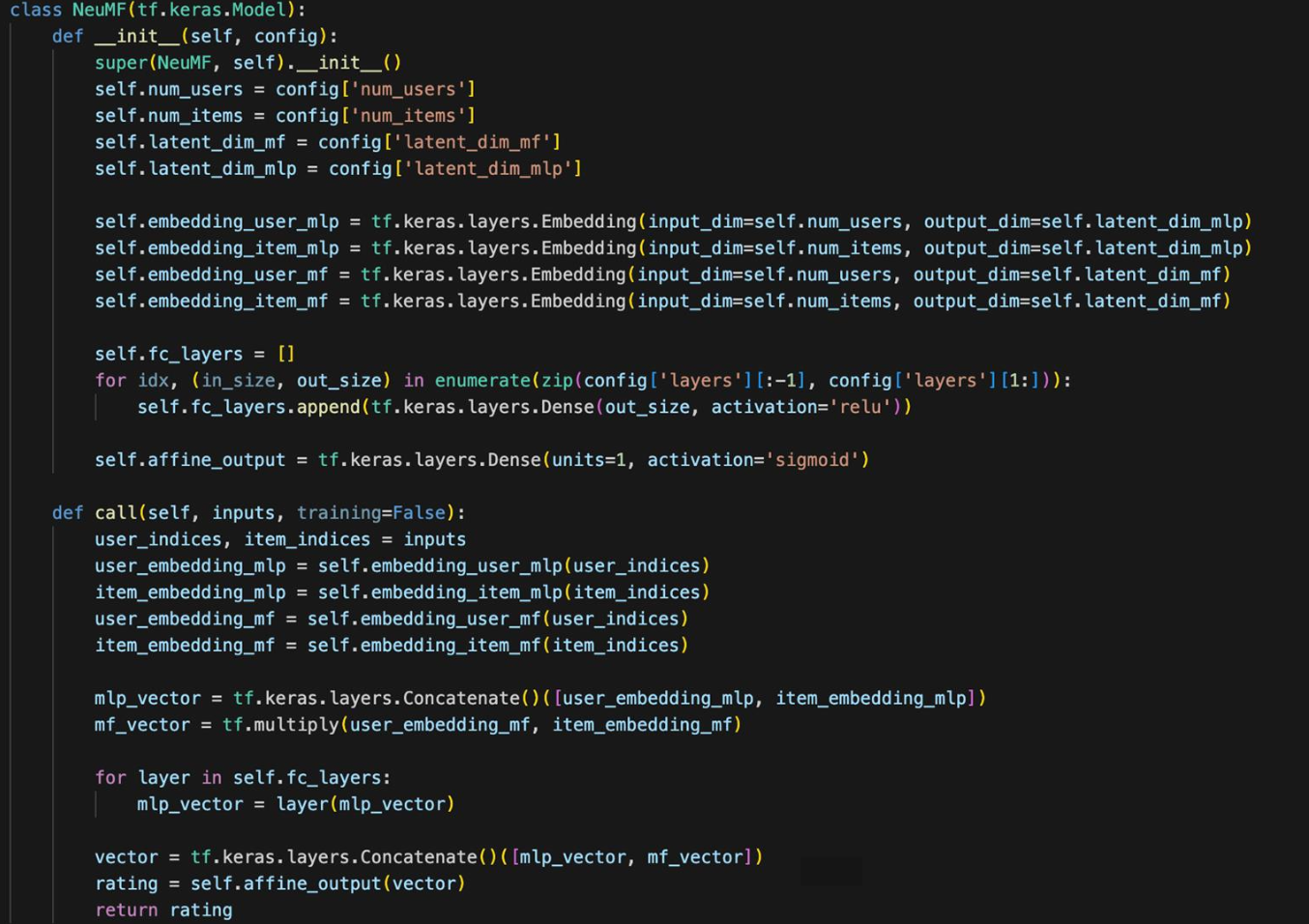
1. src/neumf.py
[모델 정의 파트]
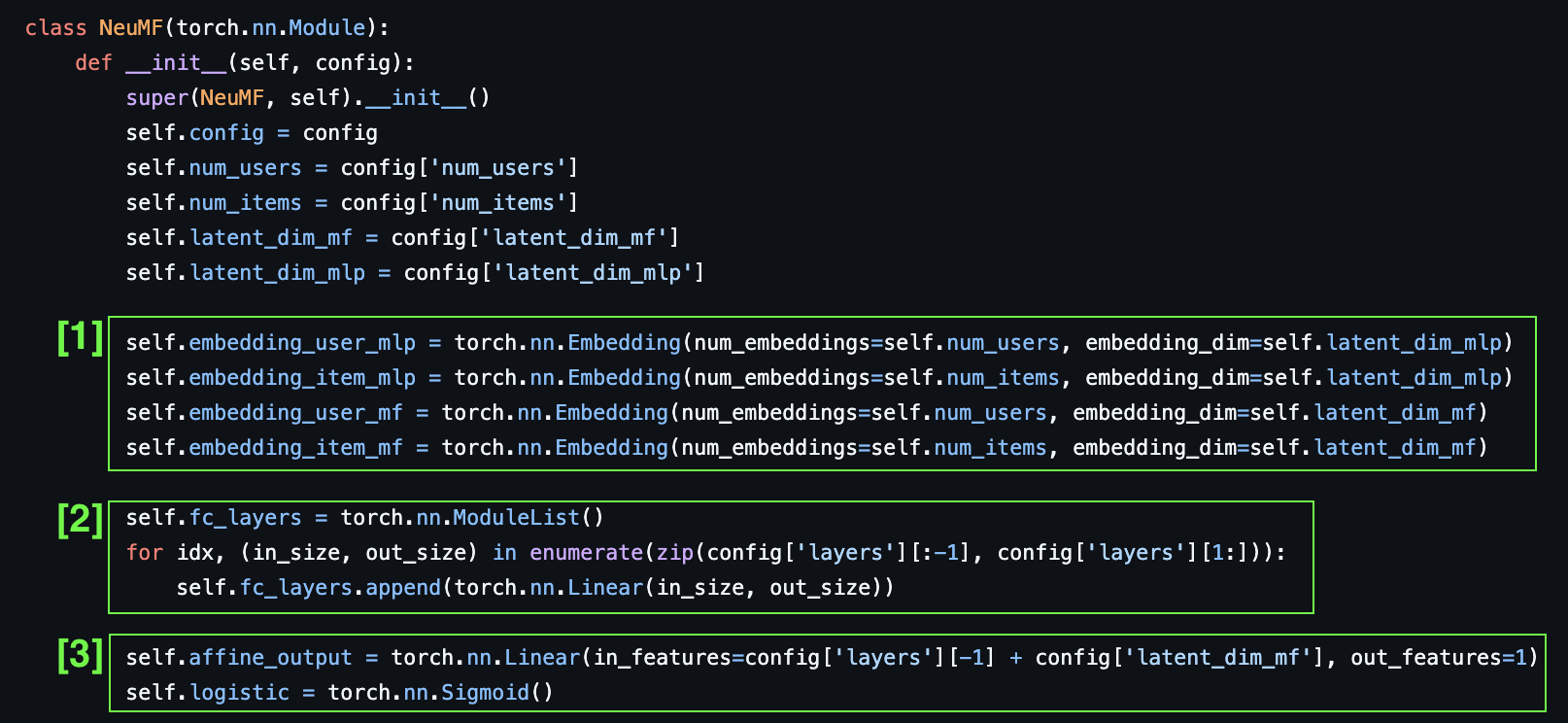
- 1번
- MLP:
embedding_user_mlp,embedding_item_mlp - MF:
embedding_user_mf,embedding_item_mf
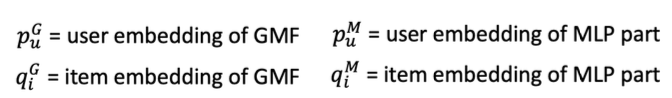
- MLP:
-
2번, 3번
-
2번: Multi-Layer 퍼셉트론 구현 코드
- 비선형적 구조 레이어를 스택 형태로 쌓은 구조
- 레이어 수만큼 모듈 리스트에 선형 레이어를 쌓음
-
Output Layer
- 사용자가 아이템을 클릭할 것인가에 대한 예측값이기 때문에 1이 나와야 함
-
3번: 최종적으로 사용자가 이 예측을 인터렉션할 것이라는 값을 추출

-
[Forword 파트]

-
1번: MLP 레이어에 들어가기 위한 사용자와 아이템 임베딩을 컴페티네이션하는 코드
-
2번: 사용자 MF용 벡터와 아이템 MF용 벡터로 element-wise multiplication 수행
-
3번: 각 레이어를 통과하면서 ReLU 활성화 함수를 적용
-
4번: 실제 사용자가 해당 아이템을 클릭할 것인지에 대한 예측 수행
여기까지는 Pytorch 기반
TensorFlow ver
- 구조는 동일
8-4. DeepFM
논문 리뷰: DeepFM: A Factorization-Machine based Neural Network for CTR Prediction
주요 기여 사항

-
기존 연구
- Low Order or High Order에 지나친 편중
-
DeepFM
- Low Order + High Order Interaction
-
Factorization Machine(FM) + Neural network
-
Wide & Deep 구조 변형
- Wide Part ➡️ FM
- 피쳐 엔지니어링 필요하지 X
DeepFM: FM + DNN 구조 통합

- FM : Low order feature interaction 모델링
- DNN : High order feature interaction 모델링
- 피쳐 엔지니어링 불필요
Embedding vector 공유

- 효율적인 학습과 더불어, 기존 연구보다 성능 개선됨
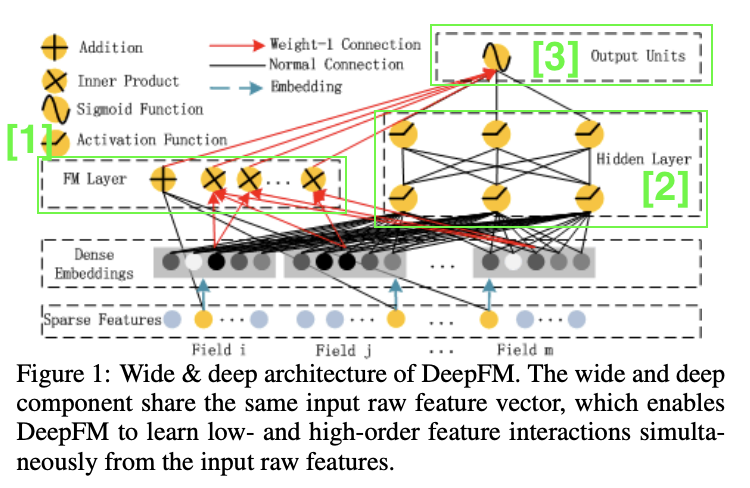
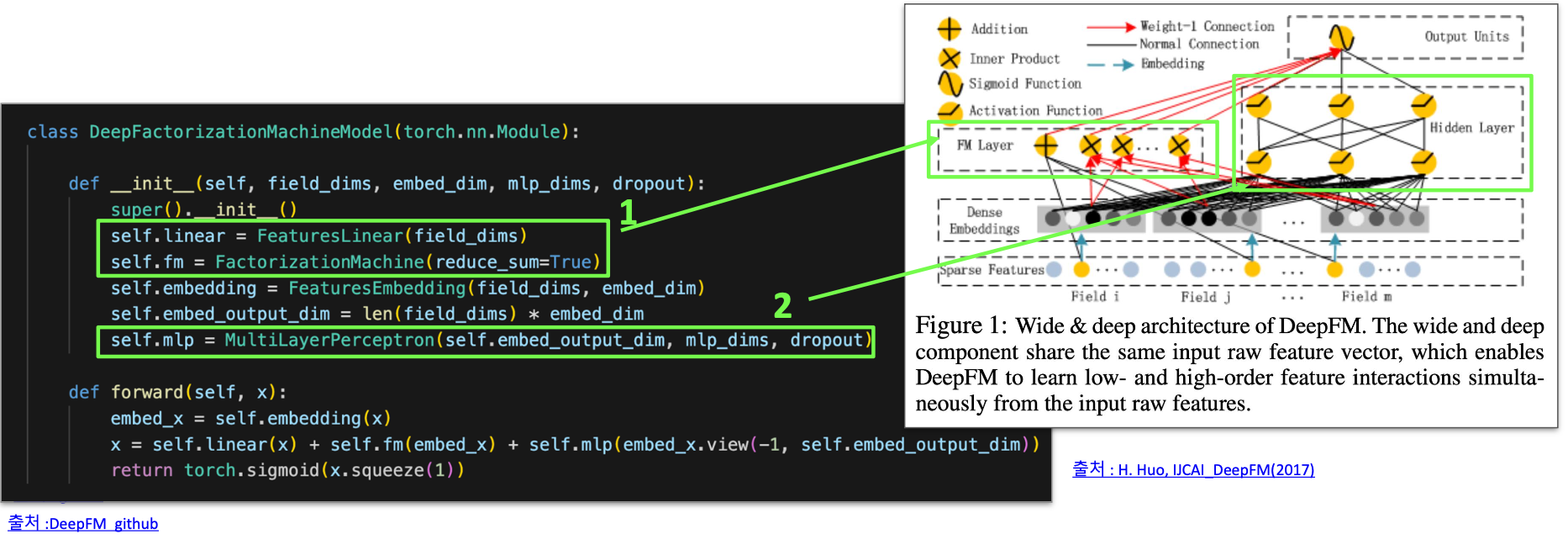
FM 컴포넌트와 Deep 컴포넌트로 분리
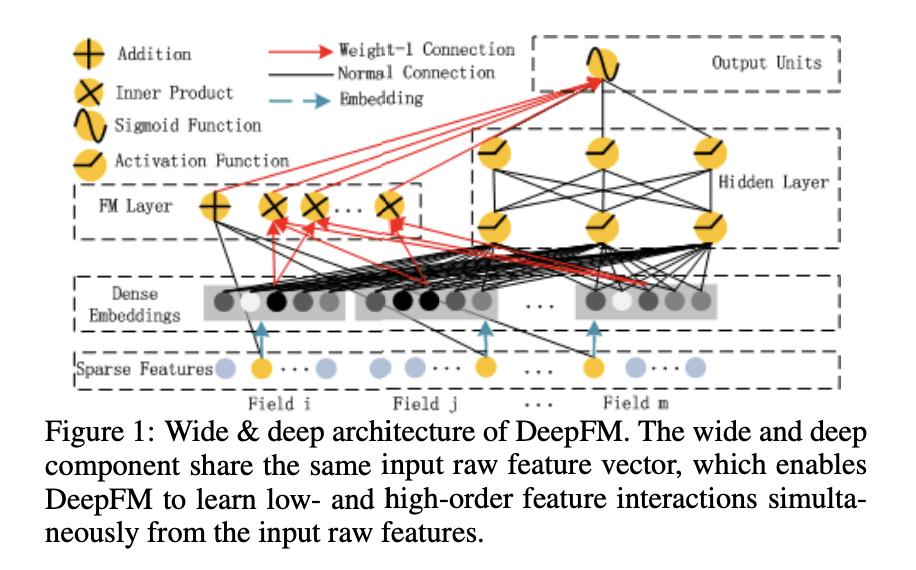
-
FM 컴포넌트
- Factorization Machine 방법
- Feature interaction 학습을 위함
-
Linear interaction, order-1 가능
-
Pairwise(order-2) feature interaction 가능
- 내적 사용

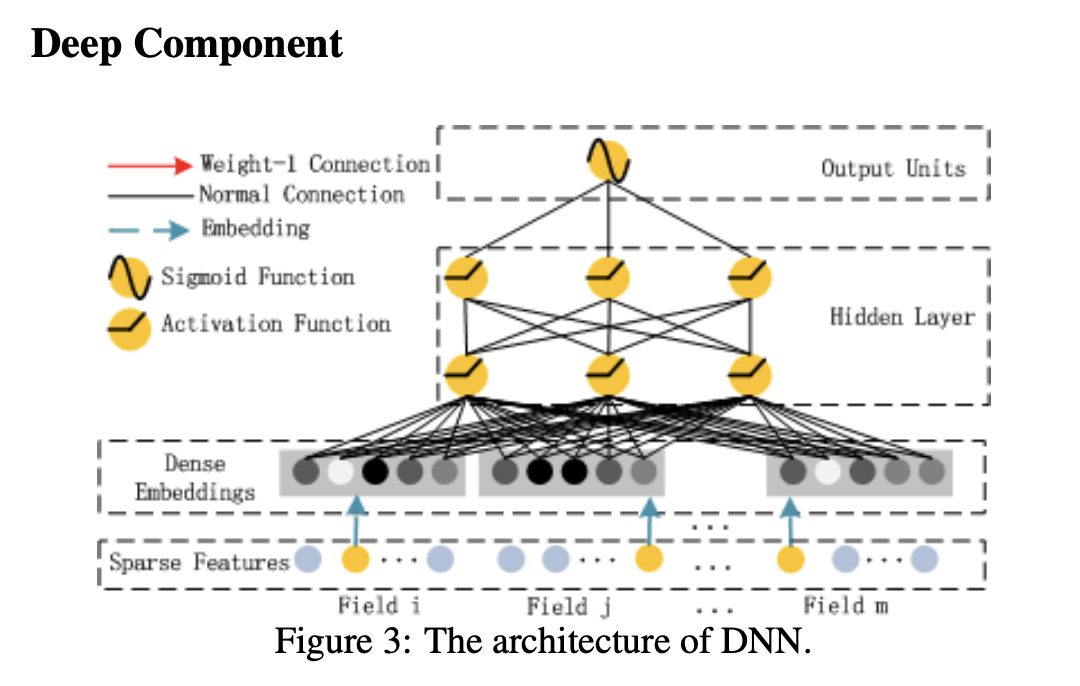
Deep Component
- NCF의 MLP 파트와 유사
- Feed forward neural network 사용
- feature 임베딩 ➡️ DNN Input으로 들어가 학습되는 것을 의미
- 레이어의 중첩을 통해 상호 작용 학습
- FM 컴포넌트의 Feature Embedding 공유
- Raw feature에서의 Low, High 상호작용 모두 학습 가능
- 피쳐 엔지니어링 불필요

DeepFM 구조

평가
- 자체 데이터셋과 Criteo 데이터셋을 활용해 평가
- 평가 지표 : AUC, Log loss
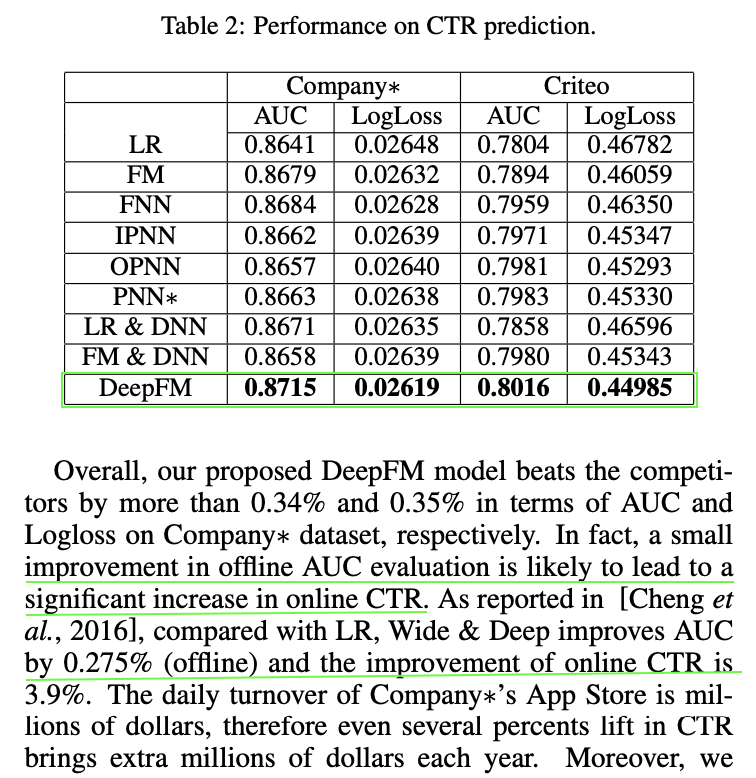
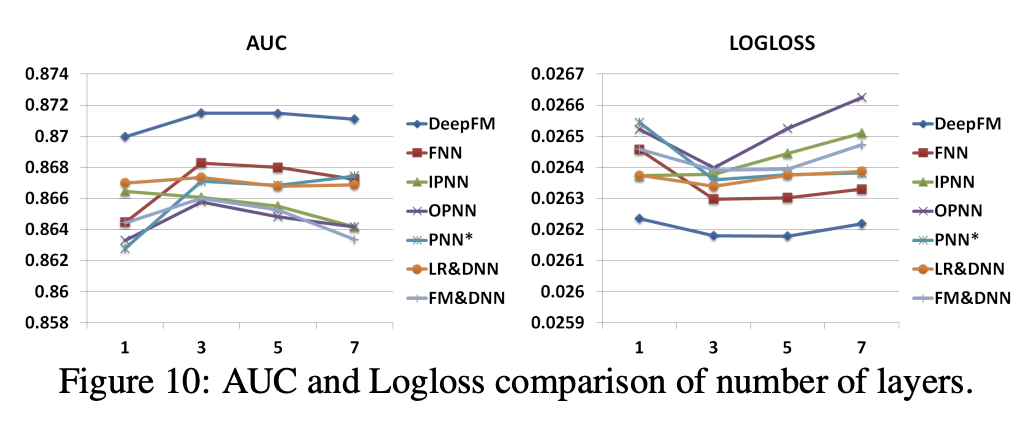
activation function에 따른 성능 평가
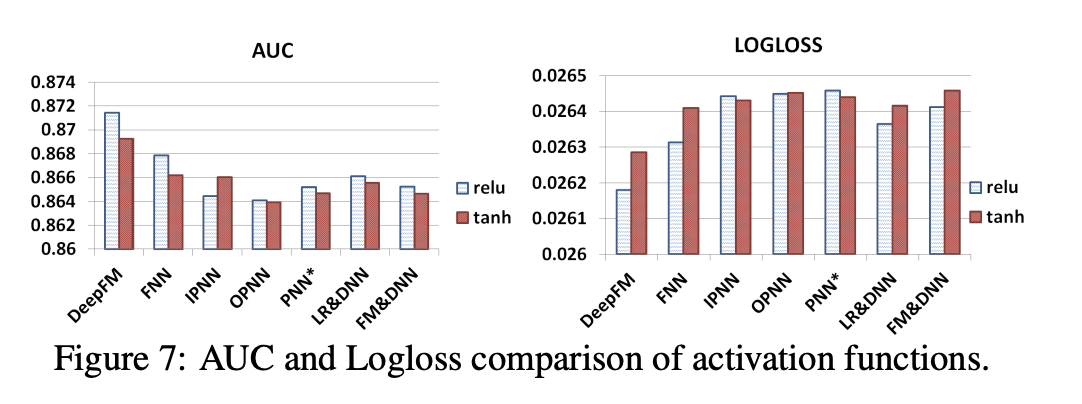
Dropout 레이트에 따른 성능 변화
- 0.9에서 가장 좋은 성능을 보임
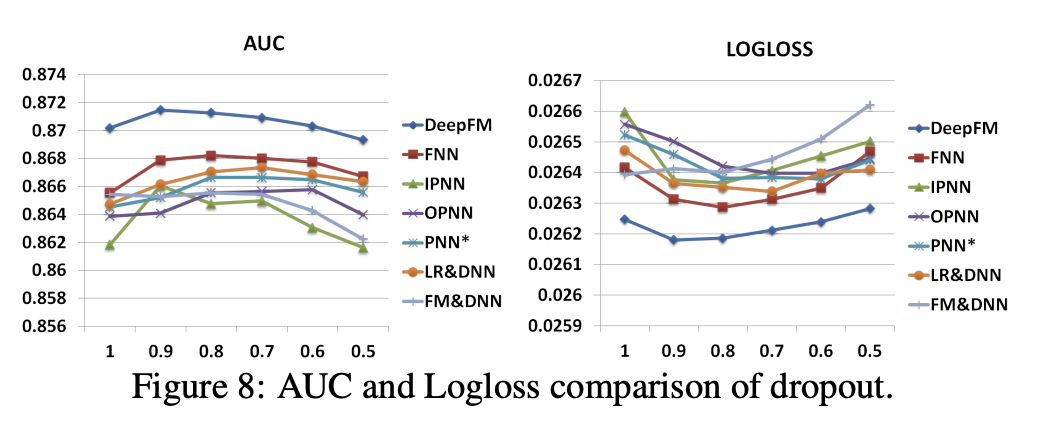
Neuron 수에 따른 성능 변화
- 400일 때 가장 좋은 성능
- 오히려, 800일 때는 성능이 조금 떨어짐
- 오버피팅 우려 있음
Layer 수에 따른 성능 변화
- 위와 비슷한 결과
- 3일 때 가장 좋은 성능
- 5, 7..을 넘어가면 오히려 성능 떨어짐
- 오버피팅
코드 리뷰: rixwew/pytorch-fm
Feature Embedding
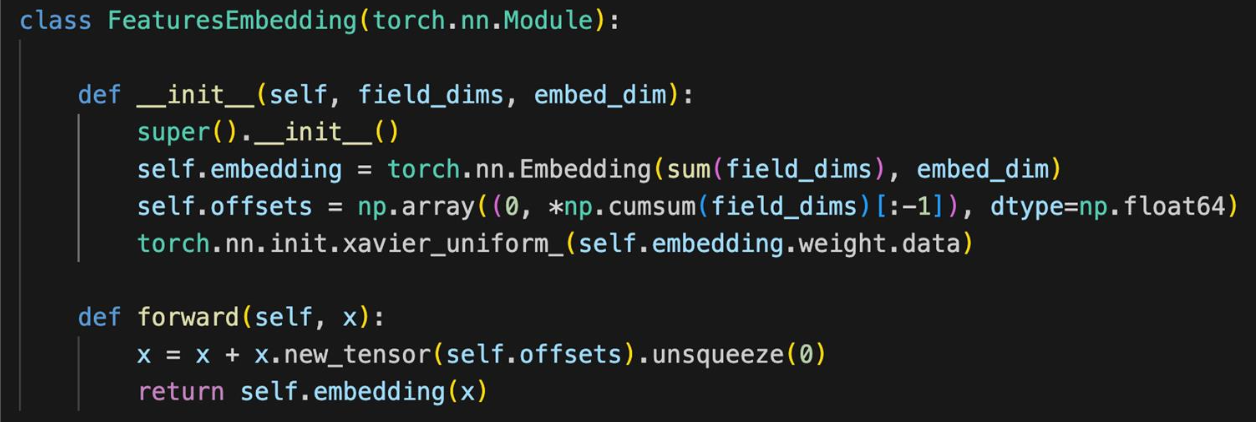
- feature에 해당되는 임베딩 값
Offsets: feature 시작 지점(필드로 구분)- Forward 결과 feature 임베딩에서 벡터값을 가져오는 형태
예시로 학습
-
field_dims = [10, 20, 30]으로 설정했을 경우의 랜덤 Input 값을 만들어 실험
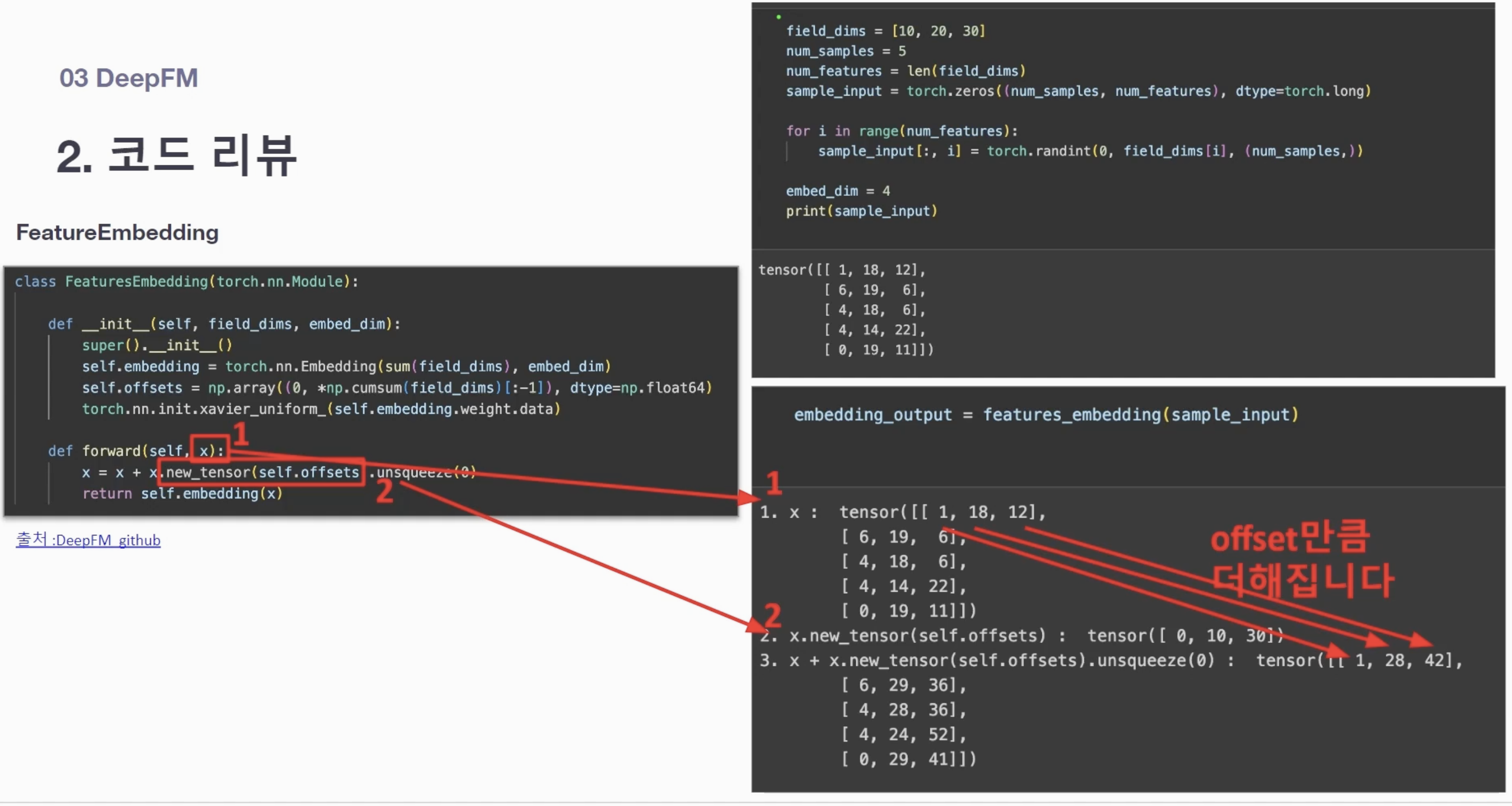
-
[1] Original feature embedding
- Input 값과 동일
-
[2] offset 결과
- 첫번째 feature는 0번째부터 시작
- 두번째 feature는 10번째부터 시작...
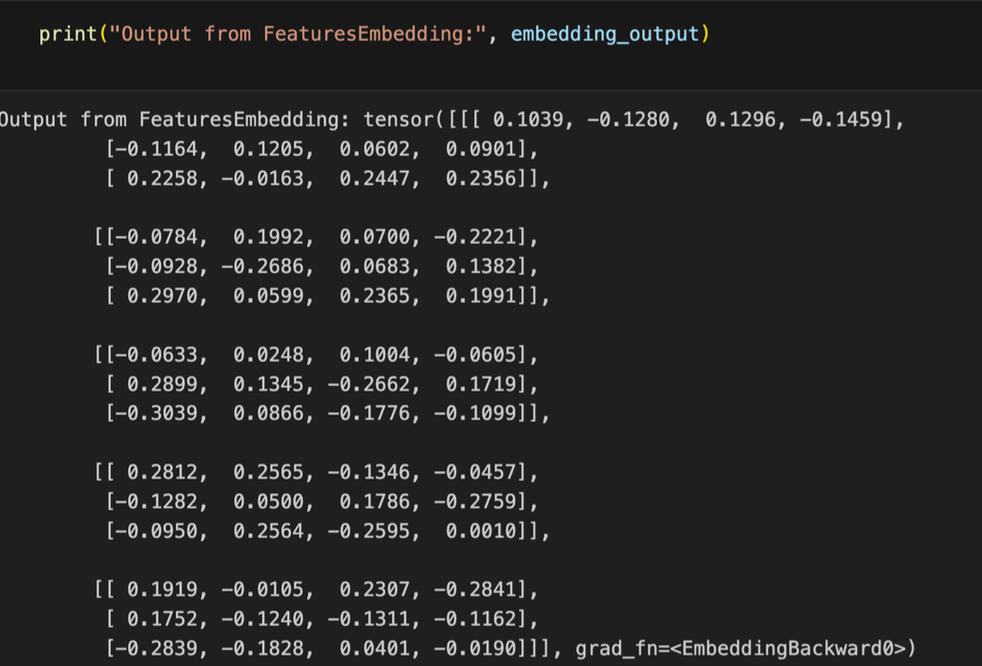
- Output
- 임베딩 값을 가져오는 것
- 앞서 뽑았던 5개 샘플에 대한 각각의 임베딩 값
- 여기에서는 4차원 벡터로 가져오게 됨
FeaturesLinear
- order-1인 Linear 연산
- Output dim: 1차원 스칼라 값
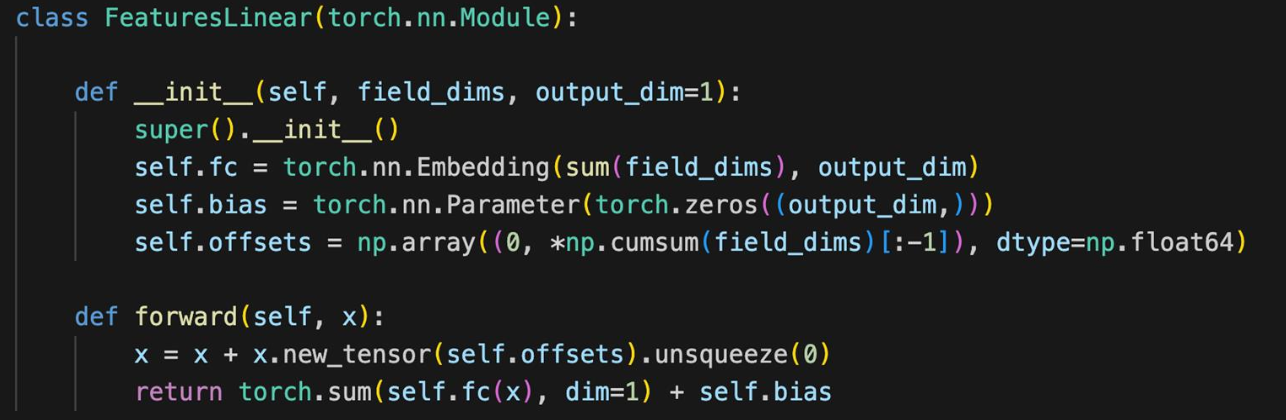
예시로 확인
- 피쳐 리니어에 이전 예시와 동일한 Input을 넣었음
- 해당 피쳐에 해당하는 offset을 통해, 그 offset에 해당하는 임베딩 값을 가져옴
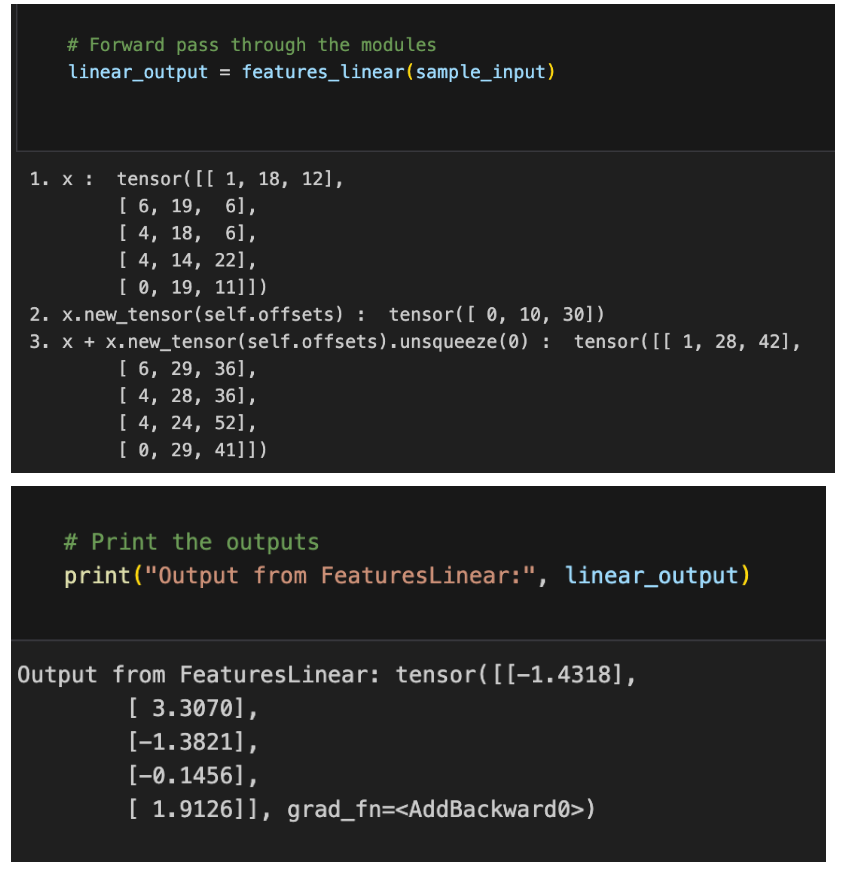
- 해당 피쳐에 해당하는 offset을 통해, 그 offset에 해당하는 임베딩 값을 가져옴
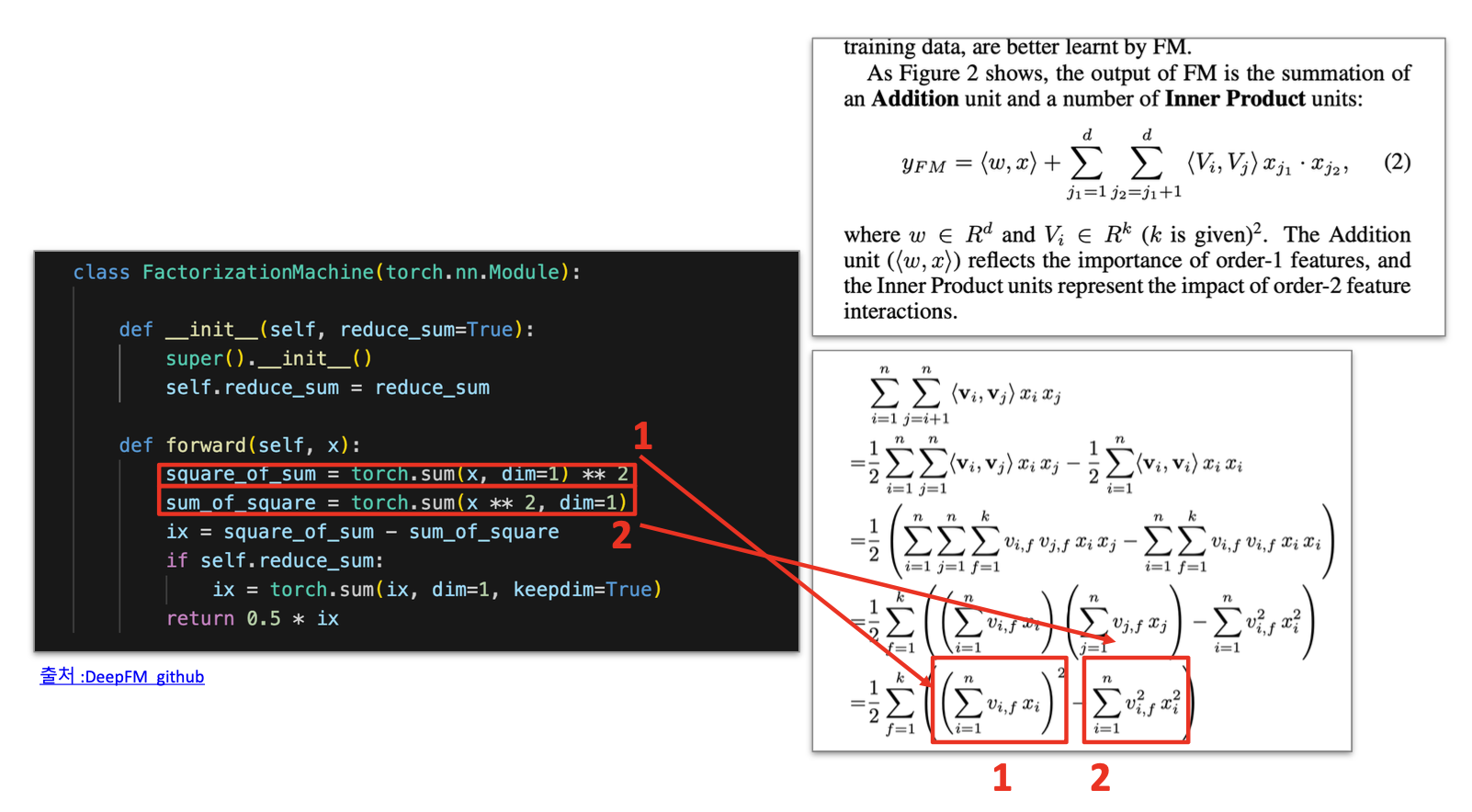
FactorizationMachine
- FM 연산을 수행하는 본체
- 계산 효율성을 위해 약간의 수학적 트릭이 적용된 수식을 사용
MultiLayerPerceptron
- MLP 레이어
- 피쳐 간의 관게성을 모델링
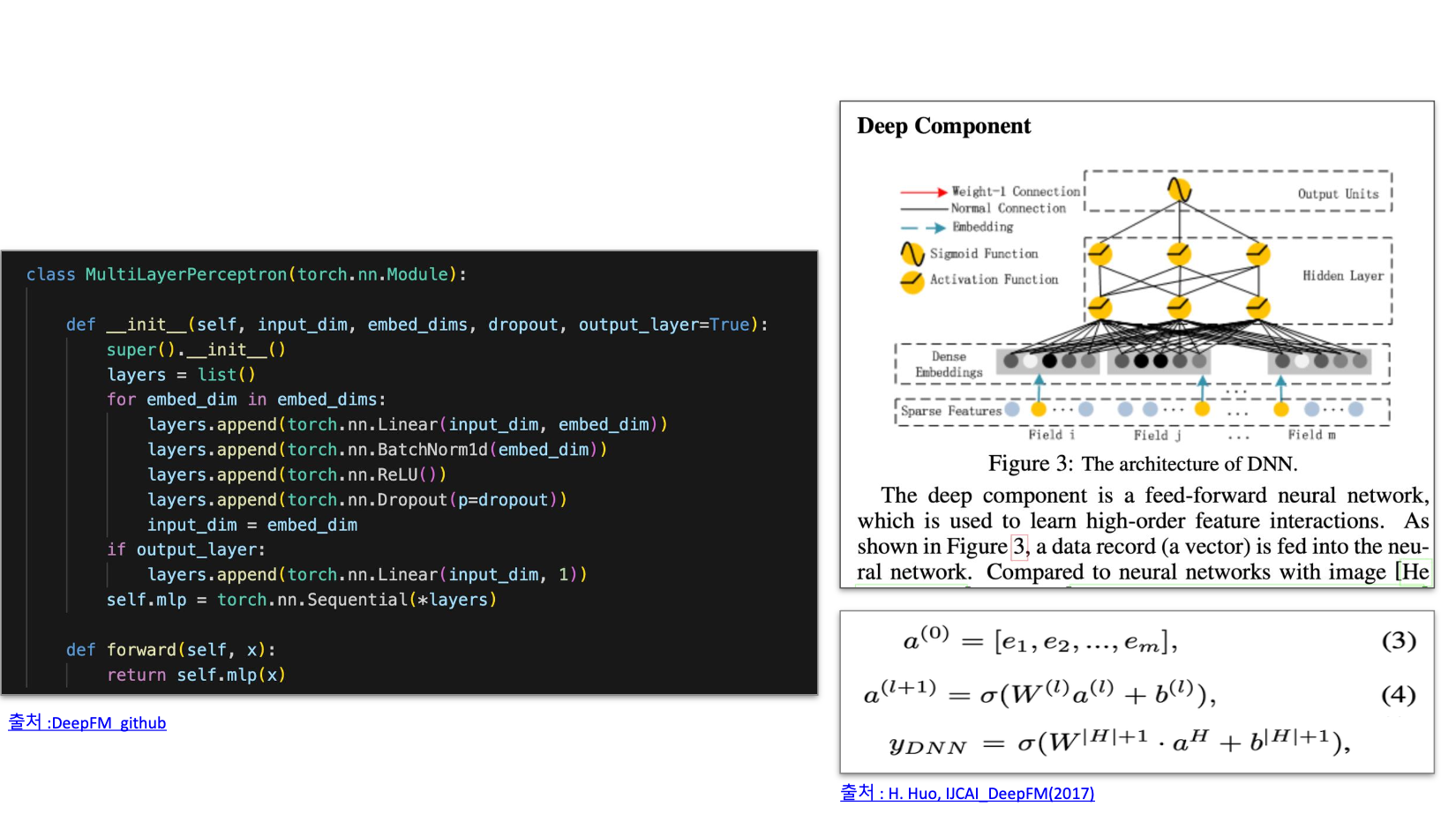
- 피쳐 간의 관게성을 모델링
DeepFM 구조
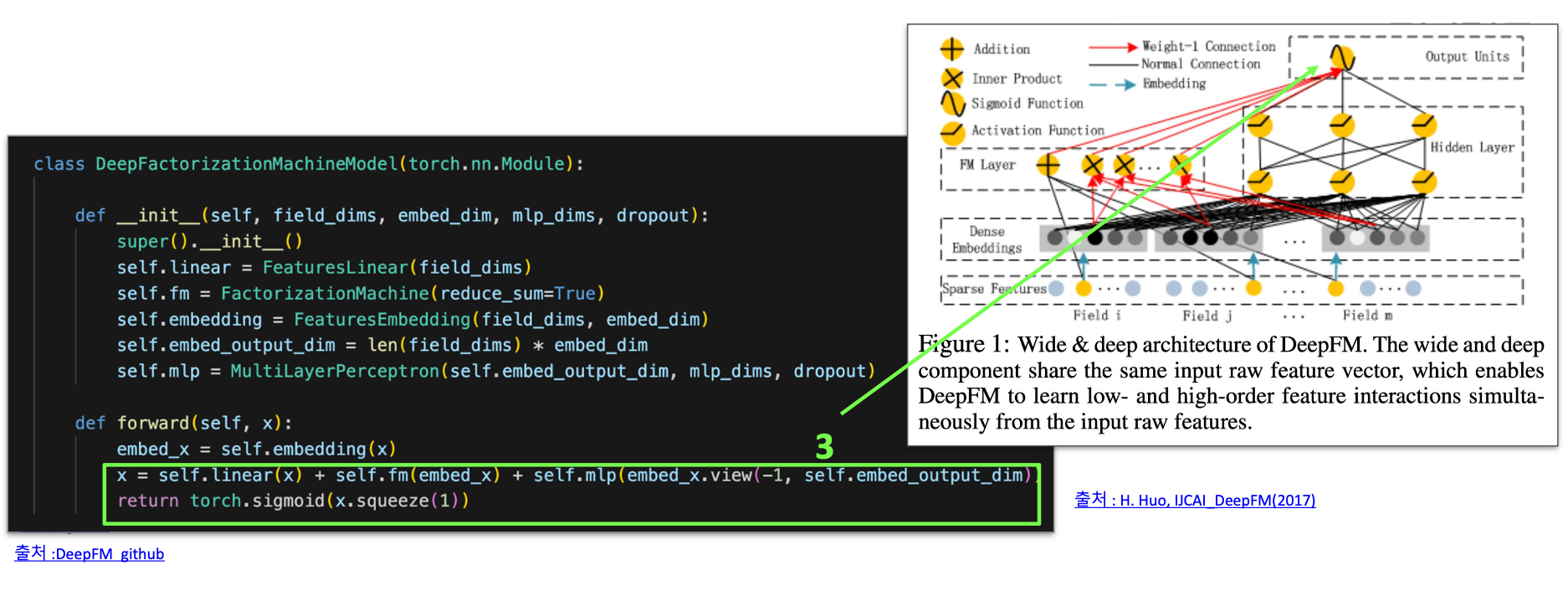
- Feature Linear 연산, FactorizationMachine 연산, MultiLayerPerceptron 연산을 각각 수행해 그 결과값을 합쳐서 제공
DeepFM Output
- One order feature interation 결과 + Second order feature interation 결과 + High order feature interation 결과의 결합 ➡️ sigmod function을 적용하여 확률값으로 변환하여 사용
8-5. AutoInt
논문 리뷰: AutoInt: Automatic Feature Interaction Learning via Self-Attentive Neural Networks
주요 기여 사항

- 입력 데이터: Sparse + High-dimensional함
- 입력 피쳐들 간 High order feature interaction에 대한 어려움
- 수작업: 도메인 전문가에 과의존, 모든 조합을 만드는 것에는 한계가 있음
- ML 모델을 이용한 학습: 가능한 모든 High order feature interaction 적용 시, 차원과 희소성의 급격한 증가로 오버피팅됨
- 이러한 특징을 가진 입력을 ➡️ 저차원으로 표현 및 매핑하려는 시도가 있었음
과거 노력들

-
FM
- 계산 복잡도의 한계
- Low order feature에만 효과적임
-
DNN
- 비선형 뉴럴 네트워크 기법
- 특징 사이의 곱셈 관계 -> 비효율적
- 암묵적 학습에 있어 설명력 부족
AutoInt 모델 제안


- 희소 + 고차원적인 데이터를 ➡️ 저차원 표현
- 멀티헤드 셀프 어텐션 구조로 입력 피쳐들 간의 상호작용 및 관계성 모델링
- Stack으로 서로 다른 차원에서의 피쳐 상호작용을 학습함
- 고차 상호 작용 ➡️ 명시적으로, 자동으로 학습하는 것
- 설명 가능성이 좋아짐!
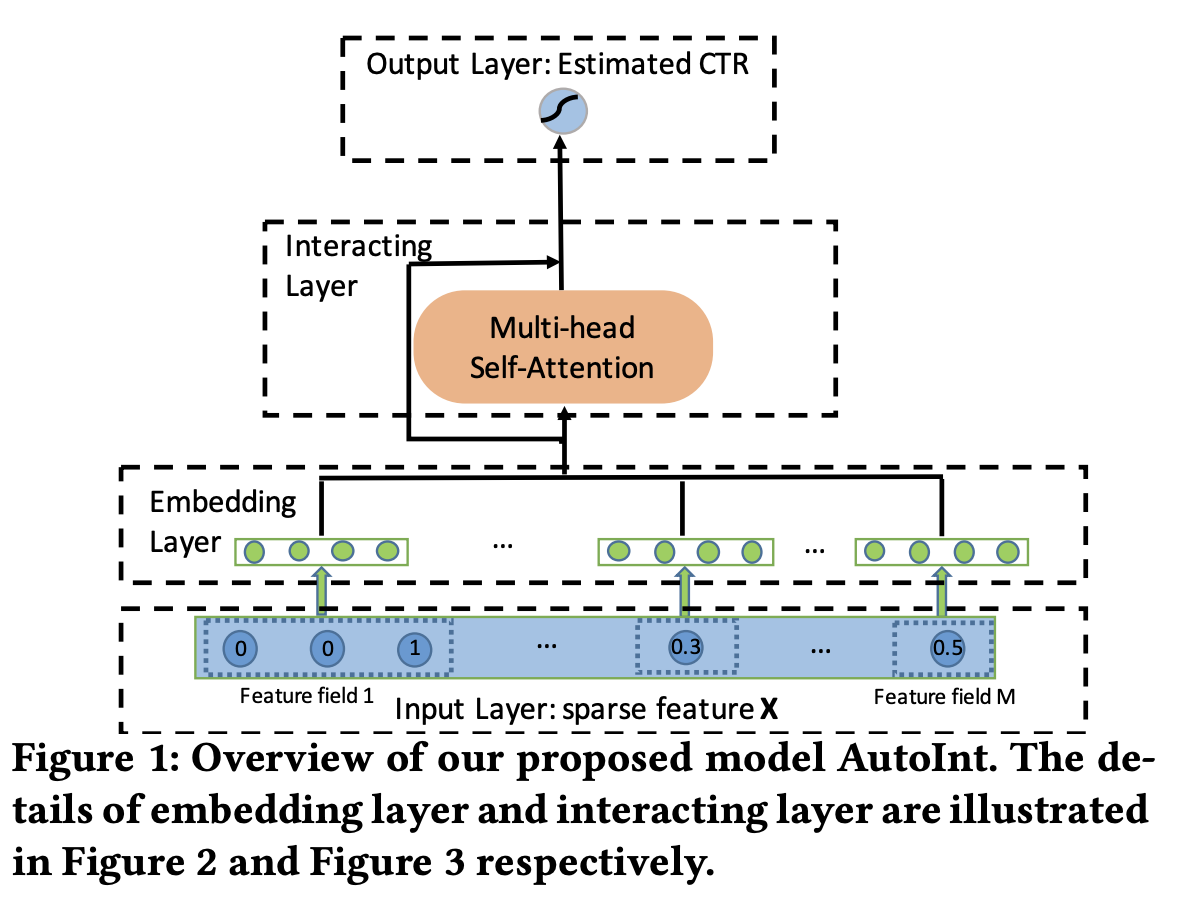
Input & Embedding layer
- Input layer
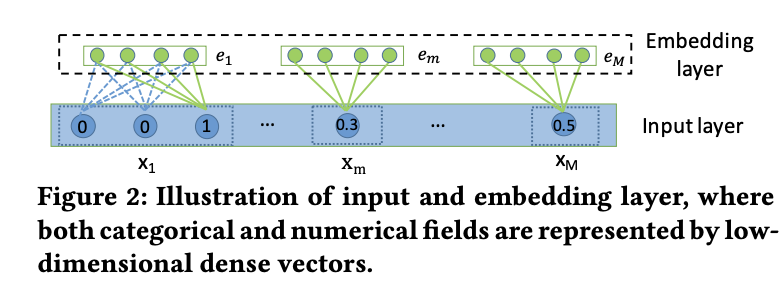

- 사용자 프로필, 아이템 속성을 가져와 모든 필드를 concat(이어줌)
- 데이터 표현 방법
- 범주형 데이터: x(one-hot)
- 수치형 데이터: scalar value
- Embedding layer

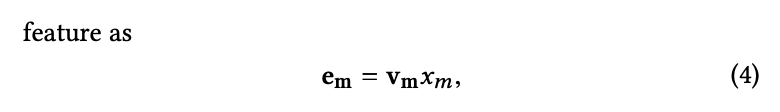
- 범주형 데이터 : 매우 희소 + 고차원 ➡️ 저차원
- 수치형 데이터: 임베딩 벡터와의 곱
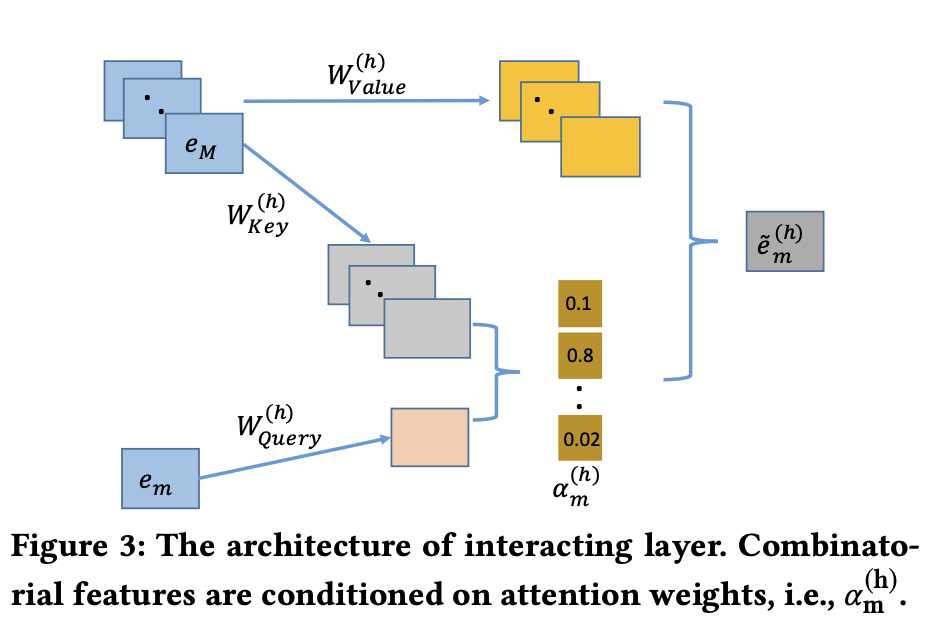
⭐️Interacting Layer⭐️
- Multi Head Attention 구조를 가짐
- 이를 사용하기 위해서는 Self Attention 과정을 수행해야 하며 ➡️ 이는, Scaled Dot Product Attention을 이용해야 함
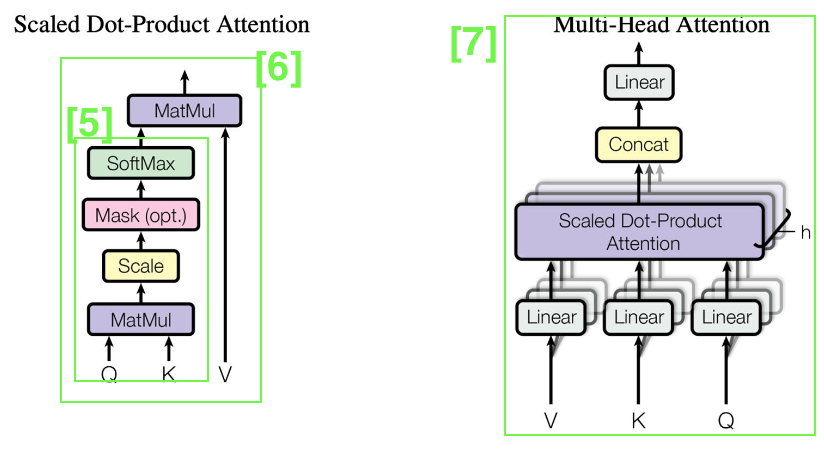
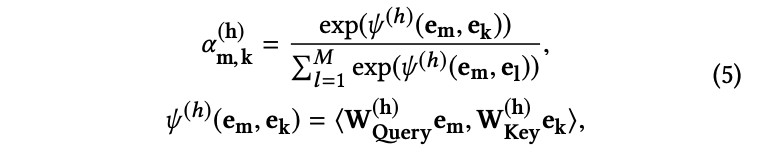
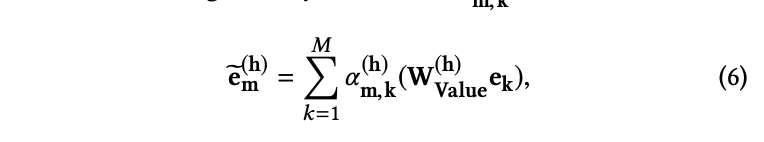
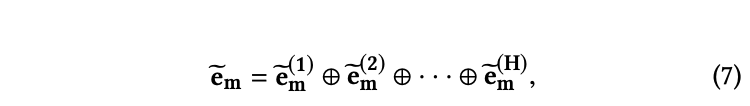
- 내용 정리
- Input feature간의 관계 ➡️ Multi-Head Self-Attention 구조로 모델링 ➡️ High order feature 형성
- 서로 다른 feature들 간 상관관계 모델링
- Query, Key, Value 관계 활용
- Multi Head 구조: Different subspace에서 구별되어 있는 feature interaction를 분리해서 모델링함!
- 이전 정보 보존 및 메모링을 위해 Residual connections을 활용한 Raw individual feature 제공
AutoInt의 전체 아키텍쳐
데이터셋을 이용한 평가
- AUC, Log loss 이용
AutoInt+

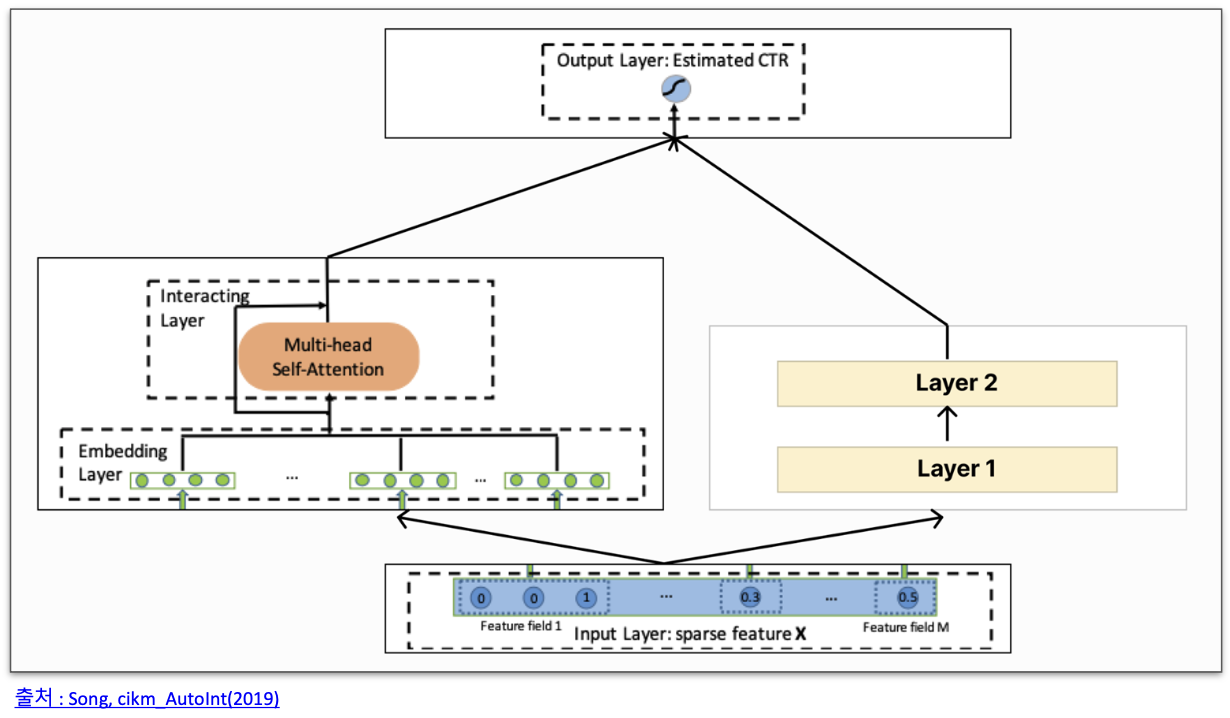
- 피드 포워드 뉴럴 네트워크 구조
- implicit feature interaction 모델링 가능
- 기존 연구들의 경우, implicit feature interaction를 통합하는 형식으로 진행됨
- AutoInt + 2개 레이어를 가진 피드 포워드 뉴럴 네트워크
- Joint를 이용해 훈련
- 성능 향상이 많이 이뤄짐!
AutoInt vs AutoInt+
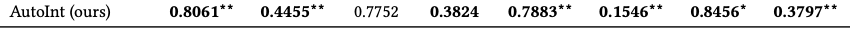
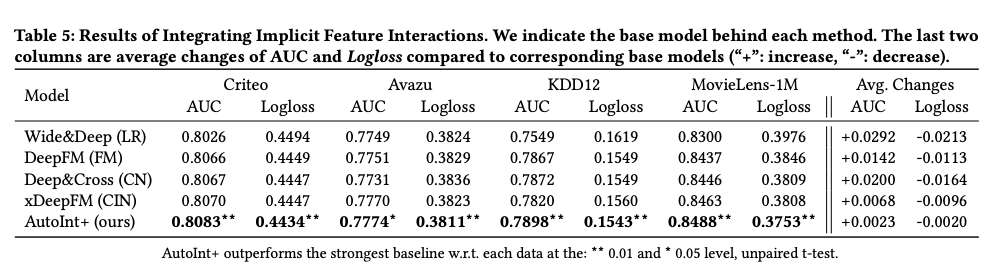
코드리뷰: DeepGraphLearning/RecommenderSystems

multihead_attention
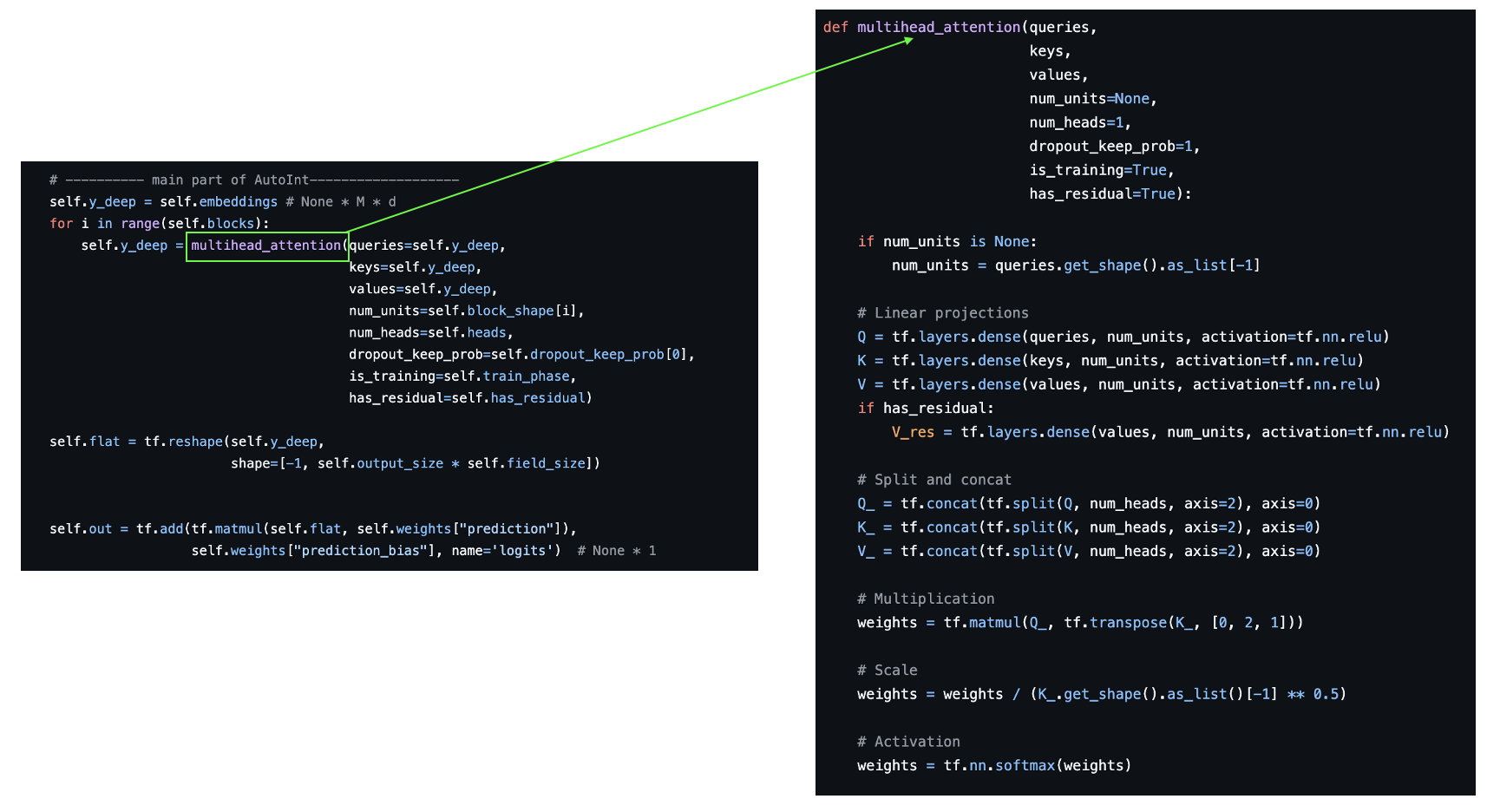
-
Input: queries, keys, values
- 텐서플로우에서 제공하는 Dense 레이어 사용해 벡터값 추출
Q = tf.layers.dense(queries, num_units, activation=tf.nn.relu) K = tf.layers.dense(keys, num_units, activation=tf.nn.relu) V = tf.layers.dense(values, num_units, activation=tf.nn.relu)- 추출한 데이터를 split
- 헤드 개수에 따른 멀티 헤드로 분리하겠다는 것
Q_ = tf.concat(tf.split(Q, num_heads, axis=2), axis=0) K_ = tf.concat(tf.split(K, num_heads, axis=2), axis=0) V_ = tf.concat(tf.split(V, num_heads, axis=2), axis=0)- 쿼리와 키 사이의 Multiplication 추출
# Multiplication weights = tf.matmul(Q_, tf.transpose(K_, [0, 2, 1])) # Scale weights = weights / (K_.get_shape().as_list()[-1] ** 0.5) # Activation weights = tf.nn.softmax(weights)
수식으로 확인
- Attention Score 추출
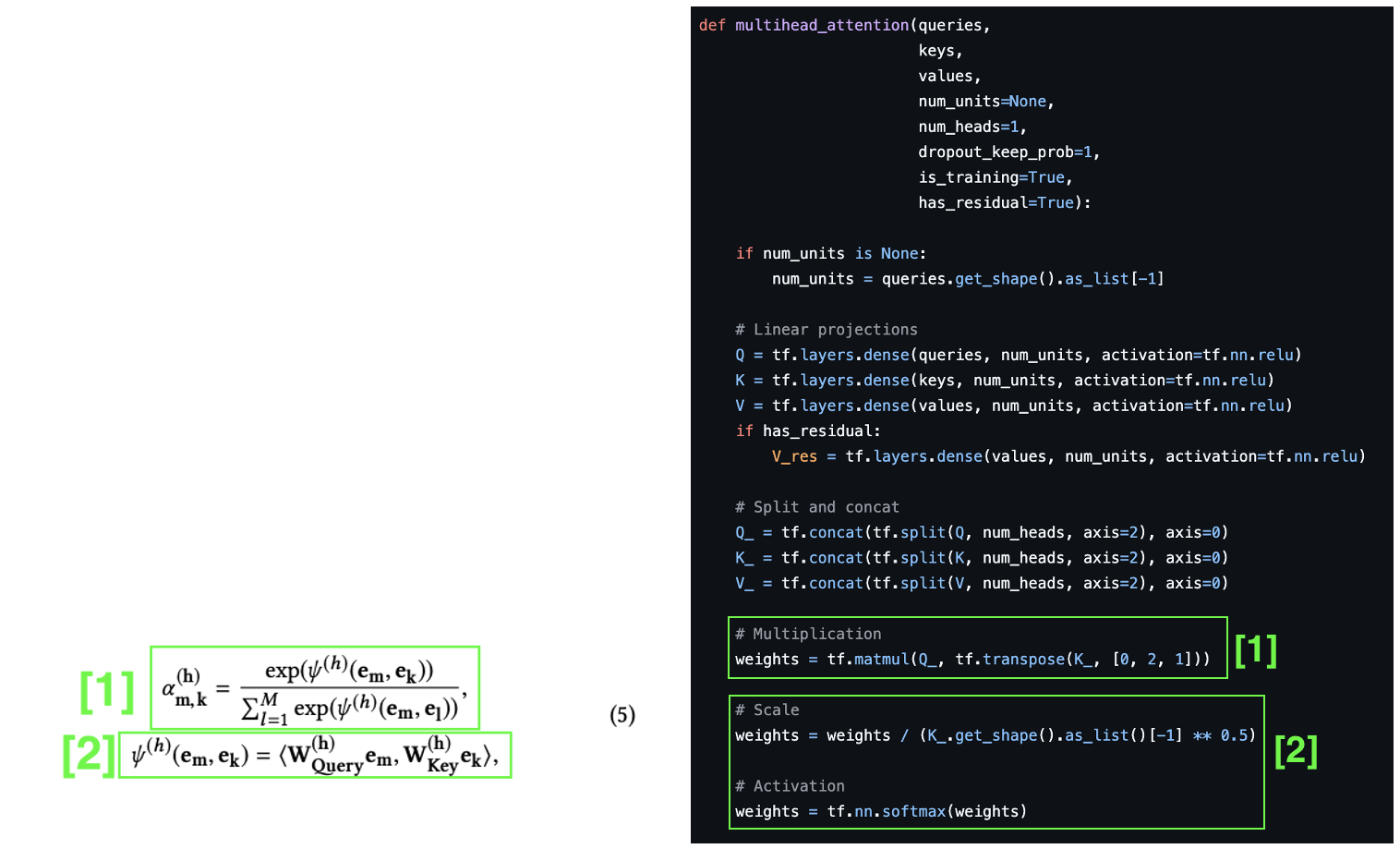
- 추출한 Score를 Value에 곱해 Vectore가 가지는 영향도를 분석

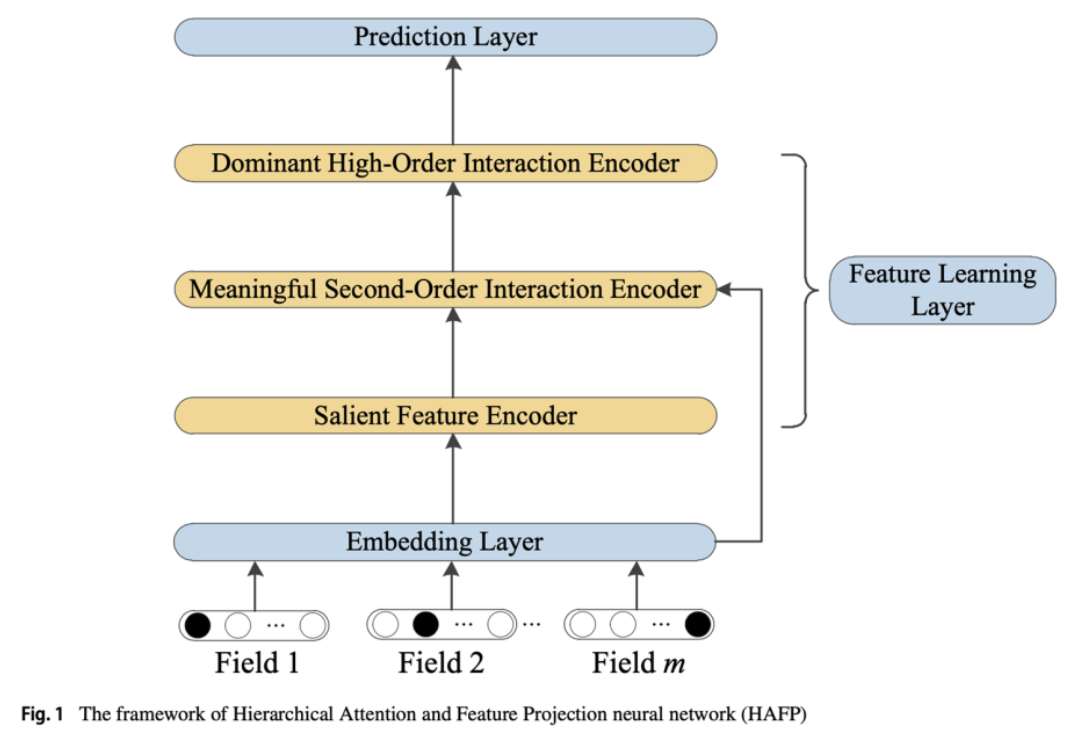
8-6. HAFP
Hierarchical attention and feature projection for click-through rate prediction
주요 기여사항
-
기존 연구
- 각 feature 중요성 무시
- feature interaction를 동등히 다룸
- 내적, 원소곱 등의 연산도 feature learning에 있어 너무 간단한 문제가 있음
-
HAFP 모델 제안
- Hierarchical(계층적 구조) Attention 메커니즘
- 2차 상호작용 ➡️ 유의미하게 변환
- 포괄적이며 세분화된 학습이 가능함
-
핵심 구조
- Salient Feature Layer
- Meaningful Second-order Interaction Encoder
- Dominant High-Order Interaction Encoder
Salient Feature Encoder
- Global Gate

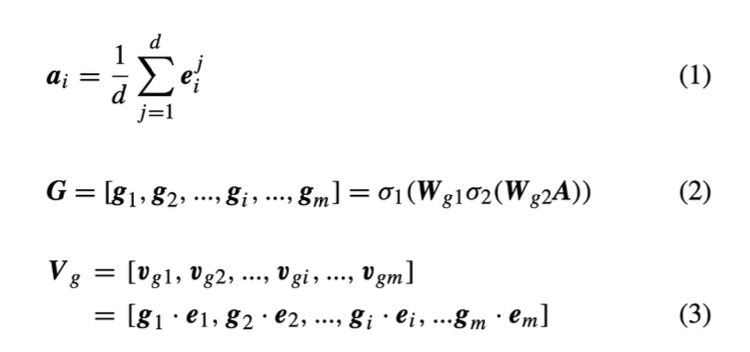
- feature의 글로벌 어텐션 정보를 뜻함
- feature 임베딩 벡터
- 각 임베딩에 Mean pooling ➡️ Global 정보를 획득하는 방식
- 그 후, 뉴럴 네트워크 구조에 글로벌 정보를 넣어 생성된 값을 Global gate G값(Weight값)으로 지정
- 그 결과를 임베딩과 곱해 가중치 적용
- Local Gate
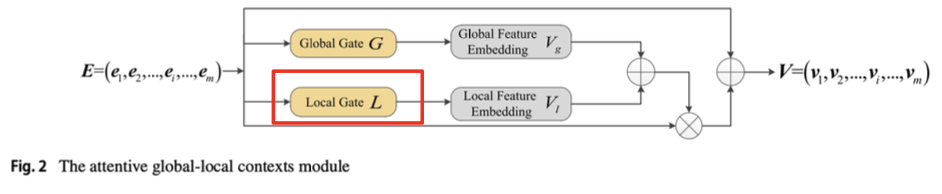
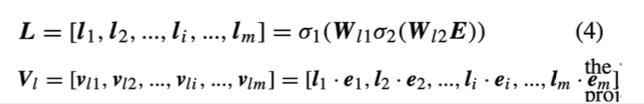
- 각 feature가 가지고 있는 특징 정보
- 뉴럴 네트워크 구조에 벡터를 넣어주어 생성된 값을 Local gate L값(Weight값)으로 지정
- 임베딩과 곱해 가중치 적용
- Local gate, Global gate 값을 이용한 Salient feature vector
- feature 중요도를 Global 및 Lacal 관점에서 구할 수 있는 것!

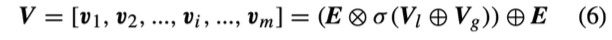
Meaningful second-order interaction encoder
- Second order - p
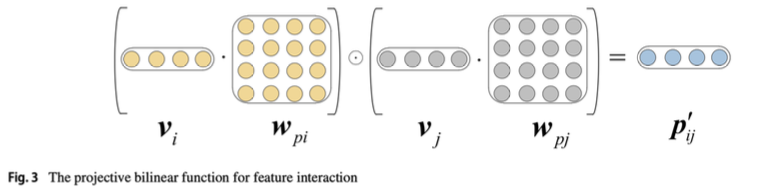
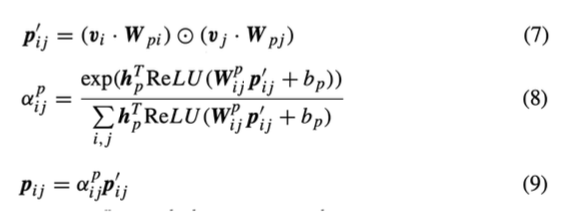
- feature 중요도가 반영된 Salient encoder 결과를 가져오는 것
- 내적을 통한 i, j 사이 feature의 Second order feature interaction
- Attention 값 도출(연관성 있는 feature를 더 부각하려는 용도)
- Second order - q
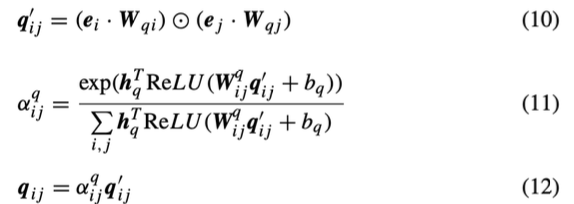
- p를 구했지만, q를 추가로 구하여 Residual connection 효과 기대
- 내적을 통한 i, j 사이 feature의 Second order feature interaction
- Attention 값 도출(연관성 있는 feature를 더 부각하려는 용도)
- encoder 최종 Output
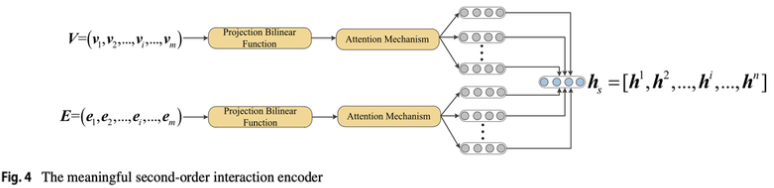
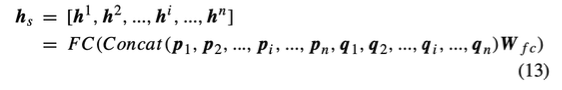
- 2차 상호작용을 더 풍부하게!
- 값들을 Concat ➡️ Fully connected layer 통과 ➡️ 포괄적 정보 학습
Dominant high-order interaction encoder
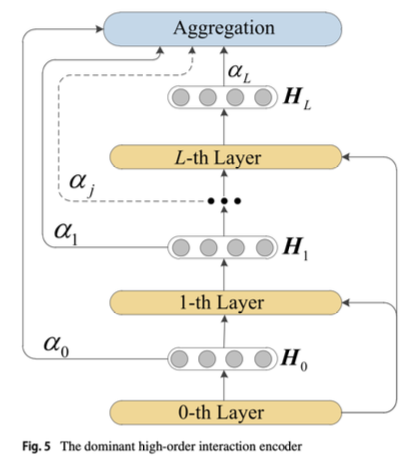
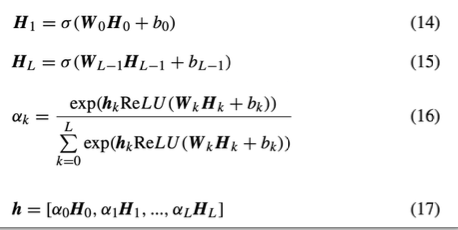
- 계층 구조를 이용한 Layer 사이의 관계 반영
- 각 Layer 마다의 feature 관계가 다른 부분을 고려
- Attention 메커니즘을 이용해 관련 있는 정보만 담을 수 있도록 하는 encoder
