5-1. 들어가며
학습 목표
- 상황에 맞는 데이터 처리(다양한 방법을 통해)
- 주어진 데이터 -> 추가 정보 찾아내기
5-2. 컬럼 이름 변경, 결측치 처리(Missing values)
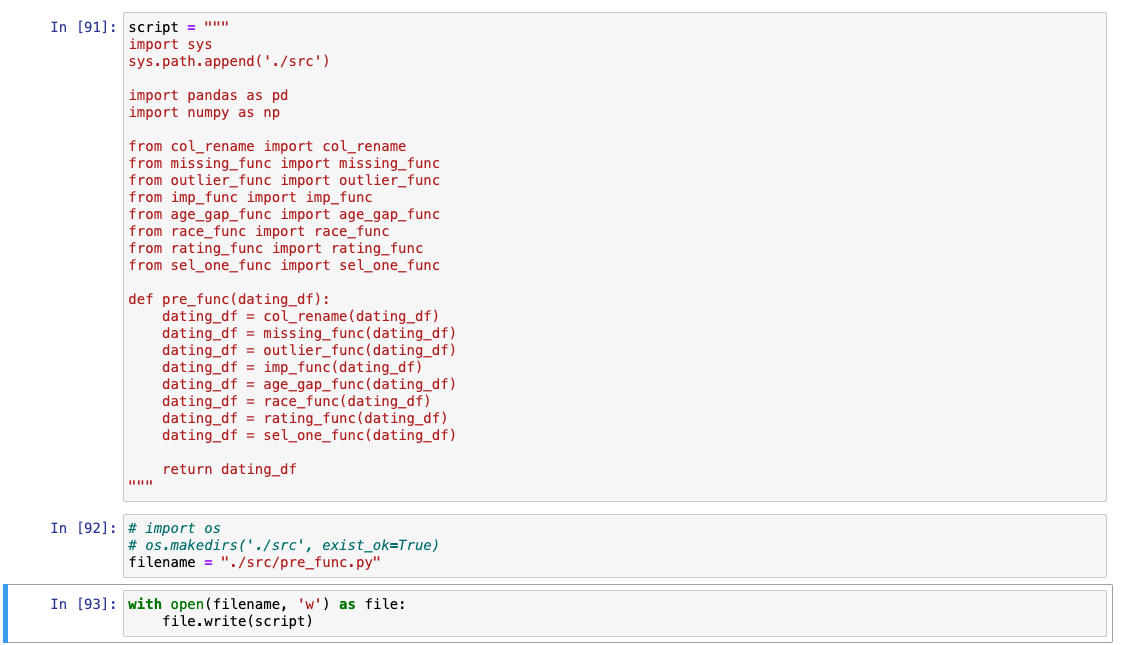
컬럼 정보
gender,age,age_o,race,race_o: 성별, 나이, 상대방 나이, 종교, 상대방 종교importance_same_race: 같은 인종이어야 하는 것에 대해서 얼마나 중요하게 생각하는지importance_same_religion: 같은 종교여야 하는 것에 대해서 얼마나 중요하게 생각하는지
pref_o_...: 상대방 정보, 뒤에 붙는 항목을 얼마나 중요하게 생각하는지를 점수화(모든 점수의 합이 100이 되도록 분배)- 6개 : 'pref_o_attractive', 'pref_o_sincere', 'pref_o_intelligence', 'pref_o_funny', 'pref_o_ambitious', 'pref_o_shared_interests'
..._o: 각 항목에 대한 상대방의 평가- 6개 : 'attractive_o', 'sincere_o', 'intelligence_o', 'funny_o', 'ambitous_o'
..._important: 본인이 생각했을 때 각 항목이 얼마나 중요한지- 6개 : 'attractive_important', 'sincere_important', 'intellicence_important', 'funny_important', 'ambtition_important', 'shared_interests_important'
_partner: 파트너에 대한 평가- 6개 : 'attractive_partner', 'sincere_partner', 'intelligence_partner', 'funny_partner', 'ambition_partner', 'shared_interests_partner'
interests_correlate: 취향 유사도(상관관계로 표현)expected_happy_with_sd_people: 이벤트에 대한 기대 정도expected_num_interested_in_me: 나에게 관심을 보이는 정도like: 상대방이 얼마나 좋았는지 점수로 표현guess_prob_liked: 상대방이 나에게 몇 점을 주었을지 표현match: 커플 성사 여부
머신러닝 관점
match: 예측해야 할 종속 변수- 나머지 독립 변수들을 이용해 실제 결과를 알기 전까지의 정보만 보고 매칭률을 예측!
데이터가 어떻게 구성되어있는지 살펴보기

-
10줄을 보면, gender와 age, race 동일 -> 상대방 정보만 바뀜. -> 동일인인건지 살펴봐야 함.
-
importance_same_race, importance_same_religion 역시 동일
-
그 외에도 확률에 대한 분포값들이(데이터들이) 동일함.
-
20개를 확인해보니 확실히 10개 행 단위로 한 명의 사람임을 알 수 있음.

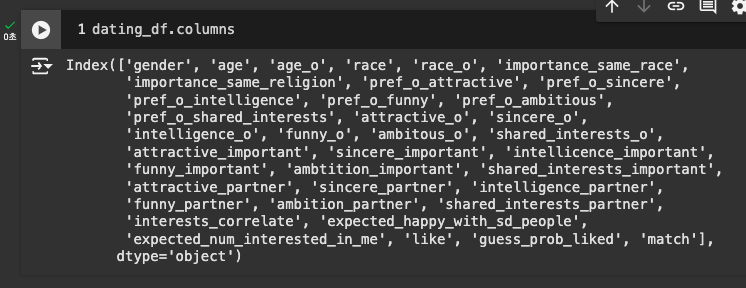
info로 데이터 자세히 살펴보기
-
Missing Value 다수 존재
-
대부분이 숫자형 데이터 -> object 데이터만 잘 살펴보면 될 듯
-
데이터 타입에는 문제가 없음을 알 수 있음.
-
1~10까지의 값에서 이상한 값 발견 -> 정리 필요
컬럼 이름 변경
- 이름 형태가 직관적이지 않음.
컬럼명을 쉽게 모으기 위한 함수 사용
-
'단어'.startswith('알파벳'): 단어가 그 알파벳으로 시작하는지 -
'단어'.endswith('알파벳'): 단어가 그 알파벳으로 끝나는지
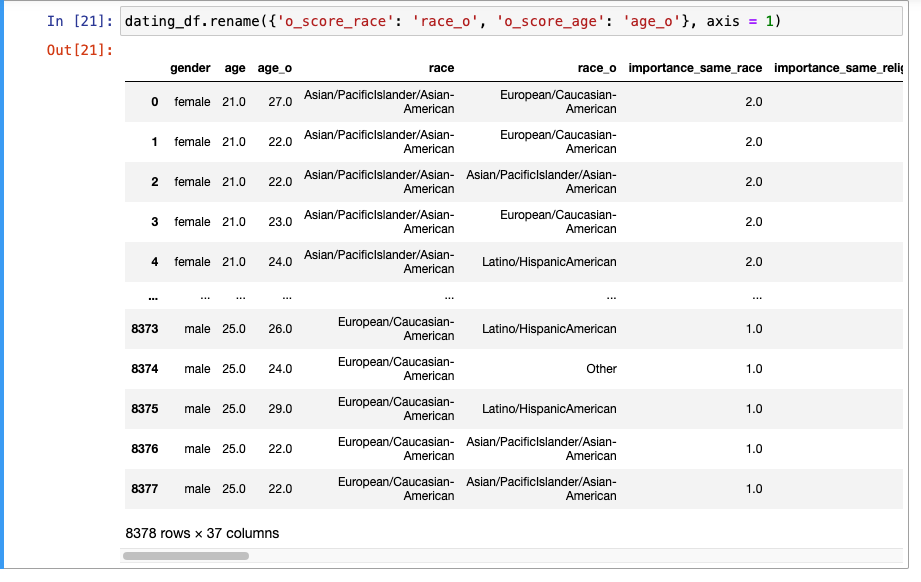
컬럼명 변경

-_o로 끝나는 부분이 변환되어서 의도치 않은 변경이 일어남.

- 다시 이 두 부분 변경(rename)

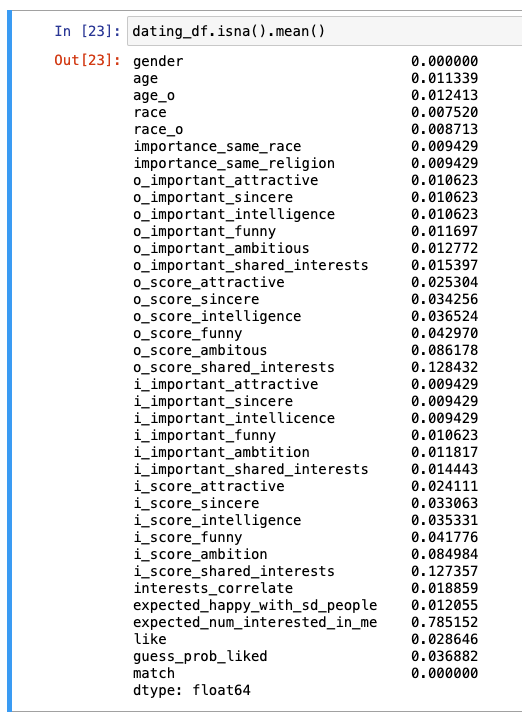
결측치 처리
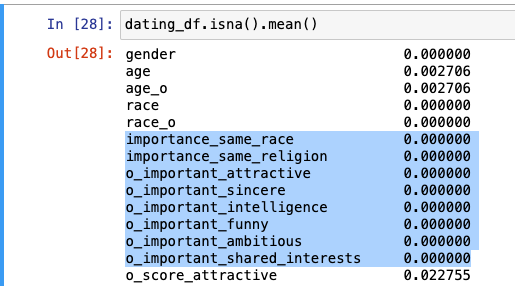
- 결측치 비율 확인 : 거의 모든 컬럼에 결측치 존재
🚨 중요 : 머신러닝 학습 시 종속변수에 결측치가 존재한다면 그 결측치는 무조건 DROP해야 함.
- 최빈값, 평균값 등으로 채울 수 없음.
- 종속 변수는 정답값이기 때문에 노이즈 이상으로 잘못된 데이터가 될 수 있음!!
- 독립 변수는 노이즈를 감수하고 대체 가능
important 관련 처리
- 6개가 한 세트로 되어 있음 -> 합이 100
- 임의의 값으로 채울 경우 100이 깨질 수 있기 때문에 함부로 채우기 어려움.
- 이 여러 개의 값 중 1개 정도만 결측치라고 한다면 채울 수 있을 것.
- 확인해보기
- 다른 값들도 다 결측치 처리되어 있으니 임의로 채울 수 없음.
- important 라인을 평균치로 채우는 것도 애매함.
- 제거하는 것으로 결론.
- 다른 값들도 다 결측치 처리되어 있으니 임의로 채울 수 없음.
- 확인해보기
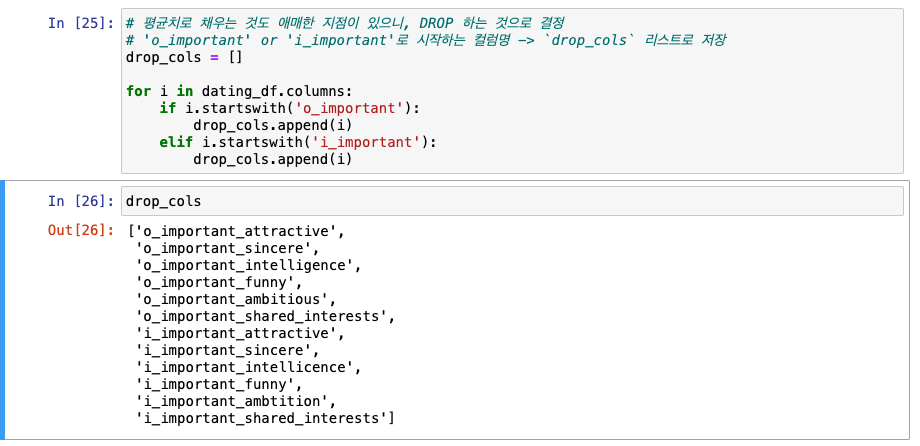
important 관련 컬럼 결측치 제거
-
'o_important' or 'i_important'로 시작하는 컬럼명 ->
drop_cols리스트로 저장
-
저장한
drop_cols를 드랍

-
결과
다른 컬럼들
- 쉽게 생각하면 min 값으로 채워줄 수도 있겠지만, 이 데이터의 특성을 따져보면 응답을 하지 않은 것의 의미가 있을 수 있음.
- 무응답 처리를 할 수 있었을 가능성이 매우 높음.
무응답에 대한 처리: -99로 채우기
- 최빈값이나 평균값이 아닌 임의의 값으로 처리

이렇게 처리할 수 있는 이유
- object 컬럼(gender, race, race_o)의 결측치가 없음.
- 숫자형 컬럼에만 결측치가 있음.
-99와 같은 수치를 넣고 -> 선형 모델을 쓰면 안됨!
- 선형 모델에서는 그 수치를 굉장히 좋지 않고 낮은 것으로 받아들임.
- 선형 모델은 숫자의 크고 작음에 많이 민감하기 때문.
- 트리 기반 모델은 선형 모델보다 덜 민감.
5-3. 이상치 처리(Outlier), 나이차(Age), 인종(Race)
-
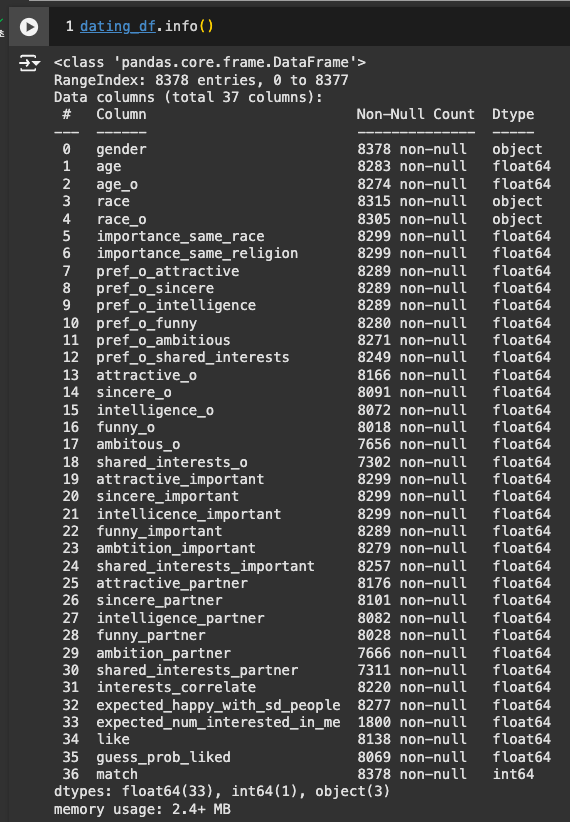
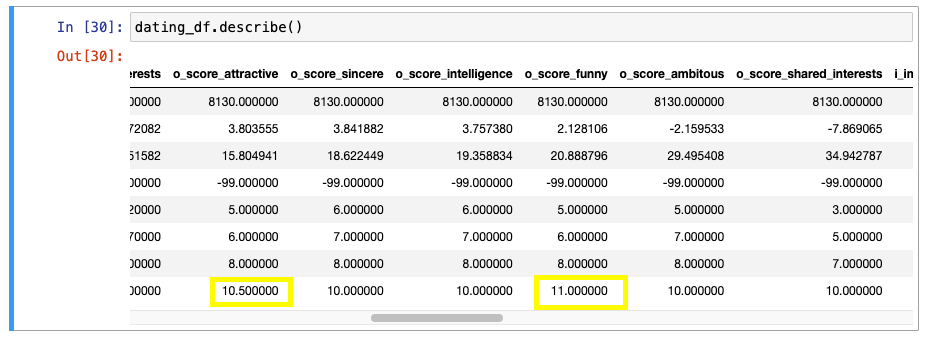
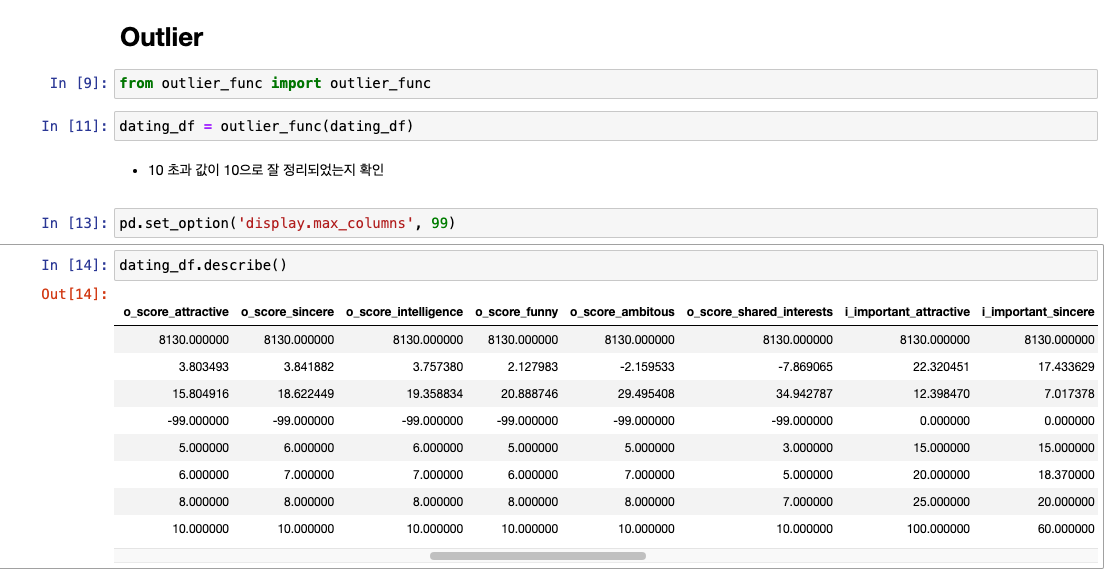
수치 다시 한번 확인
-
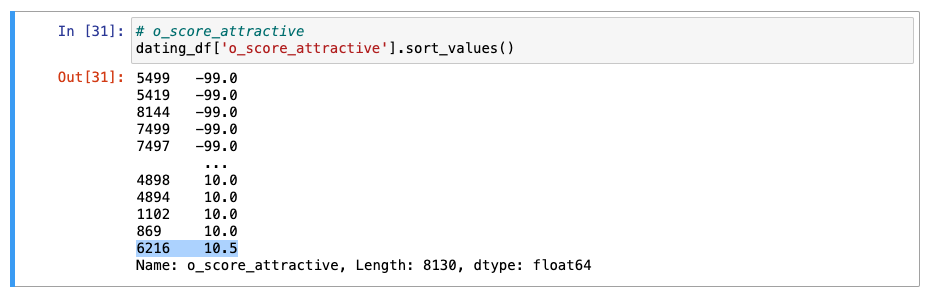
o_score_attractive
- 1명이 10.5로 수치를 작못 작성
- 1명이 10.5로 수치를 작못 작성
-
o_score_funny
- 1명이 11로 수치 잘못 작성

- 1명이 11로 수치 잘못 작성
- 둘 다 10 초과값을 정리해서 없애기


-
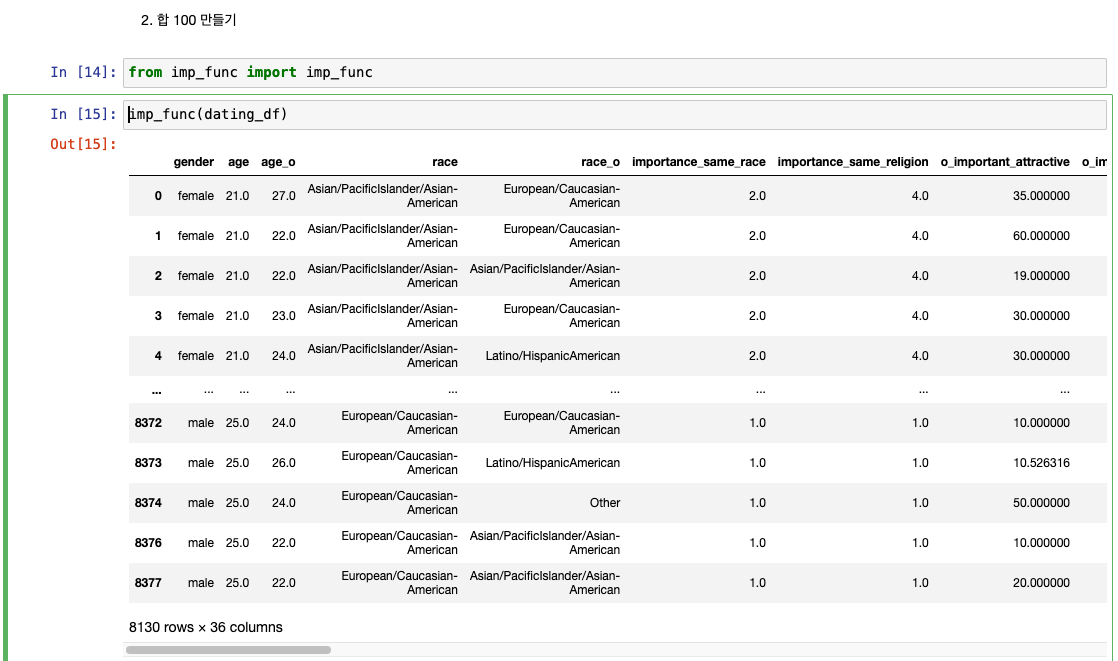
import 관련 컬럼 6개 합이 100 미만 또는 100 초과하는 케이스도 정리
-
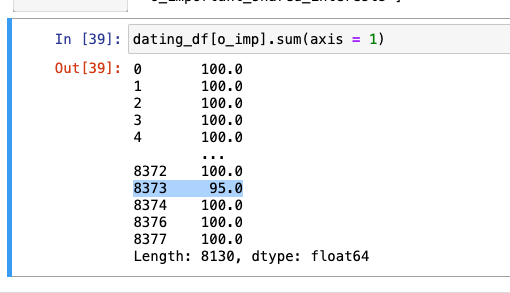
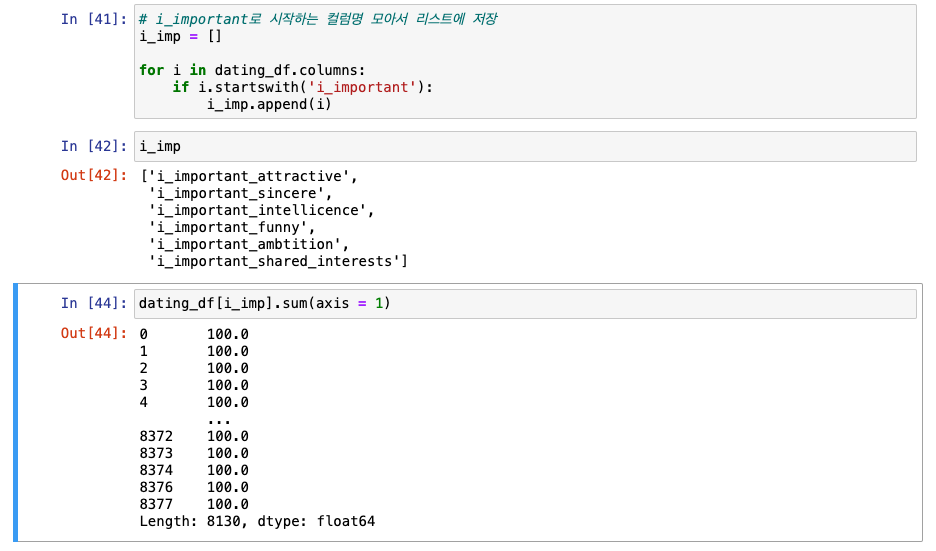
o_important로 시작하는 컬럼명 모아서 리스트에 저장

-
100이 아닌 수치 찾기 -> o_imp_sum으로 저장

-
i_impotant도 동일하게 진행

-
확인
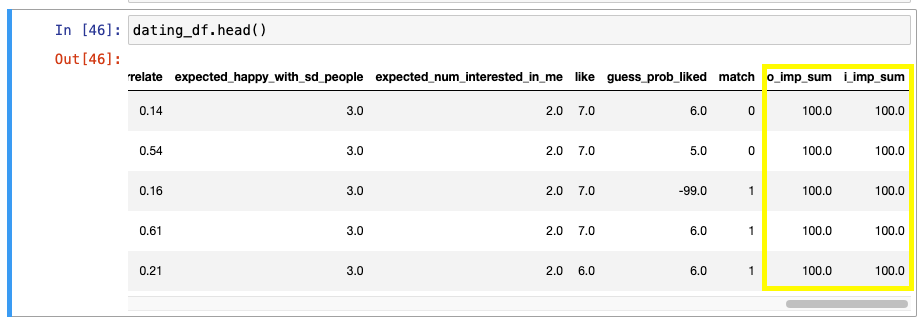
-
아웃라이어는 아니지만 처리해야할 값
-
합이 100이 아닌 경우 찾기
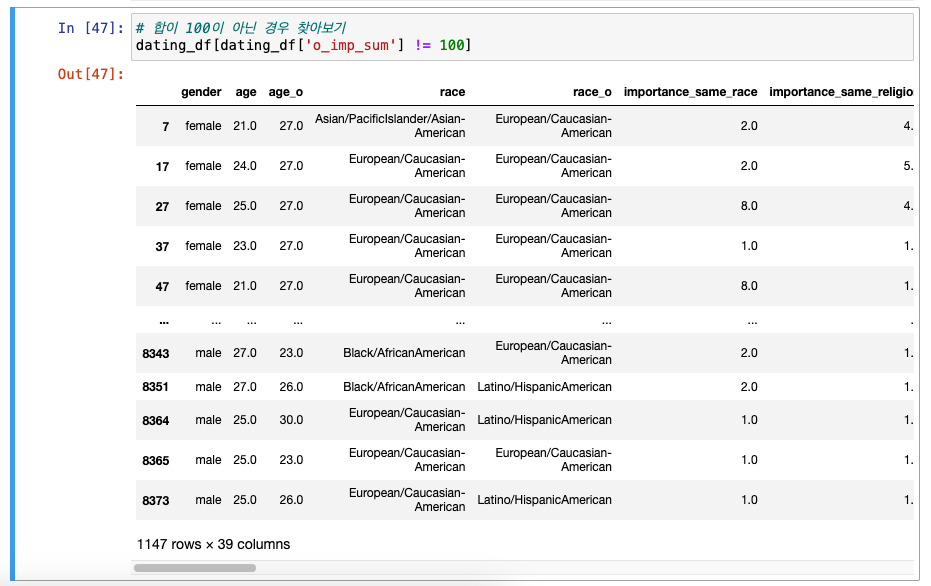
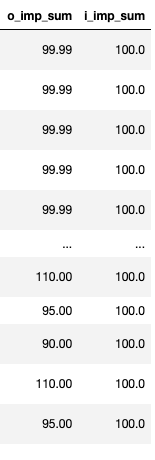
-
해결 방법 : 강제로 합이 100이 되게끔 가중치를 부여!
- 합계가 95인 값을 -> 합이 100이 되게끔 하려면
- 100/95 -> 1.0526315789473684 -> 이게 가중치
- 그러면 이걸 다시 95를 곱하면 -> 합이 100이 됨!

-
95였던 합이 100으로 맞춰짐(i, o 모두 진행)



-
이제 필요없어진 o_imp_sum, i_imp_sum 다시 드랍

Feature Engineering 시작하기
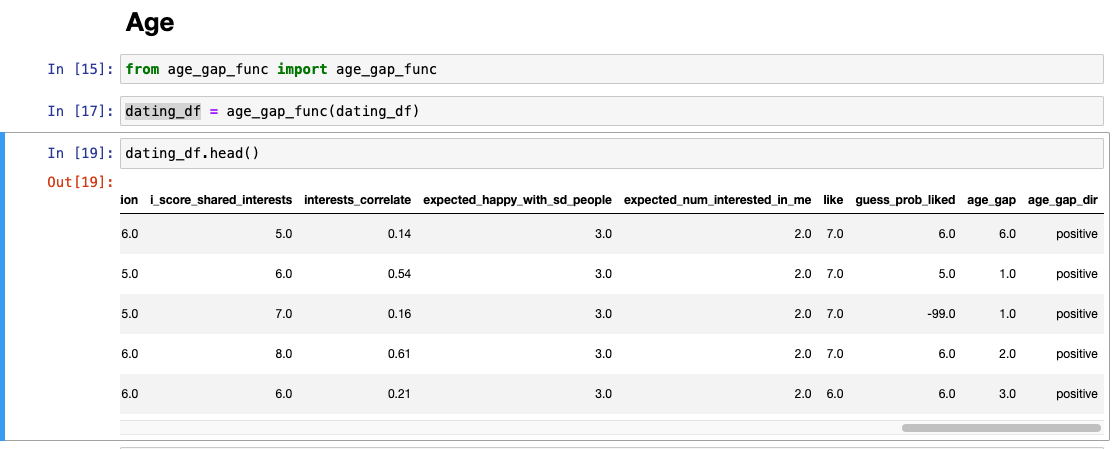
나이차 계산 : age - age_o
-
결측치가 있었다는 문제가 있었고 -> -99로 채웠음.
-
바로 계산 시 음수값들이 나올 것임.
나이 부분에 -99 값이 있을 경우 -> 나이차도 -99로 정리
-
나이차가 남자가 더 많은지, 여자가 더 많은지에 따라서도 변수가 될 수 있음.
실습
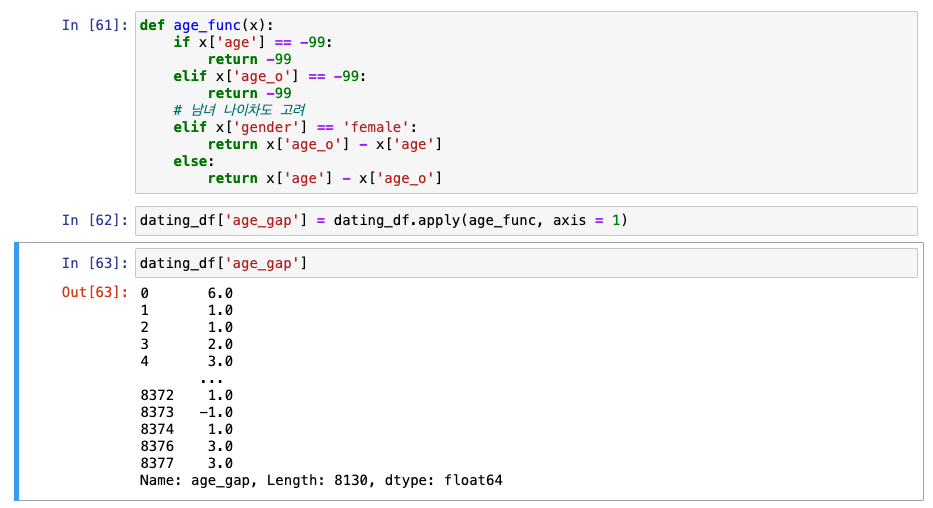
+, -는 어느쪽의 나이가 더 많은지에 대해서 표시한 것 -> 그러나 컴퓨터 입장에서는 -로 갈수록 나이차가 계에속 더더더더 적어진다고만 생가할 것임.
-
별도 컬럼을 만들어 남녀 구분이 가능하도록 할 것.
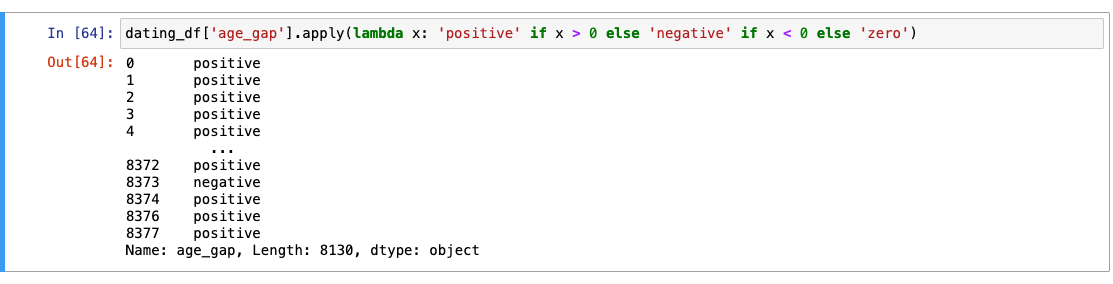

-
절대값 처리(구분한 컬럼을 만들었으니까)

-
값 확인 : 나이차 적용이 잘 되었는지 확인하기
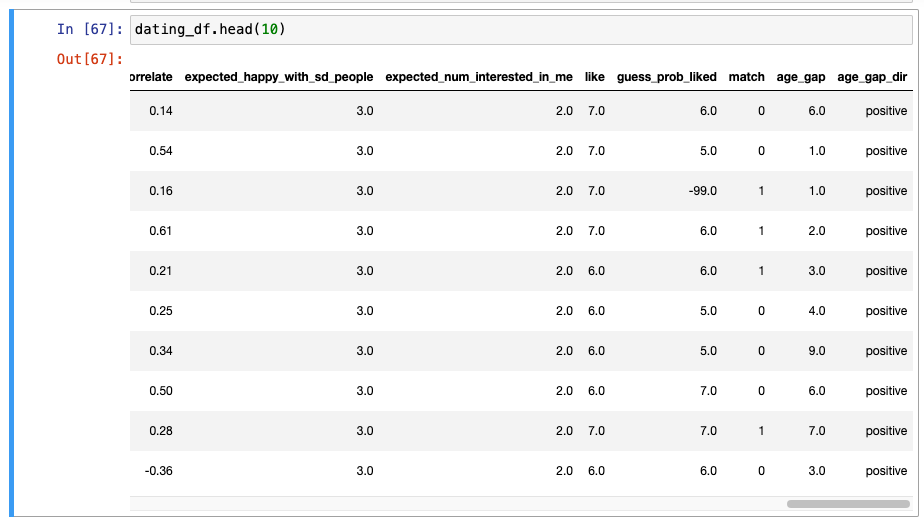
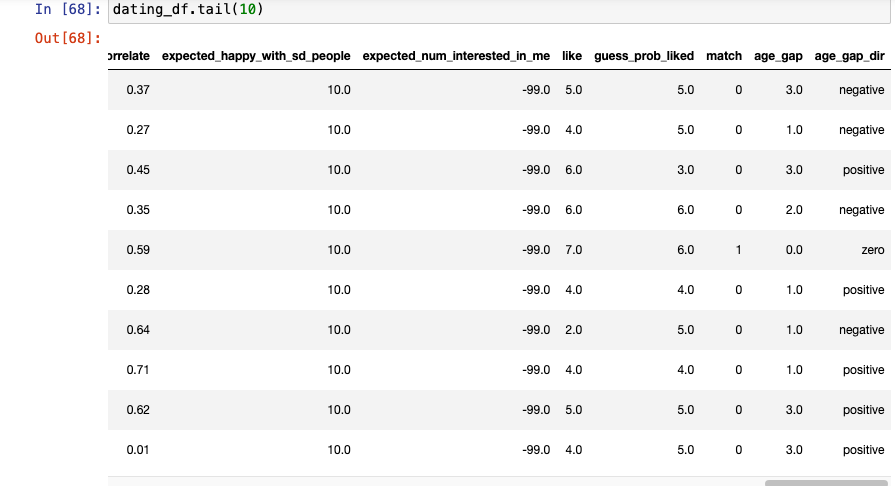
인종(Race)이 같은지 아닌지 확인
-
결측치 처리를 했고, 드랍을 했기 때문에 -99같은 값은 없을 것.
- 확인
- 확인
-
같은 인종인지 여부 ->
same_race로 저장

-
same_race에 importance_same_race를 곱해주면
- 같은 인종이라면 : 1 * 중요도(importance_same_race)
- 다른 인종이라면 : 0 * 중요도(importance_same_race)
- 디테일을 두어서 그 정도의 차이를 내는 것.
-
하지만, 인종이 다른 경우는 무조건 0이 곱해지는 문제 발생
- 인종이 같은지 여부가 매우 중요한데 -> 인종이 달랐다 -> 0이 되어버림.
same_race의 0 부분을 -> -1로 변경해서 의도한 값이 나오도록!
- 0 값을 -1로 조정

- 계산

5-4. 평가(Rating) 관련 피처 생성 및 활용
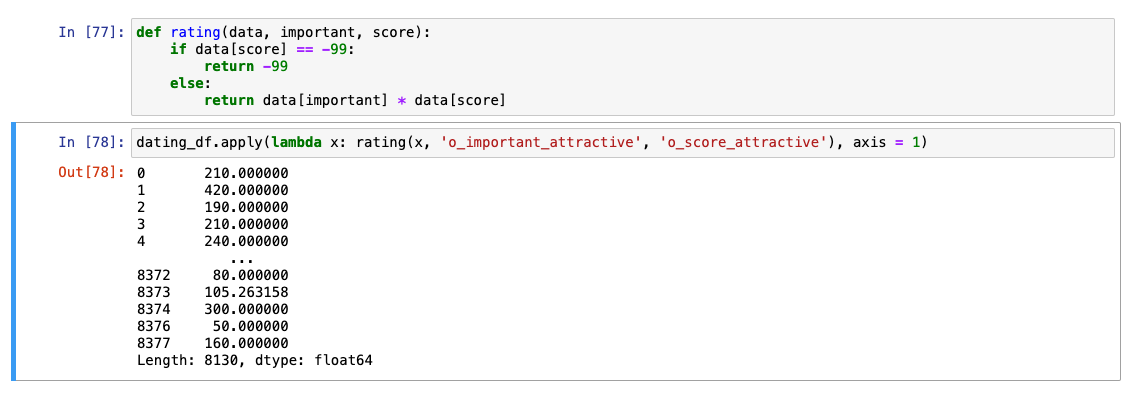
importance와 score를 엮어서 계산하기
-
상대방에게 준 점수를 수치화하는데 더 유의미한 결과가 나올 것.
🚨주의 : score에는 -99로 결측치를 채워준 부분이 있음.
즉, -99가 포함되었을 경우 ➡️ -99로 계산 결과값이 나오도록 조정
-
리스트 모아주기

참고 : zip 함수 사용법
-
o_rating, i_rating에 들어갈 컬럼명 지정
-
o_rating
-
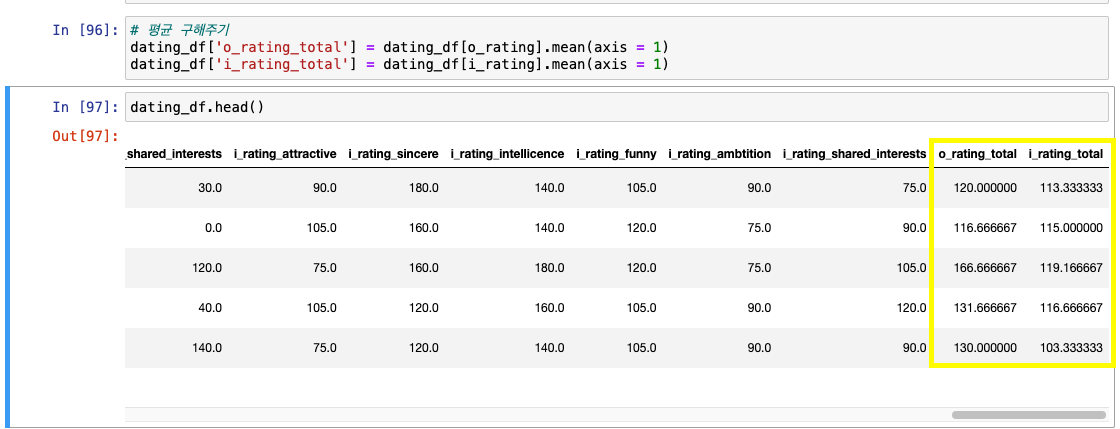
계산 결과를 -> o_rating, i_rating으로 저장

-
확인

-
-
i_rating
- 동일하게 진행

- 동일하게 진행
-
각 rating 평균값 구하기
더 고려할 부분
- rating 점수의 0점
- score가 0점이거나 important 부분이 0인 경우가 있음.
- 중요도가 0이라면 -> 중요하지 않게 생각하니 0으로 들어가는게 맞음.
- 하지만 10점을 줬지만, 중요하지 않아서 0점이 된 경우 -> 계산에서 제외되는 것이 맞음!
남은 계산
- i_important_sincere의 0을 -> -99로 처리
- -99로 연산된 rating도 -99의 결과가 나올테니 -> 다른 -99들과 함께 평균에서 제외!
important

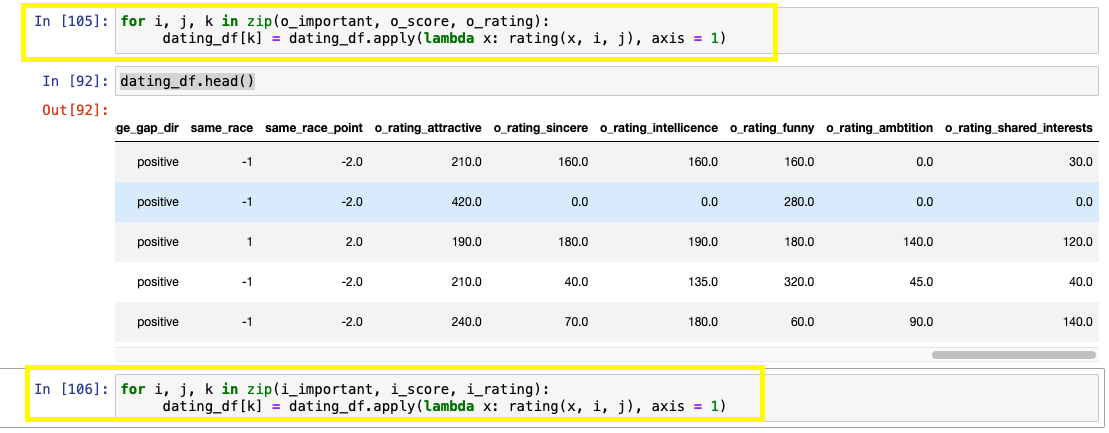
- rating 함수 수정
- -99로 처리되는 값이 늘었으니까!

- i_rating, o_rating 재적용(이 두 부분 재실행)
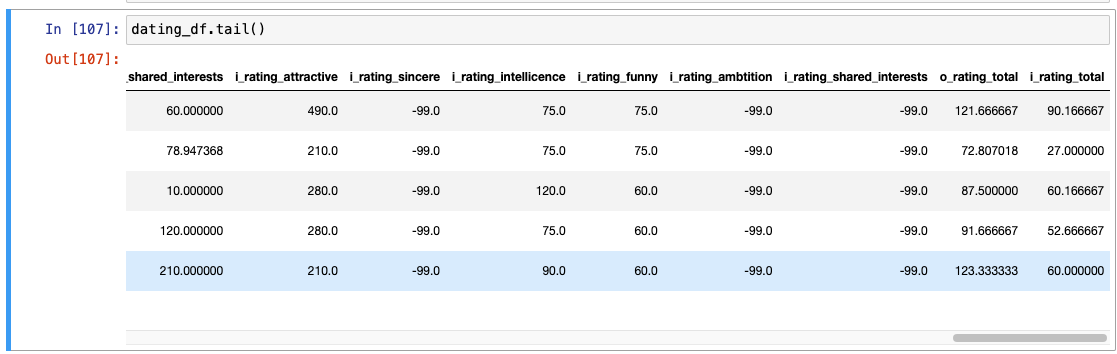
- 확인 : 0은 사라지고 -99로 다 바뀌었음을 확인
- -99로 처리되는 값이 늘었으니까!
평균이 잘못되었던 부분 수정! -> -99를 제외할 수 있도록
-
바로 평균을 구하는 코드를 전체에 적용하기보단, test를 해보고 이해한다음 코드를 잘 써서 적용해보자.
-
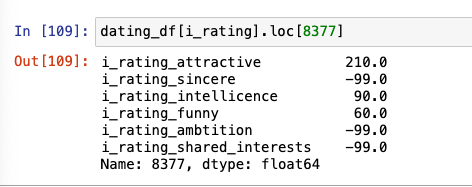
8377번(-99가 3개 있음)으로 test
- -99 제외하는 방법 고민
- True인 것만 확인

- True인 것만 확인
- -99 제외하는 방법 고민
-
dating_df[i_rating].loc[8377][dating_df[i_rating].loc[8377] > 0].mean()이 개념을 통해 평균 코드 일반화해 작성하기

-
head(), tail()로 다시 확인
마지막 피처 엔지니어링: 나의 rating total 값과 상대방의 rating total 값을 연산하자.
- 내가 상대방에게 높은 점수를 줬고, 상대방도 내게 높은 점수를 줬다면 매칭 확률이 더 올라갈테니!
- 그럼 단순히 o_rating_total과 i_rating_total의 평균을 구하면 되지 않을까?
문제 상황
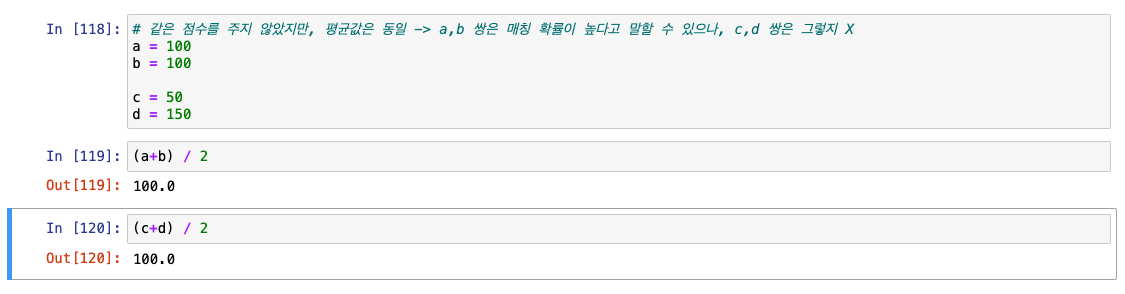
- 같은 점수를 주지 않았지만, 평균값은 동일 -> a,b 쌍은 매칭 확률이 높다고 말할 수 있으나, c,d 쌍은 그렇지 X
해결법: 조합 평균(=가중평균)
🧐 조합 평균이란?
- 두 값이 비슷할수록 -> 평균값이 높게 측정됨.
- 조합 평균 구하는 방법 :
2 * 데이터1 * 데이터2 / (데이터1 + 데이터2)

나의 rating total 값과 상대방의 rating total 값의 "조합평균"을 구하자.
dating_df['rating_mean'] = 2 * dating_df['o_rating_total'] * dating_df['i_rating_total'] / (dating_df['o_rating_total'] + dating_df['i_rating_total'])
- 피처 엔지니어링은 끝.
중요하지 않은 컬럼은 제외하자.
- age_o : 나이차를 계산했으니 불필요
- race_o : 종교 일치 여부 계산했으니 불필요
- i_important.., o_important.., i_score.., o_score.. : rating 값 계산을 마쳤기 때문에 불필요
- importance_same_religion : 없는 내용이기 때문에 빼기
남겨둘 컬럼
-
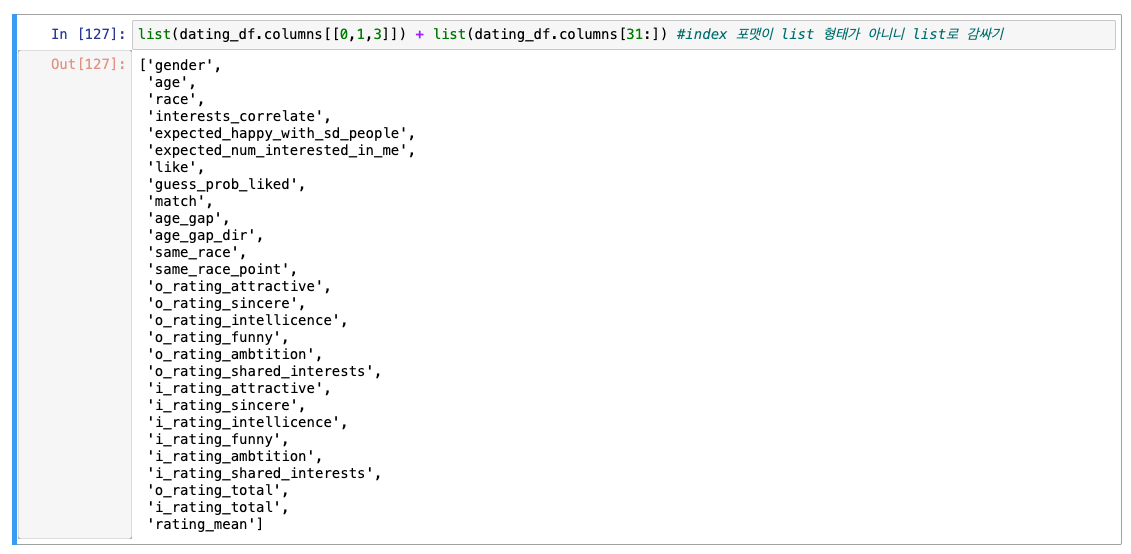
위의 제외 컬럼 빼고 아래 사진(gender, age...등등 기본은 물론 무조건 유지!)

-
계산

-
same_race도 삭제

-
same_race_point만 잘 남은 것 확인 완료
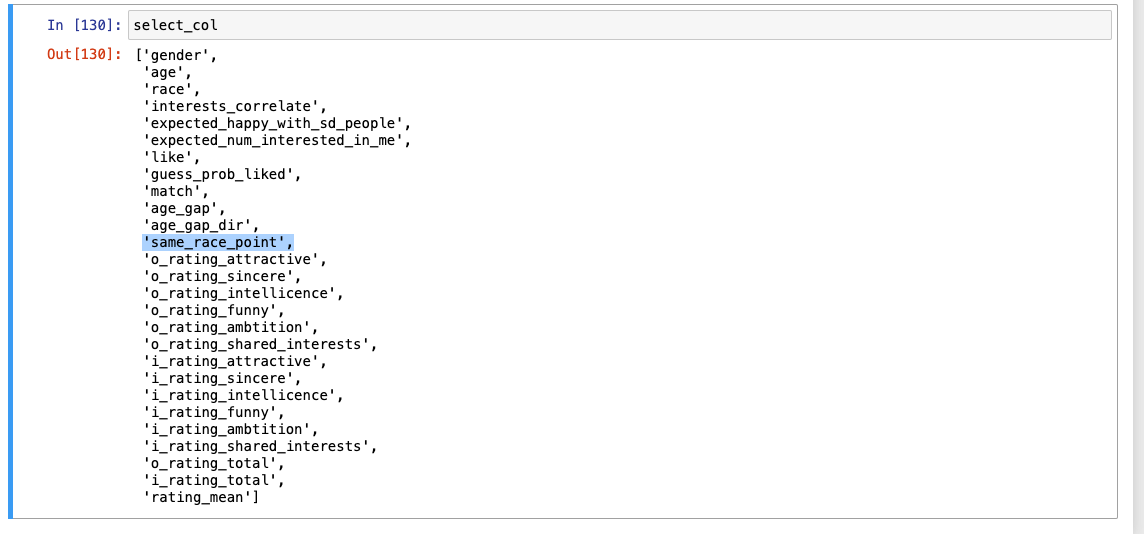
최종 결과
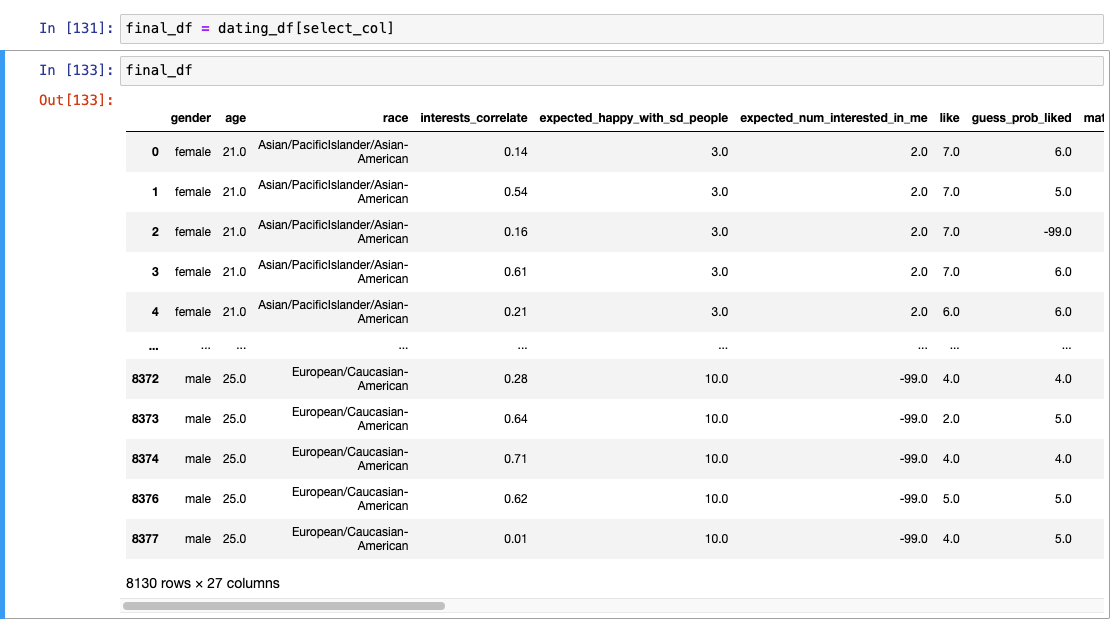
- object 컬럼들 원핫인코딩 필요!
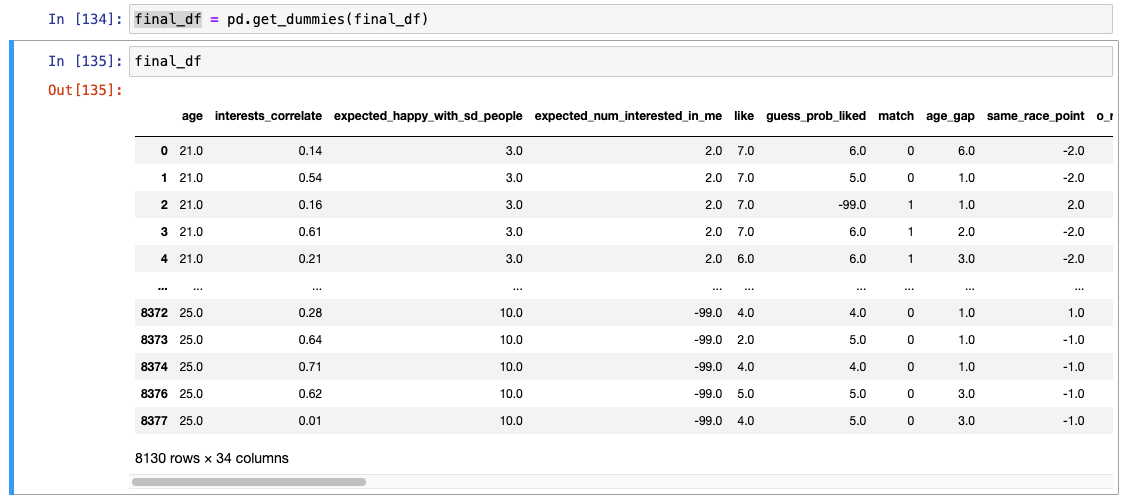
이 데이터를 적용할만한 모델은?
- 트리 기반 모델
- 거리 기반 모델이나 선형 모델의 경우에는 적합하지 않음.(- 구간 거리를 반영할 것이기 때문)
- 스케일링은?
- 그렇게 필요할만한 상황은 아님.
5-5. 퀴즈
5-6. 실무팁(Code Function)
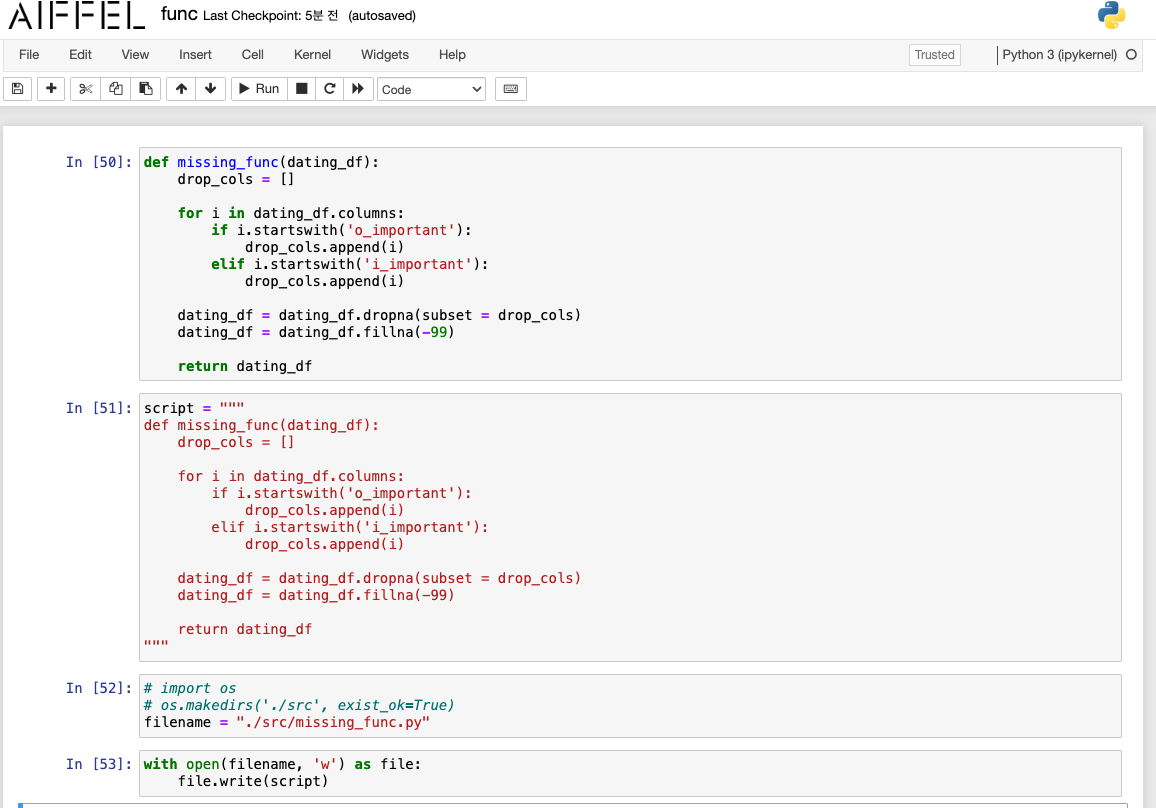
Code Function을 정리하자.
기본 사용 방법
func.ipynb
-
함수 정의

-
script로 등록

-
파일 저장(루드 폴더에 src 폴더 미리 생성)

FileNotFoundError
import os
os.makedirs('./src', exist_ok=True)
- 실제로는 aiffel 폴더 내부에 src로 저장됨!

test.ipynb
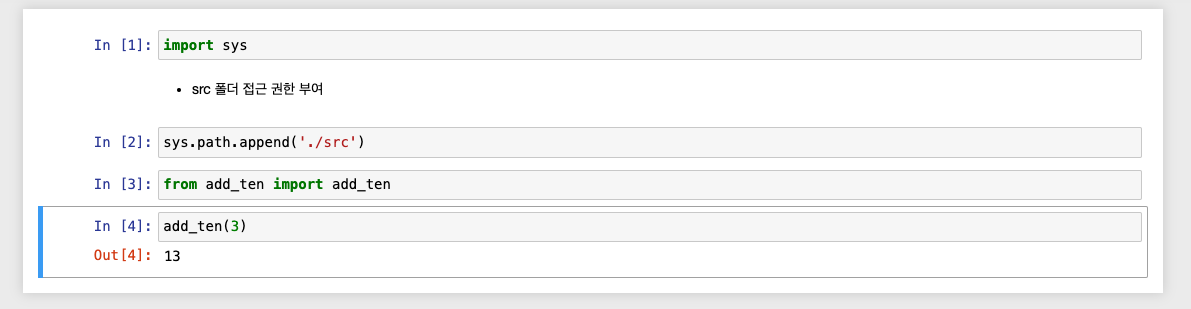
스피딩 데이터 파일에 적용
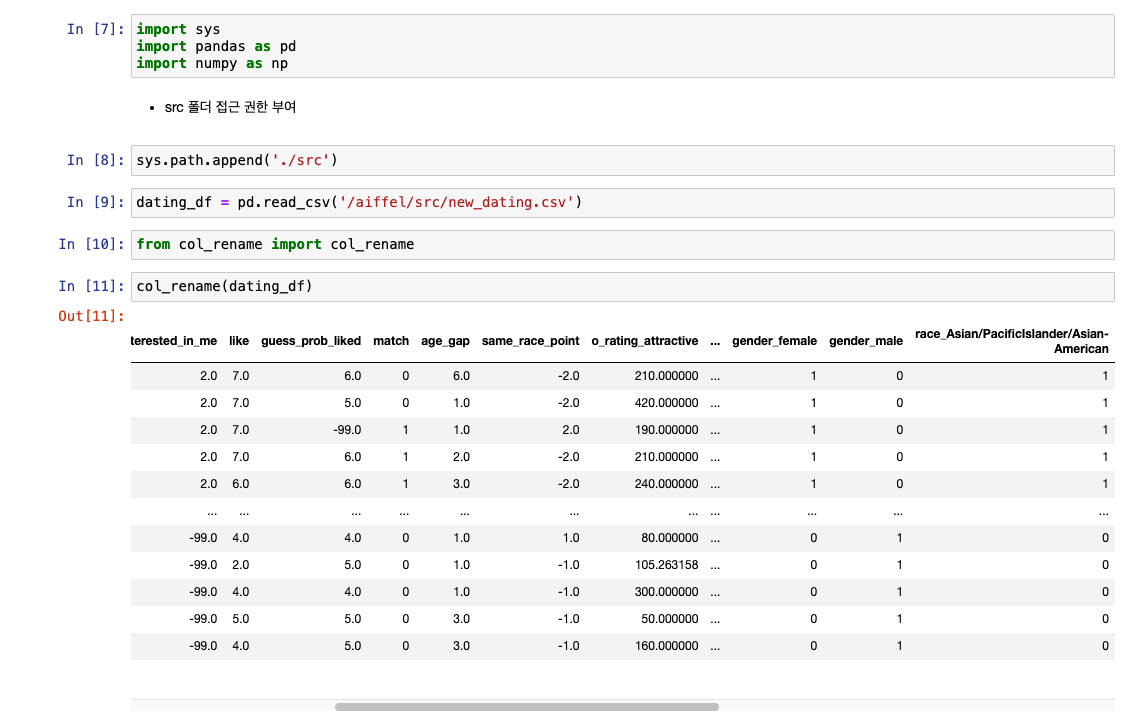
컬럼 이름 변경에 사용한 함수 : col_rename으로 저장

- func.py
- 마지막에 return dating_df 꼭 적어줘야 함!


- 마지막에 return dating_df 꼭 적어줘야 함!
-
./aiffel/src에 저장되었는지 확인

-
test.py
- new_dating.csv: 앞서서 피처 엔지니어링을 마친 데이터!

- 실제 적용한 function이 잘 불러와지는지 확인

- new_dating.csv: 앞서서 피처 엔지니어링을 마친 데이터!
- 컬럼 이름이 잘 반영되지 않았는데? -> 해당 코드가 빠져서 그런 것
- 그런데... 피처 엔지니어링이 끝난 데이터면..이미 위 함수들을 다 거쳐온 데이터 아닌가...? 근데 이게 적용이 되는지 확인할 수 있어..?
- 일단 하자
아무래도 원본 데이터가 맞는거 같음...!
- 거기에서 match만 드랍해서 new_dating2.csv로 저장해서 쓰자.
- 그리고 모든 새로운 함수 등록 시 -> 커널 재시작 + 셀 모두 재실행해서 적용할 것!
결측치 처리

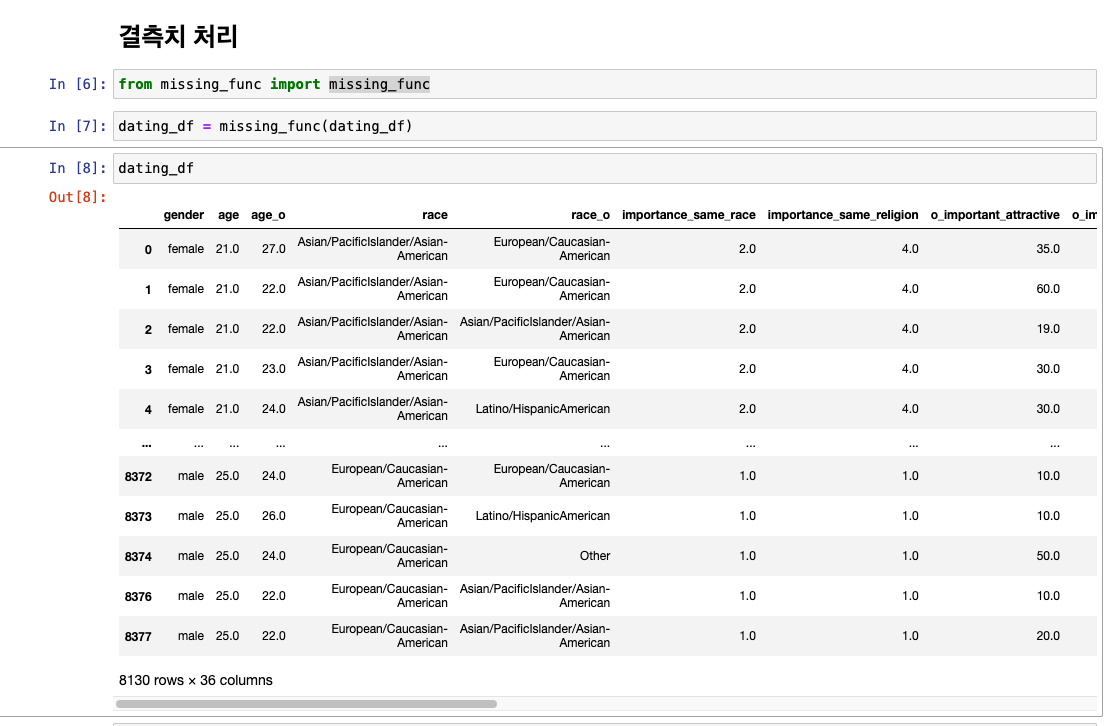
Outlier
- 위에서 피처 엔지니어링을 했을 때는 직접 데이터를 확인해서 했지만 -> function을 만들려면 일반화 필요!
-
10 초과값 -> 10으로 정리 파트

-
합 100 만들기 파트

Age
Race

Rating



마지막 처리

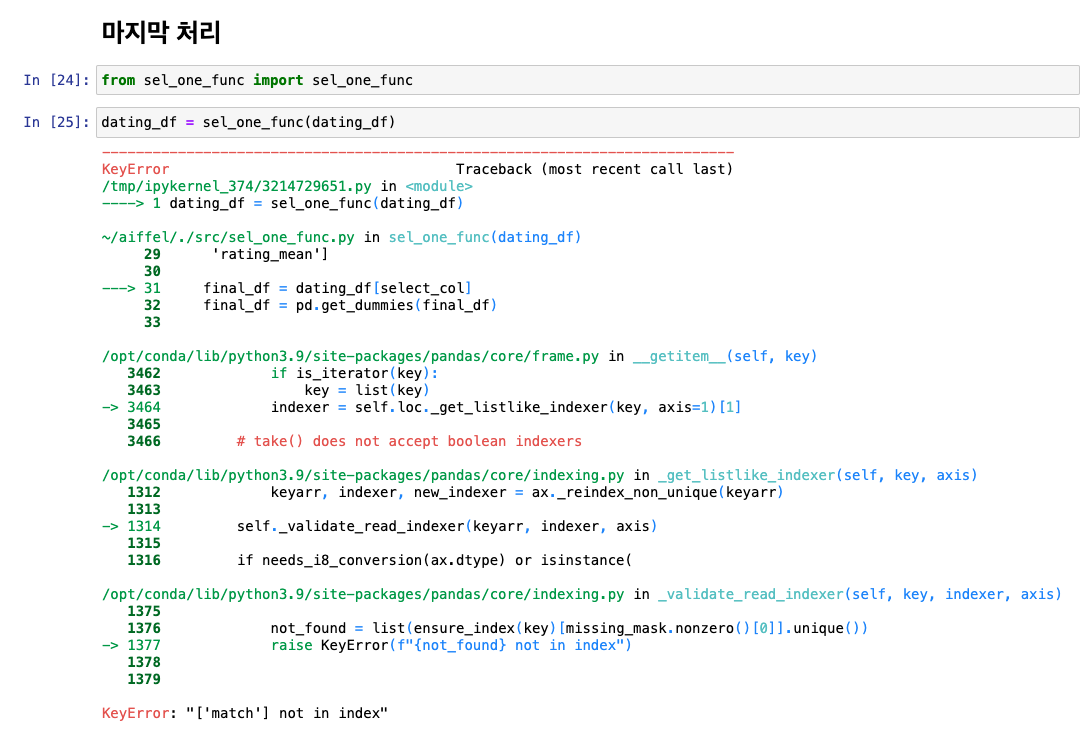
- match는 없앴기 때문에 에러 : match 컬럼 삭제!
- pandas도 없어서 에러날 것 -> 넣어주기!
하나의 파일로 묶어주기