
1-1. 인공지능과 가위바위보 하기
숫자 손글씨 인식기를 만드는 방법
- Sequential Model 이용
- 딥러닝 : 데이터 준비 ➡️ 딥러닝 네트워크 설계 ➡️ 학습 ➡️ 테스트(평가)
- 입력 : 손으로 쓴 숫자 이미지
- 출력 : 숫자
학습 목표
- MNIST Dataset, 텐서플로우 Sequential API를 이용한 숫자 손글씨 인식기 만들기
- Sequential Model: 딥러닝 네트워크 설계 및 학습
- Test data를 이용한 성능 확인, 하이퍼파라미터 조정을 통한 성능 개선
- 가위바위보 분류기를 만들기 위한 기본 데이터 -> 웹캠으로 만들기
학습 내용
- 정제된 10개 클래스의 숫자 손글씨 데이터 분류기 만들기
- 비정제 웹캠 사진을 통해 데이터 생성
- 컬러 사진 학습 분류기 만들기
- 클래스 개수 조절(10개 -> 3개)
1-2. 데이터를 준비하자!
MNIST 숫자 손글씨 Dataset 불러들이기
tf.keras의Sequential API를 이용한 숫자 손글씨 인식기 생성- 🚨 version : Tensorflow 2.6.0
import tensorflow as tf
from tensorflow import keras
import numpy as np
import matplotlib.pyplot as plt
import os
print(tf.__version__)
mnist = keras.datasets.mnist
# MNIST 데이터 로드
(x_train, y_train), (x_test, y_test) = mnist.load_data()
print(len(x_train))
- 내용 참고 : THE MNIST DATABASE of handwritten digits
- 숫자 손글씨 이미지 크기 : 28x28
- MNIST dataset에는 총 70,000장의 손글씨 이미지가 있음
- train_set : 60,000
- test_set : 10,000
- training set에는 약 250명의 손글씨가 들어있음
숫자 손글씨 이미지 하나 출력
- MNIST 데이터셋
x_train,x_test: 이미지 데이터 matrix- 주의 :
x_train[1]은x_train행렬의 2번째 이미지임!
- 주의 :
plt.imshow(x_train[1],cmap=plt.cm.binary)
plt.show()
y_train행렬 2번째 값 확인- 이미지와 대응하는 실제 숫자 값이 있음
print(y_train[1])
- 다른 숫자도 출력해보기
index = 10000 # 0 ~ 59999 사이 숫자
plt.imshow(x_train[index],cmap=plt.cm.binary)
plt.show()
print( (index+1), '번째 이미지의 숫자는 바로 ', y_train[index], '입니다.')
index = 40000 # 0 ~ 59999 사이 숫자
plt.imshow(x_train[index],cmap=plt.cm.binary)
plt.show()
print( (index+1), '번째 이미지의 숫자는 바로 ', y_train[index], '입니다.')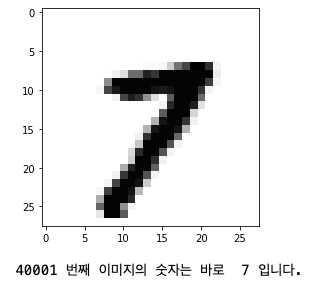
학습용 데이터와 시험용 데이터
- 총 약 500명의 사용자 숫자 이미지
- 250명의 데이터가 학습용 데이터, 다른 250명의 데이터가 시험용 데이터로 분리 사용
학습용 데이터 장수 확인
- 28x28 크기의 숫자 이미지 -> 60,000장 있다는 의미
print(x_train.shape)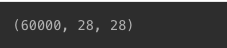
시험용 데이터 장수 확인
print(x_test.shape)
Q&A
- validation set(검증 데이터) 사용
- ML 과정의 정상적 진행 여부
- overfitting 여부 확인
- 학습 중단 가능 여부 판단...
- 교차 검증(cross validation) 기법
- 모델 평가 및 성능 측정의 한 기법으로, 주어진 데이터를 분할해서 모델 훈련 및 검증하는 과정을 반복하는 기법을 말함.
- 일반적으로 데이터 양이 부족한 경우 자주 사용하며, 모델 일반화 성능을 더 정확히 평가할 수 있게끔 해줌.
- K-Fold Cross-Validation을 주로 사용!
데이터 전처리
- 숫자 데이터 실제 픽셀 값 : 0 ~ 255
print('최소값:',np.min(x_train), ' 최대값:',np.max(x_train))
- 입력을 0 ~ 1으로 정규화
- MNIST 데이터: 0 ~ 255 사이의 값을 가지기 때문에, 255.0으로 나눠주면 됨
x_train_norm, x_test_norm = x_train / 255.0, x_test / 255.0
print('최소값:',np.min(x_train_norm), ' 최대값:',np.max(x_train_norm))
1-3. 딥러닝 네트워크 설계하기
Sequential Model
tf.keras의 Sequential API 사용- 개발 자유도는 다소 떨어지나, 간단히 딥러닝 모델을 만들 수 있음
- 딥러닝 layer를 쉽게 추가할 수 있음
LeNet 딥러닝 네트워크 설계 예시
- 손글씨 숫자 분류기 구현에는 충분함
Conv2D(16, (3,3): 16 -> 이미지 특징 개수input_shape=(28,28,1): 입력 이미지 형태- 28x28 크기의 흑백 이미지를 모델에 입력한다는 의미
- 1이 그레이 스케일, RGB의 경우 3으로 설정
keras.layers.Dense(32,...: 분류기 알고리즘의 복잡도 설정(숫자가 커질수록 복잡도 올라감)- 첫번째 인자 : 분류기에 사용되는 뉴런 숫자
- ex) 알파벳 구분 시 -> 대문자 26개, 소문자 26개이니 총 52개 클래스 분류가 필요 -> 64, 128 등을 고려할 수 있음
keras.layers.Dense(10,...: 최종 분류기 class 개수(0~9까지 총 10개의 클래스이기 때문에 10으로 설정)
model=keras.models.Sequential()
model.add(keras.layers.Conv2D(16, (3,3), activation='relu', input_shape=(28,28,1)))
model.add(keras.layers.MaxPool2D(2,2))
model.add(keras.layers.Conv2D(32, (3,3), activation='relu'))
model.add(keras.layers.MaxPooling2D((2,2)))
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(32, activation='relu'))
model.add(keras.layers.Dense(10, activation='softmax'))
print('Model에 추가된 Layer 개수: ', len(model.layers))
model.summary()로 만든 딥러닝 네트워크 모델 확인
model.summary()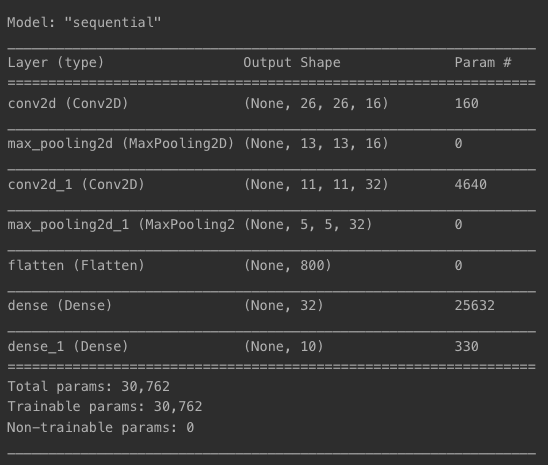
1-4. 딥러닝 네트워크 학습시키기
채널 수 정보 추가
- 네트워크 입력 형태 :
(데이터 개수, 이미지 크기 x, 이미지 크기 y, 채널 수)- x_train의 경우, 채널 수 정보가 없으니 추가해주기
- x_train_reshaped에서 데이터 개수 부분에 -1을 작성하면 -> reshap시에 자동으로 계산됨
print(f"Before Reshape - x_train_norm shape: {x_train_norm.shape}")
print(f"Before Reshape - x_test_norm shape: {x_test_norm.shape}")
x_train_reshaped=x_train_norm.reshape( -1, 28, 28, 1)
x_test_reshaped=x_test_norm.reshape( -1, 28, 28, 1)
print(f"After Reshape - x_train_reshaped shape: {x_train_reshaped.shape}")
print(f"After Reshape - x_test_reshaped shape: {x_test_reshaped.shape}")
x_train 데이터로 딥러닝 네트워크 학습
- 최적화(optimizer), 손실 함수(loss function), 평가 지표(metrics) 정의
epochs=10: 전체 데이터(60,000)를 10번 반복 사용해 학습한다는 의미
- epoch별로 accuracy가 올라가는 추이를 확인할 수 있음
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(x_train_reshaped, y_train, epochs=10)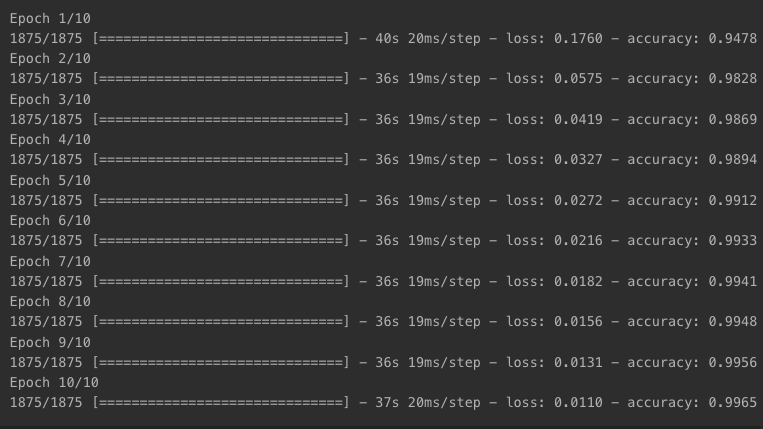
1-5. 얼마나 잘 만들었는지 확인하기
테스트 데이터로 성능 확인
- x_test에 적용
- 앞서 확인한 수치와 다른 이유 : 시험용 데이터와 학습용 데이터의 손글씨 주인이 다르기 때문에 자연스러운 현상(test_loss, test_accuracy도 바뀜)
test_loss, test_accuracy = model.evaluate(x_test_reshaped,y_test, verbose=2)
print(f"test_loss: {test_loss}")
print(f"test_accuracy: {test_accuracy}")
잘못 예측한 데이터 확인해보기
model.predict()- 모델이 입력값을 보고 실제 추론한 확률분포 출력 가능
- 확률값이 높은 숫자가 모델이 추론한 숫자!
- 첫번째 x_test로 보기
predicted_result = model.predict(x_test_reshaped)
predicted_labels = np.argmax(predicted_result, axis=1)
idx=0
print('model.predict() 결과 : ', predicted_result[idx])
print('model이 추론한 가장 가능성이 높은 결과 : ', predicted_labels[idx])
print('실제 데이터의 라벨 : ', y_test[idx])
- 결과 해석 방법
- 순서대로 0, 1, 2, 3, ..., 7, 8, 9일 확률로 해석
- 벡터값이 가장 1.00에 근접한 숫자를 기준으로 확인해보기 : "7"
plt.imshow(x_test[idx],cmap=plt.cm.binary)
plt.show()
모델이 추론한 숫자 vs 실제 라벨 값
- i번째 test_labels와 y_test가 다른 경우를 모아서 확인
- wrong_predict_list에서 5개를 랜덤하게 뽑아서 확인
import random
wrong_predict_list=[]
for i, _ in enumerate(predicted_labels):
if predicted_labels[i] != y_test[i]:
wrong_predict_list.append(i)
samples = random.choices(population=wrong_predict_list, k=5)
for n in samples:
print("예측확률분포: " + str(predicted_result[n]))
print("라벨: " + str(y_test[n]) + ", 예측결과: " + str(predicted_labels[n]))
plt.imshow(x_test[n], cmap=plt.cm.binary)
plt.show()
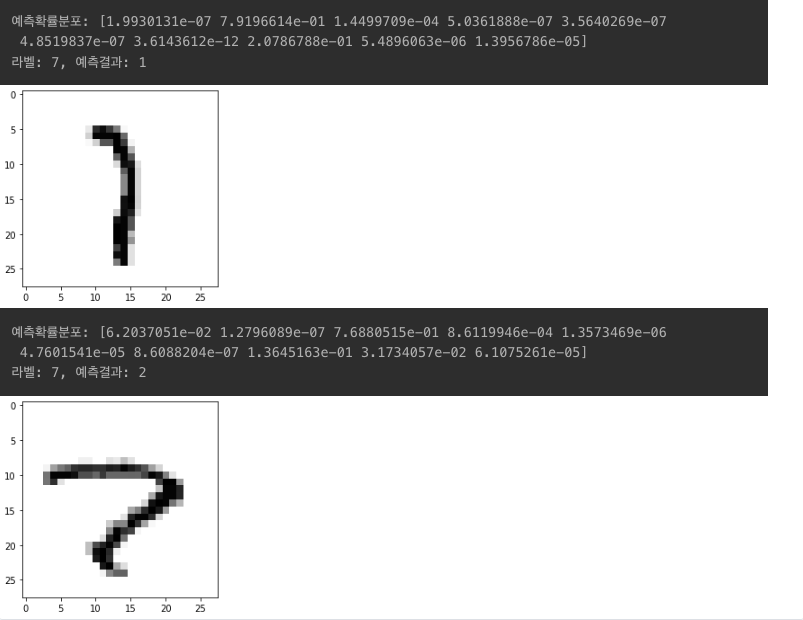
라벨과 예측 결과가 상당히 다르게 나옴을 확인할 수 있음
1-6. 더 좋은 네트워크 만들어 보기
하이퍼파라미터 변경
Conv2D: 입력 이미지 특징 수 변경Dense: 뉴런 개수 변경epoch: 학습 횟수 변경
...
- 시도 1
- n_channel_1=16
- n_channel_2=32
- n_dense=32
- n_train_epoch=10
# 변경 시도가 가능한 파라미터
n_channel_1=16
n_channel_2=32
n_dense=32
n_train_epoch=10
model=keras.models.Sequential()
model.add(keras.layers.Conv2D(n_channel_1, (3,3), activation='relu', input_shape=(28,28,1)))
model.add(keras.layers.MaxPool2D(2,2))
model.add(keras.layers.Conv2D(n_channel_2, (3,3), activation='relu'))
model.add(keras.layers.MaxPooling2D((2,2)))
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(n_dense, activation='relu'))
model.add(keras.layers.Dense(10, activation='softmax'))
model.summary()
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 모델 훈련
model.fit(x_train_reshaped, y_train, epochs=n_train_epoch)
# 모델 시험
test_loss, test_accuracy = model.evaluate(x_test_reshaped, y_test, verbose=2)
print(f"test_loss: {test_loss} ")
print(f"test_accuracy: {test_accuracy}")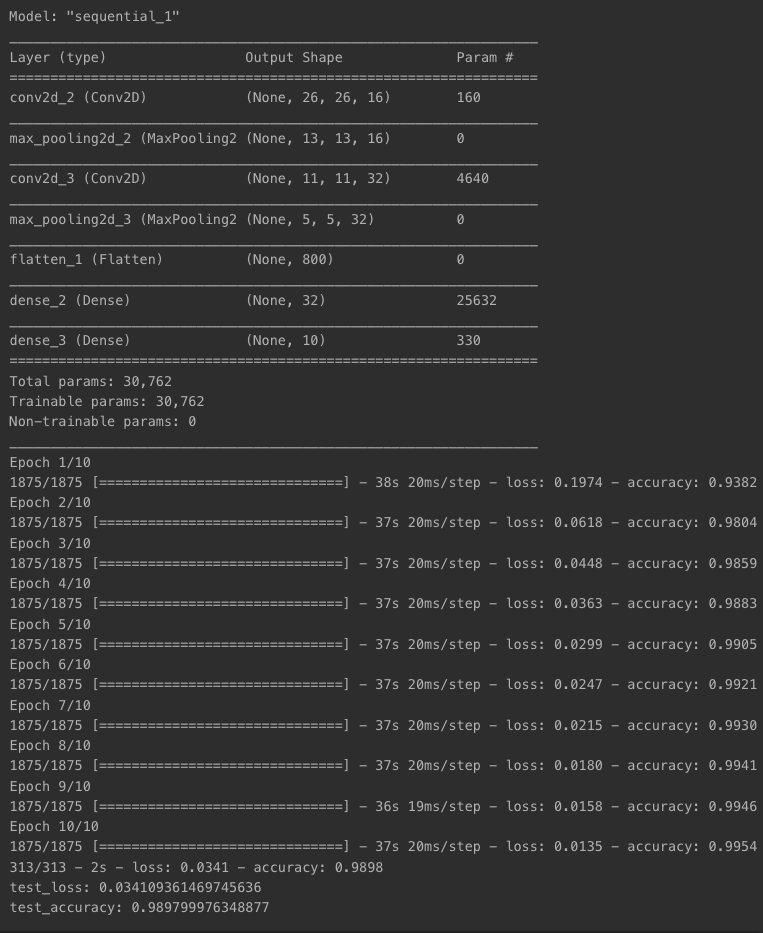
- 시도 2
- n_channel_1 = 32
- n_channel_2 = 64
- n_dense = 128
- n_train_epoch = 15
n_channel_1 = 32
n_channel_2 = 64
n_dense = 128
n_train_epoch = 15
model = keras.models.Sequential()
model.add(keras.layers.Conv2D(n_channel_1, (3,3), activation='relu', input_shape=(28,28,1)))
model.add(keras.layers.MaxPool2D(2,2))
model.add(keras.layers.Conv2D(n_channel_2, (3,3), activation='relu'))
model.add(keras.layers.MaxPooling2D((2,2)))
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(n_dense, activation='relu'))
model.add(keras.layers.Dense(10, activation='softmax'))
model.summary()
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 모델 훈련
model.fit(x_train_reshaped, y_train, epochs=n_train_epoch)
# 모델 시험
test_loss, test_accuracy = model.evaluate(x_test_reshaped, y_test, verbose=2)
print(f"test_loss: {test_loss}")
print(f"test_accuracy: {test_accuracy}")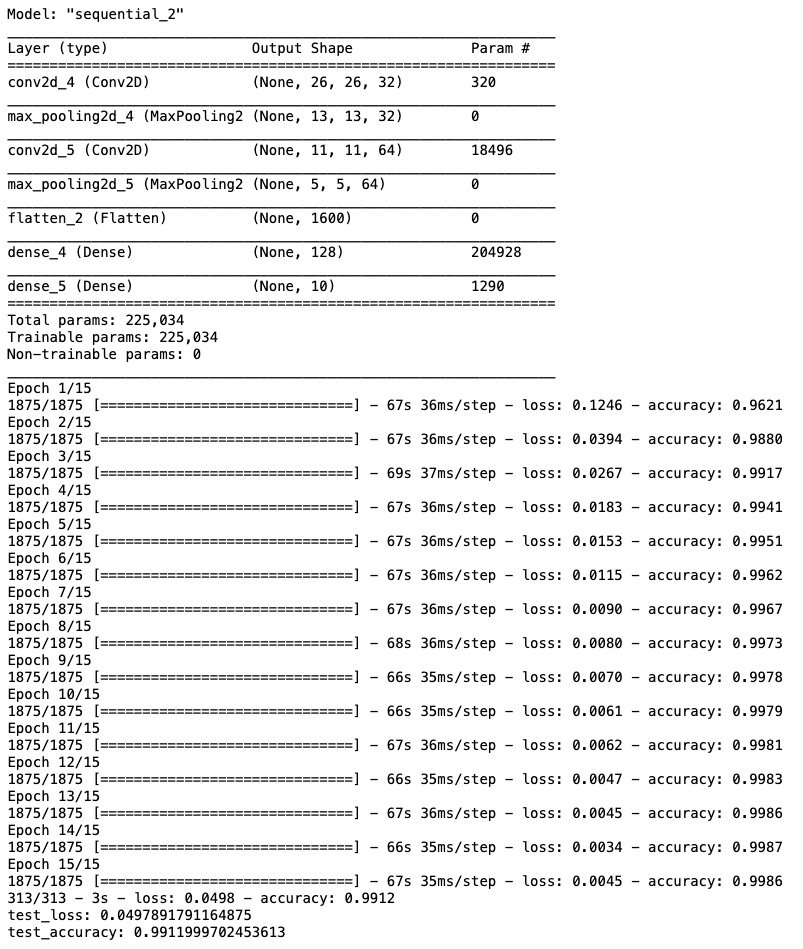

언젠가 내 코드로 세상에 기여할 수 있도록, Data Science&BE 개발 기록 노트☘️