
참고 자료 : 토큰화(Tokenization)
6-1. 들어가며
학습 목표
- 한국어 문장의 형태소 단위 분리
- 자연어 전처리
- 긍정, 부정 감성 분석
6-2. 자연어 처리 기초
-
어휘 사전 구축
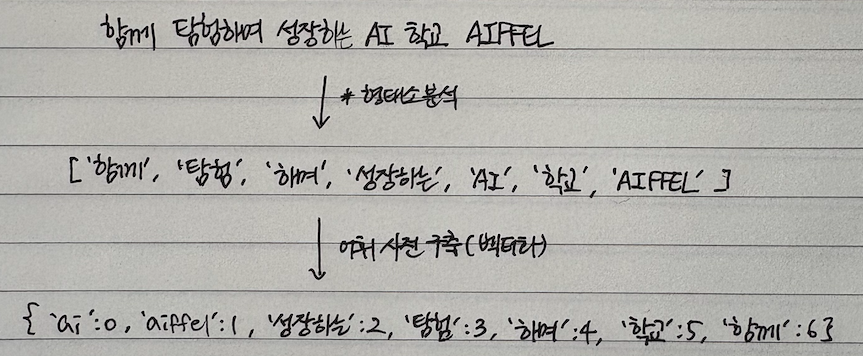
-
어휘 사전과 새로 들어온 문장 매칭

CountVectorizer
- 각 문장 속 단어 출현 횟수 카운팅
- BOW(Bag Of Word)
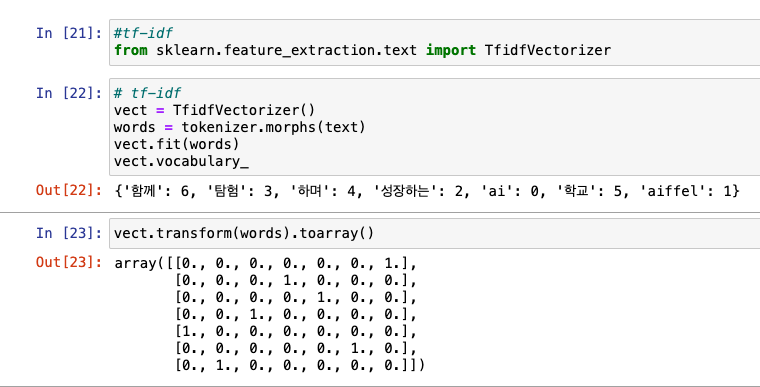
TfidfVectorizer
- 특정 문서에 출현 빈도수가 높은 단어에 높은 가중치 부여
- TF-IDF(Term Frequency - Inverse Document Frequency)
형태소 분석기
- konlpy : 한국어 처리 형태소 분석기
- 형태소 : 가장 작은 말의 단위(의미를 가지는 요소로 더이상 분석할 수 없는 정도까지)
실습
형태소 분석기
-
판다스 라이브러리 + konply 설치

-
토큰화

CountVectorizer
-
토큰화 + 학습 + 학습된 어휘 확인
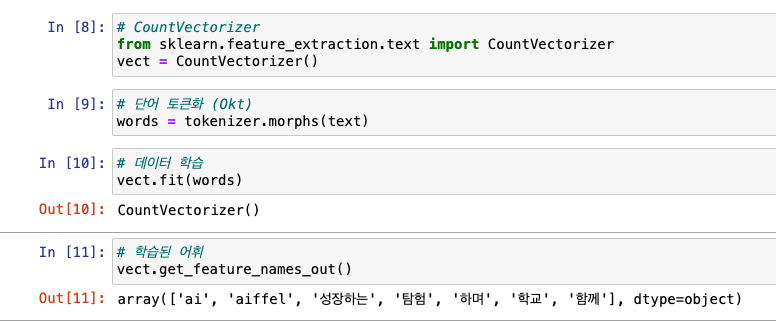
-
단어 사전 확인

-
인코딩
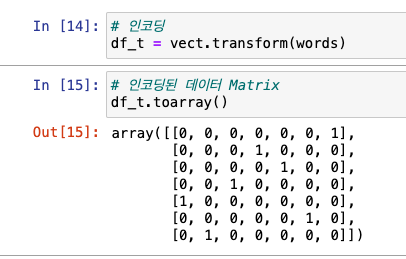
-
어휘와 피처를 매칭해서 확인하기

-
테스트(새로운 단어가 들어오면 어떻게 매칭하는지 확인!)
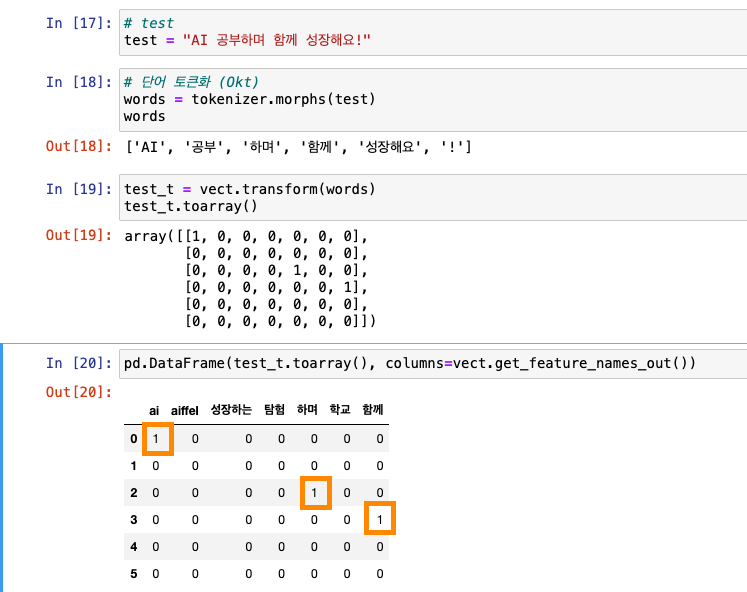
TfidfVectorizer
- 과정 동일
6-3. 감성 분석
ML 프로세스에서 자연어 전처리
- 문제 정의 ➡️ EDA ➡️ 데이터 전처리(토큰화, 어휘 사전 구축, 인코딩) ➡️ 모델 학습 ➡️ 예측(긍정/부정)
실습
- 데이터 불러오기
- 네이버 영화 리뷰 데이터를 취합해 감성 분석을 해놓은 데이터셋

- 네이버 영화 리뷰 데이터를 취합해 감성 분석을 해놓은 데이터셋
-
EDA, 데이터 전처리
-
데이터 정보 파악

-
target 확인

-
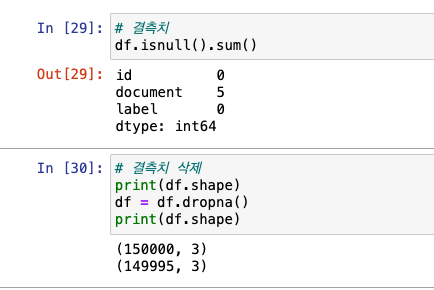
결측치 처리
-
피쳐 엔지니어링
- label이 0일 경우와 1일 경우 비슷
- 0 ~ 44까지가 많음
-
데이터 샘플링

-
토큰화

-
-
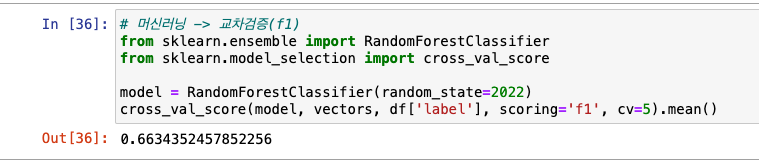
머신러닝(랜덤 포레스트 모델 사용) & F1으로 교차검증
- 교차 검증 : train set을 -> train set과 validation set(검증셋)으로 나눠서 학습 중 검증, 수정 수행
- F1 : 분류 모델 평가 지표, 정밀도(precisiton) + 재현율(recall) 조화평균
6-3. 자연어 전처리
어휘 사전 구축
00%이상 나타내는 단어 -> 무시- ex) 50%, 70%..
- 최소 N개 문장에만 나타나는 단어만 -> 유지
실습

불용어(stopword)
- 큰 의미 없는 단어(은, 는, 이, 가, 여기, 저기..)
실습

띄어쓰기
- 참고 자료 : PyKoSpacing
실습
- Spacing 설치 : https://github.com/haven-jeon/PyKoSpacing.git

- 띄어쓰기

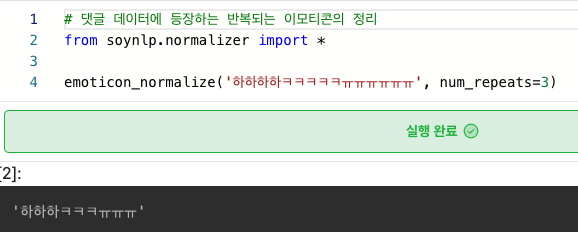
반복 글자 -> 정리
- 참고 자료 : soynlp
실습
맞춤법 검사
- 참고 자료 :py-hanspell
실습
- 기존 단어(익숙한 단어, 많이 사용한 단어)가 아닌 경우, 잘 못잡아내는 단점이 있음!



언젠가 내 코드로 세상에 기여할 수 있도록, Data Science&BE 개발 기록 노트☘️