Node 16. 텍스트의 분포로 벡터화 하기
☺️ AIFFEL 데이터사이언티스트 3기

16-1. 들어가며
학습 목표
- 단어 빈도 이용: DTM, TF-IDF 구현
- LSA, LDA
- 형태소 분석기
학습 내용
-
단어 빈도 벡터화
- Bag of Words
- DTM, 코사인 유사도
- DTM 구현 & 한계점
- TF-IDF
-
LSA, LDA
- LSA 학습 & 실습
- LDA 학습 & 실습
-
텍스트 분포 이용 비지도 학습 토크나이저
- 형태소 분석기 & 단어 미등록 문제
- soynlp(품사 태깅, 형태소 분석 등 지원)
사전 준비
$ mkdir -p ~/aiffel/topic_modelling/data16-2 ~ 7. 단어 빈도를 이용한 벡터화
벡터화 방법
- 통계와 머신러닝 활용
- 인공신경망 활용
(1) Bag of Words(BoW)
- 자연어 처리(Natural Language Processing), 정보 검색(Information Retrieval)에 쓰이는 간단한 단어 표현법
- 문서 내 단어 분포 확인 & 문서 특성 파악
문서 내 단어들의 빈도(frequency) 파악
- 문서의 텍스트를 단어 단위로 토큰화
- 단어들을 가방에 넣고 ➡️ 흔들기 ➡️ 순서 무시되며 섞임
- BoW는 중복 제거 없이 단어 카운트
- 결론: 단어 순서 무시, 단어 빈도 정보 보존
예시: doc1, doc2
- doc1
doc1 = 'John likes to watch movies. Mary likes movies too.'- BoW 표현
BoW1 = {"John":1, "likes":2, "to":1, "watch":1, "movies":2, "Mary":1, "too":1}- doc2
doc2 = 'Mary also likes to watch football games.'- BoW 표현
BoW2 = {"Mary":1, "also":1, "likes":1, "to":1, "watch":1, "football":1, "games":1}key: 단어, value: 단어의 등장 횟수(순서 중요하지 않음)
- BoW, BoW1 본질은 동일
BoW = {"too":1, "Mary":1, "movies":2, "John":1, "watch":1, "likes":2, "to":1} BoW1 = {"John":1, "likes":2, "to":1, "watch":1, "movies":2, "Mary":1, "too":1}
BoW 한계점
- BoW 방식의 문장 벡터화
I ate lunch.,Lunch ate I.는 같은 문장- 어순 반영이 안됨
- doc3 : doc1, doc2
doc3 = 'John likes to watch movies. Mary likes movies too. Mary also likes to watch football games.'- BoW3
BoW3 = {"John":1, "likes":3, "to":2, "watch":2, "movies":2, "Mary":2, "too":1, "also":1, "football":1, "games":1};(2) Bag of Words 구현
keras Tokenizer
from tensorflow.keras.preprocessing.text import Tokenizer
sentence = ["John likes to watch movies. Mary likes movies too! Mary also likes to watch football games."]
tokenizer = Tokenizer()
tokenizer.fit_on_texts(sentence)
bow = dict(tokenizer.word_counts)
print("Bag of Words :", bow)
print('단어장(Vocabulary)의 크기 :', len(tokenizer.word_counts)) # 중복 제거(단어 개수)Bag of Words : {'john': 1, 'likes': 3, 'to': 2, 'watch': 2, 'movies': 2, 'mary': 2, 'too': 1, 'also': 1, 'football': 1, 'games': 1}
단어장(Vocabulary)의 크기 : 10단어장(Vocabulary): 중복 제거한 단어 집합(≠ BoW)
scikit-learn CountVectorizer
from sklearn.feature_extraction.text import CountVectorizer
sentence = ["John likes to watch movies. Mary likes movies too! Mary also likes to watch football games."]
vector = CountVectorizer()
bow = vector.fit_transform(sentence).toarray()
print('Bag of Words : ', bow) # 코퍼스 -> 각 단어 빈도수 기록
print('각 단어의 인덱스 :', vector.vocabulary_) # 단어 인덱스 보여줌Bag of Words : [[1 1 1 1 3 2 2 2 1 2]]
각 단어의 인덱스 : {'john': 3, 'likes': 4, 'to': 7, 'watch': 9, 'movies': 6, 'mary': 5, 'too': 8, 'also': 0, 'football': 1, 'games': 2}vector.fit_transform([문장]).toarray()- 단어 빈도만 출력(어떤 단어인지 정보는 없음)
vector.vocabulary_- 인덱스 확인
also: 인덱스 0, BoW 리스트의 0번 인덱스 값은 1 ➡️ 빈도는 1likes: 인덱스 4, BoW 리스트의 4번 인덱스 값은 3 ➡️ 빈도는 3
BoW 단어장 크기
print('단어장(Vocabulary)의 크기 :', len(vector.vocabulary_))
(3) DTM과 코사인 유사도
DTM(Document-Term Matrix)
- 문서-단어 행렬
- 여러 문서의 BoW ➡️ 행렬 1개로 구현
- 단어 빈도수를 1개 행렬로 통합
- 행 : 문서, 열 : 단어
- 반대로 된다면, TDM(Term-Document Matrix)으로 부름
DTM 확인
- Doc 1: Intelligent applications creates intelligent business processes
- Doc 2: Bots are intelligent applications
- Doc 3: I do business intelligence
- DTM

- 행 : 각 문서
- 열 : 문서 3개 통합 단어장 단어
- 즉, 행에 0이 많이 포함됨
행: 문서 벡터(document vector), 열: 단어 벡터(word vector)
- 문서 수 커짐 ➡️ 통합 단어장도 커짐 ➡️ 문서 벡터 및 단어 벡터 대부분이 0이 되는 성질이 있음
예시: 문서 비교 & 문서 간 유사도
- 문서1 : I like dog
- 문서2 : I like cat
- 문서3 : I like cat I like cat
- DTM(cat:0, I:2, like:3)
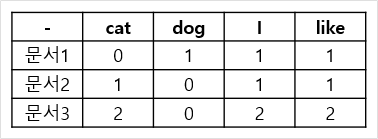
- 문서 벡터 유사도 구하기 ➡️ 코사인 유사도 사용
cos_sim: 코사인 유사도 함수
import numpy as np
from numpy import dot
from numpy.linalg import norm
doc1 = np.array([0,1,1,1]) # 문서1 vector
doc2 = np.array([1,0,1,1]) # 문서2 vector
doc3 = np.array([2,0,2,2]) # 문서3 vector
def cos_sim(A, B):
return dot(A, B)/(norm(A)*norm(B))코사인 유사도
- 두 벡터 간 코사인 각도를 통해 유사도를 구하는 것
- 0°(방향 동일) : 1
- 90° : 0
- 180°(반대 방향) : -1
- 코사인 유사도는 -1 이상 1 이하 값(1에 가까울수록 유사도 높음)
- 한 문서 내 단어 빈도수가 동일하게 증가 ➡️ 기본 문서와의 코사인 유사도는 1
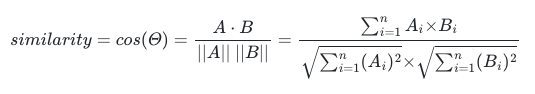
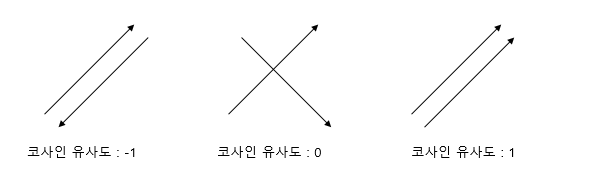
- 코사인 유사도 계산
- DTM에서의 코사인 유사도 : 0 이상 1 이하
- 1에 가까울수록 유사도 높음
print('{:.2f}'.format(cos_sim(doc1, doc2))) #문서1 & 문서2 Cosine Similarity
print('{:.2f}'.format(cos_sim(doc1, doc3))) #문서1 & 문서3 Cosine Similarity
print('{:.2f}'.format(cos_sim(doc2, doc3))) #문서2 & 문서3 Cosine Similarity
(4) DTM의 구현과 한계점
scikit-learn CountVectorizer
- BoW와 유사 ➡️ 다수 문서를 입력값으로 바꾸면 됨
- 3개 문서에 대한 DTM
from sklearn.feature_extraction.text import CountVectorizer
corpus = [
'John likes to watch movies',
'Mary likes movies too',
'Mary also likes to watch football games',
]
vector = CountVectorizer()
print(vector.fit_transform(corpus).toarray()) # 코퍼스로부터의 각 단어의 빈도수
print(vector.vocabulary_) # 각 단어 인덱스 확인[[0 0 0 1 1 0 1 1 0 1]
[0 0 0 0 1 1 1 0 1 0]
[1 1 1 0 1 1 0 1 0 1]]
{'john': 3, 'likes': 4, 'to': 7, 'watch': 9, 'movies': 6, 'mary': 5, 'too': 8, 'also': 0, 'football': 1, 'games': 2}DTM 한계점
-
DTM의 특징 : 문서 수 및 단어 수 증가에 따른 행과 열이 대부분 0의 값을 가진다는 것
- 저장 공간 낭비 문제
- 지나친 차원 크기가 차원의 저주 문제 발생시킴
-
단어 빈도에만 집중
- 불용어(the)의 경우 문서에 항상 자주 등장 ➡️ 불용어의 빈도수가 높다해서 문서 유사도가 높다고 할 수 없을 것
- 중요한 단어, 그렇지 않은 단어의 가중치가 필요함
TF-IDF
- Term Frequency-Inverse Document Frequency
- 단어 빈도 - 역문서 빈도
- 각 단어 중요도 판단을 통해 가중치 부여
- 모든 문서에 자주 등장하는 단어: 중요도 낮게 판단
- 특정 문서에만 자주 등장하는 단어: 중요도 높게 판단
- 중요도가 낮으면서 + 모든 문서에 등장하는 단어들(ex.불용어)의 노이즈 완화
- 그렇다고 해서 DTM보다 성능이 무조건적으로 좋다고는 할 수 없음
- DTM을 만들고 ➡️ TF-IDF 가중치를 DTM에 적용하는 방식으로 사용
- DTM이 TF이기 때문에, DTM 각 단어에 IDF를 곱하면 TF-IDF 행렬이 됨
TF-IDF 계산
- 수식
- x: 단어, y: 문서
- log항 : IDF

Q. 전체 문서 수 5개일때,
like의 IDF는?
- 단어
like
- 문서 2에서 200번, 문서 3에서 300번
- 다른 문서에는 등장하지 않음
- DF
- 문서 빈도
- DF는 2(∵ 몇 개의 문서에 등장했는지만 보기 때문)
- N
- 전체 문서 수
- 전체 문서 수
- 즉, IDF = (자연로그) = = 0.91629073187
- 문서2
likeTF-IDF : = 183.258146375 - 문서3
likeTF-IDF : = 274.887219562
결과 : 문서3 TF-IDF > 문서2 TF-IDF- 특정 문서에서 자주 등장하는 단어 중요도 ➡️ 높게 판단하니 자연스러운 결과
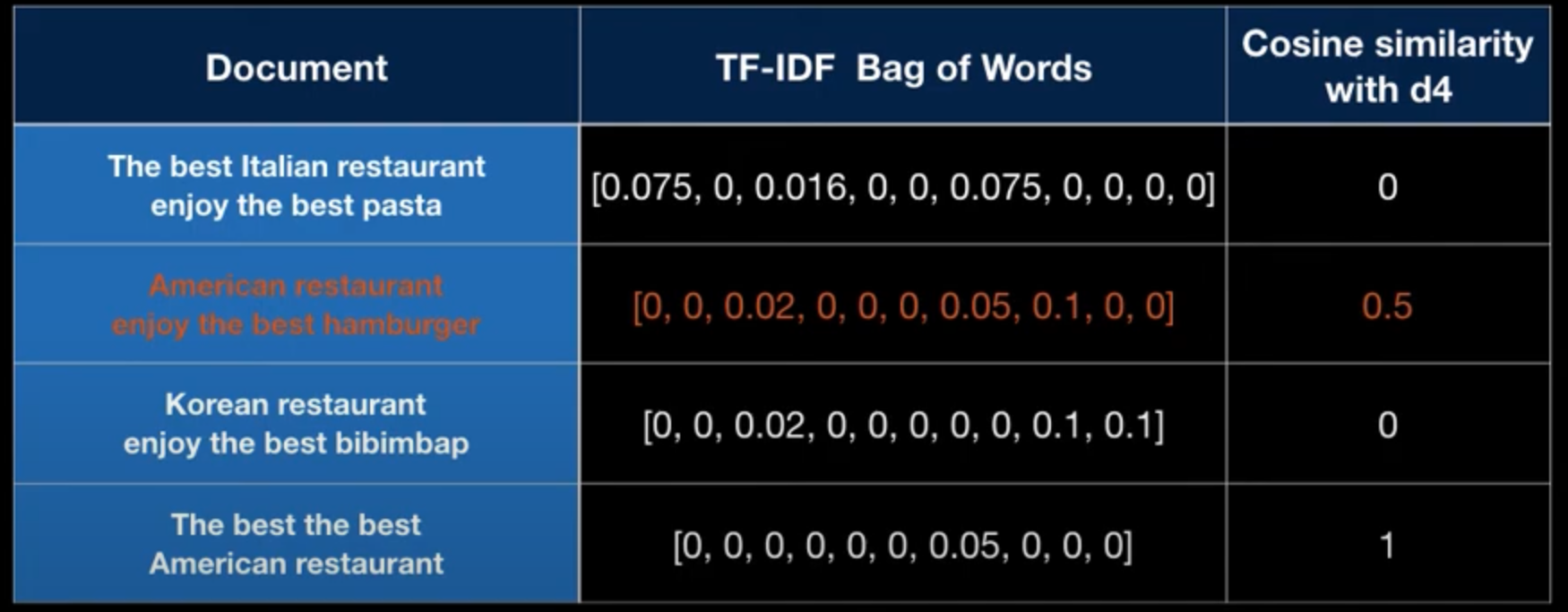
📍 참고 자료 : TF-IDF 문서 유사도 측정
- TF-IDF with Bag of words Cosine similarity
- 장점
- Easy to get document similarity
- Keep relevant words score
- lower just frequent words score
- 단점
- Only based on Terms(words)
- Weak on capturing document topic
- Weak handing synonym(different words but same meaning)
- ex
- "U.S. President speech in public"
- "Donald Trump presentation to people"
- 거의 유사한 문장이나, TF-IDF with Bag of words Cosine similarity 측정 시 0이 나옴(같은 단어가 없기 때문)
- 개선 방안
- LSA(Latent Semantic Analysis
- Word Embeddings(Word2Vec, Glove)
- ConceptNet
(6) TF-IDF 구현하기
직접 계산
라이브러리 import
from math import log
import pandas as pd문서 3개 사용
docs = [
'John likes to watch movies and Mary likes movies too',
'James likes to watch TV',
'Mary also likes to watch football games',
]문서 3개의 단어가 모두 들어간 통합 단어장 생성
- DTM 열 생성을 위함
vocab = list(set(w for doc in docs for w in doc.split()))
vocab.sort()
print('단어장의 크기 :', len(vocab))
print(vocab)단어장의 크기 : 13
['James', 'John', 'Mary', 'TV', 'also', 'and', 'football', 'games', 'likes', 'movies', 'to', 'too', 'watch']중복 제거한 단어 개수가 13개라는 의미
총 문서수 저장 : N
N = len(docs)
N
TF, IDF, TF-IDF 함수
참고
- 파이썬 패키지에서는 식이 조금 다름
- log 항 분모에 1을 더함(분모가 0이 되는 상황 방지)
- log 항에 1 더하기(분자와 분모 값이 동일 -> log 진수가 1이 되면 IDF 값이 0이 됨)
def tf(t, d):
return d.count(t)
def idf(t):
df = 0
for doc in docs:
df += t in doc
return log(N/(df + 1)) + 1
def tfidf(t, d):
return tf(t,d)* idf(t)TF 함수를 이용한 DTM
result = []
for i in range(N):
result.append([])
d = docs[i]
for j in range(len(vocab)):
t = vocab[j]
result[-1].append(tf(t, d))
tf_ = pd.DataFrame(result, columns = vocab)
tf_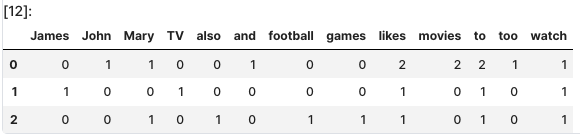
각 단어 IDF
result = []
for j in range(len(vocab)):
t = vocab[j]
result.append(idf(t))
idf_ = pd.DataFrame(result, index = vocab, columns=["IDF"])
idf_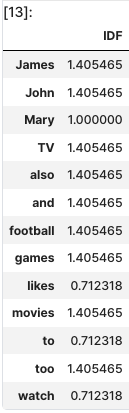
분석
like,to,watch
- 모든 문서에 등장 ➡️ 가장 낮은 값
Mary
- 2개 문서에서 등장 ➡️ 그 다음으로 낮은 값
- 그 외
- 1개 문서에서만 등장 ➡️ 가장 높은 값
TF-IDF 행렬
- DTM의 각 단어 TF x 각 단어 IDF
result = []
for i in range(N):
result.append([])
d = docs[i]
for j in range(len(vocab)):
t = vocab[j]
result[-1].append(tfidf(t,d))
tfidf_ = pd.DataFrame(result, columns = vocab)
tfidf_
scikit-learn TFidVectorizer 사용
TfidfVectorizer
- 사이킷런에서 제공하는 TF-IDF 자동 계산 및 출력
- 기본식에서 조금 조정되었음
- 파이썬 구현식을 포함해, log 항 분자에도 1 더함 + TF-IDF 결과에 L2 Norm까지 추가 수행
- 기본식에서 조금 조정되었음
from sklearn.feature_extraction.text import TfidfVectorizer
corpus = [
'John likes to watch movies and Mary likes movies too',
'James likes to watch TV',
'Mary also likes to watch football games',
]
tfidfv = TfidfVectorizer().fit(corpus)
vocab = list(tfidfv.vocabulary_.keys())
vocab.sort()
# TF-IDF 행렬
# - 단어장을 데이터프레임의 열로 지정(데이터프레임 생성)
tfidf_ = pd.DataFrame(tfidfv.transform(corpus).toarray(), columns = vocab)
tfidf_
16-8 ~ 10. LSA와 LDA
- 토픽 모델링 알고리즘
- 문서 집합에서 토픽을 찾아내는 프로세스
(1) LSA
기존 방식의 한계점
- DTM, TF-IDF 행렬
- Bag of Words 기반
- 단어 의미를 벡터로 표현하지 못함
LSA(Latent Semantic Analysis)
- 잠재 의미 분석
- 전체 코퍼스에서 문서에 있는 단어 사이 관계를 찾는 자연어 처리 정보 검색 기술
- 단어와 단어 사이, 문서와 문서 사이 의미적 유사성 점수 찾기 가능
- 빈도수보다 대부분 효과적
기본 지식 정리
📍 고유값 (Eigenvalue)과 고유벡터 (Eigenvector)
- 고유값
(: A 고유값)
- 선형방정식 세트 연관 특별한 스칼라 값
- 행렬 방정식에서 사용
- == 특징값, 특징 뿌리, 잠재 뿌리
- 고유벡터 변환에 사용되는 스칼라
- 고유값은 확장 요인으로 간주
- 고유값 음수 ➡️ 변환 방향 음수
- 고유벡터
- 특징적 뿌리(characteristic roots)
- 선형 변환 적용 후 최대 스칼라 요인으로 변경될 수 있는 0이 아닌 벡터
- 방향이 변하지 않음 ➡️ 스칼라 배수만큼 변환
- A : 벡터 공간 V의 선형 변환, x : V의 0이 아닌 벡터
- A(X)가 x의 스칼라 배수라면 x는 A의 고유벡터라고 할 수 있음
- 벡터 x 고유 공간 : 동일한 고유값 가지는 모든 고유벡터 및 영벡터 집합(영벡터 ≠ 고유벡터)
- 0이 아닌 벡터 x가
Ax = λx (x: 고유값 λ에 대응하는 A의 고유 벡터)식 만족 시 ➡️ 고유 벡터- 특징
- 하나의 고유값에 대응하는 고유 벡터는 무한히 많을 수 있음
- 서로 다른 고유값에 대응하는 고유 벡터는 선형적 독립
- 고유값은 행렬 방정식의 특수 집합
A: 정방행렬(nxn)[A- λI]: 고유행렬(정의되지 않은 스칼라 λ 포함)
- 고유 행렬의 행렬식
- 0 : 고유 방정식
- I : 단위 행렬(identity matrix)
- 고유 행렬 근(Eigen matrix roots) = 고유근(Eigen roots)
- 삼각 행렬, 대각 행렬 고유값 = 주대각선 요소와 동일
- 스칼라 행렬 고유값 = 그 스칼라 자체
- 고유값 특성 정리
- 고유값이 다른 고유벡터 ➡️ 선형 독립적
- 특이 행렬: 0 고유값으로 가짐
- A가 정방행렬일 때 : λ = 0은 A의 고유값이 아님
- 행렬의 스칼라 배수 : A가 정방행렬이고 λ가 A의 고유값 ➡️ aλ : aA 고유값
- 행렬의 거듭제곱 : A가 정방행렬이고 λ가 A의 고유값이며, n≥0인 정수 ➡️ 는 의 고유값
- 행렬의 다항식 : A가 정방행렬이고 λ가 A의 고유값이며, p(x)가 변수 x에 대한 다항식 ➡️ p(λ)는 행렬 p(A)의 고유값
- 역행렬 : A가 정방행렬이고 λ가 A의 고유값 ➡️ 는 의 고유값
- 전치행렬 : A가 정방행렬이고 λ가 A의 고유값 ➡️ λ는 A^T의 고유값

Q&A
-
Q. 단위 행렬이란?
- A. 주 대각선 원소가 모두 1, 나머지 원소는 0인 정방행렬
-
Q. n차 정사각행렬 행렬 A에 대해 어떤 행렬을 곱했을 때, 결과 행렬이 단위 행렬 ➡️ A의 무슨 행렬이라고 해야하는지?
- A. 역행렬(Inverse Matrix)
특잇값 분해(Singular Value Decompotion, SVD)
m x n사이즈의 임의 사각 행렬 A를 Full SVD로 나타내는 것- 즉,
특이 벡터(singular vector) 행렬,특잇값(singular value) 대각행렬로 분해
- 즉,
📍 참고 자료 : DS 스쿨: 특잇값 분해
- 행렬 A에 특잇값 분해 수행 시, U, Σ, V의 3개 행렬로 분해 ➡️ 특잇값은 어디서 얻을 수 있는지?
- Σ의 대각 성분
절단된 특잇값 분해(Truncated SVD)
- 특잇값 분해 중에서도 조금 특별한 특잇값 분해
- 특잇값 중 가장 중요한(큰) t개만 남겨 해당 특잇값에 대응되는 특이 벡터 ➡️ 행렬 A 근사(approximate)
- 해당 특잇값 분해 수행 시, Σ 행렬의 대각 원소 중 상위 t개만 남음
- U 행렬, V 행렬 t열까지만 남음
- 세 행렬에서 값 손실 발생(기존 행렬 A의 완전 복구는 불가)
- t : 하이퍼파라미터(작게 잡아야 노이즈 생길 가능성 낮아짐)
LSA와 Truncated SVD
-
참고: 그림에서는 하이퍼파라미터 t를 k로 표현
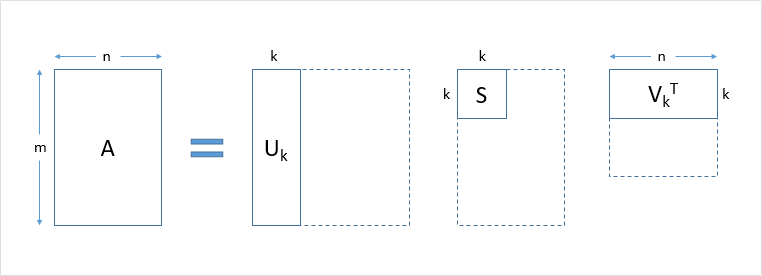
-
LSA
- DTM 혹은 TF-IDF 행렬 ➡️ Truncated SVD 수행
- 분해 행렬 3가지
- : 문서 관련 의미 표현 행렬
- : 단어 관련 의미 표현 행렬
- : 각 의미 중요도 표현 행렬
- 분해 행렬 3가지
- DTM 혹은 TF-IDF 행렬 ➡️ Truncated SVD 수행
-
- m(문서 수), n(단어 수)
- 크기 :
m x k- m은 줄어들지 않음
- 행 : 각 문서 표현 문서 벡터
-
- 크기 :
k x n - n은 줄어들지 않았음
- 열 : 각 단어를 나타내는 n차원 단어 벡터
- A에서의 단어 벡터 크기가 m이었던 것에 비하면, k 크기가 되었으니 벡터가 저차원으로 축소된 것
- 크기 :
-
의 k열
- 전체 코퍼스로부터 얻어낸 k개 topic
(2) LSA 실습
- 텍스트 데이터로부터 k개의 topic 추출
라이브러리 import
import pandas as pd
import numpy as np
import urllib.request
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfVectorizer
import nltk
from nltk.corpus import stopwords
from nltk.stem import WordNetLemmatizerNLTK 도구 사용을 위한 데이터셋 다운로드
nltk.download('punkt')
nltk.download('wordnet')
nltk.download('stopwords')
데이터 다운로드
import os
csv_filename = os.getenv('HOME')+'/aiffel/topic_modelling/data/abcnews-date-text.csv'
urllib.request.urlretrieve("https://raw.githubusercontent.com/franciscadias/data/master/abcnews-date-text.csv",
filename=csv_filename)
전체 샘플 수 및 일부 샘플 확인
- 약 108만 개
data = pd.read_csv(csv_filename, on_bad_lines='skip')
data.shape
data.head()
headline_text만 별도 저장
text = data[['headline_text']].copy()
text.head()
데이터 중복 확인 및 제거
- 중복 제외 시 약 105만 개 샘플
text.nunique()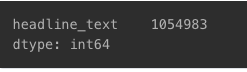
- 중복 샘플 3만 개 제거
text.drop_duplicates(inplace=True)
text.reset_index(drop=True, inplace=True)
text.shape
데이터 정제 및 정규화
NLTK토크나이저로 전체 텍스트 데이터에 대한 단어 토큰화NLTK불용어 리스트로 불용어 제거- 수 분 소요
text['headline_text'] = text.apply(lambda row: nltk.word_tokenize(row['headline_text']), axis=1)
stop_words = stopwords.words('english')
text['headline_text'] = text['headline_text'].apply(lambda x: [word for word in x if word not in (stop_words)])
text.head()
- 단어 정규화
- 3인칭 단수 : 1인칭, 과거형 : 현재형 등의 동일 단어의 다른 표현을 통합
- 길이 1 ~ 2인 단어 제거
text['headline_text'] = text['headline_text'].apply(lambda x: [WordNetLemmatizer().lemmatize(word, pos='v') for word in x])
text = text['headline_text'].apply(lambda x: [word for word in x if len(word) > 2])
print(text[:5])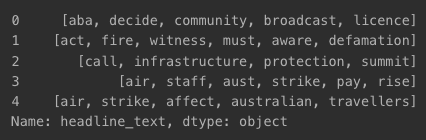
역토큰화 및 DTM 생성
- CountVectorizer(DTM 생성) or TfidfVectorizer(TF-IDF 행렬 생성) 입력으로 사용하기 위함
detokenized_doc = []
for i in range(len(text)):
t = ' '.join(text[i])
detokenized_doc.append(t)
train_data = detokenized_doc
train_data[:5]
- CountVectorizer로 DTM 생성
- 단어 수 : 5,000개
- DTM 크기(shape) : 문서 수 x 단어 집합 크기
c_vectorizer = CountVectorizer(stop_words='english', max_features = 5000)
document_term_matrix = c_vectorizer.fit_transform(train_data)
print('행렬의 크기 :',document_term_matrix.shape)
scikit-learn TruncatedSVD 활용
- Truncated SVD로 LSA를 수행
- topic 수 : 10(k를 의미)
- 행렬 = k x (단어 수)가 되는 크기를 가지도록 DTM에 TruncatedSVD 수행
from sklearn.decomposition import TruncatedSVD
n_topics = 10
lsa_model = TruncatedSVD(n_components = n_topics)
lsa_model.fit_transform(document_term_matrix)
- 크기 확인 = k x (단어 수) 크기가 되었음을 알 수 있음
print(lsa_model.components_.shape)
- 각 행 : 전체 코퍼스의 k개 topic으로 판단 & 각 topic에서 n개 단어를 각각 출력
terms = c_vectorizer.get_feature_names_out()
def get_topics(components, feature_names, n=5):
for idx, topic in enumerate(components):
print("Topic %d:" % (idx+1), [(feature_names[i], topic[i].round(5)) for i in topic.argsort()[:-n - 1:-1]])
get_topics(lsa_model.components_, terms)Topic 1: [('police', 0.74636), ('man', 0.45353), ('charge', 0.21085), ('new', 0.14091), ('court', 0.11144)]
Topic 2: [('man', 0.69419), ('charge', 0.30034), ('court', 0.16807), ('face', 0.11415), ('murder', 0.10673)]
Topic 3: [('new', 0.83665), ('plan', 0.23645), ('say', 0.18253), ('council', 0.11047), ('govt', 0.11009)]
Topic 4: [('say', 0.73951), ('plan', 0.35906), ('govt', 0.16691), ('council', 0.13751), ('urge', 0.07383)]
Topic 5: [('plan', 0.73232), ('council', 0.17642), ('govt', 0.14117), ('urge', 0.08439), ('water', 0.06963)]
Topic 6: [('govt', 0.52423), ('court', 0.26036), ('urge', 0.24402), ('fund', 0.19701), ('face', 0.15587)]
Topic 7: [('charge', 0.54358), ('court', 0.41193), ('face', 0.32731), ('murder', 0.14612), ('plan', 0.1423)]
Topic 8: [('win', 0.58029), ('court', 0.37609), ('kill', 0.1856), ('crash', 0.15866), ('australia', 0.11652)]
Topic 9: [('win', 0.56641), ('charge', 0.47087), ('council', 0.17785), ('australia', 0.09547), ('crash', 0.08958)]
Topic 10: [('kill', 0.55631), ('crash', 0.36436), ('council', 0.28418), ('charge', 0.17757), ('car', 0.14663)](3) LDA
- Latent Dirichlet Allocation
- 잠재 디리클레 할당
- 문서 : topic 혼합
- topic : 확률 분포 기반 단어 생성으로 가정
- 데이터가 주어지면 ➡️ (가정을 기반으로) 단어들 분포로부터 문서 생성되는 과정 역추적 ➡️ 문서 topic 찾음
LDA(Latent Dirichlet Allocation) 시뮬레이션
- 시뮬레이션 사이트 : LDA Topic Modeling Simulation
시뮬레이션 순서
+Add Document로 문서 다수 추가Topics값을 지정(주제 개수 정하는 하이퍼파라미터)Run LDA-> 2개 행렬(결과) 확인- documents 출처 : 21-02 잠재 디리클레 할당(Latent Dirichlet Allocation, LDA)
- 첫번째 행렬 : 행은 단어 집합 단어, 열은 Topic
- 두번쨰 행렬 : 행은 문서, 열은 Topic
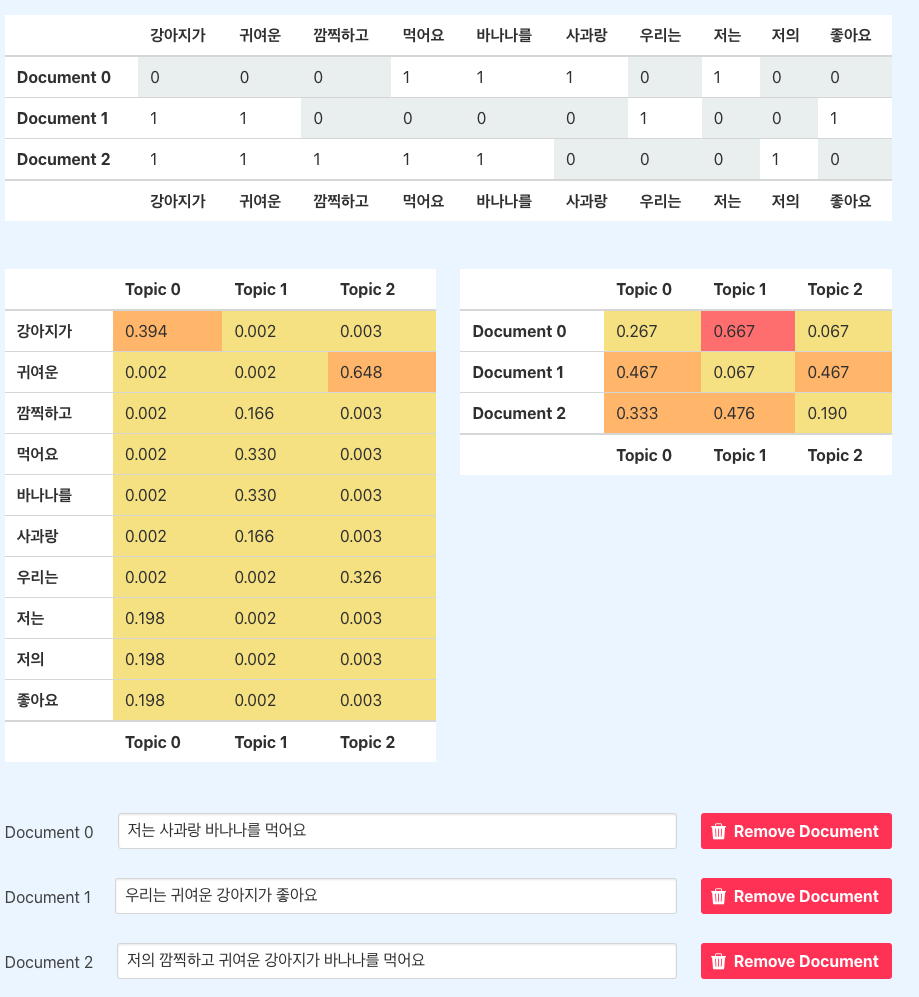
LDA(Latent Dirichlet Allocation)의 두 가지 결과
-
LDA는 각 토픽 단어 분포, 각 문서 토픽 분포 추정
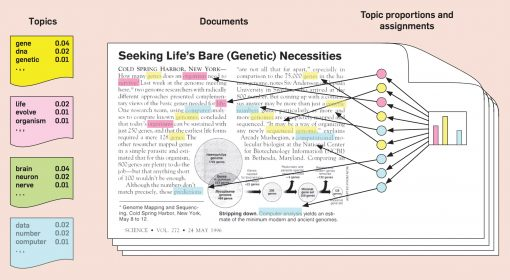
-
특정 topic에 ➡️ 특정 단어가 나타날 확률 추정
Topics: 초록색 부분brain의 등장 확률 0.04Documents: 노란색, 분홍색, 하늘색 토픽(3가지 토픽)- 직관적으로 봤을 경우, 노란색이 가장 많음
Topic proportions and assignments- 그래프 : 토픽 비율 시각화
- 그래프로 봤을 때에도, 노란색이 가장 많이 등장
- topic이 노란색일 가능성이 높음
LDA의 가정
-
모든 문서 하나하나 작성 ➡️ 문서 작성자의 가정
"이 문서 작성을 위해 이런 topic을 넣고, 이런 단어들을 넣을 것"
-
LDA의 직관
- 참고 자료 : 위키독스: 잠재 디리클레 할당
LSA와 LDA 매커니즘
- LSA : DTM 차원 축소를 통해 축소 차원에서 ➡️ 근접 단어들 topic으로 묶기
- LDA : 단어가 특정 토픽에 존재할 확률 + 문서에 특정 토픽이 존재할 확률 ➡️ 결합 확률로 추정(topic 추출)
LDA 아키텍쳐
(4) LDA 실습
- LSA 진행하며 전처리 완료한
train_data재사용- 역토큰화까지 끝낸 데이터임
TF-IDF 행렬 생성
- 입력 : DTM or TF-IDF
TfidfVectorizer사용- 단어 수 : 5,000개
tfidf_vectorizer = TfidfVectorizer(stop_words='english', max_features=5000)
tf_idf_matrix = tfidf_vectorizer.fit_transform(train_data)
print('행렬의 크기 :', tf_idf_matrix.shape)
scikit-learn LDA Model 활용
- 사이킷런에 LDA 모델이 있음
- 토픽 개수 : 10개(n_components)
from sklearn.decomposition import LatentDirichletAllocation
lda_model = LatentDirichletAllocation(n_components=10, learning_method='online', random_state=777, max_iter=1)
lda_model.fit_transform(tf_idf_matrix)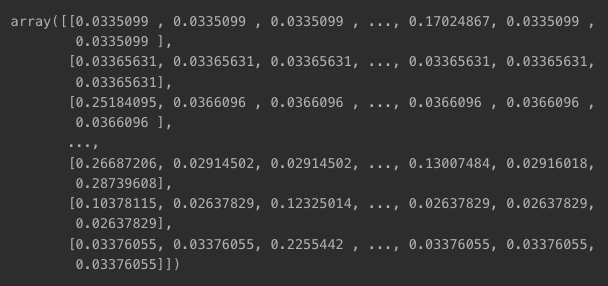
- 결과 행렬 크기 확인
print(lda_model.components_.shape)
- 전체 코퍼스에 얻은 10개 topic, 각 topic 내 단어 비중 확인
# 내 코드
terms = tfidf_vectorizer.get_feature_names_out()
def get_topics(components, terms, n=5):
for i, topic in enumerate(components, 1):
top_terms = [(terms[j], round(topic[j], 5)) for j in topic.argsort()[-n:][::-1]]
print(f"Topic {i}: {top_terms}")
get_topics(lda_model.components_, terms)Topic 1: [('australia', 9359.06334), ('sydney', 5854.97288), ('attack', 4784.76322), ('change', 4193.63035), ('year', 3924.88997)]
Topic 2: [('government', 6344.07413), ('charge', 5947.12292), ('man', 4519.7974), ('state', 3658.16422), ('live', 3625.10473)]
Topic 3: [('australian', 7666.65651), ('say', 7561.01807), ('police', 5513.22932), ('home', 4048.38409), ('report', 3796.04446)]
Topic 4: [('melbourne', 5298.35047), ('south', 4844.59835), ('death', 4281.78433), ('china', 3214.44581), ('women', 3029.28443)]
Topic 5: [('win', 5704.0914), ('canberra', 4322.0963), ('die', 4025.63057), ('open', 3771.65243), ('warn', 3577.47151)]
Topic 6: [('court', 5246.3124), ('world', 4536.86331), ('country', 4166.34794), ('woman', 3983.97748), ('crash', 3793.50267)]
Topic 7: [('election', 5418.5038), ('adelaide', 4864.95604), ('house', 4478.6135), ('school', 3966.82676), ('2016', 3955.11155)]
Topic 8: [('trump', 8189.58575), ('new', 6625.2724), ('north', 3705.40987), ('rural', 3521.42659), ('donald', 3356.26657)]
Topic 9: [('perth', 4552.8151), ('kill', 4093.61782), ('break', 2695.71958), ('budget', 2596.93268), ('children', 2586.01957)]
Topic 10: [('queensland', 5552.68506), ('coast', 3825.32603), ('tasmanian', 3550.75997), ('shoot', 3185.71575), ('service', 2695.21462)]# 예시 코드
terms = tfidf_vectorizer.get_feature_names_out() # 단어 집합. 5,000개의 단어가 저장됨.
def get_topics(components, feature_names, n=5):
for idx, topic in enumerate(components):
print("Topic %d:" % (idx+1), [(feature_names[i], topic[i].round(5)) for i in topic.argsort()[:-n-1:-1]])
get_topics(lda_model.components_, terms)Topic 1: [('australia', 9359.06334), ('sydney', 5854.97288), ('attack', 4784.76322), ('change', 4193.63035), ('year', 3924.88997)]
Topic 2: [('government', 6344.07413), ('charge', 5947.12292), ('man', 4519.7974), ('state', 3658.16422), ('live', 3625.10473)]
Topic 3: [('australian', 7666.65651), ('say', 7561.01807), ('police', 5513.22932), ('home', 4048.38409), ('report', 3796.04446)]
Topic 4: [('melbourne', 5298.35047), ('south', 4844.59835), ('death', 4281.78433), ('china', 3214.44581), ('women', 3029.28443)]
Topic 5: [('win', 5704.0914), ('canberra', 4322.0963), ('die', 4025.63057), ('open', 3771.65243), ('warn', 3577.47151)]
Topic 6: [('court', 5246.3124), ('world', 4536.86331), ('country', 4166.34794), ('woman', 3983.97748), ('crash', 3793.50267)]
Topic 7: [('election', 5418.5038), ('adelaide', 4864.95604), ('house', 4478.6135), ('school', 3966.82676), ('2016', 3955.11155)]
Topic 8: [('trump', 8189.58575), ('new', 6625.2724), ('north', 3705.40987), ('rural', 3521.42659), ('donald', 3356.26657)]
Topic 9: [('perth', 4552.8151), ('kill', 4093.61782), ('break', 2695.71958), ('budget', 2596.93268), ('children', 2586.01957)]
Topic 10: [('queensland', 5552.68506), ('coast', 3825.32603), ('tasmanian', 3550.75997), ('shoot', 3185.71575), ('service', 2695.21462)]16-12 ~ 13. 텍스트 분포를 이용한 비지도 학습 토크나이저
(1) 형태소 분석기와 단어 미등록 문제
형태소 분석기의 필요성
한국어는 *교착어
- *교착어: 하나의 어절이 하나의 어근과 단일 기능을 가지는 1개 이상의 접사 결합으로 이뤄진 언어
- 조사가 결합되어 있기 때문에, 영어와 같이 띄어쓰기 단위의 토큰화가 제대로 이뤄지지 않는 문제가 있음
영어 토큰화
en_text = "The dog ran back to the corner near the spare bedrooms"
print(en_text.split())['The', 'dog', 'ran', 'back', 'to', 'the', 'corner', 'near', 'the', 'spare', 'bedrooms']한국어 토큰화
- 조사
의,를,가,랑등..- 제거가 안되면 모두 다른 단어로 인식
- 해결을 위해 형태소 분석기 사용
kor_text = "사과의 놀라운 효능이라는 글을 봤어. 그래서 오늘 사과를 먹으려고 했는데 사과가 썩어서 슈퍼에 가서 사과랑 오렌지 사 왔어"
print(kor_text.split())['사과의', '놀라운', '효능이라는', '글을', '봤어.', '그래서', '오늘', '사과를', '먹으려고', '했는데', '사과가', '썩어서', '슈퍼에', '가서', '사과랑', '오렌지', '사', '왔어']Okt를 이용한 형태소 분석
from konlpy.tag import Okt
tokenizer = Okt()
print(tokenizer.morphs(kor_text))['사과', '의', '놀라운', '효능', '이라는', '글', '을', '봤어', '.', '그래서', '오늘', '사과', '를', '먹으려고', '했는데', '사과', '가', '썩어서', '슈퍼', '에', '가서', '사과', '랑', '오렌지', '사', '왔어']단어 미등록 문제
- 형태소 분석기의 경우, 등록된 단어 기준이기 때문에 새 단어는 인식하기 어려움
해결 방법
- 사용자 사전 등록
- 사용자가 직접 미등록 단어를 사전에 등록하는 형식
- 자동 사전 생성
- 미등록 단어 자동 추출 -> 사전 등록
- 대용량 텍스트 데이터 활용해서 빈도 수 기반 등으로 자동 사전 생성
- 기존 단어 활용
- 미등록 단어여도 -> 기존 단어 어간과 유사하다면 분석 수행 가능
- 문맥 분석
- 단어의 품사를 예측해서 분석 수행(ML 기반 분류 모델로 분석)
"모두의 연구소"라는 단어를 따로따로 처리
print(tokenizer.morphs('모두의연구소에서 자연어 처리를 공부하는 건 정말 즐거워'))
- 이 문제를 해결하기 위해 독립된 다른 단어의 연속 등장을 하나의 형태소로 파악할 수 있는
soynpl를 사용할 수 있음

(2) soynlp
- 품사 태깅, 형태소 분석 등 지원하는 한국어 형태소 분석기
- 비지도 학습
- 데이터에 등장 빈도수가 높은 단어 ➡️ 형태소로 분석함
- 내부 : 단어 점수표
- 응집 확률(cohesion probability)&브랜칭 엔트로피(branching entropy)
spynlp 실습
- 예제 말뭉치 다운로드
import urllib.request
txt_filename = os.getenv('HOME')+'/aiffel/topic_modelling/data/2016-10-20.txt'
urllib.request.urlretrieve("https://raw.githubusercontent.com/lovit/soynlp/master/tutorials/2016-10-20.txt",\
filename=txt_filename)
- 문서 단위로 분리
- 30,091개의 문서
from soynlp import DoublespaceLineCorpus
corpus = DoublespaceLineCorpus(txt_filename)
len(corpus)
- 상위 3개 문서 출력
- 공백 아닌 경우만
i = 0
for document in corpus:
if len(document) > 0:
print(document)
i = i+1
if i == 3:
break오패산터널 총격전 용의자 검거 서울 연합뉴스 경찰 관계자들이 19일 오후 서울 강북구 오패산 터널 인근에서 사제 총기를 발사해 경찰을 살해한 용의자 성모씨를 검거하고 있다 성씨는 검거 당시 서바이벌 게임에서 쓰는 방탄조끼에 헬멧까지 착용한 상태였다 독자제공 영상 캡처 연합뉴스 서울 연합뉴스 김은경 기자 사제 총기로 경찰을 살해한 범인 성모 46 씨는 주도면밀했다 경찰에 따르면 성씨는 19일 오후 강북경찰서 인근 부동산 업소 밖에서 부동산업자 이모 67 씨가 나오기를 기다렸다 이씨와는 평소에도 말다툼을 자주 한 것으로 알려졌다 이씨가 나와 걷기 시작하자 성씨는 따라가면서 미리 준비해온 사제 총기를 이씨에게 발사했다 총알이 빗나가면서 이씨는 도망갔다 그 빗나간 총알은 지나가던 행인 71 씨의 배를 스쳤다 성씨는 강북서 인근 치킨집까지 이씨 뒤를 쫓으며 실랑이하다 쓰러뜨린 후 총기와 함께 가져온 망치로 이씨 머리를 때렸다 이 과정에서 오후 6시 20분께 강북구 번동 길 위에서 사람들이 싸우고 있다 총소리가 났다 는 등의 신고가 여러건 들어왔다 5분 후에 성씨의 전자발찌가 훼손됐다는 신고가 보호관찰소 시스템을 통해 들어왔다 성범죄자로 전자발찌를 차고 있던 성씨는 부엌칼로 직접 자신의 발찌를 끊었다 용의자 소지 사제총기 2정 서울 연합뉴스 임헌정 기자 서울 시내에서 폭행 용의자가 현장 조사를 벌이던 경찰관에게 사제총기를 발사해 경찰관이 숨졌다 19일 오후 6시28분 강북구 번동에서 둔기로 맞았다 는 폭행 피해 신고가 접수돼 현장에서 조사하던 강북경찰서 번동파출소 소속 김모 54 경위가 폭행 용의자 성모 45 씨가 쏜 사제총기에 맞고 쓰러진 뒤 병원에 옮겨졌으나 숨졌다 사진은 용의자가 소지한 사제총기 신고를 받고 번동파출소에서 김창호 54 경위 등 경찰들이 오후 6시 29분께 현장으로 출동했다 성씨는 그사이 부동산 앞에 놓아뒀던 가방을 챙겨 오패산 쪽으로 도망간 후였다 김 경위는 오패산 터널 입구 오른쪽의 급경사에서 성씨에게 접근하다가 오후 6시 33분께 풀숲에 숨은 성씨가 허공에 난사한 10여발의 총알 중 일부를 왼쪽 어깨 뒷부분에 맞고 쓰러졌다 김 경위는 구급차가 도착했을 때 이미 의식이 없었고 심폐소생술을 하며 병원으로 옮겨졌으나 총알이 폐를 훼손해 오후 7시 40분께 사망했다 김 경위는 외근용 조끼를 입고 있었으나 총알을 막기에는 역부족이었다 머리에 부상을 입은 이씨도 함께 병원으로 이송됐으나 생명에는 지장이 없는 것으로 알려졌다 성씨는 오패산 터널 밑쪽 숲에서 오후 6시 45분께 잡혔다 총격현장 수색하는 경찰들 서울 연합뉴스 이효석 기자 19일 오후 서울 강북구 오패산 터널 인근에서 경찰들이 폭행 용의자가 사제총기를 발사해 경찰관이 사망한 사건을 조사 하고 있다 총 때문에 쫓던 경관들과 민간인들이 몸을 숨겼는데 인근 신발가게 직원 이모씨가 다가가 성씨를 덮쳤고 이어 현장에 있던 다른 상인들과 경찰이 가세해 체포했다 성씨는 경찰에 붙잡힌 직후 나 자살하려고 한 거다 맞아 죽어도 괜찮다 고 말한 것으로 전해졌다 성씨 자신도 경찰이 발사한 공포탄 1발 실탄 3발 중 실탄 1발을 배에 맞았으나 방탄조끼를 입은 상태여서 부상하지는 않았다 경찰은 인근을 수색해 성씨가 만든 사제총 16정과 칼 7개를 압수했다 실제 폭발할지는 알 수 없는 요구르트병에 무언가를 채워두고 심지를 꽂은 사제 폭탄도 발견됐다 일부는 숲에서 발견됐고 일부는 성씨가 소지한 가방 안에 있었다
테헤란 연합뉴스 강훈상 특파원 이용 승객수 기준 세계 최대 공항인 아랍에미리트 두바이국제공항은 19일 현지시간 이 공항을 이륙하는 모든 항공기의 탑승객은 삼성전자의 갤럭시노트7을 휴대하면 안 된다고 밝혔다 두바이국제공항은 여러 항공 관련 기구의 권고에 따라 안전성에 우려가 있는 스마트폰 갤럭시노트7을 휴대하고 비행기를 타면 안 된다 며 탑승 전 검색 중 발견되면 압수할 계획 이라고 발표했다 공항 측은 갤럭시노트7의 배터리가 폭발 우려가 제기된 만큼 이 제품을 갖고 공항 안으로 들어오지 말라고 이용객에 당부했다 이런 조치는 두바이국제공항 뿐 아니라 신공항인 두바이월드센터에도 적용된다 배터리 폭발문제로 회수된 갤럭시노트7 연합뉴스자료사진WordExtractor.extract()- 비지도 학습 방법이기 때문에 학습 과정 필요
- 전체 코퍼스로부터 응집 확률, 브랜칭 엔트로피 점수표 만드는 것
from soynlp.word import WordExtractor
word_extractor = WordExtractor()
word_extractor.train(corpus)
word_score_table = word_extractor.extract()
soynlp의 응집 확률(cohesion probability)
-
내부 문자열(substring)의 응집도 및 빈도수 판단의 척도
-
문자열을 문자 단위로 분리해 내부 문자열 만듦 ➡️ 왼쪽부터 문자 추가 ➡️ 문자열 주어진 경우 그 다음 문자가 나올 확률 계산 및 누적곱
-
값이 높을수록 ➡️ 전체 코퍼스에서 이 문자열 시퀀스가 1개 단어로 등장할 가능성도 커지는 것
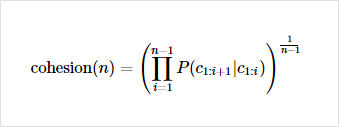
-
ex)
반포한강공원에- 길이 7 문자 시퀀스
- 각 내부 문자열 스코어

-
응집 확률 계산
word_score_table["반포한"].cohesion_forward
word_score_table["반포한강"].cohesion_forward
word_score_table["반포한강공"].cohesion_forward
word_score_table["반포한강공원"].cohesion_forward
👉 이 경우의 응집 확률이 최대 ==
반포한강공원이 1개 단어일 확률이 가장 높다는 의미
word_score_table["반포한강공원에"].cohesion_forward
soynlp의 브랜칭 엔트로피(branching entropy)
- 확률 분포의 엔트로피값 사용
- 주어진 문자열에서 다음 문자가 등장할 가능성 판단 척도
- 브랜칭 엔트로필 ➡️ 주어진 문자 시퀀스에서 다음 문자 예측 시 혼동되는 정도
- 하나의 완성된 단어에 가까워진다는 것
- 문맥으로 정확히 예측하게 되면서 점점 줄어듦
word_score_table["디스"].right_branching_entropy
디스플다음은레가 명확하게 오는 것을 알수 있기 때문에 0
word_score_table["디스플"].right_branching_entropy
디스플레도 같은 이유
word_score_table["디스플레"].right_branching_entropy
디스플레이- 값이 올라감
- 디스플레이 다음 문자 시퀀스는 조사 or 다른 단어가 나오는 경우로 증가되기 때문
- 하나의 단어 end ➡️ 경계부터 브랜칭 엔트로피 값 증가!
- 값이 올라감
word_score_table["디스플레이"].right_branching_entropy
2가지 토크나이저 보기
soynlp의 LTokenizer
- 띄어쓰기 단위로 잘 나뉘어 있는 문장의 경우 사용하면 좋음
- 한국어 :
L 토큰 + R 토큰
- 한국어 :
L 토큰 + R 토큰으로 나눔 + 점수가 가장 높은L 토큰찾는 기준
from soynlp.tokenizer import LTokenizer
scores = {word:score.cohesion_forward for word, score in word_score_table.items()}
l_tokenizer = LTokenizer(scores=scores)
l_tokenizer.tokenize("국제사회와 우리의 노력들로 범죄를 척결하자", flatten=False)
최대 점수 토크나이저
MaxScoreTokenizer- 띄어쓰기 안된 문장에서 점수 높은 글자 시퀀스 순차로 찾는 토크나이저
from soynlp.tokenizer import MaxScoreTokenizer
maxscore_tokenizer = MaxScoreTokenizer(scores=scores)
maxscore_tokenizer.tokenize("국제사회와우리의노력들로범죄를척결하자")
16-14. 마무리하며
최종 정리
- DTM (Document-Term Matrix)
- 정의: 문서-단어 빈도수를 행렬로 표현한 기법
- 특징: 단어 빈도만 반영, 의미 정보 부족
- TF-IDF (Term Frequency - Inverse Document Frequency)
- 정의: 자주 등장하지만 흔한 단어의 가중치를 낮추고, 중요한 단어의 가중치를 높이는 방법
- 특징: DTM의 한계를 보완, 중요 단어 강조
- LSA (Latent Semantic Analysis)
- 정의: DTM 또는 TF-IDF 행렬을 차원 축소하여 의미 관계를 찾는 기법
- 특징: SVD(특이값 분해) 기반, 의미적 유사성 반영
- LDA (Latent Dirichlet Allocation)
- 정의: 문서를 토픽의 혼합으로 보고, 확률 기반으로 토픽과 단어 분포를 추정하는 방법
- 특징: 확률 모델 활용, 주제 분석에 적합
- soynlp
- 정의: 한국어 자연어 처리를 위한 Python 라이브러리, 특히 비지도학습 기반의 단어 토큰화와 형태소 분석을 지원
- 기능: 신조어와 복합어 처리, 단어 점수 계산(응집도: 글자들이 함께 자주 등장하는 정도, 빈도수 기반 확률로 신뢰도 높은 단어 추출), 문장 분리(줄바꿈 없이 이어진 문장 자동 구분)
- 특징: 사전 의존도가 낮아 신조어와 미등록 단어(OOV) 처리에 강, 한국어 특화 기능이 있고 토크나이저, 품사 태깅, 단어 점수 분석 도구 활용 가능
