Node 04. 아이유팬이 좋아할 만한 다른 아티스트 찾기
☺️ AIFFEL 데이터사이언티스트 3기

4-1. 들어가며
학습 목표
- 추천 시스템의 개념과 목적 파악
Implicit라이브러리를 이용한 MF 기반 추천 모델 생성- 음악 감상 기록을 이용한 유사 아티스트 찾기 및 추천
- CSR Matrix
- 추천 시스템에서 자주 사용되는 데이터 구조
- 유저 행위 데이터의 차이점
- Explicit data
- Implicit data
- 새 데이터셋으로 추천 모델 만들어보기
4-2. 추천 시스템이란 게 뭔가요?
콘텐츠 추천 알고리즘의 진화
Q. 협업 필터링 vs 콘텐츠 기반 필터링
- 협업 필터링
- 반드시 기존 자료 활용 필요
- 콜드 스타트
- 계산량이 많아, 사용자 수가 많다면 효율적으로 추천할 수 없음
- 롱테일
- 콘텐츠 기반 필터링
- 행동 기록을 이용하는 협업 필터링과는 달리, 콘텐츠 기반 필터링은 항목 자체를 분석해 추천을 구현
- 아이템 분석 알고리즘이 핵심
- 군집 분석, 인공 신경망, TF-IDF 등 기술 사용
- 콜드 스타트 문제 해결 가능
- 다양한 형식의 항목을 추천하기에는 어려움이 있음
- 차이점
- 협업 필터링 : 다수 사용자의
아이템 구매 이력 정보만으로 사용자 간 유사성, 아이템 간 유사성 판단- 아이템 - 사용자 간 행동(관계)에만 주목
- 콘텐츠 기반 필터링 :
아이템 고유 정보로 아이템 간 유사성 판단- 아이템 자체 속성에만 주목
Q. 협업 필터링을 바로 사용할 수 없는 3가지 제약 조건
제약 조건
- 콜드 스타트 : 시스템이 충분한 정보를 모으지 못한 사용자 또는 아이템에 대한 추론을 할 수 없는 상태
- 계산량이 많아 추천 효율이 떨어짐
- 롱테일 문제 : 사용자 관심이 저조한 항목 정보가 부족해 추천에서 배제됨
Q. 유튜브 뮤직에서의 첫화면에서 신규 접속 사용자에게 좋아하는 아티스트 5명 이상의 정보를 요구하는 이유는?
- 사용자에 대한 초기 정보가 없기 때문에, 사용자 기반 추천을 할 수 없으니 콘텐츠 기반 필터링 방식으로의 추천만 가능
- 이 부분을 보완해, 처음부터 맞춤형 서비스를 제공하려는 목적
- 단점
- 필터 버블: 모든 사용자가 처음 추천된 콘텐츠만 시청
- 추천 다양성 저해
추천 시스템의 실제 사례
- Youtube: 동영상의 양이 많고, 유저 취향이 다양
- Facebook: 포스팅 되는 글이 많고, 유저의 관심 페이지, 친구 및 그룹이 모두 다름
- Amazon: 카테고리를 필터링하더라도 판매 품목 자체가 많음, 좋아하는 브랜드 등의 구매 기준이 다양할 수 있음
Last.fm
- 유저가 좋아하는 특정 아티스트와 유사한 타 아티스트 추천하는 시스템에 필요한 데이터셋
- 어떤 유저가 특정 아티스트 노래를 몇 번 들었는지에 대한 데이터
- 2010년 spotify 데이터: 생소할 수 있음
- 국내 아티스트를 기반으로 추천 시스템을 만들고 싶다면 ➡️ Melon Playlist Dataset 사용
$ mkdir -p ~/aiffel/recommendata_iu/data/lastfm-dataset-360K
$ ln -s ~/data/lastfm-dataset-360K/* ~/aiffel/recommendata_iu/data/lastfm-dataset-360K4-3. 데이터 탐색하기와 전처리
데이터 준비
- 데이터 형태 : tsv
- 구분자가 comma가 아닌
\t read_csv로도 충분히 파싱 가능
- 구분자가 comma가 아닌
$ more ~/aiffel/recommendata_iu/data/lastfm-dataset-360K/usersha1-artmbid-artname-plays.tsv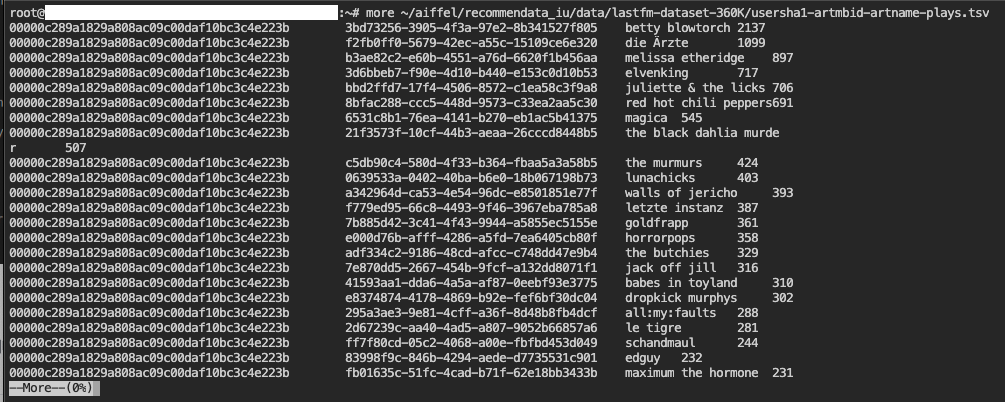
Q. 4가지 컬럼의 의미
user-mboxsha1 \t musicbrainz-artist-id \t artist-name \t plays
- user-mboxsha1 : 고유 유저 정보(User ID)
- musicbrainz-artist-id : 고유 아티스트 아이디(Artist MBID)
- artist-name : 아티스트 이름
- plays : 재생 횟수
- 데이터 열어보기
col_names로 적절하게 컬럼명 지정 필요
import pandas as pd
import os
fname = os.getenv('HOME') + '/aiffel/recommendata_iu/data/lastfm-dataset-360K/usersha1-artmbid-artname-plays.tsv'
col_names = ['user_id', 'artist_MBID', 'artist', 'play'] # 컬럼명 임의 지정
data = pd.read_csv(fname, sep='\t', names= col_names) # sep='\t'로 설정하여 tsv 열기
data.head(10)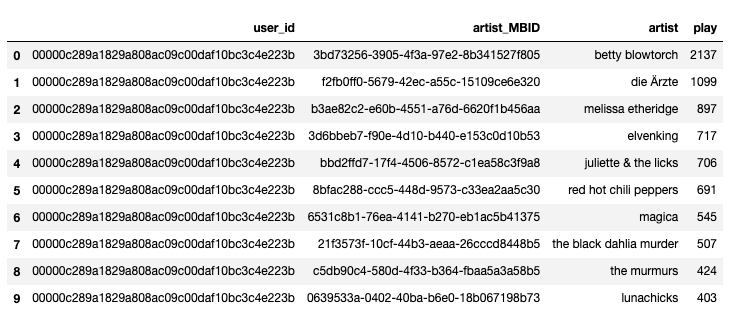
- 사용할 컬럼만 남기기
artist_MBID는 관심사가 아니기 때문에 제거
using_cols = ['user_id', 'artist', 'play']
data = data[using_cols]
data.head(10)
- 아티스트 문자열 ➡️ 소문자로 교체
- 검색에 용이할 수 있도록!
data['artist'] = data['artist'].str.lower()
data.head(10)
- 첫 번째 유저 확인
- 어떤 아티스트의 노래를 듣는지 살펴보기
- 생소한 아티스트가 많음(이렇게 될 경우 도메인 지식이 모자라 검증에 어려움이 있을 수 있음!)
condition = (data['user_id']== data.loc[0, 'user_id'])
data.loc[condition]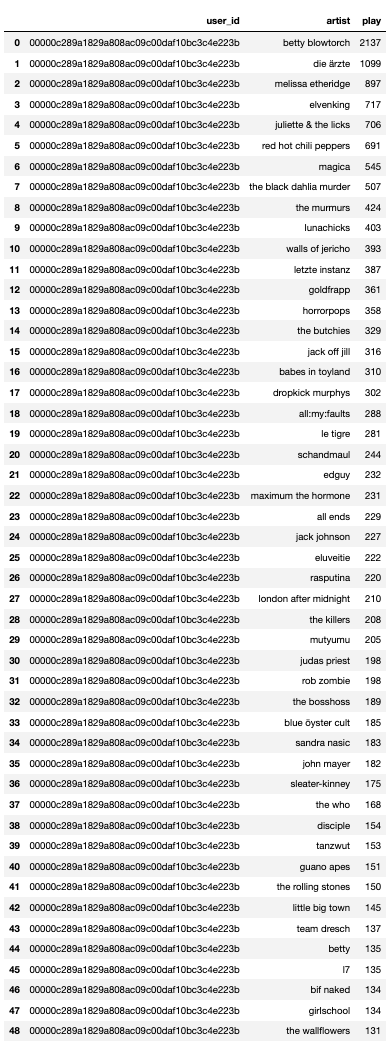
데이터 탐색
확인할 항목 정리
- 유저 수, 아티스트 수, 인기가 많은 아티스트
- 유저들이 몇 명의 아티스트를 듣고 있는지에 대한 통계
- 유저 플레이 횟수 중앙값 통계
- 유저 수
data['user_id'].nunique()
- 아티스트 수
data['artist'].nunique()
- 인기가 많은 아티스트
artist_count = data.groupby('artist')['user_id'].count()
artist_count.sort_values(ascending=False).head(30)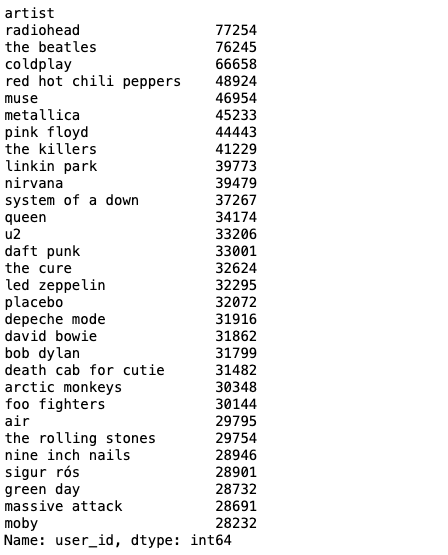
- 유저들이 몇 명의 아티스트를 듣고 있는지에 대한 통계
user_count = data.groupby('user_id')['artist'].count()
user_count.describe()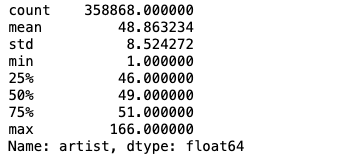
- 유저 플레이 횟수 중앙값 통계
user_median = data.groupby('user_id')['play'].median()
user_median.describe()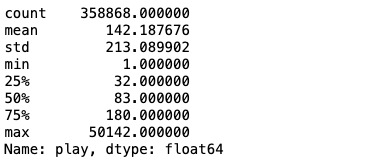
모델 검증을 위한 사용자 초기 정보 세팅
- 유명한 아티스트들을 기존 데이터에 추가하여 넣기
- 유튜브 뮤직 등의 추천 시스템에서 처음 가입하는 사용자의 취향 및 유사 아티스트 정보를 5개 이상 입력받는 과정을 구현하는 것
my_favorite = ['red hot chili peppers' , 'queen' ,'jason mraz' ,'coldplay' ,'beyoncé']
# 'hayan'이라는 user_id가 위 아티스트의 노래를 30회씩 들었다고 가정
my_playlist = pd.DataFrame({'user_id': ['hayan']*5, 'artist': my_favorite, 'play':[30]*5})
if not data.isin({'user_id':['hayan']})['user_id'].any():
data = pd.concat([data, my_playlist])
data.tail(10)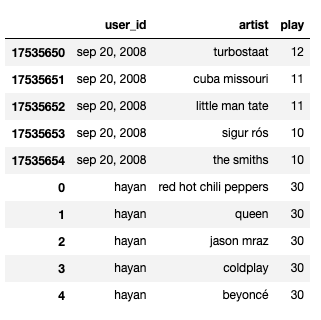
모델에 활용하기 위한 전처리
- 인덱싱 : user, artist에 번호 붙이기
user_unique = data['user_id'].unique()
artist_unique = data['artist'].unique()
user_to_idx = {v:k for k,v in enumerate(user_unique)}
artist_to_idx = {v:k for k,v in enumerate(artist_unique)}- 확인
print(user_to_idx['hayan'])
print(artist_to_idx['red hot chili peppers'])
- indexing으로 컬럼 내 값 변경
user_to_idx.get: user_id 컬럼 값을 인덱싱한 시리즈 구하기artist컬럼 : artist_to_idx로 동일 방식 인덱싱 수행
# user_to_idx.get을 통해 user_id 컬럼의 모든 값을 인덱싱한 Series 구하기
temp_user_data = data['user_id'].map(user_to_idx.get).dropna()
if len(temp_user_data) == len(data):
print('user_id column indexing OK!!')
data['user_id'] = temp_user_data
else:
print('user_id column indexing Fail!!')
# artist_to_idx을 통해 artist 컬럼도 동일한 방식으로 인덱싱
temp_artist_data = data['artist'].map(artist_to_idx.get).dropna()
if len(temp_artist_data) == len(data):
print('artist column indexing OK!!')
data['artist'] = temp_artist_data
else:
print('artist column indexing Fail!!')
data
4-4. 사용자의 명시적/암묵적 평가
명시적 평가
- 좋아요, 별점 등
암묵적 평가
- 사용자가 아티스트의 곡을 몇 번 플레이했는지에 대한 정보
- 서비스 사용 시 자연스럽게 발생하는 암묵적 피드백
- ex) 플레이 횟수, 플레이 시간, 플레이 스킵 여부, 플레이리스트 추가 여부, 클릭 수, 구매 여부, 검색 기록, 방문 페이지 이력, 구매 내역, 마우스 움직임 기록...
Collaborative Filtering for Implicit Feedback Datasets
- 암묵적 피드백 데이터셋 활용 시 염두해야 하는 부분
- No Negative Feedback
- 부정 피드백이 없음
- Inherently Noisy
- 원래부터 노이즈가 많음
- The numerical value of implicit feedback indicates confidence
- 수치는 신뢰도를 의미하는 것
- Evaluation of implicit-feedback recommender requires appropriate measures
- Implicit-feedback Recommender System 평가는 적절한 방법에 대해 고민해야 함
Q. 유저가 어떠한 아티스트의 곡을 1회만 들었다면, 이 유저에게 해당 아티스트와 관련된 사람을 추천해도 될지?
- 1회 들었으나, 그 평가가 긍정적일 수도 부정적일 수도 있기 때문에 애매한 지점이 있음
- 도메인 지식 + 직관이 활용되어야 하는 영역임
1회만 플레이한 데이터 비율 확인
only_one = data[data['play']==1]
one, all_data = len(only_one), len(data)
print(f'{one},{all_data}')
print(f'Ratio of only_one over all data is {one/all_data:.2%}')
- 규칙 선정
- 1회라도 들었다면 ➡️ 선호하는 것으로 간주
- 재생 횟수가 많은 아티스트에게 가중치를 주어 더 좋아하는 것으로 판단!
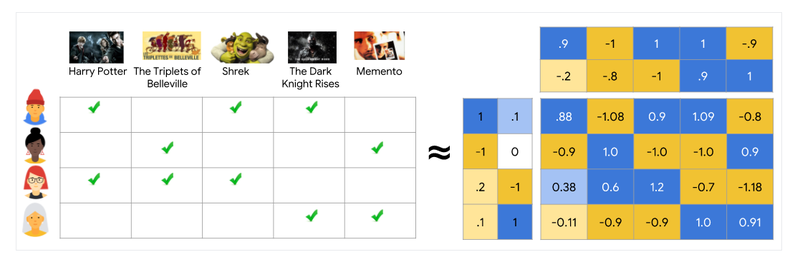
4-5. Matrix Factorization(MF)
Matrix Factorization(MF, 행렬 분해) 모델
- m명의 사용자들이 n명의 아티스트에 대해 평가한 데이터
- (m, n) 행렬 R ➡️ (m, k) 행렬 P & (k, n) 행렬 Q로 분해 ➡️ R이 P와 Q 행렬곱으로 표현 가능한 행렬임을 증명
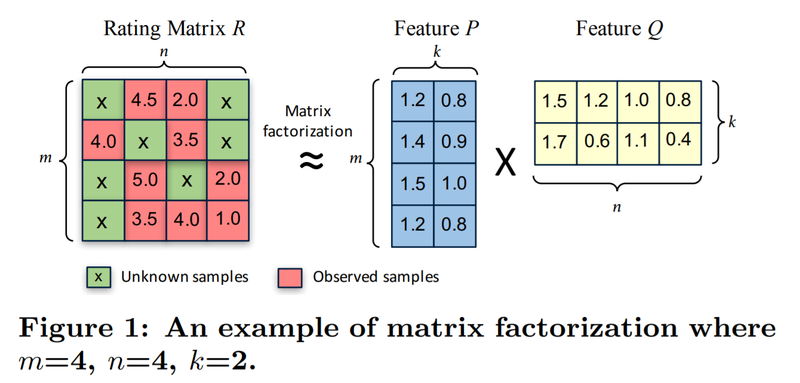
(m, k) Feature Matrix P
-
k차원 벡터를 사용자 수만큼 모은 행렬
- : 첫번째 사용자 특성 벡터(Feature vector)
- : 해리포터 영화의 특성 벡터(Feature vector)
-
사용자의 영화 선호도 모델: 이 2개의 벡터를 내적해 얻은 0.88 ➡️ 으로 정의
벡터를 잘 만드는 기준
유저 i의 벡터와 아이템 j의 벡터 내적및유저 i가 아이템 j에 대해 평가한 수치와의 유사도
사용할 모델: Collaborative Filtering for Implicit Feedback Datasets 제안 모델
- 이전 단계에서 'red hot chili peppers'를 플레이한 데이터를 추가했음
벡터&red hot chili peppers 벡터의 곱 : 1에 가까워야 모델이 잘 학습한 것이라고 말할 수 있음!- 이를 추측하면, 듣지 않은 아티스트의 노래에 대해서도
벡터&새로운 아티스트 벡터의 곱으로 수치 예상이 가능해짐
만약, 유저 재생 횟수를 맞혀야 할 경우
4-6. CSR(Compressed Sparse Row) Matrix
유저 x 아이템 평가 행렬
- user: 36만 명
- Artist: 29만 명
- 행렬 표현 & 각 원소에 1byte씩 => 36만 x 29만 x 1byte≈97GB
Q. 평가행렬의 용량이 많이 커지는 이유?
희소 행렬
- 많은 아티스트의 노래를 들었다고 하더라도, 아티스트가 29만 명에 달하기 때문에 평가 행렬 대부분이 0으로 채워짐
- 메모리 낭비 최소화 : 유저가 들어본 아티스트에 대한 정보만 저장 & 그러면서도 전체 행렬 형태는 유추가 가능해야 함
CSR(Compressed Sparse Row) Matrix
- Sparse한 Matriz에서 0이 아닌 유효 데이터로 채워지는 데이터 값 및 좌표 정보로 구성
- data, indices, indptr: 행렬 압축
예시
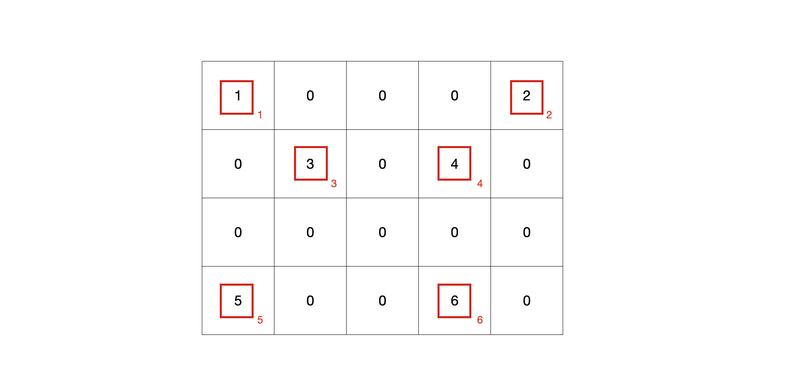
data = [1, 2, 3, 4, 5, 6]
indices = [0, 4, 1, 3, 0, 3]
indptr = [0, 2, 4, 4, 6]
- data : 0이 아닌 원소로 이뤄짐
- indices: data 각 요소가 어떤 column에 있는지 표현한 인덱스 값
- indptr: [최초 시작 행번호, 시작 행에서의 데이터 개수, 두번째 행에서의 데이터 개수, ...]
- data 요소들이 어느 row에 있는지 파악
- 즉, data[0:2]는 첫 번째 행, data[2:4]는 두 번째 행, data[4:4]는 세 번째 행, data[4:6]는 네 번째 행임을 알 수 있는 것!
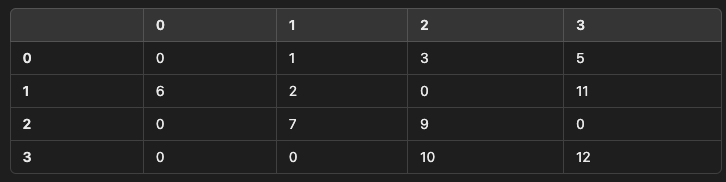
Q. CSR Matrix를 (4,4) matrix로 변환
data = np.array([1,3,5,6,2,11,7,9,10,12])
indices = np.array([1,2,3,0,1,3,1,2,2,3])
indptr = np.array([0,3,6,8,10])
- 답: matrix([[0, 1, 3, 5], [6, 2, 0, 11], [0, 7, 9, 0], [0, 0, 10, 12]])
실습: 데이터에 CSR 적용
from scipy.sparse import csr_matrix
num_user = data['user_id'].nunique()
num_artist = data['artist'].nunique()
csr_data = csr_matrix((data.play, (data.user_id, data.artist)), shape= (num_user, num_artist))
csr_data
4-7. MF 모델 학습하기
implicit 이용
- 암묵적 데이터셋을 사용하는 모델을 빠르게 학습할 수 있음
- als(AlternatingLeastSquares) 모델 사용 예정
- 한쪽을 고정, 다른 쪽을 학습시키는 방식을 사용 -> 이 과정을 번갈아 수행
from implicit.als import AlternatingLeastSquares
import os
import numpy as np
# 기본 설정
os.environ['OPENBLAS_NUM_THREADS']='1'
os.environ['KMP_DUPLICATE_LIB_OK']='True'
os.environ['MKL_NUM_THREADS']='1'AlternatingLeastSquares 클래스의 init 파라미터
factors: 유저 및 아이템 벡터의 차원 수regularization: 과적합 방지를 위한 정규화 값을 얼마나 사용하는지 결정use_gpu: GPU 사용 여부iterations: ==epoch(반복 학습 횟수)
factors, iterations를 늘리면 -> 학습 데이터를 더 잘 학습하나, 과적합 우려가 커질 수 있음
# 모델 선언
als_model = AlternatingLeastSquares(factors=100, regularization=0.01, use_gpu=False, iterations=15, dtype=np.float32)# Transpose
csr_data_transpose = csr_data.T
csr_data_transpose
모델 학습
# 모델 훈련
als_model.fit(csr_data_transpose)
모델 성능 확인
- Zimin 벡터, red hot chili peppers 벡터를 어떻게 만들고 있는지 확인
- 벡터 곱은 어떤 값으로 도출되는지 확인
hayan, red_hot_chili_peppers = user_to_idx['hayan'], artist_to_idx['red hot chili peppers']
hayan_vector, red_hot_chili_peppers_vector = als_model.user_factors[hayan], als_model.item_factors[red_hot_chili_peppers]hayan_vector
red_hot_chili_peppers_vector
- 벡터 내적
np.dot(hayan_vector, red_hot_chili_peppers_vector)
- 결과 확인
- 0.55 정도의 낮은 수치
- factors or iterations를 늘려야 할 수 있음
factors 혹은 iterations를 늘려서 1에 가까운 수치가 나온다면, 이 모델이 잘 학습되었다고 할 수 있는지?
- 검증되지 않음.
- fitting은 되었으나 이 모델이 보지 못한 데이터의 경우에는 예측 결과를 속단할 수 없기 때문
- 새로운 아티스트에 대한 선호도 예측 결과 보기
- 사전에 넣었던 아티스트 리스트에 없는 아티스트로 진행
- black eyed peas
black_eyed_peas = artist_to_idx['black eyed peas']
black_eyed_peas_vector = als_model.item_factors[black eyed peas]
np.dot(hayan_vector, black_eyed_peas_vector)
- radiohead
radiohead = artist_to_idx['radiohead']
radiohead_vector = als_model.item_factors[radiohead]
np.dot(hayan_vector, radiohead_vector)
4-6. 비슷한 아티스트 찾기 + 유저에게 추천하기
비슷한 아티스트 찾기
similar_items- AlternatingLeastSquares 클래스에 구현되어 있음
favorite_artist = 'coldplay'
artist_id = artist_to_idx[favorite_artist]
similar_artist = als_model.similar_items(artist_id, N=15)
similar_artist
- 아티스트 id ➡️ 아티스트 이름으로 매핑
- artist_to_idx를 뒤집어서 생성
idx_to_artist = {v:k for k,v in artist_to_idx.items()}
[idx_to_artist[i[0]] for i in similar_artist]
- 반복 확인을 위해 함수화
def get_similar_artist(artist_name: str):
artist_id = artist_to_idx[artist_name]
similar_artist = als_model.similar_items(artist_id)
similar_artist = [idx_to_artist[i[0]] for i in similar_artist]
return similar_artist- 아티스트
2pac으로 확인- 힙합 장르의 아티스트들이 추천됨(힙합은 마니아층이 있어 더 잘 추천되는 경향이 있음!)
get_similar_artist('2pac')
Q. 마니아가 데이터에서 표현되는 특징?
- 특정 장르의 아티스트에게 선호도 집중
- 타 장르와는 선호도 낮은 경향
- 즉, 위의
get_similar_artist가 마니아 유저일 경우 장르별 특성이 더 두드러지게 나타날 것
- 아티스트
lady gaga로 확인- 여성 아티스트들이 추천됨
get_similar_artist('lady gaga')
유저에게 아티스트 추천하기
recommend- 이 메서드 역시 AlternatingLeastSquares 클래스에 구현되어 있음
filter_already_liked_items- 유저가 기평가한 아이템 제외
user = user_to_idx['hayan']
# recommend의 경우 user*item CSR Matrix를 입력으로 받음
artist_recommended = als_model.recommend(user, csr_data, N=20, filter_already_liked_items=True)
artist_recommended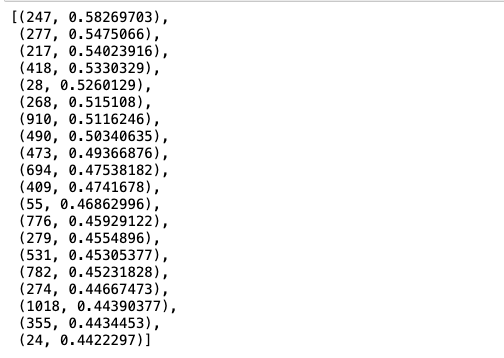
[idx_to_artist[i[0]] for i in artist_recommended]
muse를 추천explain메서드: 추천에 기여한 정도를 확인
muse = artist_to_idx['muse']
explain = als_model.explain(user, csr_data, itemid=muse)- 어떤 아티스트가 추천에 어느 정도로 기여하고 있는지 확인
[(idx_to_artist[i[0]], i[1]) for i in explain[1]]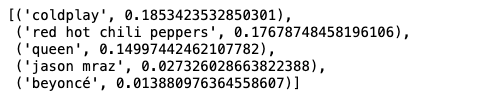
coldplay, red hot chili peppers 모두 밴드 그룹이기 때문에 유사한 밴드인 muse를 추천한 것으로 보임
이 부분에서의 의심되는 부분
- 현재 다른 경우의 아티스트 리스트를 넣어 추천 아티스트가 이미 듣고 있는 아티스트와 우연히 겹치지 않았음
- 그러나,
filter_already_liked_items=True로 설정하더라도 이미 있는 아티스트와 추천 아티스트가 겹치는 경우가 생김- mplicit 버전 0.4.2의 버그
현재 모델의 아쉬운 점
- 유저 및 아티스트에 대한 메타 정보 반영이 어려움
- ex) 연령대별 음악 취향도 다양할 수 있음
- 유저가 언제 플레이했는지를 알기 어려움
- ex) 10년 전 듣던 아티스트와, 현재 듣고 있는 아티스트를 비교한다면?
