논문리뷰
1.Few-Shot Learning(Siamese, Triplet, Relation Neural Network)

Few-Shot Learning(Siamese, Triplet, Relation Network)
2.BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding

BERT paper summary
3.End-to-end Neural Coreference Resolution
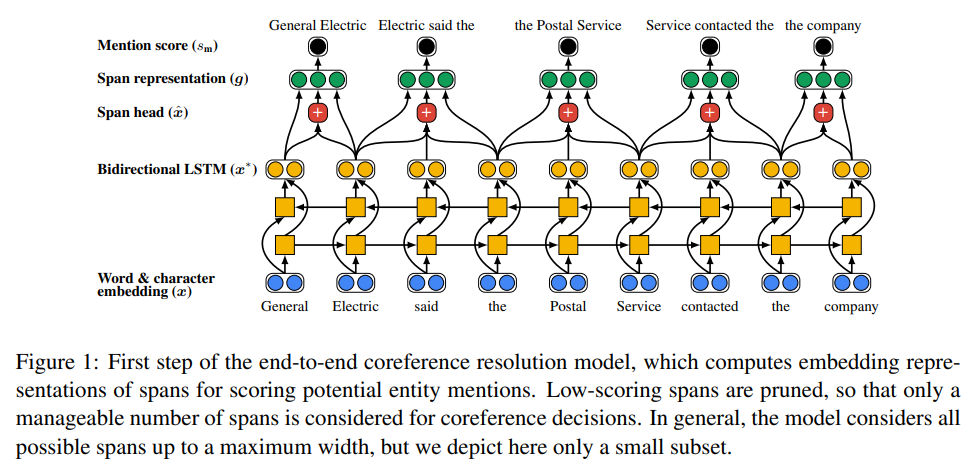
coreference : 임의의 개체(entity)를 표현하는 다양한 명사구(멘션)들을 찾아 연결해주는 자연어처리 문제.
4.Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing
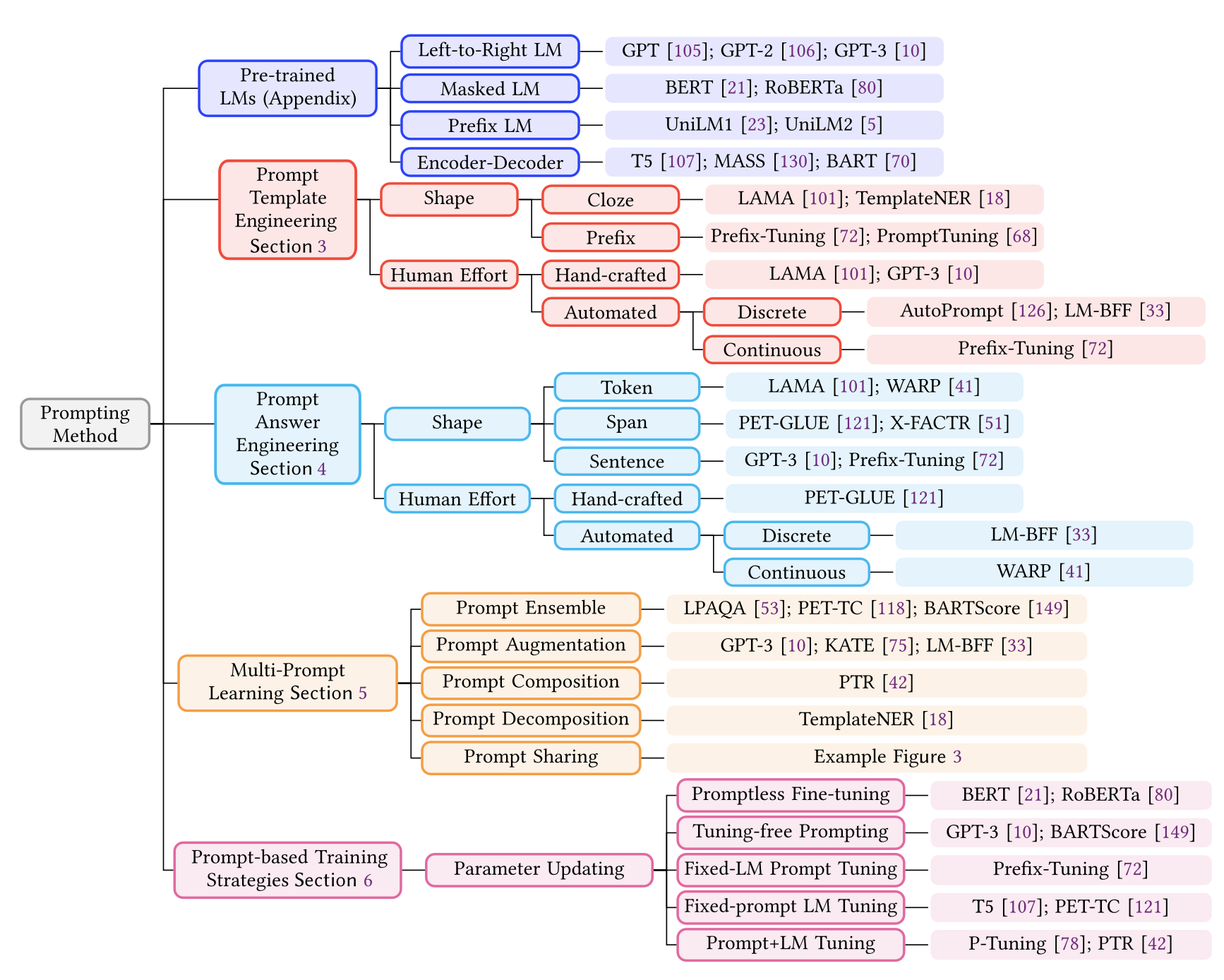
NLP분야에서 전통적 지도학습부터 현재 트랜드 및 프롬프트에 관한 survey논문
5.BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension

BART 논문리뷰
6.Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
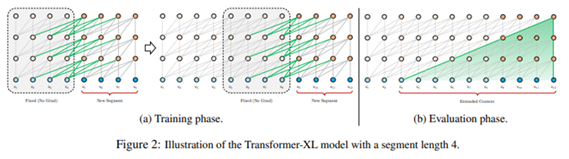
트랜스포머 구조를 이용한 고정된 길이의 한계점 → 더 긴 의존성을 이용할 수 있는 방법 제시. XLNet과 동일한 저자가 작성
7.GPT2 : Language Models are Unsupervised Multitask Learners
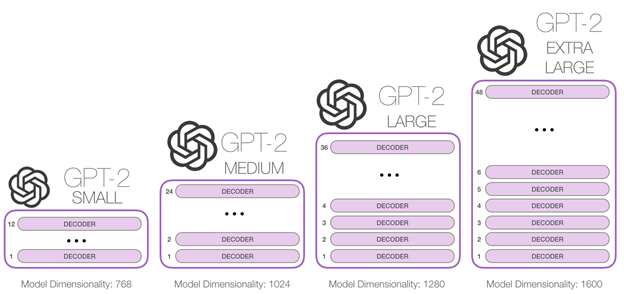
agnostic task 가능한 LM 을 만들어보자 지도학습 + 비지도학습을 통한 모델 형성은 특정 테스크 수행으 잘하도록 학습이 된다. 하지만, 이는 작은 데이터셋의 변화에도 쉽게 task를 망칠 수 도 있는 위험이 존재한다. 지금까지 모델들은 좁은 범위
8.GPT1 : Improving Language Understanding by Generative Pre-Training
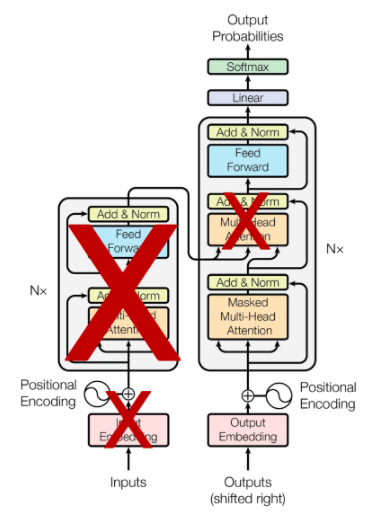
unlabeled data 사용어떤 형태의 최적화 목적(optimization objective)가 가장 좋은지 불분명해, transfoer에 유용한 text 표현이 뭔지 알기 어렵다 → LM, machine translation, discourse coherence
9.XLNet- Generalized Autoregressive Pretraining for Language Understanding
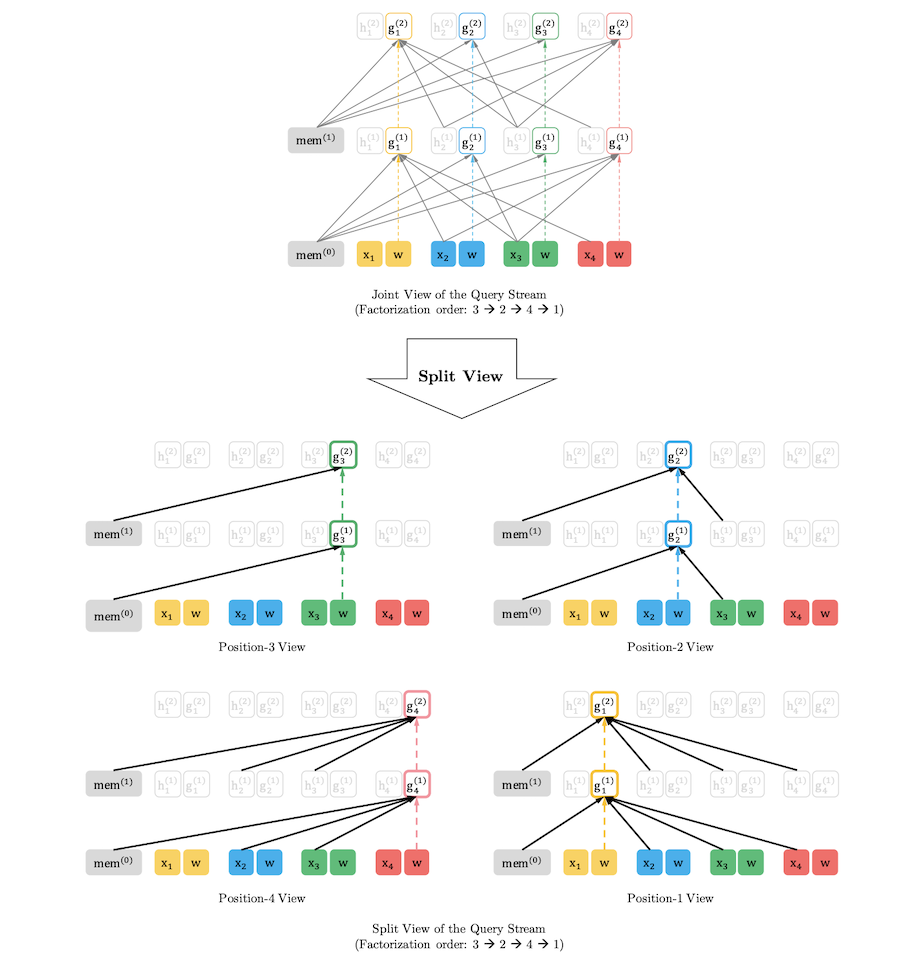
XLNet - transformer xl 저자들이 쓴 논문으로, xl 방식을 많이 사용하면서 permutation 방식 적용
10.MT-DNN: Multi-Task Deep Neural Networks for Natural Language Understanding
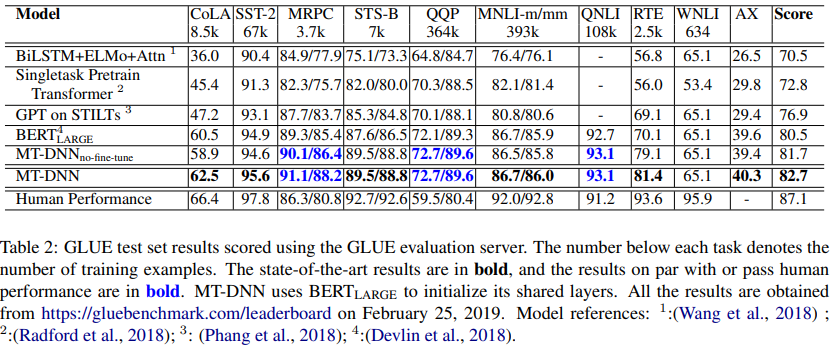
여러 task 동시에 학습하여 regularization에서 효과적, 특정 task에 대한 overfitting 막아준다. → MT-DNN은 기존 pre-trianing기법에 MTL을 합치는 것이 상호 보완적 효과를 가져올 수 있겠다는 생각에서 출발해 → 성능개선
11.Anomaly Transformer: Time Series Anomaly Detection with Association Discrepancy
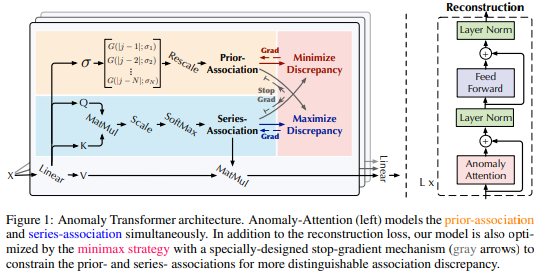
논문에서는 “각 time point를 주변의 모든 time point들간의 관계로 표현할 수 있다.” 라고 주장, 이를 point-wise distribution으로 표현
12.ALBERT: A Lite BERT for Self-supervised Learning of Language Representations

Factorizaed Embedding Parameterization, Cross Layer parameter sharing, SOP, Encoder 모델은 hid_size, Layer 계속 늘린다고 성능이 좋아지지 않는다.ALBERT에서 제시Factorized Emb
13.ELECTRA : Pre-training Text Encoders as Discriminators Rather Than Generators
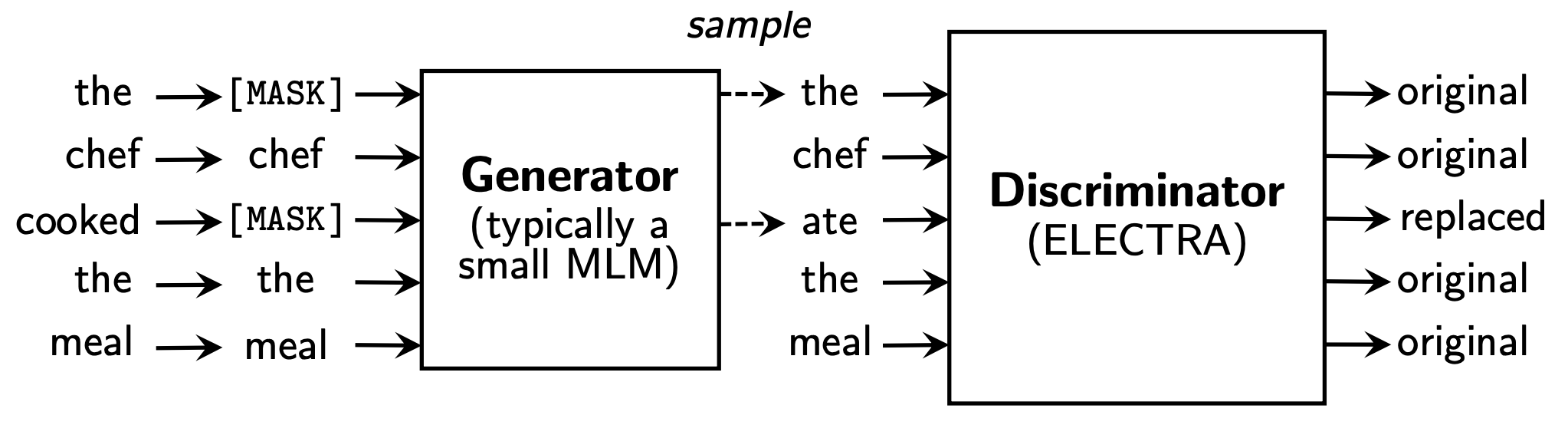
Electra 모델은 정확도와 함께 학습의 효율성에 주목한다. 본 논문에서는 학습의 효율 향상을 위해 Replaced Token Detection(RTD)이라는 새로운 pre-training task를 제안했다.ELETRA모델은 빠르고 효과적으로 학습한다. 동일한 조건
14.GPT-3 : Language Models are Few-Shot Learners

GPT-3 paper review
15.InstructGPT

InstructGPT
16.LoRA : Low-Rank Adaptation of Large Language Models

LoRA paper review
17.Pseudo-LiDAR from Visual Depth Estimation: Bridging the Gap in 3D Object Detection for Autonomous Driving

voxel : pixel + volume : 2D(pixel) → 3D(+volume ) 로 표현한 것 camera parameter(calibration) : 2D → 3D로 바꿔주는 방식disparty cost volumne (더 정확한 3D 포인트 클라우드 추정할
18.Extrapolating Large Language Models to Non-English by Aligning Languages
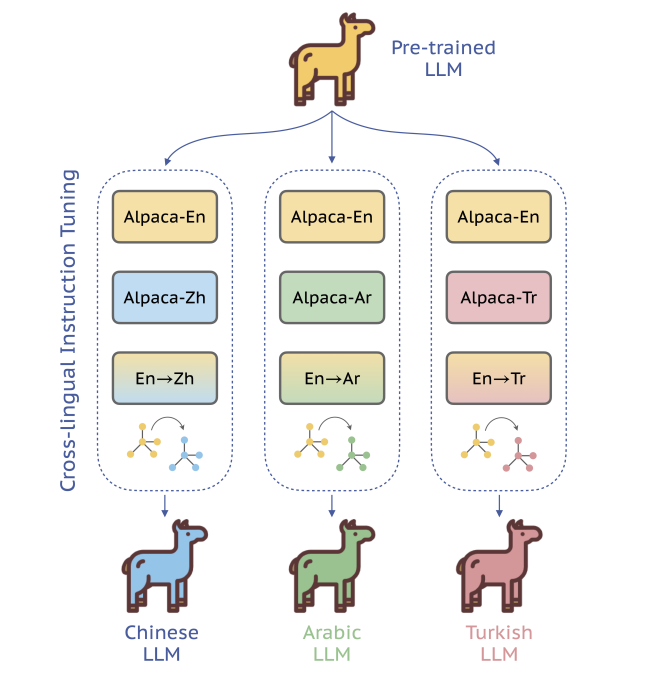
업로드중..unbalanced training data distribution으로 인해 En편향성을 갖는다.⇒segmentic alignment across language 통해 해결하려함모델성능은 alpaca와 비교했을 때 평균 42.5%(단, 실험이 번역 실험임)
19.DPO : Direct Preference Optimization: Your Language Model is Secretly a Reward Model
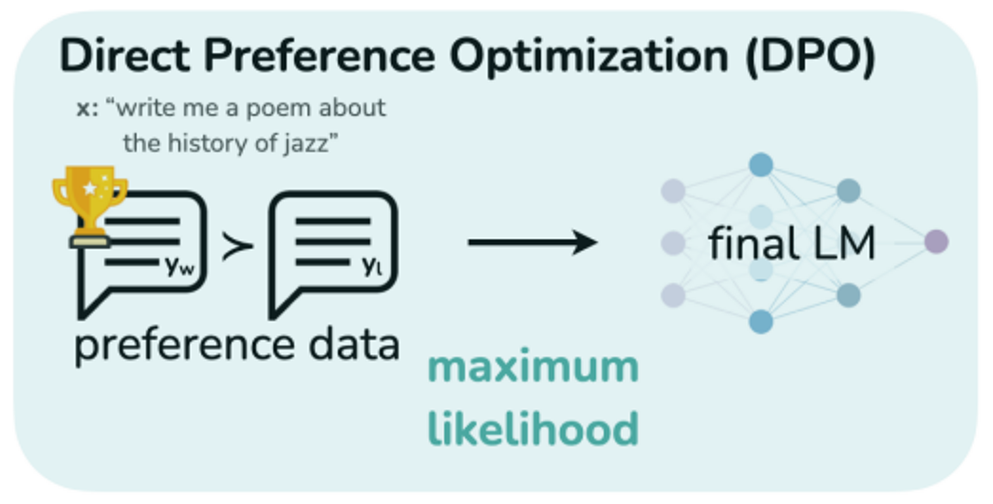
해당논문 이전까지는 human preference를 높이기위한 방법으로 강화학습을 적용했을때 가장 성공적인 결과가 나왔음\+) RM의 경우 본인이 직접 뭔가 작성하는 것보다 남들이 작성해놓은 것을 보고 평가하는 것이 더 일관성있는 어노테이션이 가능 → 이 rlhf는 최
20.GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
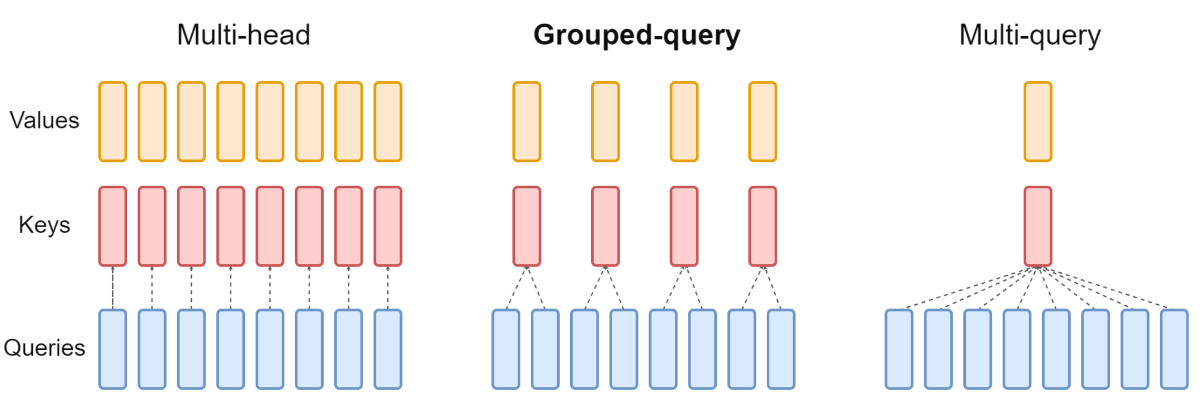
GQA(Grouped Query Attention)으로 라마2에서 쓰인 기술로 유명하다. GQA는 MHA(Multi Head Attention)과 MQA(Multi-Query Attention)의 장점을 결합한 기술로, 추론 속도를 빠르게 하면서 성능을 유지할 수 있다
21.NEFTUNE: NOISY EMBEDDINGS IMPROVE INSTRUCTION FINETUNING

embedding vectors에 노이즈를 더해 학습을 시킬 때 일반 finetuning보다 큰 성능향상을 가져올 수 있다. 또한 RLHF학습을 통해 LLaMA-2-chat 모델에서도 효과적이다. neftune algorithm (매우 간단함)embedding vect
22.Multiscale Positive-Unlabeled Detection of AI-Generated Texts

짧은 문장들에 대해서는 인공지능이 분류하기 어려운 문제가 존재 -> 이를 해결하기 위해 MPU(Multiscale Positive-Unlabeles) 를 사용해서
23.RLAIF
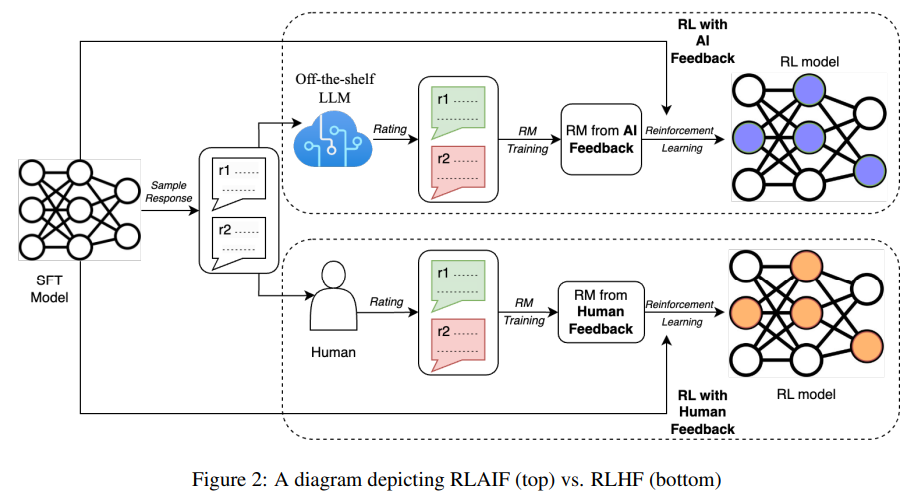
self-consistency : multi CoT를 이용해 나온 결과들은 결과들을 합산해서? 모아서 최종결과를 뽑아내는 방법RLHF VS RLAIFAI 피드백이 인간의 피드백을 받아서 학습한 것과 비슷한 성능이 나온다. RLAIF 는 인간수준의 성능을 뽑을 수 있으며
24.KCTS - Knowledge-Constrained Tree Search Decoding with Token-Level Hallucination Detection

문제 : hallucination 해결 -> decoding 방식의 변화가 hallucination 완화 가능해진다. 하지만 말을 할 때 지식을 확인하는 방법이 부재 MCTS를 이용 KCTS : discriminator guided decoding method - 지식
25.Enhancing Retrieval-Augmented Large Language Models with Iterative Retrieval-Generation Synergy

query rewriting Q→Retrieval → {{{ Retrieval Augmented Generation(RAG) → Q + RAG → Generation-Aumented Retrieval(GAR) }}} * T 번 반복 → RAG → output
26.TAKE A STEP BACK: EVOKING REASONING VIA ABSTRACTION IN LARGE LANGUAGE MODELS
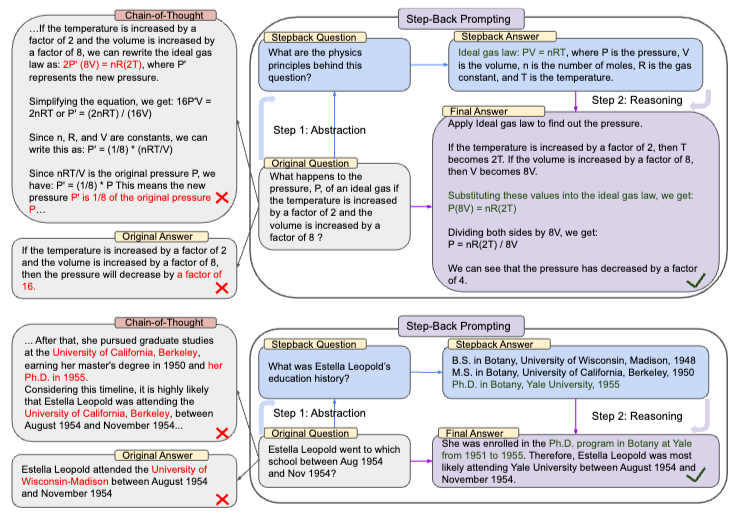
query rewriting Your task is to step back and paraphrase a question to a more generic step-back question <Passage from original RAG> <Pas
27.DayDreamer: World Models for Physical Robot Learning
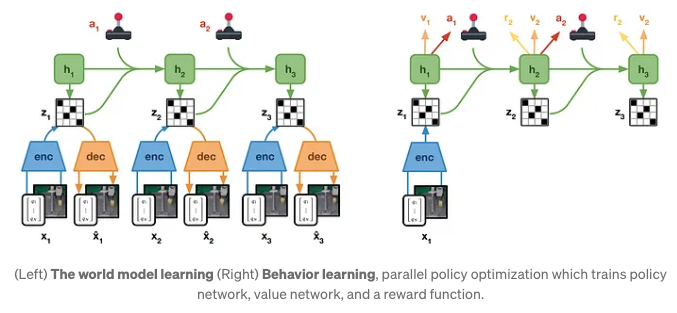
빠른속도로 학습이 가능, world model과 intricate challenges60분만에 로봇이 world에서 물리적으로 걸을 수 있게 되었다.straightforward
28.Decision Transformer: Reinforcement Learning via Sequence Modeling
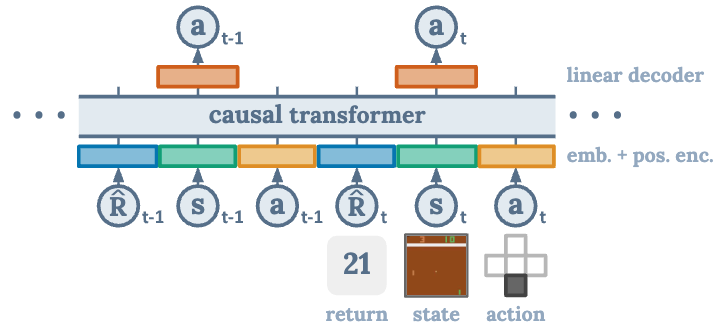
한줄요약: sequential 한 강화학습에서 casual transformer 모델을 적용함요약: 기존 강화학습에서 transformer 적용하기 힘들다는 점이 있었다. 이를 r, s, a 순서로 tranformer에 주입하고 동시에 들어간 timestep에 같은 P
29.Active Retrieval Augmented Generation
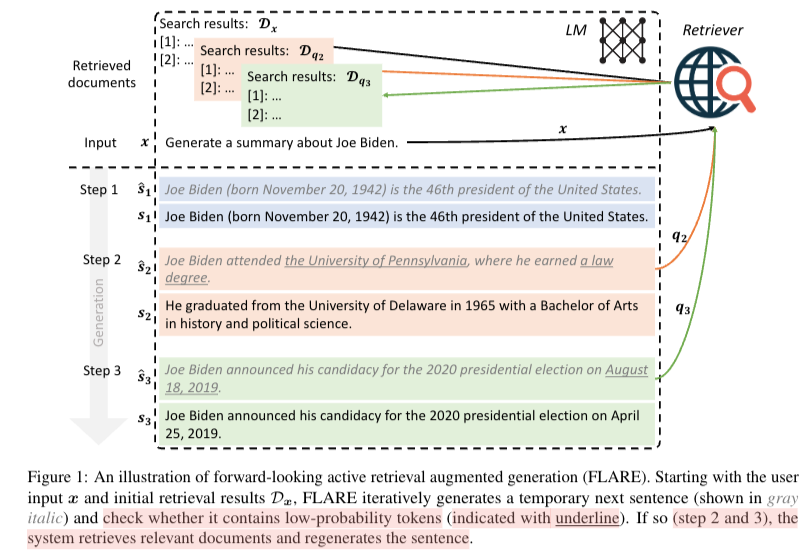
query rewriting 본 연구에서는 능동 검색 증강 생성에 대한 일반화된 관점, 생성 과정 전반에 걸쳐 언제, 무엇을 검색할지 적극적으로 결정하는 방법을 제공 $FLARE_{instruct}$, $FLARE_{direct}$query rewriting 본 연구에
30.Query2doc: Query Expansion with Large Language Models
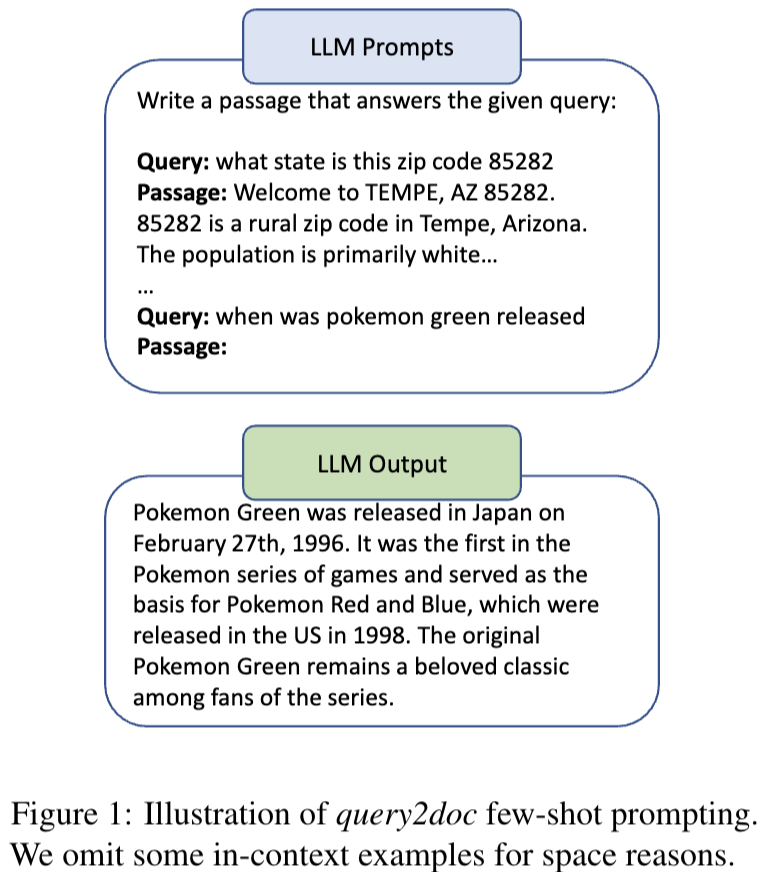
query + pesudo docs generated by LLM → retrieval 시스템에 넣어버린다.
31.Self-ask: Measuring and Narrowing the Compositionality Gap in Language Models
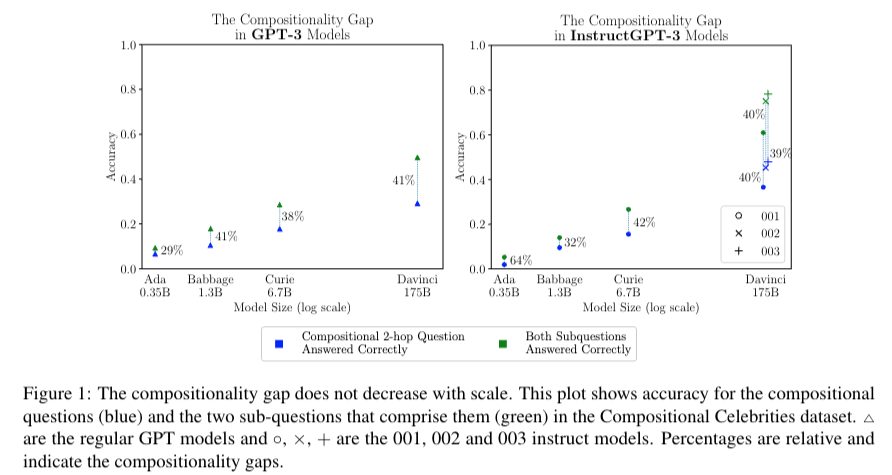
prompt를 이용한(follow up~) - Compositionality gap해결. 본 저자는 언어모델이 답변을 만들어내기 위한 sub problem으로
32.RaR: Rephrase and Respond: Let Large Language Models Ask Better Questions for Themselves

한줄요약: LLM 이 이해할 수 있는 말로 repharse and response
33.Self-Rewarding Language Models
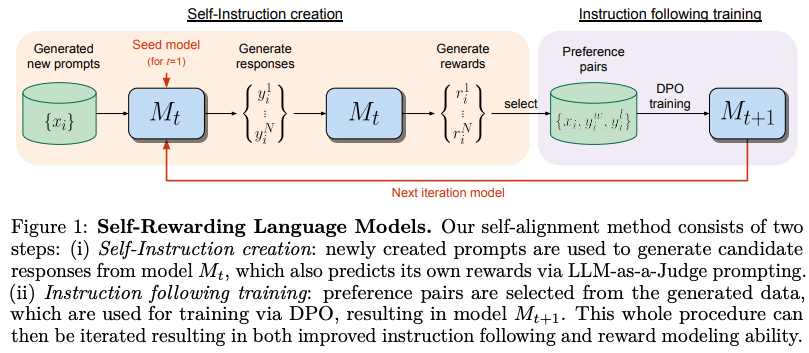
저자는 superhuman agents를 만드는 방식을 소개했다. 현 시점에서의 문제는 reward모델은 사람의 preference로 부터 오기때문에 bottlenecked by human 이라고 말한다. 이는 reward모델을 통해서 더 나은 LLM으로의 학습에 방해
34.Unifying Large Language Models and Knowledge Graphs: A Roadmap
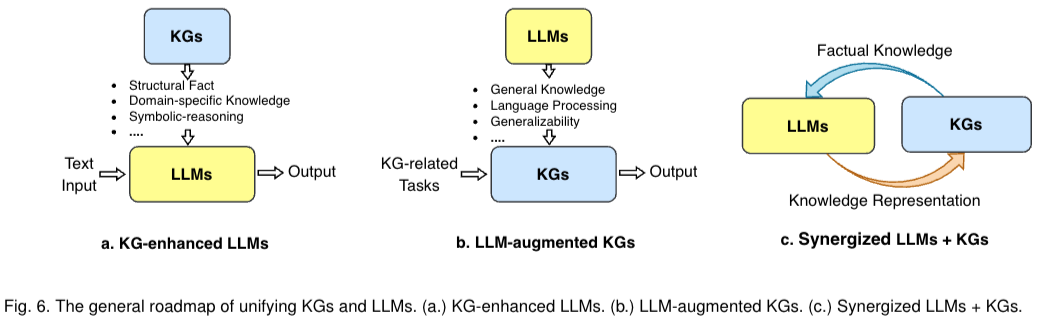
KG는 LLMs에 외부지식으로부터의 inference와 해석가능성을 강화시킬 수 있다. 하지만 KG는 만드는데 어려움이 존재하고, unseen knowledge에 대해서 새로운 facts를 생성하는것은 challenges로 남아있다. 본 논문의 저자는 LLMs과 KG의
35.MindMap: Knowledge Graph Prompting Sparks Graph of Thoughts in Large Language Models
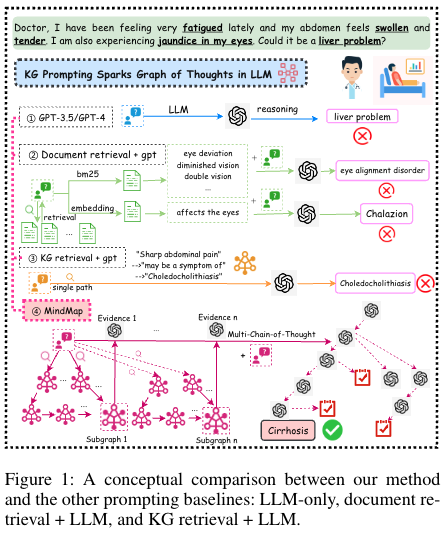
MindMap이라는 prompt + KG(Knowledge Graph)를 바탕으로 GPT3.5를 이용해 QA task에서 GPT4를 이길 수 있다. LLM의 문제: hallucination(모르는데 아는척 하면서 말하는 현상), Inflexibility(최신 정보 업데
36.Grape: Knowledge Graph Enhanced Passage Reader for Open-domain Question Answering
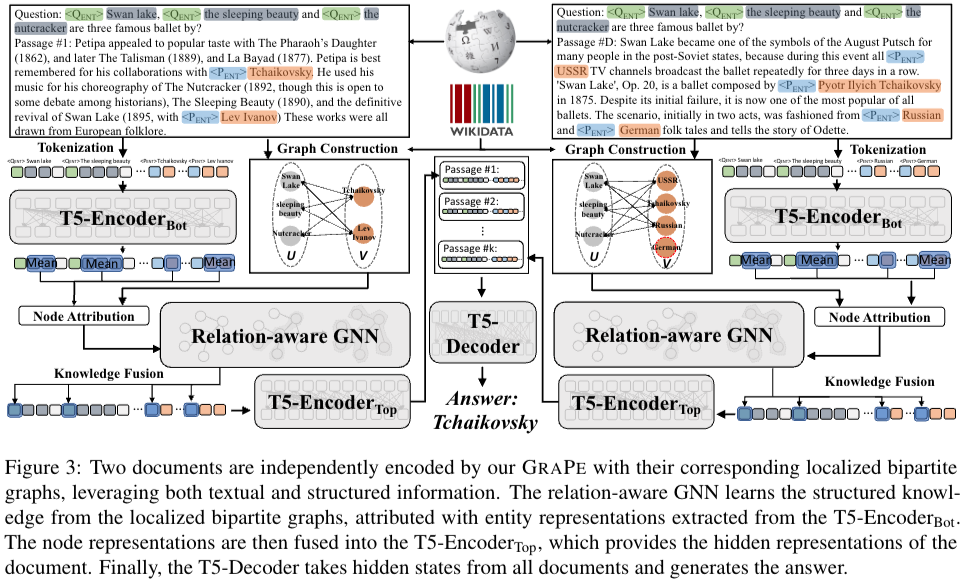
기존 그래프를 이용한 방식은 복잡한 관계(entities)를 캡처하는데 어려움이 존재하마. 이를 바탕으로 생성할 때 모순적인 facts를 생산한다. 본 논문은 ODQA(open domain question & answer) 작업에서 reader의 performance를
37.Learning to Tokenize for Generative Retrieval
Information retrieval pipline dpr을 기반으로 지속적으로 발전되고 있는 분야의 pipline 해당 테스크의 중점은 검색 속도와 검색 정확도가 중요한다. 대표적인 논문으로는 DPR에서 제안하는 학습 및 추론 과정의 전반을 사용하고 있다. i
38.multimodal- diffusion 논문 10개 정리
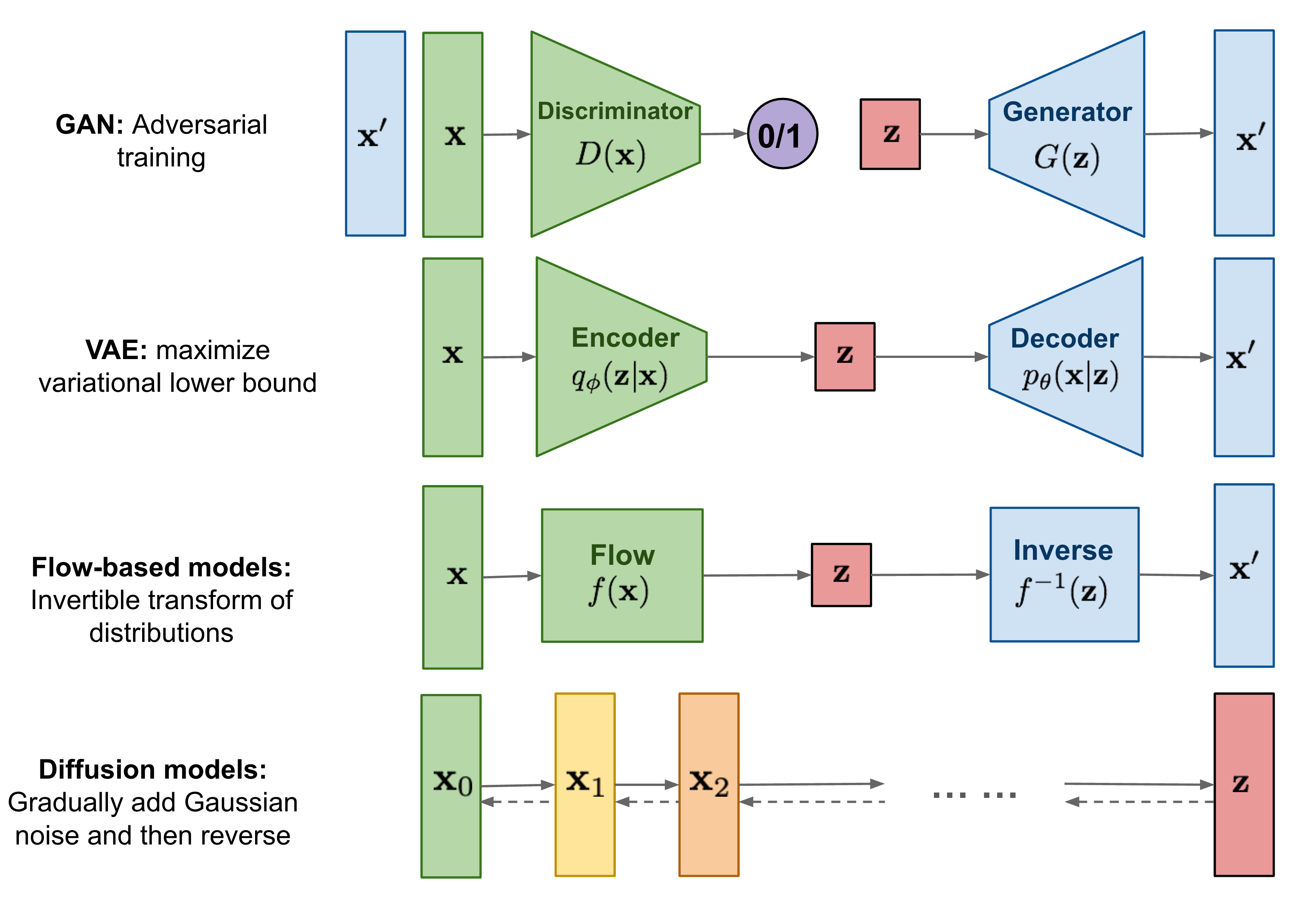
multimodal 정리, DDPM, AMD, GLIDE, Stable diffusion, classifier-Free diffusion, DALLE2, Imagen, GLIGEN
39.Adaptive Chameleon or Stubborn Sloth: REVEALING THE BEHAVIOR OF LARGE LANGUAGE MODELS IN KNOWLEDGE CONFLICTS
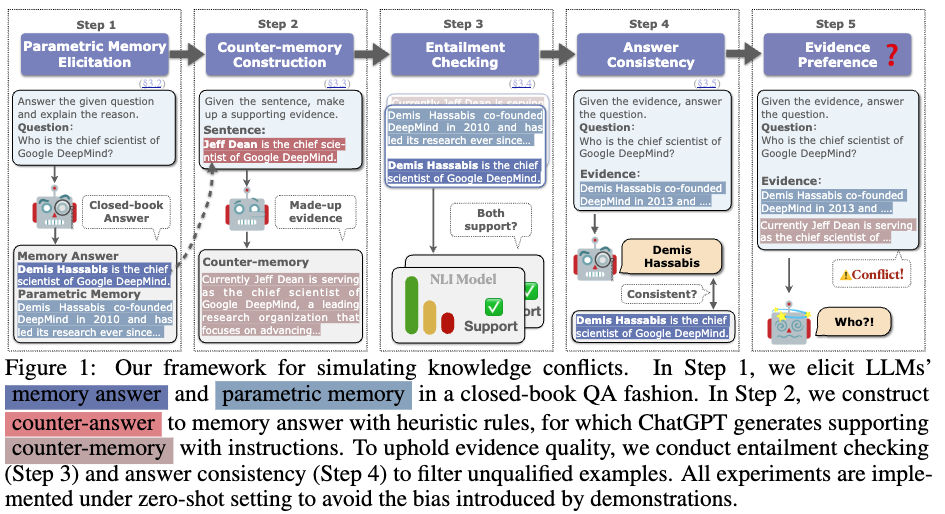
본 논문은 LLM이 외부지식을 수용할 때 내부에 저장된 지식과 충돌하거나 같은 경우에 어떻게 수용하는지에 대한 논문이다. 논문에서는 외부지식이 일관성 있고 확실한 말을 할때 내부지식과 상반되는관점을 가져도 받아드리게 된다고한다. 반면, 외부지식과 내부지식이 같을 때는
40.Unlocking Anticipatory Text Generation: A Constrained Approach for Large Language Models Decoding
본 논문은 decoding 을 통한 optimal result얻는 과정을 해결하고자 한다. 이를 위해 형식화 + future-constrained 방법을 통해 undesirable behavior 최소화 하려고 한다. 본 논문에서는 past generation에 집중하
41.QUERY-DEPENDENT PROMPT EVALUATION AND OPTIMIZATION WITH OFFLINE INVERSE RL

이전연구는 multi agent debate prompting 이라는 방식을 사용 → 경제적 문제등이 있음. 이를 해결하기위해 Prompt-OIRL (offline inverse reinforcement learning) 이라는 방식제안. offline inverse
42.LONGEMBED: EXTENDING EMBEDDING MODELS FOR LONG CONTEXT RETRIEVAL
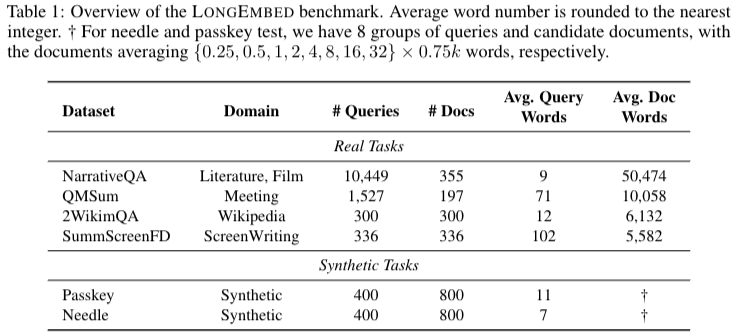
보간법(Interpolation): 주파수 파형 등을 부드럽게 변화시키는 방법Neural Tangent Kernel (NTK)는 딥러닝과 커널 메소드를 연결하는 개념. DNN 학습할 동안 발생하는 기울기 변화를 분석하는데 사용된다. NTK는 딥러닝 모델의 특정 초기화와
43.Mathematical Language Models: A Survey

최근 수학 도메인에서 언어모델을 활용한 성능이 매우 좋게 나오고 있다. 본 논문에서는 task와 methodologies를 중점적으로 mathematical LMs 에 대해서 설명한다. 특히 instruction learning, tool-based methods, f
44.Let's Verify Step by Step
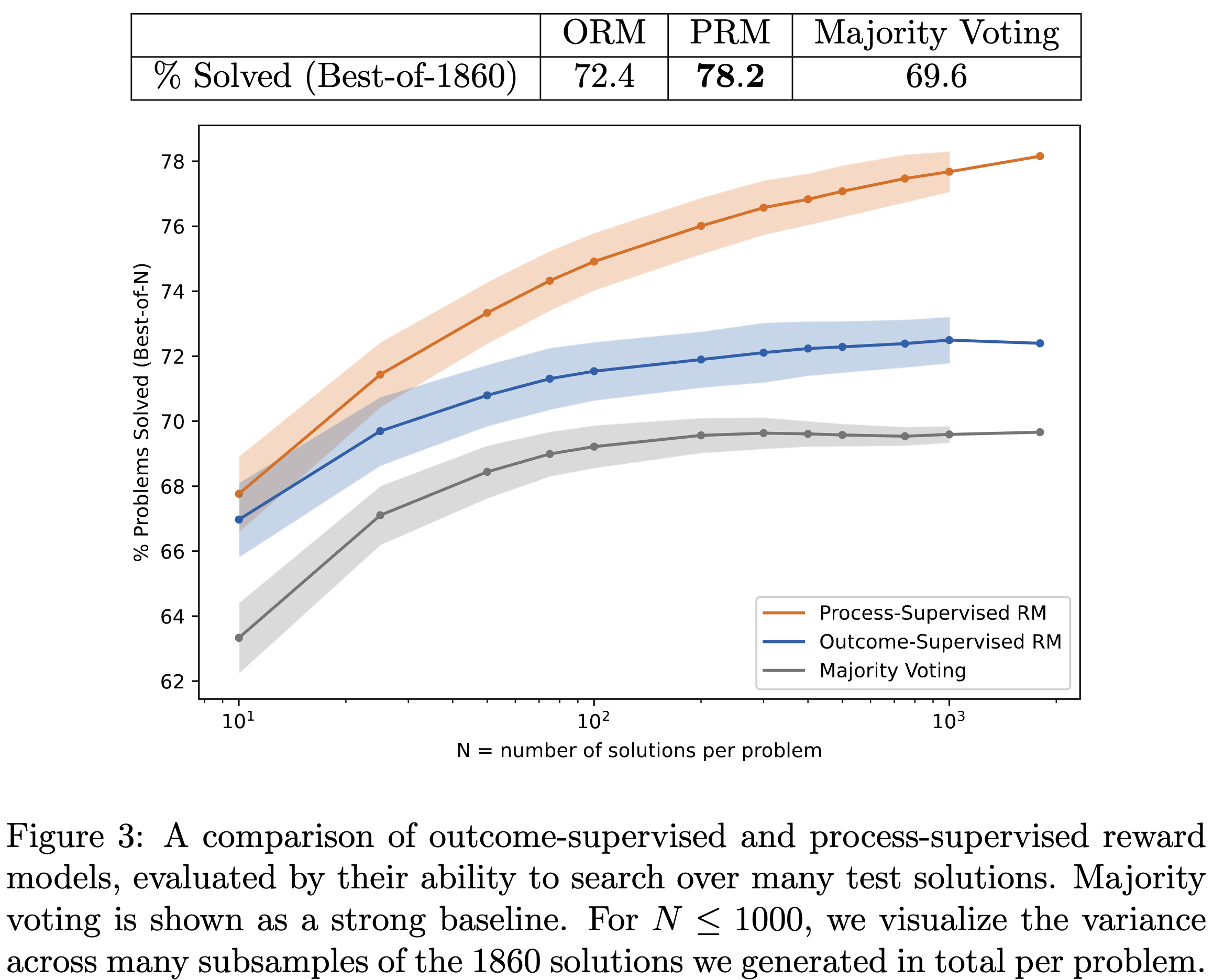
잘못된 내용이 있다면 댓글 부탁드립니다!! 감사합니다 :)Motivation: 사람이 수학문제를 풀 때 중간에 틀린 부분을 참고해서 학습하게되는데 모델을 answer부분만 학습을 하고있음. → 중간단계를 학습시키는 것이 성능에 더 효과적이지 않을까?Summary: 답변
45.Inference-Time Intervention: Eliciting Truthful Answers from a Language Model
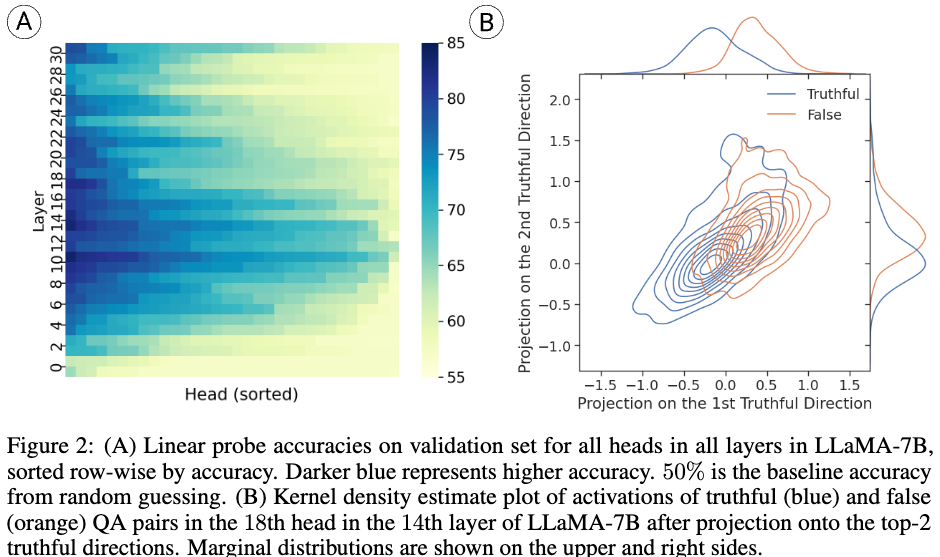
잘못된 내용이 있다면 댓글 부탁드립니다!! 감사합니다 :)Motivation: LLM이 겉으로는 거짓을 생성하더라도 모델 내부엔 사실에 대한 representation을 가질 수 있다.Summary: 모델 내부 파라미터에 activation 조정을 통해 Truthful
46.Local Interpretations for Explainable Natural Language Processing: A Survey
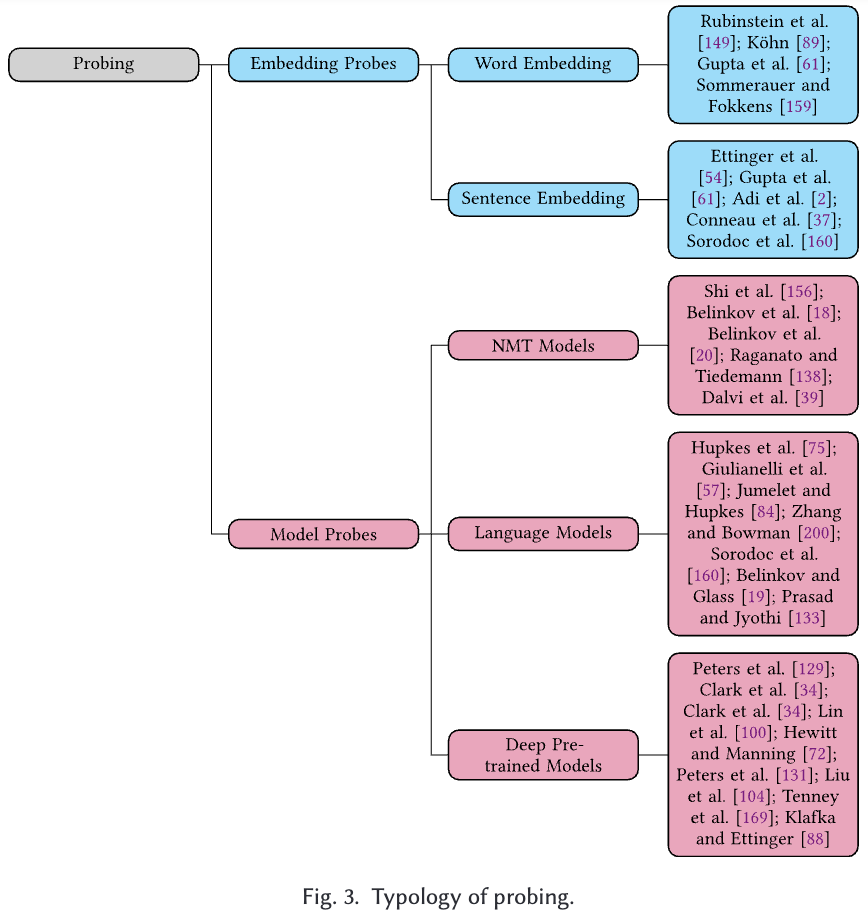
Paper link: https://dl.acm.org/doi/pdf/10.1145/3649450rationale selector: 텍스트 데이터에서 모델의 예측에 중요한 영향을 미치는 부분(단어나 구절)을 선택하는 모델의 부분 또는 알고리즘Gradient-b
47.Analyzing Feed-Forward Blocks in Transformers through the Lens of Attention Maps
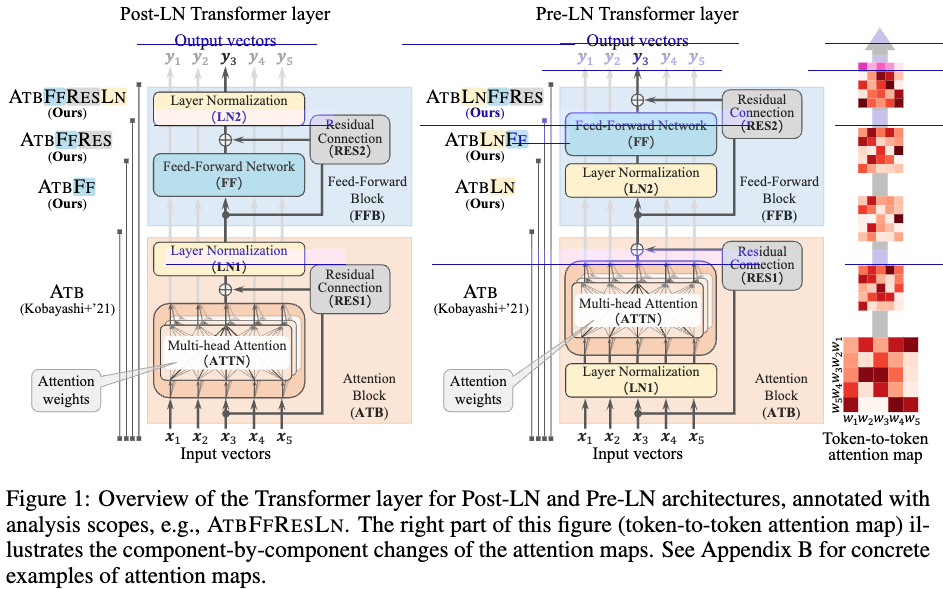
잘못된 내용이 있다면 댓글 부탁드립니다!! 감사합니다 :)Motivation: 기존 방식들은 FF 네트워크 까지 통합하지 않음. Summary: 전체 Layer를 이용해 input 과 output의 관계를 확인하는 방법Novelty: non-linear function
48.Sparse Autoencoders Find Highly Interpretable Features in Language Models
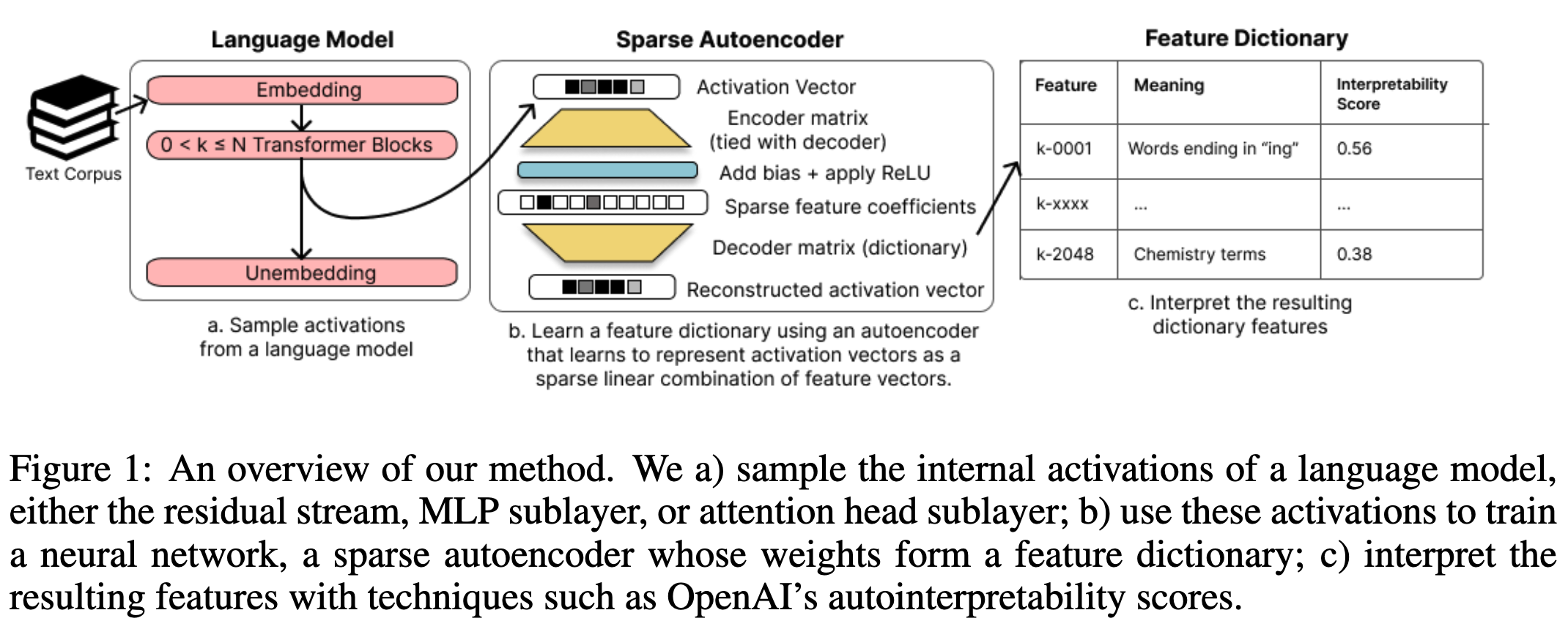
polysemanticity 는 모델 내부 지식을 파악하는데 어려움을 준다. 이런 polysemanticity 가 발생한 원인으로 보는 가설인 superposition은 하나의 neural network가 여러 표현을 overcomplete하게 학습되어 발생된 것이라는
49.Scaling and evaluating sparse autoencoders
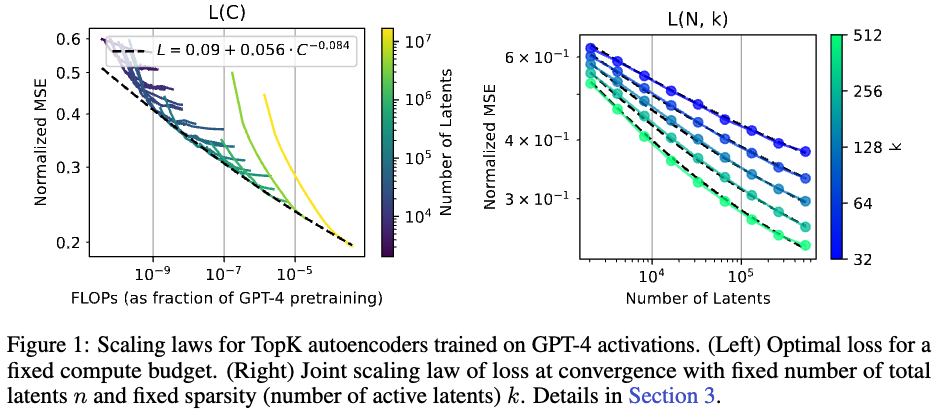
Keyword: dictionary learning, sparse autoencoderNovelty: sparse autoencoder scaling law 를 만들어냄.Summary: 최적 학습 lr 및 토큰 수, 그리고 새로운 topk sparse autoencod
50.Identifying Functionally Important Features with End-to-End Sparse Dictionary Learning
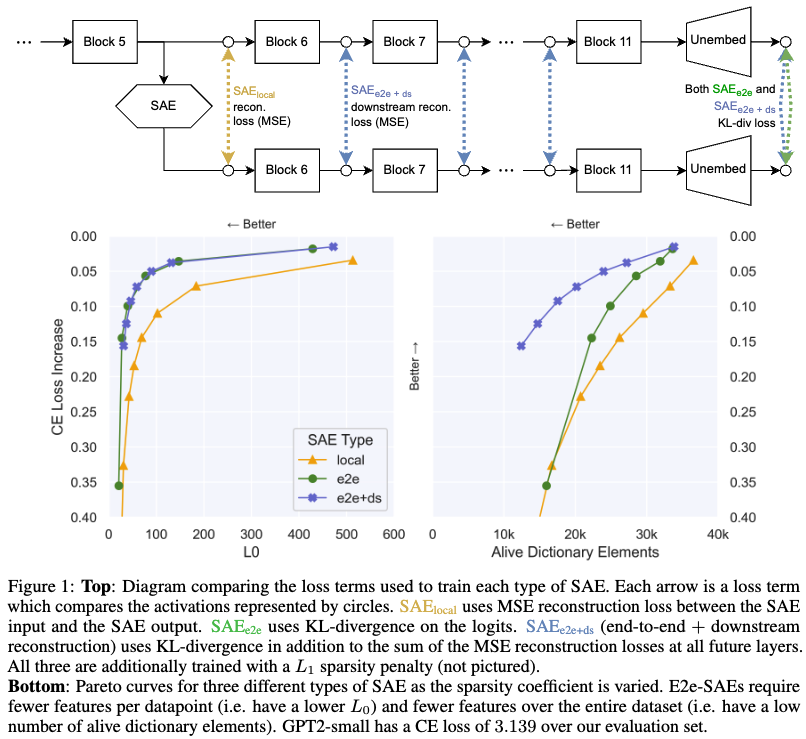
Keyword: dictionary learning, sparse autoencoderNovelty: $SAE{e2e}$방식과 $SAE{e2e + ds}$ 방식 제안Summary: 모델의 성능 유지와 feature 를 더 잘 찾을 수 있는 sparse autoencod
51.Towards Automated Circuit Discovery for Mechanistic Interpretability
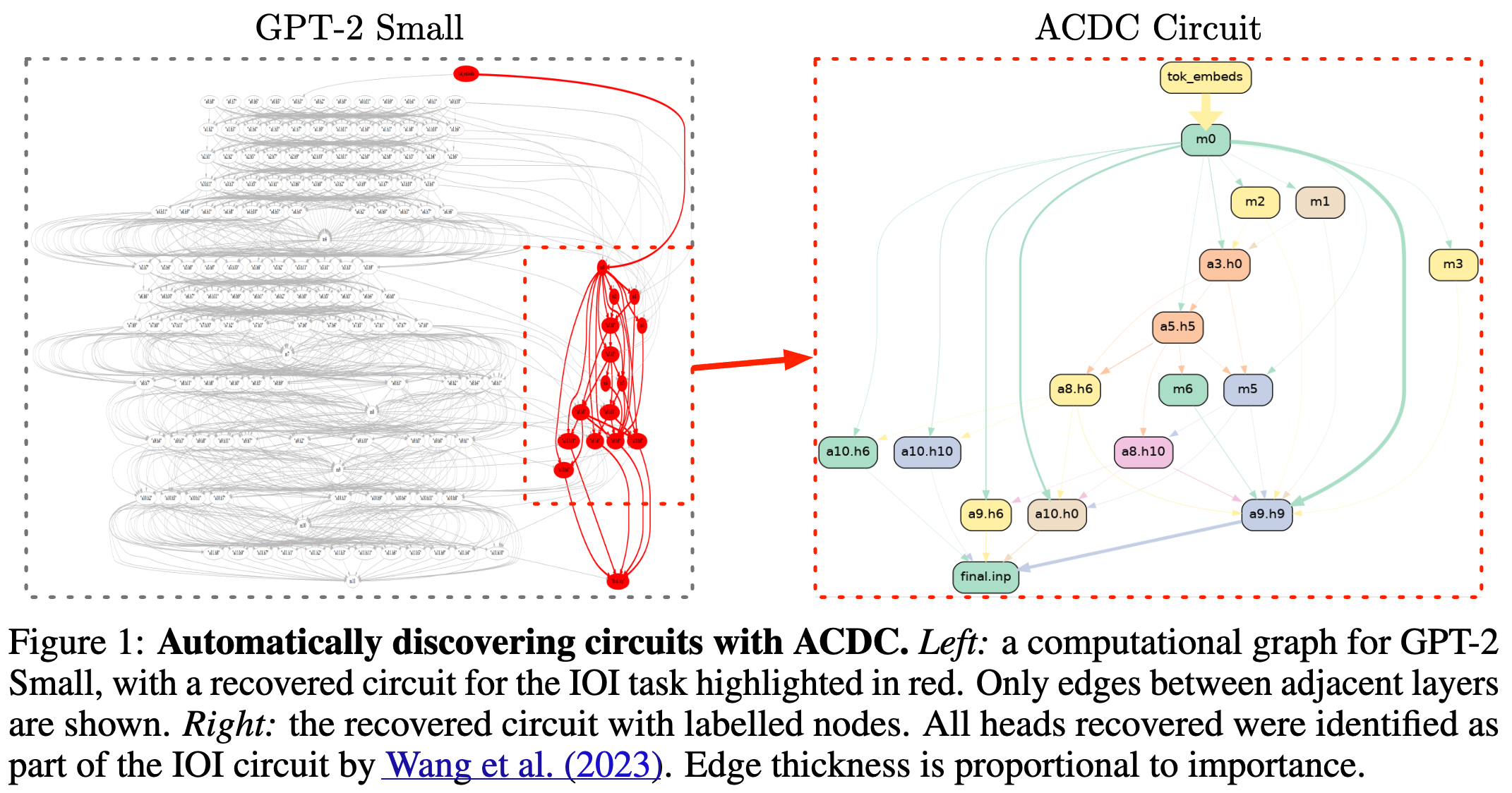
Keyword : ACDC, circuits, automatic interpretability, Novelty : 자동화된 모델 circuit만드는 방법 제안, Summary : 다음 노드에 활성화 영향을 주는 부분만 남기고 나머지 부분을 잘라내는 방법으로
52.Controlling Large Language Model Agents with Entropic Activation Steering
Keyword: confidence, steering, EASTNovelty: Confidence 를 줄이고자하는 노력Summary: EAST라는 방식을 통해 LLM이 과하게 자신을 믿는 경향인 overconfidence를 극복하고자함Paper Motivation: L
53.Representation engineering: A top-down approach to ai transparency
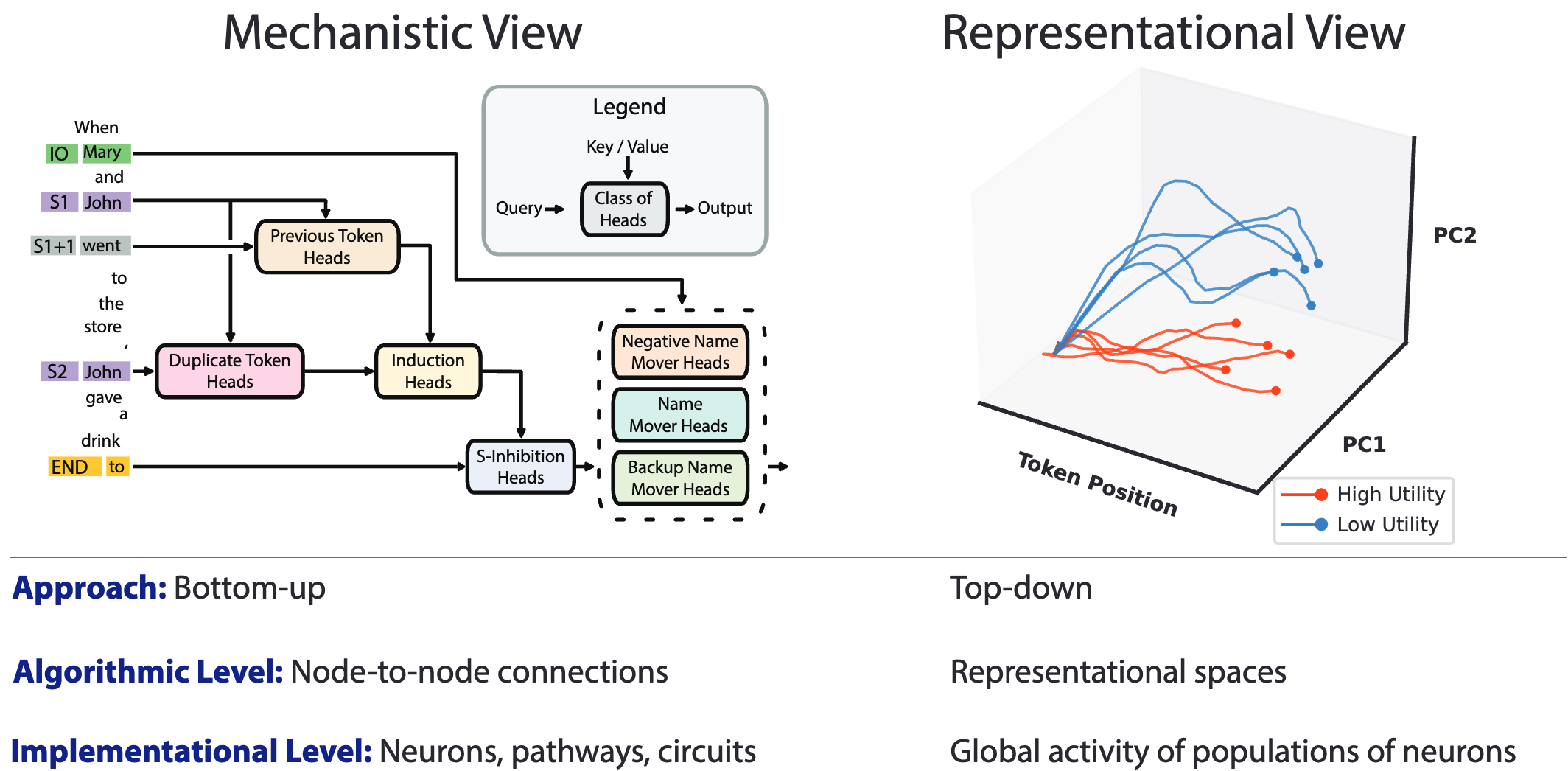
Summary: representation engineering (RepE): AI 시스템의 투명성을 높이기 위한 새로운 접근 방식. 해당 방법은 circuits 이나 neuron 단위가 아닌 representation에 집중representation engineer
54.Dragin: Dynamic retrieval augmented generation based on the real-time information needs of large language models
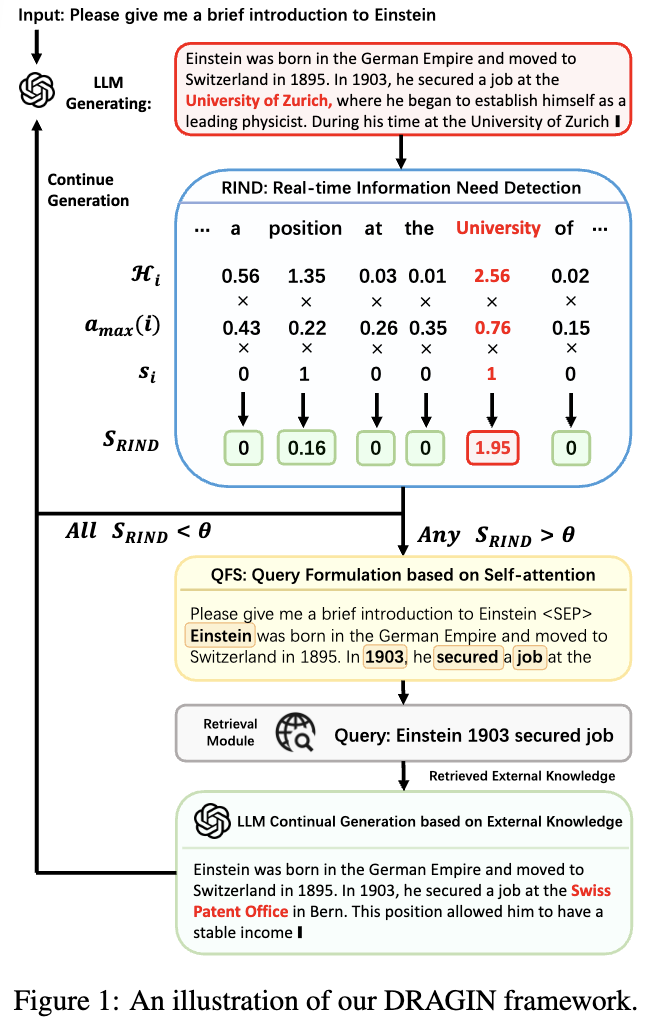
ACL 2024 mainDynamic retrieval augmented generation 이 언제 그리고 어떻게 retrieve 할지 선택하는 것이다. 저자는 아래의 2개가 해당 분야의 key elements 라고 말함.retrieval module 을 언제 act
55.Fine-Grained Human Feedback Gives Better Rewards for Language Model Training

Summary: 여러 관점의 reward모델을 만드는 것이 단순 pairwise reward model 보다 성능이 더 좋다.Novelty: Fine-Grained reward modelingLM은 toxic or irrelevant output을 생성하는 경향이 존재
56.RLHF-V: Towards Trustworthy MLLMs via Behavior Alignment from Fine-grained Correctional Human Feedback
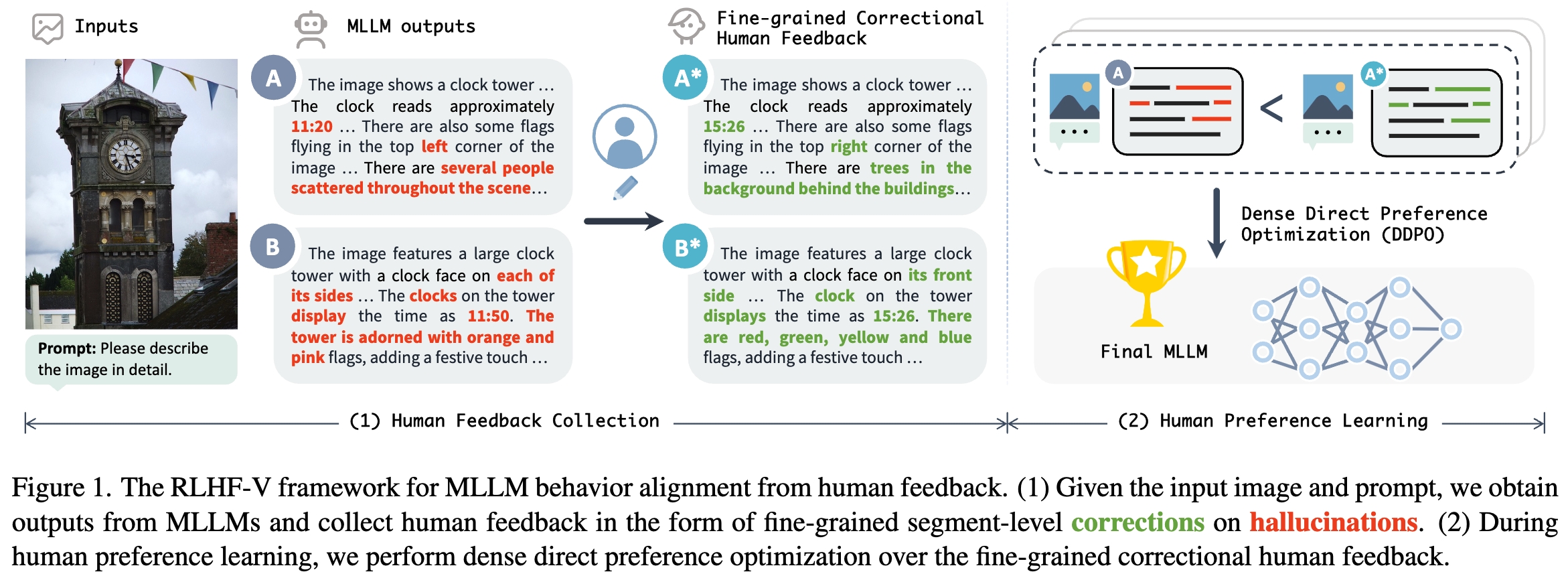
Multimodal 에 fine-grained correctional human feedback을 통해 MLLM의 신뢰성을 향상시키고자 한다. RLHF-V 는 1.4K annotated data를 통해 34.8% hallucination을 줄일 수 있었고 10K 데이터
57.Improving Visual Grounding by Encouraging Consistent Gradient-based Explanations

해당 논문은 VLM에서 gradient 텍스트기반의 attention map을 사용한 학습방법과 attention mask consistency objective function을 소개한다. 이는 사람이 지정한 이미지의 특정 영역과 더 잘 맞도록 학습하는 방식이다. 이
58.Visual Instruction Tuning

AI의 핵심 목표 중 하나는 인간의 의도에 맞춰 멀티모달 비전 및 언어 명령을 효과적으로 따를 수 있는 범용적인 어시스턴트를 개발하는 것범용 비전 어시스턴트를 구축하기 위해 instruction-tuning을 언어-이미지 멀티모달 공간으로 확장하려는 첫 번째 시도인 v
59.MuRAG: Multimodal Retrieval-Augmented Generator for Open Question Answering over Images and Text
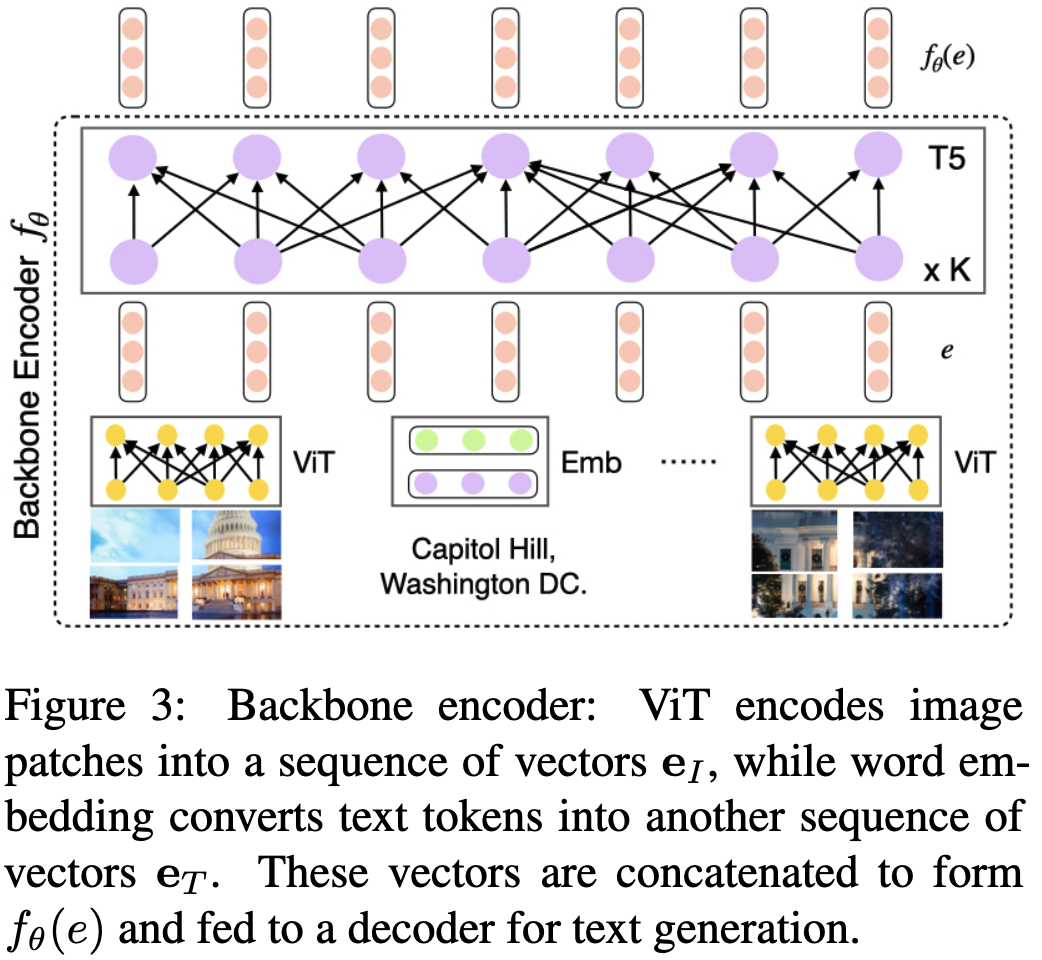
본 논문은 retrieval-augmented generation이 text 정보를 바탕으로 활발하게 연구되고 있음을 문제점으로 말한다. 실제적인 정보는 mulitmodal 정보가 존재하기 때문에 이를 사용하는 것으로 image와 text를 함께사용하는 MuRAG 방식
60.PPLLaVA: Varied Video Sequence Understanding With Prompt Guidance
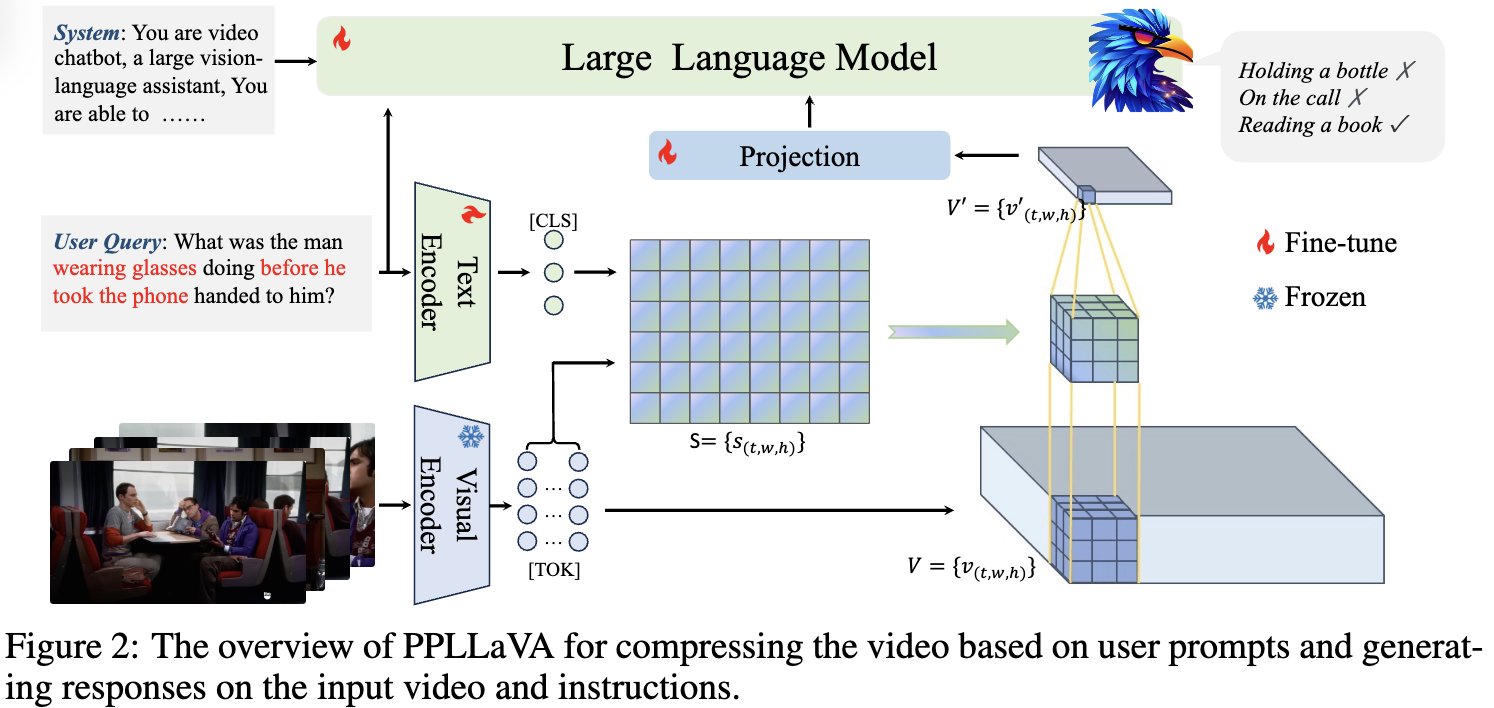
과거 video-based LLM 연구는 video 길이에 대해 완전한 이해를 바탕으로한 통합된 모델을 만드는데 challenge가 존재한다. 해당 논문은 비디오의 풍부한 content에 따른 이슈를 해결하고자한다. 방법으로 저자들은 pooling전략을 사용해 toke
61.IM-RAG: Multi-Round Retrieval-Augmented Generation Through Learning Inner Monologues
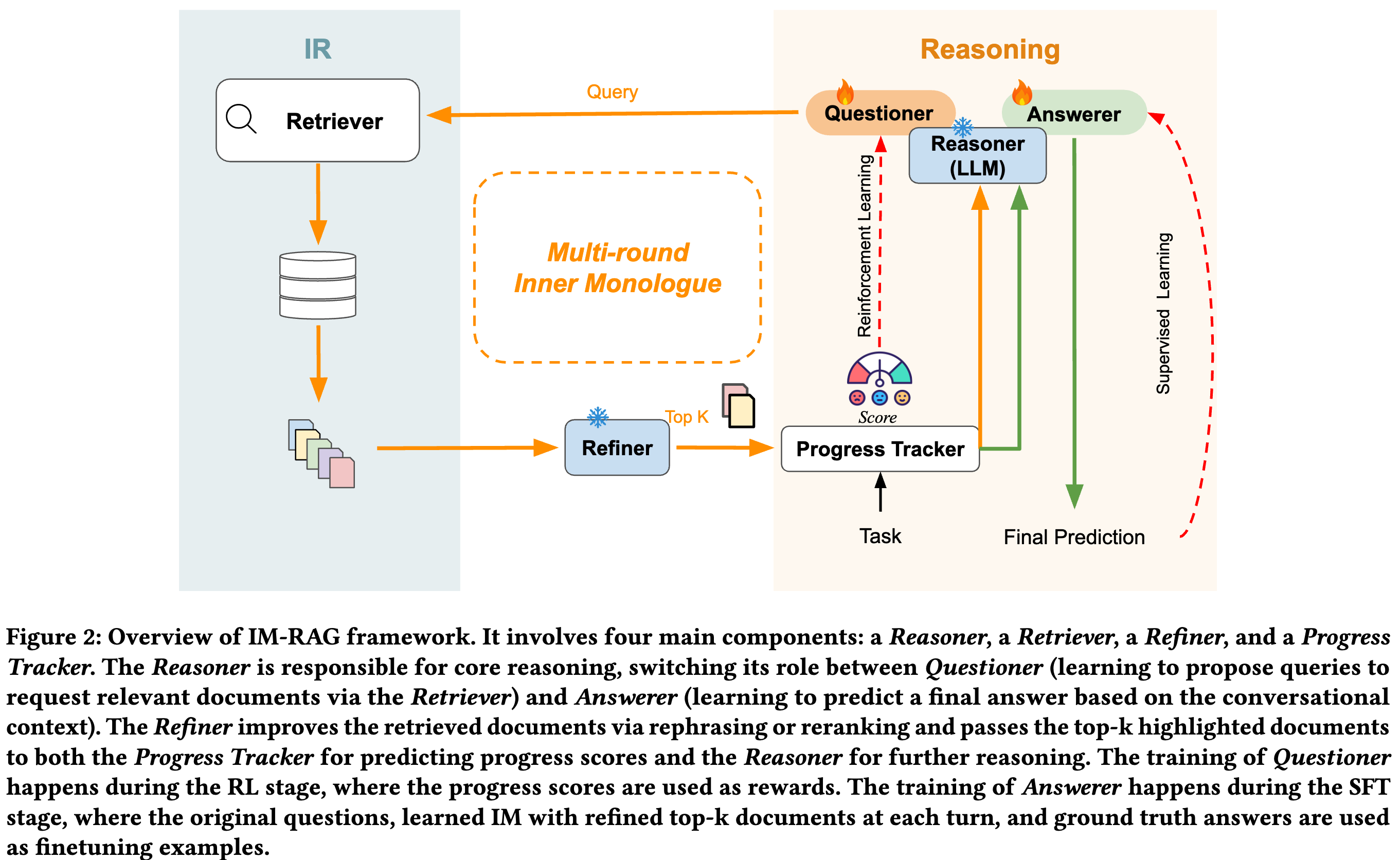
용어: Jointly Train: retriever과 LLM 통합적으로 학습. 단일 학습과정에 동시에 학습되는 특징. 학습 데이터가 많은 양을 필요로한다는 단점이 존재. IR 시스템이나 LLM 변경시 전체 모델을 다시 학습시켜야함. 장점은 최적화되면 성능이 매우 높음L
62.Retrieval Head Mechanistically Explains Long-Context Factuality
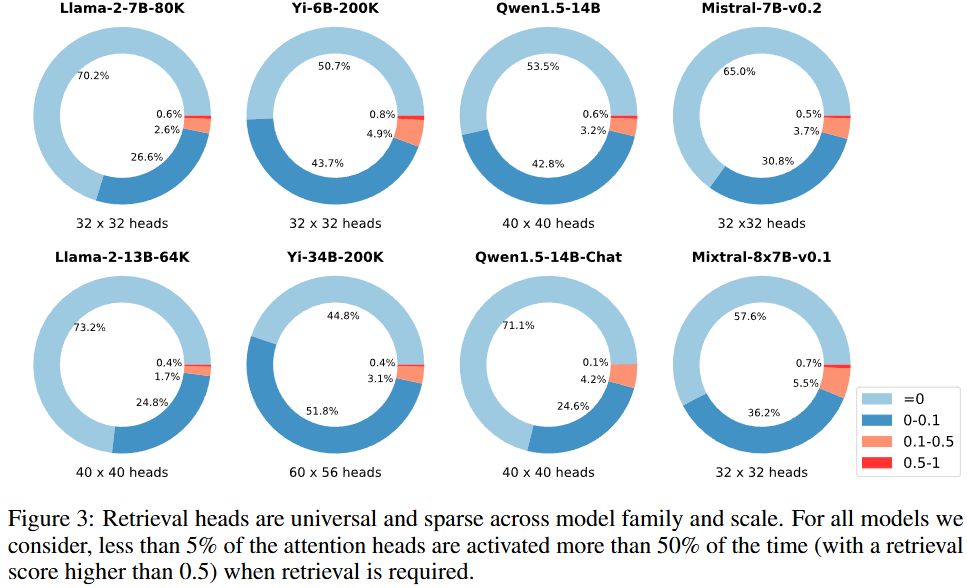
Motivation: transformer-based LM이 relevant information을 longcontext에서 어떻게 가져오는 지 보기위한 실험을 진행함. retrieval head: the heads that redirect information fro
63.Attention Heads of Large Language Models: A Survey
사람의 생각 process에 영감을 받은 4개의 stage framework를 소개한다: Knowledge Recalling, In-Context Identification, Latent Reasoning, and Expression Preparation. attent