- GPT1 → BERT → GPT2 → XLNET(transformer-xl 과 동일저자)
- AE 모델 장점과 AR모델 장점을 합한 AE모델
기본 지식
Query(쿼리): 쿼리는 주목하고자 하는 단어로, 다른 단어들과의 관계를 파악하기 위한 대상
Key(키): 키는 입력 문장에서 각 단어가 쿼리와 얼마나 관련이 있는지를 결정하는 요소
Value(값): 값은 관련성이 높은 단어들의 정보를 실제로 반영하기 위한 요소
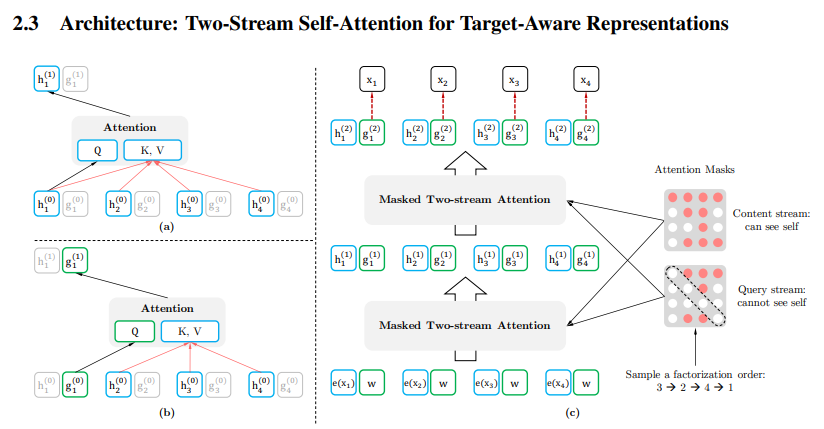
AR 모델 - LM objective
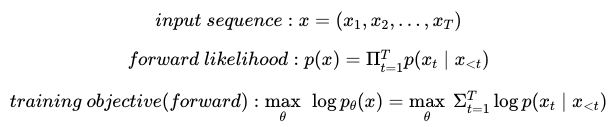
AE 모델

Proposed Method
- 새로운 Objective (Permutation Language Modeling) → AR, AE 장점은 살리고 단점을 줄이는 방식
- 이를 반영하기위한 Target-Aware Representation

지금 까지의 방법으로는 각 토큰에 위치정보를 주어서 다음 타겟을 예측하게 하면 문제가 없었지만 순열을 사용하는 경우 위의 예시처럼 받은 토큰을 바탕으로 서로다른 next token prediction해야하는 상황이 발생 → target 토큰의 위치정보만 받아 예측을 진행하자 ( 아이디어 )
- 위 내용과 Transformer 구조를 동시에 이용하기 위한 새로운 Two-stream Self-Attention 구조
t 시점에서 target position 의 token
: set of all possible permutation of the length -T
Quary stream (Q, target position aware, next token distribution):
can’t see self (context info , , …, , position info : z = t only ⇒
Context stream (K, V): can see self ( context info, , …, ), position info : ⇒
위의 식이 (b)의 과정 - Quary Stream
아래의 식이 (a)의 과정 - Context Stream
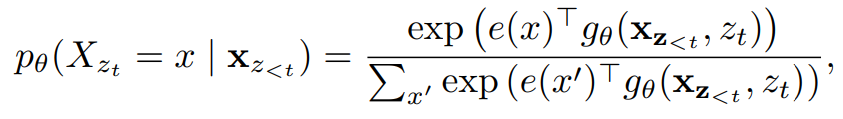
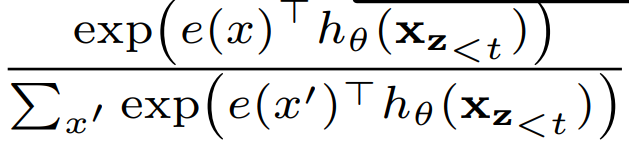
이전시점의 token 정보와 현재시점의 위치정보를 활용하기 위해서 2개의 수식을 사용함
결과

