CoLA dataset 예시
- Sentence: The cat is on the mat.
Acceptability: 1 (올바른 문장) - Sentence: She is going to the store.
Acceptability: 1 (올바른 문장) - Sentence: John and Mary eating ice cream.
Acceptability: 0 (잘못된 문장)
STS-B dataset 예시
- Sentence 1: A man is playing the guitar.
Sentence 2: A person is strumming a guitar.
Similarity Score: 4.5 - Sentence 1: The sun is shining brightly in the sky.
Sentence 2: The weather is sunny.
Similarity Score: 3.8 - Sentence 1: Two dogs are playing in the park.
Sentence 2: The canines are having fun at the park.
Similarity Score: 4.2
Natural Language Inference(MNLI, SNLI, XNLI, aNLI, SciTail, Quora, RTE, QNLI) : 자연어 추론 ex) SNLI
- 전제 (Premise): A man inspects the uniform of a figure in some East Asian country.
가설 (Hypothesis): The man is sleeping. → contradiction - 전제: A young girl in a pink hat is feeding a white pony.
가설: The girl is outside. → entailment - 전제: A soccer game with multiple males playing.
가설: Some men are playing a sport. → neutral
QNLI dataset 예시
- Question: Is it raining outside?
Sentence: Yes, it's pouring.
Label: Entailment - Question: What time does the movie start?
Sentence: The movie starts at 7 PM.
Label: Entailment - Question: Did they win the game?
Sentence: No, they lost by a narrow margin.
Label: Contradiction - Question: Are you goin

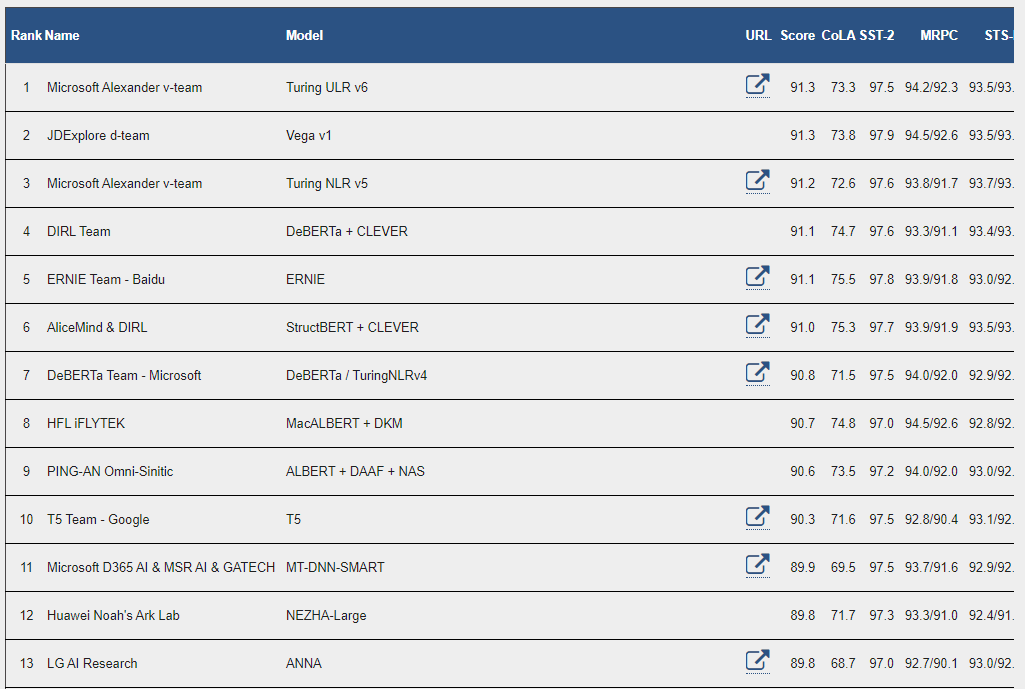
현재 23.6.24 일기준 GLUE benchmark 11위 기록
초록
NLP에서는 ELMO, GPT, BERT 같은 pre-training기법과 Multi Task Learning(MLT)두가지 방법있다.
pre-training : unsupervised dataset 활용해 모델 학습
MTL : 여러가지 Supervised Task를 1개의 모델을 통해 학습
MLT를 이용하면 하나의 task로 fine-tuning하는 것보다 많은 데이터셋으로 학습하는 효과가 있으며, task상호간에 이득을 주게끔 학습하는 것. MTL 제안한 사람은 스케이팅을 배운사람이 상대적으로 안배운사람보다 스키를 더 잘 타지 않겠다는 비유를 들어 설명하였다.
여러 task 동시에 학습하여 regularization에서 효과적, 특정 task에 대한 overfitting 막아준다.
→ MT-DNN은 기존 pre-trianing기법에 MTL을 합치는 것이 상호 보완적 효과를 가져올 수 있겠다는 생각에서 출발해 → 성능을 개선시킨 모델
Main Idea
BERT Encoder와 다양한 NLU테스크들의 multi-task learning을 동시에 적용해 BERT를 능가하는 Multi-Task Deep Neural Network(MT-DNN)제시
특정 task에 fine-tuning에서 단순 Linear layer 대신 다른 구조(Stochastic Answer Network)이용해 향상된 성능→ MT-DNN = BERT + SAN
Tasks
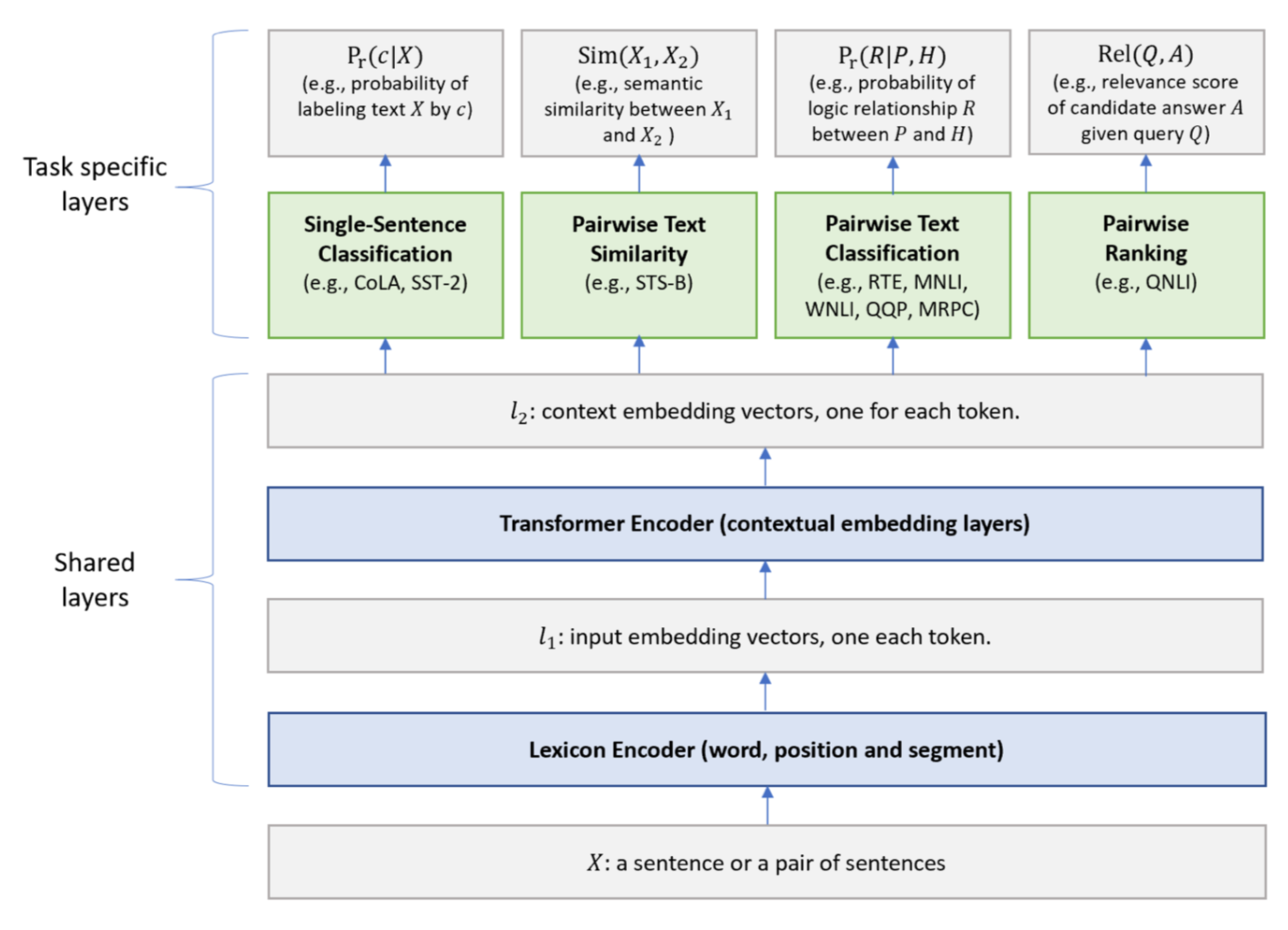
The Proposed MT-DNN Model
: Lexicon Encoder word, segment, positional embedding
: BERT pretraining model
top layers - task specific outputs
-
Single-Sentence Classification : , 는 task specific parameter matrix, c : label, X : input,
-
Pairwise Test Similarity : , BERT의 [CLS] token 기준으로 로 나눠준 후 유사도 점수를 구한다.
-
Pairwise Text Classification - 문장 간의 의미 관계 등을 분류 SAN network 사용 → 여러번의 예측을 통한 결과 예측 방식(?) 이를 위해 RNN으로 time step 마다 classification결과를 예측하고 해당 결과를 조합해 사용하는것이 SAN 네트워크 아래 그림에서
는 premise(전제)문장 Token vector, 는 Hypothesis 문장 Token vector
-
Pairwise Ranking
아래 모델은 MRC논문에 나오는 SAN 네트워크입니다. 해당 모델에서 attention을 사용해서 모델을 표현했을 때 SAN 의 발전된 모델이며 해당 아키텍처는 NLI task에서 강점을 보입니다.
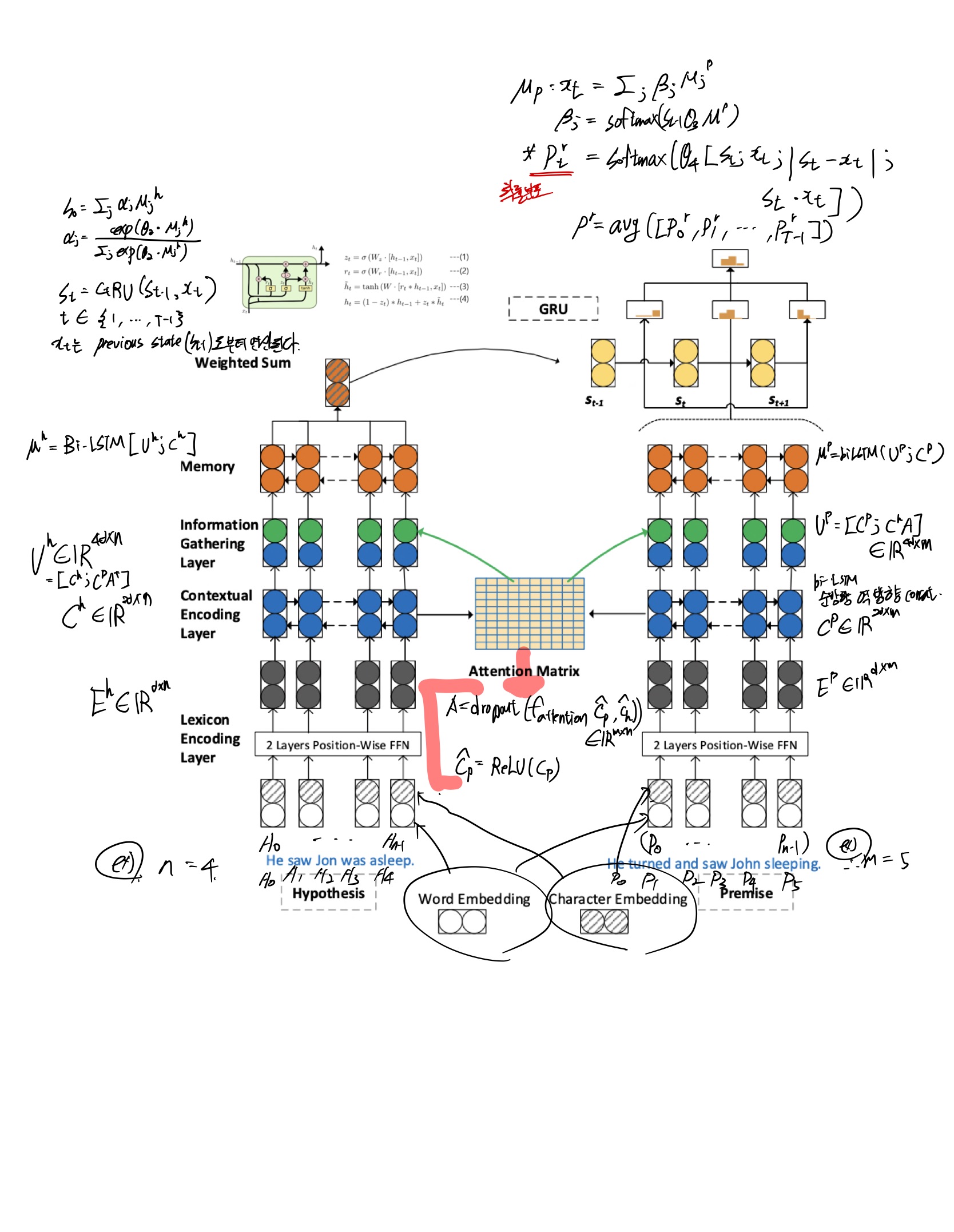
마지막 에서 입력단어 단순 concat, 문장 간 거리, 문장간 유사도 구하여 모두 concat해준 후 마지막에 평균을 내어서 최종 아웃풋을 내어 결과 예측한다.
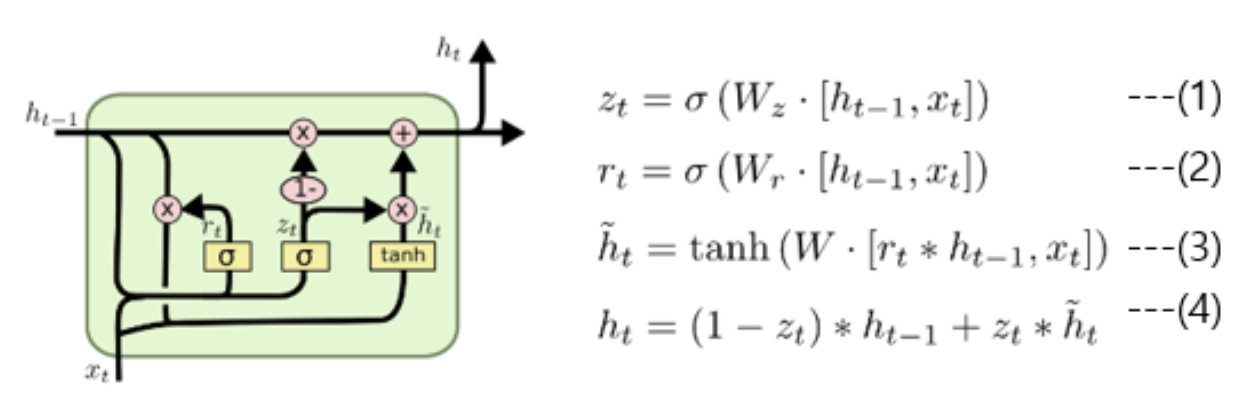
3.1 The training Procedure
lexicon 과 Transformer Encoder 의 경우 BERT 학습과정과 같다고 생각하면 된다.
MLM, NSP 사용해서 pretraining
multi-task learning stage : minibatch → SGD
dataset : 9 GLUE task (each epoch)
- Single-Sentence Classification -CE LOSS 사용
- Pairwise Test Similarity - MSE LOSS 사용
- Pairwise Text Classification - SAN network에 avg 와 정답 차이를 loss로 사용
- Pairwise Ranking - negative log likelihood
4. Experiments
→ MTL 방식의 효율성을 입증했다고 주장 (finetuning 사용 x)
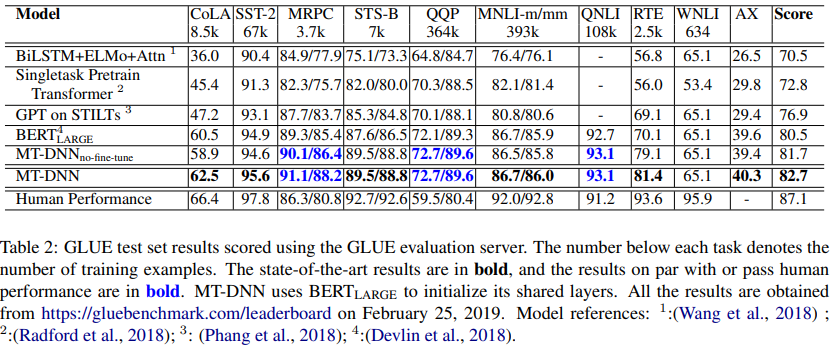
cola : single sentence classification, sts-b : text similarity regression, MRPC, QQP, MVLI-m/mm, RTE, WNLI : Pairwise Text Classification, QNLI : Relevance Ranking
dataset : GLUE, CNLI, SciTail 사용
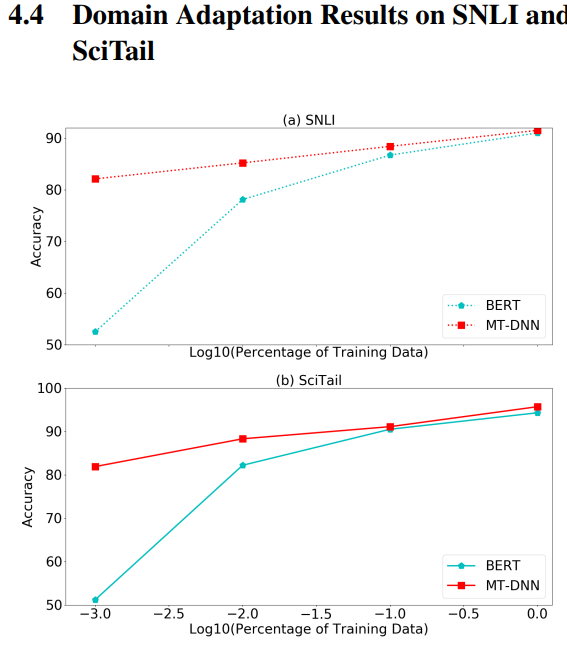
아래 실험은 도메인 적응성 실험인데, BERT의 경우 finetuning에서 따로 모델을 붙여서 실험하지 않으니까 상대적으로 MT-DNN이 적응이 빠르다는 실험 ( 논문에서는 언급하지 않았지만 SNLI 와 SciTail이 SAN 네트워크 상단부분이 추가되어 도메인 적응도가 높게 나온다고 볼 수 있음) → 데이터가 적을 때 더 높은성능을 낸다. ( MPRC, RTE)
code :
mt-dnn/module/san_model.py
SanLayer : rnn 유형, 양방향성, number of hidden layer,
SanEncoder : encoding 해주는 부분, ModuleList 를 통해 레이어 연장
SanPooler : attention 및 dropout Wrapper 클래스 사용 → 어텐션 연산을 거친 후 밀집 레이어와 활성화 함수를 거친 결과로, 원래의 텐서를 변환하여 추상화된 표현을 얻는 용도
해당 레이어 통과 시 torch.Size([1, 8, 768]) → torch.Size([1, 768])
class SanPooler(nn.Module):
def __init__(self, hidden_size, dropout_p):
super().__init__()
my_dropout = DropoutWrapper(dropout_p, False)
self.self_att = SelfAttnWrapper(hidden_size, dropout=my_dropout)
self.dense = nn.Linear(hidden_size, hidden_size)
self.activation = nn.Tanh()
def forward(self, hidden_states, attention_mask):
"""
Arguments:
hidden_states {FloatTensor} -- shape (batch, seq_len, hidden_size)
attention_mask {ByteTensor} -- 1 indicates padded token
"""
first_token_tensor = self.self_att(hidden_states, attention_mask)
pooled_output = self.dense(first_token_tensor)
pooled_output = self.activation(pooled_output)
return pooled_output
linear = nn.Linear(768,1)
# SelfAttnWrapper
x = sequence_output
x_flat = x.contiguous().view(-1,x.size(-1))
print(x_flat.shape)
scores = linear(x_flat).view(x.size(0), x.size(1))
print(scores.shape)
scores.data.masked_fill_(attn_mask.data, -float('inf'))
print(scores)
alpha = F.softmax(scores,1)
print(alpha)
print(alpha.unsqueeze(1).bmm(x).squeeze(1).shape)SanModel : 위의 클래스 종합적으로 실행해주는 클래스
mt-dnn/mt-dnn/loss.py → loss function 11개 정의함 ( 동적할당방식을 위해 숫자로 지정해 놓고 개별 적으로 config에 저장해 놓았음)
class LossCriterion(IntEnum):
CeCriterion = 0
MseCriterion = 1
RankCeCriterion = 2
...위의 모든단계를 실행시키는 클래스
