초록
비지도 시계열 이상치 탐지의 목적
- 모델이 복잡한 시간정보에 대한 의미를 함축적으로 학습할 수 있어야한다.
- 대부분의 정상데이터중 작은 이상치 데이터에대해 학습을 하게 되는데 criterion 잘 유도해야한다.
기존 AD의 경우 ML방식 모델자체에 모든 정보가 들어가 시간정도가 들어가지 않음,,, 현실데이터를 일반화 하는 것이 매우 어렵다. → deep learning AD(+temporal) 대표적으로 RNN의 형태가 있음. 하지만 이상치가 정상데이터에 비해 매우 없기 떄문에 정상데이터에 뭍히는 경우가 발생하게됨. DEEP AD 정상데이터를Reconstruction 해서 Reconstruction 된거랑 차이를 Reconstruction error라고 하는데(Reconstruction = point wisely 하게 계산됨.)
point wise representation → 문제
2017 lstm attention AD에 관한 설명내용
- less informative for complex temporal pattern
- can be dominated by normal patters, which can make rare anmalies less distinguishable
RNN의 경우 시간이 흘러가면서 정보가 손실될 수 있음.
이상치 전에 수많은 정상데이터들이 존재함
본 논문에서는 “각 time point를 주변의 모든 time point들간의 관계로 표현할 수 있다.” 라고 주장, 이를 point-wise distribution으로 표현하고자함
뿐만 아니라, 이상치의 경우 다음과 같은 특징을 갖는다는 점을 활용함
- 이상치는 rare하기 때문에 전반적인 시계열에 약한 상관관계(association)을 갖는다. (global)
- 하지만, 이상치는 인접한 영역에 대해서는 강한 상관관계(연관성, association)을 갖는다.(prior)
이상치의 특징으로 인해 각각 normal과 abnormal point의 association간의 차이가 있을 것이라고 보고, 이를 연관불일치(Association Discrepancy) 라고 명명
연관 불일치는 각 time point의 prior association과 series association의 distance로 정의함
연관불일치 값을 효율적으로 추출하기 위해 Mini-Max 기법을 활용함
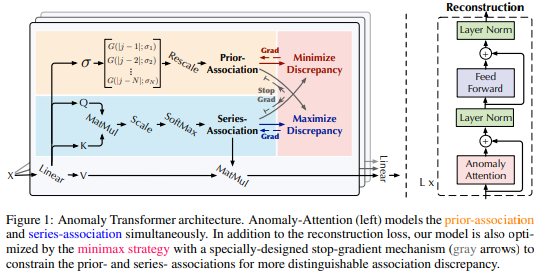
본 연구는 연관불일치를 활용하여 anomaly-attention을 잡아내는 anomaly transformer를 제안하는 연구
Related Work

Method!
-
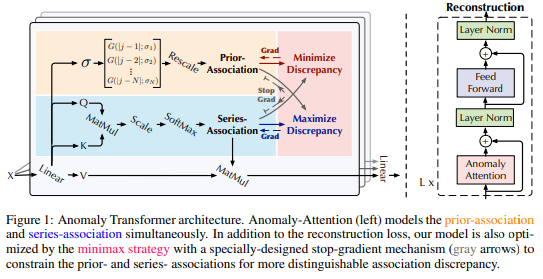
prior-association : 주변정보 강조해서 학습하는 (locality강조함)
가우시안 distribution사용 한다.
시그마를 learnable parameter로 사용하고, prior association이 various time series pattern 에 적응되게하고 different lengths of anomaly segments를 진행한다.
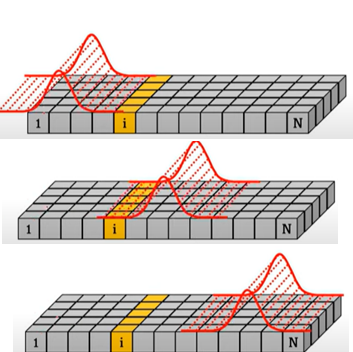
시점에 대해서 가우시안을 통과시켜서 적당한 시그마를 학습하게 된다.
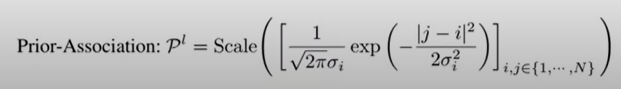
각각의 로우에 대해서 스케일해주게된다.
-
series-association : 전체 time-series에 대한 association을 학습하는 부분
기존 raw series 를 넣어서 association을 학습하게된다.(기존 트랜스포머 식)

-
각각 minimax 기법을 통해 더 좋은 임베딩 값을 추출해 낸다.

Association Discrepancy
prior-association : 주변 시점에 가중치를 준 attention 값
Series-association : 기존 transformer와 동일한 attention값
KL divergence를 이용하여 두 association간의 유사도를 측정함
KL divergence를 분해하면, 정보 엔트로피와 크로스 엔트로피로 분해가 가능하다
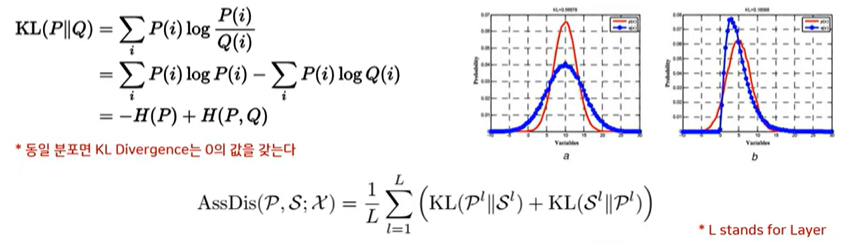


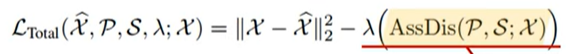
정상의 경우 Association Discrepancy(KL div) 가 클것이다.
AD를 maximize하도록 normal과 abnormal 차이 극대화를 위해 AD term을 추가함
: x를 reconstruction 한 것 을 term으로 사용함 = lr
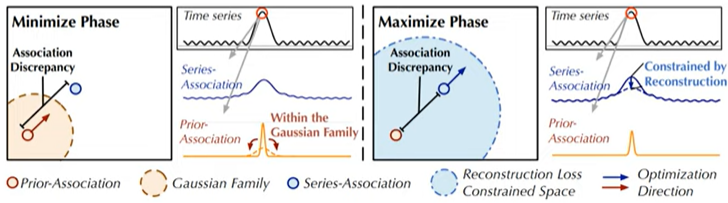
하지만 단순 AD를 최대화 하면 Gaussian prior의 variance를 극소화하는 위험 존재 → 해결하기위해 MiniMax 전략을 사용함
minimize phase : 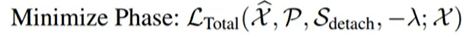
s 는 고정되어 있는 상태에서 P만 변하게되는 형태, prior 업데이트 되면서 s와 유사해지는 것이다.
maximize:
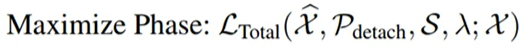
series association이 association discrepancy를 최대화할 수 있도록 함
series association이 보다 더 넓은 영역(non-adjacen)에 attention을 줄 수 있도록 함
Anomaly Score
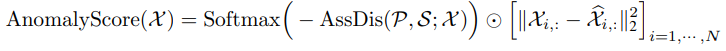
Anomaly Score 는 normalized된 association discrepany와 reconstruction loss를 사용하여 정의
이때 함꼐 사용하므로서 1. 보다 나은 reconstruction을 위해 adjacent한 time point에 보다 높은 attention을 가함 2. abnormal point들은 assoication discrepancy가 보다 낮아지고, anomaly score가 보다 커지는 효과


{kind=link}