초록
unlabeled data 사용
- 어떤 형태의 최적화 목적(optimization objective)가 가장 좋은지 불분명해, transfoer에 유용한 text 표현이 뭔지 알기 어렵다 → LM, machine translation, discourse coherence 등 우위를 점하는 objective가 달랐다.
- 이렇게 학습된 표현들을 목표작업으로 transfer시키는 가장 효과적인 방법이 불분명하다.
→ 비지도(pre-training) + 지도(fine-tuning) = semi supervised learning 제시
→ 다양한 작업에 사용가능, 약간의 변화(adaptation) ⇒ transfer할 수 있는 보편적인 표현을 학습하는 것
다량 unlabeled corpus(pre-training), labeled dataset(fine-tuning) 필요
+) transfer시 traversal-style approache에서 사용된 task에 특정적인 input adaptation사용 , task에 따라 출력부가 바뀐다.
NLI, QA, Text classification, 문장의 의미적 동일성(Discourse Coherence) 12개 Task중 9개 sota
관련연구
이전까지는 단어수준의 정보를 transfer한다는 점에서 한계가 있었다. → 이 논문에서는 더 높은 수준정보 transfer목적
최근 연구에서는 문장 or 문맥 수준 임베딩을 시도하고 있다.
unsupervised learning(pre-training) 에서는 좋은 initialization을 찾는 것이 목표, 이전 LSTM-짧은 부분만 사용가능 → transformer사용함
보조적 학습 목적함수(auxiliary training objectives)
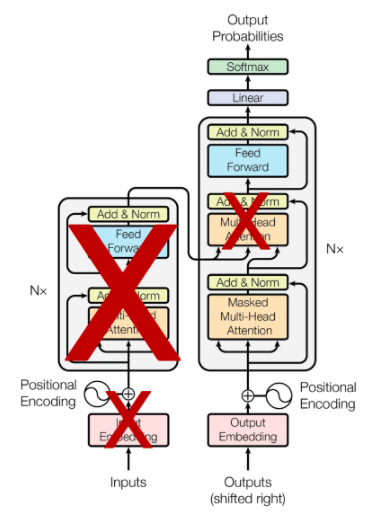
Framework
Unsupervised pre-training
Corpus of text(pre-training) → fine-tuning
→ 우도를 최대화 하는 방향으로 표준언어 모델링 목적함수 사용
k = context window
, ,
U 는 u{-k}, …, u{-1}에 해당하는 토큰의 context vector, n : layer 수 , W_e : emb matrix, W_p : position emb matrix

supervised fine-tuning
, y : label, x : input token, h : 사전학습모델 출력결과, W : 선형출력
, 여기서 L_1 : auxiliary training objective(보조목적함수)
L{3}를 최대화 한다. → **미세조정 시 모델에서 요구하는 추가 파라미터는 오직 W{y}와 구분자 토큰을 위한 embdding**
Task specific input transformations
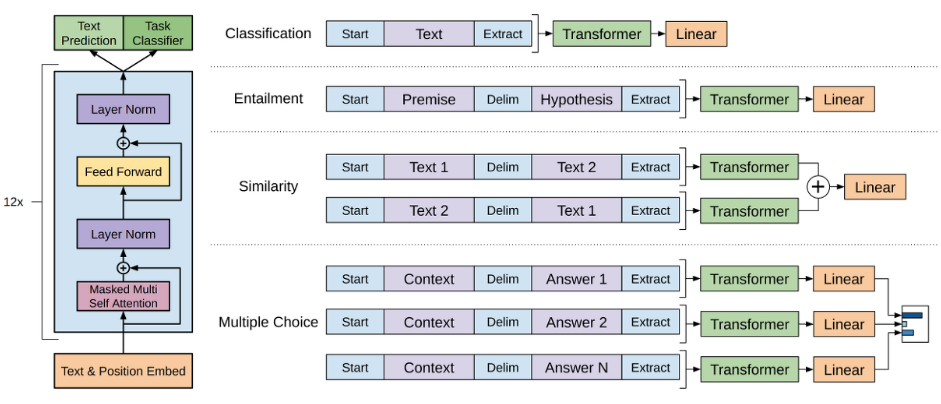
사전 학습 시 연속적 text sequence 로 훈련 → 구조화된 input 필요로한다. ⇒ 작업에 맞는 모델을 추가적으로 실행하야 한다.
이는 목표작업에 구조화된 입력을 사전학습 모델에 사용할 수 있다. → 정렬된 시퀀스로 변환해 사용한다.
Analysis
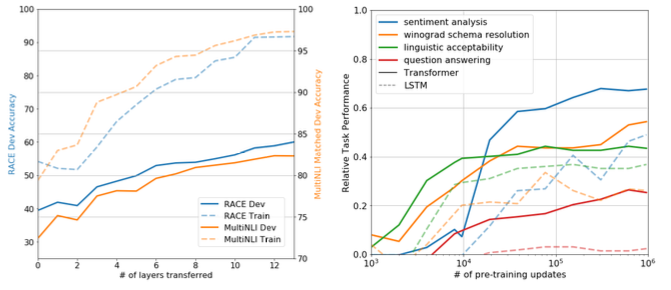
왼쪽 차트는 layer 갯수에 대한 분석
오른쪽은 zero-shot behavior: transformer 구조의 귀납적 편향이 transfer에 도움이 된다. LSTM의 경우 편차가 매우 크게 나타나는걸 볼 수 있다.
Ablation studies
- Auxiliary training objective → NLI, QQP 에 도움이 된다. 큰데이터에서는 효과가 있는것으로 나타났으며 작은데이터에서는 도움이 되지 않았다.
- LSTM VS Transformer → MRPC 를 제외한 모든 부분에서 transformer가 성능이 좋음
- 사전학습 X, 지도학습만진행 : 성능이 다 떨어짐
