agnostic task 가능한 LM 을 만들어보자
Introduction
지도학습 + 비지도학습을 통한 모델 형성은 특정 테스크 수행으 잘하도록 학습이 된다. 하지만, 이는 작은 데이터셋의 변화에도 쉽게 task를 망칠 수 도 있는 위험이 존재한다. 지금까지 모델들은 좁은 범위(Task Specific)의 모델을 만들었지만 범용적으로 사용 가능한 모델을 만들기 위해 GPT2를 제안했다.
방대한 training data와 label할 필요없는 단순 비지도학습과 1.5B 파라미터의 Decoder모델(GPT1과 형태는 유사 약간의 차이는 존재)을 이용해 모델을 학습시켰다.
또한 Zero shot 설정을 통해 범용적 언어모델 능력을 만들고자 했다.
Approach
비지도 분포 추정을 하는데 일련의 symbol ()으로 구성된 예제 ()에서 추정 single task 학습은 을 추정하는 framework로 추정한다. general(agnostic) task의 경우 와같은 형식으로 수행한다. 해당 형식은 meta-learning setting과 같다.
Training data는 web scrapping을 진행했다. 이때 문제는 데이터의 품질인데 hand craft(Manually filtering)를통해서 품질 문제를 개선했다고 했다. (이전 모델들에서는 news article, wiki등을 사용했다 .) web에서 크롤링해 데이터를 사용한 이유는 방대하고 자료를 다양한 도메인과 컨텍스트를 적용시키기 위해서 라고 한다.
토큰을 만들기 위해서 BPE를 사용했으며 여기서 byte수준 token화를 진행해 토큰이 400억 byte중 26번 밖에 안나오도록 했다. 이는 다양한 언어 처리와 보다 정확한 문맥 파일이 가능하다는 장점이 있다.
Model
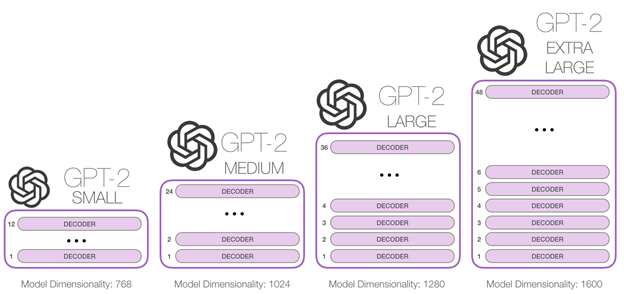
기본적으로 GPT1과 동일하다. Layer Normalize 부분이 sub-block의 input으로 옮겨 졌으며 마지막 self-attention block 이후에 추가되었다. 모델 깊이에 따른 residual path 초기화 방법 변경(논문에 자세히 안나와있음) , batch = 512, context size = 1024 token으로 증가

맨 아래 1542M 이 GPT2모델
성능
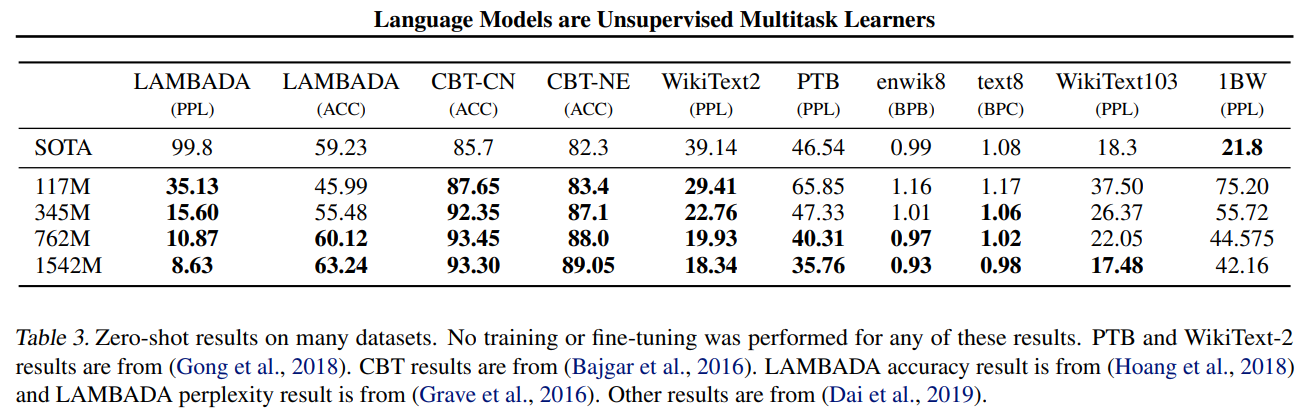
Zero-shot 으로 8개중 7개 SOTA
Zero-shot인 것을 감안하면 꽤 안정적인 성능
독해등에서는 견줄만 하지만 요약에서는 실제로 사용하기 무리가 있음(성능 매우 낮음)
Generalization VS Memorization
dataset 중 test할때 겹치는 데이터가 존재해 측정이 올바르게 된것인가 라는 의문을 제기된 점이 있어 이부분에 대해 8-gram Bloom Filter를 만들어 테스트를 진행 했음 → webtext 써도 된다는 결과 나옴.
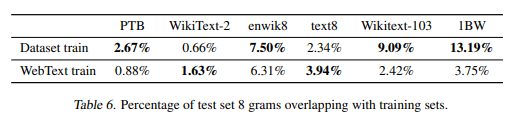
위그림은 dataset train 할때와 webtest 로 train 했을 때 test와 overlapping 되는 percentage 를 보여주는 표로 대부분 비슷하거나 dataset train 할때가 더 높다.
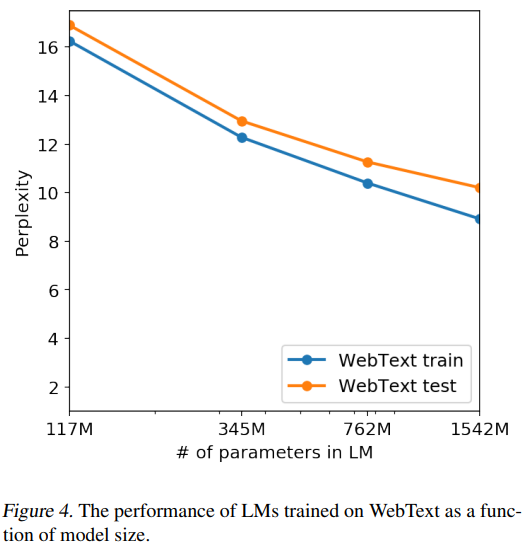
또한 Memorization 하고 있다면 overfitting 되어 기억된것을 대답하는 형식으로 test가 진행되야 하지만 gpt2는 1542M parameters에도 underfitting되어 있는 것으로 나타났다.