novelty: pesudo docs를 만들어서 lexical mismatch 를 최소화 시킬 수 있다. → retireve 퍼포먼스 더 잘 나옴
LIMITATION: 실험결과에 나오듯이 주로 sparse retrieval model들에서 점수가 크게 상승하는 반면 dense retrieval 방식에서는 점수가 크게 변하지 않는다는 단점이 존재한다. docs를 만들고 생성하는 과정에서 latency가 발생한다. dense retrieval 에서 퍼포먼스 안나오는게 hidden representation에 너무 많은 docs가 들어가서 이지 않을까?
Abstract, Introduction
query 확장 방식으로 라는 방식을 제안. sparse and dense retrieval system성능을 더 증가시킬 수 있다고 주장. 첫번째로 LLM을 이용한 few-shot prompting 으로 가짜 docs를 만든 후 가짜 docs로부터 query를 확장하는 방식.
BM25 tjdsmddmf 3%~15%정도 향상, 추가 학습 없이.(ad-hoc IR datasets에서. MSMARCO, TREC DL)
IR은 docs에서 관련된 유저의 query와 관련된 위치를 찾는 것이 중요하다.
BM25 remains competitive on out-of-domain dataset 에서 유리함(경쟁력 있음). rewrite the query 는 외부 지식 소스로부터 재작성 or 관련된 가짜의 feedback을 통한 재작성 방식이 있다.
본 논문에서 제안하는 방식은 LLM(text-davinci-003)을 통한 few-shot prompting을 이용해 가짜 docs를 생성한 후 original query와 concatenates 시켜 새로운 query를 만드는 방식을 제안한다. 실험에서 BM25를 이용, dense retrievers에도 효과가 좋았다(SimLM, DPR, E5). 특히 zero-shot OOD 셋팅에서 outperform.
데이터셋: https://huggingface.co/datasets/intfloat/query2doc_msmarco?row=99
Method
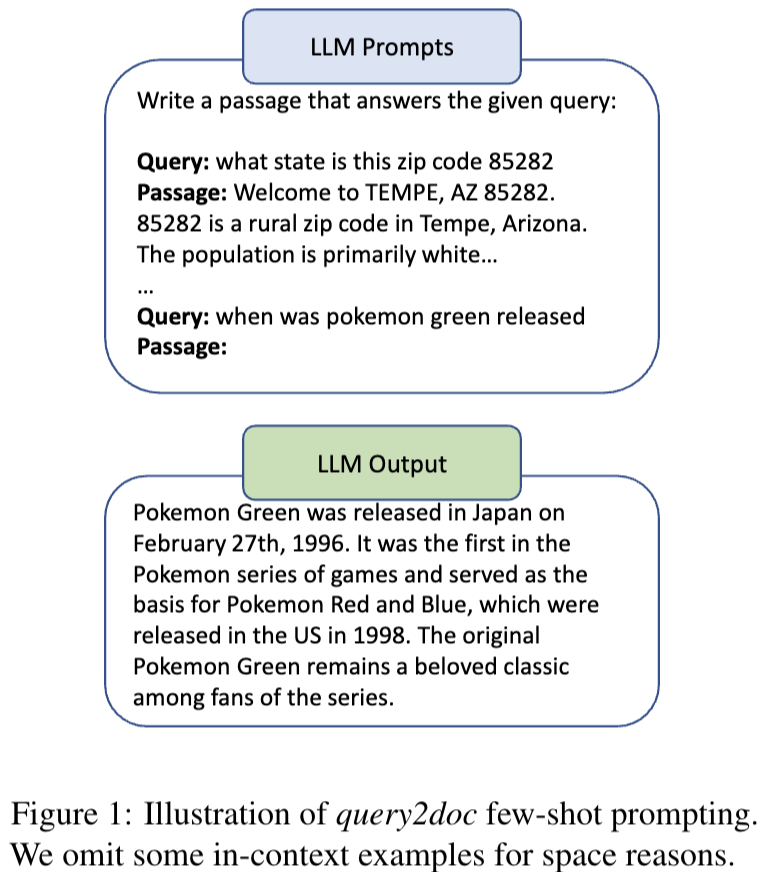
docs를 만들 때 간단한 in-context(4개) 예시 몇개와 앞에 write~~ 라는 프롬프트를 주어서 쿼리를 바탕으로 passage를 작성하게한다. 그 후 가짜 passage(docs)로 부터 쿼리를 재작성하게 한다
sparse 의경우 docs +약 5개정도 기존 쿼리를 더 넣어서(의미가 사라지지 않게 하기 위함?? 왜 더 넣지..?!?) 단순히 concat 시키는 방식으로 사용한다.
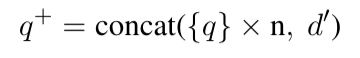
dense의 경우 contrastive loss 와 KL term을 두어서 학습시킨다.
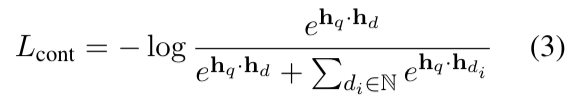
KL term에서 ce, stu는 cross encoder teacher model 로부터 distillation 시킨 loss 를 사용한다.
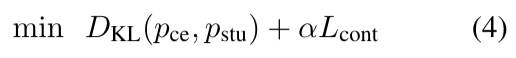
전통적인 query 확장방식으로 PRF(pseudo-relevance feedback)방식이 존재하는데 기존 방식은 단순히 top-k docs에서 초기 retrieval step을 뽑는 방식이라면, 본 논문에서의 방식은 가짜 docs를 스스로 만들어서 사용하기 때문에 초기 query가 noisy가 있거나 irrelevent할 수 있다는 단점을 없앨 수 있다.
Experiment
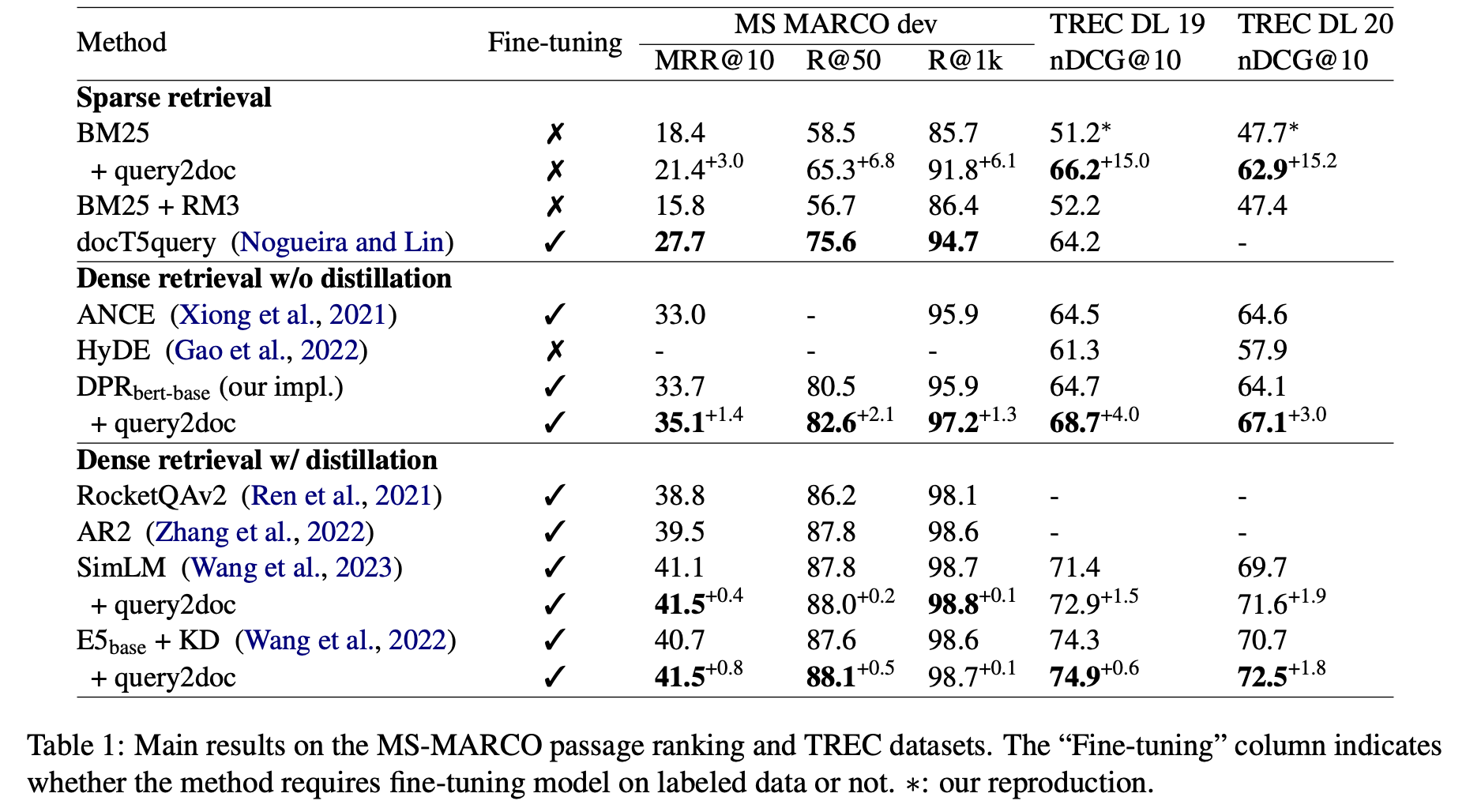
위 실험결과는 retrieval model 들이
Text REtrieval Conference (TREC) Question Classification dataset
query expansion 하는 과정에서 모델 사이즈가 클수록 퍼포먼스도 더 잘나온다.

