소개
GQA(Grouped Query Attention)으로 라마2에서 쓰인 기술로 유명하다. GQA는 MHA(Multi Head Attention)과 MQA(Multi-Query Attention)의 장점을 결합한 기술로, 추론 속도를 빠르게 하면서 성능을 유지할 수 있다. 라마2에 사용된 경우 성능 향상을 보인다.
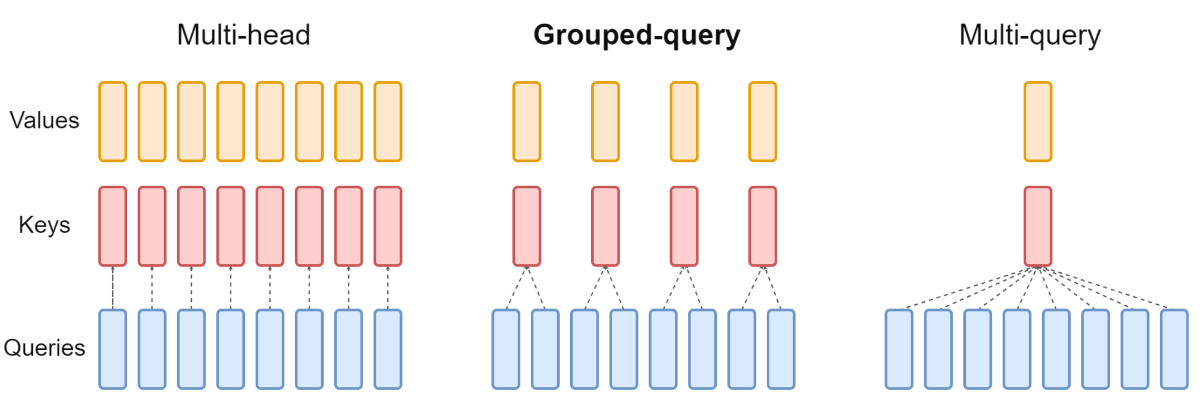
MQA는 메모리 대역폭을 엄청나게 줄일 수 있지만, 성능저하와 불안정 하다는 문제가 존재한다. → 이를 해결하고자 GQA가 제안
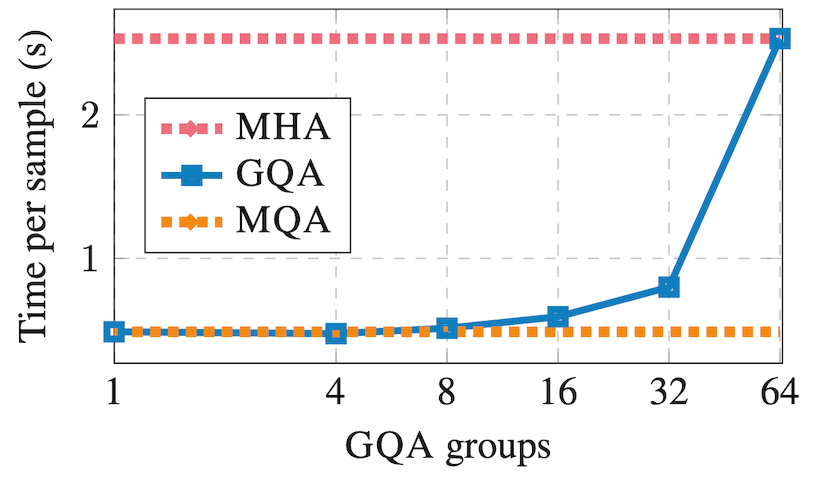
KV를 1개로 줄인는 대신 적절한 갯수의 그룹으로 줄인다. 만약 갯수가 1개면 MQA가되고 갯수가 Q와 같다면 MHA가 된다. 즉, 위 둘을 일반화 했다고 볼 수 있다.
MHA → GQA 로 갈때 mean pooling 방식으로 k,v 를 뽑아낸 상태에서 약간의 pretraining 만큼 진행 (scratch 로 학습시키는 것보다 더 좋음)
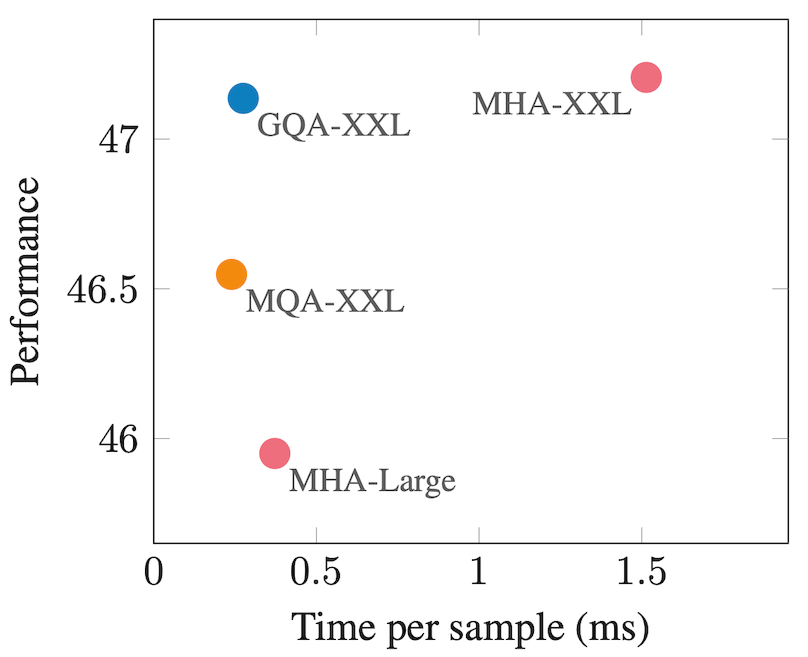
ablation study에서 약 0.1 정도일 때 MHA와 GQA의 performance가 비슷하게 나온다.
큰모델에서 사용하기 좋은 형태.
성능
얼핏 보면 GQA는 MHA와 MQA의 중간이지만 속도와 performance모두 훌륭한 방법이다.
특정한 법칙은 아니지만 H가 64개일 때 8개의 갯수가 적절한 성능이 나온다는 것을 알 수 있다.