용어
self-consistency : multi CoT를 이용해 나온 결과들은 결과들을 합산해서? 모아서 최종결과를 뽑아내는 방법
Abstract
RLHF VS RLAIF
AI 피드백이 인간의 피드백을 받아서 학습한 것과 비슷한 성능이 나온다.
RLAIF 는 인간수준의 성능을 뽑을 수 있으며, RLHF scalability 한계를 제안한다.
Intro
- SL에 비해 RL을 이용한 학습은 최적화 시키기 쉽지 않다.
- RLAIF : AI 의 선호도를 바탕으로 RM을 학습시킬 때 사용한다. -> 또한 RM은 RL에 사용된다.
- Constitutional AI (법을 따른는 AI?) : 이전연구들은 해당방법을 통해 스스로 수정 검토를 통해 AI 선호도를 뽑아내고 이는 SF baseline보다 좋은 성능을 뽑아낼 수 있다.
해당 연구들은 AI VS Human을 직접적으로 비교한 연구가 아니다. - 본 논문에서는 요약부분에서 RLHF 와 RLAIF의 성능을 비교한다.
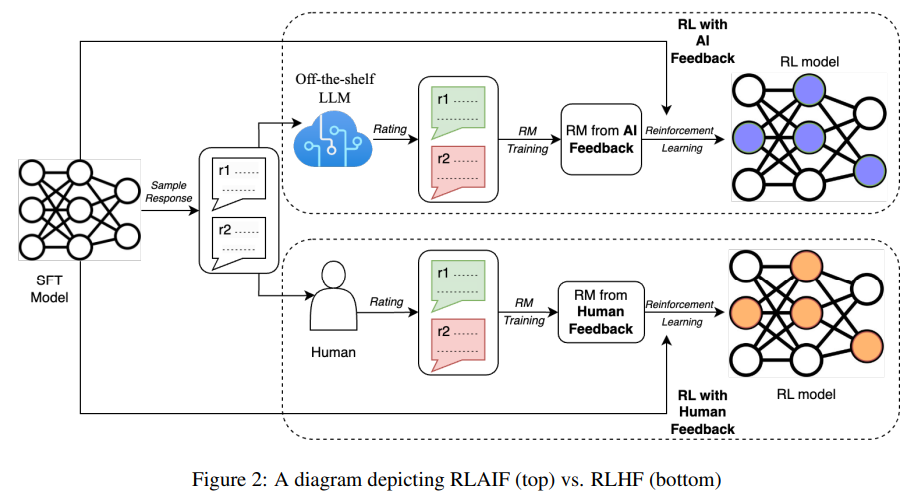
학습방법
1. 2개의 candidate responses 중에 선호도 레이블링을 하기위해 (off-the-shelf)LLM을 가져와 사용한다.
2. 선호도 레이블링이 진행되면 대조손실값(contrastive Loss)을 이용해 RM을 학습시킨다.
3. 마지막으로 policy model 을 RL을 이용해 학습시킨다.
평가방법
1. RLAIF VS SF, RLHF VS SF -> 71%, 73% human preference가 나옴
2. RLAIF VS RLHF 사람이 생성된 문장을 비교 -> 50% 50% win rate 가 나옴
-> 해당 실험의 결과로 human annotation에 의존할 필요가 없음을 의미
추가적실험
1. CoT 구체화, LLM Instruct구체화를 통해 alignment improvement 가능하다.
2. few-shot, self-consistency 방식들은 정확도 향상에 도움이 되지 않는다.
3. LLM size와 number of preference의 trade-off 관계에 대한 scailing 실험을 진행
3.RLAIF Methodology
3-1. Preference Labeling with LLMs - PLaM2 사용

- Preamble - 테스크에대한 안내를 위한 지시문(CoT가 들어감)
- Few-shot exemplars - Preferred Summary 에 올바른 답변을 위해 예시
- Sample to Annote - Annotation하기 위한 지시문 넣음
- Ending - 정답값 도출
3-1 Position Bias
LLM 이 위치에 따라 관측값들의 bias 를 가지고 있어 정확학 측정에 편향이 생길 수 있음.
이 부분을 경감하기 위해서 두개의 inference를 만들었다. candidate들이 reversed제공하면서 최종 preference distribution을 평균에 맞추게 함
3-2 CoT
Preamble 부분에 CoT 지문과 함께 추론의 예시로 One-shot prompt 를 넣어서 진행함
3-3 Self-Consistency
multi-CoT를 이용해 정확도를 올리고자 하였다.
2. Reinforcement Learning from AI Feedback
- PPO방식에 사용되는 기존 RM방식이 아닌 단순 BCE를 이용해 RM을 학습시켰다.
- 바로 사용하는 방식은 연산적으로 비용이 많이 든다는 단점이 존재한다.
- 또한 PPO는 A2C(Advantage Actor-Critic)방식에 안정성과 조금 보수적인 방법이다. 본 논문에서는 A2C를 이용해 학습에 사용하였다. (더 성능이 좋았음)
3. Evaluation
1. AI Labeler Alignment
PLaM 2 모델이 얼마나 정확하게 labeling 하는지 사람과 비교한 것
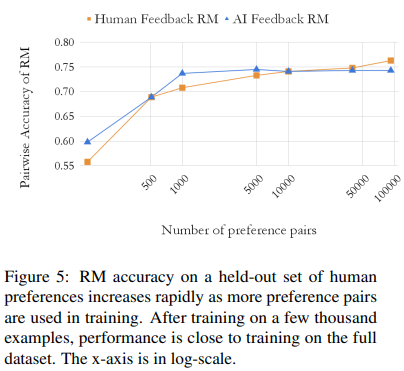
2. Pairwise Accuracy - Figure 5와 함께 볼 것
학습된 RM의 정확도를 나타낸다.
RM Score : 2가지 candidate중에서 선호지문 > 비선호지문 -> +1
반대로 대답할 경우 + 0
3. win rate
두 모델 중 어떤것이 더 선호되는지 측정하는 방법 -> 선호도는 사람에 의해 측정된다.
4. Experiment Details
4-1. Datasets - Reddit TL;DR 사용
4-2. LLM Labeling
언어모델을 통해 레이블링을 진행 해 보상모델을 학습시키기 위한 목적 PLaM2를 사용함
T = 0 - greedy decoding
4-3
모델학습을 진행할때 SFT - PLaM2 xs 를 사용함, RM - ????, 강화학습은 A2C 사용
AI-Labeled preference : PLaM2 L + CoT + Open AI prompt 사용함
5. Results
5.1 RLAIF vs RLHF
RLAIF vs baseline SFT -> 71% win rate
RLHF vs baseline SFT -> 73% win rate
RLAIF vs human summaries -> 80% win rate
RLHF vs human summaries -> 79% win rate
RLAIF vs RLHF -> 50% win rate
5.2 Prompting Techniques
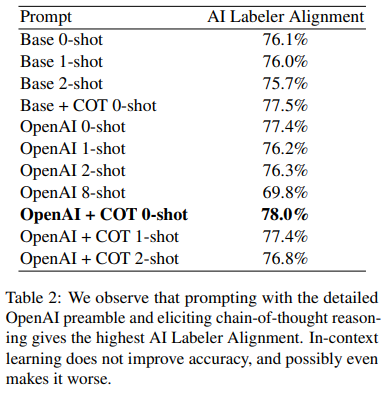
해당 측정은 PLaM2가 얼마나 labeling을 사람과 동일하게 할 수 있는가를 측정한 결과
프롬프트를 추가+ CoT를 사용 했을때 결과가 가장좋음 단 one-shot이 아닌 few-shot 으로 주어졌을 때 성능이 떨어지는 현상이 나타남
5.3 Self-Consistency
-> CoT에 Sample을 추가한 후 aggregate 진행했을 때 결과

더 나빠짐
5.4 Size of LLM Labeler
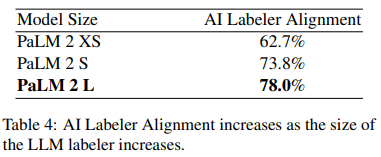
model size가 커질수록 더 좋은성능
5.5 Number of Perference Examples
측정 방식이 사람이 만든 2개의 prompt
Preference candidate > non-preference candidate => score + 1
Preference candidate < non-preference candidate => score + 0
사람의 FB을 받아 학습된 RM과 AI에게 FB을 받아 학습된 RM 의 Accuracy
RLAIF는 빠르게 증가 후 안정기(정체기)에 들어가는 형태를 보인다.
!!! 한계점 : human preference로 학습된 RM은 지속적으로 증가하는 형태를 보인다.
6. Qualitative Analysis
크게 2가지 차이가 존재했다.
1. RLAIF는 RLHF에 비해 hallucination이 적게 나오는 양상을 보인다.
2. RLHF는 RLAIF에 비해 상대적으로 문법, 조리있게 말하는 특징을 보인다.
각 policy에 따라 특정 경향성이 존재한다. 하지만 둘다 퀄리티는 좋게 나타난다.
8. Conclusion
- RLHF와 동등하게 PLAIF도 좋은 성능을 보인다.
- AI labeling 기술들이 소개되었다.
- 요약에 대해서만 성능을 측정하였다.
