- Keyword: dictionary learning, sparse autoencoder
- Novelty: 방식과 방식 제안
- Summary: 모델의 성능 유지와 feature 를 더 잘 찾을 수 있는 sparse autoencoder obj loss 제안
feature 가 학습된 neural network에 대한 interpretability는 중요한 challenge이다. 이중 Sparse autoencoders (SAEs) 는 overcomplete dictionary를 reconstrcts 함으로 써 feature들을 확인하는 작업을 진행한다. 그러나 SAEs는 데이터셋 구조를 더 많이 학습해 네트워크 연산 구조를 충분히 반영하지 못할 수 있다. 이는 dictionary에서 발견된 방향이 네트워크에 기능적으로 중요한지에 대한 직접적인 근거가 부족해지는 문제가 있다. 이를 위해 e2e sparse dictionary learning 이라는 방식을 제안한다. SAEs가 학습하는 특징이 기능적으로 중요하도록 한다. 이는 원래 모델과 SAE 활성화를 삽입한 모델의 출력 분포간 KL divergence를 최소화 시키는 방식으로 학습이 진행된다. 이는 SAEs에 비해 성능을 더 좋고 적은 수의 특징을 사용하며 해석가능성을 희생하지 않으면서 더 적은 수의 동시에 활성화된 특징을 필요로 한다.
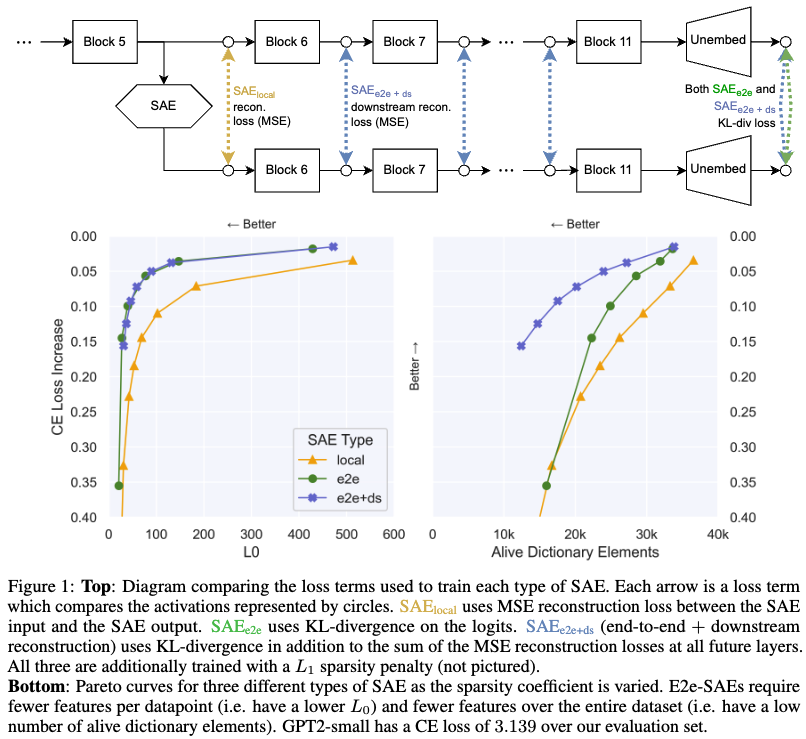
Reconstruction error = MSE error, Residual Error = 네트워크의 성능을 성명하지 못하는 부분, 재구성된 데이터와 원본 데이터의 차이로 인해 발생한다. 이 잔차는 네트워크가 실제로 중요한 기능적 특징을 포착하지 못할 경우를 반영할 수 있다. 즉, SAEs가 학습한 특징이 네트워크의 실제 성능과 얼마나 관련이 잇는지에 대한 지표로 사용될 수 있다. 본 논문은 MSE 를 최소화 시키면서 학습되는게 네트워크의 성능을 잘 설명하는 것은 아니라고 말한다. 실제로 중요한 특징은 네트워크 동작과 더 밀접하게 관련되어 있을 것임을 지적한다.
위의 Figure 1 TOP 부분에 나오는 은 단순 input, output 간의 MSE loss이고 는 logits값의 KL divergence 부분이다. 마지막으로 는 MSE에 KL divergence텀을 추가적으로 넣고 학습한 결과 (앞에 두 방법을 함께 사용)이다. 본 논문에서 제안하는 방식이 dictionary elements 남아있는 갯수가 더 많고 CE loss 가 더 작게 나온다.
Training end-to-end SAEs
formula
FFN 에 대해 L 번 째 layer의 hidden activationmdf 이라고 했다. D: dictionary matrix, = , : reconstruction loss term control 하기위한 텀
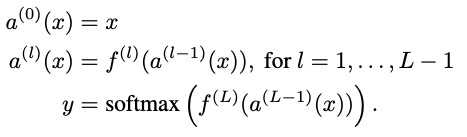
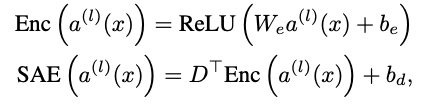
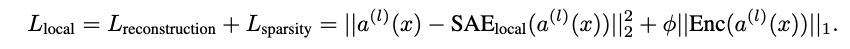
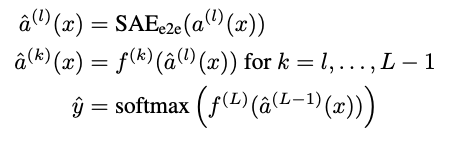
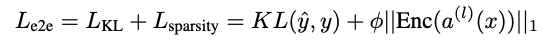
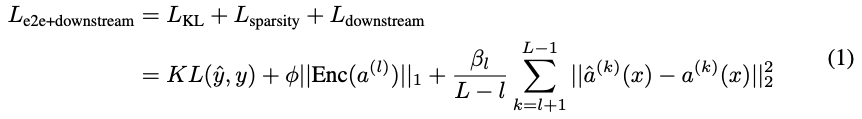
Metric
-
Cross-Entrophy Loss Increase
원래 모델과 SAE가 삽입된 모델간의 교차 엔트로피 차이. SAE 활성화를 사용했을 때 모델 성능이 얼마나 감소하는지 나타낸다. 낮은 CE는 모델의 성능을 더 잘 유지하는 것을 의미.
-
데이터 포인트에 대해 평균적으로 활성화되는 SAE 특징의 수. 적은 수의 특징을 사용하는 것이 더 효율적이다.
-
Number of Alive Dictionary Elements
학습 중에 한 번 이상 활성화된 dictionary element의 수 (500k token dataset에서 활성화된 요소로 정의됨.). 전체 데이터 세트를 설명하기 위해 사용되는 특징의 수를 나타낸다. -
Downstream Reconstruction loss
SAE 삽입 후 원래 모델과 새로운 모델의 각 층에서의 활성화 간 MSE loss
-
Automated Interpretability score
모델의 특징이 해석가능한지를 평가하여, 성능 향상이 해석 가능성의 손실 없이 이루어졌는지를 확인한다.
Experiment
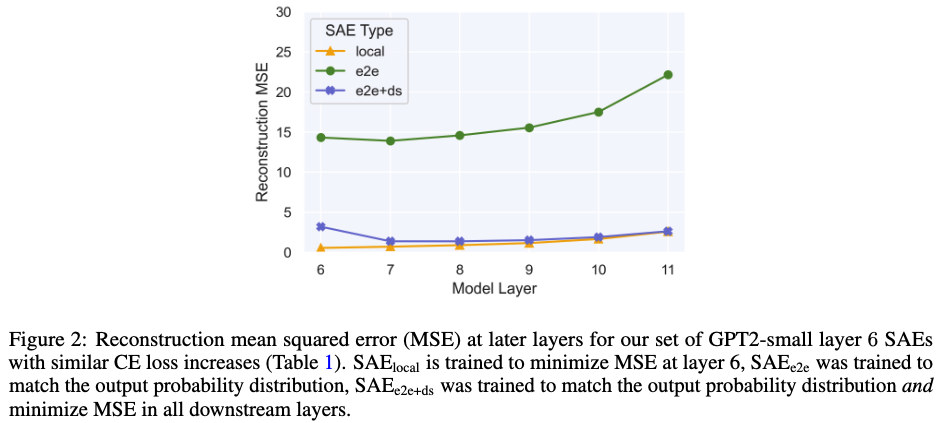

실험결과 해석: 가 CE는 매우 조금 더 낮지만 reconstruction error (MSE loss)가 매우 크게 나타난다.
Conclusion
본 논문은 e2e dictionary learning 방식을 제안한다. 방식과 방식을 통해 기존 방식보다 feature 학습으 ㄹ더 효과적으로 할 수 있고 logit 값 KL divergence를 낮출 수 있다고 주장한다.
