이전연구는 multi agent debate prompting 이라는 방식을 사용 → 경제적 문제등이 있음. 이를 해결하기위해 Prompt-OIRL (offline inverse reinforcement learning) 이라는 방식제안. offline inverse reinfocement learning - offline pormpting demonstration data로 부터 insights를 이끌어내는 방식.
- Focus:
Offline RL: Directly learns the policy from the rewards in the dataset.
Offline IRL: First infers the reward function from actions, then derives the policy.
- Data Utilization:
Offline RL: Uses state-action-reward sequences.
Offline IRL: Uses state-action pairs (or sequences) to infer rewards, even if rewards are not explicitly given.
ABSTRACT
arithmetic reasoning ability을 높이는 실험을 진행. 이전 논문은 prompt를 통해서 단순히 정답을 높이는 방식을 제안. 하지만 프롬프트마다 맞추는 문제가 다르고 directly ask과 비교했을 때 정답을 틀리게 말하는 경우도 존재함. → inference 동안 prompt를 평가하는 방식의 부재로 이러한 문제점이 나타난다라고 주장 → 본 논문은 Prompt-OIRL 이라는 offline reward system을 제안.
Prompt-OIRL: query-prompt pair 를 LLM 없이 평가하는 방식이며 이때 best-of-N 전략을 사용해 최적 prompt를 사용함.
왜 prompt-OIRL 이 필요한가? - 프롬프트를 넣지 않았을 때 더 정확한 정답을 내는 경우도 존재하며, query에 따른 optimal prompt가 존재함.

Challenge 1: inference time evaluation is hard - answer을 알 수 없기 때문에 평가하는 과정이 쉽지 않음
Challenge 2: online prompt evaluation and optimization is expensive (api price) - 돈
⇒ Solution: Query-Dependent Prompt Evaluation and Optimization with Offline Inverse RL
a solution of combining existing human knowledge in prompting systematically, effectively, and cost-efficiently
Contribution:
- 전문가들이 만든 prompt들을 이용해 prompt optimization 을 시키는 작업을 진행했다.
- query-dependent offline prompt evaluation
- 실용성과 존재하는 prompt 전략들이 benchmark로서 사용될 수 있게 함
- Prompt-OIRL의 효과. 3 arithmetic datasets (GSM8K, MAWPS, SVAMP) 에서 Prompt-OIRL을 이용해 optimization을 했다.
PROMPTING WITH OFFLINE INVERSE RL
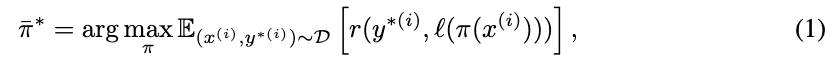
eq(1) 은 데이터셋에 가장 좋은 퍼포먼스를 내는 single prompt를 찾는 수식을 의미
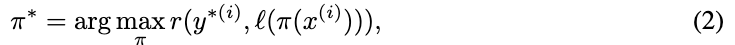
eq(2)는 queries에 대해서 퍼포먼스를 잘 내는 프롬프트를 찾는 수식
본 논문에서는 eq(2) 를 objective function으로 생각하고 해당 수식으로부터 최적을 prompt를 찾으려함.
Offline Inverse RL
step1: construction of offline IRL as a viable learning solution
다양한 prompt를 이용한 answer를 얻는 과정이 존재하고 이를 offline으로 확인하기 위해서 prompts 를 이용해 dataset을 구성한다. 이때, prompt(x), answer (y), reward (r) triple pair dataset을 구성한다.
step2: offline query-dependent prompt evaluation through reward modeling
를 바로 사용하면 범용적으로 사용하는 것과, 새로운 프롬프트 혹은 query가 있을 때마다 LLM call을 해야하기 때문에 효율적이지 못하다. → reward modeling을 통해서 범용성을 갖추고자함. parameterized proxy reward model을 통해서 query와 prompt가 인풋으로 들어가고 reward model은 proxy reward model과 true reward (target LLM 을 통해서 나온 reward)의 차이를 최소화 시키는 방향으로 학습을 진행시킴. arithmetic reasoning task는 binary classification이기 때문에 아래와 같은 loss function을 통해 Supervised Learning (SL) 을 진행함. embedding model을 통해서 text representation을 뽑아내고 이를 xgboost (gradient boosting method)를 이용해 학습시킴.
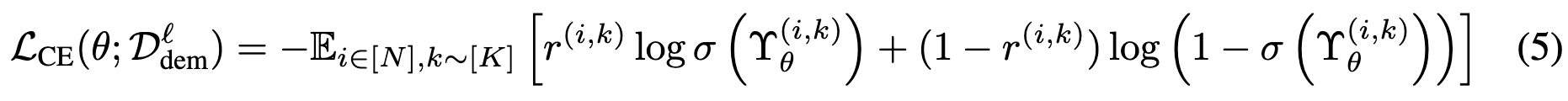
step3: offline query-dependent prompt optimization using the learned reward model
proxy reward modeling 을 통해 나온 모델과 실제 LLM call 을 이용했을 때 reward 를 approximate 하려하고 하였으며 이때 나온 prompt를 사용해 실제 LLM call에 사용한다. 이때 best-of-N 전략을 이용한다. best-of-N은 단순히 특정 K 상수를 지정하고 상수개의 prompt 중 1개를 선택해서 LLM call의 input으로 사용하는 prompt로 사용하겠다는 뜻이다.
EXPERIMENT
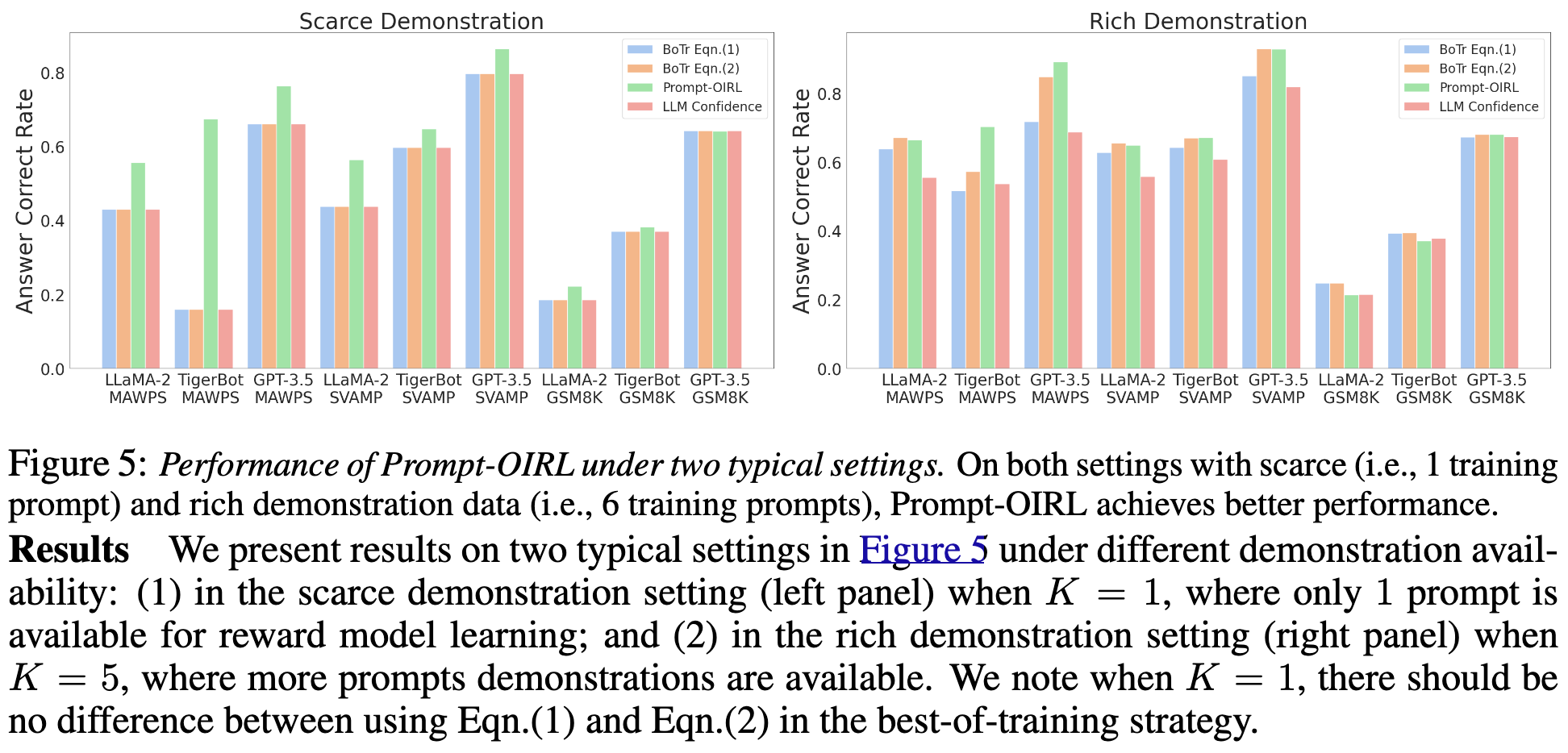
Scare demonstration (left) 에서는 K=1 로 설정 (prompt 1개 사용) 했을 때 proxy reward modeling 한 상황이고 right panel에서는 K=5로 설정한 후 학습을 진행한 reward model을 사용한 경우의 answer correctness를 측정한 것이다. 본 저자는 K=1 setting 에서 24.3% 증가한 결과가 나왔으며 K=5에서는 8.8% 향상된 점수가 나왔다고 한다.
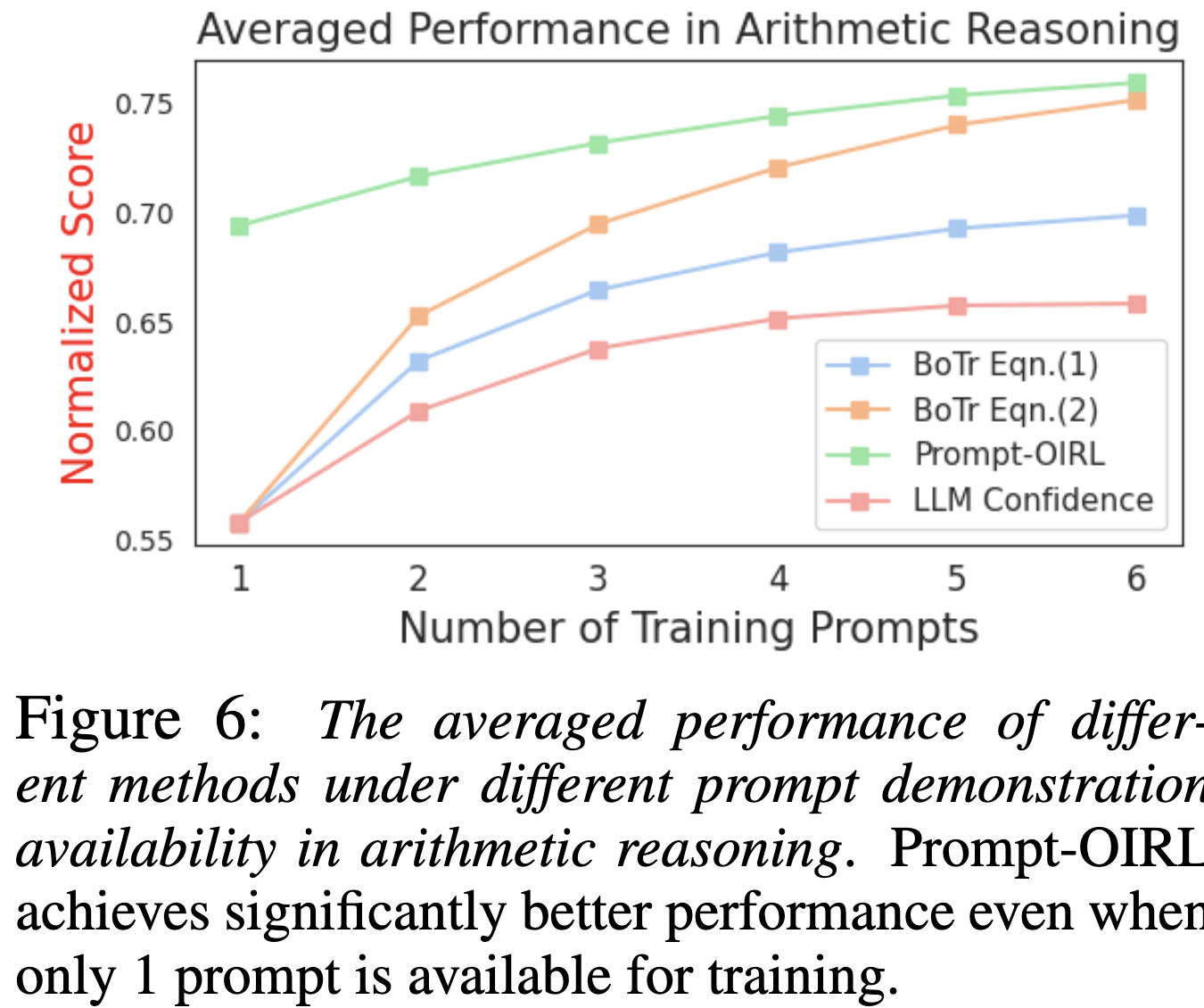
figure 6는 figure5를 normalize 한 결과이다.
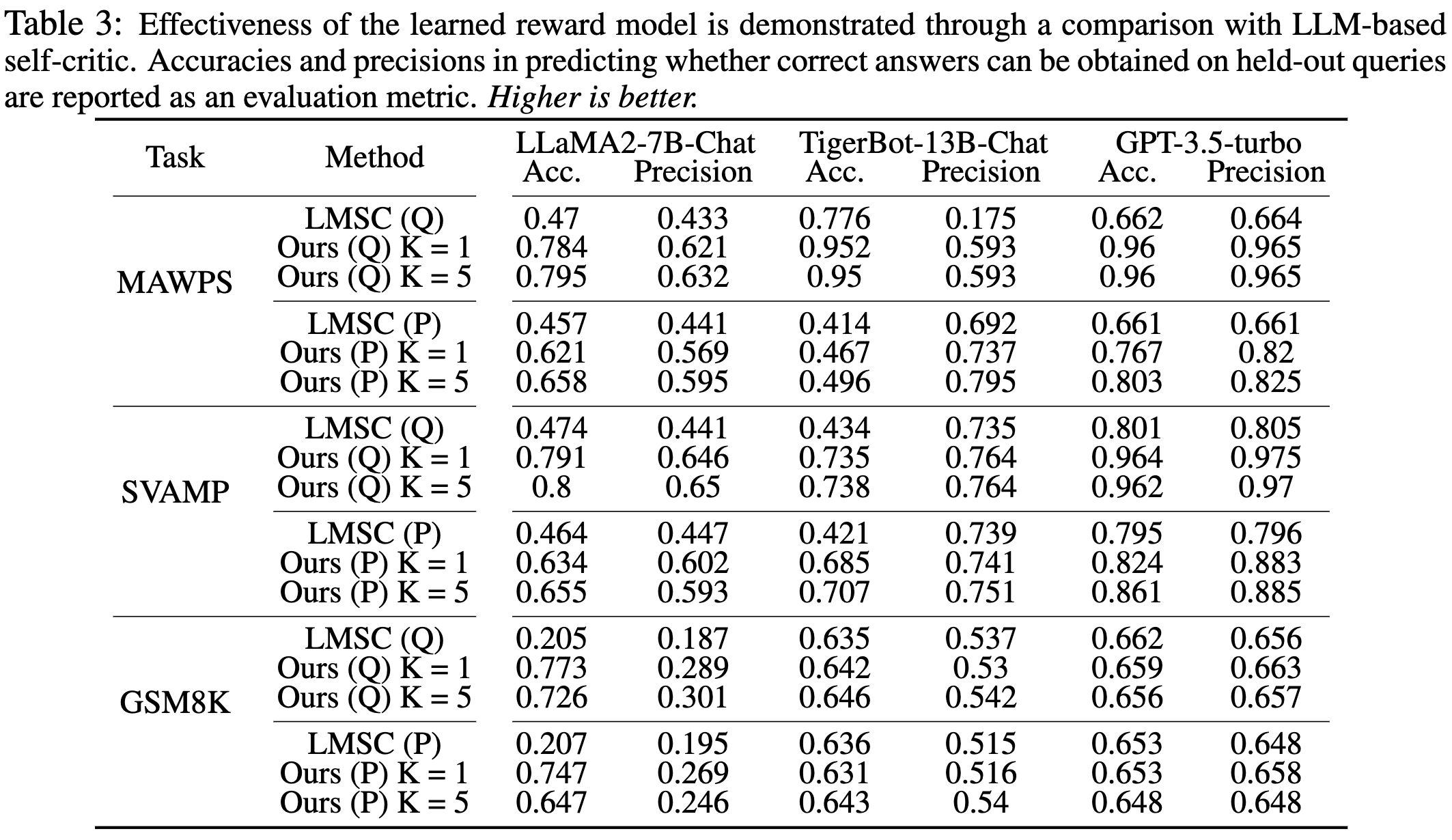
학습된 reward model 의 효율성을 평가를 우히ㅐ LLM-based self-critic이라는 방법을 baseline으로 두고 측정하였다. (language model self-critic) LMSC 이라는 방법을 human instrction에 모순이 있거나 틀린 정보가 들어가는 경우가 존재하는데 이를 LLM 이 틀린정보를 파악하고 방식이다. (evaluation으로 hh dataset등으로 측정하였음.) LMSC 는 LLM call 객체의 internal parameter를 바탕으로 평가를 하는 방식이다. 이를 baseline으로 사용한 이유도 외부 parameter에 prompt와 query를 평가한 방식과 내부 model parameter에 평가하는 방식을 비교하기 위해 설정된 셋팅으로 보인다. LMSC represents an internal method for achieving this, making it a relevant baseline for comparison
Q는 (Seen-Prompt + Unseen-Query)를 의미하고 P는 (Unseen-Prompt + Unseen-Query)를 의미한다. 즉 해당 테이블에서는 저자의 방법론의 generalization 에 효과적인지 보기 위한 실험이다.
저자는 challenge로 비용적인 측면을 제시하였다. 저자들의 방식이 얼마나 API 요금이 나가는지 나타낸 것이다. Llama2는 open source이기 때문에 GPT hour를 측정하였고 나머지는 API 요금을 측정했다.