과거 video-based LLM 연구는 video 길이에 대해 완전한 이해를 바탕으로한 통합된 모델을 만드는데 challenge가 존재한다. 해당 논문은 비디오의 풍부한 content에 따른 이슈를 해결하고자한다. 방법으로 저자들은 pooling전략을 사용해 token compression과 instruction-aware visual feature aggregation을 사용한다. 저자들은 PPLLaVA (Prompt-guided Pooling LLaVa)라는 방식을 제안한다. PPLLaVA에는 3가지 핵심요소가 존재한다.
- CLIP-based visual-prompt alignment that extract visual information relevant to the user’s instruction
- prompt-guided pooling that compresses the visual sequence to arbitrary scales using convolution-style pooling
- clip context extension designed for lengthy prompt common in visual dialogue
(추가적으로 DPO 학습도 진행함.)
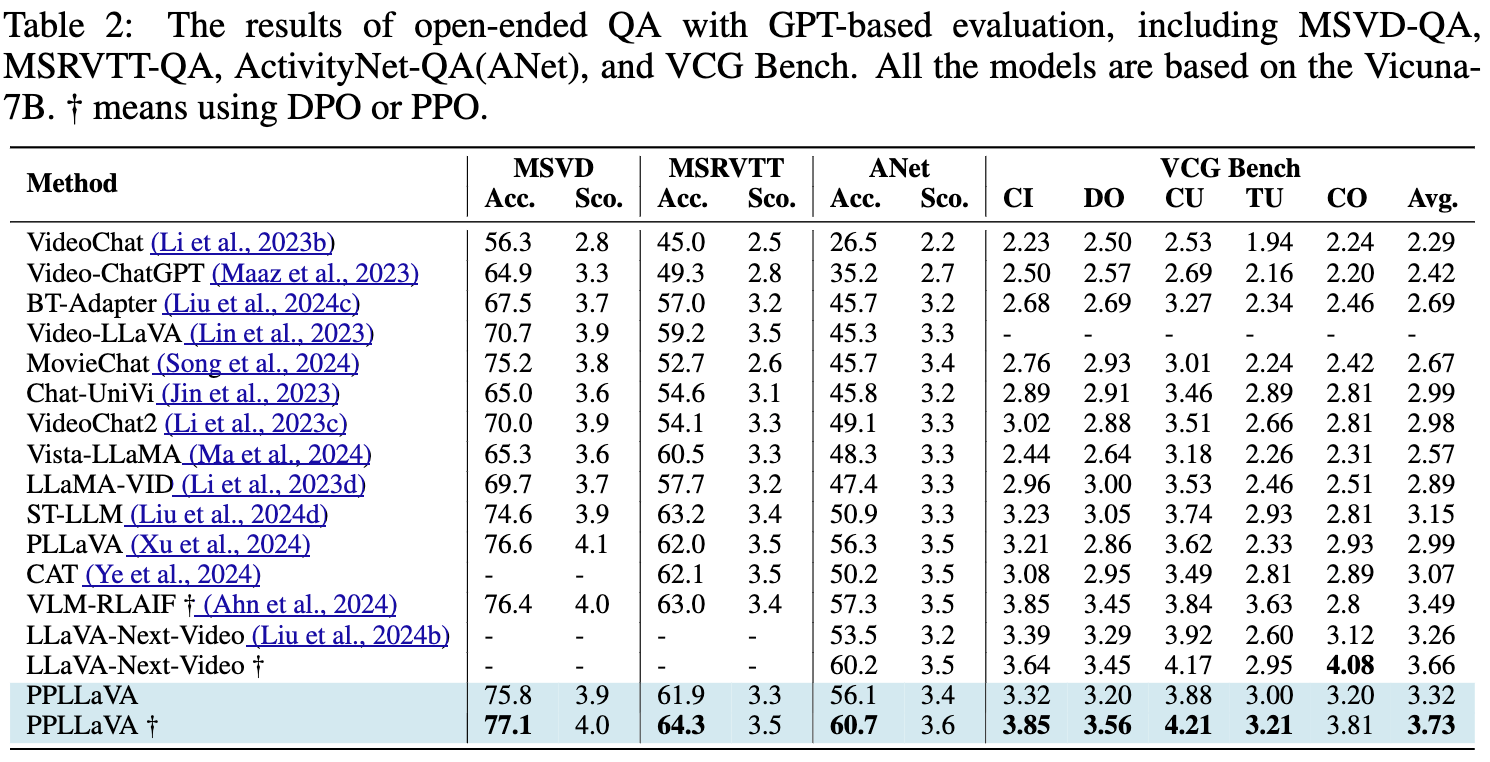
단지 1024 visual context를 이용해 해당방식은 video benchmark에서 SOTA를 달성한다고 한다.
Temporal modeling에서 직관적인 방법으로 모든 frame에 대해 input tokens을 만드는 것이지만, computation문제로 문제가있다. 이를 해결하기 위해 average pooling across the temporal dimension 방법을 사용한다. 하지만 이 방법은 고정된 길이를 받아 dynamics능력에 취약하다.
long-video 를 받아 처리하는 모델들은 반대로 짧은 video or image활용에 한계가있다. 또다른 접근방식은 token을 condition 하게 pooling하거나 aggregation하는 방식이 존재한다. 기존의 global average pooling과 다르게 이 방식은 context length 문제를 감소시키며 spatiotemporal structure 을 보존할 수 있어 효과적이다.
그러나 pooling방식은 performance 감소를 발생시킬 수 박에 없다. 저자들은 video의 특징을 생각해서 해당 문제를 해결하고자한다. video는 일부 frame이 핵심적인 요소이고 이에 대해 집중한다. → video information의 핵심적인 부분을 추출하면 compressing 하는 것보다 performance를 향상시킬 수 있다고 말함.
step1: PPLLaVA identifies the prompt-relevant visual representations through fine-grained vision-prompt alignment.
step2: using the prompt-vision relevance as a 3D convolutional kernel, compress the visual tokens to any desired three-dimensional size based on the specified output size of stride
step3: recognizing that CLIP pretraining provides a limited context length and that training video LLMs requires long text contexts, PPLLaVA also employs asymmetric positional embedding extensions to expand the text encoding capacity
저자들이 주목하는 부분은 visual token compression 이다. 전통적인 방식은 pooling을 진행하고 다른 방식은 clustering, compress into two tokens and non-parametric adaptiveAvgPool3D 방식을 사용한다. 언급한 방식들은 video 길이에 따라 성능이 크게 달라진다. 하지만 저자들의 방식은 visual token length에 robust하며 long, short video 에서 SOTA 성능이 나온다.
Method
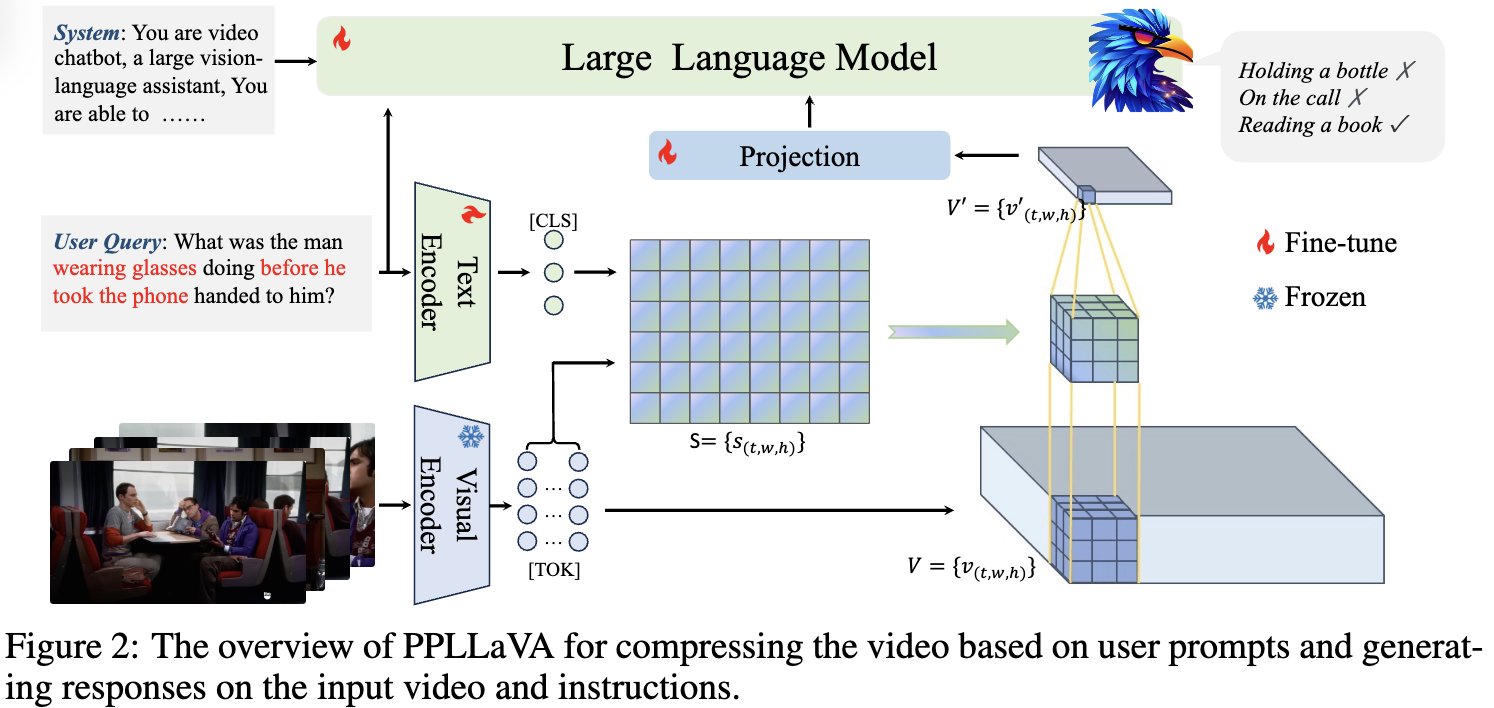
CLIP encoder로 부터 나온 visual feature를 이라고 할 때 이를 Pooling 시키면 이 나온다. 여기서 MLP (projection)을 통해서 visual input으로사용한다.
Fine-grained Vision-Prompt Alignment
text encoder는 로 표현하고, CLIP에서 CLS 토큰 부분을 가져온다. 하지만 visual token은 CLIP visual encoder 뒤에서 두번째 부분 patch token을 가져온다 (저자들은 마지막레이어는 spatial representation이 잘 표현되지 않기 때문이라고 말함). Text representation은 다음과 같이 계산된다.
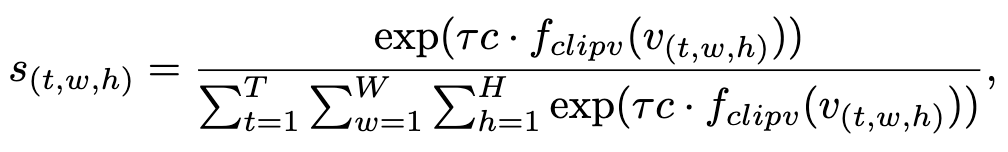
여기서 는 CLIP visual projector 이고, 는 CLIP temperature scale이다.
Prompt-Guided Pooling
text representation (token level weights)를 사용해서 video representation pooling을 진행한다.
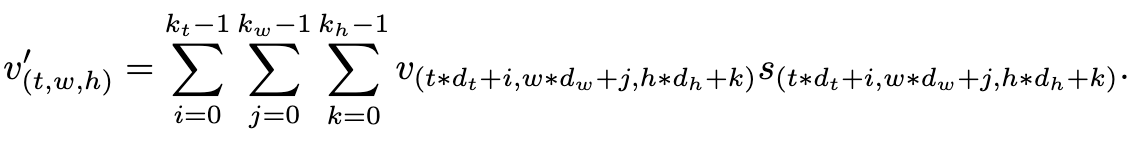
의 각각의 요소를 아래 eq와 같이 표현할 수 있다.
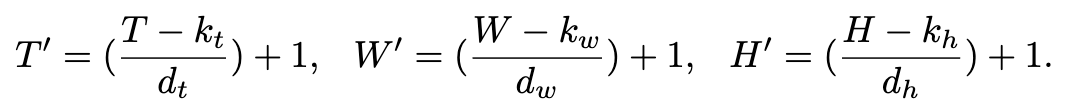
CLIP Context Extension.
Position encoding에서 CLIP은 제한이 있기 때문에 이를 해결하기위해 linear interpolation을 진행한다. global averaged interpolation은 퍼포먼스가 실험적으로 낮았는데 이에대해 저자들은 CLIP 이 잘 학습되어서 외부 확장시킨 interpolation에서는 성늦이 낮아졌다고 판단한다.
Experiment