MuRAG: Multimodal Retrieval-Augmented Generator for Open Question Answering over Images and Text
논문리뷰
본 논문은 retrieval-augmented generation이 text 정보를 바탕으로 활발하게 연구되고 있음을 문제점으로 말한다. 실제적인 정보는 mulitmodal 정보가 존재하기 때문에 이를 사용하는 것으로 image와 text를 함께사용하는 MuRAG 방식을 제안한다. 저자들은 WebQA, MultimodalQA 에서 10-20% 정도의 성능 향상이 존재한다고 말한다.

저자들은 figure1 과같은 “what can be found on the White House balconies at Christmas?” 와 같은 query에 대해 text만 사용해서 적합한 응답을 하는것이 힘들다고 강조한다. 또한 궁극적인 retrieval-augmented models의 목적은 multiple modalities를 사용하는 것이라고 한다.
이를 바탕으로 저자들은 T5와 ViT 모델을 결합한 backbone 모델을 text-only, image-text pairs, image-only 데이터셋으로 pre-trained을 진행한다. 이때 contrastive and generative loss function을 둘다 사용해서 model이 relevant passage를 가져올 수 있는 능력을 학습할 수 있다고 말한다.
Method
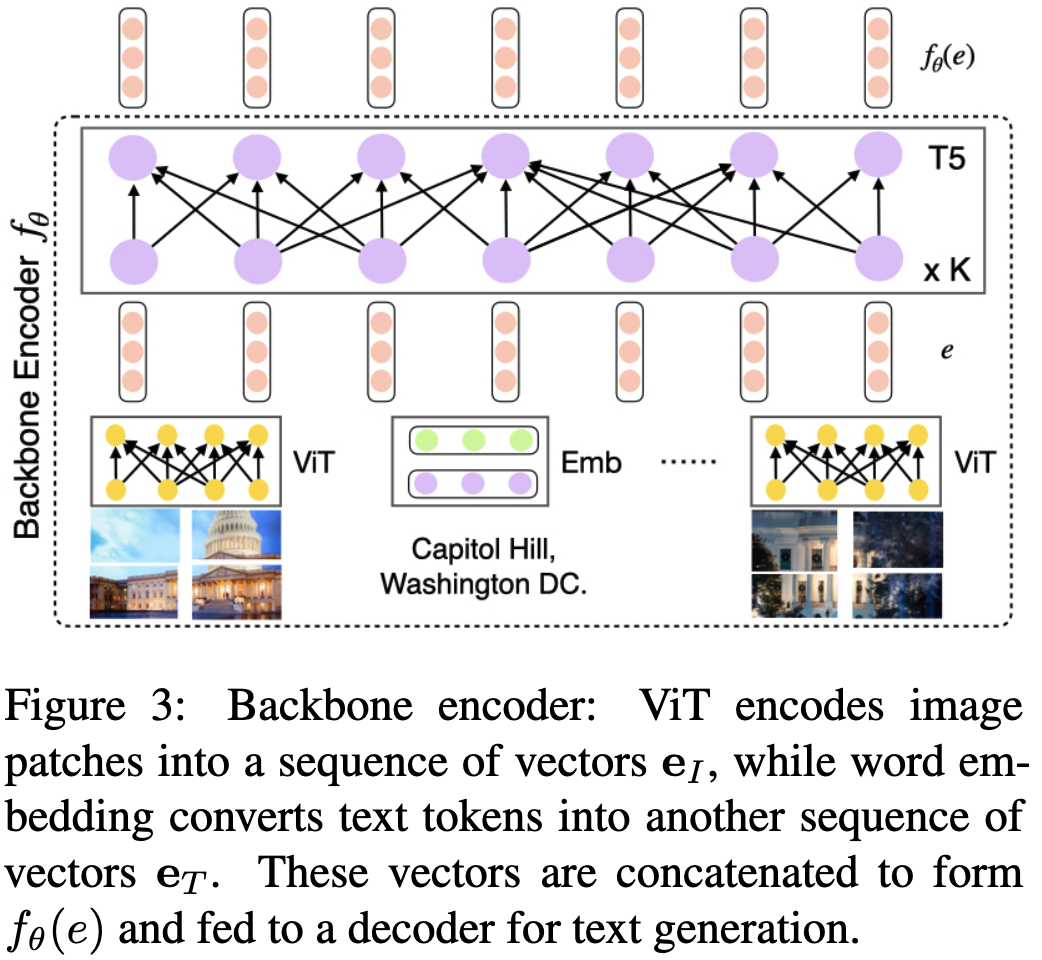
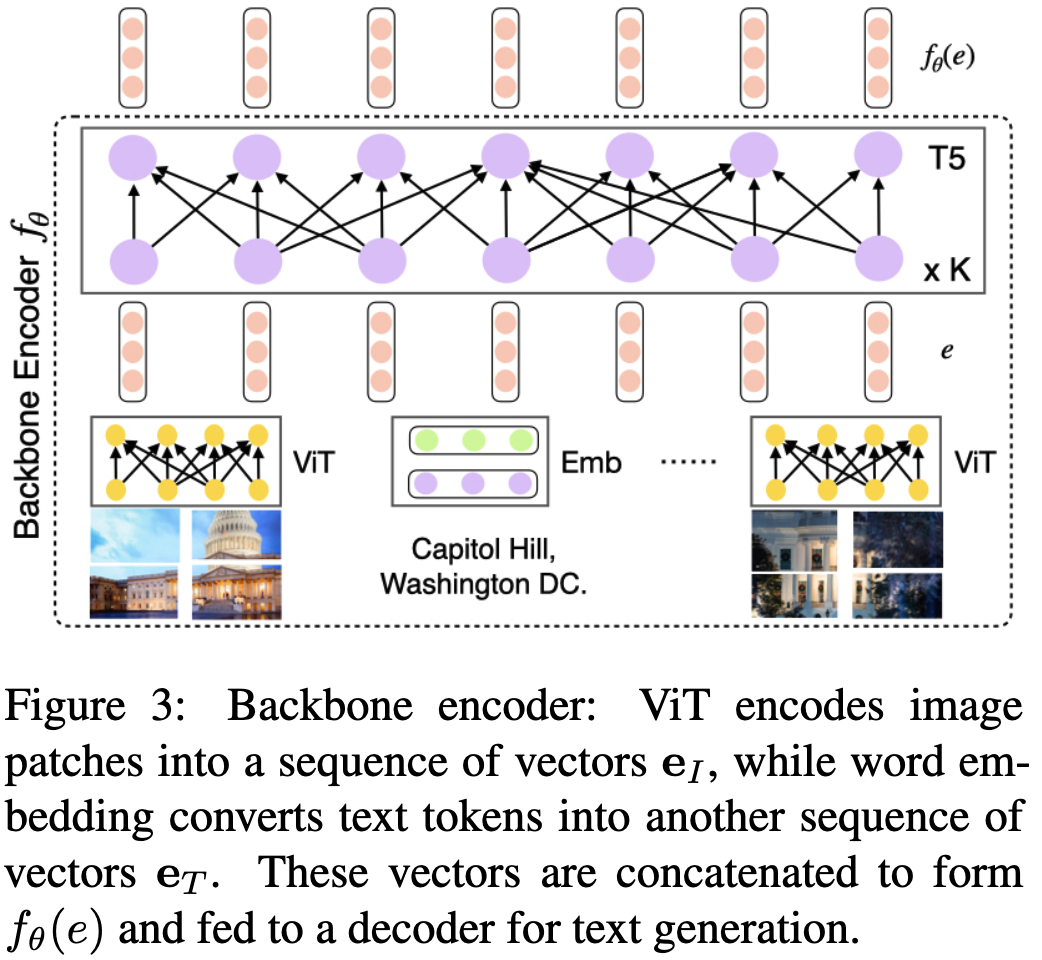
backbone model은 pre-trained visual transformer와 T5 text Transformer로 이루어져있다. multimodal encoder 와 deocde 로 이루어져있다. 는 backbone model encoder와 같다. ViT는 16 X 16 patch로 들어가게되고, visual embedding은 차원을 가지며 text는 의 형태로 표기한다. input order는 다음과 같다 , 이는 bi-directional encoder의 input으로 들어간다 (). fused representation을 로 표기할 수 있고 pooled 토큰을 representation 으로 사용한다 ()
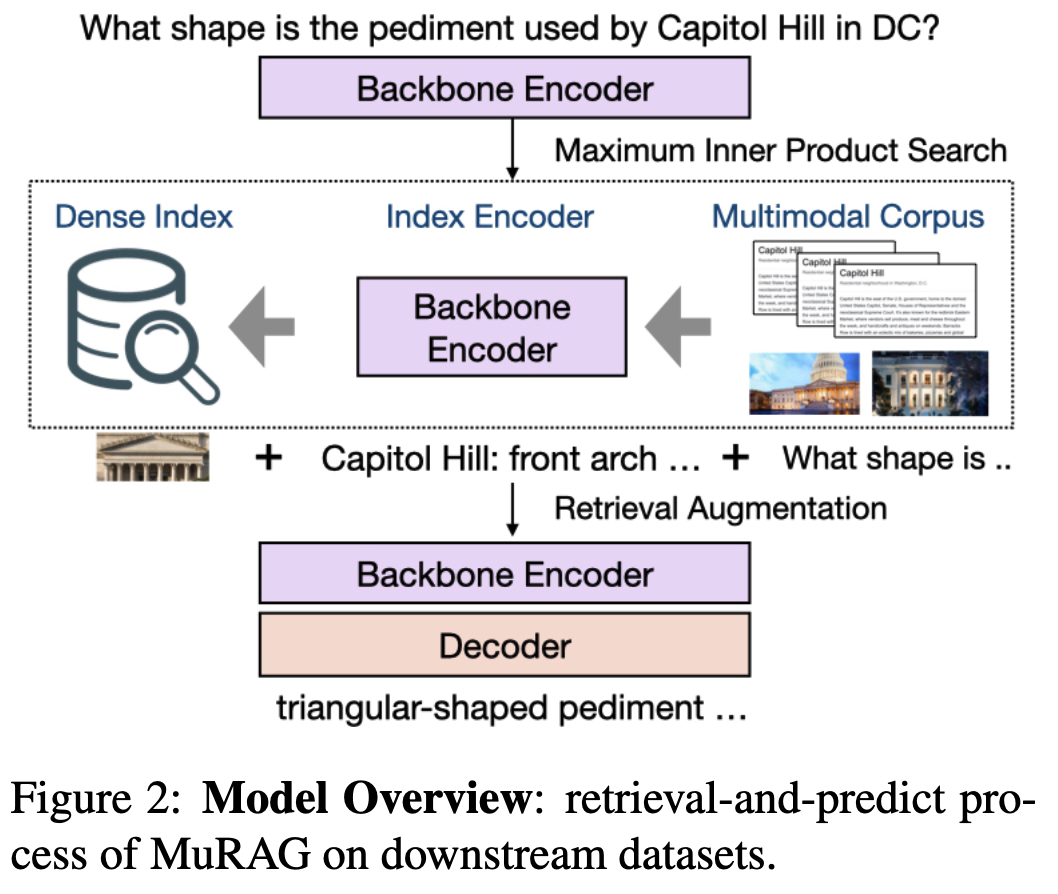
3.2 MuRAG
retriever stage에서 어떤 modality 든지 간의 query ()를 바탕으로 MIPS 를 바탕으로 external memory information 을 retrieve한다. , top k 개의 관련정보를 가져온 후, query와 함쳐서 encoder 모델 input으로 들어간다. .
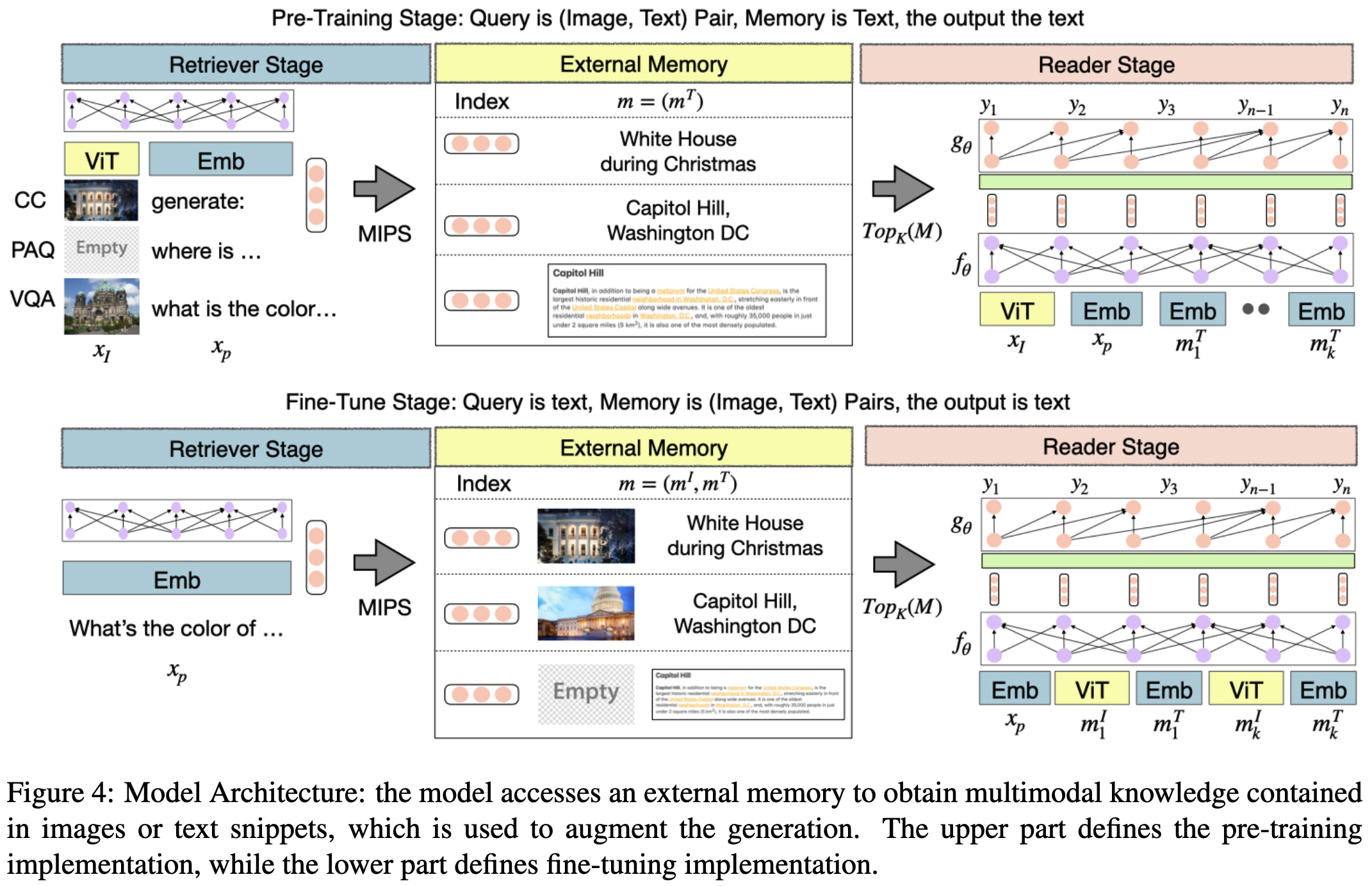
3.3 Pre-training
사전학습에는 Figure 4의 상단과 같은 과정으로 진행된다. image 와 text prompt 가 input으로 들어가고 이를 바탕으로 생성된 토큰으로 MIPS 를 진행한다. pre-training에서는 retrieved data는 text데이터만 이용한다. 각 데이터셋마다 prompt와 input형태가 달라진다. 그리고 retrieval 로 관련정보를 가져오기위한 함수와 text generation 을 목표로한 를 합한 objective function을 이용해 학습에 사용한다.
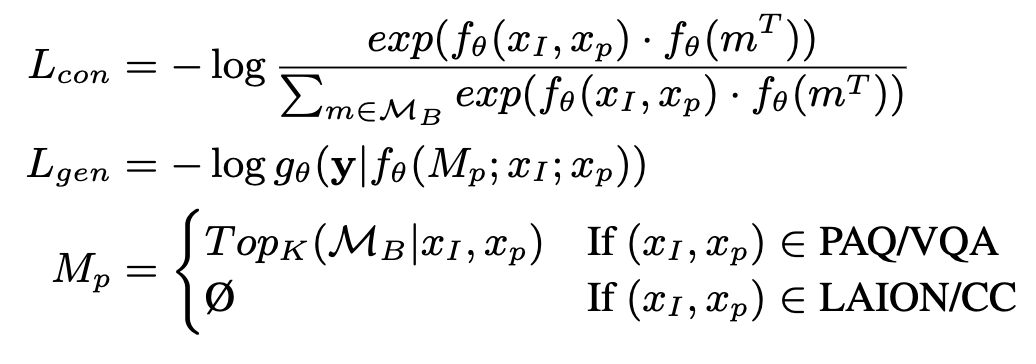
3.4 Fine-tuning
downstream task에 적용시키기 위해 추가적으로 학습시키는 과정으로 query에 text가 들어가고 external memory에 image와 text 모두 적용가능하도록 만들어 학습을 진행한다. 이때 전체 retrieval pool에 대해 학습하는 것이 아닌 개의 후보중에서 contrastive loss를 사용해서 학습을 한다.
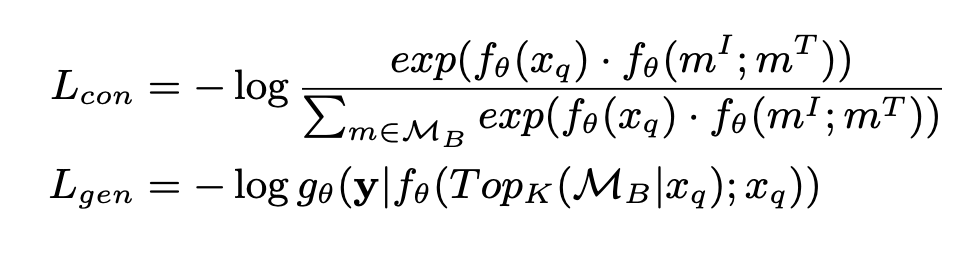
Experiment
WebQA는 multi-hop dataset으로 query들은 1-2images or 1-2text 를 답변을 위해 필요로하게 된다. 해당 평가는 BARTScore로 진행이되며 fluency, accuracy 점수를 측정한다.
MultimodalQA는 TextQ 그리고 ImageQ 타입을 결정해 subset을 만들어 평가를 진행한다. query는 1개의 image or 1개의 text를 답변을 위해 필요로 하게된다. MultimodalQA는 EM 과 F1 을 통해 평가를 진행한다.