잘못된 내용이 있다면 댓글 부탁드립니다!! 감사합니다 :)
Motivation: LLM이 겉으로는 거짓을 생성하더라도 모델 내부엔 사실에 대한 representation을 가질 수 있다.
Summary: 모델 내부 파라미터에 activation 조정을 통해 Truthful 한 생성을 가능하게함.
Novelty: intervention
neurips 2023 spotlight
ABSTRACT
Inference-Time Intervention (ITI) 라는 Truthful 을 높일 수 있는 방식을 소개한다. ITI는 model의 제한된 attention head의 activations을 inference동안에 shifting 하면서 동작한다. Instruction fine-tuned model 인 alpaca model에서 truthful QA task 성능이 32.5% → 65.1%로 향상되었다. 본 저자는 truthful과 helpfulness 간의 trade-off 관계가 있다는 것을 보이며, intervention strength (개입강도) 를 조절하면서 균형을 맞추는 방법을 소개한다. ITI방식은 단순히 few hundred examples 만으로 truthful direction을 위치시킬 수 있다 (사용할 수 있다) 고 한다. 본 논문은 LLM은 겉으로는 거짓을 생성하더라도 모델 내부엔 사실에 대한 representation을 가질 수 있음을 시사한다.
INTRODUCTION
LLM은 자신이 말하는 것 보다 많은 것을 알고있다. 이러한 부분은 direction (e.g. CoT) 와같은 context를 추가했을 때 더 정확한 답변을 생성하는 것과 같다. 이전 연구들을 바탕으로 저자들은 LLM의 latent에서 real-world correctness 와 관련된 해석가능한 구조가 있을 것이라고 생각했다.
generation accuracy (model output) 과 probe accuracy (classifying a sentence using classifier with model’s intermediate activations as input) 정확도 차이가 40%난다는 것을 확인했고 이를 줄이기 위해 ITI 를 사용했다.
ITI for Eliciting Truthful Answers
많은 언어모델에서의 activation space는 해석가능한 directions을 포함하고 있고, 이는 inference에서 해석가능한 인과관계 역할을 한다 (A theme in the literature is that the activation space of many language models appears to contain interpretable directions, which play a causal role during inference). 본 논문은 어떻게 모델을 통제해서 results를 바꾸는지에 대한 기술에 대해 설명한다.
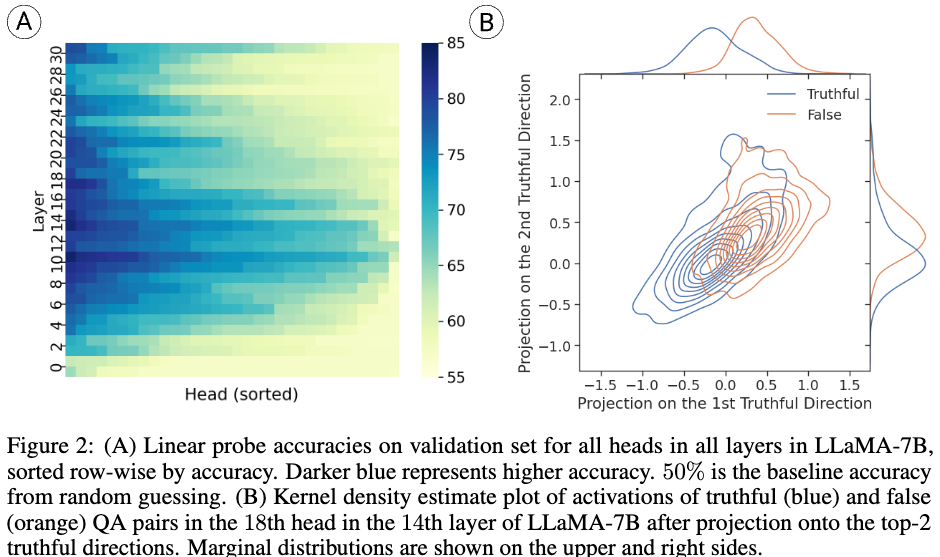
Figure2 (A)는 linear prob를 이용해 시각화 한 것이고 (B)는 가장 높은 Truthful 정답률을 보이는 prob의 layer 2개를 이용해 geometric figure 로 표현한 것이다.
Inference-Time Intervention
Figure2 (A)에서 subset layer만 truthful과 강하게 관련되어 있다는 것을 보고 일부만 개입하였다. (top K개) Figure2 (B)에서 볼 수 있듯이 tru versus false statement는 복잡하ㅗㄱ, activation shifting direction을 선택하기 위해 두개의 선택할 수 있는 조건이 있다고 한다. 첫 번째로는 vector orthogonal to the separating hyperplane learned by the probe 라는 방식과 vector connecting the means of the true and false distributions 이라는 방식이다. 후자의 방식이 실험에서는 더 좋은 결과가 나왔다고 한다.
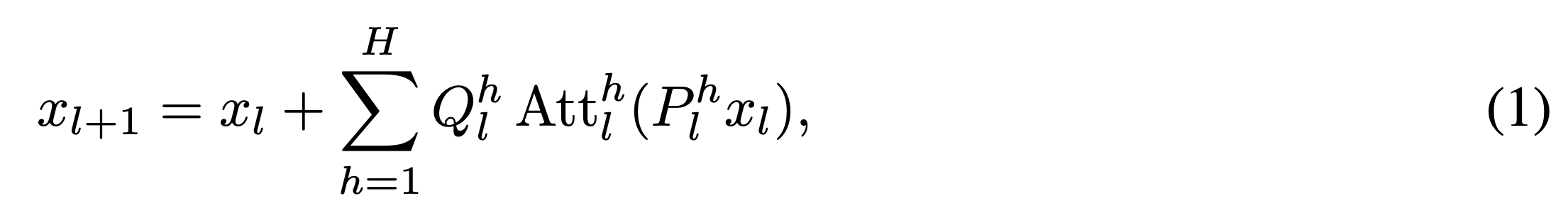
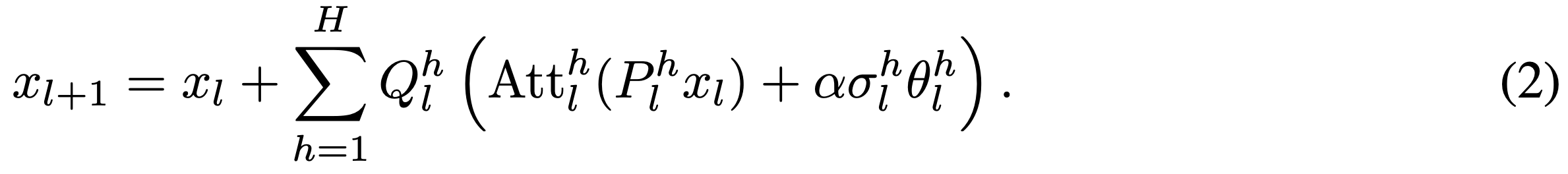
1번수식은 일반적인 attention진행하는 식이고 본 저자는 2번과 같은 식을 제안한다. 여기서 는 standard variation을 의미하고 는 strength를 의미한다. 는 선택된 attention head의 파라미터를 의미한다. k(선택된 파라미터) 가 아닌 attention head 는 zero vector를 더해주게 된다.
Experiment
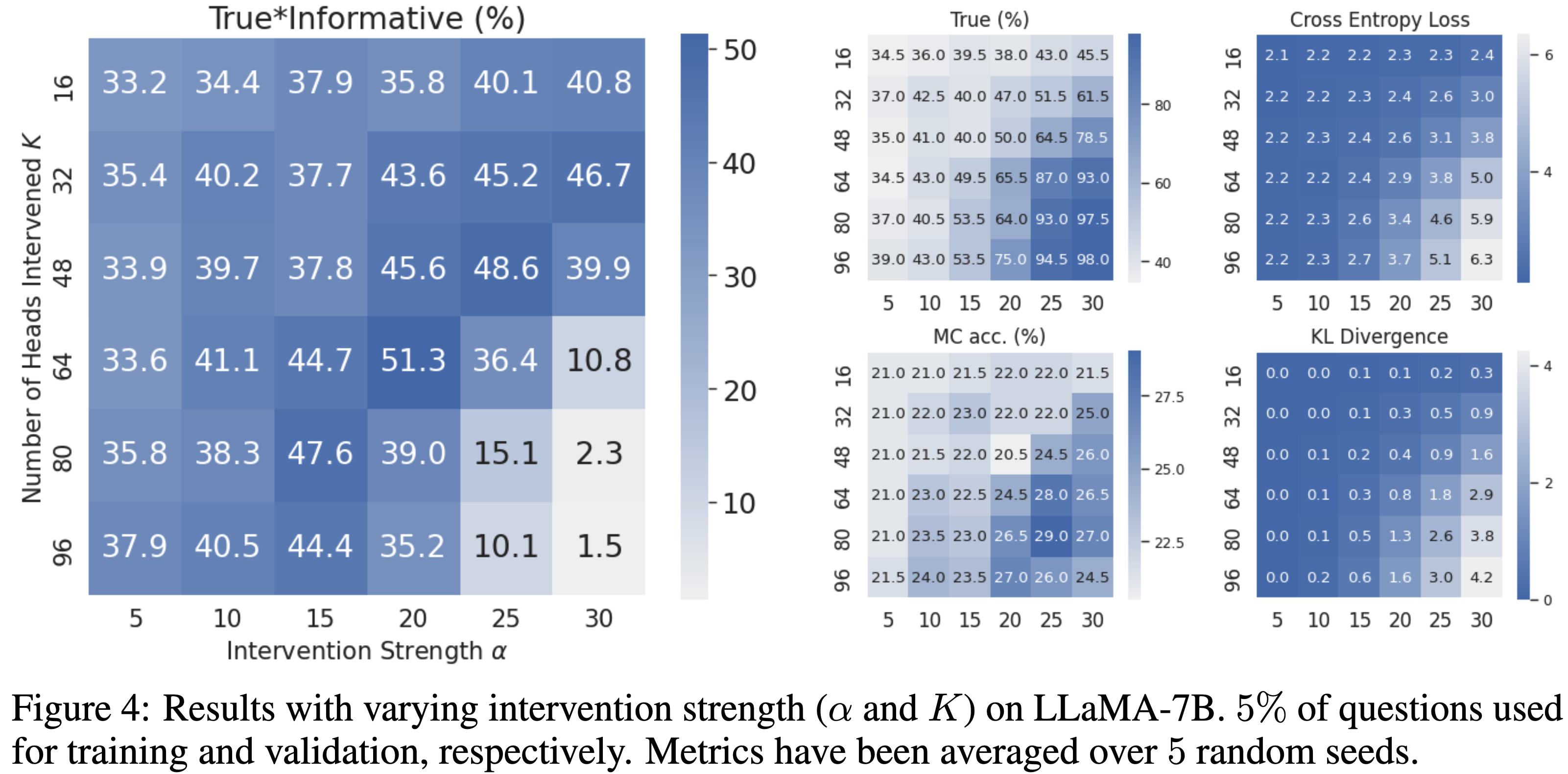
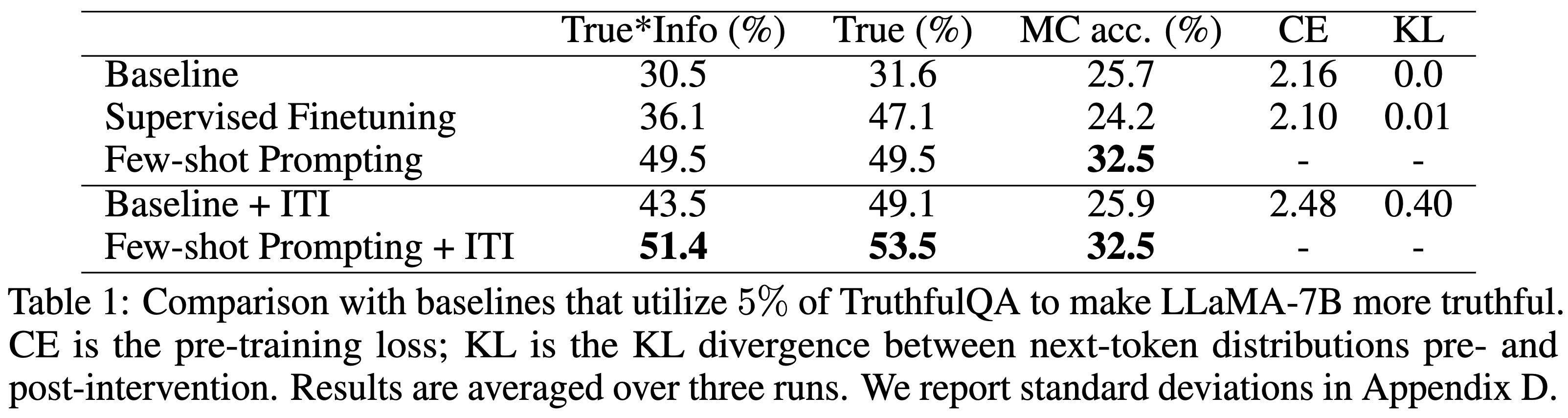
실험에서 사용한 TrueInformation 은 진실성 점수와 정보성 점수를 곱해서 산출되었다. 결과로는 ITI를 적용한 Alpaca 모델의 trueinformative 점수는 32.5%에서 65.1%로 향상되었다.
