Summary: 여러 관점의 reward모델을 만드는 것이 단순 pairwise reward model 보다 성능이 더 좋다.
Novelty: Fine-Grained reward modeling
Abstract
LM은 toxic or irrelevant output을 생성하는 경향이 존재하고 이를 완화하기위해 RLHF 등의 기술을 이용한다. 하지만 현대 RLHF는 long text에 대해 전체적인 feedback을 가져오기 때문에 어떤 측면으로 preference를 측정되어서 feedback을 주게되는지 모호해진다. (=training signal 이 모호해짐)이를 해결하기위해 본 저자는 FINE-GRADINED RLHF 라는 방식을 제안한다. 해당 방식은 reward fucntion을 2개의 관점에서 만들어서 학습하는 방식을 제안한다. 1) density, segment (sentence)단위 에서 리워드 제공 2) multiple reward type(factual incorrectness, irrelevance, information incompleteness)를 만들어서 feedback을 준다.
Introduction
reward model은 human preference 에 의해 학습되게 되고 이때 preference에는 복합적인 undesired behaviors들을 바탕으로한 판단이 진행된다. → 저자들은 이부분에 대해서 어떻게 reward model을 향상시킬 수 있을까 고민하였다.

본 논문에서는 reward 모델을 3개 (relevance, factuality and information completeness reward)를 만들어 human annotation을 통해 각 특성에 맞는 부분에 대해 rm을 학습하게 한 후 language model 학습에 사용했다고 한다. 해당 방식에 대한 평가로는 detoxification과 long-form question answering 데이터셋을 사용했다.
Method
Language Generation as a MDP
Markov Decision Process 로 이루어져있고
언어모델에서 input prompt 를 로 하고, 이는 initial state space가 된다.
Action 의 경우 모든 생성된 토큰에 대해 annotation진행한다. model이 생성한 output 이다.
전이 함수 는 현재 상태에서 특정 행동을 취했을 때 다음 상태로 어떻게 전이되는지를 정의 → .
end of state는 로 나타낼 수 있다.
Learning algorithm: PPO
PPO는 가오하학습에서 actor-critic 알고리즘으로 지속적인 성능향상을 위한 TRPO 알고리즘을 변형한 형태이다.
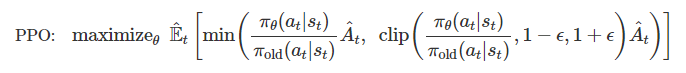
PPO는 objective term의 경우 최대화 하는 방향으로 학습하면서, cliping(penalty term) 을 최소화 하는 것을 objective function 으로 사용한다.
Advantage function ( ) 는 value function의 불안정성을 낮추기 위한 방식으로 현재 state의 value값에서 이전 state의 value값을 뺀다(평균 value 값을 빼기도 한다).
Fine-grained reward models
특정 reward model 에 대해 segment로 나눈 단위를 로 표기하고 이는 output에 대해 로 표기할 수 있다. 이는 reward model의 성격에 따라 span이 달라질 수 있다.
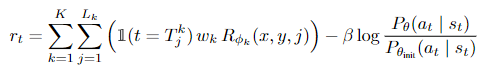
해당 논문에서 각 reward model에 해당하는 각 span에 대해 전체 합을 바탕으로 정의하고 KL div 를 통해 penalty term으로 만들었다.
TASK1 Experiment
Detoxification Experiement
해당 실험은 fine-grained reward model의 유효성을 측정하기 위해 진행한 실험으로 보여진다. GPT-2모델을 이용해 sentence-level로 짤라서 reward를 주었고, 이때 reward model은 REALTOXICITY PROMPT 데이터를 바탕으로 PERSPECTIVE API를 이용했다.
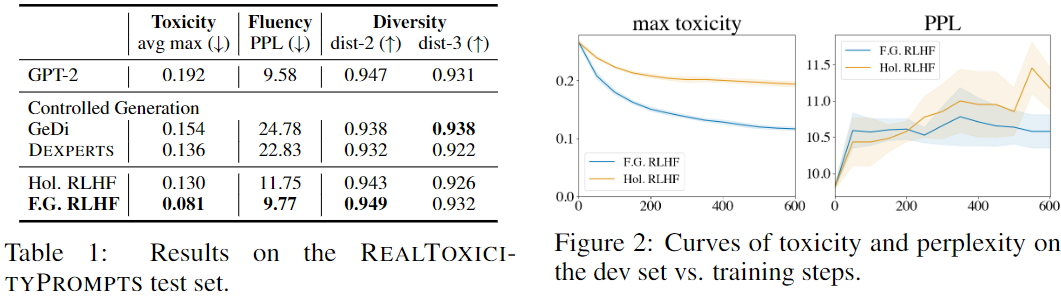
저자들은 RLHF 학습했을 때 fine-grained 로 진행하는 것이 toxicity를 더 낮추게 학습할 수 있고 이때 PPL도 상대적으로 더 낮은 것을 볼 수 있다고 주장한다.
TASK2 Experiment
Long-Form Question Answering
reward model을 더 세분화해서 만들기 위해 : irrelevance, repetition or incoherence, : incorrect or unverifiable facts, : incomplete information 을 기준으로 reward model을 설계했고 각각 segment, sentence, total output 단위로 나눠서 진행했다.
해당 reward model 학습 데이터셋을 만들기 위해 worker에게 에러타입을 만들게한다. 또한 LM model 학습을 위한 preference 데이터를 만들기 위해 model 에서 4개의 output을 만들고 reward를 annotation 하지 않은 상태에서 worker에게 6개의 preference를 생성하게 했다.
데이터셋에서 에러 타입별 overlab되지 않게 하는 과정을 진행한다. (이유는 나와 있지 않으나 reward model 학습할 때 모호성을 완전히 제거하기 위한 작업으로 생각.)
Fine-Grained Reward Models
type error는 sub-sentence 단위로 나눠서 진행이 되며 나눈 sub-sentence에 각각 요소에 [SEP]토큰을 넣어 분류를 진행하게 했다. → [sep] 토큰은 에러 여부를 확인하게 되고, 나온 reward 값에 에러가 존재하지 않을 때 +1을 주고 그렇지 않은 경우에 -1을 준다.
type error는 sentence level에서 위와 비슷하게 이뤄진다. 또한 저자들은 에서 에러가 존재하는 경우는 에서 annotation을 진행하지 않도록 했다. 만약 에 error가 있는 라벨이 존재하면 type에서는 reward model학습에 사용하지 않았다고 한다.
type error는 전체 sentence의 완성도를 보기 위한 loss이다. 해당 loss는 pair wise loss형태로 만들어 objective function으로 사용했다.
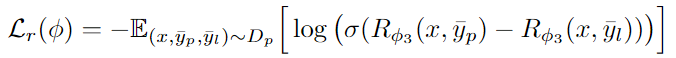
은 에 비해 적게 missed information을 가지고 있는 model output을 의미한다.
Experiment Setup
policy model: T5-large, reward model: encoder-only longformer-base
SFT: 1K example로 학습한 모델
Preference RLHF: 2.8K example 로 SFT모델을 바탕으로 학습한 모델
SFT-FULL: RLHF학습한 데이터 까지 SFT로 사용해서 학습한 모델
Evaluation: 200개의 QA-FEEDBACK example을 바탕으로 human evaluation을 진행했다.

해당 실험은 human evaluation으로 진행한 것으로 error rate을 측정하였다. 다 좋게 나온 것은 아니지만 win/tie/loss 에선 가장 좋은 수치가 나왔다고 한다.
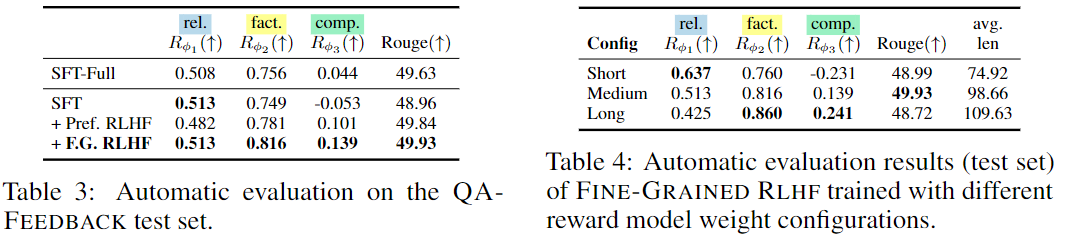
해당 실험은 reward model에서의 평가가 어떤식으로 나오나 본 것으로 당연히 해당 리워드 모델로 학습되 가장 좋은 점수가 나오는 것을 확인할 수 있다.
또한 Table4에서는 reward model weight를 변경했을 때 나오는 점수로 , , 로 변경했을 떄 각각 shot, medium, long으로 누구해서 보았다. 저자들은 short으로 생성하는것이 relevance에서 좋은 점수가 나오고 factual에서는 long의 형태가 더 좋은 점수를 가져온다고 한다.
저자들은 이 본문 내용과 관련없는 부분에 대해 패널티를 주게 되므로 값이 높을 경우 direct하게 (짧게) 답변을 가져온다고 주장한다. 또한 모델 생성길이가 짧아질수록 완성도 부분과 fact 부분에서는 떨어진다고 주장한다. (완성도는 이해가 가지만 factual은 왜 떨어지는지 이해가 안감…)
Analysis
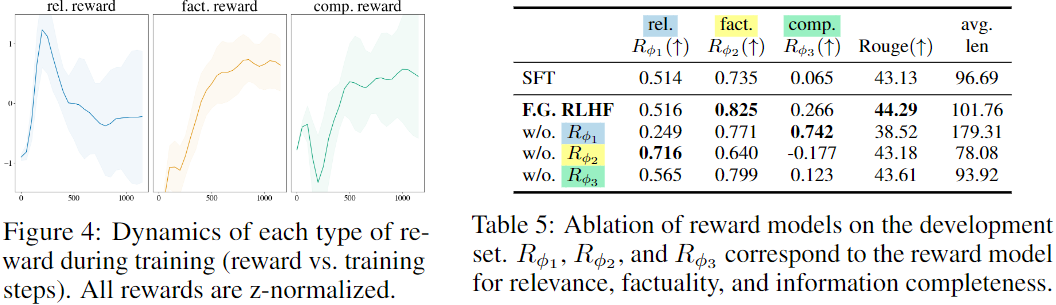
figure4 에서는 reward 모델이 training동안 변하는 dynamic를 나타내고 Table 5는 ablation study를 나타낸다. 본 저자는 rel reward ↔ fact reward (앞에서 언급함), rel reward ↔ comp reward 상충되는 고나계가 있다고 주장한다 (Table5에 이를 뒷받침하는 실험 결과가 나옴).
Reward Model Performance
rel reward acc: 0.696
fact reard acc: 0.778
comp reward acc: 0.709
