Abstract, Introduction
polysemanticity 는 모델 내부 지식을 파악하는데 어려움을 준다. 이런 polysemanticity 가 발생한 원인으로 보는 가설인 superposition은 하나의 neural network가 여러 표현을 overcomplete하게 학습되어 발생된 것이라는 보는 이론이다. 여기서 sparse autoencoder를 이용해 LLM의 activation space를 만드는 과정을 시도하였다. autoencoders 는 set of sparsely activating features 를 학습하게 되고 이는 해석가능성과 monosemantic 하게 만들어준다.
모델들은 그들이 가진 feature보다 더 많은 representation을 학습한다 (가정). 이 현상을 superposition 이라고 부른다. vector space가 많은 orthogonal vector로 구성되어 있기 때문에 네트워크는 non-orthogonal features의 basis를 학습할 수 있다. superposition이 발생하기위해서는 충분히 희소하게 활성화 되어야 한다. 희소성이 높지 않으면 non-orthogonal 간의 간섭으로 인해 superposition으로 인한 성능 향상이 방해를 받는다.
TAKING FEATURES OUT OF SUPERPOSITION WITH SPARSE DICTIONARY LEARNING
superposition가 아닌 feature를 네트워크에서 얻기 위해 sparse dictionary learning 방식을 사용한다.
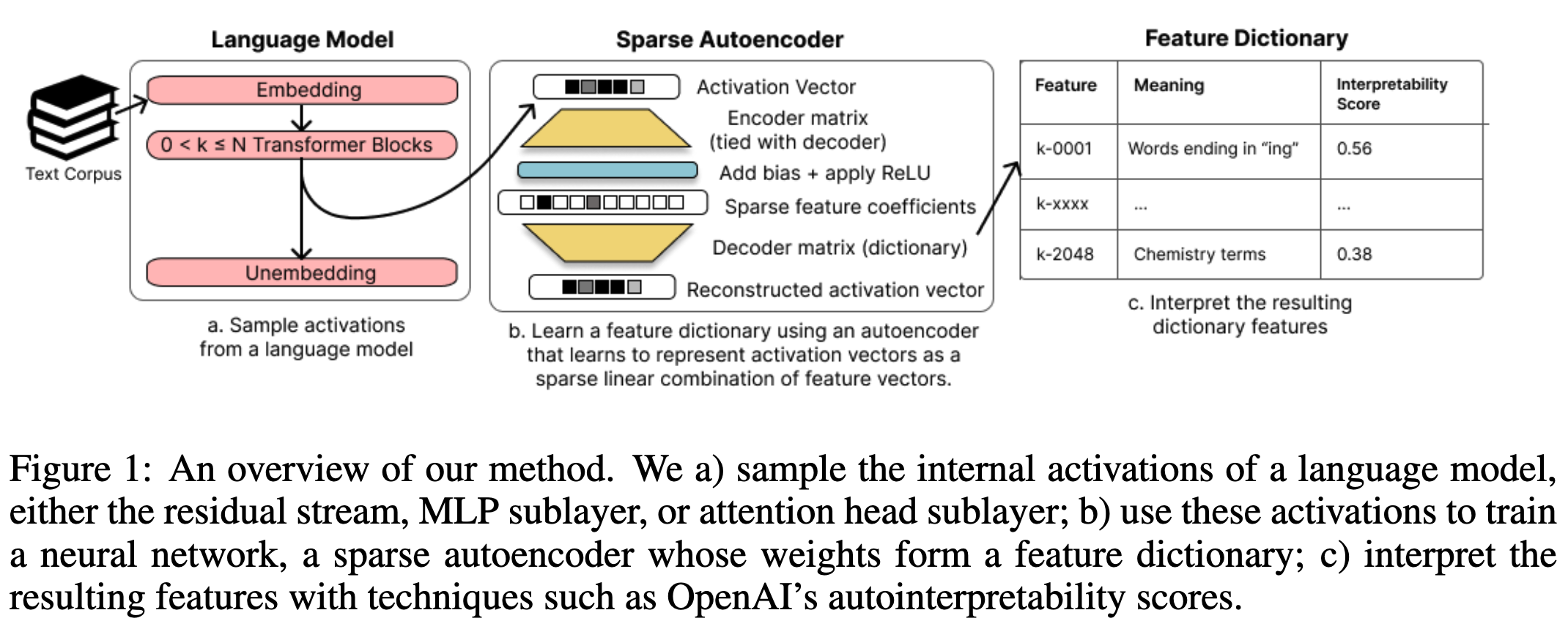
: internal activations of LM,
: ground truth network features. 가 있는 곳에 가 존재한다.
: 학습하고자 하는 것 (dictionary features)
, 는 학습된 파라미터 (wieght matrix는 encoder와 deocder가 transpose 형태로 공유한다.), M is normalized row-wise. matrix parameter
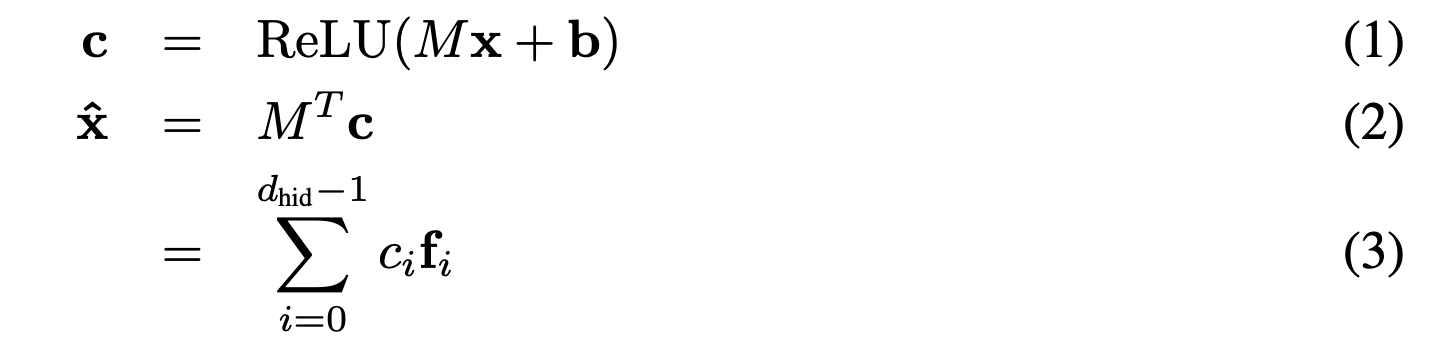
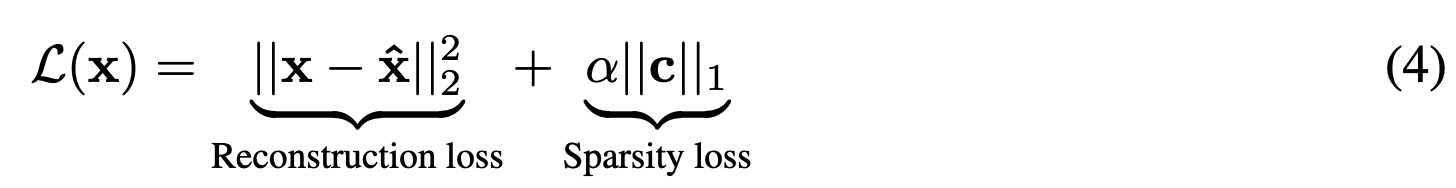
x: 모델에서나온 residual stream, MLP sublayer or attention head sublayer
M: normalized row-wise 후에 parameter matrix (feature dictionary)
: dictionary features
: hyperparameter controlling sparsity of the reconstruction
: l1 regularization loss term은 dictionary features의 선형결합을 돕는 텀이된다.
INTERPRETING DICTIONARY FEATURE
학습된 dictionary featrues의 set을 바탕으로 저자들은 polysemanticity를 감소시킬 수 있는지 그리고 해석가능한지 확인해보고자 하였다. automated measuring 방식중 OpenAI 에서 나온 방식을 사용했다. 해당 방식을 통해 measuring correlation between the model’s predicted activations and the actual activations is that feature’s interpretability score.
IDENTIFTING CAUSALLY-IMPORTANT DICTIONARY FEATURES FOR INDIRECT OBJECT IDENTIFICATION
dictionary features를 바탕으로 모델 내부 파라미터의 activation을 수정했고, 이에 따라 model’s output 변화를 관찰했다. 이때 activation patching (causal mediation analysis - manipulating the model’s internal activations to observe changes in output) 방법을 사용했다. 해당방식은 특정 feature에 causal importance를 파악하기위해 사용되는 실험이다. “We find that our dictionary features require fewer patches to reach a given level of KL divergence on the task studied than comparable decompositions.”
Adapting Activation Patching To Dictionary Features
실험을 위해 저자들은 counterfactual target sentence를 만들었다. 그러고나서 intervention이 들어갈 레이어에 original encoded features () 와 target encoded feature ()를 만들어서 두 벡터를 빼주게 된다. 는 앞서말한 dictionary feature가 되고 이렇게 수정된 벡터 를 만들어서 사용한다. 이때 는 subset of features (어디 부분에 intervention 이 들어가야하는지 나타내는 것) 을 정하기위해 ACDC 알고리즘을 사용했다.
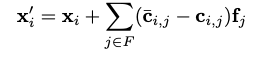
Precise Localisation of IOI Dictionary Features
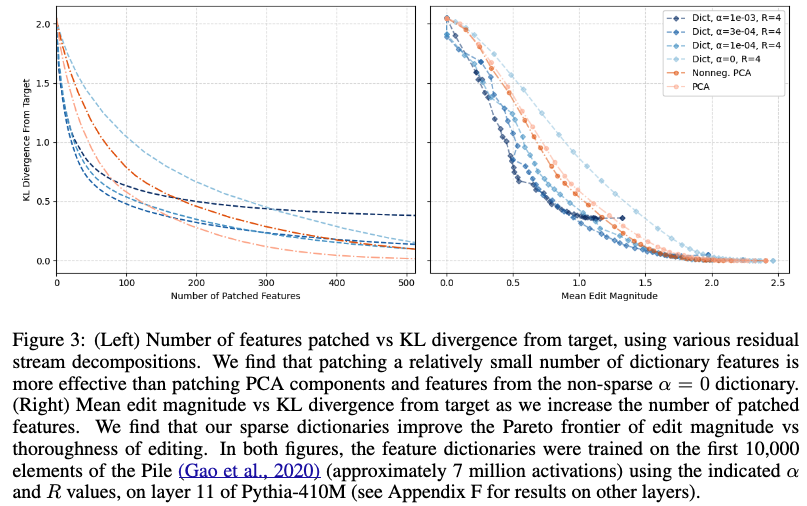
IOI task를 이용해 한 단어를 기존단어와 다르게 변경해주고 위와 같은 식을 이용해 patching 을 적용시킨다. 그 후 figure3 과 같이 변화한 정도와 patch 수를 측정하였다. KL divergence는 작을 수록 더 좋은 의미를 가짐.
Case Studies
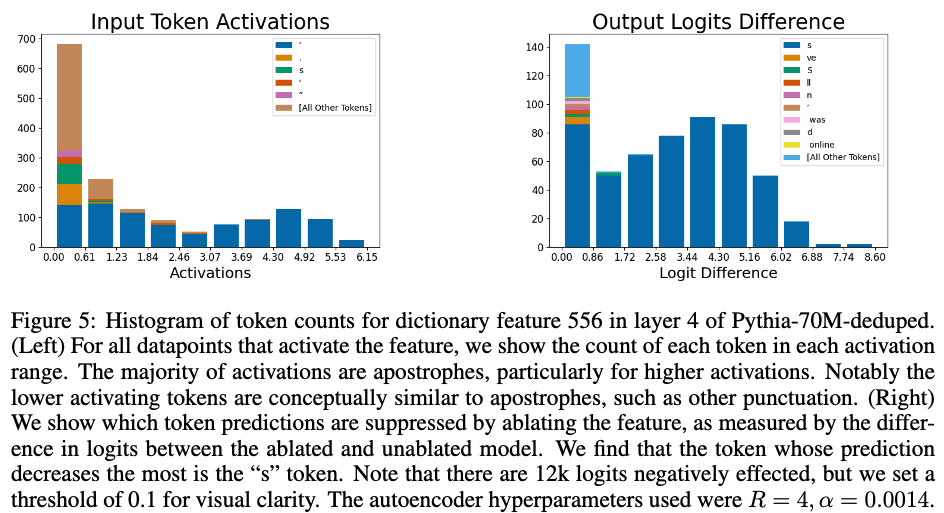
- input에 따라 어떤 token이 dictionary feature를 활성화 시키는지, 어떤 맥락에서 활성화 되는지
먼저 monosemantic dictionary feature가 잡히게 되면 특정 input에 대해 사람이 이해할 수 있는 형태로 activate 를 관찰할 수 있다. 하지만 polysemantic dictionary feature 가 잡히게 되면 input에 대해 상관없는 contexts 가 activate 되는 것을 볼 수 있다. - 어떤 feature의 변화가 output에 영향을 주는지
해당 방식으로는 figure 5에서 apostrophes 가 주는 영향을 보기위해 reisudal stream에서 오는 556 번째 neuron activate 을 삭제함으로써 output logit을 보았다. figure 5의 오른 쪽과 같이 apostrophes 대신에 s 가 활성화 되는 것을 볼 수 있다. - 이전 layer에 있는 dictionary feature가 다음 활성화되는 feature에 어떤 영향을 주는지 식별
