Summary: representation engineering (RepE): AI 시스템의 투명성을 높이기 위한 새로운 접근 방식. 해당 방법은 circuits 이나 neuron 단위가 아닌 representation에 집중
INTRODUCTION
representation engineering (RepE): AI 시스템의 투명성을 높이기 위한 새로운 접근 방식.
This approach to enhancing the transparency of AI system that draws on insights from cognitive neuroscience. 해당 방법은 circuits 이나 neuron 단위가 아닌 representation에 집중한다.
Representation Reading
- Linear Artificial Tomography (LAT): representation을 읽어내는 방법
Representation Control
- 읽어낸 representation을 바탕으로 model output을 제어한다.
- 이 과정에서 단순한 linear combination, transparency and 조각별 연산? 을 사용한다.
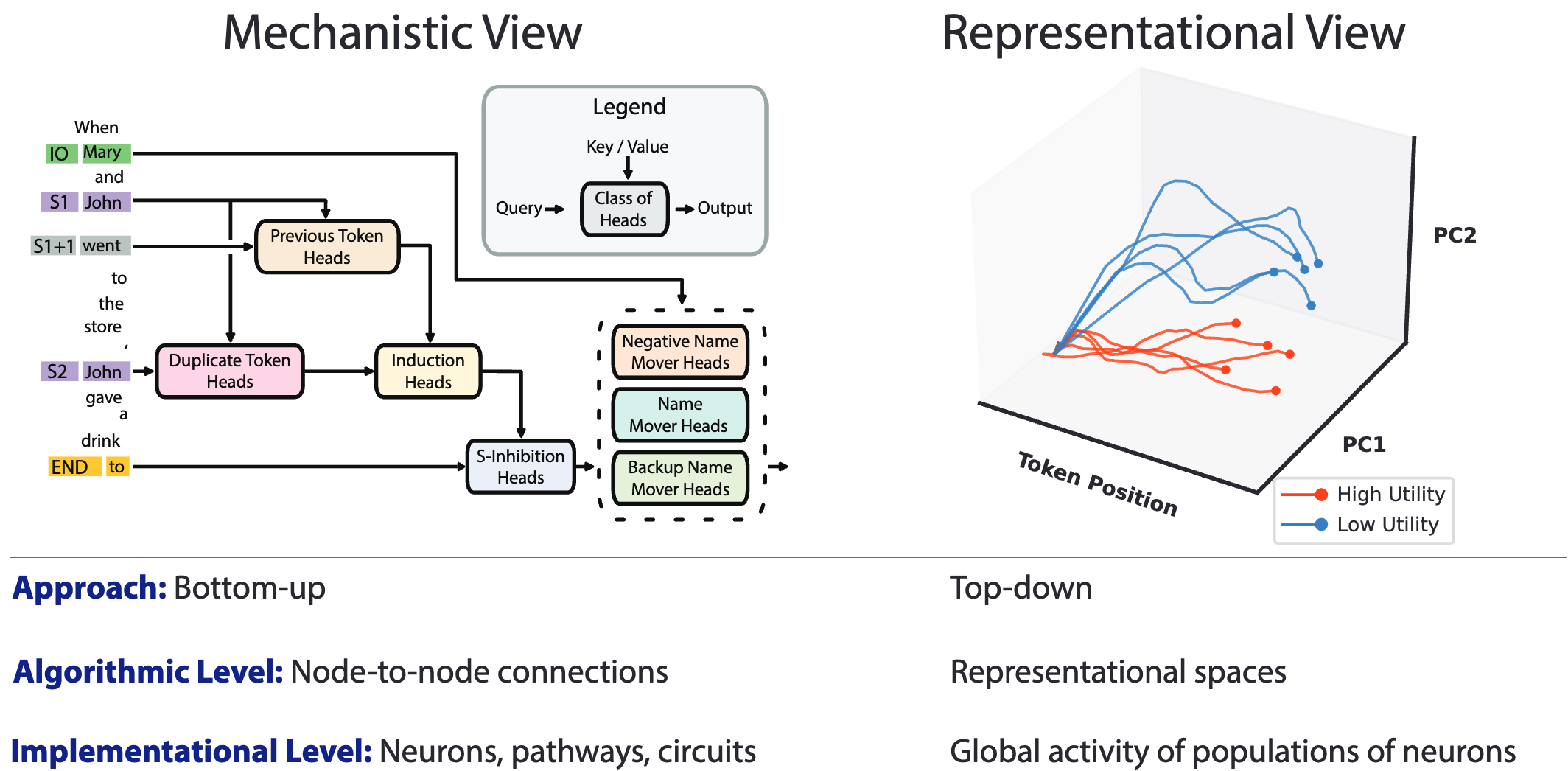
- Sherringtonian view: see cognition as the outcome of node-to-node connections implemented by neurons embedded in circuits within the brain.
- Hopfieldian view: Rather than focusing on neurons and circuits, the Hopfieldian view sees congnition as a product of representation spaces, implemented by patterns of activity across populations of neurons.
RELATED WORK
APPROACHES TO INTERPRETABILITY
Saliency Maps: 데이터의 어떤부분이 출력에 얼마나 영향을 미치는지 파악하는 방법
Feature Visualization: input에 대해 모델의 어떤 부분이 활성화 되었는지 체크하는 방법. 이를 통해 input형태를 변경하여 특정 계층의 활성화시키는 입력패턴을 찾아내는 방식
Mechanistic Interpretability: circuits 를만들어 node-to-node 로 활성화가 연결되는 것을 확인해서 설명가능한 neural network를 만드는 방식.
REPRESENTATION ENGINEERING
RepE는 top-down 방식으로 high-level cognitive phenonmena 를 이해하고 제어하기위한 방식이다.
REPRESENTATION READING
Representation reading은 high-level concepts으로 어떤 representation이 발생한 위치를 찾는 방식이다. 그리고 기능적으로 어떤 역할을 하는지 알아내는 과정이다.
BASELINE: Linear Artificial Tomography (LAT) - 3개의 스텝으로 이뤄져 있다.
1) Designing Stimulus and Task: 어떤 찾아내고자하는 기능이나 개념이 활성화되는 neuron을 뽑아내기위한 과정. (Capture concepts)

2) Collecting Neural Activity: 다양한 토큰 position에 있는 distinct representation을 얻기위한 과정으로 step1 에서 부분에 해당하는 token의 activity를 모으기 위함.
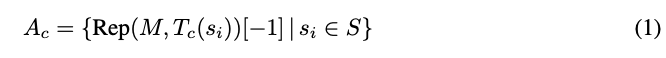

위의 수식에서 Rep 함수(=function )는 token에 대해서 representation을 뽑아내는 함수이다. A 로 표기된 것은 각각의 활성화 벡터를 의미한다.
3) Constructing a Linear Model: linear 모델 (probing, cluster mean, PCA, k-means)을 사용한다. 이를 바탕으로 prediction 하기위해 reading vector 와 representation vector 를 dot product하게 한다.
reading vector, = // representation vector =
REPRESENTATION CONTROL
Baseline1 - Reading Vector: LAT 방식에서 나온 representation을 사용한다. 이는 같은 direction이 같은 방향에 있는 경우 perturbation 이 발생할 수 있고 이는 효과적이지 않다고 말한다.
Baseline2 - Contrast Vector: Contrastive pair 를 바탕으로 inference동안에 넣어주는 과정. 여기서 cascading effect 라는 것을 말하는데 해당 벡터를 layer앞단에 넣어주는 경우 후반layer로 갈수록 효과가 미미해진다는 것을 의미한다. 이를 해결하기위해 각 타겟 레이어마다 반복적으로 해당 과정을 연산해줘버린다.
Baseline3 - Low-Rank Representation Adapator (LoRRA): 아래와 같은 알고리즘을 바탕으로 학습을 진행한다고 함.

Experiment