
1.Abstract
- BERT is designed to pre-train deep bidirectional representations from unlabeled text jointly conditioning on both left and right context in all layers
- pre-trained BERT model can be fine-tuned with just one additional output layer to create state-of-the-art models for a wide range of tasks
- It obtains new state-of-the-art results on eleven natural language processing tasks
2.Introduction
-
Two existing strategies for applying pre-trained language representations
- Feature-based : ELMo (Peters et al., 2018a), uses task-specific architectures that include the pre-trained representations as additional features. feature-based downstream task는 미리 학습된 언어 모델에서 추출한 feature를 이용하여 다운스트림 태스크를 수행하는 방식. 이 방식은 전체 모델을 fine-tuning하는 것과 달리, 사전 학습된 모델의 중간층에서 feature를 추출하여 이를 입력으로 사용
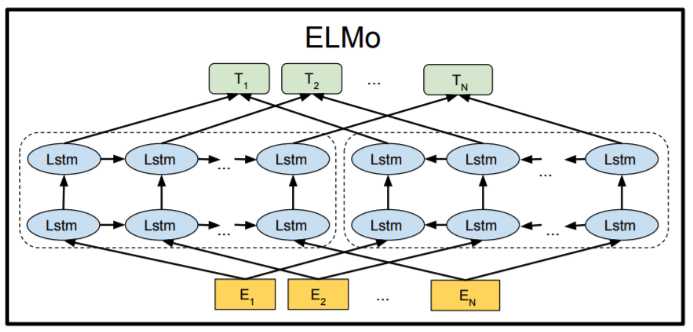
- Fine-tuning : Generative Pre-trained Transformer (OpenAI GPT) (Radford et al., 2018), introduces minimal task-specific parameters, and is trained on the downstream tasks by simply fine-tuning all **pre-trained parameters
- 둘의 차이점 : 전체 모델을 학습하는 방식과 중간층에서 feature를 추출하여 사용하는 방식의 차이
- fine-tuning-based downstream task에서는 전체 모델을 fine-tuning하여 downstream task 에 맞게 학습합니다. 따라서 fine-tuning-based downstream task는 feature-based downstream task보다 학습 시간이 더 오래 걸리며, 데이터 양과 성능 사이에 trade-off가 존재
- feature-based downstream task는 사전 학습된 모델에서 추출한 feature를 이용하므로 학습 시간이 덜 걸리며, 적은 데이터로도 높은 성능을 발휘할 수 있습니다.
- Feature-based : ELMo (Peters et al., 2018a), uses task-specific architectures that include the pre-trained representations as additional features. feature-based downstream task는 미리 학습된 언어 모델에서 추출한 feature를 이용하여 다운스트림 태스크를 수행하는 방식. 이 방식은 전체 모델을 fine-tuning하는 것과 달리, 사전 학습된 모델의 중간층에서 feature를 추출하여 이를 입력으로 사용
-
unidirectional model is very harmful when applying fine-tuning based approaches to token-level tasks
⇒ NER(Named Entity Recognition)과 같은 token-level tasks에서는 각 토큰이 속한 개체(entity)가 어떤 것인지를 판별해야 합니다. 만약 unidirectional 모델을 사용한다면, 이전 토큰에 대한 정보를 현재 토큰에 전달할 수 없기 때문에 개체를 정확하게 인식하는 것이 어려울 수 있습니다. → unidirectional 모델보다 bidirectional 모델을 사용하여 token-level tasks를 수행하는 것이 더 나은 성능을 얻을 수 있다고 주장
-
To alleviate previous unidirectionality constraint → by using MLM(Masked-Language-Model)
MLM : randomly masks some of the tokens from the input, and the objective is to predict the original vocabulary id of the masked word based only on its context.
-
enables the representation to fuse the left and the right context
+) using next sentence prediction task → BERT는 두 문장 간의 상호작용을 이해하는 능력을 향상시킬 수 있다.
→ MLM과 next sentence prediction task를 동시에 수행하여, 문장 내에서의 단어 임베딩과 두 문장 간의 관계를 이해하는 능력을 동시에 학습 ⇒ 다양한 downstream NLP 태스크에서 뛰어난 성능
-
Related work - 앞선 연구들의 문제점 지적
- ELMO - NLP 몇몇 성능지표(QA, sentiment analysis, NER)에서 SOTA 성능을 뽑아냈지만, model is feature-based and not deeply bidirectional,
Unsupervised Fine-tuning 부분에서 두가지 접근법이 나옴
- 기존 언어 모델을 다운스트림 태스트에서 fine-tuning 하는 것 → 다양한 테스크에서 pre-trained 모델을 사용을 통해 좋은 성능을 뽑을 수 있다. ex) GPT
- scratch 접근법은 pre-training없이 언어 모델을 학습하는 것 → 즉, 처음부터 학습하는 것으로 BERT아키택처를 이용해 새로운 모델을 만드는 것을 의미.
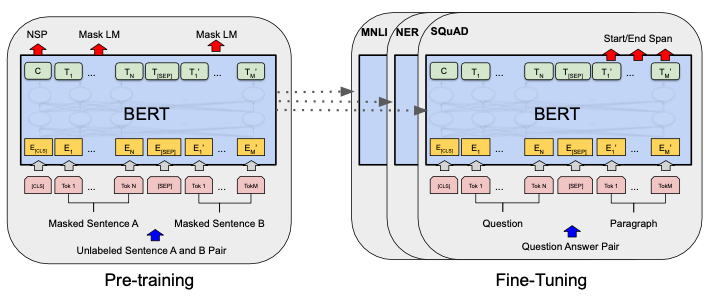
3.BERT
There are two steps in BERT framework: pre-training and fine-tuning
Model Architecture
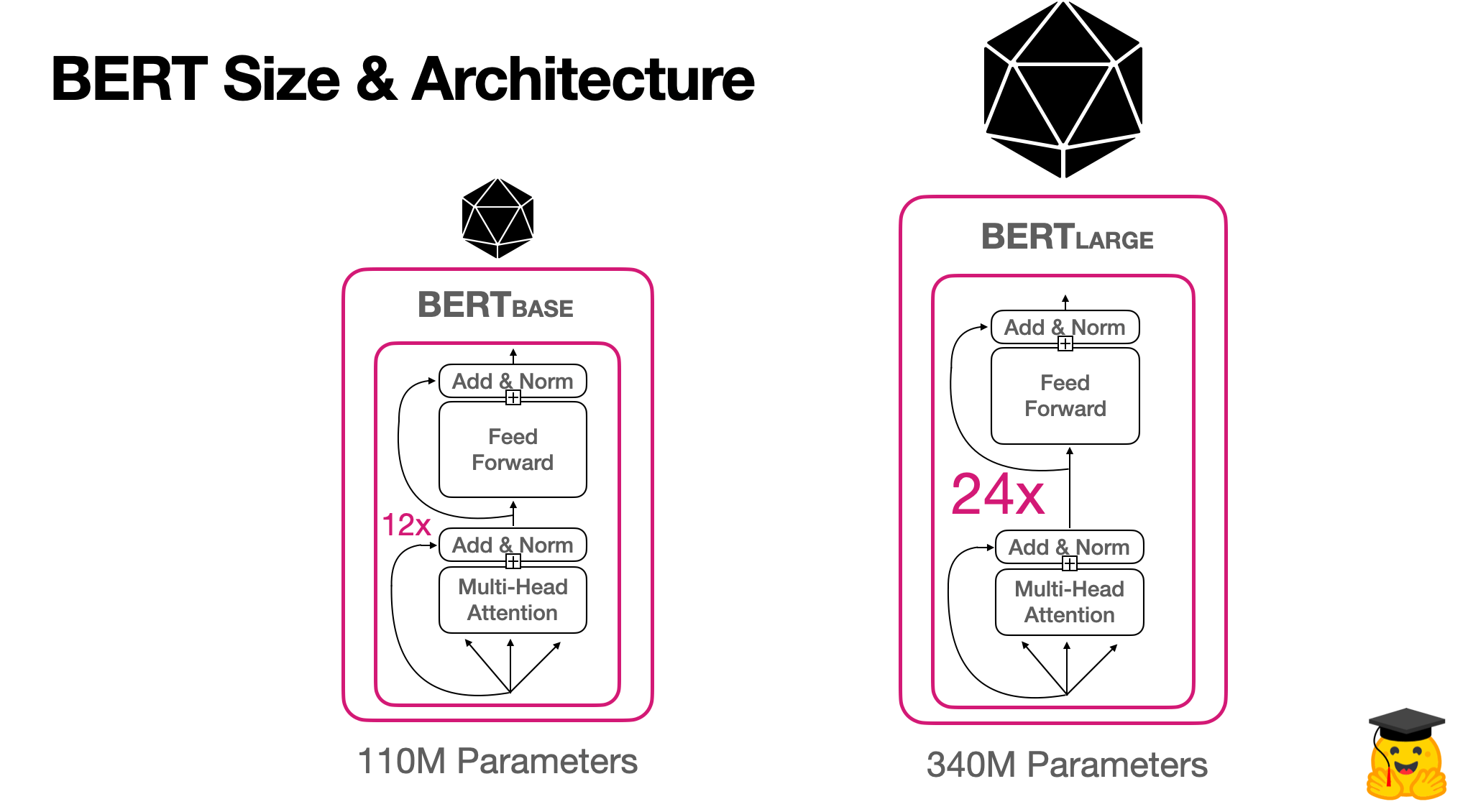
BERTBASE (L=12, H=768, A=12, Total Parameters=110M) and BERTLARGE (L=24, H=1024, A=16, Total Parameters=340M).
BERT베이스 모델은 GPT 아키텍처와 성능비교를 하기위해 동일한 파라미터로 설정
Input/Output Representations
BERT use worldpiece embedding(언어에 상관없이 적용할 수 있는 embedding 방식)
첫 번째 토큰은 [CLS] 토큰으로 시작, 다른 문장이 들어 올때는 [SEP]로 구분
3.1 Pre-training BERT
- Task 1 : (MLM)Masked Language Model → 버트 모델의 문맥을 파악하는 능력 학습 15% of the words to predict
-
80% of the time, replace with [MASK]
-
10% of the time, replace with a random word → 난이도를 높여준 것
-
10% of the time, keep the sentence as same
→ 80,10,10 으로 나누는 이유 : fine-tuning에서는 mask시키지 않아 pre-training과정과 어긋나는 현상이 발생하는데 이를 완화 시키기위해 mask 토큰을 모두 바꾸는 것이 아닌 일부는 랜덤하게, 그리고 일부는 변형되지 않는 원래 단어를 사용한다.
-
- Task 2 : Next Sentence Prediction (NSP) - QA, NLI(Natural Language Inference), NLU(Natural Language Understanding) are based on understanding the relationship between two sentence - 두 문장간의 연관성을 파악해 두 문장이 무관한 문장인지 아닌지를 예측하는 학습과정 → 이를 통해 문장의 의미를 이해하는데 도움이 되는 task
- Pre-training data : BooksCorpus (800M words), English Wikipedia (2,500M words) - 헤더, 리스트 같은건 빼고 본문만 발취함.
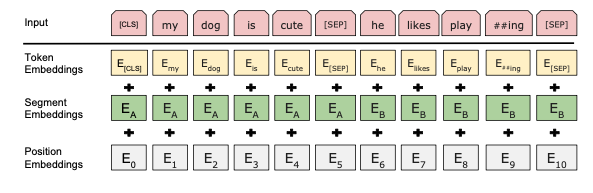
transformer 에서는 position embedding 부분이 들어갔었는데 bert에서는 문장간의 구분을 위한 embedding을 추가하면서 인코딩을 진행하였다. ( 경험적으로 성능이 증가한다고 한다. )
3.2 Fine-tuning BERT
- Fine-tuning은 사전 훈련된 BERT 모델을 특정 task에 맞게 조정하는 과정. 다양한 자연어 처리 태스크, 예를 들어 문장 분류, 질문 응답, 개체명 인식 등에서 사용
- For each task, we simply plug in the task- specific inputs and outputs into BERT and fine- tune all the parameters end-to-end. 각 작업에 대해 모든 입출력 버트에 연결 및 종단간 미세조정을 진행
- (논문 외) 영어로 pre-training 시킨 모델에 한국어 모델을 학습시켜도 좋은 정확도가 나온다.
4. Experiments
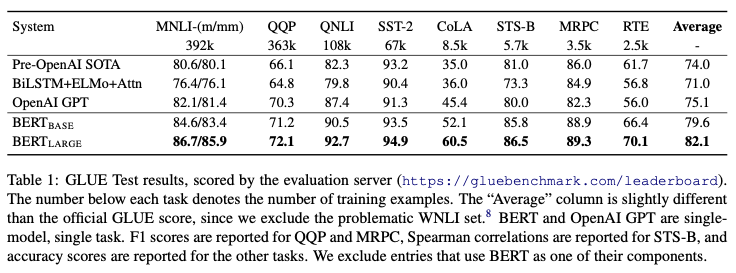
We use a batch size of 32 and fine-tune for 3 epochs over the data for all GLUE tasks. For each task, we selected the best fine-tuning learning rate (among 5e-5, 4e-5, 3e-5, and 2e-5)
5. Ablation Studies
5.1 Effect of Pre-training Tasks
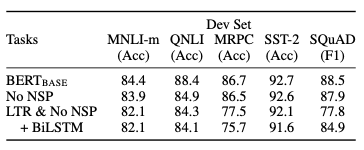
BERT base에서 몇가지 기술들을 빼면서 비교를 진행해본 결과
No NSP :양방향 학습 모델 에서 NSP를 뺀 것
LTR & NO NSP : Left to Right, 에서 NSP를 뺀 것
BiLSTM : 양방햑 학습모델
→ NSP가 가저온 영향을 보여주는 지표
5.2 Effect of Model Size
언어 처리 분야에서는 모델이 클 수록 성능이 향상된다는 것이 잘 알려져 있었음.
→ largest Transformer explored in Vaswani et al. (2017) is (L=6, H=1024, A=16) with 100M parameters for the encoder, the largest Transformer we have found in the literature is (L=64, H=512, A=2) with 235M parameters (Al-Rfou et al., 2018).
이 둘과는 대조적으로 버트베이스는 110M paramerter로 SOTA모델을 만들었다.
5.3 Feature-based Approach with BERT
feature-based 접근방식의 버트를 소개하면서 feature-based의 장점을 말
- transformer인코터 아키텍처로 모든 작업을 쉽게 표현할 수 있는 것이 아니므로 작업별 모델 아키택처를 추가해야한다는 점이 있다.
- feature-based는 Fine-tuning에 비해 계산상의 이점이 존재한다.
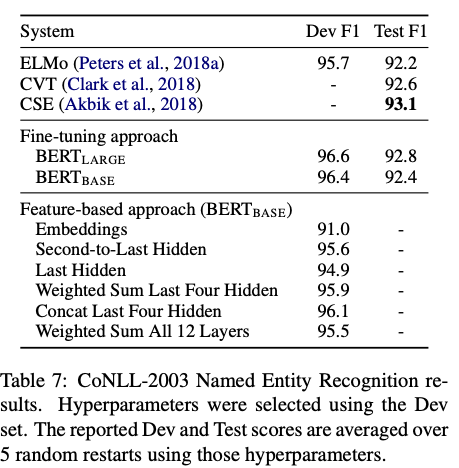
위의 표에서 나타나듯이 BERT는 모델 아키택쳐 적으로 뛰어난 성능을 내고 있으며 특히 fine-tuning을 적용했을 때 매우 효과적임을 나타낸다.
