Abstract
unbalanced training data distribution으로 인해 En편향성을 갖는다.
⇒segmentic alignment across language 통해 해결하려함
모델성능은 alpaca와 비교했을 때 평균 42.5%(단, 실험이 번역 실험임)가 나옴
비 영어권 data를 통합해서 학습시켰을때 학습이 boosting되는 것을 확인(non-En ability)
실험은 모두 번역 task 쪽으로 성능 측정
Introduction
대부분 영어로 학습이 진행되고 LLM 또한 data distribution을보면 영어가 대부분을 차지함 → 다른 단일언어 성능을 높이려는 시도는 많지만 많은 양의 data와 computing이 요구된다.
해당 논문에서는 영어를 share하는 6개의 다른 언어를 선정해서 실험함.
+이 논문 실험에서는 en to non-en 을 위한 scaling law또한 제안
논문에서 주의 깊게 살펴봐야하는 내용
- cross-lingual instruction-tuning 상대적으로 쉽게 데이터를 얻을 수 있음
- 다른 여러언어로 함께 학습 → boosting
- scaling law 제안
Background
- pre-training
- instruction-tuning
Eliciting LLM’s non-English Ability

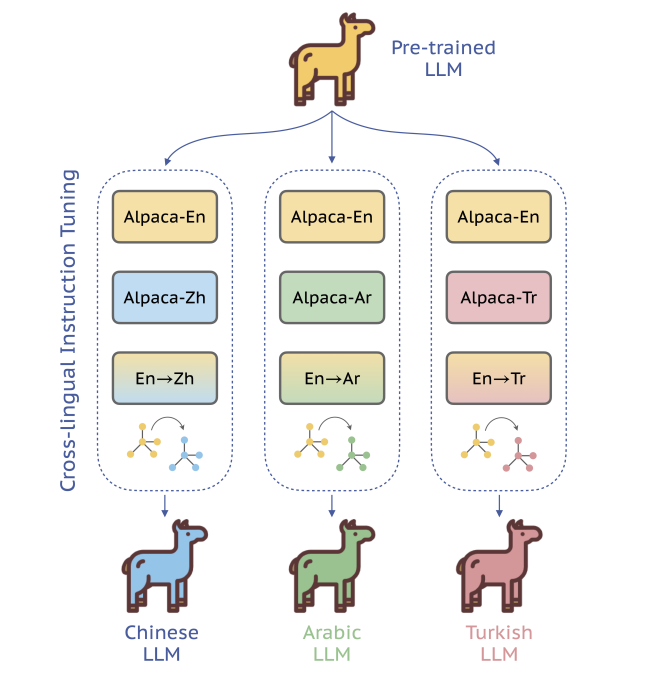
- Cross-lingual Instruction-tuning
- 번역 엔진을 사용해 두 데이터 쌍을 만든다. Translation task instruction data
- 두 언어 pair 쌍을 랜덤으로 뽑아내 결과가 나오게 한다. ( 반드시 target언어가 output이 아니다) 섞어서 진행했을 때 더 결과가 좋았음
- 번역 엔진을 사용해 두 데이터 쌍을 만든다. Translation task instruction data
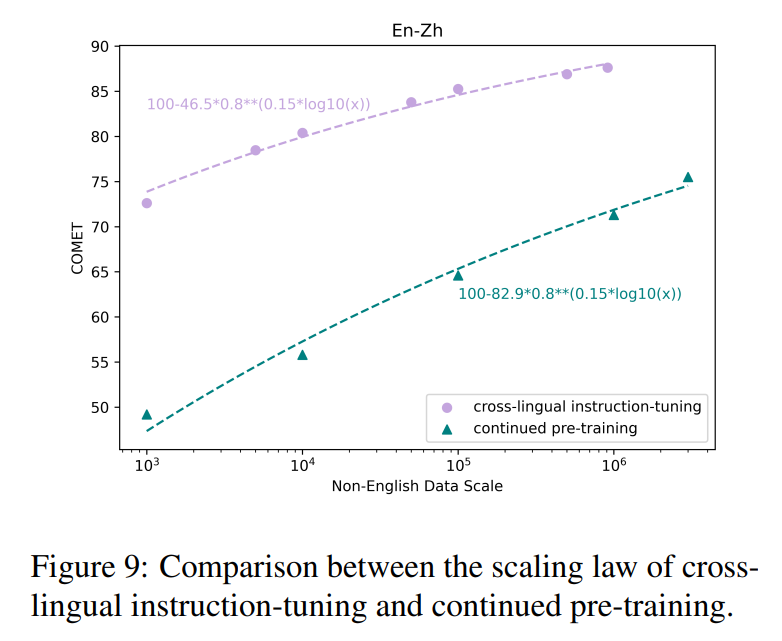
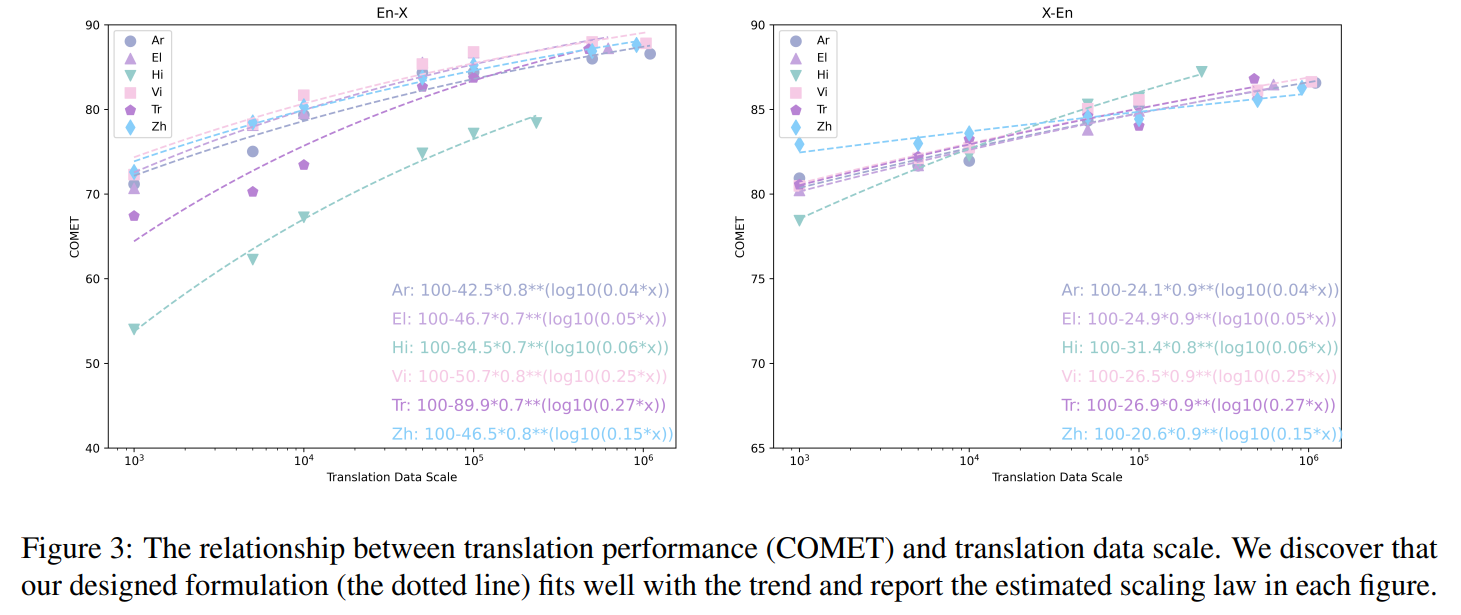
- Scaling Law of cross-lingual Instruction-tuning
-
y : 번역 성능, x : data 규모, : 언어간 유사도, , : 추정 파라미터
-
Experiment Setting
Metrics : XQUAD, MLQA, C-EVAL
A100 X 8, FSDP 방식
Main result
- alpaca 의 non-en 대답 과 x-LLaMA비교했을 때 42.% 성능향상
- 번역성능은 M2M과 비교할 정도로 좋은 성능 - M2M(12B), x-LLaMA(7B)
- 다중 언어를 함께 학습시킬 때 boosting된다.
마지막 사진은 target단일 언어를 fintuning 시키는 (녹색) 과 cross lingual training방식을 사용한( 자주색) → 해당 논문이 유의미함을 나타냄