부스트캠프 AI
1.1주차 Python 정리

Python Variable & Memory 변수는 메모리 주소를 가지고 있으며 변수의 값은 메모리 주소에 할당된다. local variable : 지역변수, 함수 내부에서만 사용 global variable : 전역변수, 프로그램전체에서 사용 List list의
2.1주차 AI Math 정리
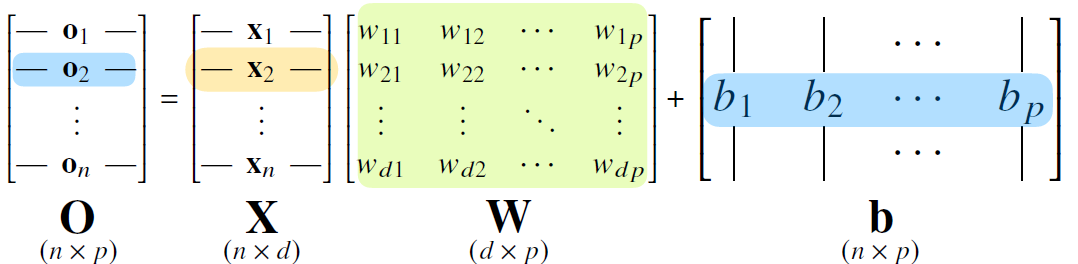
AI Math 벡터 벡터는 숫자를 원소로 가지는 list 또는 배열로써 공간의 한 점을 나타낼 때 사용한다. 벡터는 원점으로부터의 상대적 위치를 의미하며 벡터에 스칼라 곱을 하면 길이만 변한다. 음수를 곱하면 방향이 변한다. 벡터끼리의 모양이 같다면 벡터간 연산이 가
3.2주차 PyTorch 정리
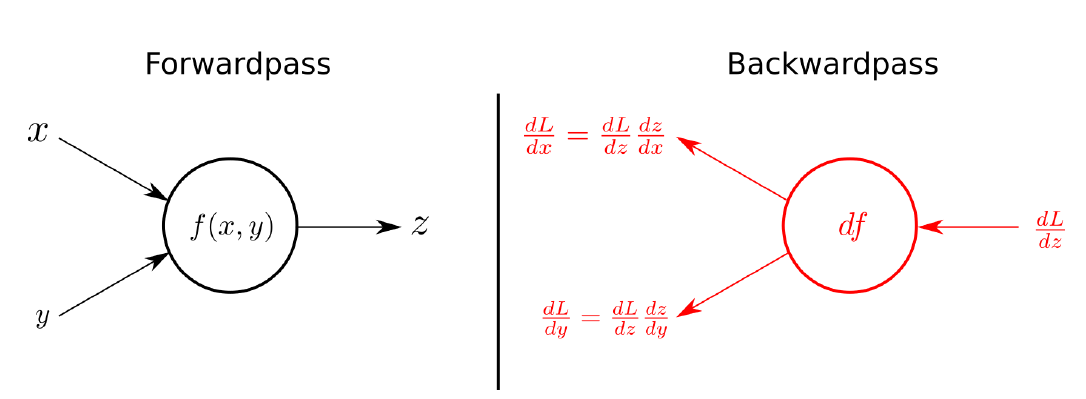
tensorflow와 함께 가장 많이 쓰이는 딥러닝 프레임워크Dynamic Computation Graph : 역전파법을 쓸 때 사용하는 AutoGrad를 할 때 실행시점에서 그래프를 정리한다.(실행을 하면서 그래프를 생성하는 방식)이런 방식으로 하면 즉시 확인이 가능
4.2주차 Model 과제정리
Tensor는 클래스, int 입력시 float로 자동변환, 데이터 입력시 새롭게 torch.Tensor를 만든 후 사용하고 입력받은 데이터의 메모리 공간 사용 tensor는 함수, int 입력시에 int 그대로 출력, 입력 받은 데이터를 새로운 메모리 공간으로 복사
5.2주차 Dataset 과제 정리
init : 데이터의 위치나 파일명과 같은 초기화 작업을 위해 동작한다. 일반적으로 CSV, XML파일과 같은 데이터를 불러온다. 여기에 이미지를 처리할 transforms들을 Compose해서 정의해둔다.len : Dataset의 최대 요소 수를 반환하는데에 사용한다
6.3주차 정리
Data Dataset 시각화를 진행하기 위해서는 Data가 필요하다. 시각화를 진행할 데이터는 데이터 셋의 관점으로 global 개별 데이터의 관점으로 local로 구분할 수 있다. 데이터의 종류는 크게 다음과 같이 나눌 수 있다. 수치형 연속형 : 길이, 무게,
7.4주차 MLP 정리
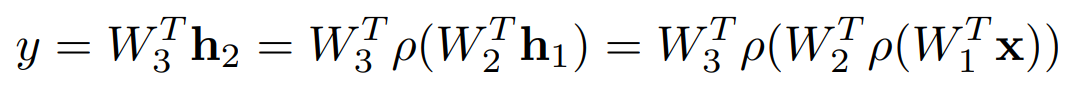
Neural Networks > 뉴럴 네트워크는 수학적이고 비선형 연산이 반복적으로 일어나는 어떤 함수를 근사하는 것이다. Linear Neural Networks 최적화 변수에 대해서 미분값을 구한다. 그리고 최적화 변수를 반복적으로 갱신한다. Beyond L
8.4주차 Optimization 정리
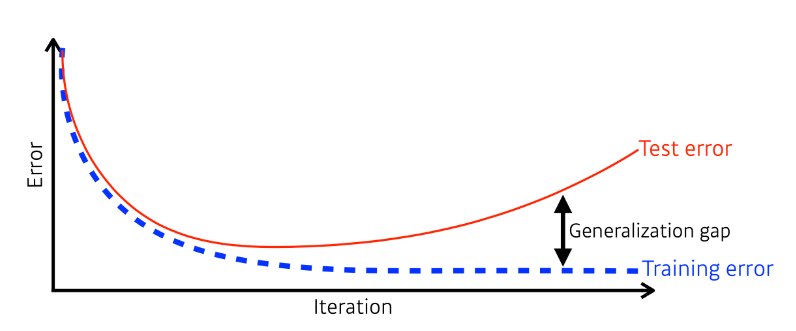
Generalization일반화는 학습 데이터로 이루어진 모델이 얼마나 테스트 데이터에서 잘 동작하는지를 나타내는 개념이다.학습이 진행될 수록 Training error가 줄어들지만 어느 정도 시간이 흐른 뒤에는 Test Error가 증가하게 된다. Test Error
9.4주차 CNN 정리
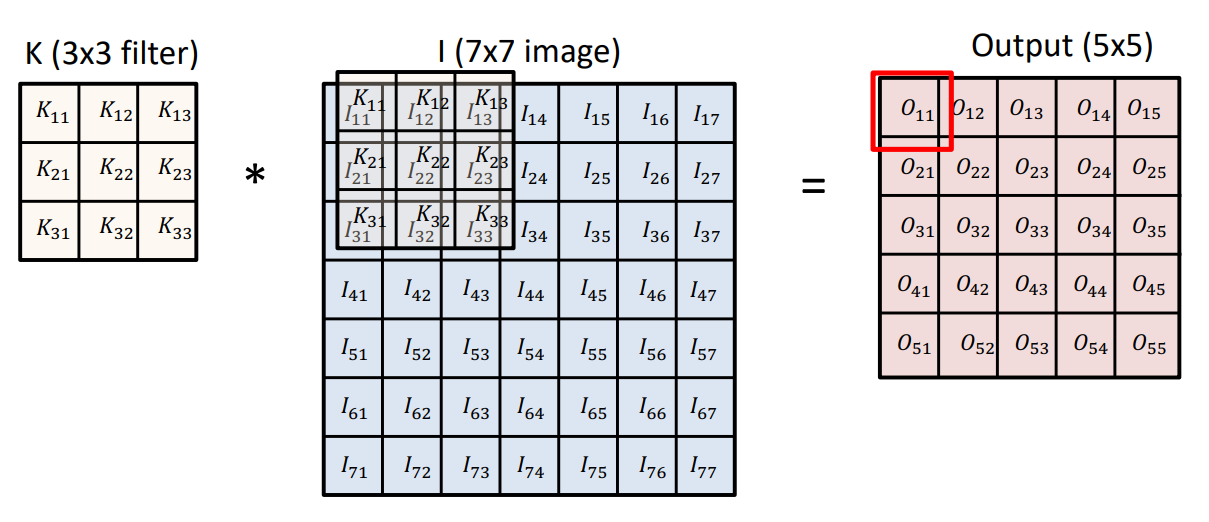
CNN은 feature값을 얻어내기 위해 합성곱 연산을 하는 convolution layer, Convolution을 거쳐 나온 activation map이 있을 때 이를 이루는 convolution layer를 resizing 하여 새로운 layer를 얻는 pooli
10.4주차 RNN 정리
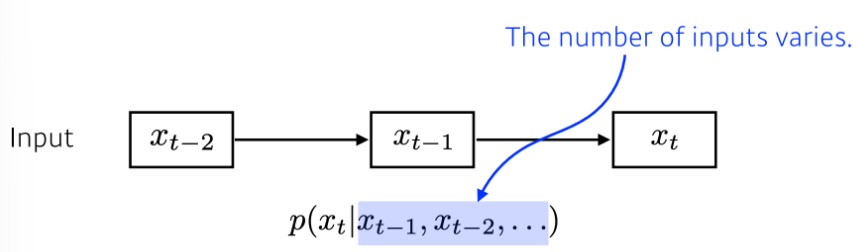
주식이나 언어 영상 등과 같이 고정된 차원의 데이터가 아닌 시간에 따라 데이터가 입력이 되는 시계열 데이터를 Sequential Data라고 하고 이에 동작하는 모델을 Sequential Model이라고 한다. 언어의 경우 첫 번째부터 n번째 등장하는 단어들을 모두 고
11.4주차 Computer Vision Applications
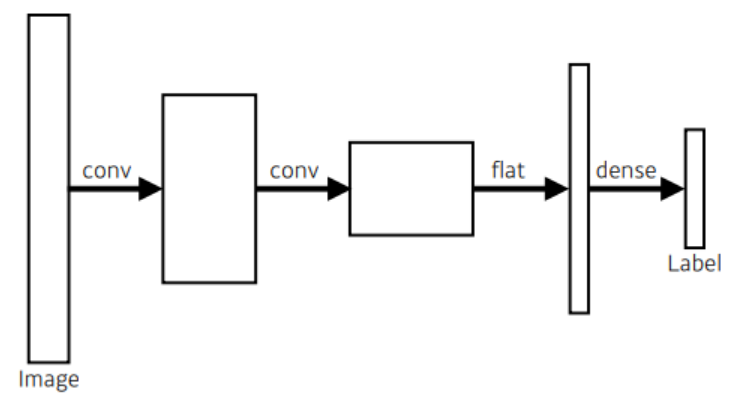
어떤 이미지가 있을 때 각 픽셀마다 분류를 하는 것으로 강아지 고양이 이런식으로 분류하는것이 아니고 이미지의 모든 픽셀이 어떤 라벨에 속하는지 예측하는 것이다.보통의 CNN 구조는 다음과 같은 구조를 따르게 된다.반면 Fully Convolutional Network는
12.4주차 Transformer 정리
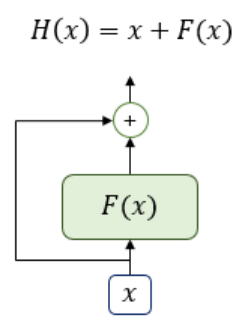
Seq2Seq & Attention Seq2Seq(Sequence-to-Sequence)는 말 그대로 어떤 연속된 데이터들을 다른 Sequence로 Mapping 하는 알고리즘이다. Seq2Seq는 크게 정보를 압축하는 Encoder 부분과 이를 통해 새로운 Data를
13.4주차 Generative Models 정리
강아지 사진이 있다면 그 사진의 분산 p(x)를 예측한다.1\. Generation : training set에 없는 강아지와 같은 이미지를 여러 개 생성할 수 있다.2\. Density Estimation : 어떤 이미지가 들어왔을 때 강아지같은지, 고양이같은지 구분
14.5주차 Product Serving 정리
문제를 잘 풀기 위해선 문제정의가 중요하다. How보단 Why에 집중한다.해결해야 하는 문제는 무엇이고 그것을 해결하면 무엇이 좋을지 어떻게 해결하면 좋을지 고민해본다.문제를 해결하기위한 Flow로 다음과 같이 나눌 수 있다.현상파악목적, 문제 정의 => 계속,쪼개서
15.5주차 Linux 정리
서버에서 자주 사용하는 OS, 무료이다.쉘을 사용하는 경우$\\cdot$ 서버에서 접속해서 사용하는 경우$\\cdot$ crontab 등 Linux 내장 기능 활용하는 경우$\\cdot$ 데이터 전처리를 하기 위해 쉘 커맨드 사용$\\cdot$ Docker를 사용하는
16.5주차 docker 정리
개발할 때, 서비스 운영에 사용하는 서버에 직접 들어가서 개발하지 않는다. Local 환경에서 개발하고, 완료되면 Staging 서버, Production 서버에 배포한다.특정 소프트웨어 환경을 만들고, Local, Production 서버에서 그대로 활용한다.개발과
17.5주차 MLflow 정리

머신러닝 실험, 배포를 쉽게 관리할 수 있는 오픈소스1) Experiment Management $ Tracking머신러닝 관련 실험들을 정리하고 각 실험들의 내용들을 기록 할 수 있다.(여러 사람이 하나의 MLflow 서버 위에서 각자 자기 실험을 만들고 공유 가능)
18.3주차 Polar Coordinate 정리
극 좌표계를 사용하는 시각 \- 거리(R), 각(Theta)를 사용하여 plot회전, 주기성 등을 표현하기에 적합projection = polar을 추가하여 사용해당 그래프는 Scatter(Line,Bar 모두 사용가능)극 좌표계에서 가장 대표적으로 사용할 수 있는
19.3주차 Pie Charts 정리
원을 부채꼴로 분할하여 표현하는 통계 차트 \- 전체를 백분위로 나타낼 때 유용가장 많이 사용하는 차트지만 비교가 어렵고 유용성이 떨어지기 때문에 사용을 지양하는 것이 좋다.중간이 비어있는 Pie Chart \- 디자인적으로 선호되고 인포그래픽에서 종종 사용됨햇살을
20.3주차 다양한 시각화 라이브러리 정리

결측치를 체크하는 시각화 라이브러리빠르게 결측 치의 분포를 확인하고 싶을 때 사용 가능계층적 데이터를 직사각형을 사용하여 포함 관계를 포현한 시각화 방법사각형을 분할하는 타일링 알고리즘에 따라 형태가 다양해진다.큰 사각형을 분할하여 전체를 나타내는 모자이크 플롯과 유사
21.6주차 EDA 정리

데이터의 분포를 확인해보고 모델을 적용하기 전 방향성을 정하기 위해 수행한다.데이터 labeling을 통해 새로운 csv를 만든다. 데이터 모델 적용을 3가지로 해볼 예정이기 때문에 label을 3개를 적용을 시킨다.그렇게 만든 csv의 상위 5항목을 출력해보면 다음과
22.마스크 분류 EDA 정리
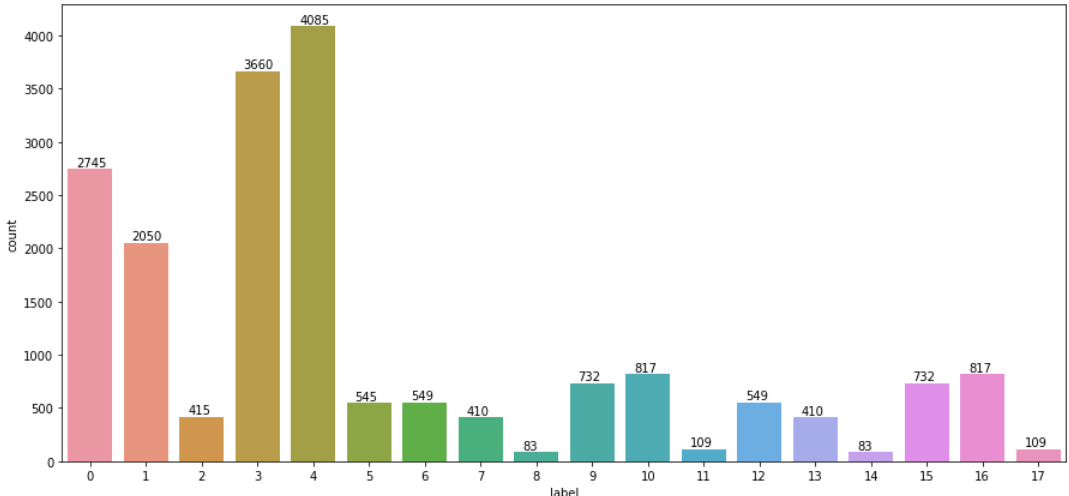
마스크를 착용하는 건 COIVD-19의 확산을 방지하는데 중요한 역할을 합니다. 제공되는 이 데이터셋은 사람이 마스크를 착용하였는지 판별하는 모델을 학습할 수 있게 해줍니다. 모든 데이터셋은 아시아인 남녀로 구성되어 있고 나이는 20대부터 70대까지 다양하게 분포하고
23.마스크 분류 대회 진행 정리

Data Augmentation은 갖고 있는 데이터셋을 여러 방법으로 Augment해서 그 규모를 키울 수 있는 방법이다. 기본적으로 아무 처리를 해주지 않았을 때의 성능은 다음과 같았다.그 다음 성능 향상을 위해 우선적으로 선택했던 방법은 기본적인 Transform에
24.8주차 Image Classification 1 정리
AI란 사람의 지능을 컴퓨터 시스템으로 구현하는 것이다. 여기서 지능이라함은 인지능력, 지각능력을 예로 들 수 있다. 그 중에서 가장 중요한것은 visualization, 즉 시각능력인데 우리가 어떤 것을 인지할 때에 시각능력에 75%나 의존하기 때문에 시각능력이 가장
25.8주차 Image Classification 2 정리
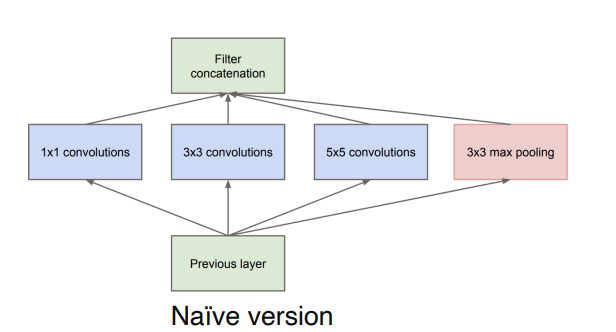
네트워크 모델들의 layer는 더 깊어지고 있다. 이것의 이유는 더 큰 크기의 receptive field를 갖기 때문이다. 하지만 무턱대고 층이 깊어지기만하면 기울기 소실,폭발 같은 문제들이 일어난다. 그리고 계산과정이 복잡해지는 문제점이 나타난다.Inception
26.8주차 Semantic Segmentation 정리
Semantic Segmentation이란 이미지 분류를 픽셀단위로 하는 것이다. 한 픽셀이 사물,동물,사람 등 어디에 속하는지 판단하는 것이다. FCN은 기존 CNN 모델을 Segmentation에 적합하게 변형하여 Segmentation 발전의 토대를 이룬 초기 모
27.8주차 Object Detection 정리

bounding box를 제안하는 방법이다. 이미지에서 모든 부분이 1개의 영역에 할당되도록 한다.hierarchical grouping algorithm을 사용하여 유사한 영역들을 합친다.통합된 영역을 바탕으로 후보들을 추출한다.딥러닝을 본격적으로 Object det
28.8주차 CNN Visualization 정리

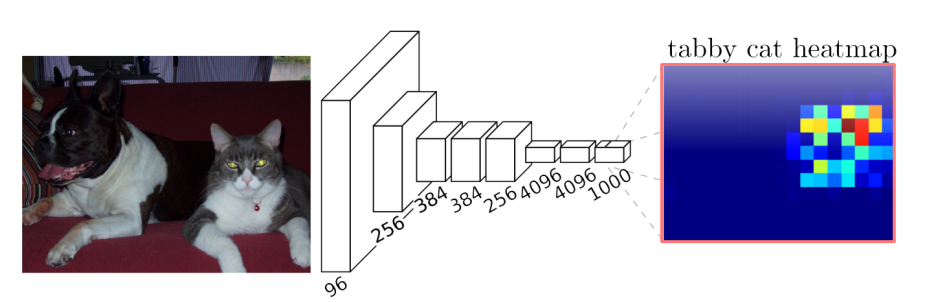
Visualizing CNN CNN을 Visualizing 한다는 것은 debugging tool을 갖는것과 동일하다. ZFNet 낮은 계층에는 기본적인 영상처리 필터들이 분포하고 점점 높은 계층으로 갈수록 high level features들을 학습했다는 것을
29.부스트캠프 9주차 Instance/Panoptic Segmentation and Landmark Localization 정리
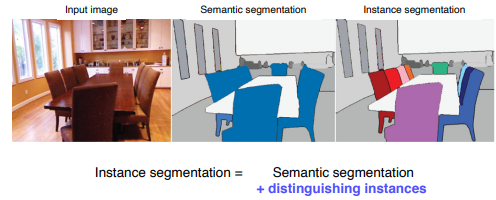
개체들까지 구분한 segmentation을 말한다.기존 Faster R-CNN에서 Mask Branch가 추가된 형태이다.기존 7x7x2048에서 14x14로 upsampling함과 동시에 채널 수를 낮추고, 최종적으로 Class의 수(80) 만큼의 binary mas
30.부스트캠프 9주차 Conditional Generative Model 정리
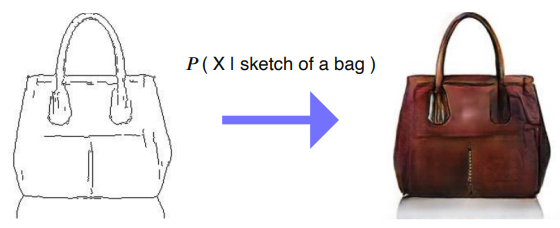
sketch of a bag이 주어졌을 때 X인 이미지가 나올 확률Generative Model은 Random Sample을 생성하고 Conditional Generative Model은 조건이 주어졌을 때 Random Sample을 생성한다.Adversarial tr
31.부스트캠프 9주차 Multi-Modal 정리
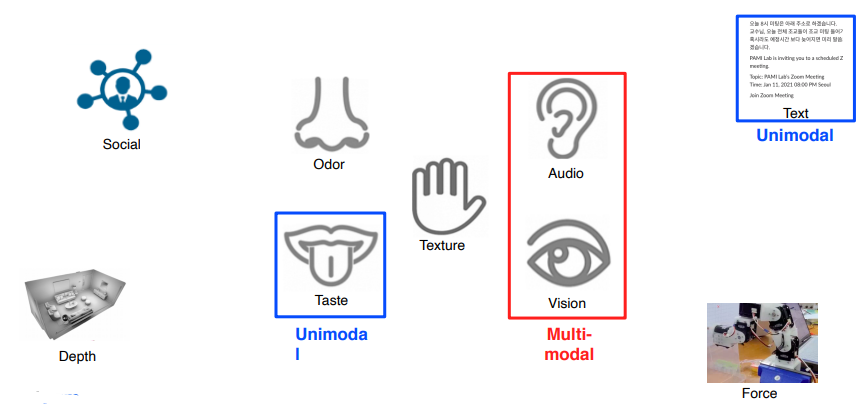
Multi-modal learning : 다른 특성을 갖는 데이터 타입들을 같이 활용하는 학습법Multi Model은 데이터들의 표현 방법이 다 다르기 때문에 어렵다.서로 다른 Modality에서 오는 정보의 양이 unbalance 하고 feature space에 대한
32.부스트캠프 9주차 Image Captioning 정리
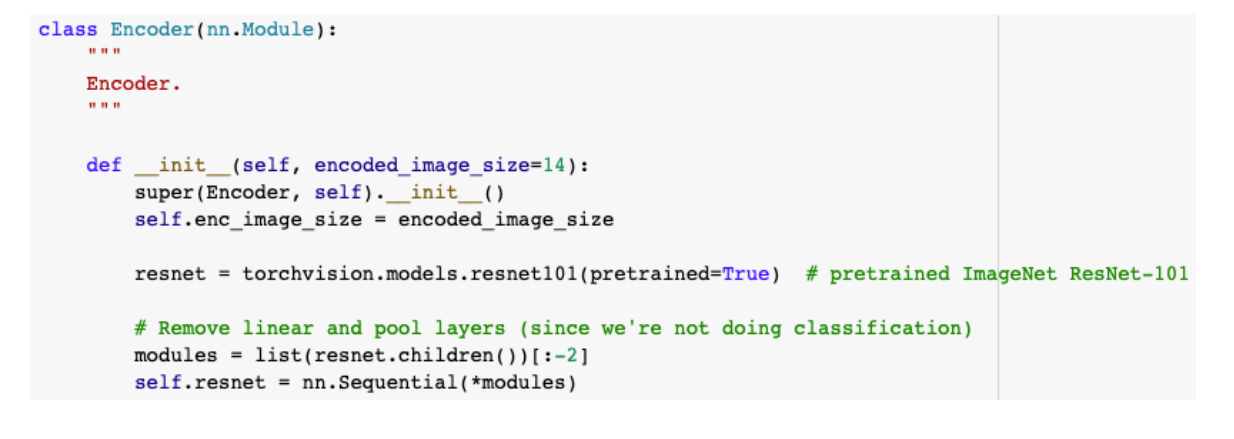
Encoder를 Image-Captioning을 위해 Pre-trained된 ResNet101을 사용Pooling과 linear를 제거하여 사용한다.start token이 decoder로 들어가고 이전에 출력된 정보와 attention 정보를 input을 넣는다.RNN
33.부스트캠프 10주차 Object detection Overview

Image Classfication과 Object Detection의 차이점은 Object Detection은 물체의 위치와 무엇인지가 다 표시된다.Semantic Segmentation은 픽셀별로 classification을 진행하지만 같은 클래스의 경우에는 따로 경
34.부스트캠프 10주차 Stage Detectors 정리

Object Detection은 크게 one-stage와 two-stage가 존재한다. two stage는 사람의 객체인식 방법과 가장 유사하게 디자인된 방법이다.1\. 객체가 있을 법한 위치를 추정한다.2\. 해당 객체가 무엇인지 추론한다.이때 객체가 있을 법한 위치
35.부스트캠프 10주차 Object Detection Library 정리
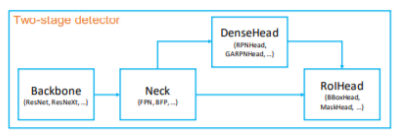
하나의 library가 아니라 여러 개의 library가 사용되고 있다. 그 중에 주로 MMDetection과 Detectron2가 주로 사용되고 있다.2-stage 모델은 크게 Backbone,Nectk,DenseHead,RoIHead로 나눌 수 있다. 각 부분은 모
36.부스트캠프 10주차 Neck 정리
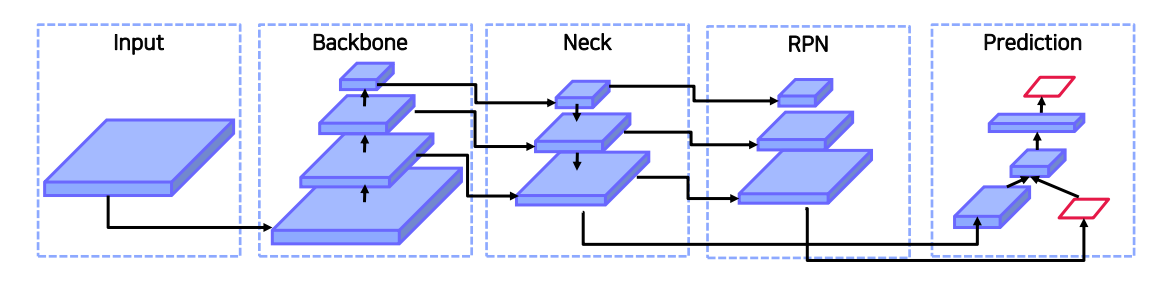
기존 RPN은 backbone network를 통과한 마지막 layer만 사용을 했다. 그것에 의문을 가진 연구자들이 중간에 있는 feature들을 사용하면서 neck이 등장하게 되었다.backbone을 통과한 feature map에서 다양한 크기의 객체를 예측해야 한
37.부스트캠프 10주차 1 stage Detectors 정리
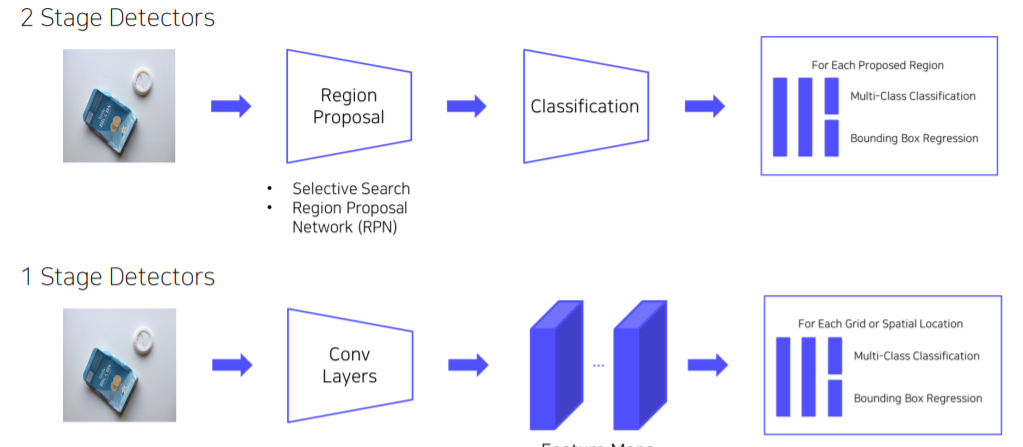
2 stage detector는 localization과 classification을 하기 때문에 realtime으로 활용이 불가능하다. 그래서 RPN 과정을 빼서 속도를 올렸다.Localization, Classification이 동시에 진행한다.전체 이미지에 대해
38.부스트캠프 10주차 EfficientDet 정리

EfficientDet EfficientNe의 알고리즘을 Object Detection분야에 적용시킨 모델이다. 1Stage Detector이다. Backbone, Feature map, FPN, Boxclassificationhead, classclassificati
39.부스트캠프 11주차 Advanced Object Detection1 정리
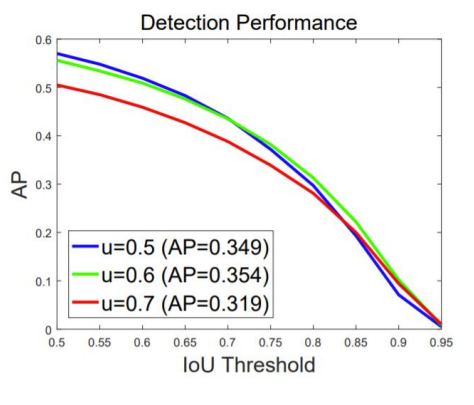
Faster RCNN을 학습할 때 배경과 객체를 나누는 기준이 threshold가 0.5였는데 이것을 바꿔서 실험을 해 보았다.Input IoU가 높을 수록 높은 IoU threshold에서 학습된 모델이 더 좋은 결과를 내었다.전반적인 AP의 경우에는 IoU thre
40.부스트캠프 11주차 Advacned Object Detection2 정리
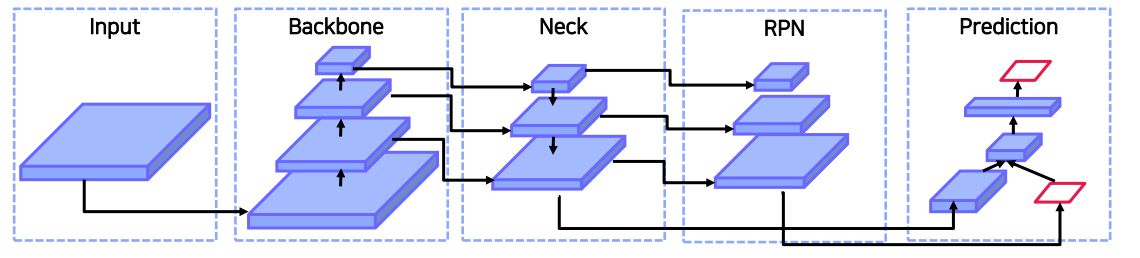
BackboneGPU platform : VGG, ResNet, ResNext, DenseNet, ...CPU platform : SqueezeNet, MobileNet, ShuffleNet, ...NeckAdditional blocks: SPP,ASPP, ...Pat
41.재활용 쓰레기 분류 대회 정리
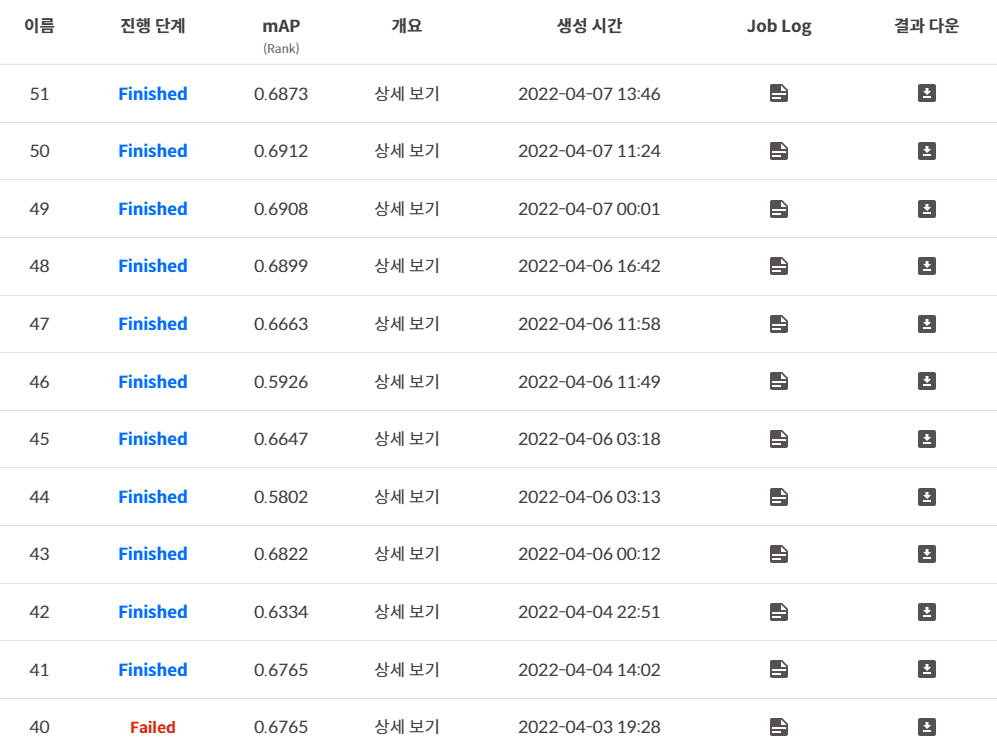
https://github.com/boostcampaitech3/level2-object-detection-level2-cv-18개인적으로 정말 많은 시간을 쏟았던 대회이다. 이 대회가 진행되는 동안 게임을 거의 하지도 않을 정도로 정성을 쏟았던 대회이다.총
42.부스트캠프 15주차 Segmentation 정리
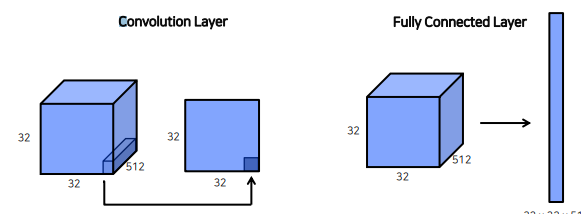
VGG Network Backbone을 사용했다.VGG Network의 FC Layer를 COnvolution 으로 대체했다.Transposed Convolution을 이용해서 Pixel Wise Prediction을 수행했다.FC Layer는 각 Pixel의 위치정보
43.부스트캠프 15주차 FCN의 한계를 극복한 model들 1

객체의 크기가 작은 경우 예측을 잘 하지 못함.큰 Object의 경우 지역적인 정보만으로 예측한다.같은 Object여도 다르게 labeling이 된다.작은 Object가 무시되는 문제가 있다.Object의 자세한 부분이 사라진다.ArchitectureDecoder와 E
44.부스트캠프 15주차 FCN의 한계를 극복한 Model 2 정리
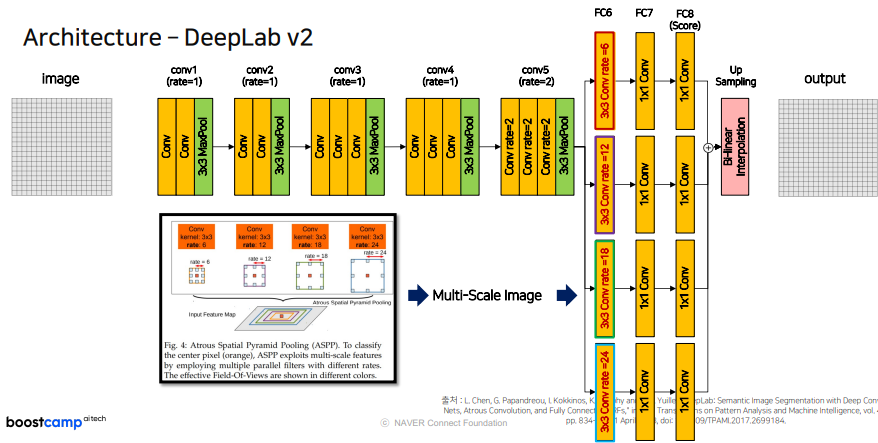
DilatedNet에서 Encoder 부분은 같고 Decoder 부분에서 4개의 가지를 만들어서 그것들을 합해서 사용해 변화를 주었다.Rate가 큰 부분은 커다란 Object를 잘 검출해내기위해 사용했다.각 Conv Block 마다 실행해주는 것들이 다르지만 공통적으로
45.부스트캠프 15주차 High Performance를 자랑하는 Unet 계열의 모델들 정리
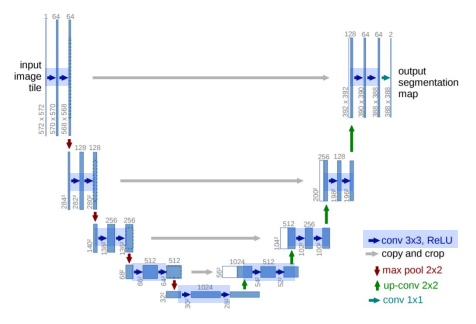
Unet은 의료계열에서의 문제상황을 해결하기 위해 나왔지만 구조가 좋기 때문에 다방면에서 사용된다.Contracting Path : 이미지 추출(3x3 Conv Network + BottleNeck + ReLU)x2Nonzero-padding으로 patch size 감
46.부스트캠프 Segmentation 대회 정리
이번 대회를 하기에 앞서 제 목표는 마지막 대회니만큼 지금까지 적용해봤던 기법들을 적용해보고 앞서 object detection 대회와 같은 dataset을 사용하기 때문에 그때 해보지 못했던 것들을 해보는 것을 목표로 잡았다. 그리고 팀이 결성되고 나서 항상 순위를
47.부스트캠프 18주차 Product Serving 정리
ServingProduction(Real World) 환경에 모델을 사용할 수 있도록 배포한다.머신러닝 모델을 개발하고, 현실 세계(앱, 웹)에서 사용할 수 있게 만드는 행위서비스화라고 표현할 수도 있다.머신러닝 모델을 회사 서비스의 기능 중 하나로 활용한다.예 : 추
48.부스트캠프 18주차 Voila 정리
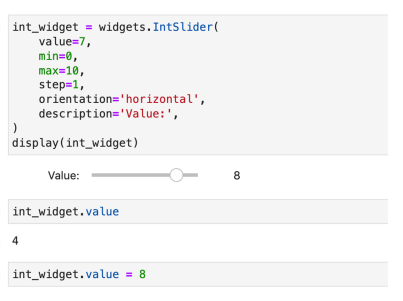
모델을 개발한 후 사람들과 테스트할 수 있는 프로토타입을 먼저 만들어봐야 한다.웹서비스를 만드는 것은 시간이 많이 소요되기 때문이다.1) Jupyter Notebook 결과를 쉽게 웹 형태로 띄울 수 있음2) Ipywidget, Ipyleaflet 등 사용 가능3) J
49.부스트캠프 18주차 Streamlit 정리
장점Python Script 코드를 조금 수정하면 웹을 띄울 수 있음백엔드 개발이나 http 요청을 구현하지 않아도 됨다양한 Component를 제공해서 대시보드 UI를 구성할 수 있음Streamlit Cloud를 통해 쉽게 배포 가능화면 녹화 기능이 존재한다.