Generative Model
입력받은 데이터와 유사한 새로운 데이터 샘플들을 생성(generate)해내는 모델이다.
Generative 모델의 목적은 모델이 만든 데이터의 분포와 실제 데이터의 분포가 최대한 똑같게 만드는 것이다.
explicit model : 어떤 값이 주어졌을 때 확률값을 얻어낼 수 있는 모델
-> NADE, PixellRNN, VAE
implicit model : 단순히 generation만 할 수 있는 모델
-> GAN
Descrete Distribution
Bernoulli distribution
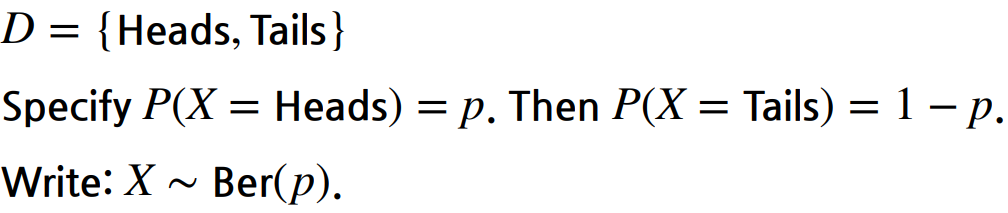
동전의 앞 뒷면을 나타내고 이 분포를 표현하려면 1개의 parameter가 필요하다.
앞이 나올 확률이 p이면 뒷면은 1-p가 된다.
Categorical distribution
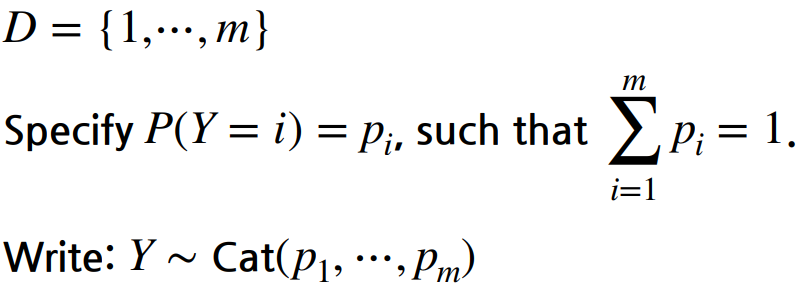
주사위를 예를 들면 5개의 parameter가 필요하고 나머지 한개는 1에서 5개의 합을 빼주면 된다.
만약 이것을 RGB로 확장해서 보면 모든 색을 표현하기 위해서 256256256개가 필요한데 parameter는 1개를 뺀 255255255개가 필요하다. 이것이 한 픽셀당 필요한 parameter의 수 이므로 이미지 하나를 표현하기 위해서는 엄청난 parameter의 수가 필요하다.
Conditional Independence

Chain rule : x1이 독립인지 상관없이 항상 성립한다.
Conditional independence : z가 주어졌을 때 x와 y가 독립이다. 그렇기 때문에 x를 표현할 때에 y는 지워져도 상관이없다.
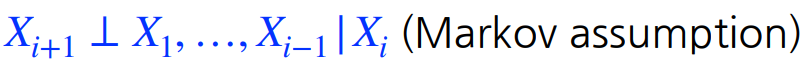
Markov assumption을 통해 parameter의 수가 2n-1로 줄일 수 있다.
Auto-regressive Model
28x28 binary pixel이 있다면 chain rule을 사용하여 p(x)를 다음과 같이 표현한다.
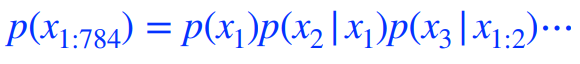
autoregressive model은 어떤 하나의 이전 정보가 이전 정보들에 대해 dependent한 것을 말한다. Markov assumption을 통해 i번째 pixel이 i-1번째 pixel에만 dependent한 것도 autoregressive model이다.
또한 이미지 도메인과 같이 순서를 정하는 것이 필요하다.
Nade : Neural Autoregressive Density Estimator
i번째 pixel을 1부터 i-1에만 dependent하게 만든 것이다.
NADE는 explicit model이고 입력의 density를 계산한다.
각 conditional probability를 독립적으로 계산한다.
Pixel RNN
pixel들을 만들어내고 싶어하는 generative model이다.

n*n RGB 이미지를 만들어 낼 때의 P(x)이다. Ordering에 따라 두 가지 모델로 나뉜다.

Row LSTM : i번째 pixel을 만들 때 위쪽에 있는 정보를 활용하는 방법
Diagonal BiLSTM : 이전 정보들을 전부 활용한 RNN으로 pixel정보를 예측한다.
Auto Encoder
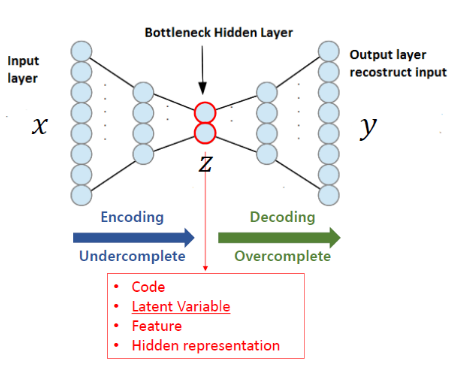
Encoder를 거쳐 데이터를 압축시킨 후 Decoder에서 복원함으로써 차원축소를 통해 Parameter 초기화 Pre-training의 효과를 기대함.
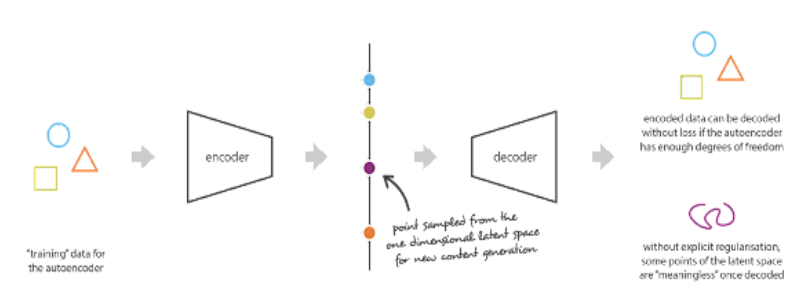
도형 3개를 잘 학습해서 latent variable z를 만들었지만 새로운 보라색 도형을 입력 decoder에 입력으로주면 AE는 조금 다른 형상을 만들어낸다.
-> AE는 무조건 원본 데이터의 분포만 잘 따르도록 학습되기 때문에 일반화가 필요하다. => AE는 보통 generative model로 사용하지 않고 encoder만 분리해서 input 데이터의 feature를 추출할 때 사용한다.
Latent Variable Models
Variational Auto-encoder
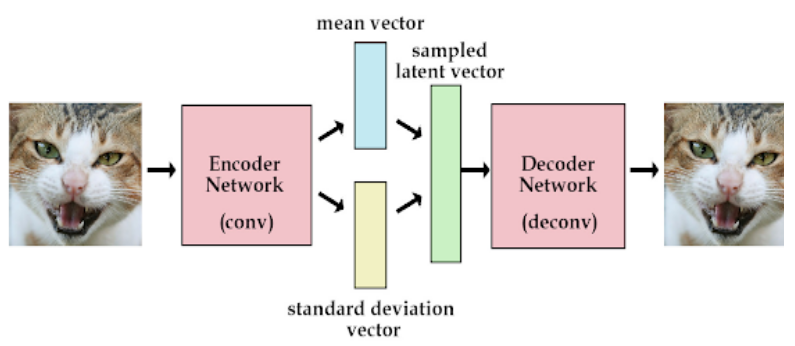
Encoder는 바로 latent variable을 만드는 것이 아니라 Encoding 된 이미지의 평균과 분산을 학습하는 layer가 추가 되었다.
데이터가 가우시안 분포를 가질 것을 가정하고 학습될 수 있는 parameterized 평균과 분산을 둔다. 그렇게 하면 결론적으로 학습될 수록 원본 이미지의 평균과 분산을 잘 학습하게 된다. 그리고 평균과 분산이 적용된 latent variable을 decoder가 학습하기 때문에 원본데이터와 다른 입력을 주더라도 분포 내에서 합당한 데이터를 generation할 수 있다.
Variational inference (VI)
베이지안 딥 러닝에서의 목적은 새로운 입력에 대한 Posterior를 추론하는 것인데 posterior는 구하기 어렵고 구했다해도 수많은 w에 대해서 적분을 해주는 것이 불가능 그래서 나온 것이 분포를 근사하는 VI이다. 그리고 이때 등장하는 개념이 KL-divergence와 ELBO(Evidence Lower Bound)이다.
사후확률(posterior)을 구하기 어려운 이유 : posterior = 인데 evidence를 직접 계산하기 위해서는 전체 변수들에 대해 적분을 수행해주어야 하기 때문.
Variational distribution을 찾는 목적은 posterior distribution을 찾기 위해서이다.
Posterior distribution : observation이 주어졌을 때 관심있어하는 random variable의 확률분포이다. z가 Latent Variable이 된다.
Variational distribution : Posterior distribution을 계산하는 과정이 힘들기 때문에 근사한 분포를 Variational distribution이라 한다.
KL-divergence는 간단히 어떤 두 분포 p와 q의 차이를 계산하는데 사용되는 함수이다. 이상과 현실 간의 괴리라고 볼 수 있다.

차이가 클 수록 값이 커지고 유사할수록 작아진다. Q(w)를 P(w|D)로 근사시키기 위해서는 KL-divergence를 최소화해야한다.
관심있는 posterior 사이의 KL divergence를 최소화하는 variational distribution을 찾는 것을 Variational inference라 한다.
문제는 불확실한 Posterior distribution에 근사하는 Variational distribution을 찾는다는 것이 불가능하다. loss fuction이 있는데 target을 모르는 상태에서 loss fuction을 줄이고 싶을 때 이를 가능하게 해주는 것이 ELBO track이다.
ELBO를 계산해서 키움으로써 원하는 object를 얻고자 한다.
-> 계산할 수도 없는 임의의 Posterior distribution과 optimization 하고자하는 variational distribution 사이의 거리를 줄이는 목적을 ELBO를 maximize함으로써 얻을 수 있다.

Posterior distribution은 계산이 불가능하지만 ELBO는 계산이 가능하다.
궁극적인 목표는 x라는 입력이 있고 그 입력을 잘 표현할 수 있는 공간 z(latent space)를 찾는 것이다. 그러나 z에 대한 확률분포 posterior를 모르므로 이것을 잘 찾기위해서 variational distribution 혹은 encoder로 근사할려는 것이다. 그리고 posterior를 잘 모르는 상태이기 때문에 variational inference로 ELBO를 maximize하는 것이 posterior distribution과 variational distribution의 사이를 줄이는 것과 같은 효과를 낸다.

두 확률분포 사이의 거리 KL term은 계산을 할 수 없기 때문에 앞의 2개를 최적화 시켜주어야 한다.
Adversarial Auto-encoder (AAE)
auto encoder의 가장 큰 단점은 가우시안을 사용해야한다는 점이다. 가우시안이 아닌 다른 분포를 활용하기 위해 adversarial auto-encoder를 사용한다.
Generative Adversarial Network (GAN)
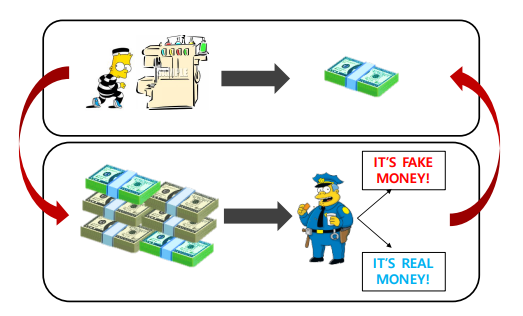
geneartor는 dicriminator를 속이기 위해 fake data를 생성한다
discriminator는 real data와 fake data를 판별한다.
discriminator의 성능과 generator의 성능은 비례한다.
GAN의 장점은 generator를 학습시키는 discriminator가 점점 좋아지는 데에 있다.
GAN vs VAE
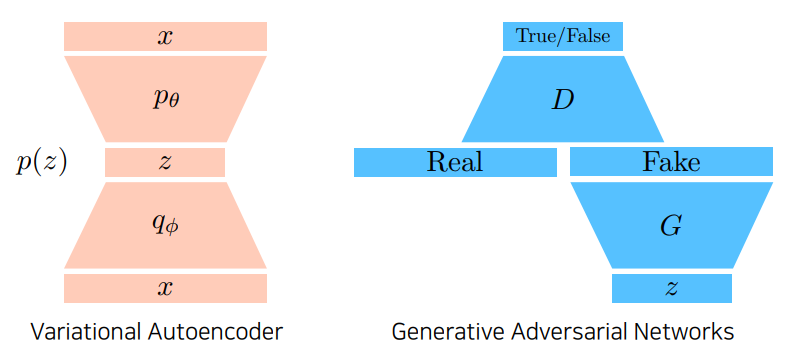
VAE : x라는 이미지 혹은 입력 도메인이 들어오면 encoder를 통해 latent vector로 갔다가 z를 sampling해서 decoder를 통해 x가 generative한 결과가 된다.
GAN : z를 통해서 fake가 생성된다. Discriminator는 분류기를 학습하고 generator는 discriminator 입장에서 true가 나오도록 다시 update하고 discriminator는 update된 generator의 생성 결과물을 분류할 수 있도록 성장함.
GAN Objective
generator와 discriminator의 minmax 게임이다.
-> 어느 한 쪽은 높이고 싶어하고 어느 한 쪽은 낮추고 싶어하는 게임
Discriminator 알고리즘
다음 수식은 generator가 fix가 되어있을 때 항상 최적으로 갈라주는 Optimal Discriminator이다.
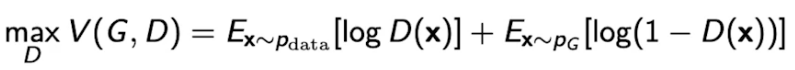
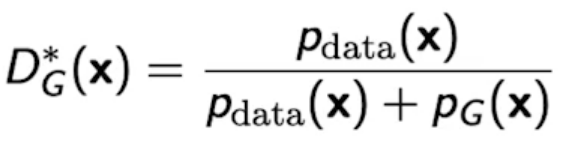
Generator 알고리즘
동일한 Loss에 대해서 discriminator는 최대화하려고 하는 반면 generator는 최소화 하려고 한다.
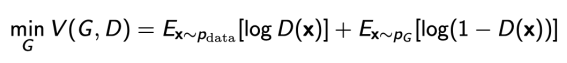
Optimal Discriminator를 generator 수식에 적용시키면 다음과 같은 식이 나온다.

이 수식을 통해 GAN의 목적이 실제 데이터의 분포와 학습한 데이터의 분포 사이에 JSD(두 확률 분포 사이의 거리,,가 같으면 0으로 최소)를 최소화 하는 것임을 알 수 있다.
이 수식은 discriminator가 Optimal하다는 가정 하에 generator 알고리즘에 대입해야 나온다. 실제로 discriminator가 optimal discriminator에 수렴한다는 것을 보장하기 힘들고 그렇게되면 generator가 위와 같이 전개 될 수 없다. 따라서 현실적으로 JSD를 줄이는 것은 불가능하다.
DCGAN
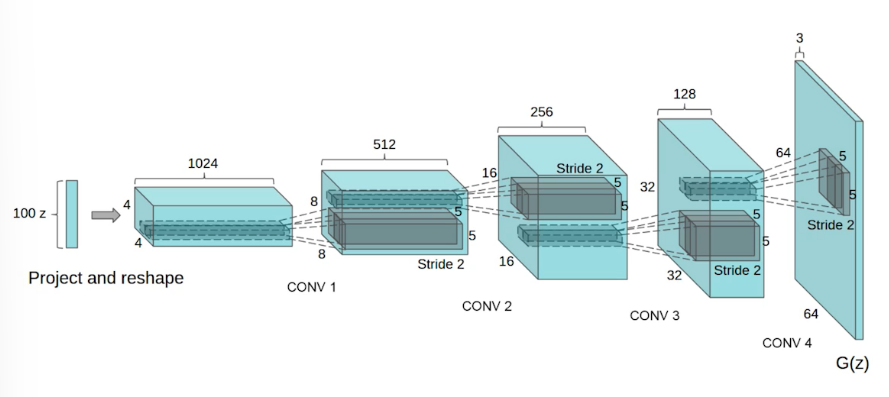
GAN은 MLP를 사용해서 만들었다. generator에는 deconvolution을 활용했고, discriminator에는 convolution 연산을 수행했다.
Info-GAN
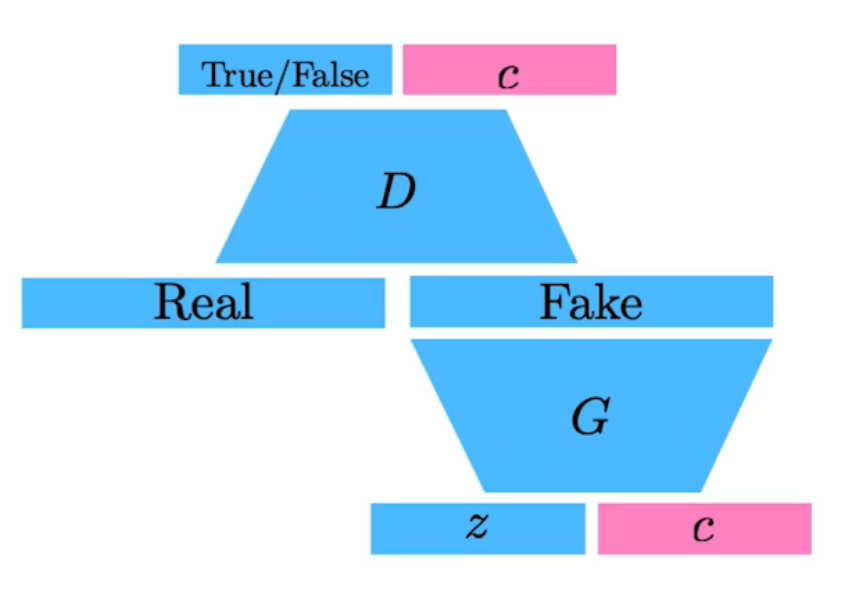
학습할 때 z를 통해 이미지만 만드는 것이 아닌 임의의 onehot vector(c)를 집어넣는다. generation을 할 때 특정모드에 집중할 수 있게 해준다.
Text2Image

문장을 input으로 받아서 conditional GAN을 만들어서 이미지를 만든다.
Puzzle-GAN
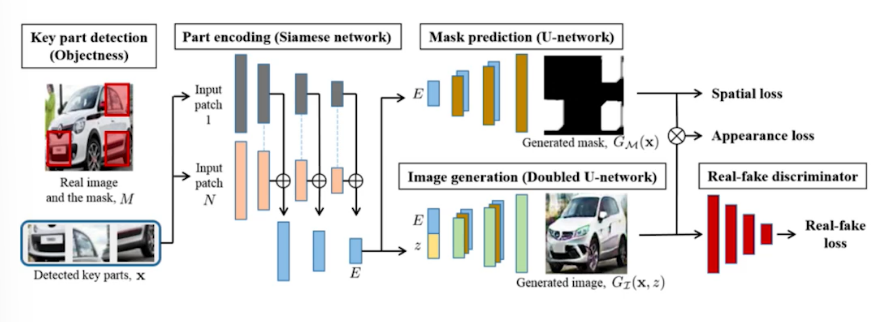
이미지 안에 subpatch가 있기 때문에 sub patch를 받아서 원래의 이미지를 복원한다.
Cycle GAN

이미지사이의 도메인을 바꿀 수 있다.
Cycle-consistency loss
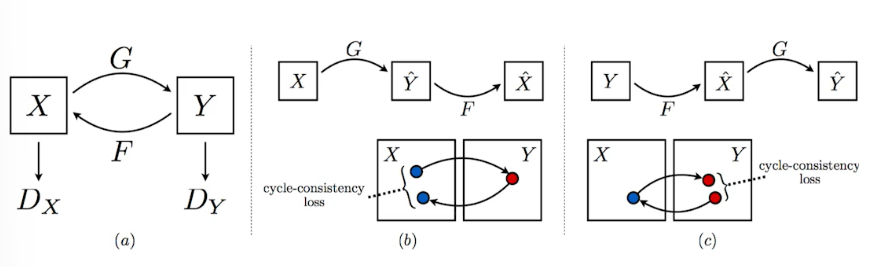
Cycle GAN은 Cycle-consistency loss를 사용했다. 원래 도메인을 다른 도메인으로 변경하려면 일반적으로 두 개의 사진이 필요한 반면 Cycle-consistency loss는 임의의 관련 이미지들을 다 모아두고 이를 활용해 하나의 이미지를 다른 도메인의 이미지로 그냥 변형시킨다. 이 과정에서 GAN 구조가 2개 들어간다.
Star GAN

이미지를 원하는 형태로 제어 할 수 있다.
Progressive GAN
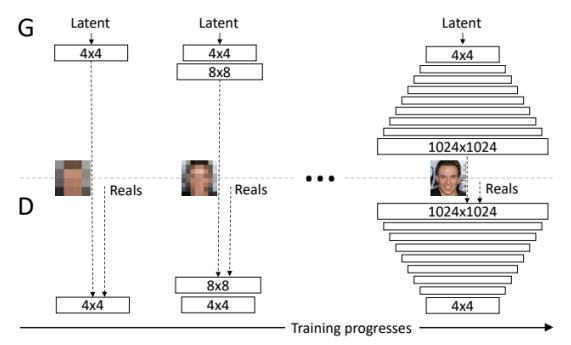
고해상도의 이미지를 만들 수 있다. 4x4부터 1024x1024 이미지까지 픽셀을 키워가는 생성방법을 사용했다.
