Object Detection Model
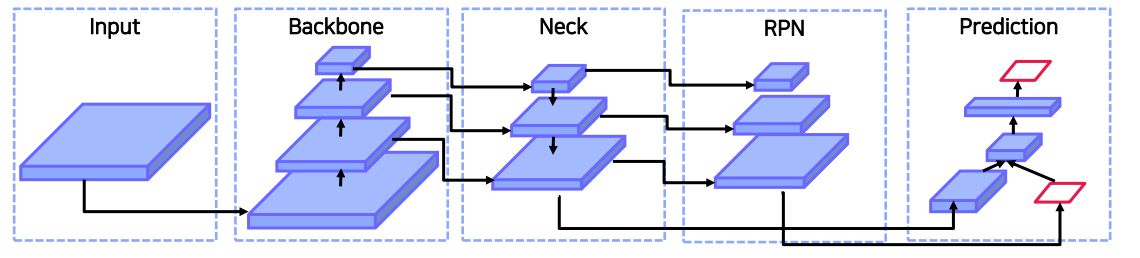
Backbone
- GPU platform : VGG, ResNet, ResNext, DenseNet, ...
- CPU platform : SqueezeNet, MobileNet, ShuffleNet, ...
Neck
- Additional blocks: SPP,ASPP, ...
- Path-aggregation blocks: FPN, PAN, NAS-FPN, BiFPN ...
Head
- Dense Prediction(1-stage): RPN, YOLO, SSD, RetinaNet, CornerNet, FCOS, ...
- Sparse Prediction(2-stage): Faster-RCNN, R-FCN, Mask R-CNN, ...
Bag of Freebies
Inference cost를 늘리지 않아서 real time을 보장한다.

Data Augmentation
- 입력 이미지를 변화시켜서 overfitting을 막는다.
Segmantic Distribution Bias
- Dataset에 특정 라벨이 많은 경우 불균형 해소를 위한 방법 ex) Focal loss
- Label Smoothing
- 라벨을 0 or 1 이 아니라 smooth 하게 부여한다. ex) 0.9,1.1...
- 모델의 overfitting을 막아주고 regularization 효과를 기대할 수 있다.
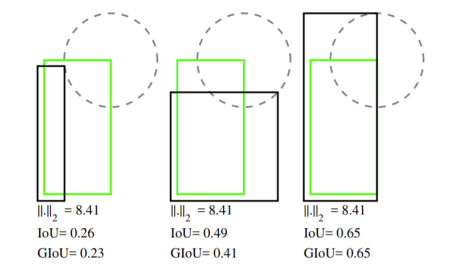
Bounding Box Regression
- Bounding Box 좌표값들을 예측하는 방법은 거리가 일정하더라도 IoU가 다를 수 있다.
- IoU 기반 loss를 제안한다.
- GIoU
- IoU 기반 loss
- IoU가 0인 경우에 대해서 차별화하여 loss를 부여한다.
- IoU의 거리를 고려한다.
Bag of Specials

- Enhance Receptive Field
- Feature map의 receptive field를 키워서 검출 성능을 높이는 방법이다.
- SPP
- conv layer의 마지막 feature map을 고정된 크기의 grid로 분할해 pooling하여 고정된 크기의 벡터를 출력한다.
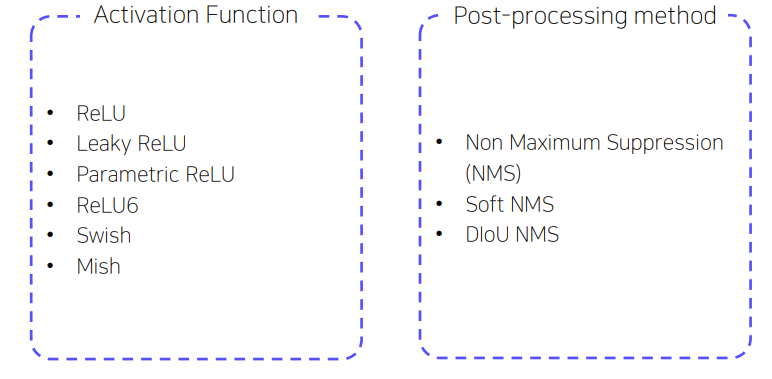
- Attention Module
둘다 feature map에 Attention 정보가 추가된다. 중요한 feature map에 집중할 수 있도록 한다.
- Feature Integration
- Feature map을 통합하기 위한 방법으로 Neck과 동일하다.
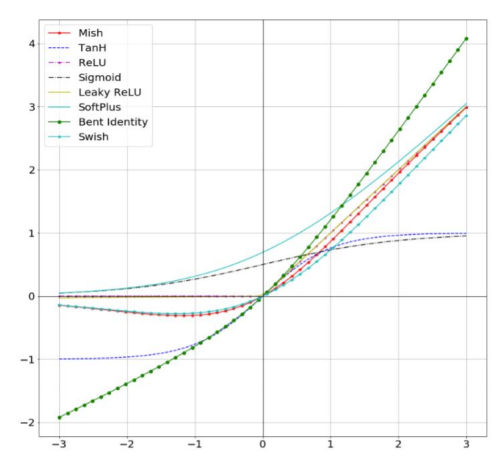
- Activation Function
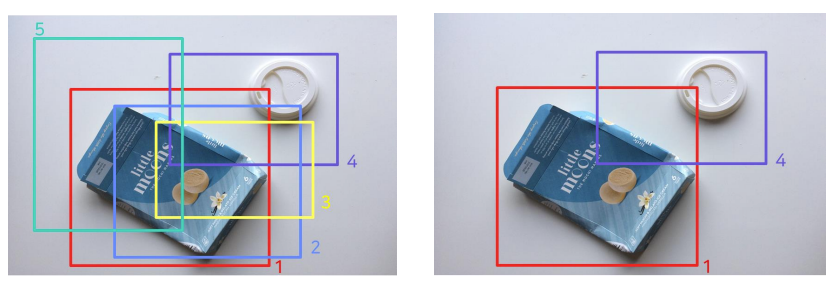
- Post-processing Method
- 불필요한 Bbox를 제거하는 방법이다.
Selection of Architecture
Detector 고려사항
- 작은 물체를 검출하기 위해선 큰 네트워크 입력 사이즈가 필요하다.
- 네트워크 입력 사이즈가 증가함으로써 큰 receptive field가 필요하므로 많은 layer를 필요로 한다.
- 하나의 이미지로 다양한 사이즈의 물체를 검출하기 위해 모델의 용량이 더 커야 한다.
Cross Stage Partial Network (CSPNet)
- 정확도를 유지하면서 모델을 경량화시켰다.
- 메모리 cost를 감소시켰다.
- 다양한 backbone에서 사용이 가능하다.
- 연산 bottleneck을 제거했다.
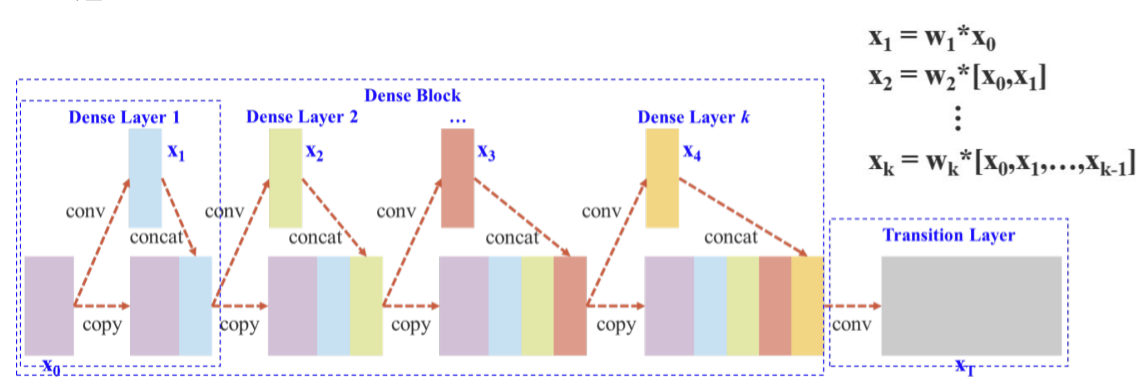
기존의 DenseNet에서의 CSPNet이고 이것을 YOLOv4에서는 다음과 같이 변형시켰다.
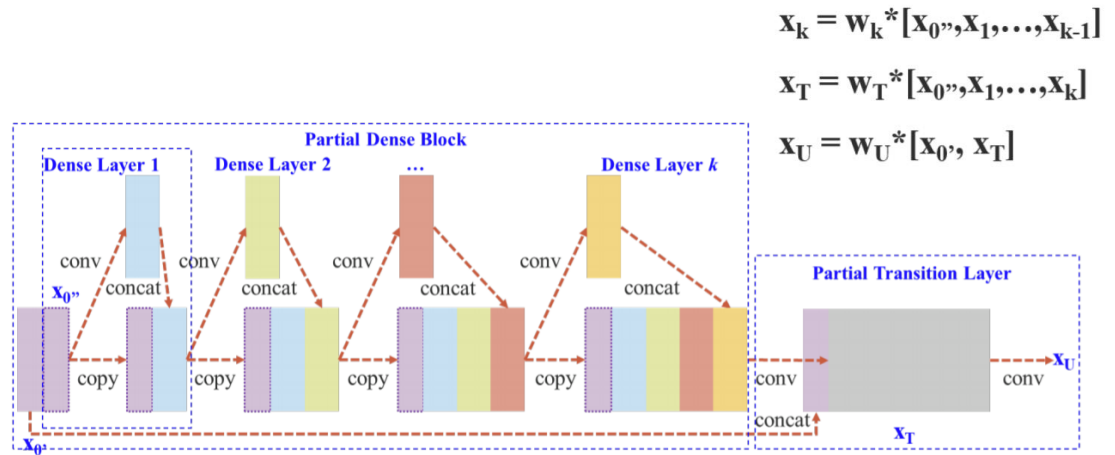
Input channel을 전부 사용하지 않고 절반만 사용하여 gradient information이 많아지는 것을 방지했다.
Additional Improvements
- Mosaic
- Self-Adversarial Training
- Modified SAM
- Modified PAN
- Cross mini-Batch Normalization
M2Det
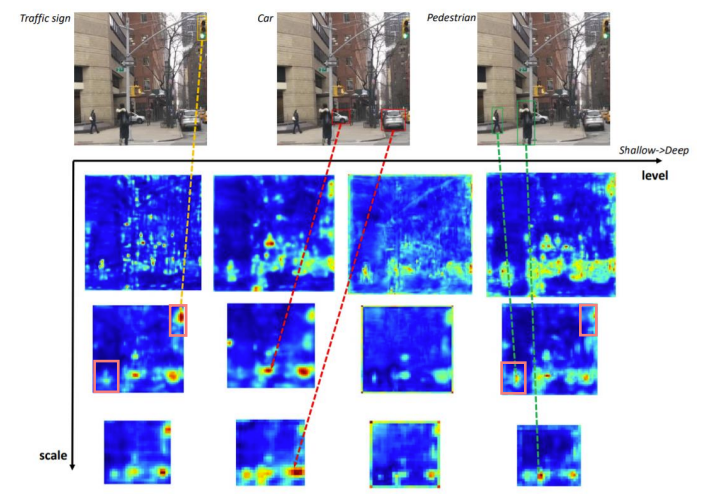
Feature Pyramid의 한계점
- Backbone으로부터 feature pyramid를 구성하기 때문에 Classification task를 위해 설계된 backbone은 object detection task를 수행하기에 적합하지 않다.
- Backbone network는 single-level 정보만 나타낸다.
- 일반적으로 low-level feature는 간단한 외형을, high-level feature는 복잡한 외형을 나타내는데 적합하다.
FPN은 multi scale이지만 멀리있는 신호등과 멀리 있는 사람을 구분하기 힘들다. 사람이 더 복잡한 외형을 지니고 있기 때문에 high level feature가 필요하다.
M2Det에서 Multi level ,multi-scale feature pyramid를 제안했다.
SSD에 합쳐서 M2Det라는 1-stage detector를 제안했다.
Architecture
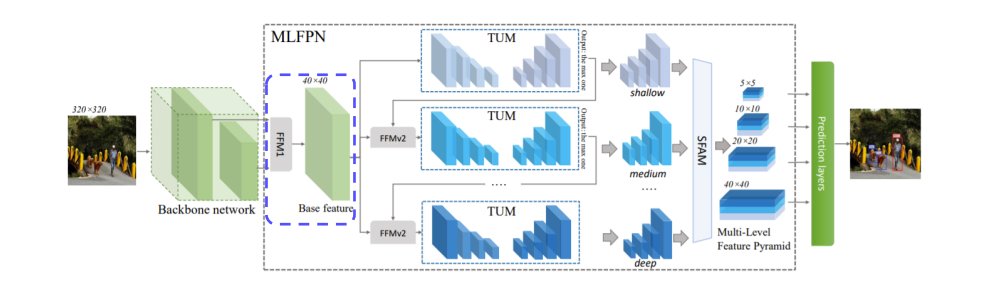
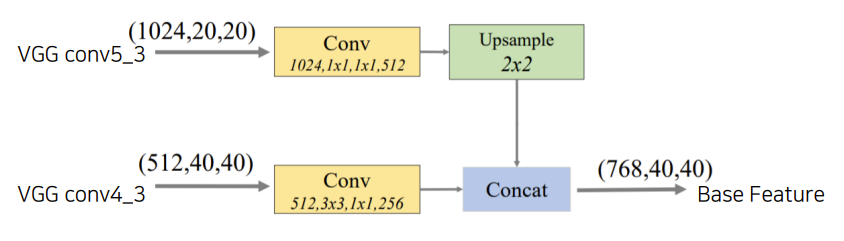
FFM : Feature Fusion Module
- FFMv1: base feature를 생성한다.
- Base Feature: 서로 다른 scale의 2 feature map을 합쳐서 semantic 정보가 풍부하다.
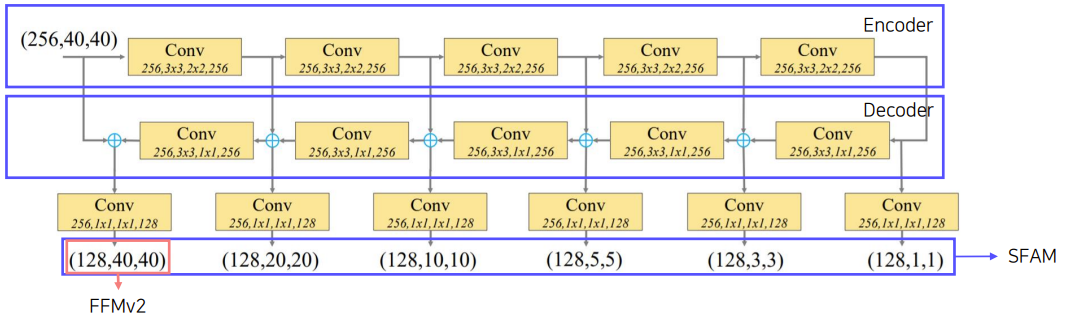
TUM : THinned U-shape Module
- Encode-Decode 구조이다.
- Decoder는 현재 level에서의 multi-scale feature들을 출력한다.
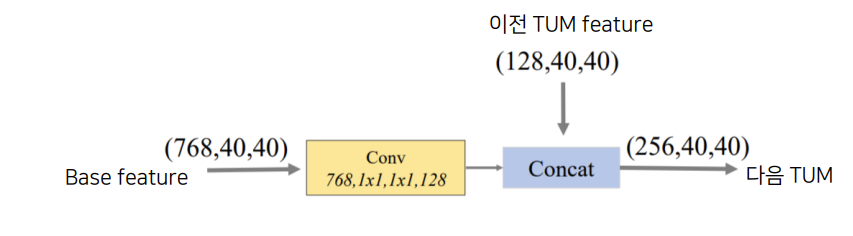
FFM : Feature Fusion Module
- FFMv2: base feature과 이전 TUM 출력 중에서 가장 큰 feature를 합치고 그 다음 TUM의 입력을 넣는다.
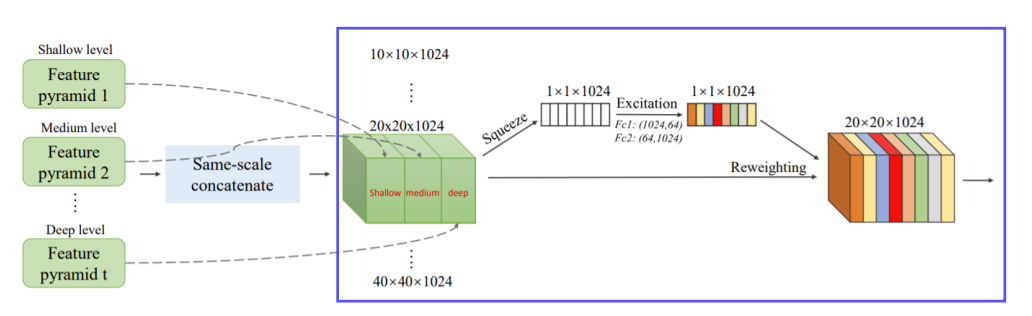
SFAM : Scale-wise Feature Aggregation Module
- TUMs에서 생성된 multi-level, multi-scale을 합치는 과정이다.
- 동일한 크기의 feature들끼리 연결한다.
- 각각의 scale의 feature들은 multi-level 정보를 포함한다.
- Channel-wise attention을 도입했다.
- 채널별 가중치를 계산하여 각각의 feature를 강화시키거나 혹은 약화시킨다.
8개의 TUM을 사용하여 6개의 scale feature들을 출력한다.
Detection Stage
- 6개의 feature마다 2개의 conv layer를 추가하여 regression, classification을 수행한다.
- 6개의 anchor box를 사용한다.
- Soft NMS를 사용한다.
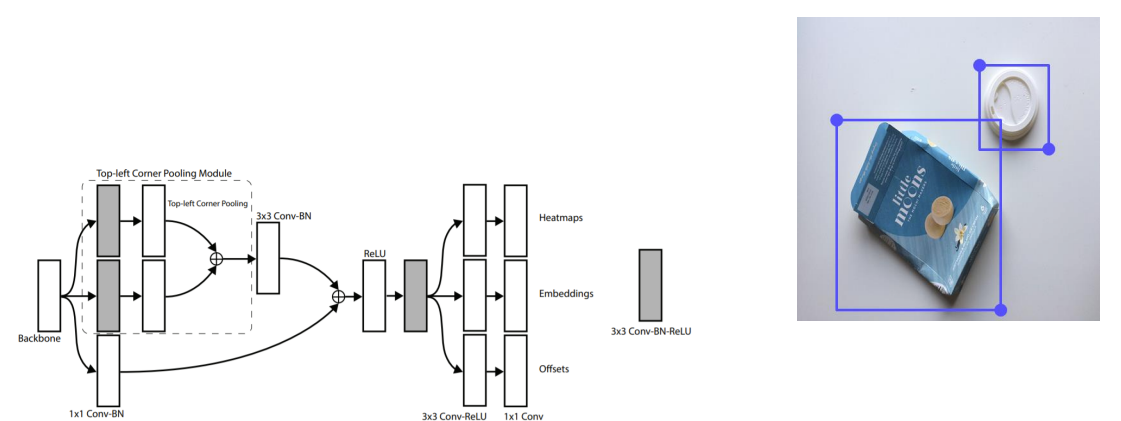
CornerNet
Anchor Box단점
- 수가 엄청나게 많다.
- 거의 대부분은 배경이라 Positive Sample이 적다. -> 클래스 불균형 문제 발생
- 하이퍼 파라미터를 고려해야 한다.(box 개수, 사이즈, 비율)
=> Anchor box가 없는 1stage detector이다.- 좌측 상단, 우측 하단 점을 이용하여 객체를 검출한다.
- Centor이 아니라 Corner를 사용하게 되면 2개의 면만 고려해주면 되기 때문에 모서리를 사용한다.
Architecture
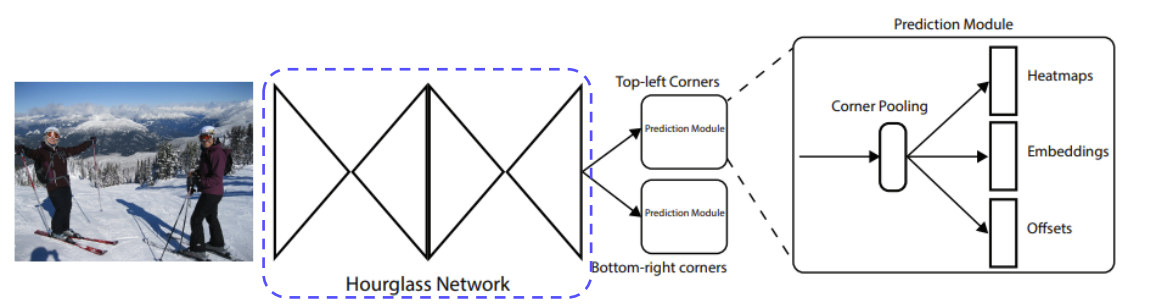
Heatmaps
- h,w,c의 feature map
- c는 채널이 아니라 category의 수이다.
Embeddings
- top left와 bottom right를 mapping하기 위해 사용한다.
- Embedding vector의 거리가 가까우면 같은 객체를 의미한다.
Offsets
- 이미지가 conv 연산을 할 때 downsampling upsampling 등으로 데이터 소실 문제가 발생한다.
- 작은 값의 상실은 작은 bounding box에 큰 영향을 미치므로 이것을 조정하기위해 사용한다.
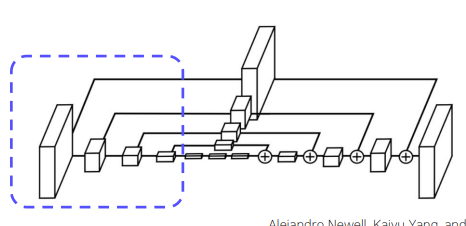
Hourglass Network
- Human Pose Estimation Task에서 사용하는 모델로 Global, Local 정보 모두 추출이 가능하다.
- Encoder는 입력으로부터 특징을 추출하고 Decoder는 그것을 바탕으로 재구성하는 부분이다.
Encoding Part
- Feature 추출 : Conv layer + maxpooling layer
- 별도의 branch로 convolution을 진행해서 scale마다 feature를 추출한다.
CornerNet에서는 Maxpooling 대신 stride 2를 사용하고 5번 scale을 감소시킨다.
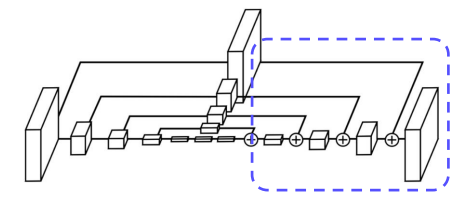
Decoding Part
- Encoder 과정에서 추출한 feature를 조합한다.
- Upsampling 과정에서는 Nearest Neighborhood Sampling, feature조합에서는 element-wise addition을 사용한다.
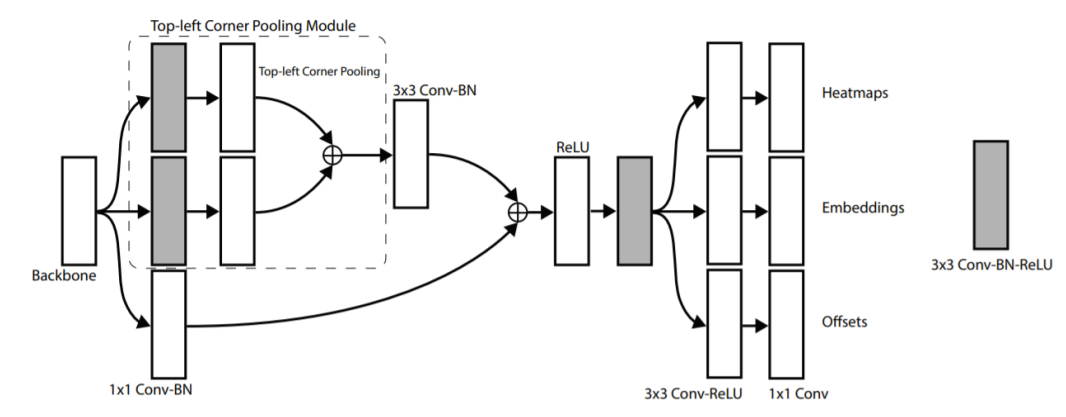
Predicition Module
- 2개의 heatmpa을 통해서 예측한다.
- HxWxC로 구성되어있다.
- 각 채널은 클래스에 해당하는 corner의 위치를 나타내는 binary mask이다.
Detecting Corner
- 2개의 heatmpa을 통해서 예측한다.
- HxWxC로 구성되어있다.
- 각 채널은 클래스에 해당하는 corner의 위치를 나타내는 binary mask이다.
- 모든 negative 위치를 동일하게해서 penalty를 부여하지 않는다.
- Positive location 반지름 안에 들어오는 negative location들은 penalty를 감소시킨다.
- 반지름은 물체의 크기에 따라 결정짓는다.
- 거리에 따라 패널티가 감소한다.
- Focal Loss 변형
- 정답에 근접한 예측값은 낮은 loss를 부여한다.
- convolution을 통과하면서 heatmap에 floating point loss가 발생한다.
- Heatmap에서 이미지로 위치를 다시 mapping 시킬 때 차이가 발생한다.
- Offset을 사용하여 예측한 위치를 약간 조정한다.
- Smooth L1 Loss를 사용한다.
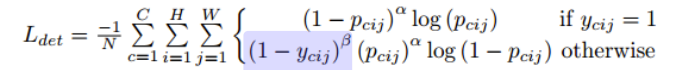

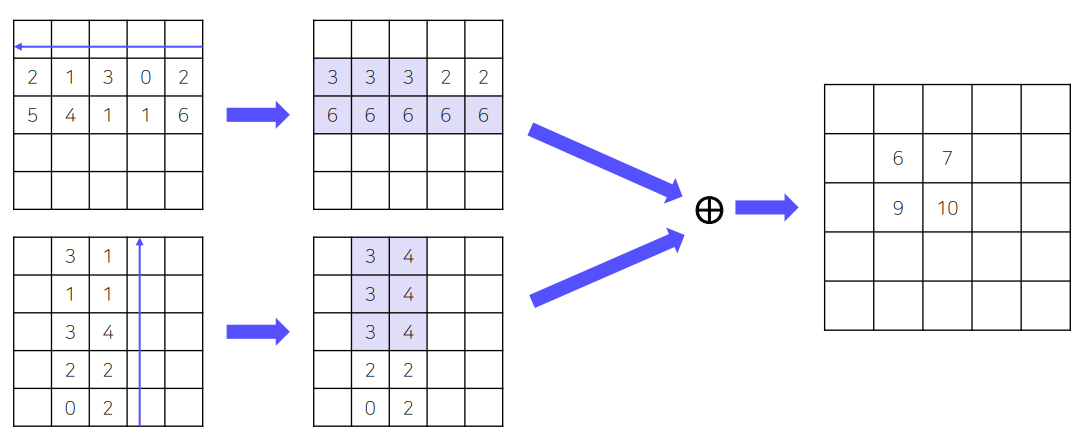
Grouping Corner
- Corner에는 특징적인 부분이 없다.
- Corner를 결정하기 위해서 Corner Pooling 과정이 필요하다.
- Top left 코너에 어떤 특징점이 없고 그냥 배경위에 점을 찍는다.
- 코너에 객체 정보를 집약시켜주는것을 corner pooling이라 한다.
각 객체를 담고있는 feature map의 최대값이 corner가 된다.