Semantic Segmentation
어떤 이미지가 있을 때 각 픽셀마다 분류를 하는 것으로 강아지 고양이 이런식으로 분류하는것이 아니고 이미지의 모든 픽셀이 어떤 라벨에 속하는지 예측하는 것이다.
Fully Convolutional Network
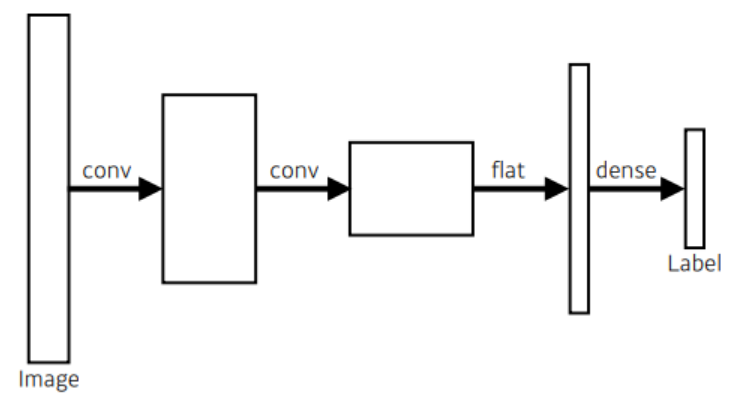
보통의 CNN 구조는 다음과 같은 구조를 따르게 된다.
반면 Fully Convolutional Network는 다음과 같은 구조를 따르게 된다.

dense layer를 없애는 과정을 convolutionalization이라고 하며 위의 CNN 모델에서 나오는 파라미터의 수와 정확히 일치하는 파라미터의 수가 나온다.
기존 CNN 모델의 문제점은 첫째, 공간/위치 정보를 잃는다. Fully connected layer에 값을 넘겨주기 위해 3차원 이미지 데이터는 1차원 벡터로 변형이된다. 예를들어 고양이가 담장 위 오른쪽 끝에 있다는 위치/공간 정보가 아닌 이것이 고양이 사진이다 식의 정보만 남게 된다.
둘째로 input 이미지의 크기가 고정되어 있다. fully connected layer의 weight 개수가 고정되어 있어서 전 단계의 feature map 크기가 고정되어 있기 때문이다.
이를 해결하는 방법이 바로 Convolutionalization이다. 1x1 Convolutional Layer로 변환하는 경우 input 이미지의 위치 정보를 끝까지 유지할 수 있다.
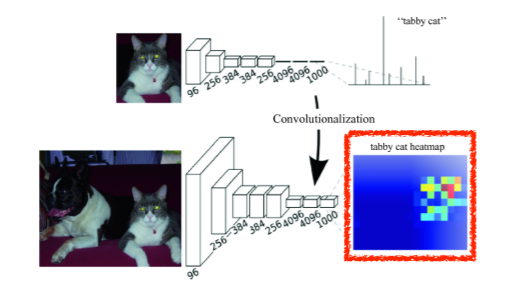
그러나 Convolutionalization에도 문제점이 있는데 바로 Convolutional Layer를 거치면서 점점 feature map의 크기는 줄고 두께가 점점 두꺼워진다. 목표인 픽셀단위의 정확하고 세밀한 segmentation을 output 이미지의 크기가 줄어들어 정보가 소실되면 달성하기 불가능해진다. 게다가 픽셀 단위의 예측에 비해 output의 feature map이 너무 coarse해질 경우 계산량이 너무 커져 효율이 떨어지게 된다. 따라서 해상도를 원본 이미지에 가깝게 올려주고 원본 이미지의 크기에 가까운 dense map으로 바꿔주는 작업이 필요하다.
Deconvolution
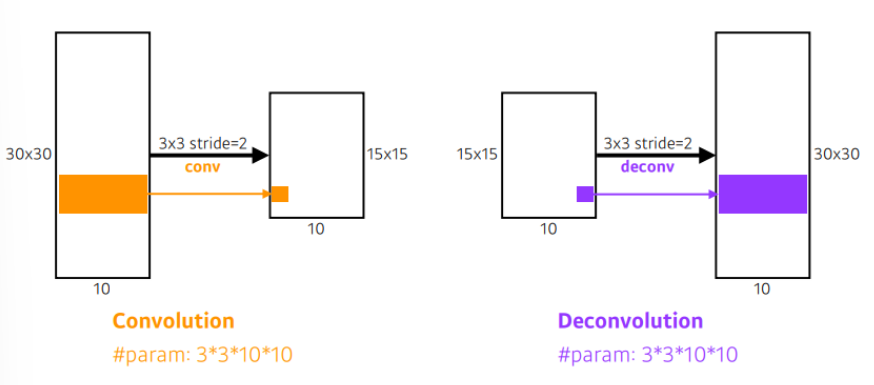
convolution을 거꾸로 수행하는 것이다. output 이미지와 filter를 사용하여 input 이미지를 얻어내기 위한 연산을 한다.

예를들어 3x3 크기의 filter 1개를 5x5 크기의 input 이미지 위에서 stride 2로 움직여 2x2 크기의 feature map 1개를 얻었다고 하면 이를 되돌리기 위해서 2x2 크기의 이미지의 각 픽셀마다 9개의 값을 추출한 뒤 stride 2로 움직여 5x5 크기의 이미지를 얻어내는 것을 deconvolution과정이라고 한다.
Detection
이미지 안에서 어느 물체가 어디 위치에 있는지 찾는 것이다.
픽셀 단위가 아닌 bouding box로 찾는 것이다.
R-CNN
Regional CNN으로 가장 간단한 방법이다.
여러 개의 region(패치)를 뽑고 selective search 방법을 사용한다.
bounding box이므로 현재 크기가 다르기 때문에 이것을 CNN에 돌리기 위해서 같은 크기로 맞춰준다. 이때 region에 대한 feature는 CNN을 통해 얻고 feature를 뽑을 때에는 AlexNet을 사용하고 분류에는 linear SVM을 사용한다.
이 방법의 가장 큰 문제는 bounding box를 2000개 뽑으면 그 2000개의 이미지패치를 전부 CNN에 통과시켜야 하기 때문에 엄청난 연산이 필요하다. -> 시간이 오래걸림
SPPNet

R-CNN의 문제점인 시간이 오래걸리는 것을 해결하기 위해 나온 것으로 이미지 안에서 bounding box를 뽑고 이미지 전체에 대한 convolutional feature map을 만들고 뽑힌 bounding box의 위치의 convolutional feature map의 sub-tensor만 들고오는 것이다.
결론적으로 CNN을 한 번 돌려서 얻어지는 convolutional feature map 위에서 얻어도고자 하는 bounding box의 패치를 뜯어오는 것이다.
Fast R-CNN
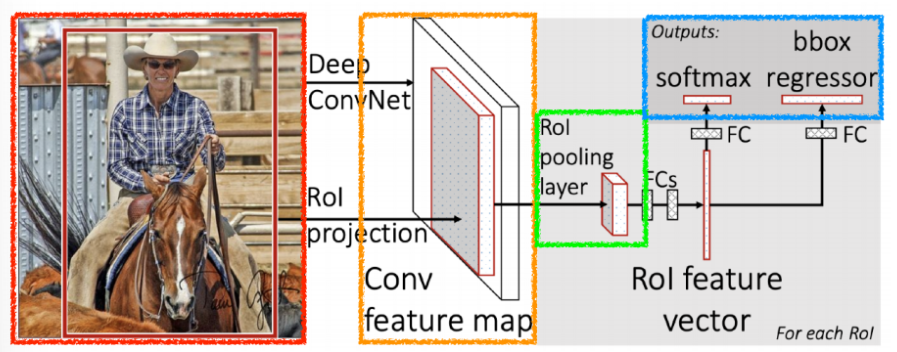
input이 들어오면 selective search(이미지 후보 영역을 추천할 때 사용하는 알고리즘)를 통해서 boudning box를 2천개정도 뽑고 CNN을 한 번 통과하여 convolution map을 한번 얻는다 그 다음 각자의 region에 대해서 RoI(Region of Interest)를 통해 fixed length feature를 뽑는다.
Faster R-CNN
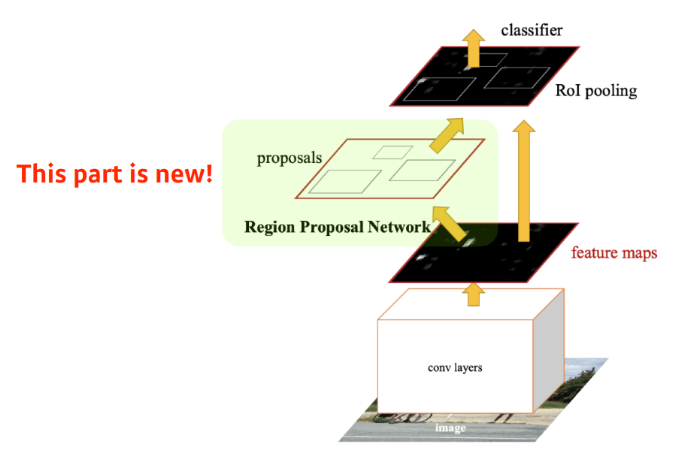
기존 Fast R-CNN의 구조를 그대로 가져오면서 selective search를 제거하고 Region Proposal Network(RPN)를 통해 RoI를 계산한다. bounding box를 뽑아내는 selective search 방식이 detection에 맞지 않기 때문이다.
RPN

이미지에서 특정영역이 bouding box로서의 의미가 있는지, 이 안에 물체가 있는지 없는지 찾아주는 역할이다. 미리 정해놓은 bounding box의 크기를 지칭하는 Anchor box가 필요하다.
이 이미지 안에 어떤 크기의 물체가 있을 건지 알고 있는 것
k개의 템플릿을 만들어놓고 이 템플릿에 얼마나 바뀔지에 대한 offset을 찾고 궁극적으로는 템플릿을 미리 고정해놓는게 가장 큰 특징
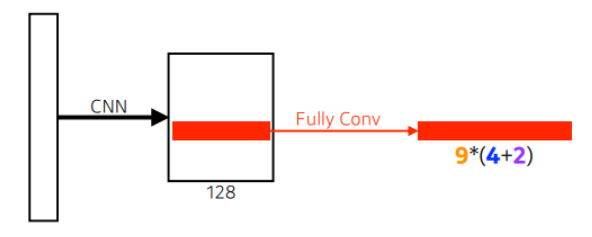
9는 anchor box의 type(9개의 region size 중 하나를 고름)이고 4는 bouding box의 regression(width, height, x_offset, y_offset 얼마나 키우고 줄일지), 2는 사용여부를 결정하는 것이다.
YOLO

한 개의 네트워크에서 탐지를 원하는 물체의 영역(bounding box)와 이름을 표시한다. 이미지를 입력으로 받고 SxS 크기의 grid로 이미지를 나눈다. 각 grid에서 예측을 한 후 이를 종합하여 bouding box를 구성한다.
이미지 한 장에서 바로 찍어서 결과를 만들어 내므로 매우 빠른 속도를 자랑한다.
grid cell안에 물체의 중앙이 들어가게 되면 그 cell이 해당 물체에 대한 bouding box와 물체가 무엇인지 예측해준다.
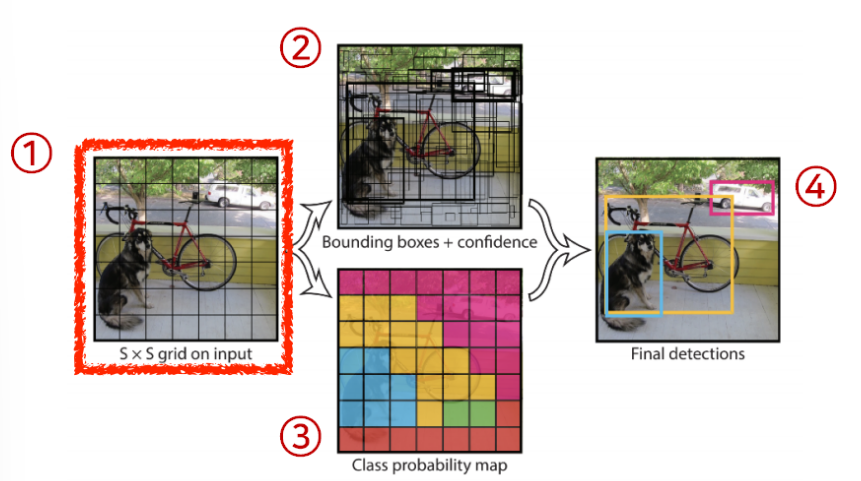
B개의 bouding box에 대한 x,y,w,h를 찾아주게 되고 그 box가 쓸모 있는지도 함께 찾아준다. 두 정보를 취합하여 bouding box와 그 box가 어떤 것을 의미하는지 알 수 있게 된다.
요약하면 다음과 같다.
SxSx(B5C) 사이즈의 tensor를 만든다.
이 중 (B5C)는 채널의 크기이다.
B개의 bounding box가 있고 그 박스마다 5개의 property를 가진다. (x,y,w,h,confidence(사용여부)) 그리고 C개의 class probability도 함께 가진다.
객 채널에 맞는 정보가 들어갈 수 있도록 Neural Network가 학습을 진행한다.
