Optimization
Generalization
Generalization
일반화는 학습 데이터로 이루어진 모델이 얼마나 테스트 데이터에서 잘 동작하는지를 나타내는 개념이다.
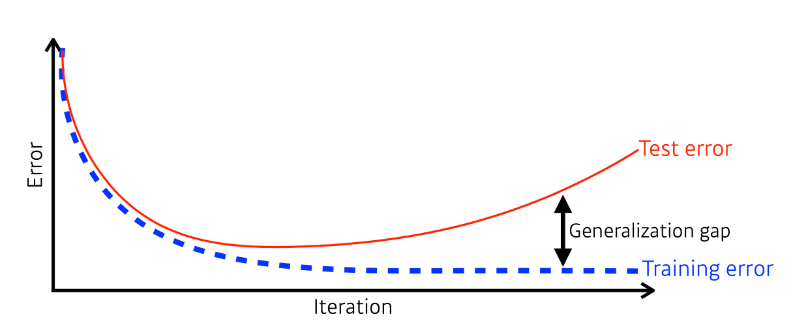
학습이 진행될 수록 Training error가 줄어들지만 어느 정도 시간이 흐른 뒤에는 Test Error가 증가하게 된다. Test Error와 Training Error의 차이를 Generalization Gap이라고 하며 이것이 크면 Generalization Performance가 낮다고 볼 수 있다.
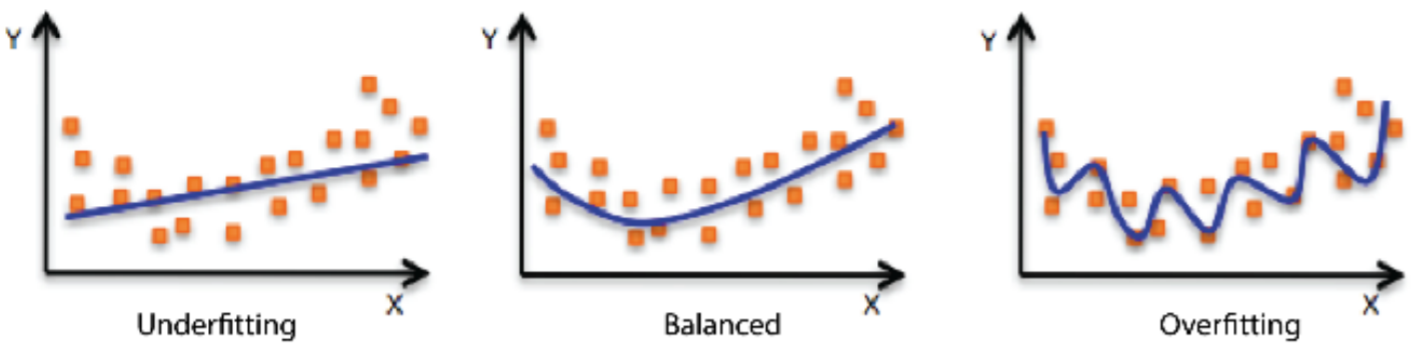
Underfitting vs Overfitting
Underfitting vs Overfitting
Underfitting은 네트워크가 작거나 학습을 적게 해서 학습 데이터의 정확률이 낮은 것을 의미한다.
Overfitting은 반대로 학습데이터에 너무 과도하게 잘 맞는 것을 의미한다. 그래서 테스트데이터에는 잘 동작하지 않는 것을 의미한다.
Cross Validation
Cross Validation
데이터는 크게 train data와 test data로 나누는데 train data에서 검증을 하기 위해 일정 부분을 분리시켜 만든 data를 말한다.
train data로 학습 시킨 모델이 train에 사용되지 않은 data 기준으로 얼마나 잘 동작하는지 알아보기 위해 사용한다.
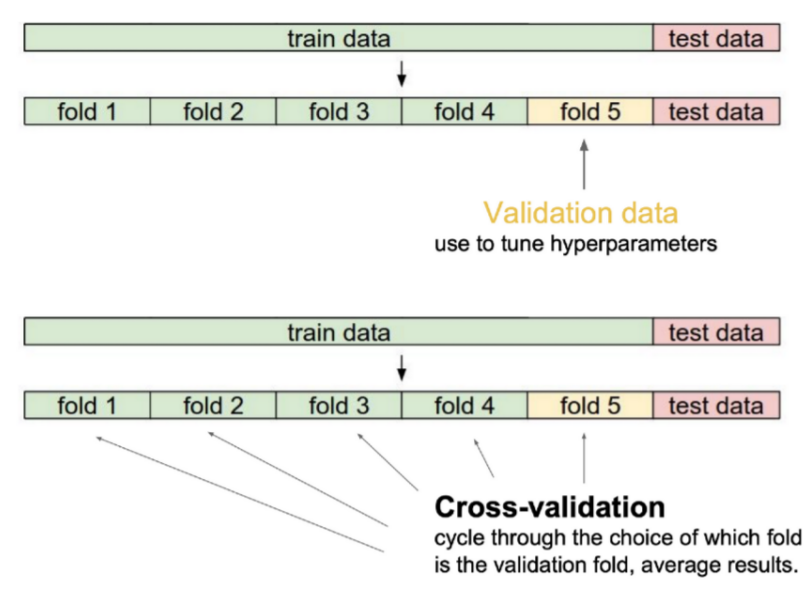
Cross validation은 train data를 k개의 fold로 나누고 1개의 fold는 validation data로 나머지 것들은 train data로 사용한다. 이를 fold마다 번갈아가면서 k번을 수행하여 서로 다른 validation값들이 나오면 그것들의 평균을 낸다.
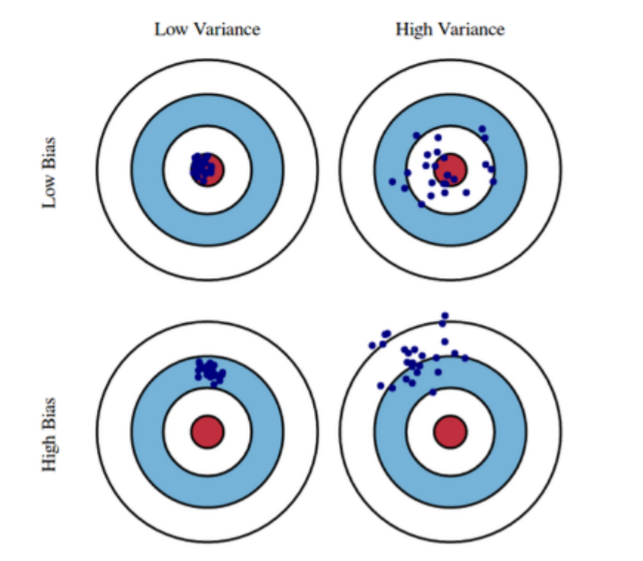
Bias and Variance
Bias and Variance
Variance는 출력이 얼마나 일관되어있는지를 나타내는 지표이다. Variance가 낮으면 출력이 일관되게 출력되고 높으면 출력이 산발적으로 출력된다.
Bias는 출력이 얼마나 Target 또는 mean과 가까운지를 나타내는 지표이다. Bias가 낮으면 가깝고 높으면 멀다.
Bootstrapping
고정된 학습데이터를 가지고 랜덤하게 샘플링 된 데이터로 여러 모델을 만들어 어떤 목적을 수행하는 것이다. 하나의 입력에 대해 여러 모델이 같은 값을 예측할 수도 있고 다른 값을 예측할 수도 있다. 그래서 입력 값들에 대해 이 모델들의 출력값의 일치도를 보고 모델의 불확실성을 예측할 때에 사용한다.
Bagging vs Boosting
Bagging : Bootstrapping 방법을 사용하며 전체 데이터에서 일부를 추출하여 여러 모델들을 만들고 그것들의 평균을 낸다.
Boosting : 전체 학습 데이터에 대해 모델을 만들고 그 중 학습이 잘 안된 데이터에 대해 또 다른 모델을 만들어서 학습이 잘 되도록 하는 작업을 반복적으로 수행한다. 마지막으로 이렇게 만들어진 모델들을 하나로 합친다.
Gradient Descent Methods
Stochastic gradient descent : 전체 학습 데이터에서 한 번에 한 개의 sample data에 대해서 backpropagation으로 gradient를 구하고 그 값을 갱신하는 것을 반복하는 것을 말한다.
Mini-batch gradient descent : 배치 사이즈를 일정 사이즈로 정하고 그것에 대해서 계산된 gradient를 갱신한다.(대부분 이 방법을 사용)
Batch gradeint descent : 전체 데이터에 대해 계산된 gradient를 사용하여 parameter를 갱신한다.
Gradient Descent
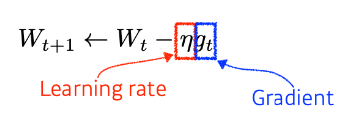
W는 update 될 parameter vector, t는 Time, g는 미분값을 의미한다.
graidient값을 학습률이라고 하는 Learning Rate값과 곱해서 W와 빼주고 그 값을 갱신하는 방법이다. 적절한 학습률 설정이 정말 중요하다.
Momentum
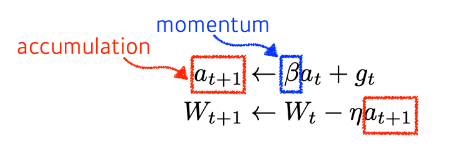
한 번 계산되고 g_t를 버리지 않고 그 값이 β(momentum)과 같이 계산되어 accumulation에 들어가게 되고 다음 번의 경사하강 계산의 a_t로써 들어간다.
전에 계산된 방향으로 조금 보정해서 흘러가는 방법이다.
Nesterov Accelerated Gradient
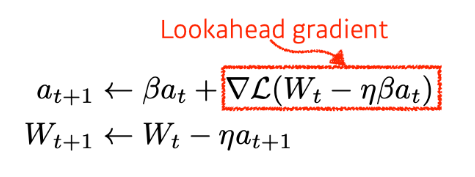
Accumulate Gradient인 a와 Learning Rate가 곱해져서 경사하강하는 방식이다. 이 때에 Lookahead Gradient를 계산하는데 이것은 a라는 현재 gradient 정보가 있으면 그 반대방향으로 가서 거기서 gradient를 계산하여 accumulate한다.
Adagrad
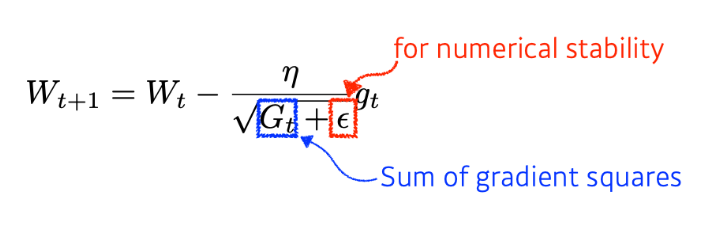
네트워크가 학습하면서 parameter값이 많이 변했다면 적게 반대로 적게 변한 parameter에 대해서는 크게 변화시키는 방식이다.
G_t 값이 커진다는 것은 해당하는 parameter들이 많이 변했다는 것을 의미한다. 역수를 취해졌기 때문에 다음 번에는 적은 그 만큼 적은 변화가 일어나게 된다.
그러나 이 값이 무한대로 커지게 되면 gradient값이 무한대로 작아지게 되어 학습이 멈추는 현상이 일어나게 되는 것이 문제점이다.
Adadelta

Adagrad에서 G_t값이 무한대로 커지는 것을 방지하기 위한 방법이다. 고정적인 Learning Rate가 아니라 Learning Rate를 갱신하면서 학습을 수행한다.
H_t는 실제로 갱신하고자하는 parameter의 값을 미분하여 제곱한 값이고 이것을 H_t-1의 값과 감마 상수를 잘 조합한 값이다. 이 값을 G_t에 대한 역수값으로 넣어줘서 학습이 진행됨에 따라 뒤로 가도 학습이 진행되도록 할 수 있다.
Adam
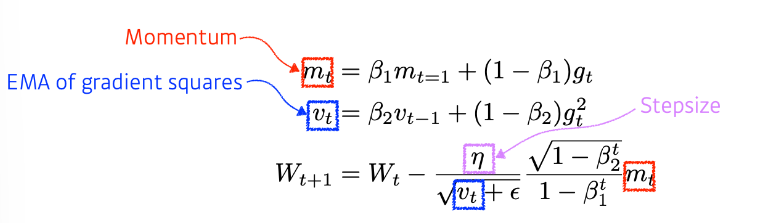
gradient의 크기가 바뀜에 따라 적응적으로 Learning Rate를 바꾸는 것과 이전에 계산된 Momentum을 현재 gradient값과 조합해 새로운 Momentum을 조합하는 방법이다.
Batch-size
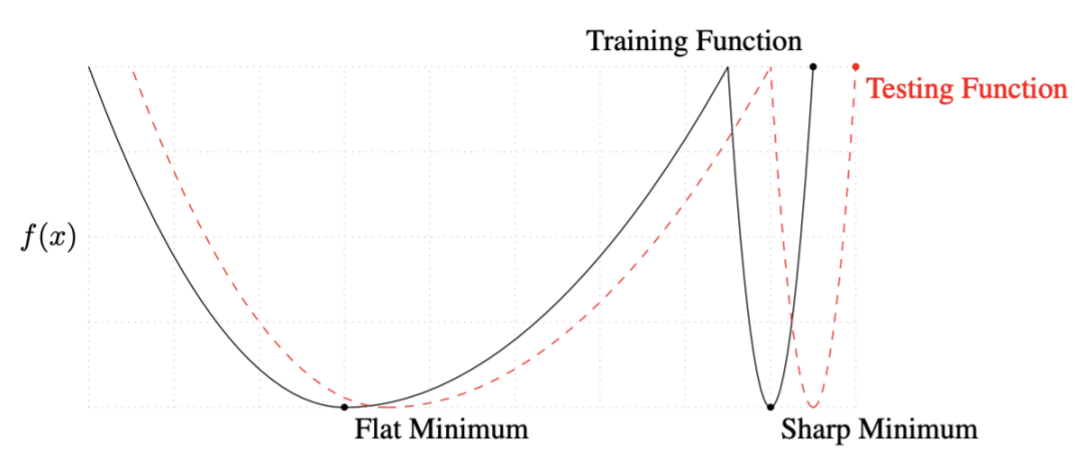
Flat Minimum에서 Training Function값이 멀어져도 Test Function의 값과 큰 차이를 보이지 않는 반면 Sharp Minimum에서는 약간만 멀어져도 아주 높은 값이 나온다. 이를 정리하여 말하면 Flat Mimimum에서는 Generalization performance가 높고 Sharp Minimum에서는 Generalization performance가 낮다.
